python卷积神经网络人脸识别示例实现详解
目录
一、准备
1)使用pytorch
2)安装pytorch
3)准备训练和测试资源
二、卷积神经网络的基本结构
三、代码实现
1)导入库
2)数据预处理
3)加载数据
4)构建一个卷积神经网络
5)模型训练
6)模型测试
四、测试结果
五、模型导出
1)保存模型的状态参数
2)保存完整模型
六、总结
一、准备
1)使用pytorch
为什么建议使用pytorch来构建卷积神经网络呢?因为pytorch是基于python开发的一个神经网络工具包,它已经实现了激活函数定义、权重矩阵定义、卷积计算、正向传播、反向传播、权重矩阵更新等神经网络的基本操作,而不需要我们再去编写代码实现这些功能,只需调用相应的函数就可以搭建好我们所需的网络结构。pytorch极大方便了我们构建神经网络,加快了神经网络开发速度,我们只需要关注网络的结构层次,而不用关心所建立的网络具体训练和预测过程。
2)安装pytorch
pytorch有CPU版和GPU版,GPU版需要使用到英伟达的显卡来加快网络速度,安装过程也稍显复杂。本文重点是对python卷积神经网络示例解析,因此安装CPU版。在pycharm开发工具的终端中直接执行命令:pip install torch torchvision torchaudio,即可完成pytorch的CPU版本安装。
3)准备训练和测试资源
因为使用pytorch开发卷积神经网络实现人脸识别,pytorch对数据存放有一定要求,因此需要将相关资源放在特定的目录结构下。训练目录和测试目录结构如下图所示,在文件夹中放入相应的图片资源即可。文件路径可以自行定义,但是同一个人的照片必须放在同一个文件夹下,pytorch根据该文件夹的名称自动将相应的图片资源归于一类。


二、卷积神经网络的基本结构
一个简单的卷积神经网络包括输入层、卷积层、池化层、扁平化层和全连接层。网络的复杂度体现在卷积、池化层的大小和数量上。卷积神经网络主要用于处理有大量数据输入的情景,如图像识别是最好的例子,可以极大减少运算量。下面以一个人脸识别的实际例子,详细讲解卷积神经网络的搭建流程。

三、代码实现
1)导入库
使用PyCharm工具新建一个.py文件,在文件中导入下面需要使用到的相关库。在导入下面的库前,需要确保已经安装好了pytorch相关依赖包。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader2)数据预处理
以下定义了一组针对图片进行预处理的方法,包括3个。第一个是将图像调整为100*100像素大小,这样我们就可以输入任何大小图片,并能保证数据输入到网络中的大小是一致的。第二个是将图像数据转换为张量格式,这时pytorch自定义的一种数据格式,可以简单理解为类似于多维向量。第三个是对图像进行归一化处理,其目的是使数据的均值为 0,标准差为 1。这样做可以加速模型的训练过程,提高模型的稳定性和收敛速度。函数参数如下:
-
mean:一个长度为 3 的列表,分别代表图像三个通道(RGB)的均值。这里[0.485, 0.456, 0.406]是在 ImageNet 数据集上统计得到的三个通道的均值。 -
std:一个长度为 3 的列表,分别代表图像三个通道(RGB)的标准差。[0.229, 0.224, 0.225]是在 ImageNet 数据集上统计得到的三个通道的标准差。
参数的取值可以直接使用上面提供的经验值。对于输入图像的每个像素RGB值 ,归一化后的像素RGB值 按照以下公式计算:

其中,mean 和 std 分别是对应通道的均值和标准差。
transform = transforms.Compose([transforms.Resize((100, 100)), # 调整图像大小transforms.ToTensor(), # 将图像转换为张量transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])3)加载数据
使用dataset.ImageFolder()加载需要的训练图像和测试凸显数据。这里的数据路径需要注意,并没有到具体的文件名。比如在D:/zhaopian/train目录下,程序会自动读取该目录下的子文件夹,并将子文件夹中的图像数据归集到以该子文件夹命名的类别中。参数transform=transform就是调用上述第二步定义的数据预处理方法集,在读取每一张图像数据时将自动依次执行上述3个方法。并将最终转换好的数据返回。
创建数据加载器是为了便于网络训练时分批次加载数据,避免一次加载所有图像数据导致内存不足。
-
batch_size=32:指定每个批次中包含的数据样本数量。这里设置为 32,表示每次从train_dataset中取出 32 个样本组成一个批次进行训练。batch_size的选择会影响模型的训练速度和性能,较大的batch_size可以加快训练速度,但可能会导致内存不足;较小的batch_size可以增加模型的泛化能力,但训练速度会变慢。 -
shuffle=True:一个布尔值,用于指定是否在每个训练周期(epoch)开始时打乱数据集的顺序。设置为True可以增加数据的随机性,避免模型学习到数据的特定顺序,有助于提高模型的泛化能力。
train_dataset = datasets.ImageFolder(root='D:/zhaopian/train', transform=transform)
test_dataset = datasets.ImageFolder(root='D:/zhaopian/test', transform=transform)
all_samples = test_dataset.samples
print("数据集中的类别:", train_dataset.classes)# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)4)构建一个卷积神经网络
自定义一个卷积神经网络类FaceCNN,继承自nn.Module。该网络包含两个卷积层,两个池化层,两个全连接层。在卷积层和全连接层之间均使用了相同的激活函数ReLU:

