【愚公系列】《Python网络爬虫从入门到精通》001-初识网络爬虫
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
文章目录
- 🚀前言
- 🚀一、网络爬虫详细概述
- 🔎 1. 网络爬虫概述
- 🔎 2. 网络爬虫的分类
- 🦋2.1 通用网络爬虫
- 🦋2.2 聚焦网络爬虫
- 🦋2.3 增量式网络爬虫
- 🔎 3. 网络爬虫的基本原理
- 🚀二、搭建开发环境
- 🔎1.安装Anaconda
- 🔎2.PyCharm 的下载与安装
- 🔎3.配置 PyCharm
- 🔎4.测试 PyCharm
🚀前言
随着互联网的快速发展,数据的获取与处理变得愈发重要。在这个信息爆炸的时代,如何有效地收集和利用网络上的海量数据,成为了各行业面临的一大挑战。网络爬虫,作为一种自动化获取网页信息的技术,正逐渐成为数据分析、市场研究、竞争对手监控等领域不可或缺的工具。
本文将带领读者初步了解网络爬虫的基本概念、工作原理以及常见应用场景。我们将探讨爬虫的构建过程,包括如何发送请求、解析网页、存储数据等关键步骤。同时,还会涉及一些爬虫开发中的注意事项,如如何遵循网站的robots.txt协议、避免被封禁等。
🚀一、网络爬虫详细概述
在这个大数据的时代里,网络信息量变得越来越大、越来越多,此时如果通过人工的方式筛选自己所感兴趣的信息是一件很麻烦的事情,爬虫技术便可以自动高效地获取互联网中的指定信息,因此网络爬虫在互联网中的地位变得越来越重要。
🔎 1. 网络爬虫概述
网络爬虫(又被称为网络蜘蛛、网络机器人,在某些社区中经常被称为网页追逐者),是一种按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中信息的程序。通过Python,可以很轻松地编写爬虫程序或脚本。
在生活中,网络爬虫非常常见,搜索引擎的工作离不开网络爬虫。例如,百度搜索引擎的爬虫名字叫作百度蜘蛛(Baiduspider)。百度蜘蛛是百度搜索引擎的一个自动程序,它每天都会在海量的互联网信息中进行爬取,收集并整理互联网上的网页、图片、视频等信息。然后当用户在百度搜索引擎中输入关键词时,百度会从收集的网络信息中找出相关内容,并按照一定顺序将信息展现给用户。
百度蜘蛛的工作过程中,搜索引擎会构建一个调度程序来调度百度蜘蛛的工作,这些调度程序使用一定的算法来实现。采用不同的算法,爬虫的工作效率和爬取结果会有所不同。因此,在学习爬虫时,不仅需要了解爬虫的实现过程,还需要了解一些常见的爬虫算法。在特定情况下,开发者还需要自己制定相应的算法。
🔎 2. 网络爬虫的分类
网络爬虫可以按照实现的技术和结构分为通用网络爬虫、聚焦网络爬虫和增量式网络爬虫。在实际的网络爬虫应用中,通常是这几类爬虫的组合。下面分别介绍这几类网络爬虫。
🦋2.1 通用网络爬虫
通用网络爬虫又叫作全网爬虫(Scalable Web Crawler),其爬行范围和数量巨大。由于爬取的数据是海量数据,因此对爬行速度和存储空间要求较高。通用网络爬虫在爬行页面的顺序要求上相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,因此需要较长时间才可以刷新一次页面。这种网络爬虫主要应用于大型搜索引擎,有着非常高的应用价值。通用网络爬虫主要由以下部分构成:
- 初始URL集合
- URL队列
- 页面爬行模块
- 页面分析模块
- 页面数据库
- 链接过滤模块
🦋2.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler),也叫主题网络爬虫(Topical Crawler),是指按照预先定义好的主题,有选择地进行相关网页爬取的一种爬虫。与通用网络爬虫相比,聚焦网络爬虫不会将目标资源定位在整个互联网中,而是将目标网页定位在与主题相关的页面中。这种爬虫极大地节省了硬件和网络资源,保存的页面数量较少,速度也更快。聚焦网络爬虫主要应用于对特定信息的爬取,为某一类特定的人群提供服务。
🦋2.3 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),对应增量式更新。增量式更新指的是在更新时只更新变化的部分,而未改变的部分则不更新。因此,增量式网络爬虫在爬取网页时,只会爬行新产生或发生更新的页面,对于没有发生变化的页面则不会爬取。这样可以有效减少数据下载量,减小时间和空间上的消耗,但在爬行算法上增加了一些难度。
🔎 3. 网络爬虫的基本原理

