大数据学习之SparkStreaming、PB级百战出行网约车项目一

一.SparkStreaming
163.SparkStreaming概述



164.SparkStreaming_架构

165.SparkStreaming_创建项目


166.SparkStreaming_WORDCOUNT

167.SparkStreaming_数据抽象


168.SparkStreaming_RDD队列创建DSTREAM




169.SparkStreaming_自定义数据源一

170.SparkStreaming_自定义数据源二

171.SparkStreaming_DSTREAM无状态转换

172.SparkStreaming_DSTREAM无状态转换transform


173.SparkStreaming_DSTREAM有状态转换


174.SparkStreaming_窗口操作reducebykeyandwidow概述

175.SparkStreaming_窗口操作reducebykeyandwidow实战



176.SparkStreaming_窗口操作reducebykeyandwidow优化


177.SparkStreaming_窗口操作WINDOW



178.SparkStreaming_输出



179.SparkStreaming_优雅关闭一

180.SparkStreaming_优雅关闭二


181.SparkStreaming_优雅关闭测试

182.SparkStreaming_整合KAFKA模式

183.SparkStreaming_整合kafka开发一

184.SparkStreaming_整合kafka开发二

185.SparkStreaming_整合kafka测试


二.PB级百战出行网约车项目一
1.百战出行
2.百战出行架构设计
3.环境搭建_HBASE安装部署
4.环境搭建_HBASE安装部署
5.环境搭建_MYSQL安装部署
6.环境搭建_REDIS安装部署
7.构建父工程
8.订单监控_收集订单数据
9.订单监控_订单数据分析
10.订单监控_存储数据之读取数据
11.订单监控_存储数据之保持数据至MYSQL
12.订单监控_MAXWELL介绍
13.订单监控_MAXWELL安装
14.订单监控_SPARK_STREAMING整合KAFKA_上
15.订单监控_SPARK_STREAMING整合KAFKA_下
16.订单监控_实时统计订单总数之消费订单数据
17.订单监控_实时统计订单总数之构建订单解析器
18.订单监控_实时统计订单总数之解析订单JSON数据
19.订单监控_实时统计订单总数
20.订单监控_实时统计乘车人数统计
相关文章:
大数据学习之SparkStreaming、PB级百战出行网约车项目一
一.SparkStreaming 163.SparkStreaming概述 Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Spark Streaming 是核心 Spark API 的扩展,支持实时数据…...

Java 高频面试闯关秘籍
目录 Java基础篇:涵盖OOP、多线程、集合等基础知识。Java高级篇:深入探讨HashMap、JVM、线程池等高级特性。Java框架篇:介绍Spring、SpringMVC、MyBatis等常用框架。Mysql数据库篇:包含SQL语句、事务、索引等数据库知识。分布式技…...

边缘计算网关驱动智慧煤矿智能升级——实时预警、低延时决策与数字孪生护航矿山安全高效运营
迈向智能化煤矿管理新时代 工业物联网和边缘计算技术的迅猛发展,煤矿安全生产与高效运营正迎来全新变革。传统煤矿监控模式由于现场环境复杂、数据采集和传输延时较高,已难以满足当下高标准的安全管理要求。为此,借助边缘计算网关的实时数据…...
学习计划书)
Oracle认证大师(OCM)学习计划书
Oracle认证大师(OCM)学习计划书 一、学习目标 Oracle Certified Master(OCM)是Oracle官方认证体系中的最高级别认证,要求考生具备扎实的数据库管理技能、丰富的实战经验以及解决复杂问题的能力。本计划旨在通过系统化的…...

力扣 单词拆分
动态规划,字符串截取,可重复用,集合类。 题目 单词可以重复使用,一个单词可用多次,应该是比较灵活的组合形式了,可以想到用dp,遍历完单词后的状态的返回值。而这里的wordDict给出的是list&…...