函数 nn.Conv2d(3, 16, kernel_size=3, padding=1) 的作用是定义一个二维卷积层,参数3表示输入的数据是3个通道,这里对应的是彩色图像的RGB三组数据,即每张图会有3个100*100的矩阵输入到该卷积层中。参数16表示该卷积层有16个卷积核,每个核的大小均是3*3(参数kernel_size=3确定的)的矩阵,这16个3*3的卷积核初始值是随机的,它的值是通过模型训练最终确定的,也就是神经网络中的权重矩阵。定义16个卷积核意味着什么呢?当一幅彩色图像输入该卷积层时,该图像有3组矩阵,每组矩阵与一个卷积核进行卷积,得到3个卷积后的矩阵,然后在将这3个卷积后的矩阵对应位置取平均值,得到一个最终的卷积均值矩阵。16个卷积核依次执行上述操作,则经过该卷积层后,会得到16个卷积均值矩阵。参数padding=1表示对输入数据进行扩充,1表示在数据四周加一行,填充的目的通常是为了保持输入和输出特征图的尺寸一致。那么,经过该卷积层后,最终会得到16个100*100的卷积均值矩阵。
函数nn.MaxPool2d(2)的作用是定义一个2*2的二维池化层,该池化层输出池中的最大值。在最大池化操作中,池化窗口会在输入特征图上滑动,对每个窗口内的元素进行操作。这里设置为 2,表示使用一个 2x2 的池化窗口。当池化窗口在特征图上滑动时,会选取每个 2x2 区域内的最大值作为该区域的输出值。此处需要注意的是,经过2*2的二维池化层后,输出的矩阵变为了50*50,因为池化层的步幅等于它的大小,这与卷积不同,卷积默认步幅为1。
函数nn.Conv2d(16, 32, kernel_size=3, padding=1) 用于定义第二个二维卷积层。在该卷积层中,前面两个参数分别是16和32,16对应的是前面的16个卷积核,因为一幅图像经过第一层卷积后会输出16组数据,所以此处第二层卷积时,输入的数据就是16组。32表示第二层卷积后输出32组50*50的矩阵。
函数nn.Linear(32 * 25 * 25, 128)的作用是定义一个全连接层,全连接层的每个神经元都与前一层的所有神经元相连接,通过对输入进行线性变换(加权求和)并加上偏置,实现从输入特征到输出特征的映射。第一个参数32 * 25 * 25=20000,表示输入数据的数量,128表示输出数据的数量。全连接层线性变换公式为:
![]()
其中, x是输入向量,W 是权重矩阵,b 是偏置向量, y是输出向量。权重矩阵W的形状为 (20000, 128), b的形状为 (128,1)。W和b都是在模型训练中需要更新的矩阵。
在建立的神经网络中还定义了前向传播函数forward(),它由开发者自行设计数据在网络中传播的方向。图像数据首先经过第一个卷积层,然后通过激活函数,再进入第一个池化层,随后依次进入第二个卷积层,第二个激活函数,第二个池化层。x = x.view(-1, 32 * 25 * 25)的作用是将得到的数据展平为一维数据。从前面的输出可知,x是一组由32个25*25矩阵组成的数据集,x.view会将该数据集整合为一个一维数组,数组的元素总量保持不变。
数据在经过展平后,进入了第一全连接层,由网络结构可知,第一个全连接层输出的是一个128个元素的数组,数据量被极大压缩了。然后再次经过激活函数,随后进入第二个全连接层,第二个全连接层输出的数组由n个元素组成,n=len(train_dataset.classes),就是我们训练模型时提供的n个人数。但需要注意的是,此处输出的结果与人脸识别并无直接关系,我们需要对该结果进行进一步处理,让它与人脸对应起来。
class FaceCNN(nn.Module):def __init__(self):super(FaceCNN, self).__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1) # 定义第一个二维卷积层self.relu1 = nn.ReLU() # 定义第一个激活函数self.pool1 = nn.MaxPool2d(2) # 定义第一个二维池化层self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1) # 定义第二个二维卷积层self.relu2 = nn.ReLU() # 定义第二个激活函数self.pool2 = nn.MaxPool2d(2) # 定义第二个二维池化层self.fc1 = nn.Linear(32 * 25 * 25, 128) # 定义第一个全连接层,展平后输出128个特征量self.relu3 = nn.ReLU() # 定义第三个激活函数self.fc2 = nn.Linear(128, len(train_dataset.classes)) # 定义第二个全连接层,展平后输出n个特征量,n为人数def forward(self, x):x = self.pool1(self.relu1(self.conv1(x)))x = self.pool2(self.relu2(self.conv2(x)))x = x.view(-1, 32 * 25 * 25)x = self.relu3(self.fc1(x))x = self.fc2(x)return x5)模型训练
首先用自己定义卷积神经网络类实例化一个对象。然后定义一个损失函数,这里直接使用了pytorch库中提供的交叉熵损失函数对象,交叉熵损失函数(Cross-Entropy Loss)是分类问题中常用的一种损失函数,尤其适用于多分类任务。它能够有效衡量模型预测的概率分布与真实标签的概率分布之间的差异。该函数的具体实现比较复杂,如果不做算法研究,可以暂时不用管其具体实现,只需要知道在分类问题中适用该函数。
optimizer = optim.Adam(model.parameters(), lr=0.001) 这行代码在 PyTorch 中用于创建一个 Adam 优化器对象 optimizer,该优化器将用于更新模型 model 的参数。Adam(Adaptive Moment Estimation)是一种常用的优化算法,它结合了 AdaGrad 和 RMSProp 两种算法的优点。Adam 算法能够自适应地调整每个参数的学习率,同时利用梯度的一阶矩估计(均值)和二阶矩估计(方差)来更新参数。它具有收敛速度快、对不同类型的数据集和模型都有较好表现等优点,因此在深度学习中得到了广泛应用。我们同样也不需要去关心它的具体实现,PyTorch已经帮我们完成了相应的操作。其中的参数定义如下:
-
model.parameters():这是optim.Adam的第一个参数,它是一个生成器,用于返回模型model中所有需要更新的参数。在 PyTorch 中,模型的参数通常是可学习的张量,通过调用model.parameters()可以获取这些参数,优化器将根据这些参数的梯度信息来更新它们。 -
lr=0.001:lr是学习率(learning rate)的缩写,它是optim.Adam的一个重要超参数,用于控制每次参数更新的步长。学习率决定了模型在训练过程中朝着损失函数最小值前进的速度。这里将学习率设置为 0.001,表示每次更新参数时,参数的变化量是梯度乘以 0.001。如果学习率设置得过大,模型可能会跳过损失函数的最小值,导致无法收敛;如果学习率设置得过小,模型的训练速度会变得很慢。
# 初始化模型
model = FaceCNN()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20 # 训练10次
for epoch in range(num_epochs):model.train() # 将模型设置为训练模式。running_loss = 0.0for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad() # 每次反向传播之前,将优化器中所有参数的梯度清零outputs = model(images) # 自动调用模型的 forward 方法loss = criterion(outputs, labels) # 计算损失值loss.backward() # 调用 loss.backward() 开始反向传播过程,计算每个可训练参数的梯度,并将这些梯度存储在参数的 .grad 属性中。optimizer.step() # 优化器会根据存储在参数 .grad 属性中的梯度,按照指定的优化算法更新模型的参数。running_loss += loss.item()6)模型测试
模型测试的代码实现如下。测试时首先将模型设置为评估模式,在这里同样使用批量传入测试图像数据的方式。
_, predicted = torch.max(outputs.data, 1)用于找出在模型输出的结果outputs.data中,每一行数据的最大值在该行中的索引位置,torch.max 函数的第二个参数,指定了在哪个维度上进行最大值查找。这里设置为 1,表示在每一行(即每个样本)上查找最大值。需要进一步说明的是,由于我们采用批量处理的方式,outputs.data应是一个二维数组,每一行表示模型对一张图的处理结果。根据前面网络结构定义可知,若是输入3个人的人脸照片,则每一行应该有3个元素。这里取最大值,是因为模型输出的结果表征的是模型预测的概率,概率越大说明输入图像是对应人脸的概率越大。而对应的人脸在labels中表征,在本例中输入3个人的照片,则它是一个包含3个元素[0,1,2]的数组,每个值对应一个人。因此, torch.max找到最大值在每一行中的索引位置后,该位置也就表征了对应的人。
# 测试模型
model.eval() # 将模型切换到评估模式。
correct = 0
total = 0
with torch.no_grad(): # 不计算导数for index, (images, labels) in enumerate(test_loader):outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()labels_array = labels.numpy()predicted_array = predicted.numpy()# 计算当前批次的起始索引start_idx = index * test_loader.batch_size# 计算当前批次的结束索引end_idx = start_idx + images.size(0)# 获取当前批次的图像文件路径batch_samples = all_samples[start_idx:end_idx]# 提取图像文件名称batch_image_names = [sample[0].split('\\')[2] for sample in batch_samples]for i in range(len(predicted_array)):print(f'图名: {batch_image_names[i]}', f'实际名字: {train_dataset.classes[labels_array[i]]}',f'预测名字: {train_dataset.classes[predicted_array[i]]}')
print(f'总测试数量: {total}', f'正确识别数量: {correct}')
print(f'Test Accuracy: {100 * correct / total}%')四、测试结果
从网络上随机下载了一些公开图片,对网路进行了训练和测试,得到结果如下。实际看神经网络的识别准确率还是比较高的。模型的完整代码和使用的资源可在这里下载。


