YOLOv11-ultralytics-8.3.67部分代码阅读笔记-patches.py
patches.py
ultralytics\utils\patches.py
目录
patches.py
1.所需的库和模块
2.def imread(filename: str, flags: int = cv2.IMREAD_COLOR):
3.def imwrite(filename: str, img: np.ndarray, params=None):
4.def imshow(winname: str, mat: np.ndarray):
5.PyTorch functions
6.def torch_load(*args, **kwargs):
7.def torch_save(*args, **kwargs):
1.所需的库和模块
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# 使用 Monkey 补丁来更新/扩展现有功能。
"""Monkey patches to update/extend functionality of existing functions."""import time
from pathlib import Pathimport cv2
import numpy as np
import torch# OpenCV Multilanguage-friendly functions OpenCV 多语言友好功能------------------------------------------------------------------------------
# 这段代码定义了一个别名 _imshow ,用于 OpenCV 的 cv2.imshow 函数。这种做法通常是为了避免在后续代码中直接调用原函数时可能出现的递归错误。
# 定义了一个别名 _imshow ,它指向 OpenCV 的 cv2.imshow 函数。
# 目的 :通过这种方式,可以避免在后续代码中直接调用 cv2.imshow ,从而防止可能出现的递归错误。
# 递归错误 :递归错误通常发生在函数调用自身时,如果没有正确的退出条件,会导致无限递归,最终导致栈溢出错误。在某些情况下,如果开发者需要对 cv2.imshow 函数进行包装或修改其行为,直接调用原函数可能会导致递归调用问题。
# 应用场景 :在对 cv2.imshow 函数进行扩展或修改时,使用别名可以安全地调用原函数,确保代码的逻辑清晰且不会出现递归问题。
_imshow = cv2.imshow # copy to avoid recursion errors 复制以避免递归错误。
# 这段代码通过定义 _imshow 别名,为 OpenCV 的 cv2.imshow 函数创建了一个安全的代理。这种做法的主要目的是避免在后续代码中直接调用原函数时可能出现的递归错误。通过使用别名,开发者可以在不影响原函数功能的前提下,对这些函数进行扩展或修改,从而实现更灵活的功能。2.def imread(filename: str, flags: int = cv2.IMREAD_COLOR):
# 这段代码定义了一个自定义的 imread 函数,用于从文件中读取图像。
# 定义了一个函数 imread ,它接受两个参数。
# 1.filename :一个字符串,表示图像文件的路径。
# 2.flags :一个整数,表示读取图像的模式,默认值为 cv2.IMREAD_COLOR ,表示以彩色模式读取图像。
def imread(filename: str, flags: int = cv2.IMREAD_COLOR):# 从文件中读取图像。"""Read an image from a file.Args:filename (str): Path to the file to read.flags (int, optional): Flag that can take values of cv2.IMREAD_*. Defaults to cv2.IMREAD_COLOR.Returns:(np.ndarray): The read image."""# 这是函数的核心部分,使用了 OpenCV 的 cv2.imdecode 函数来读取图像。# np.fromfile(filename, np.uint8) :从文件中读取二进制数据,并将其转换为 NumPy 数组。 np.uint8 表示数据类型为无符号8位整数。# cv2.imdecode :将从文件中读取的二进制数据解码为图像。 flags 参数决定了图像的读取模式(例如彩色、灰度等)。return cv2.imdecode(np.fromfile(filename, np.uint8), flags)
# 这段代码实现了一个自定义的 imread 函数,用于从文件中读取图像。它通过 np.fromfile 读取文件的二进制数据,并将其转换为 NumPy 数组,然后使用 cv2.imdecode 将其解码为图像。这种方法特别适用于处理非标准文件路径或需要支持多种文件格式的场景。与 OpenCV 的默认 cv2.imread 函数相比,这种方法更加灵活,能够更好地处理文件路径和编码问题。3.def imwrite(filename: str, img: np.ndarray, params=None):
# 这段代码定义了一个自定义的 imwrite 函数,用于将图像保存到文件中。
# 定义了一个函数 imwrite ,它接受三个参数。
# 1.filename :一个字符串,表示要保存的目标图像文件路径。
# 2.img :一个 NumPy 数组,表示要保存的图像。
# 3.params :一个可选的参数列表,用于指定保存图像时的附加参数(例如压缩格式、质量等)。默认值为 None 。
def imwrite(filename: str, img: np.ndarray, params=None):# 将图像写入文件。"""Write an image to a file.Args:filename (str): Path to the file to write.img (np.ndarray): Image to write.params (list of ints, optional): Additional parameters. See OpenCV documentation.Returns:(bool): True if the file was written, False otherwise."""