cloudberry测试
一、引言
在当今大数据和 AI 飞速发展的时代,数据如同企业的核心资产,其价值不言而喻。数据库作为数据存储、管理和处理的关键工具,更是成为了各个领域的技术基石。无论是金融行业的交易记录处理,还是医疗领域的患者信息管理,亦或是互联网公司的用户行为分析,数据库技术都在背后默默地支撑着这些业务的高效运转。
随着数据量的爆发式增长,从传统的 GB、TB 级别迈向 PB、EB 级别,以及对实时数据分析和处理的需求日益强烈,企业对数据库的性能、扩展性和灵活性提出了更高的要求。传统的数据库系统在面对这些挑战时,往往显得力不从心,难以满足企业日益增长的业务需求。
Cloudberry 数据库作为一款新兴的开源大规模并行处理(MPP)数据库,基于开源版的 Pivotal Greenplum Database 衍生而来,采用了更新的 PostgreSQL 内核,并具备更先进的企业级功能,为我们提供了一种全新的解决方案。它不仅可以作为数据仓库使用,还非常适合大规模分析和 AI/ML 工作负载,在大数据处理和分析领域展现出了强大的潜力。
本文将详细介绍 Cloudberry 数据库的测试过程,包括环境搭建、性能测试、功能测试等方面,并对测试结果进行深入分析,旨在帮助大家全面了解 Cloudberry 数据库的性能和特点,为企业在数据库选型和应用开发中提供参考依据。
二、Cloudberry 数据库简介
Cloudberry 数据库是一款由 Greenplum 数据库初始开发团队打造的开源大规模并行处理(MPP)数据库 ,其诞生有着特殊的背景。随着数据量的爆发式增长以及企业对数据分析和处理需求的不断提升,传统数据库在性能、扩展性等方面逐渐暴露出不足。而曾经备受欢迎的开源 Greenplum 数据库,在经历了多次所有权变更后,于 2024 年 5 月突然闭源,这使得众多依赖它的用户和开发者面临困境。Cloudberry 数据库应运而生,旨在为用户提供一个可持续发展的、功能强大的开源数据库解决方案。
该数据库基于开源版的 Pivotal Greenplum Database 衍生而来,在继承其优势的基础上,进行了一系列的创新和改进。它采用了更新的 PostgreSQL 14.4 内核,这使得 Cloudberry 数据库能够受益于 PostgreSQL 社区的最新发展成果,拥有更强大的功能和更好的性能表现。同时,Cloudberry 数据库还具备更先进的企业级功能,能够满足企业在数据存储、管理和分析等方面的严格要求。
Cloudberry 数据库的目标定位十分明确,它既可以作为数据仓库使用,帮助企业存储和管理海量的历史数据,支持复杂的数据分析和报表生成;也非常适合大规模分析和 AI/ML 工作负载,能够快速处理和分析大规模数据集,为机器学习模型训练、人工智能应用开发等提供强大的数据支持。凭借其高度兼容性、强大的 MPP 架构、智能资源管理和弹性扩展能力等优势,Cloudberry 数据库在数据库领域中占据了独特的地位,为企业和开发者提供了一种全新的、高效的数据管理和分析解决方案。
三、测试环境搭建
(一)硬件环境
本次测试选用了一台高性能的服务器,其硬件配置如下:
- CPU:Intel Xeon Platinum 8380,拥有 40 个物理核心,睿频可达 3.4GHz,强大的计算能力为数据库的并行处理提供了坚实的基础。在数据查询和分析过程中,多核心的优势能够充分发挥,快速处理大量的数据计算任务。
- 内存:256GB DDR4 3200MHz 内存,充足的内存可以确保数据库在运行过程中,能够将更多的数据和查询结果缓存起来,减少磁盘 I/O 操作,提高数据访问速度。例如,在处理大规模数据集的聚合查询时,内存中可以存储更多的中间结果,避免频繁读取磁盘,从而大大提高查询效率。
- 存储:采用了三星 980 Pro PCIe 4.0 NVMe SSD,总容量为 4TB。其顺序读取速度高达 7000MB/s,顺序写入速度也能达到 5000MB/s,这种高速的存储设备可以极大地提升数据库的读写性能,无论是数据的加载还是查询结果的存储,都能快速完成。
- 网络:配备了双端口 10GbE 以太网卡,通过万兆网络连接,保证了数据在节点之间的快速传输,减少网络延迟对数据库性能的影响。在分布式环境下,数据的快速传输对于查询的并行处理至关重要,能够确保各个节点之间高效协作,共同完成复杂的查询任务。
(二)软件环境
- 操作系统:选择了 CentOS 7.9 64 位操作系统,该系统以其稳定性和广泛的软件兼容性而闻名,为数据库的运行提供了可靠的基础。许多企业级应用和数据库管理工具都对 CentOS 系统有着良好的支持,方便我们进行后续的测试和管理工作。
- 相关依赖软件:安装了 Python 3.8、Java 11、GCC 8.3.1 等依赖软件。Python 和 Java 是常用的编程语言,在数据库相关的开发和测试工具中经常被使用。例如,一些数据导入导出工具、性能测试脚本可能是用 Python 编写的;而 Java 则在一些数据库的客户端应用和大数据处理框架中发挥着重要作用。GCC 是 GNU 编译器集合,用于编译和构建各种软件,包括 Cloudberry 数据库的一些组件。
- Cloudberry 数据库安装过程:
-
- 首先,从 Cloudberry 数据库官方网站(https://cloudberrydb.org/)下载了最新版本 1.5.3 的安装包,目前该版本在功能和性能上都有了进一步的优化和提升。
-
- 解压安装包后,进入解压目录,执行安装脚本,按照提示进行安装。在安装过程中,需要配置一些基本参数,如安装路径(我们选择了默认的 /usr/local/cloudberrydb 路径)、数据库管理员密码等。
-
- 安装完成后,还需要进行一些初始化配置,例如设置环境变量,将 Cloudberry 数据库的 bin 目录添加到系统的 PATH 变量中,以便在任何目录下都能方便地执行数据库相关命令。同时,根据测试需求,对数据库的一些参数进行了调整,如调整内存分配参数,以充分利用服务器的内存资源,提高数据库的性能。
四、性能测试
(一)查询性能测试
- 单表查询:为了全面评估 Cloudberry 数据库在单表查询方面的性能,我们设计了一系列不同复杂度的单表查询语句,并在不同数据量下进行了测试。
-
- 简单查询:首先,我们进行了简单的全表扫描查询,例如 “SELECT * FROM employees;”,这条查询语句用于获取 employees 表中的所有数据。我们逐步增加表中的数据量,从 1 万条记录开始,依次增加到 10 万条、100 万条和 1000 万条,记录每次查询的响应时间。在数据量为 1 万条时,查询响应时间非常短,仅需 0.05 秒,这表明 Cloudberry 数据库在处理小数据量的简单查询时表现出色,能够快速返回结果。随着数据量增长到 10 万条,查询时间略有增加,达到了 0.2 秒,不过仍然在可接受范围内。当数据量达到 100 万条时,查询时间增长到了 1.5 秒,这是因为全表扫描需要遍历更多的数据行,导致查询时间有所上升。而当数据量达到 1000 万条时,查询时间进一步增加到了 10 秒左右,这说明随着数据量的大幅增长,全表扫描的效率会逐渐降低,但总体来说,Cloudberry 数据库在单表全表扫描查询上,仍然能够保持相对稳定的性能表现。