五、模型导出
在完成神经网络模型训练后,需要将训练好的模型导出,以供后续使用,具体方法有两种。
1)保存模型的状态参数
在训练后的模型下加入下列代码,则模型中的所有参数均会保存到对应的.pth文件中。
torch.save(model.state_dict(), 'model_state_dict.pth')在重新使用模型时,需要再次实例化模型对象,然后加载保存的模型参数。因此,重新使用时我们需要知道模型的结构定义,即重写FaceCNN类。
# 加载模型的状态字典
loaded_model = FaceCNN()
loaded_model.load_state_dict(torch.load('model_state_dict.pth'))
loaded_model.eval() # 设置为评估模式2)保存完整模型
我们也可以直接保存完整的模型文件,在重新使用时直接加载该模型即可。这种方式简单,但缺少灵活性。
# 保存整个模型
torch.save(model, 'whole_model.pth')# 加载整个模型
loaded_model = torch.load('whole_model.pth')
loaded_model.eval() # 设置为评估模式六、总结
通过一个人脸识别示例,详细说明了利用pytorch模块搭建卷积神经网络的实现流程,并对代码进行了逐行解释。pytorch极大方便了神经网络开发,让开发人员可以不用关注网络中具体的算法实现,而更加侧重在网络模型搭建上。在本例试验测试中,模型的训练次数和网络结构参数的调整均会对图像识别的准确造成大幅度影响,仍需要通过大量测试优化网络结构参数。
相关文章:
python卷积神经网络人脸识别示例实现详解
目录 一、准备 1)使用pytorch 2)安装pytorch 3)准备训练和测试资源 二、卷积神经网络的基本结构 三、代码实现 1)导入库 2)数据预处理 3)加载数据 4)构建一个卷积神经网络 5࿰…...