# 使用 try 块来尝试执行保存图像的操作。如果在执行过程中发生异常,将捕获异常并返回 False 。try:# Path(filename).suffix :使用path lib.Path 模块获取文件的扩展名(例如 .jpg 、 .png 等)。这用于确定保存图像的格式。# cv2.imencode :将图像编码为指定格式的二进制数据。 Path(filename).suffix 提供了文件扩展名, img 是要保存的图像, params 是附加参数。# cv2.imencode(...)[1] : cv2.imencode 返回一个元组,其中第二个元素是编码后的二进制数据。# .tofile(filename) :将编码后的二进制数据写入目标文件。cv2.imencode(Path(filename).suffix, img, params)[1].tofile(filename)# 如果图像成功保存,返回 True 。return True# 如果在保存图像的过程中发生任何异常,将捕获异常。except Exception:# 如果发生异常,返回 False ,表示图像保存失败。return False
# 这段代码实现了一个自定义的 imwrite 函数,用于将图像保存到文件中。它通过 cv2.imencode 将图像编码为指定格式的二进制数据,然后使用 .tofile 方法将数据写入目标文件。函数还通过 try-except 块来处理可能发生的异常,确保在保存失败时能够返回错误信息。这种方法特别适用于需要处理文件路径和格式的场景,比 OpenCV 的默认 cv2.imwrite 函数更加灵活和健壮。4.def imshow(winname: str, mat: np.ndarray):
# 这段代码定义了一个自定义的 imshow 函数,用于在指定窗口中显示图像。
# 定义了一个函数 imshow ,它接受两个参数。
# 1.winname :一个字符串,表示显示图像的窗口名称。
# 2.mat :一个 NumPy 数组,表示要显示的图像。
def imshow(winname: str, mat: np.ndarray):# 在指定窗口中显示图像。"""Displays an image in the specified window.Args:winname (str): Name of the window.mat (np.ndarray): Image to be shown."""# 这是函数的核心部分,调用了 _imshow 函数来显示图像。# winname.encode("unicode_escape").decode() : winname.encode("unicode_escape") 将窗口名称字符串编码为 Unicode 转义序列。例如, "图像" 会被编码为 "\u56fe\u50cf" 。 .decode() 将编码后的 Unicode 转义序列解码回普通字符串。这一步是为了确保窗口名称在不同操作系统和语言环境下都能正确显示。# mat :传递给 _imshow 的图像数据。_imshow(winname.encode("unicode_escape").decode(), mat)
# 这段代码实现了一个自定义的 imshow 函数,用于在指定窗口中显示图像。它通过将窗口名称进行 Unicode 转义编码和解码,确保窗口名称在多语言环境下能够正确显示。这种方法特别适用于需要支持多语言窗口标题的场景。5.PyTorch functions
# PyTorch functions ----------------------------------------------------------------------------------------------------
# 这段代码定义了两个别名 _torch_load 和 _torch_save ,分别用于 PyTorch 的 torch.load 和 torch.save 函数。这种做法通常是为了避免在后续代码中直接调用原函数时可能出现的递归错误。
# 定义了一个别名 _torch_load ,它指向 PyTorch 的 torch.load 函数。
# 目的 :通过这种方式,可以避免在后续代码中直接调用 torch.load ,从而防止可能出现的递归错误。递归错误通常发生在函数调用自身时,如果没有正确的退出条件,会导致无限递归,最终导致栈溢出错误。
# 应用场景 :在某些情况下,开发者可能需要对 torch.load 函数进行包装或修改其行为,而直接调用原函数可能会导致递归调用问题。通过定义别名,可以安全地调用原函数。
_torch_load = torch.load # copy to avoid recursion errors
# 定义了一个别名 _torch_save ,它指向 PyTorch 的 torch.save 函数。
# 目的 :与 _torch_load 类似,为了避免在后续代码中直接调用 torch.save ,从而防止递归错误。
# 应用场景 :在对 torch.save 函数进行扩展或修改时,使用别名可以避免直接调用原函数,确保代码的逻辑清晰且不会出现递归问题。
_torch_save = torch.save
# 这段代码通过定义 _torch_load 和 _torch_save 别名,为 PyTorch 的 torch.load 和 torch.save 函数创建了安全的代理。这种做法的主要目的是避免在后续代码中直接调用原函数时可能出现的递归错误。通过使用别名,开发者可以在不影响原函数功能的前提下,对这些函数进行扩展或修改,从而实现更灵活的功能。6.def torch_load(*args, **kwargs):
# 这段代码定义了一个自定义的 torch_load 函数,用于加载 PyTorch 模型或对象,并通过添加额外的参数来避免警告。
# 定义了一个函数 torch_load ,它接受可变长度的参数列表 *args 和任意关键字参数 **kwargs 。这种参数形式允许函数接受任意数量和类型的参数,并将它们传递给 torch.load 。
def torch_load(*args, **kwargs):# 使用更新的参数加载 PyTorch 模型以避免出现警告。