如何在Linux中设置定时任务(cron)
在Linux系统中,定时任务是自动执行任务的一种非常方便的方式,常常用于定期备份数据、更新系统或清理日志文件等操作。cron是Linux下最常用的定时任务管理工具,它允许用户根据设定的时间间隔自动执行脚本和命令。在本文中,我们将详…...

C# ASP.NET核心特性介绍
.NET学习资料 .NET学习资料 .NET学习资料 在当今的软件开发领域中,C# ASP.NET凭借其强大的功能和丰富的特性,成为构建 Web 应用程序的重要技术之一。以下将详细介绍 C# ASP.NET的核心特性。 多语言支持 ASP.NET 支持多种语言进行开发,这使…...

Response 和 Request 介绍
怀旧网个人博客网站地址:怀旧网,博客详情:Response 和 Request 介绍 1、HttpServletResponse 1、简单分类 2、文件下载 通过Response下载文件数据 放一个文件到resources目录 编写下载文件Servlet文件 public class FileDownServlet exten…...

Spring常用注解和组件
引言 了解Spring常用注解的使用方式可以帮助我们更快速理解这个框架和其中的深度 注解 Configuration:表示该类是一个配置类,用于定义 Spring Bean。 EnableAutoConfiguration:启用 Spring Boot 的自动配置功能,让 Spring Boo…...

Spring中都应用了哪些设计模式?
好的!以下是您提到的八种设计模式在 Spring 中的简单示例: 1. 简单工厂模式 简单工厂模式通过传入参数来决定实例化哪个类。Spring 中的 BeanFactory 就是简单工厂模式的应用。 示例代码: // 1. 创建接口和具体实现类 public interface A…...

VSCode的安裝以及使用
c配置: 【MinGw-w64编译器套件】 https://blog.csdn.net/weixin_60915103/article/details/131617196?fromshareblogdetail&sharetypeblogdetail&sharerId131617196&sharereferPC&sharesourcem0_51662391&sharefromfrom_link Python配置: 【簡單ÿ…...

Datawhale 组队学习 Ollama教程 task1
一、Ollama 简介 比喻:Ollama 就像是一个“魔法箱子”,里面装满了各种大型语言模型(LLM)。你不需要懂复杂的魔法咒语(配置),只需要轻轻一按(一条命令),就能让…...

前端技术学习——ES6核心基础
1、ES6与JavaScript之间的关系 ES6是JavaScript的一个版本:JavaScript是基于ECMAScript规范实现的编程语言,而ES6(ECMAScript 2015)是该规范的一个具体版本。 2、ES6的基础功能 (1)let和const let用于声明…...

《DeepSeek技术应用与赋能运营商办公提效案例实操落地课程》
大模型算法实战专家—周红伟老师 法国科学院数据算法博士/曾任阿里巴巴人工智能专家/曾任马上消费企业风控负责人 课程背景 随着大模型技术的迅猛发展,企业面临着提升工作效率、降低运营成本和优化资源配置的巨大压力。DeepSeek做出十三项革命性的大模型技术突破…...