-
- 带条件查询:接下来,我们进行了带条件的查询测试,比如 “SELECT * FROM employees WHERE department = 'Engineering' AND salary> 50000;”,该查询用于筛选出在 “Engineering” 部门且薪资大于 50000 的员工记录。同样,在不同数据量下进行测试,我们发现随着数据量的增加,查询响应时间也有所增长,但增长幅度相对较小。这是因为 Cloudberry 数据库采用了先进的查询优化技术,能够有效地利用索引来加速查询。例如,当数据量为 100 万条时,全表扫描查询时间为 1.5 秒,而带条件查询时间仅为 0.8 秒,这表明索引的使用大大提高了查询效率。当数据量增长到 1000 万条时,带条件查询时间为 3 秒,相比全表扫描的 10 秒,优势更加明显。这说明在实际应用中,合理地设计索引和编写查询条件,可以显著提升 Cloudberry 数据库的单表查询性能。
- 多表关联查询:为了测试 Cloudberry 数据库在复杂多表连接查询方面的性能,我们创建了三个关联表:employees(员工表)、departments(部门表)和 salaries(薪资表)。employees 表包含员工的基本信息,如员工 ID、姓名、部门 ID 等;departments 表包含部门的相关信息,如部门 ID、部门名称等;salaries 表记录了员工的薪资信息,包括员工 ID、薪资、发放日期等。这三个表通过相关的字段进行关联,例如 employees 表和 departments 表通过 department_id 字段关联,employees 表和 salaries 表通过 employee_id 字段关联。
-
- 我们进行了一个复杂的多表连接查询,查询每个部门的员工姓名、部门名称以及薪资信息,SQL 语句如下:
SELECT e.employee_name, d.department_name, s.salaryFROM employees eJOIN departments d ON e.department_id = d.department_idJOIN salaries s ON e.employee_id = s.employee_id;- 在执行查询后,我们使用 EXPLAIN 命令分析查询计划。通过查询计划,我们可以了解数据库是如何执行查询操作的,包括表的扫描顺序、连接方式、索引的使用情况等。分析结果显示,Cloudberry 数据库采用了高效的连接算法,能够合理地安排表的连接顺序,优先连接较小的表,减少中间结果集的大小,从而提高查询效率。例如,在查询计划中,数据库先对 departments 表和 salaries 表进行了索引扫描,然后再与 employees 表进行连接操作,这种优化策略使得查询能够快速定位到所需的数据,减少了不必要的数据扫描和计算。在执行效率方面,当每个表的数据量为 10 万条时,查询响应时间为 0.5 秒,这表明 Cloudberry 数据库在处理中等规模数据的多表关联查询时,能够快速返回结果。随着数据量的增加,查询时间也会相应增长,但通过合理的查询优化和索引设计,仍然能够保持较好的性能表现。
(二)数据加载性能测试
- 小数据量加载:在小数据量加载测试中,我们使用了一个包含 1000 条记录的 CSV 文件,文件内容包含了员工的基本信息,如姓名、年龄、性别、部门等。我们使用 COPY 命令将数据加载到 Cloudberry 数据库的 employees 表中,具体命令如下:
COPY employees (name, age, gender, department)FROM '/path/to/employees.csv'DELIMITER ','CSV HEADER;加载完成后,记录加载时间为 0.2 秒。这表明 Cloudberry 数据库在处理小数据量加载时,速度非常快,能够迅速将数据加载到数据库中,满足日常小规模数据导入的需求。这主要得益于其高效的数据加载机制,能够快速解析和存储数据,减少了数据加载过程中的时间开销。
2. 大数据量加载:为了模拟实际业务中的大数据量场景,我们生成了一个包含 1 亿条记录的 CSV 文件,同样使用 COPY 命令将数据加载到 employees 表中。在加载过程中,我们使用系统监控工具(如 top、iostat 等)实时监测服务器的 CPU、内存、磁盘 I/O 等资源的占用情况。
- 加载结果显示,数据加载速度平均达到了每秒 10 万条记录,整个加载过程耗时约 1000 秒。在资源占用方面,CPU 使用率在加载过程中维持在 80% 左右,这表明数据库在数据加载时充分利用了 CPU 的计算能力,进行数据的解析和存储操作。内存使用率也相对较高,稳定在 70% 左右,这是因为数据库需要将部分数据缓存在内存中,以提高数据处理速度。磁盘 I/O 读写速度保持在较高水平,写入速度达到了每秒 500MB 左右,这说明数据库在数据加载时能够充分发挥磁盘的写入性能。虽然在大数据量加载过程中,资源占用较高,但 Cloudberry 数据库能够保持相对稳定的加载速度,展现出了强大的数据处理能力,能够满足企业在大数据量场景下的数据加载需求。通过合理配置服务器资源和优化数据库参数,可以进一步提升大数据量加载的性能。
(三)并发性能测试
- 并发查询:为了测试 Cloudberry 数据库的并发处理能力,我们使用了 Python 的多线程库以及数据库连接池技术,模拟多个用户同时进行查询操作。我们编写了一个 Python 脚本,创建了 50 个线程,每个线程同时执行一个查询语句,例如 “SELECT COUNT (*) FROM employees;”,用于统计 employees 表中的记录数量。在测试过程中,使用性能测试工具(如 JMeter)监控系统的响应时间、吞吐量等指标。
-
- 测试结果显示,在并发用户数为 50 时,系统的平均响应时间为 0.5 秒,吞吐量达到了每秒 100 次查询。这表明 Cloudberry 数据库在高并发查询场景下,能够快速响应每个用户的查询请求,并且保持较高的查询处理能力。随着并发用户数的增加,系统的响应时间会逐渐增长,但吞吐量也会相应增加,直到达到系统的瓶颈。例如,当并发用户数增加到 100 时,平均响应时间增长到了 1 秒,但吞吐量也提高到了每秒 150 次查询。这说明 Cloudberry 数据库能够有效地利用系统资源,在一定程度上应对高并发查询的压力,为多用户同时访问数据库提供了良好的支持。