# 此函数包装 torch.load 并为 PyTorch 1.13.0+ 添加“weights_only”参数以防止出现警告。# 注意:# 对于 PyTorch 2.0 及更高版本,如果未提供参数,此函数会自动设置“weights_only=False”,以避免出现弃用警告。"""Load a PyTorch model with updated arguments to avoid warnings.This function wraps torch.load and adds the 'weights_only' argument for PyTorch 1.13.0+ to prevent warnings.Args:*args (Any): Variable length argument list to pass to torch.load.**kwargs (Any): Arbitrary keyword arguments to pass to torch.load.Returns:(Any): The loaded PyTorch object.Note:For PyTorch versions 2.0 and above, this function automatically sets 'weights_only=False'if the argument is not provided, to avoid deprecation warnings."""# 从 ultralytics.utils.torch_utils 模块中导入 TORCH_1_13 。 TORCH_1_13 是一个布尔值,用于检查当前安装的 PyTorch 版本是否为 1.13.0 或更高版本。from ultralytics.utils.torch_utils import TORCH_1_13# 检查当前 PyTorch 版本是否为 1.13.0 或更高版本,并且检查 kwargs 中是否已经提供了 weights_only 参数。if TORCH_1_13 and "weights_only" not in kwargs:# 如果没有提供 weights_only 参数,将其设置为 False 。# 这一步是为了避免在 PyTorch 1.13.0 及以上版本中出现的警告,特别是关于 weights_only 参数的弃用警告。kwargs["weights_only"] = False# 调用 _torch_load 函数(这是 torch.load 的别名),并将 *args 和 **kwargs 传递给它。 返回加载的 PyTorch 对象。return _torch_load(*args, **kwargs)
# 这段代码实现了一个自定义的 torch_load 函数,用于加载 PyTorch 模型或对象。它通过检查 PyTorch 版本,并在必要时添加 weights_only=False 参数,避免了在 PyTorch 1.13.0 及以上版本中可能出现的警告。这种方法特别适用于需要兼容多个 PyTorch 版本的场景,确保代码的健壮性和兼容性。7.def torch_save(*args, **kwargs):
# 这段代码定义了一个自定义的 torch_save 函数,用于保存 PyTorch 模型或对象。它通过增加重试机制和指数退避策略来提高保存操作的鲁棒性。
# 定义了一个函数 torch_save ,它接受可变长度的参数列表 *args 和任意关键字参数 **kwargs 。这种参数形式允许函数接受任意数量和类型的参数,并将它们传递给 torch.save 。
def torch_save(*args, **kwargs):# 可选择使用 dill 序列化 lambda 函数(pickle 无法做到),通过 3 次重试和指数对峙来增强稳健性,以防保存失败。"""Optionally use dill to serialize lambda functions where pickle does not, adding robustness with 3 retries andexponential standoff in case of save failure.Args:*args (tuple): Positional arguments to pass to torch.save.**kwargs (Any): Keyword arguments to pass to torch.save."""# 使用 for 循环实现最多 3 次重试。循环变量 i 的范围是 0, 1, 2, 3 ,因此总共尝试 4 次(包括第一次尝试)。for i in range(4): # 3 retries# 在 try 块中调用 _torch_save 函数(这是 torch.save 的别名),并将 *args 和 **kwargs 传递给它。 如果保存操作成功,返回保存的结果。try:return _torch_save(*args, **kwargs)# 如果在保存过程中发生 RuntimeError ,捕获异常并处理。 这种错误可能是由于设备正在刷新、磁盘空间不足或杀毒软件正在扫描文件等原因导致的。except RuntimeError as e: # unable to save, possibly waiting for device to flush or antivirus scan# 如果这是第 4 次尝试(即 i == 3 ),则重新抛出异常,表示保存操作失败。if i == 3:raise e# 如果不是最后一次尝试,则使用指数退避策略等待一段时间后再尝试保存。# time.sleep((2**i) / 2) :根据尝试次数 i ,计算等待时间。例如 :# 第一次失败后等待 0.5 秒。# 第二次失败后等待 1.0 秒。# 第三次失败后等待 2.0 秒。# 这种策略可以减少因设备忙或杀毒软件扫描导致的连续失败。time.sleep((2**i) / 2) # exponential standoff: 0.5s, 1.0s, 2.0s
# 这段代码实现了一个自定义的 torch_save 函数,用于保存 PyTorch 模型或对象。它通过增加重试机制和指数退避策略来提高保存操作的鲁棒性。这种方法特别适用于在某些情况下可能会失败的保存操作,例如磁盘空间不足、设备正在刷新或杀毒软件正在扫描文件等。通过重试和等待,可以显著提高保存操作的成功率。相关文章:

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-patches.py
patches.py ultralytics\utils\patches.py 目录 patches.py 1.所需的库和模块 2.def imread(filename: str, flags: int cv2.IMREAD_COLOR): 3.def imwrite(filename: str, img: np.ndarray, paramsNone): 4.def imshow(winname: str, mat: np.ndarray): 5.PyTorch…...

R语言LCMM多维度潜在类别模型流行病学研究:LCA、MM方法分析纵向数据
全文代码数据:https://tecdat.cn/?p39710 在数据分析领域,当我们面对一组数据时,通常会有已知的分组情况,比如不同的治疗组、性别组或种族组等(点击文末“阅读原文”获取完整代码数据)。 然而,…...

2025 年前端开发现状分析:卷疯了还是卷麻了?
一、前端现状:框架狂飙,开发者崩溃 如果你是个前端开发者,那么你大概率经历过这些场景: 早上打开 CSDN(或者掘金,随便),发现又有新框架发布了,名字可能是 VueXNext.js 之…...

RDK新一代模型转换可视化工具!!!
作者:SkyXZ CSDN:SkyXZ~-CSDN博客 博客园:SkyXZ - 博客园 之前在使用的RDK X3的时候,吴诺老师wunuo发布了新一代量化转换工具链使用教程,这个工具真的非常的方便,能非常快速的完成X3上模型的量化…...

JVM春招快速学习指南
1.说在前面 在Java相关岗位的春/秋招面试过程中,JVM的学习是必不可少的。本文主要是通过《深入理解Java虚拟机》第三版来介绍JVM的学习路线和方法,并对没有过JVM基础的给出阅读和学习建议,尽可能更加快速高效的进行JVM的学习与秋招面试的备战…...

C#中的序列化和反序列化
序列化是指将对象转换为可存储或传输的格式,例如将对象转换为JSON字符串或字节流。反序列化则是将存储或传输的数据转换回对象的过程。这两个过程在数据持久化、数据交换以及与外部系统的通信中非常常见 把对象转换成josn字符串格式 这个过程就是序列化 josn字符…...

xcode常见设置
1、如何使用cmake构建archs为$(ARCHS_STANDARD)的xcode项目 在cmake中使用如下指令 set(CMAKE_OSX_ARCHITECTURES "$(ARCHS_STANDARD)") cmake - nomadli的博客 | nomadli Blog...

PG高可用学习@2
目录标题 一、Patroni 支持在同步复制下备库故障时自动降级为异步复制?参考依据1. PostgreSQL 官方文档2. Patroni 官方文档3. 高可用和容错设计原则 二、patroni 是如何检测备库故障的?1. 心跳机制2. 监控数据库进程状态3. 查询系统视图4. 复制延迟监测5. 网络连接…...

