【经验分享】Linux 系统安装后内核参数优化
在 Linux 系统安装后,进行内核优化有助于提升系统的性能、稳定性和安全性。以下是一些常见的内核优化操作:
修改/etc/sysctl.conf 文件
执行sysctl -p使配置生效。
kernel.shmmax = 135185569792
kernel.shmall = 4294967296
fs.aio-max-nr = 3145728
fs.file-max = 6815744
kernel.shmmni = 4096
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048586
kernel.panic_on_oops = 1
net.ipv4.ipfrag_high_thresh=41943040
net.ipv4.ipfrag_low_thresh=40894464
net.ipv4.ipfrag_time=60
kernel.sem = 1024 60000 1024 128#based on best practice
net.ipv4.ipfrag_high_thresh=41943040
net.ipv4.ipfrag_low_thresh=40894464
net.ipv4.ipfrag_time=60
kernel.sem = 1024 60000 1024 128#if there are issue like the one described in note 2163270.1
vm.dirty_background_ratio=1
vm.dirty_ratio=3
以下是对这些 sysctl.conf 配置项的详细解释:
共享内存相关参数
kernel.shmmax = 135185569792
- 内涵:
kernel.shmmax定义了单个共享内存段(Shared Memory Segment)能够分配的最大字节数。共享内存是一种进程间通信(IPC)机制,多个进程可以访问同一块物理内存区域,从而实现高效的数据共享。 - 意义:在需要大量数据共享的应用场景中,如数据库管理系统,较大的
shmmax值可以避免因共享内存段大小限制而导致的性能问题或错误。该值设置为135185569792字节(约 126GB),为应用程序提供了较大的共享内存空间。
kernel.shmall = 4294967296
- 内涵:
kernel.shmall表示系统范围内可以使用的共享内存页面总数。页面是操作系统进行内存管理的基本单位,不同系统的页面大小可能不同(通常为 4KB 或 8KB)。 - 意义:该参数限制了系统中所有共享内存段的总大小。通过设置合适的
shmall值,可以确保系统有足够的页面来支持共享内存的使用。这里设置为4294967296,允许系统使用较多的共享内存页面。
kernel.shmmni = 4096
- 内涵:
kernel.shmmni定义了系统中可以同时存在的共享内存段的最大数量。 - 意义:在多进程共享内存的场景中,限制共享内存段的数量可以防止系统资源被过度占用。设置为
4096意味着系统最多可以创建 4096 个共享内存段。
文件系统相关参数
fs.aio-max-nr = 3145728
- 内涵:
fs.aio-max-nr表示系统中可以同时存在的异步 I/O(Asynchronous I/O)请求的最大数量。异步 I/O 允许应用程序在发起 I/O 请求后继续执行其他任务,而不必等待 I/O 操作完成。 - 意义:对于需要处理大量并发 I/O 请求的应用程序,如数据库和文件服务器,增加该参数的值可以提高系统的 I/O 处理能力。设置为
3145728允许系统同时处理较多的异步 I/O 请求。
fs.file-max = 6815744
- 内涵:
fs.file-max定义了系统中可以同时打开的文件描述符的最大数量。文件描述符是操作系统用于标识打开文件的整数,每个打开的文件、套接字等都有一个对应的文件描述符。 - 意义:在高并发的应用场景中,如 Web 服务器,可能会同时打开大量的文件和套接字。增加
fs.file-max的值可以避免因文件描述符耗尽而导致的错误。
网络相关参数
net.ipv4.ip_local_port_range = 9000 65500
- 内涵:
net.ipv4.ip_local_port_range指定了系统在创建 TCP 或 UDP 套接字时可以使用的本地端口号范围。端口号是用于标识网络应用程序的 16 位整数,范围从 0 到 65535。 - 意义:默认情况下,系统使用的本地端口号范围可能较小,在高并发的网络环境中可能会导致端口号耗尽。通过扩大本地端口号范围,可以增加系统的并发连接能力。这里将范围设置为
9000到65500。
net.core.rmem_default = 262144 和 net.core.rmem_max = 4194304
- 内涵:
net.core.rmem_default是套接字接收缓冲区的默认大小(以字节为单位),而net.core.rmem_max是套接字接收缓冲区的最大大小。接收缓冲区用于临时存储从网络接收到的数据。 - 意义:适当调整接收缓冲区的大小可以提高网络数据的接收效率。较大的接收缓冲区可以减少数据丢失的可能性,特别是在网络带宽较高或数据传输速率较快的情况下。
net.core.wmem_default = 262144 和 net.core.wmem_max = 1048586
- 内涵:
net.core.wmem_default是套接字发送缓冲区的默认大小(以字节为单位),net.core.wmem_max是套接字发送缓冲区的最大大小。发送缓冲区用于临时存储要发送到网络的数据。 - 意义:调整发送缓冲区的大小可以优化网络数据的发送性能。较大的发送缓冲区可以减少应用程序等待网络发送的时间,提高数据发送的效率。
net.ipv4.ipfrag_high_thresh=41943040 和 net.ipv4.ipfrag_low_thresh=40894464
- 内涵:这两个参数与 IP 分片(IP Fragmentation)有关。当 IP 数据包的大小超过网络接口的最大传输单元(MTU)时,数据包会被分片。
net.ipv4.ipfrag_high_thresh是 IP 分片缓存的高水位线,当缓存中的分片数据达到该值时,系统会开始丢弃新的分片;net.ipv4.ipfrag_low_thresh是低水位线,当缓存中的分片数据减少到该值以下时,系统会恢复接收新的分片。 - 意义:通过合理设置这两个参数,可以避免 IP 分片缓存占用过多的系统内存,同时确保在必要时能够正常处理 IP 分片。
net.ipv4.ipfrag_time=60
- 内涵:
net.ipv4.ipfrag_time表示 IP 分片在缓存中保留的最长时间(以秒为单位)。如果在该时间内所有分片没有全部到达,则会丢弃这些分片。 - 意义:设置合适的分片保留时间可以避免因丢失分片而导致的缓存占用时间过长,提高系统资源的利用率。
内核其他参数
kernel.panic_on_oops = 1
- 内涵:
kernel.panic_on_oops是一个布尔值参数,当设置为1时,表示在内核发生严重错误(Oops)时,系统会立即进入崩溃(Panic)状态。 - 意义:在生产环境中,内核错误可能会导致系统不稳定或数据丢失。通过设置该参数,可以在发生严重错误时及时停止系统,避免进一步的问题,并方便进行故障排查。
kernel.sem = 1024 60000 1024 128
- 内涵:
kernel.sem用于设置 System V 信号量(Semaphores)的相关参数,这四个值分别表示:- 每个信号量集(Semaphore Set)中允许的最大信号量数量。
- 系统范围内允许的最大信号量数量。
- 每个信号量集的最大操作数量。
- 系统范围内允许的最大信号量集数量。
- 意义:信号量是一种用于进程同步和互斥的机制。通过调整这些参数,可以满足不同应用程序对信号量的需求,避免因信号量资源不足而导致的错误。
虚拟内存相关参数
vm.dirty_background_ratio=1 和 vm.dirty_ratio=3
- 内涵:
vm.dirty_background_ratio表示当系统中脏页(Dirty Pages,即已修改但尚未写入磁盘的内存页面)的比例达到该值时,内核会启动一个后台进程将脏页写入磁盘;vm.dirty_ratio表示当脏页比例达到该值时,应用程序在进行写操作时会被阻塞,直到部分脏页被写入磁盘。 - 意义:适当调整这两个参数可以平衡内存使用和磁盘 I/O 性能。较小的值可以减少脏页在内存中停留的时间,降低数据丢失的风险,但可能会增加磁盘 I/O 负担;较大的值可以减少磁盘 I/O 次数,但可能会导致系统在崩溃时丢失更多的数据。
这些内核参数的调整旨在优化系统的性能、稳定性和资源利用率,以满足不同应用场景的需求。
相关文章:

【经验分享】Linux 系统安装后内核参数优化
在 Linux 系统安装后,进行内核优化有助于提升系统的性能、稳定性和安全性。以下是一些常见的内核优化操作: 修改/etc/sysctl.conf 文件 执行sysctl -p使配置生效。 kernel.shmmax 135185569792 kernel.shmall 4294967296 fs.aio-max-nr 3145728 fs.fi…...

linux统计文件夹下有多少个.rst文件行数小于4行
您可以使用 find 命令结合 wc 命令来统计文件夹下 .rst 文件行数小于 4 行的文件数量。以下是一个具体的命令示例: find /path/to/directory -name "*.rst" -type f -exec wc -l {} | awk $1 < 4 | wc -l解释: find /path/to/directory …...

使用开源项目xxl-cache构建多级缓存
xxl-cache简介 官网地址:https://www.xuxueli.com/xxl-cache/ 概述 XXL-CACHE 是一个 多级缓存框架,高效组合本地缓存和分布式缓存(RedisCaffeine),支持“多级缓存、一致性保障、TTL、Category隔离、防穿透”等能力;拥有“高性…...
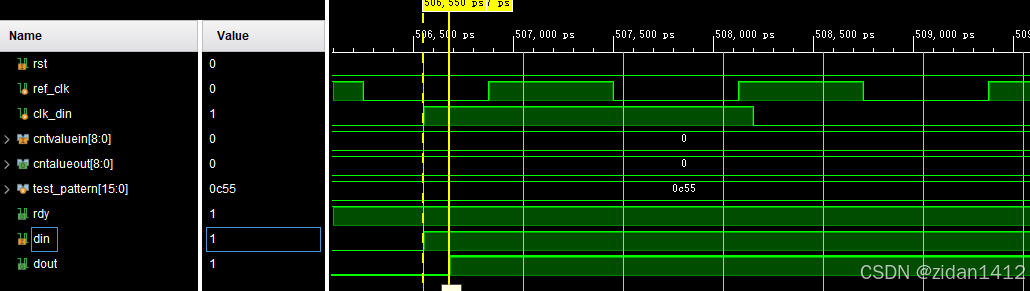
LVDS接口总结--(5)IDELAY3仿真
仿真参考资料如下: https://zhuanlan.zhihu.com/p/386057087 timescale 1 ns/1 ps module tb_idelay3_ctrl();parameter REF_CLK 2.5 ; // 400MHzparameter DIN_CLK 3.3 ; // 300MHzreg ref_clk ;reg …...