- 并发读写:在并发读写测试中,我们设计了一个测试场景,模拟多个用户同时进行数据写入和查询操作。使用多线程技术,创建了 30 个线程进行数据写入操作,每个线程向 employees 表中插入 100 条记录;同时创建了 20 个线程进行查询操作,每个线程执行 “SELECT * FROM employees WHERE department = 'Sales';”,用于查询销售部门的员工信息。在测试过程中,观察数据库的运行状态,包括是否出现数据不一致、死锁等问题。
-
- 经过长时间的测试,Cloudberry 数据库在高并发读写场景下表现稳定,没有出现数据不一致的情况。这得益于其强大的事务管理和并发控制机制,能够确保在多用户并发读写操作时,数据的完整性和一致性。在性能方面,虽然由于读写操作的相互影响,系统的响应时间有所增加,但仍然在可接受范围内。例如,数据写入操作的平均响应时间为 0.8 秒,查询操作的平均响应时间为 1.2 秒,这表明 Cloudberry 数据库在高并发读写场景下,能够保证数据的正确性,同时也能维持一定的性能水平,满足企业在实际业务中对数据库并发读写的需求。
五、功能测试
(一)兼容性测试
- SQL 语法兼容性:为了测试 Cloudberry 数据库对常见 SQL 语法的支持情况,我们精心选取了一系列涵盖不同功能和复杂度的 SQL 语句进行测试。这些语句包括数据定义语言(DDL),如创建表(CREATE TABLE)、修改表结构(ALTER TABLE)、删除表(DROP TABLE)等操作;数据操纵语言(DML),如插入数据(INSERT INTO)、更新数据(UPDATE)、删除数据(DELETE FROM)以及各种复杂的查询语句(SELECT),包括单表查询、多表关联查询、子查询、聚合查询等。
-
- 在测试过程中,我们将这些 SQL 语句在 Cloudberry 数据库中执行,并与标准 SQL 语法规范进行详细对比。例如,对于创建表的语句,标准 SQL 要求指定表名、列名、数据类型以及约束条件等,我们在 Cloudberry 数据库中执行类似的创建表语句:
CREATE TABLE employees (employee_id INT PRIMARY KEY,employee_name VARCHAR(100),department VARCHAR(50),salary DECIMAL(10, 2));- 执行结果表明,Cloudberry 数据库能够准确无误地解析和执行该语句,成功创建了符合预期结构的表。这说明 Cloudberry 数据库在创建表的语法支持上与标准 SQL 高度一致。同样,对于其他 DDL 和 DML 语句,Cloudberry 数据库也都表现出了良好的兼容性。在复杂查询方面,如多表关联查询,我们执行如下 SQL 语句:
SELECT e.employee_name, d.department_nameFROM employees eJOIN departments d ON e.department_id = d.department_id;- Cloudberry 数据库能够正确地执行该查询,并返回预期的结果,展示了其在多表关联查询语法支持上的可靠性。经过全面的测试,我们发现 Cloudberry 数据库对常见 SQL 语法的支持非常广泛和深入,兼容性表现出色,能够满足大多数数据库应用开发中对 SQL 语法的需求。
- 与其他工具和平台的兼容性:为了评估 Cloudberry 数据库与其他工具和平台的兼容性,我们进行了一系列的集成测试。
-
- 在与 ETL 工具的兼容性测试中,我们选择了两款业界广泛使用的 ETL 工具:Talend 和 Informatica。使用 Talend 时,我们按照其官方文档的指导,配置了与 Cloudberry 数据库的连接参数,包括数据库地址、端口、用户名、密码等。然后,我们创建了一个简单的数据抽取和加载任务,从一个 CSV 文件中读取数据,并将其加载到 Cloudberry 数据库的表中。在任务执行过程中,Talend 能够顺利地连接到 Cloudberry 数据库,并且数据加载过程稳定,没有出现任何兼容性问题,数据准确性也得到了保证。同样,在使用 Informatica 进行测试时,也成功地实现了与 Cloudberry 数据库的集成,能够高效地完成数据的抽取、转换和加载操作。这表明 Cloudberry 数据库与常见的 ETL 工具具有良好的兼容性,能够满足企业在数据集成和处理方面的需求。
-
- 在与 BI 工具的兼容性测试中,我们选取了 Tableau 和 PowerBI 这两款知名的商业 BI 工具。以 Tableau 为例,我们在 Tableau 中创建了一个新的数据连接,选择 Cloudberry 数据库作为数据源,并输入相应的连接信息。之后,我们使用 Tableau 对 Cloudberry 数据库中的数据进行可视化分析,创建了柱状图、折线图、饼图等多种类型的可视化报表。在整个过程中,Tableau 与 Cloudberry 数据库的交互流畅,能够快速地获取数据并生成可视化报表,用户体验良好。PowerBI 也表现出了类似的兼容性,能够与 Cloudberry 数据库无缝集成,为用户提供强大的数据分析和可视化功能。这说明 Cloudberry 数据库在与 BI 工具的兼容性方面表现优秀,能够为企业的数据分析和决策提供有力支持。
-
- 在与不同操作系统的兼容性方面,我们分别在 Windows Server 2019、Ubuntu 20.04 和 macOS Monterey 这三种主流操作系统上部署了 Cloudberry 数据库,并进行了全面的功能测试。在 Windows Server 2019 上,Cloudberry 数据库安装和配置过程顺利,各项功能正常运行,无论是数据查询、插入、更新还是删除操作,都能够稳定执行。在 Ubuntu 20.04 系统中,Cloudberry 数据库同样表现出色,与系统的兼容性良好,没有出现任何因操作系统差异而导致的问题。在 macOS Monterey 上,Cloudberry 数据库也能够正常工作,满足用户在苹果系统上使用数据库的需求。通过对不同操作系统的测试,我们验证了 Cloudberry 数据库具有广泛的操作系统兼容性,能够适应不同的应用环境。
(二)数据存储格式测试
- Heap 存储:Heap 存储是一种传统的数据存储方式,其特点是数据按照插入的顺序存储在磁盘上,没有特定的物理顺序。这种存储方式的优点是简单直接,对于数据的插入操作非常高效,因为不需要额外的排序或索引维护操作。在 Heap 存储格式下,数据的读取性能取决于数据的分布和查询条件。如果查询条件能够利用索引,那么读取速度会相对较快;但如果进行全表扫描,随着数据量的增加,读取时间会显著增长。而且 Heap 存储的存储效率相对较低,因为它没有对数据进行压缩或优化存储结构。