网络爬虫的基本工作流程如下:
- 获取初始的URL,该URL地址是用户自己制定的初始爬取的网页。
- 爬取对应URL地址的网页时,获取新的URL地址。
- 将新的URL地址放入URL队列。
- 从URL队列中读取新的URL,然后依据新的URL爬取网页,同时从新的网页中获取新的URL地址,重复上述爬取过程。
- 设置停止条件。如果没有设置停止条件,爬虫会一直爬取下去,直到无法获取新的URL地址或者达到停止条件后,爬虫将会停止爬取。
🚀二、搭建开发环境
🔎1.安装Anaconda
Anaconda 是一个完全免费的用于大规模数据处理、预测分析和科学计算的工具,不仅集成了 Python 解析器,还包含许多第三方模块,如 requests 模块、Beautiful Soup 模块、lxml 模块等,适合网络爬虫的开发。
-
打开浏览器,访问 Anaconda 官方下载页面。
-
下载适用于 Windows 系统的安装文件(选择 64-Bit Graphical Installer)。如图 1.2 所示。

-
下载完成后,双击运行下载的安装文件。在出现的 “Welcome to Anaconda3” 窗口中,单击 Next 按钮。如图 1.3 所示。

-
在 “License Agreement” 窗口中,单击 I Agree 按钮。如图 1.4 所示。

-
在 “Select Installation Type” 窗口中,选择 “All Users (requires admin privileges)”,然后单击 Next 按钮。如图 1.5 所示。

-
在 “Choose Install Location” 窗口中,选择安装路径(建议不要使用中文路径),然后单击 Next 按钮。如图 1.6 所示。

-
在 “Advanced Installation Options” 窗口中,选中 “Add Anaconda to the system PATH environment variable” 复选框,然后单击 Install 按钮进行安装。如图 1.7 所示。

安装过程较长,请耐心等待。安装进度如图 1.8 所示。

-
安装完成后,进入 “Installation Complete” 窗口,单击 Next 按钮。如图 1.9 所示。

-
在 “Anaconda 与 JetBrains 合作关系推荐使用 PyCharm” 窗口中,单击 Next 按钮。如图 1.10 所示。

-
在 “Thanks for installing Anaconda3!” 窗口中,根据个人需求选择复选框(笔者选择取消),然后单击 Finish 按钮。如图 1.11 所示。

-
打开命令提示符窗口,输入
conda list并按 Enter 键,查看已安装的模块列表。如图所示。

🔎2.PyCharm 的下载与安装
PyCharm 是由 JetBrains 公司开发的 Python 集成开发环境,具有智能代码编辑、自动代码格式化、代码完成、智能提示、重构、单元测试、自动导入和一键代码导航等功能。
-
打开 PyCharm 官方下载页面。
-
选择 Windows 平台,下载 PyCharm Community 版。如图 1.13 所示。

-
双击 PyCharm 安装包进行安装。在欢迎界面,单击 Next 按钮,如图 1.14 所示。

-
在 “Choose Install Location” 窗口中选择安装路径(不建议设置在默认的 C 盘),单击 Next 按钮。如图 1.15 所示。

-
在 “Installation Options” 窗口中,设置桌面快捷方式(选择 64-bit launcher),关联文件(选中
.py复选框),单击 Next 按钮。如图 1.16 所示。

-
在 “Choose Start Menu Folder” 窗口中,单击 Install 按钮进行安装。如图 1.17 所示。

-
安装完成后,在 “Completing PyCharm Community Edition Setup” 窗口中,单击 Finish 按钮。如图 1.18 所示。

🔎3.配置 PyCharm
-
双击 PyCharm 桌面快捷方式启动 PyCharm 程序。选择是否导入配置文件(选择不导入),单击 OK 按钮。进入阅读协议页,如图 1.19 所示。