STM32-知识
一、Cortex-M系列双指针 Cortex-M系列的MSP与PSP有一些重要的区别,双指针是为了保证OS的安全性和稳健性。本质上,区别于用户程序使用PSP,操作系统和异常事件单独使用一个MSP指针的目的,是为了保证栈数据不会被用户程序意外访问或…...
)
线程同步(互斥锁与条件变量)
文章目录 1、为什么要用互斥锁2、互斥锁怎么用3、为什么要用条件变量4、互斥锁和条件变量如何配合使用5、互斥锁和条件变量的常见用法 参考资料:https://blog.csdn.net/m0_53539646/article/details/115509348 1、为什么要用互斥锁 为了使各线程能够有序地访问公共…...
Ubuntu指令学习(个人记录、偶尔更新)
Ubuntu指令学习 0、一点常用指令列表一、Ubuntu下复制与移动,cp/mv二、Ubuntu下echo 与 重定向>,>>三、Ubuntu下chmod,用户权限四、Ubuntu下的tar打包,gzip压缩五、Ubuntu(22.04)下系统语言为中文,切换主目录文件名为英文。六、Ubun…...
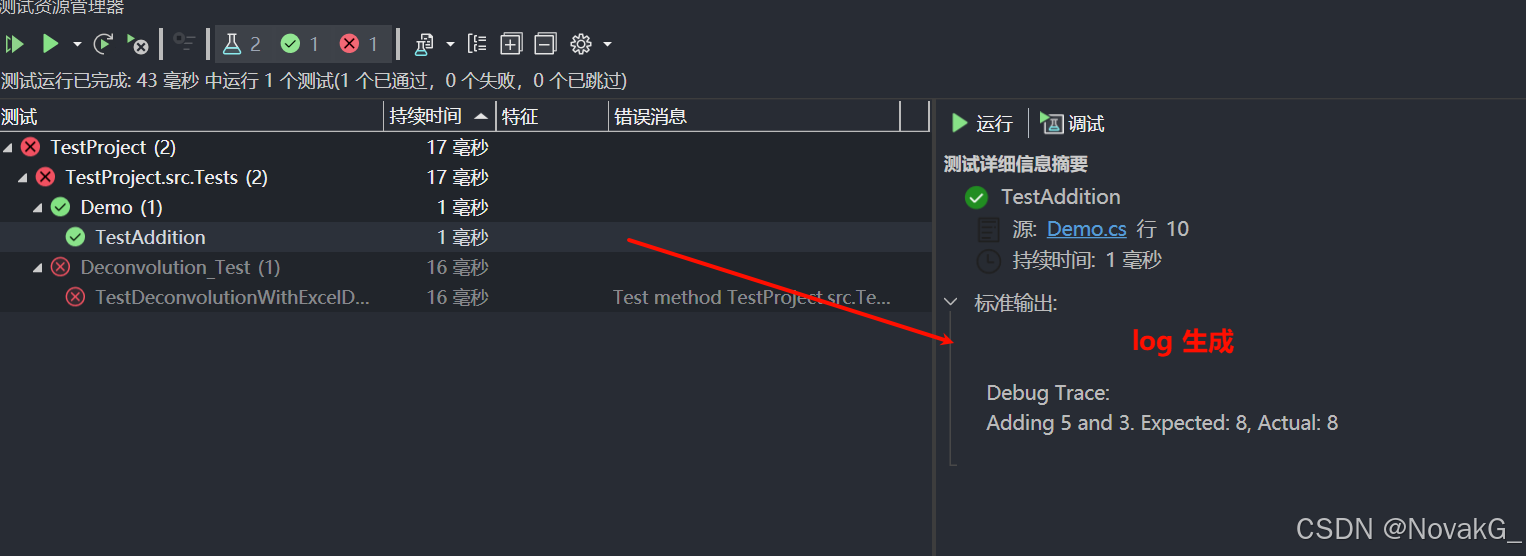
Visual Studio 进行单元测试【入门】
摘要:在软件开发中,单元测试是一种重要的实践,通过验证代码的正确性,帮助开发者提高代码质量。本文将介绍如何在VisualStudio中进行单元测试,包括创建测试项目、编写测试代码、运行测试以及查看结果。 1. 什么是单元测…...

【经验分享】Linux 系统安装后内核参数优化
在 Linux 系统安装后,进行内核优化有助于提升系统的性能、稳定性和安全性。以下是一些常见的内核优化操作: 修改/etc/sysctl.conf 文件 执行sysctl -p使配置生效。 kernel.shmmax 135185569792 kernel.shmall 4294967296 fs.aio-max-nr 3145728 fs.fi…...

linux统计文件夹下有多少个.rst文件行数小于4行
您可以使用 find 命令结合 wc 命令来统计文件夹下 .rst 文件行数小于 4 行的文件数量。以下是一个具体的命令示例: find /path/to/directory -name "*.rst" -type f -exec wc -l {} | awk $1 < 4 | wc -l解释: find /path/to/directory …...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...