Vue3(1)
一.create-vue // new Vue() 创建一个应用实例 > createApp() // createRouter() createStore() // 将创建实例进行了封装,保证每个实例的独立封闭性import { createApp } from vue import App from ./App.vue// mount 设置挂载点 #app (id为app的盒子) createA…...
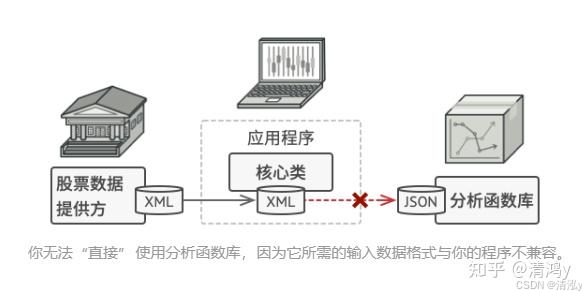
玩转适配器模式
文章目录 解决方案现实的举例适用场景实现方式适配器模式优缺点优点:缺点:适配器模式可比上一篇的工厂模式好理解多了,工厂模式要具有抽象的思维。这个适配器模式,正如字面意思,就是要去适配某一件物品。 假如你正在开发一款股票市场监测程序, 它会从不同来源下载 XML 格…...
2.11寒假作业
web:[SWPUCTF 2022 新生赛]js_sign 打开环境是这样的,随便输入进行看看 提示错误,看源码其中的js代码 这个代码很容易理解,要让输入的内容等于对应的字符串,显然直接复制粘贴是错的 这串字符看起来像是base64加密&…...
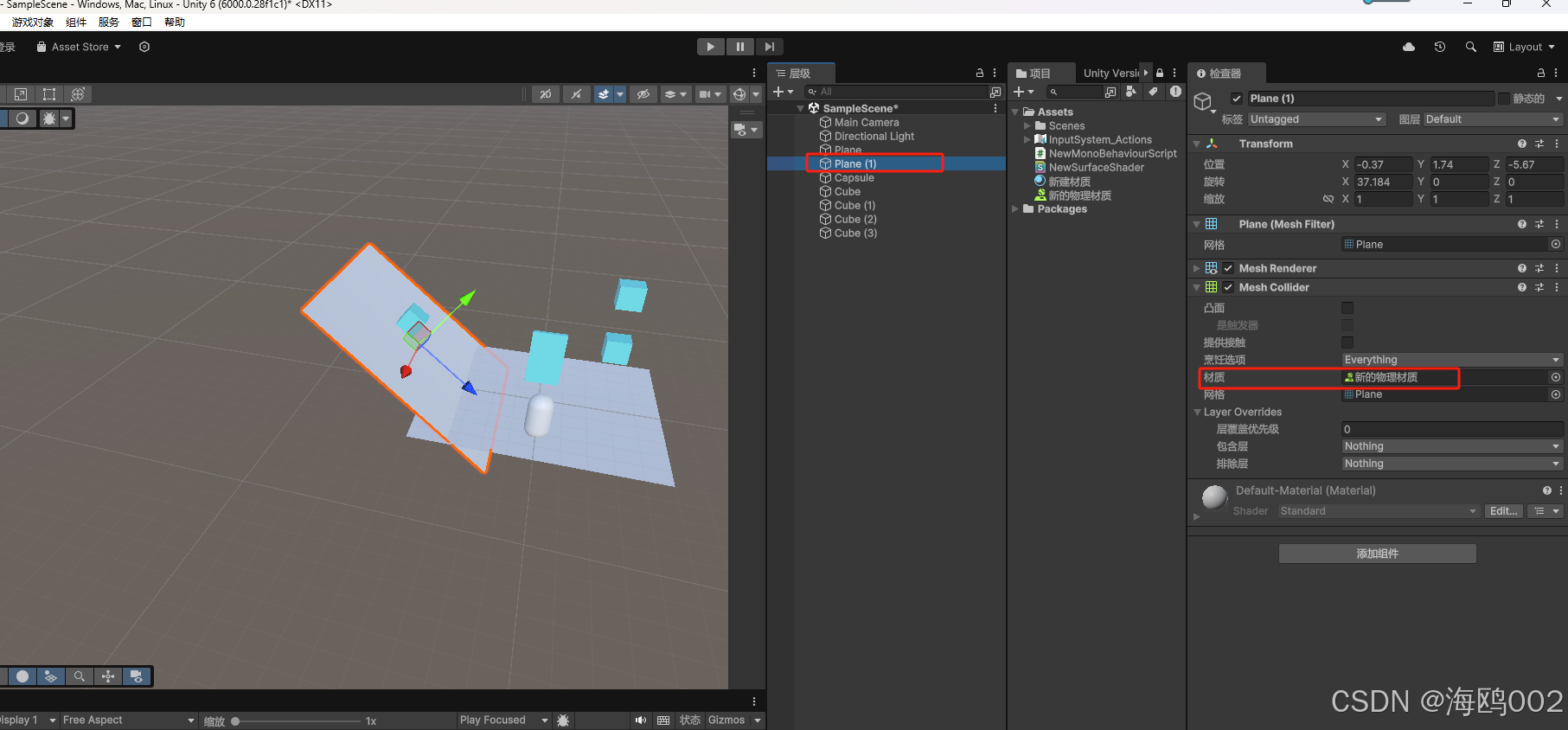
untiy 冰面与地面,物理材质的影响
效果 WeChat_20250211165601...