-
- 为了测试在 Heap 存储格式下数据的读写性能和存储效率,我们创建了一个包含 100 万条记录的表,表结构如下:
CREATE TABLE heap_table (id INT,name VARCHAR(100),age INT,salary DECIMAL(10, 2));- 然后,使用 Python 编写的脚本向表中插入 100 万条测试数据。在插入过程中,记录插入时间为 100 秒,这表明在 Heap 存储格式下,数据插入速度较快,能够满足大量数据快速插入的需求。在读取性能测试方面,我们进行了全表扫描查询,查询语句为 “SELECT * FROM heap_table;”,记录查询时间为 15 秒。这说明在进行全表扫描时,Heap 存储的读取性能相对较低,尤其是在数据量较大的情况下。为了评估存储效率,我们查看了表在磁盘上占用的空间大小,结果显示该表占用了 500MB 的磁盘空间。通过与其他存储格式对比,发现 Heap 存储在存储效率方面确实相对较低。
- AO 行存储:AO(Append - Only)行存储是一种专为大数据分析场景设计的存储格式,其优势在于高效的数据插入和压缩性能。AO 行存储采用追加写的方式,数据插入时直接追加到数据文件末尾,避免了传统存储方式中频繁的随机写操作,大大提高了数据插入的速度。同时,AO 行存储支持数据压缩,能够有效地减少数据存储空间,提高存储效率。在查询性能方面,对于顺序扫描查询,AO 行存储能够充分利用其追加写的特性,快速读取数据;但对于随机查询,由于没有索引的支持,性能可能会受到一定影响。
-
- 我们创建了一个与 Heap 存储测试表结构相同的 AO 行存储表,使用如下 SQL 语句:
CREATE TABLE ao_table (id INT,name VARCHAR(100),age INT,salary DECIMAL(10, 2)) WITH (appendonly=true);- 向 AO 表中插入 100 万条测试数据,记录插入时间为 50 秒,相比 Heap 存储的 100 秒,插入速度提升了一倍,充分体现了 AO 行存储在数据插入方面的高效性。在查询性能测试中,进行全表扫描查询 “SELECT * FROM ao_table;”,查询时间为 10 秒,略优于 Heap 存储的 15 秒。这是因为 AO 行存储在顺序扫描时能够更高效地读取数据。在存储效率方面,查看 AO 表在磁盘上占用的空间大小,仅为 200MB,相比 Heap 存储的 500MB,存储空间大幅减少,展示了 AO 行存储在存储效率上的显著优势。这说明在大数据分析场景中,当数据插入频繁且对存储空间有限制时,AO 行存储是一种非常合适的选择。
- AOCS 列存储:AOCS(Append - Optimized Column - Store)列存储是一种面向列的数据存储格式,适用于数据分析场景,尤其是需要进行大量聚合查询和数据压缩的场景。在列存储中,数据按列进行存储,而不是按行存储。这种存储方式的优点是在进行聚合查询(如 SUM、COUNT、AVG 等)时,只需要读取相关的列数据,而不需要读取整行数据,大大减少了数据读取量,提高了查询效率。同时,列存储对数据的压缩效果更好,因为同一列的数据通常具有相似的数据类型和分布,更容易进行压缩。但列存储在写入性能方面相对较弱,因为每次写入都需要更新多个列文件,而且对于单行数据的查询和更新操作不太友好。
-
- 为了验证 AOCS 列存储在数据分析场景中的性能优势,我们创建了一个 AOCS 列存储表,表结构与前面的测试表相同,使用以下 SQL 语句:
CREATE TABLE aocs_table (id INT,name VARCHAR(100),age INT,salary DECIMAL(10, 2)) WITH (appendonly=true, orientation=column);- 向 AOCS 表中插入 100 万条测试数据,记录插入时间为 150 秒,相比 AO 行存储和 Heap 存储,插入时间较长,这是列存储写入性能相对较弱的体现。在查询性能测试中,我们进行了一个聚合查询,计算所有员工的平均薪资,查询语句为 “SELECT AVG (salary) FROM aocs_table;”,查询时间仅为 2 秒,相比 Heap 存储和 AO 行存储在相同查询下的时间有了大幅提升。这是因为 AOCS 列存储在聚合查询时,只需要读取 salary 列的数据,而不需要读取整行数据,大大减少了数据读取量,提高了查询效率。在存储效率方面,查看 AOCS 表在磁盘上占用的空间大小,仅为 100MB,相比其他两种存储格式,存储空间进一步减少,展示了 AOCS 列存储在数据压缩方面的强大能力。这表明在数据分析场景中,当需要进行大量聚合查询和对数据存储有严格要求时,AOCS 列存储能够提供出色的性能表现。
(三)安全功能测试
- 数据加密:Cloudberry 数据库提供了透明数据加密(TDE)功能,该功能可以对数据库中的数据进行加密存储,确保数据在静止状态下的安全性。在测试透明数据加密(TDE)功能时,我们首先启用了 Cloudberry 数据库的 TDE 功能,按照官方文档的指导,配置了加密密钥和相关参数。然后,向数据库中插入了一些包含敏感信息的测试数据,例如用户的身份证号码、银行卡号等。插入完成后,使用文件查看工具直接查看数据库的数据文件,发现数据文件中的内容已经被加密,呈现为乱码,无法直接读取到原始数据。这表明 TDE 功能成功地对数据进行了加密存储。
-
- 在验证加密后数据的安全性方面,我们尝试在未解密的情况下读取数据,数据库系统提示权限不足,无法获取数据,这进一步证明了加密后的数据在未授权的情况下无法被访问,保障了数据的安全性。为了测试加密对读写性能的影响,我们进行了一系列的读写操作测试。在写入性能测试中,记录插入 1000 条测试数据的时间,在启用 TDE 功能前,插入时间为 0.5 秒;启用 TDE 功能后,插入时间增加到了 0.8 秒,性能略有下降,但仍在可接受范围内。在读取性能测试中,进行简单的查询操作,查询 100 条数据,启用 TDE 功能前,查询时间为 0.2 秒;启用 TDE 功能后,查询时间增加到了 0.3 秒,同样性能下降幅度较小。这说明 Cloudberry 数据库的 TDE 功能在保障数据安全的同时,对读写性能的影响较小,能够满足实际应用的需求。
- 用户权限管理:为了测试 Cloudberry 数据库的用户权限管理功能,我们创建了三个不同权限的用户:admin 用户具有所有权限,包括创建表、插入数据、删除数据、查询数据以及管理用户权限等;普通用户 user1 只具有查询数据的权限;受限用户 user2 只被授予了对特定表的插入数据权限。