-
在 “Set UI theme” 窗口中,根据个人需求选择主题样式(选择 Light),单击 Next: Featured plugins 按钮。如图 1.20 所示。

-
在 “Download featured plugins” 窗口中,直接单击 “Start using PyCharm” 按钮,进入欢迎界面。如图 1.21 所示。

-
在欢迎页,单击 “Create New Project” 创建新工程文件。如图 1.22 所示。

-
在 “New Project” 窗口中,选择工程文件保存路径,然后单击 Create 按钮。如图 1.23 所示。

-
工程创建完成后,关闭 “Tip of the Day” 窗口,选择
File->Settings选项。如图 1.24 所示。

-
在 “Settings” 窗口中,选择
Project: demo->Project Interpreter,在右侧的下拉列表中选择 “Show All…”,打开 “Project Interpreters” 窗口。如图 1.25 所示。

-
在 “Project Interpreters” 窗口中,单击右侧的 “+” 按钮。如图 1.26 所示。

-
在 “Add Python Interpreter” 窗口中,选择左侧的 “System Interpreter” 选项,然后在右侧的下拉列表中选择 Anaconda 中的
python.exe,单击 OK 按钮。如图 1.27 所示。

-
返回 “Project Interpreters” 窗口,选择新添加的 Anaconda 中的
python.exe编译器,单击 OK 按钮。如图 1.28 所示。

-
返回 “Settings” 窗口,此时将自动显示 Anaconda 内已安装的所有 Python 模块,单击 OK 按钮。如图 1.29 所示。

🔎4.测试 PyCharm
-
右击新建好的 demo 项目,在弹出的快捷菜单中选择
New->Python file命令(必须选择 Python file 项,这个至关重要),如图 1.30 所示。

-
在新建文件对话框中输入文件名
hello_world,按 Enter 键完成新建 Python 文件工作。如图 1.31 所示。

-
在代码编辑区输入代码:
print("hello world!")如图 1.32 所示。

-
右击代码编辑区,在弹出的快捷菜单中选择
Run 'hello_world'命令,运行测试代码。如图 1.33 所示。

-
如果程序代码没有错误,将显示运行结果,如图 1.34 所示。

相关文章:
【愚公系列】《Python网络爬虫从入门到精通》001-初识网络爬虫
标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主&…...

【linux学习指南】模拟线程封装与智能指针shared_ptr
文章目录 📝线程封装🌉 Thread.hpp🌉 Makefile 🌠线程封装第一版🌉 Makefile:🌉Main.cc🌉 Thread.hpp: 🌠线程封装第二版🌉 Thread.hpp:🌉 Main.cc …...

10、Python面试题解析:解释reduce函数的工作原理
reduce 是 Python 中的一个高阶函数,位于 functools 模块中。它的作用是将一个可迭代对象(如列表、元组等)中的元素依次通过一个二元函数(即接受两个参数的函数)进行累积计算,最终返回一个单一的结果。 1.…...

【含开题报告+文档+PPT+源码】学术研究合作与科研项目管理应用的J2EE实施
开题报告 本研究构建了一套集注册登录、信息获取与科研项目管理于一体的综合型学术研究合作平台。系统用户通过注册登录后,能够便捷地接收到最新的系统公告和科研动态新闻,并能进一步点击查看详尽的新闻内容。在科研项目管理方面,系统提供强…...

MySQL主从复制过程,延迟高,解决应对策略
MySQL主从复制延迟高是常见的性能问题,通常由主库写入压力大、从库处理能力不足或配置不当导致。以下从原因定位、优化策略和高级解决方案三个维度提供系统性解决方法: 一、快速定位延迟原因 1. 查看主从同步状态 SHOW SLAVE STATUS\G关键字段…...

Deepseek模拟阿里面试——数据库
在模拟阿里面试时,数据库部分需要涵盖广泛的知识点,包括基础概念、事务管理、索引优化、数据库设计、高并发处理、分布式数据库等。以下是对这些问题的详细分析和解答: 事务的ACID特性是什么,如何保证? ACID特性&…...

大数据学习之SparkStreaming、PB级百战出行网约车项目一
一.SparkStreaming 163.SparkStreaming概述 Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Spark Streaming 是核心 Spark API 的扩展,支持实时数据…...