视频编解码标准中的 Profile 和 Level
视频编解码标准中的 Profile 和 Level 在视频编码标准(如 H.264/AVC、HEVC/H.265、H.266/VVC、AV1)中,Profile(配置文件) 和 Level(级别) 是两个重要的概念,它们用于定义编码器和解码器支持的特性、功能以及视频质量与编码效率之间的权衡。 Profile(配置文件) Pro…...

通用的将jar制作成docker镜像sh脚本
通用的将jar制作成docker镜像sh脚本 为了在将 JAR 制作成 Docker 镜像的过程中创建日志目录,可以对之前的脚本进行扩展。以下是改进后的脚本,会在镜像构建时在容器内创建日志目录,并将日志文件挂载到该目录下。 在生成的 Dockerfile 中添加…...

AUTOGPT:基于GPT模型开发的实验性开源应用程序; 目标设定与分解 ;;自主思考与决策 ;;信息交互与执行
目录 AUTOGPT是一款基于GPT模型开发的实验性开源应用程序目标设定与分解自主思考与决策信息交互与执行AUTOGPT是一款基于GPT模型开发的实验性开源应用程序 目标设定与分解 自主思考与决策 信息交互与执行 AUTOGPT是一款基于GPT模型开发的实验性开源应用程序,它能让大语言模…...

异步线程中使用RestTemplate注入空指针解决
在某种情况下,调用第三方或者jar文件中封装的httpClient时,上层调用采用异步线程调用,导致底层的RestTemplate注入为空,无法正常调用,需要强制将spring的上下文绑定到异步线程中。 强制传递 Spring 上下文到异步线程 …...
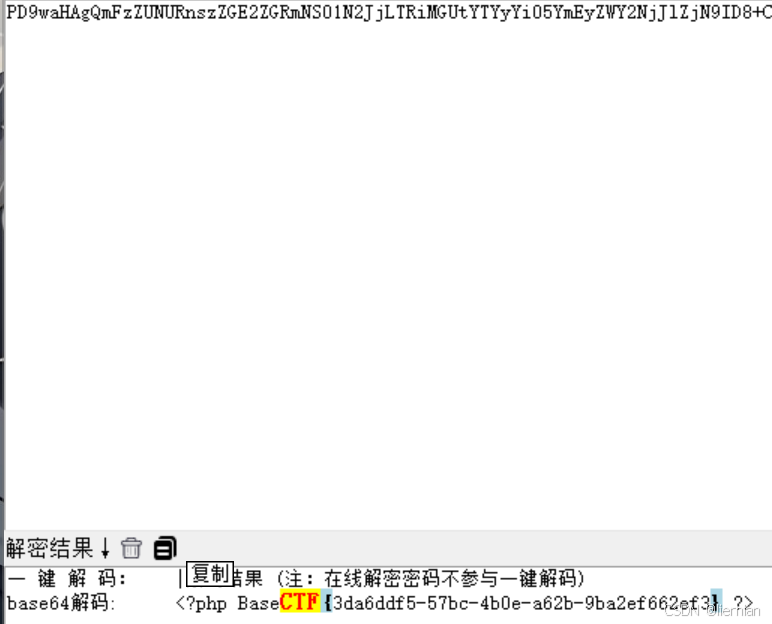
2024BaseCTF_week4_web上
继续!冲冲冲 目录 圣钥之战1.0 nodejs 原型 原型链 原型链污染 回到题目 flag直接读取不就行了? 圣钥之战1.0 from flask import Flask,request import jsonapp Flask(__name__)def merge(src, dst):for k, v in src.items():if hasattr(dst, __geti…...