EX_25/2/11
将 epoll 服务器 客户端拿来用 客户端: 写一个界面,里面有注册登录 服务器:处理注册和登录逻辑,注册的话将注册的账号密码写入数据库,登录的话查询数据库中是否存在账号,并验证密码是否正确 额外功能&a…...
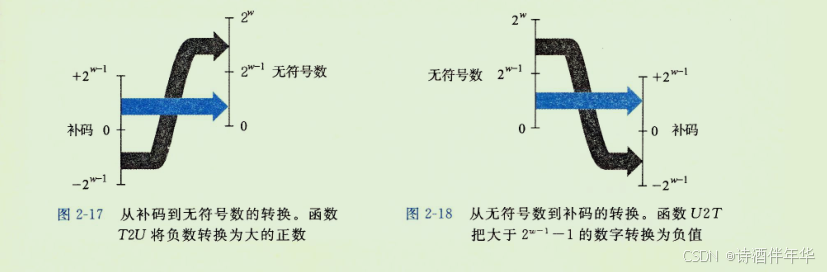
二.2 整数表示(2.1-2.4)
在本节中,我们描述用位来编码整数的两种不同的方式:一种只能表示非负数,而另一种能够表示负数、零和正数。后面我们将会看到它们在数学属性和机器级实现方面密切相关。我们还会研究扩展或者收缩一个已编码整数以适应不同长度表示的效果。 图2…...

中间件-安装Minio-集成使用(ubantu-docker)
目录 1、安装docer 2、运行以下命令拉取MinIO的Docker镜像 3、检查当前所有Docker下载的镜像 4、创建目录 5、创建Minio容器并运行 6、SDK操作 FileUploader.java 1、安装docer 参考这篇:Linux安装Docker 2、运行以下命令拉取MinIO的Docker镜像 docker pull…...

夸克网盘多链接批量保存,自动同步更新,批量分享
最近夸克网盘有点火,好多资源都上夸克网盘了,做了一个夸克网盘的批量化程序,已经打包好了,不用配置代码环境就能用 夸克网盘工具:https://pan.quark.cn/s/c22f3451a6ab 百度网盘工具:https://pan.quark.cn…...
)
2025清华:DeepSeek从入门到精通.pdf(附下载)
本文是一份关于如何深入理解和使用DeepSeek技术的全面指南,由清华大学新闻与传播学院新媒体研究中心元宇宙文化实验室的余梦珑博士后及其团队编撰。DeepSeek是一家中国科技公司,专注于通用人工智能(AGI)的研发,其开源推…...

【AIGC】在VSCode中集成 DeepSeek(OPEN AI同理)
在 Visual Studio Code (VSCode) 中集成 AI 编程能力,可以通过安装和配置特定插件来实现。以下是如何通过 Continue 和 Cline 插件集成 DeepSeek: 一、集成 DeepSeek 获取 DeepSeek API 密钥:访问 DeepSeek 官方网站,注册并获取 …...

android动态设置是否允许应用卸载
摘要:通过广播设置全局参数控制应用是否允许卸载,全局参数在Launcher和PackageInstaller两个模块中使用到。此功能可用于MDM后台控制是否允许设备卸载应用。 1. 静态注册广播 由于系统安装和卸载的功能集中在PackageInstaller模块中,为了更…...