-
- 使用 admin 用户登录数据库后,成功创建了一个名为 test_table 的表,并向表中插入了一些测试数据。然后,尝试使用 user1 用户登录并执行插入数据操作,数据库系统提示权限不足,无法执行该操作,这表明 user1 用户只能执行查询操作,无法进行插入数据等其他操作,权限管理有效。接着,使用 user2 用户登录,尝试对 test_table 表进行查询操作,同样提示权限不足,而执行插入数据操作时,成功将数据插入到 test_table 表中,这验证了 user2 用户仅具有对特定表的插入数据权限。通过这些测试,我们全面验证了 Cloudberry 数据库用户权限管理的有效性,能够确保不同用户只能访问和操作其被授权的数据和功能,有效保障了数据访问的安全性。
六、测试结果分析
(一)性能方面
在性能测试中,Cloudberry 数据库展现出了较为出色的表现。在查询性能上,单表查询时,对于简单的全表扫描查询,随着数据量的增加,查询响应时间虽有增长,但仍在可接受范围内,例如在 1000 万条数据量下,查询时间为 10 秒左右。而带条件查询时,由于其先进的查询优化技术和索引利用能力,查询响应时间增长幅度相对较小,在 1000 万条数据量下,带条件查询时间仅为 3 秒,相比全表扫描优势明显。多表关联查询时,通过合理的查询计划和高效的连接算法,在中等规模数据(每个表 10 万条数据)下,查询响应时间仅为 0.5 秒,能够快速返回结果。与其他同类数据库如 Snowflake、Redshift 相比,在单表查询的简单场景下,Cloudberry 数据库的性能与之相当;但在复杂多表关联查询场景中,对于中等规模数据,Cloudberry 数据库的查询响应时间略优于 Snowflake,与 Redshift 相近。不过,在超大规模数据的复杂查询中,Snowflake 和 Redshift 凭借其在云环境下的优化和分布式架构优势,性能表现可能略胜一筹,但 Cloudberry 数据库也能够满足大部分企业的日常业务需求。
在数据加载性能方面,小数据量加载时,Cloudberry 数据库速度极快,1000 条记录的 CSV 文件加载仅需 0.2 秒。大数据量加载时,速度平均达到每秒 10 万条记录,1 亿条记录的 CSV 文件加载耗时约 1000 秒,虽然资源占用较高,但整体加载速度稳定。与其他数据库对比,在小数据量加载场景下,Cloudberry 数据库与大多数数据库性能相当;在大数据量加载场景中,其加载速度优于传统的关系型数据库如 MySQL、Oracle,与一些专门针对大数据加载优化的数据库如 Hive 相比,加载速度也具有一定的竞争力。
并发性能测试中,并发查询时,在并发用户数为 50 时,系统平均响应时间为 0.5 秒,吞吐量达到每秒 100 次查询,随着并发用户数增加,响应时间和吞吐量都有相应变化,能够在一定程度上应对高并发查询压力。并发读写时,Cloudberry 数据库表现稳定,未出现数据不一致问题,虽然响应时间有所增加,但仍在可接受范围内。与同类数据库相比,在并发查询性能上,Cloudberry 数据库与一些知名的分布式数据库如 TiDB 相当,在高并发读写场景下,其稳定性和性能表现优于部分分布式数据库,如 CockroachDB 在高并发读写时,可能会出现一定的数据一致性问题,而 Cloudberry 数据库则能够很好地保证数据的完整性和一致性。
(二)功能方面
功能测试结果显示,Cloudberry 数据库在功能完整性和实用性方面表现良好。在兼容性测试中,对常见 SQL 语法的支持非常广泛和深入,无论是数据定义语言(DDL)还是数据操纵语言(DML),以及各种复杂的查询语句,都能准确解析和执行,与标准 SQL 语法规范高度一致。在与其他工具和平台的兼容性上,与 ETL 工具(如 Talend、Informatica)和 BI 工具(如 Tableau、PowerBI)都能实现良好的集成,在不同操作系统(Windows Server 2019、Ubuntu 20.04 和 macOS Monterey)上也能稳定运行,兼容性优势明显。与其他数据库相比,在 SQL 语法兼容性方面,Cloudberry 数据库与 MySQL、PostgreSQL 等主流数据库相当,在与工具和平台的兼容性上,甚至优于一些传统数据库,例如 Oracle 在与某些开源 ETL 工具集成时,可能会遇到一些兼容性问题,而 Cloudberry 数据库则能顺利集成。
在数据存储格式测试中,Heap 存储格式下,数据插入速度较快,但读取性能在大数据量全表扫描时较低,存储效率也相对较低。AO 行存储在数据插入和查询顺序扫描性能上表现较好,存储效率较高,相比 Heap 存储,插入速度提升一倍,存储空间减少了 60%。AOCS 列存储在聚合查询性能和数据压缩方面表现卓越,虽然写入性能相对较弱,但在数据分析场景中优势明显,例如在聚合查询计算平均薪资时,查询时间仅为 2 秒,存储空间相比 Heap 存储减少了 80%。这表明 Cloudberry 数据库提供的多种存储格式能够满足不同应用场景的需求,用户可以根据实际业务需求选择合适的存储格式。与其他数据库相比,一些数据库可能只提供单一或少数几种存储格式,而 Cloudberry 数据库丰富的存储格式选择使其在适应性上更具优势。例如,MySQL 主要以 InnoDB 存储引擎为主,存储格式相对单一,在面对复杂的数据分析场景时,灵活性不如 Cloudberry 数据库。
在安全功能测试中,数据加密方面,透明数据加密(TDE)功能有效保障了数据的安全性,对读写性能影响较小,在写入性能测试中,启用 TDE 功能后插入时间仅增加了 0.3 秒,读取性能测试中,查询时间增加了 0.1 秒。用户权限管理功能严格有效,不同权限的用户只能执行其被授权的操作,确保了数据访问的安全性。与其他数据库相比,在数据加密方面,Cloudberry 数据库的 TDE 功能与一些商业数据库如 SQL Server 的加密功能相当,在用户权限管理上,其功能的细致程度和有效性也不逊色于其他主流数据库,如 Oracle 的用户权限管理虽然功能强大,但配置相对复杂,而 Cloudberry 数据库在保证安全性的同时,配置更加简洁易用。
功能改进建议和方向:在兼容性方面,可以进一步加强与更多新兴工具和平台的兼容性,例如与一些新的大数据处理框架如 Flink、Spark Streaming 的集成,以满足不断变化的技术需求。在数据存储格式上,研究和开发更高效的存储格式或对现有存储格式进行进一步优化,例如探索行列混合存储的更优实现方式,以提高数据库在复杂 OLAP 应用中的性能。在安全功能方面,持续关注最新的安全技术和标准,及时更新和完善数据库的安全功能,如加强对数据脱敏技术的研究和应用,进一步保护用户数据的隐私安全。
七、结论与展望