说一下 jvm 有哪些垃圾回收器?
JVM 垃圾回收器对比表 垃圾回收器类型工作方式回收方式停顿时间适用场景优点缺点常见问题常见配置Serial GC串行单线程,STW年轻代:复制算法 老年代:标记-整理长小内存、单核CPU,如桌面应用或嵌入式设备简单高效,适用于…...

react国际化配置react-i18next详解
react PC端项目构建TS,react18.2.0antdviteaxiosreduxsassts 完整版代码下载: https://download.csdn.net/download/randy521520/88922625 react PC端项目构建,react18.2.0antdviteaxiosreduxsass完整版代码下载: https://downloa…...

Java并发编程——上下文切换、死锁、资源限制
文章目录 1.1上下文切换(1)上下文切换的概念(2)多线程一定比单线程快吗?(3)测量上下文切换如何减少上下文切换 1.2 死锁(1)死锁的定义(2)死锁产生…...
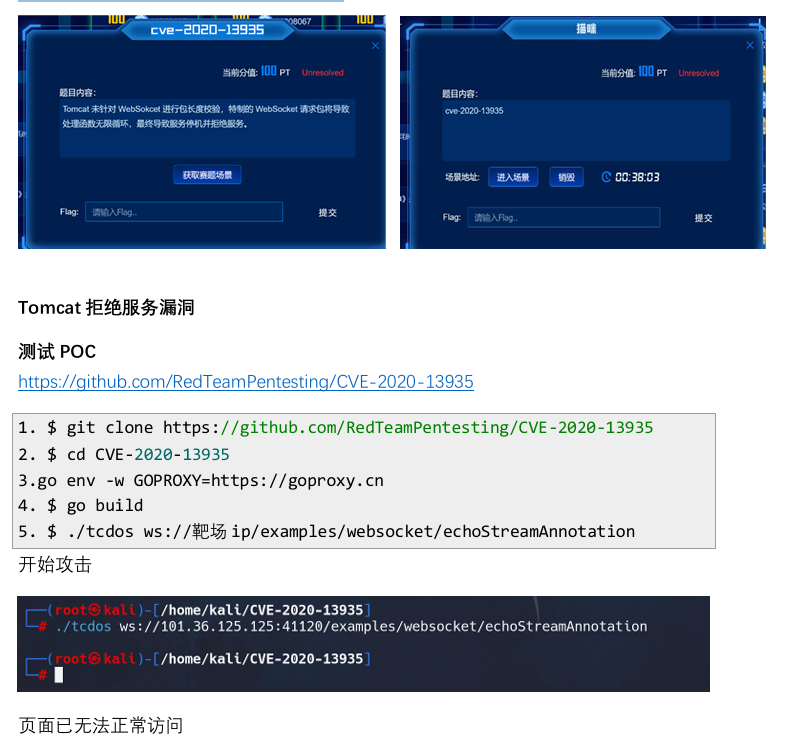
MS08067练武场--WP
免责声明:本文仅用于学习和研究目的,不鼓励或支持任何非法活动。所有技术内容仅供个人技术提升使用,未经授权不得用于攻击、侵犯或破坏他人系统。我们不对因使用本文内容而引起的任何法律责任或损失承担责任。 注:此文章为快速通关…...

ubuntu文件同步
1. 使用 rsync 同步文件 rsync 是一个常用的文件同步工具,可以在本地或远程系统之间同步文件和目录。 基本用法: rsync -avz /源目录/ 目标目录/-a:归档模式,保留文件属性。-v:显示详细输出。-z:压缩传输…...

C++23 新特性解析
引言:C的持续进化 在ISO C标准委员会的不懈努力下,C23作为继C20后的又一重要迭代版本,带来了十余项核心语言特性改进和数十项标准库增强。本文将深入解析最具实用价值的五大新特性,介绍std::expected到模块化革命。 编译器支持 …...

算法05-堆排序
堆排序详解 堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法。它的核心思想是利用堆的性质(最大堆或最小堆)来实现排序。堆排序分为两个主要步骤:建堆和排序。 1. 什么是堆? 堆是一种特殊的完全二叉…...