centos 8和centos 9 stream x64的区别
以下是 CentOS 8 与 CentOS Stream 9 的主要区别,从技术架构、更新策略到适用场景等维度进行对比: AI产品独立开发实战营 联系我了解 1. 定位与更新策略 特性CentOS 8CentOS Stream 9定位原为 RHEL 8 的免费稳定复刻版RHEL 9 的上游开发分支ÿ…...
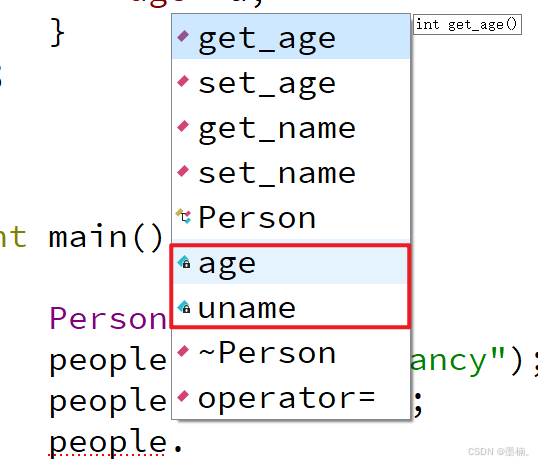
C++基础学习记录—类
1、面向对象的三大特征:封装、继承、多态 2、类和对象 2.1、类的概念 类:类是一个抽象的概念,用于描述同一类对象的特点。 对象:根据类的概念所创造的实体。 类中包含属性和行为 属性:描述类的数据,一…...

云原生时代的后端开发:架构、工具与最佳实践
随着云计算的迅猛发展,云原生(Cloud Native)逐渐成为后端开发的主流趋势。云原生后端不仅能够提高应用的灵活性和可扩展性,还能显著优化开发和运维流程。本文将围绕云原生后端的关键概念、当前热门技术及最佳实践,帮助…...

ARM Cortex-M3/M4 权威指南 笔记【一】技术综述
一、Cortex-M3/M4 处理器的一般信息 1.1 处理器类型 ARM Cortex-M 为 32 位 RISC(精简指令集)处理器,其具有: 32位寄存器32位内部数据通路32位总线接口 除了 32 位数据,Cortex-M 处理器(以及其他任何 A…...

12.项目结构
后端结构 ruoyi-admin 项目启动的入口 提供了两种启动方式 1.RuoYiApplication基于springboot,内置tomcat,直接运行。 2.RuoYiServletInitializer将springboot项目打成一个war包,用外置的servlet容器来运行。 通用功能的controller 后台登录相关的、权限控制相关的、数据字…...

保研考研机试攻略:python笔记(4)
🐨🐨🐨15各类查找 🐼🐼二分法 在我们写程序之前,我们要定义好边界,主要是考虑区间边界的闭开问题。 🐶1、左闭右闭 # 左闭右闭 def search(li, target): h = len(li) - 1l = 0#因为都是闭区间,h和l都可以取到并且相等while h >= l:mid = l + (h - l) // 2…...

高阶C语言|枚举与联合
💬 欢迎讨论:在阅读过程中有任何疑问,欢迎在评论区留言,我们一起交流学习! 👍 点赞、收藏与分享:如果你觉得这篇文章对你有帮助,记得点赞、收藏,并分享给更多对C语言感兴…...

【天梯赛】L1-104 九宫格(C++)
易忽略的错误:开始习惯性地看到n就以为是n*n数组了,实际上应该是9*9的固定大小数组,查了半天没查出来 题面 L1-104 九宫格 - 团体程序设计天梯赛-练习集 代码实现 #include<bits/stdc.h> using namespace std; //易错:开…...

现代C++多线程基础 -忆苦思甜pthread_mutex
c 老古董 文章目录 c 老古董pthread_mutex概念常用apipthread_mutex_initpthread_mutex_lockpthread_mutex_trylockpthread_mutex_unlockpthread_mutex_destroy 案例 pthread_mutex 概念 互斥锁 mutex是一种简单的加锁的方法来控制对共享资源的访问,mutex只有两种…...

soular基础教程-使用指南
soular是TikLab DevOps工具链的统一帐号中心,今天来介绍如何使用 soular 配置你的组织、工作台,快速入门上手。  1. 账号管理 可以对账号信息进行多方面管理,包括分配不同的部门、用户组等,从而确保账号权限和职责…...

网络安全网格架构(CSMA) 网络安全框架csf
CSRF:Cross Site Request Forgy(跨站请求伪造) 用户打开另外一个网站,可以对本网站进行操作或攻击。容易产生传播蠕虫。 CSRF攻击原理: 1、用户先登录A网站 2、A网站确认身份返回用户信息 3、B网站冒充用户信息而不是直接获取用…...