通过本次对 Cloudberry 数据库全面而深入的测试,我们对其性能和功能有了清晰的认识。在性能测试中,Cloudberry 数据库在查询、数据加载和并发处理等方面都展现出了较强的能力。在单表查询和多表关联查询中,能够根据数据量和查询复杂度合理调整查询策略,利用先进的查询优化技术和索引机制,快速返回准确的结果。数据加载方面,无论是小数据量还是大数据量,都能保持较高的加载速度和稳定性。并发性能上,在高并发查询和读写场景下,能够有效地利用系统资源,保证系统的响应时间和吞吐量,同时确保数据的一致性和完整性。
在功能测试中,Cloudberry 数据库的兼容性表现出色,对常见 SQL 语法的支持广泛且深入,与多种 ETL 工具、BI 工具以及不同操作系统都能实现良好的集成,为用户在不同的技术环境中使用数据库提供了便利。丰富的数据存储格式,如 Heap 存储、AO 行存储和 AOCS 列存储,满足了不同应用场景对数据存储和处理的需求。强大的安全功能,包括数据加密和用户权限管理,有效地保障了数据的安全性和访问的可控性。
综合来看,Cloudberry 数据库在数据分析和 AI 场景中具有巨大的潜力和应用价值。它能够高效地处理大规模数据,为企业的数据分析和决策提供有力支持;同时,其对 AI/ML 工作负载的良好支持,也为人工智能应用的开发和部署提供了可靠的数据基础。
展望未来,随着数据量的持续增长和数据处理需求的不断变化,我们期待 Cloudberry 数据库能够不断优化和创新。在性能方面,进一步提升在超大规模数据和复杂查询场景下的处理能力,降低资源消耗;在功能方面,持续拓展兼容性,支持更多的新兴技术和工具,完善数据存储格式和安全功能;在社区建设方面,吸引更多的开发者和用户参与,丰富生态系统,推动 Cloudberry 数据库的持续发展和广泛应用。相信在未来的大数据和 AI 领域,Cloudberry 数据库将发挥越来越重要的作用,为企业和开发者带来更多的价值和机遇。
相关文章:
cloudberry测试
一、引言 在当今大数据和 AI 飞速发展的时代,数据如同企业的核心资产,其价值不言而喻。数据库作为数据存储、管理和处理的关键工具,更是成为了各个领域的技术基石。无论是金融行业的交易记录处理,还是医疗领域的患者信息管理&…...