基于微信小程序的博物馆预约系统的设计与实现
hello hello~ ,这里是 code袁~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 🦁作者简介:一名喜欢分享和记录学习的在校大学生…...
使用NPOI自定义导出excel文件
说明 1、自定义列名,将从数据库查询到的数据赋值到对应的单元格上。 2、excel文件默认导出到桌面。 3、支持进度条显示。 界面 功能实现 public void TaskTest(){Task task new Task(ExportExcel);task.Start(); }/// <summary>/// 查询数据/// </summa…...

基于vue2 的 vueDraggable 示例,包括组件区、组件放置区、组件参数设置区 在同一个文件中实现
为了在Vue 2中实现一个包含组件区、组件放置区以及组件参数设置区的界面,我们可以使用vue-draggable库来处理拖拽功能,并结合其他UI组件库如Element UI来构建界面。下面是一个基本的示例,展示如何实现这样的布局。 第一步:安装必…...

使用rknn进行facenet部署
文章目录 开源仓库pth转onnxnetron可视化onnx转rknnC++实现开源仓库 https://github.com/bubbliiiing/facenet-pytorch pth转onnx 修改facenet网络的forward函数代码 修改前 def forward(self, x, mode = "predict"):if mode ==...

#渗透测试#批量漏洞挖掘#29网课交单平台 SQL注入
免责声明 本教程仅为合法的教学目的而准备,严禁用于任何形式的违法犯罪活动及其他商业行为,在使用本教程前,您应确保该行为符合当地的法律法规,继续阅读即表示您需自行承担所有操作的后果,如有异议,请立即停止本文章读。 目录 1. 漏洞原理 2. 漏洞定位 3. 攻击验证示…...

百问网imx6ullpro调试记录(linux+qt)
调试记录 文章目录 调试记录进展1.开发板相关1.1百问网乌班图密码 1.2 换设备开发环境搭建串口调试网络互通nfs文件系统挂载 1.3网络问题1.4系统启动1.5进程操作 2.QT2.1tslib1.获取源码2.安装依赖文件3.编译 2.2qt移植1.获取qt源码2.配置编译器3.编译 2.3拷贝到开发板1.拷贝2.…...

【python】3_容器
目录 一、列表 list 1.1基本语法 1.2 常用操作方法 1.3 列表的遍历 二、元组 tuple 特点: 三、字符串 常用操作方法: 四、序列 操作方法:切片 五、元素 特点: 基本语法: 集合常用功能: 六、字…...
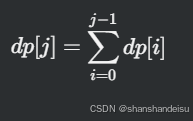
数据结构与算法:动态规划dp:背包问题:理论基础(状态压缩/滚动数组)和相关力扣题(416. 分割等和子集、1049.最后一块石头的重量Ⅱ、494.目标和)
背包问题 01背包理论基础 对于01背包问题,物品下标为0到i,对应的重量为weight[0]到weight[i],价值为value[0]到value[i],每个物品只可以取或不取,背包最大容量为j的场景。 常见的状态转移方程如下: dp[i…...

数字游牧时代:IT人力外包的范式革命与文明重构
当英国工业革命时期的企业主们将生产环节外包给家庭作坊时,他们不会想到这种生产组织方式会演变为21世纪最复杂的商业形态。IT人力外包行业在经历三十年爆炸式增长后,正在经历一场静默的范式革命。这场革命不仅重构着全球IT产业链的拓扑结构,…...

Qt - 地图相关 —— 3、Qt调用高德在线地图功能示例(附源码)
效果 作者其他相关文章链接: Qt - 地图相关 —— 1、加载百度在线地图(附源码) Qt - 地图相关 —— 2、Qt调用百度在线地图功能示例全集,包含线路规划、地铁线路查询等(附源码) Qt - 地图相关 —— 3、Qt调用…...

cloudberry测试
一、引言 在当今大数据和 AI 飞速发展的时代,数据如同企业的核心资产,其价值不言而喻。数据库作为数据存储、管理和处理的关键工具,更是成为了各个领域的技术基石。无论是金融行业的交易记录处理,还是医疗领域的患者信息管理&…...