Java 高频面试闯关秘籍
目录 Java基础篇:涵盖OOP、多线程、集合等基础知识。Java高级篇:深入探讨HashMap、JVM、线程池等高级特性。Java框架篇:介绍Spring、SpringMVC、MyBatis等常用框架。Mysql数据库篇:包含SQL语句、事务、索引等数据库知识。分布式技…...

边缘计算网关驱动智慧煤矿智能升级——实时预警、低延时决策与数字孪生护航矿山安全高效运营
迈向智能化煤矿管理新时代 工业物联网和边缘计算技术的迅猛发展,煤矿安全生产与高效运营正迎来全新变革。传统煤矿监控模式由于现场环境复杂、数据采集和传输延时较高,已难以满足当下高标准的安全管理要求。为此,借助边缘计算网关的实时数据…...
学习计划书)
Oracle认证大师(OCM)学习计划书
Oracle认证大师(OCM)学习计划书 一、学习目标 Oracle Certified Master(OCM)是Oracle官方认证体系中的最高级别认证,要求考生具备扎实的数据库管理技能、丰富的实战经验以及解决复杂问题的能力。本计划旨在通过系统化的…...

力扣 单词拆分
动态规划,字符串截取,可重复用,集合类。 题目 单词可以重复使用,一个单词可用多次,应该是比较灵活的组合形式了,可以想到用dp,遍历完单词后的状态的返回值。而这里的wordDict给出的是list&…...

如何在Linux中设置定时任务(cron)
在Linux系统中,定时任务是自动执行任务的一种非常方便的方式,常常用于定期备份数据、更新系统或清理日志文件等操作。cron是Linux下最常用的定时任务管理工具,它允许用户根据设定的时间间隔自动执行脚本和命令。在本文中,我们将详…...

C# ASP.NET核心特性介绍
.NET学习资料 .NET学习资料 .NET学习资料 在当今的软件开发领域中,C# ASP.NET凭借其强大的功能和丰富的特性,成为构建 Web 应用程序的重要技术之一。以下将详细介绍 C# ASP.NET的核心特性。 多语言支持 ASP.NET 支持多种语言进行开发,这使…...

Response 和 Request 介绍
怀旧网个人博客网站地址:怀旧网,博客详情:Response 和 Request 介绍 1、HttpServletResponse 1、简单分类 2、文件下载 通过Response下载文件数据 放一个文件到resources目录 编写下载文件Servlet文件 public class FileDownServlet exten…...

Spring常用注解和组件
引言 了解Spring常用注解的使用方式可以帮助我们更快速理解这个框架和其中的深度 注解 Configuration:表示该类是一个配置类,用于定义 Spring Bean。 EnableAutoConfiguration:启用 Spring Boot 的自动配置功能,让 Spring Boo…...

Spring中都应用了哪些设计模式?
好的!以下是您提到的八种设计模式在 Spring 中的简单示例: 1. 简单工厂模式 简单工厂模式通过传入参数来决定实例化哪个类。Spring 中的 BeanFactory 就是简单工厂模式的应用。 示例代码: // 1. 创建接口和具体实现类 public interface A…...

VSCode的安裝以及使用
c配置: 【MinGw-w64编译器套件】 https://blog.csdn.net/weixin_60915103/article/details/131617196?fromshareblogdetail&sharetypeblogdetail&sharerId131617196&sharereferPC&sharesourcem0_51662391&sharefromfrom_link Python配置: 【簡單ÿ…...

Datawhale 组队学习 Ollama教程 task1
一、Ollama 简介 比喻:Ollama 就像是一个“魔法箱子”,里面装满了各种大型语言模型(LLM)。你不需要懂复杂的魔法咒语(配置),只需要轻轻一按(一条命令),就能让…...

前端技术学习——ES6核心基础
1、ES6与JavaScript之间的关系 ES6是JavaScript的一个版本:JavaScript是基于ECMAScript规范实现的编程语言,而ES6(ECMAScript 2015)是该规范的一个具体版本。 2、ES6的基础功能 (1)let和const let用于声明…...