RocketMQ、RabbitMQ、Kafka 的底层实现、功能异同、应用场景及技术选型分析
1️⃣ 引言 在现代分布式系统架构中,📩消息队列(MQ)是不可或缺的组件。它在系统🔗解耦、📉流量削峰、⏳异步处理等方面发挥着重要作用。目前,主流的消息队列系统包括 🚀RocketMQ、&…...

UWB功耗大数据插桩调研
一、摘要 UWB功耗点 插桩点 日志关键字 电流 蓝牙持锁 BatteryStats的锁统计 vendor_bluetooth_lock 30~40mA 测距 UwbSessionManager.startRanging UwbSessionManager.stoptRanging 或接入fadiKey Uwb状态广播 "com.fadiui.dkservice.action.uwb.state.change&q…...

郭羽冲IOI2024参赛总结
非常荣幸能代表中国参加第 36 36 36 届国际信息学奥林匹克竞赛( I O I 2024 IOI2024 IOI2024)。感谢 C C F CCF CCF 为我们提供竞赛的平台,感谢随行的老师们一路上为我们提供的帮助与支持。 在每场比赛的前一个晚上,领队、副领…...

03:Spring之Web
一:Spring整合web环境 1:web的三大组件 Servlet:核心组件,负责处理请求和生成响应。 Filter:用于请求和响应的预处理和后处理,增强功能。 Listener:用于监听 Web 应用中的事件,实…...
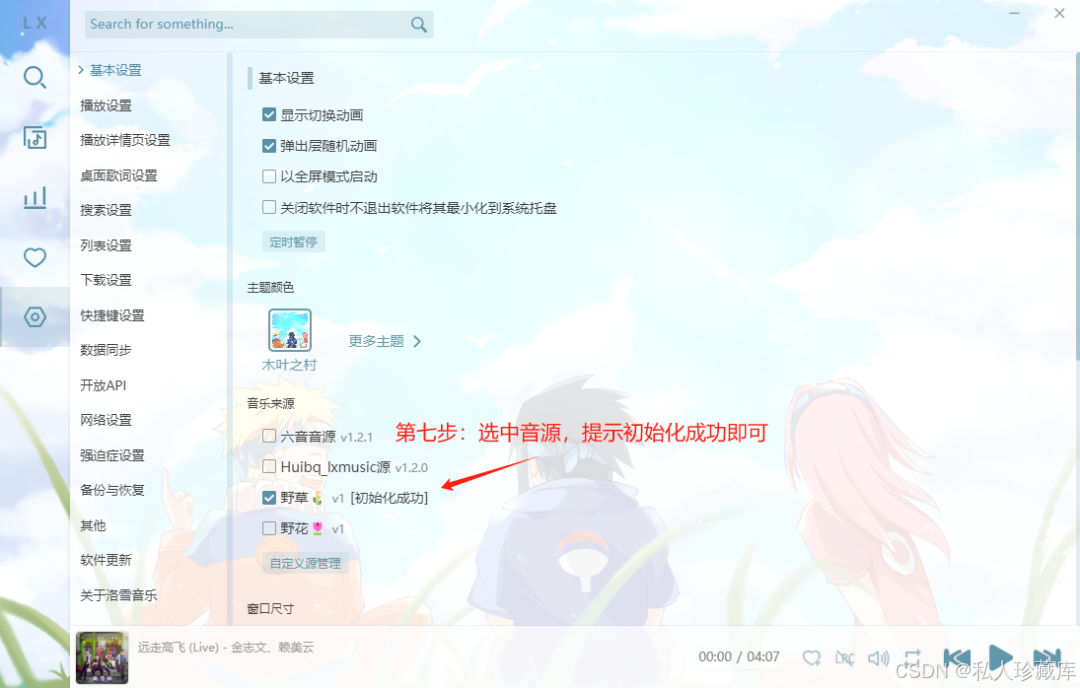
lx-music落雪音乐-开源免费听歌软件[提供最新音源使用, 支持全网平台, 支持无损音乐下载]
lx-music_落雪音乐 链接:https://pan.xunlei.com/s/VOIpEt1xqf0un-vEQilidhjIA1?pwdgcux#...