RocketMQ、RabbitMQ、Kafka 的底层实现、功能异同、应用场景及技术选型分析
1️⃣ 引言 在现代分布式系统架构中,📩消息队列(MQ)是不可或缺的组件。它在系统🔗解耦、📉流量削峰、⏳异步处理等方面发挥着重要作用。目前,主流的消息队列系统包括 🚀RocketMQ、&…...

如何让电子书阅读效率提升200%?这款开源神器彻底解决格式兼容与跨设备难题
如何让电子书阅读效率提升200%?这款开源神器彻底解决格式兼容与跨设备难题 【免费下载链接】koreader An ebook reader application supporting PDF, DjVu, EPUB, FB2 and many more formats, running on Cervantes, Kindle, Kobo, PocketBook and Android devices …...

全网最全JAVA面试八股文,终于整理完了
前言 今天为大家整理了目前互联网出现率最高的大厂面试题,所谓八股文也就是指文章的八个部分,文体有固定格式:由破题、承题、起讲、入题、起股、中股、后股、束股八部分组成,题目一律出自四书五经中的原文。 而JAVA面试八股文也就是为了考验…...
)
UI自动化测试--02(Xpath与CSS定位全攻略)
1.Xpath定位xpath和css定位可以利用以下元素的信息来完成定位: 层级结构 元素自身的所有信息 什么是Xpath: 是一种专门在xml文档中找元素的公式(表达式),而HTML刚好和XML结构很类似,所以XPATH的表达 式也可…...

论文AI率从80%降到10%以下的完整攻略:实测3款降AI率工具真实效果
论文AI率从80%降到10%以下的完整攻略:实测3款降AI率工具真实效果 上个月我同学发来一张知网检测报告,AI率87%,整个人都懵了。她用DeepSeek写了大部分初稿,没想到检测会这么高。当时距离论文提交截止不到两周,她问我有没…...

YOLO X Layout与Python结合实战:自动化文档结构解析应用
YOLO X Layout与Python结合实战:自动化文档结构解析应用 1. 项目背景与价值 在日常工作中,我们经常会遇到大量需要处理的文档——扫描的合同、电子发票、研究报告、技术文档等等。传统的人工处理方式不仅效率低下,还容易出错。想象一下&…...

Qwen-Image-2512-SDNQ使用心得:如何写出更有效的中文Prompt获得理想图片
Qwen-Image-2512-SDNQ使用心得:如何写出更有效的中文Prompt获得理想图片 1. 为什么中文Prompt需要特别优化? 在AI绘画领域,Prompt(提示词)的质量直接影响生成结果。对于中文用户而言,使用母语描述想象中的…...

C++多线程编程:为什么compare_exchange_weak比strong更适合循环场景?
C多线程编程:为什么compare_exchange_weak比strong更适合循环场景? 在构建高性能并发系统时,C开发者常常需要在原子操作的精确性和执行效率之间寻找平衡点。compare_exchange系列函数作为无锁编程的核心工具,其强弱两种变体的选择…...
:PEI体系关键参数进阶优化指南【曼博生物】)
细胞转染优化方向(二):PEI体系关键参数进阶优化指南【曼博生物】
摘要:在PEI转染体系中,除基础培养条件外,质粒比例、DNA与PEI比率、孵育条件及病毒收获时间等参数同样显著影响转染效率与病毒产量。本文结合实验数据,对关键参数进行系统分析,为AAV及慢病毒生产提供优化思路。 关键词…...

ESP32S3端口死活不识别?别急着换线,先试试这个USB驱动修复大法
ESP32S3端口识别难题:从底层原理到实战修复的全方位指南 当你满怀期待地将ESP32S3开发板连接到电脑,准备开始物联网项目的开发时,却发现设备管理器里怎么也找不到对应的COM端口——这种挫败感我深有体会。作为一款功能强大的Wi-Fi/蓝牙双模芯…...

贝叶斯分位数回归实战指南:从理论到业务落地
贝叶斯分位数回归实战指南:从理论到业务落地 【免费下载链接】pymc Python 中的贝叶斯建模和概率编程。 项目地址: https://gitcode.com/GitHub_Trending/py/pymc 在数据科学实践中,我们常面临这样的困境:当预测用户行为、设备故障时间…...