《DeepSeek技术应用与赋能运营商办公提效案例实操落地课程》
大模型算法实战专家—周红伟老师 法国科学院数据算法博士/曾任阿里巴巴人工智能专家/曾任马上消费企业风控负责人 课程背景 随着大模型技术的迅猛发展,企业面临着提升工作效率、降低运营成本和优化资源配置的巨大压力。DeepSeek做出十三项革命性的大模型技术突破…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
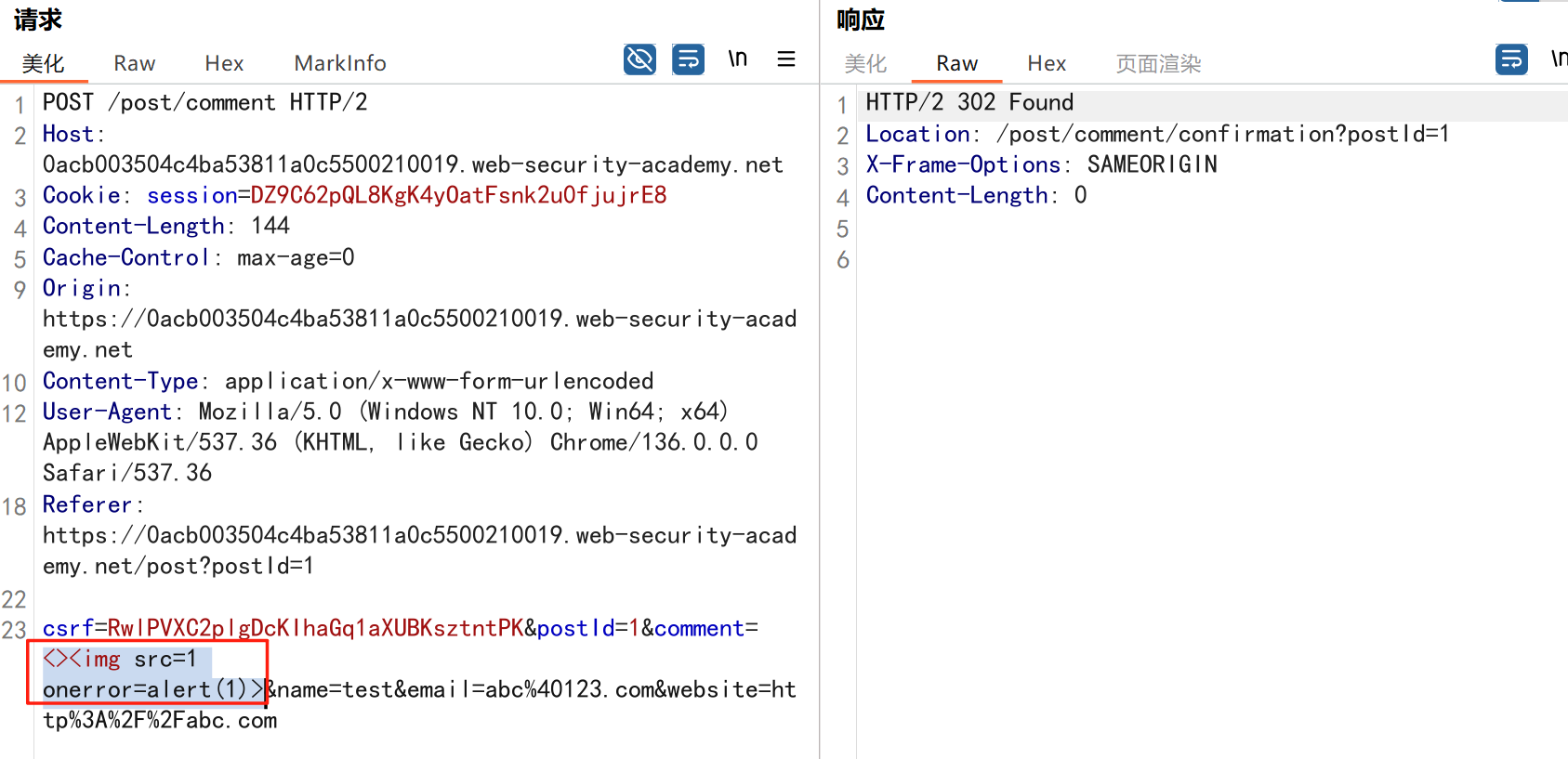
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...