OpenClaw安全防护全攻略:Qwen3-32B-Chat操作权限精细控制
OpenClaw安全防护全攻略:Qwen3-32B-Chat操作权限精细控制 1. 为什么需要安全防护? 当我第一次把OpenClaw接入本地部署的Qwen3-32B-Chat模型时,那种兴奋感至今记忆犹新——我的电脑突然有了一个24小时待命的AI助手。但很快,一个细…...

CUA Computer SDK:虚拟机自动化的终极解决方案,让AI代理掌控桌面级交互
CUA Computer SDK:虚拟机自动化的终极解决方案,让AI代理掌控桌面级交互 【免费下载链接】cua Create and run high-performance macOS and Linux VMs on Apple Silicon, with built-in support for AI agents. 项目地址: https://gitcode.com/GitHub_T…...

163MusicLyrics全能工具:三步搞定音乐歌词高效解决方案
163MusicLyrics全能工具:三步搞定音乐歌词高效解决方案 【免费下载链接】163MusicLyrics Windows 云音乐歌词获取【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 163MusicLyrics是一款专注于音乐歌词获取与管理的开源…...

企业如何防御LockBit 3.0?从IOC到实战检测规则编写指南
企业级防御实战:LockBit 3.0勒索病毒全维度对抗指南 1. 勒索病毒威胁态势与企业防御挑战 2023年全球网络安全报告显示,勒索软件攻击同比增长47%,其中LockBit系列占比高达28%。不同于传统恶意软件,LockBit 3.0采用模块化设计&#…...

超越矩阵SVD:T-SVD如何用傅里叶变换搞定三维数据补全?一个视频修复案例讲透
超越矩阵SVD:T-SVD如何用傅里叶变换搞定三维数据补全?一个视频修复案例讲透 当一段珍贵的历史视频出现帧丢失或噪声污染时,传统矩阵分解方法往往束手无策——它们将三维视频数据强行"压扁"成二维矩阵进行处理,破坏了时空…...

Keil MDK-ARM中map文件解析与内存管理
Keil MDK-ARM中map文件全面解析1. 项目概述在嵌入式系统开发过程中,内存管理是至关重要的环节。map文件作为编译链接过程中生成的中间文件,包含了程序内存布局的完整映射信息。对于使用Keil MDK-ARM开发环境的工程师而言,深入理解map文件的结…...

OpenClaw调试技巧:ollama-QwQ-32B任务失败日志分析方法
OpenClaw调试技巧:ollama-QwQ-32B任务失败日志分析方法 1. 为什么需要关注OpenClaw任务失败日志 上周我在尝试用OpenClaw自动整理项目文档时,遇到了一个令人抓狂的问题:明明配置好了ollama-QwQ-32B模型,任务却总是莫名其妙地卡在…...

腾讯地图SDK隐私协议合规接入实战:你的App真的合法显示地图了吗?
腾讯地图SDK隐私合规实战:从法律条文到代码落地的全流程指南 当你的App因为地图功能被应用商店拒审时,当用户投诉你的应用"偷偷收集位置信息"时,当合规团队发来长达20页的整改清单时——这些场景正在成为移动开发者的日常。去年某社…...

PCtoLCD2002字模提取软件:从基础配置到高效应用
1. PCtoLCD2002基础功能解析 第一次接触PCtoLCD2002时,我被它简洁的界面和强大的功能所吸引。这款软件虽然体积小巧,但在嵌入式开发领域却是不可或缺的利器。它主要解决了一个核心问题:如何将我们熟悉的文字和图形,转换成单片机能…...

Tailwind CSS在Vue3+Vite项目中的实战应用:从零到响应式按钮
Tailwind CSS在Vue3Vite项目中的实战应用:从零到响应式按钮 如果你正在使用Vue3和Vite构建现代Web应用,却对传统CSS的维护成本感到头疼,那么Tailwind CSS可能会成为你的新宠。这个实用优先的CSS框架彻底改变了我们编写样式的方式——不再需要…...