基于DeepSeek API和VSCode的自动化网页生成流程
1.创建API key 访问官网DeepSeek ,点击API开放平台。 在开放平台界面左侧点击API keys,进入API keys管理界面,点击创建API key按钮创建API key,名称自定义。 2.下载并安装配置编辑器VSCode 官网Visual Studio Code - Code Editing…...

南京大学发布“视频侦探“系统:让AI像侦探一样从长视频中找线索
这项由南京大学与中科院自动化所联合进行的研究发表于2026年的计算机视觉与模式识别(CVPR)会议,论文编号为arXiv:2603.22285。有兴趣深入了解的读者可以通过该编号查询完整论文内容。当我们观看一部两小时的电影时,想要回答"主角在什么时候第一次露…...

等保三级Java安全改造全周期实录,从代码审计到渗透验证的12个生死关卡
第一章:等保三级Java安全改造的合规基线与生命周期全景图等保三级对Java应用提出了覆盖身份鉴别、访问控制、安全审计、通信保密性、代码安全及可信执行环境的全维度要求。其合规基线并非静态清单,而是贯穿需求分析、设计开发、测试验证、上线部署与持续…...

Calypso vs PC-DMIS:三坐标两大软件脱机编程实战对比与选型指南
Calypso vs PC-DMIS:三坐标测量软件脱机编程深度对比与实战选型策略 在精密制造领域,三坐标测量机(CMM)的脱机编程能力直接决定了检测效率与资源利用率。作为行业两大标杆,蔡司Calypso与海克斯康PC-DMIS在用户界面设计、编程逻辑、仿真验证等…...

别再手动画封装了!用嘉立创EDA免费库5分钟搞定Altium Designer缺失的器件
5分钟极速救援:用嘉立创EDA破解Altium Designer封装缺失难题 深夜11点,李工盯着屏幕上闪烁的光标和半成品的PCB布局图,额头渗出细密的汗珠。项目交付截止前48小时,团队突然发现Altium Designer官方库中缺少关键芯片TPS5430DDAR的封…...

Wan2.2-I2V-A14B私有部署镜像优势:零依赖冲突、开箱即用、免编译安装
Wan2.2-I2V-A14B私有部署镜像优势:零依赖冲突、开箱即用、免编译安装 1. 镜像核心价值与定位 Wan2.2-I2V-A14B私有部署镜像是专为文生视频场景打造的一站式解决方案。这个镜像最大的特点就是解决了AI模型部署中最让人头疼的环境配置问题,真正做到下载即…...
)
别再手动转格式了!用Python的docx2pdf库5行代码搞定Word转PDF(Windows/Mac通用教程)
5行代码终结格式转换焦虑:Python自动化Word转PDF全攻略 每次市场部门催着要电子合同时,你是不是还在手忙脚乱地点击"另存为PDF"?当运营团队需要批量生成上百份产品手册时,是否还在忍受重复机械的格式转换操作࿱…...

2026年Java面试最常被问的1000道题目及参考答案
Java学到什么程度可以面试工作? 要达到能够面试Java开发工作的水平,需要掌握以下几个方面的知识和技能: 1. 基础扎实:熟悉Java语法、面向对象编程概念、异常处理、I/O流等基础知识。这是所有Java开发者必备的基础,也…...

【人生底稿 03】2012 末日传说与我踏入 IT 的起点
接上《人生底稿》系列,本篇记录一段真实的成长碎片,不严格按时间线更新,只为记下一个农村少年,一步步走向社会的真实轨迹。 在参加某科技公司 ITMS 培训之前,我先经历了一轮面试 —— 上机题 技术面,分数…...
到底是怎么工作的?)
3GPP TS 23.256标准解读:无人机广播远程识别码(Broadcast Remote ID)到底是怎么工作的?
3GPP TS 23.256标准深度解析:无人机广播远程识别码的技术实现与合规路径 当一架无人机在城市上空盘旋时,地面人员如何快速确认它的合法身份?监管机构又该如何在密集的无线电环境中精准捕捉每一架飞行器的信息?这些问题的答案&…...
)
OpenCV实战:3种图像降噪滤波器的Python代码对比(附效果图)
OpenCV实战:3种图像降噪滤波器的Python代码对比(附效果图) 在数字图像处理中,噪声是影响图像质量的主要因素之一。无论是来自传感器的不完美,还是传输过程中的干扰,噪声都会降低图像的清晰度和可用性。对于…...