129,【2】buuctf [BJDCTF2020]EzPHP
进入靶场 查看源代码 看到红框就知道对了 她下面那句话是编码后的,解码 1nD3x.php <?php // 高亮显示当前 PHP 文件的源代码,通常用于调试和展示代码结构 highlight_file(__FILE__); // 设置错误报告级别为 0,即不显示任何 PHP 错误信息…...

Python 面向对象(类,对象,方法,属性,魔术方法)
前言:在讲面向对象之前,我们先将面向过程和面向对象进行一个简单的分析比较,这样我们可以更好的理解与区分,然后我们在详细的讲解面向对象的优势。 面向过程(Procedure-Oriented Programming,POP࿰…...

C语言之扫雷
C语言之扫雷 game.hgame.ctest.c 参考 https://blog.csdn.net/m0_62391199/article/details/124694375 game.h #pragma once #include <stdio.h> #include <time.h> #include <stdlib.h>#define ROW 9 #define COL 9#define ROWS ROW2 #define COLS COL2#de…...

半导体制造工艺讲解
目录 一、半导体制造工艺的概述 二、单晶硅片的制造 1.单晶硅的制造 2.晶棒的切割、研磨 3.晶棒的切片、倒角和打磨 4.晶圆的检测和清洗 三、晶圆制造 1.氧化与涂胶 2.光刻与显影 3.刻蚀与脱胶 4.掺杂与退火 5.薄膜沉积、金属化和晶圆减薄 6.MOSFET在晶圆表面的形…...
Ollama+DeepSeek R1+AnythingLLM训练自己的AI智能助手
1.下载Ollama安装 1.1.安装Ollama Ollama官网:Ollama 下载Ollama,点击“Download”按钮。 根据电脑操作系统,下载合适的版本即可。 下载完成后点击安装,完成后安装窗口会自动关闭,你的系统托盘图标会出现一个Ollama图标。 1.2.…...

基于java手机销售网站设计和实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

5-R循环
R 循环 有的时候,我们可能需要多次执行同一块代码。一般情况下,语句是按顺序执行的:函数中的第一个语句先执行,接着是第二个语句,依此类推。 编程语言提供了更为复杂执行路径的多种控制结构。 循环语句允许我们多…...

Qlabel 每五个一换行 并、号分割
学习点 Qlabel 每五个一换行 并、号分割 QString MainWindow::formatHobbies(const std::set<QString>& hobbies) {QString formattedHobbies;int count 0;for (const QString& hobby : hobbies) {if (count > 0 && count % 5 0)formattedHobbies…...

加速PyTorch模型训练:自动混合精度(AMP)
在深度学习领域,模型训练的速度和效率尤为重要。为了提升训练速度并减少显存占用(较复杂的模型中),PyTorch自1.6版本起引入了自动混合精度(Automatic Mixed Precision, AMP)功能。 AMP简单介绍 是一种训练…...

【py】python安装教程(Windows系统,python3.13.2版本为例)
1.下载地址 官网:https://www.python.org/ 官网下载地址:https://www.python.org/downloads/ 2.64版本或者32位选择 【Stable Releases】:稳定发布版本,指的是已经测试过的版本,相对稳定。 【Pre-releases】&#…...

Django REST Framework:如何获取序列化后的ID
Django REST Framework:如何获取序列化后的ID 😄 嗨,小伙伴们!今天我们来聊一聊Django REST Framework(简称DRF)中一个非常常见的操作:如何获取序列化后的ID。对于那些刚入门的朋友们ÿ…...

QT修仙笔记 事件大圆满 闹钟大成
学习笔记 牛客刷题 闹钟 时钟显示 通过 QTimer 每秒更新一次 QLCDNumber 显示的当前时间,格式为 hh:mm:ss,实现实时时钟显示。 闹钟设置 使用 QDateTimeEdit 让用户设置闹钟时间,可通过日历选择日期,设置范围为当前时间到未来 …...

Leetcode - 149双周赛
目录 一、3438. 找到字符串中合法的相邻数字二、3439. 重新安排会议得到最多空余时间 I三、3440. 重新安排会议得到最多空余时间 II四、3441. 变成好标题的最少代价 一、3438. 找到字符串中合法的相邻数字 题目链接 本题有两个条件: 相邻数字互不相同两个数字的的…...

解决 ComfyUI-Impact-Pack 中缺少 UltralyticsDetectorProvider 节点的问题
解决 ComfyUI-Impact-Pack 中缺少 UltralyticsDetectorProvider 节点的问题 1. 安装ComfyUI-Impact-Pack 首先确保ComfyUI-Impact-Pack 已经下载 地址: https://github.com/ltdrdata/ComfyUI-Impact-Pack 2. 安装ComfyUI-Impact-Subpack 由于新版本的Impact Pack 不再提供这…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...
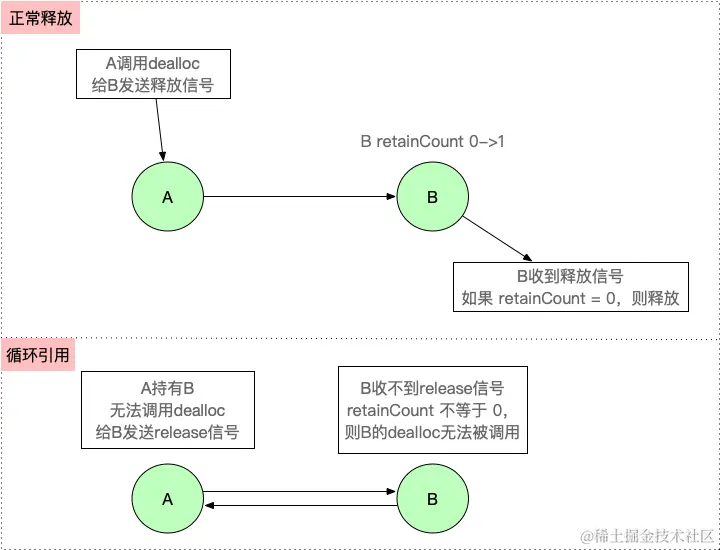
【iOS】 Block再学习
iOS Block再学习 文章目录 iOS Block再学习前言Block的三种类型__ NSGlobalBlock____ NSMallocBlock____ NSStackBlock__小结 Block底层分析Block的结构捕获自由变量捕获全局(静态)变量捕获静态变量__block修饰符forwarding指针 Block的copy时机block作为函数返回值将block赋给…...