flink cdc2.2.1同步postgresql表
目录
- 简要说明
- 前置条件
- maven依赖
- 样例代码
简要说明
在flink1.14.4 和 flink cdc2.2.1下,采用flink sql方式,postgresql同步表数据,本文采用的是上传jar包,利用flink REST api的方式进行sql执行。
前置条件
1.开启logical
确保你的 postgresql.conf 文件中的相关设置允许逻辑复制和插件的使用。特别是下面几个配置项:
wal_level 应该设置为 logical。
max_replication_slots 需要大于0。
配置文件修改完毕后,重启 PostgreSQL 服务
SHOW wal_level; 命令查看日志等级是否修改
2.创建逻辑复制槽
SELECT * FROM pg_create_logical_replication_slot(‘flink_slot’, ‘pgoutput’);
flink_slot 为槽名
pgoutput 是从PostgreSQL 10开始提供的一个内置输出插件,用于逻辑解码
验证逻辑复制槽:SELECT * FROM pg_replication_slots;
查询逻辑复制状态:SELECT * FROM pg_stat_replication;
3.更改复制标识包含更新和删除之前值(目的是为了确保表 xxxx(tableName) 在实时同步过程中能够正确地捕获并同步更新和删除的数据变化。如果不执行这两条语句,那么 xxxx 表可能无法实时同步时丢失更新和删除的数据行信息,从而影响同步的准确性)
ALTER TABLE xxxx REPLICA IDENTITY FULL;
4.修改类加载机制
在flink的flink-conf.yaml文件,classloader.resolve-order: child-first,将 child-first 改为 parent-first
maven依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.4</flink.version><flink-cdc.version>2.2.1</flink-cdc.version><scala.binary.version>2.12</scala.binary.version></properties>
<dependencies><!-- flink --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>1.14.4</version><!--<scope>provided</scope>--></dependency><!-- flink cdc --><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-mysql-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-oracle-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-postgres-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-sqlserver-cdc</artifactId><version>${flink-cdc.version}</version></dependency><!-- database driver --><!-- postgresql --><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.5</version></dependency><!-- json --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.9.9.3</version></dependency><!-- lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency><!-- log --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><!-- junit --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency>
样例代码
sql:
CREATE TABLE `new_table1_37877` (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'debezium.database.tablename.case.insensitive'='false',
'debezium.log.mining.continuous.mine'='true',
'password'='*****',
'hostname'='***.**.**.***',
'debezium.log.mining.strategy'='online_catalog',
'connector'='postgres-cdc',
'port'='5432',
'schema-name'='public',
'database-name'='test',
'table-name'='new_table1',
'username'='******',
'slot.name'='flink_slot',
'decoding.plugin.name'='pgoutput'
);
CREATE TABLE `new_table1_bak_37877` (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'password'='*****',
'connector'='jdbc',
'table-name'='public.new_table1_bak',
'url'='jdbc:postgresql://地址:5432/test',
'username'='用户'
);
insert into new_table1_bak_37877 select * from new_table1_37877;
参数类:
@Data
public class InputOutputParams {/*** 作业名称*/private String jobName;/*** 代码文本,分号分隔的flink sql语句*/private String codeText;}
main方法:
public class FlinkMain {/*** flink job 运行入口** @param args 运行参数*/public static void main(String[] args) throws IOException {if (args == null || args.length == 0) {throw new RuntimeException("运行参数为空");}// 取第一个参数(必须是json字符串)为运行参数String json = args[0];ObjectMapper objectMapper =new ObjectMapper().configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);InputOutputParams params = objectMapper.readValue(json, InputOutputParams.class);// 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 开启快照点,每 3 * 60秒保存一次快照env.enableCheckpointing(3 * 60 * 1000L);//检查点可容忍失败阈值env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);//检查点超时时间env.getCheckpointConfig().setCheckpointTimeout(10 * 60 * 1000);// 同一时间只允许一个 checkpoint 进行env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 开启在 job 中止后仍然保留的 externalized checkpointsenv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 重启策略,最多尝试重启3次,每次重启的时间间隔为20秒env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(20L, TimeUnit.SECONDS)));env.setParallelism(1);EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();// 获取表执行环境StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);tEnv.getConfig().getConfiguration().setString("pipeline.name", params.getJobName());// 执行操作sqlString codeText = params.getCodeText();if (codeText == null || codeText.trim().isEmpty()) {throw new RuntimeException("flink sql is empty");}String[] flinkSqlArr = codeText.split(";");for (String flinkSql : flinkSqlArr) {if (flinkSql != null && !flinkSql.trim().isEmpty()) {tEnv.executeSql(flinkSql);}}}
}将项目打包成不带依赖的jar
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-dependency-plugin</artifactId><version>2.10</version><executions><execution><id>copy-dependencies</id><phase>package</phase><goals><!-- 复制依赖jar包 --><goal>copy-dependencies</goal></goals><configuration><!-- 依赖jar包输出目录 --><outputDirectory>${project.build.directory}/lib</outputDirectory></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><version>2.4</version><configuration><archive><manifest><!-- main方法所在主类 --><mainClass>com.test.FlinkMain</mainClass></manifest></archive></configuration></plugin></plugins></build>
然后将lib下的依赖全部拷贝到flink的lib下,将刚才打包好的jar界面上传

然后通过postman调用flink的REST api接口提交sql,接口文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/rest_api/

相关文章:
flink cdc2.2.1同步postgresql表
目录 简要说明前置条件maven依赖样例代码 简要说明 在flink1.14.4 和 flink cdc2.2.1下,采用flink sql方式,postgresql同步表数据,本文采用的是上传jar包,利用flink REST api的方式进行sql执行。 前置条件 1.开启logical 确保你…...

rebase和merge
rebase 和merge区别: rebase变基,改变基底:rebase会抹去提交记录。 git pull 默认merge,git pull --rebase 变基 rebase C、D提交属于feature分支,是基于master分支,在B提交额外拉出来的,当…...

Spring boot中实现字典管理
数据库脚本 CREATE TABLE data_dict (id bigint NOT NULL COMMENT 主键,dict_code varchar(32) DEFAULT NULL COMMENT 字典编码,dict_name varchar(64) DEFAULT NULL COMMENT 字典名称,dict_description varchar(255) DEFAULT NULL COMMENT 字典描述,dict_status tinyint DEFA…...

调用DeepSeek官方的API接口
效果 前端样式体验链接:https://livequeen.top/deepseekshow 准备工作 1、注册deepseek官网账号 地址:DeepSeek 点击进入右上角【API开放平台】,并进行账号注册。 2、注册完成后,依次点击【API keys】-【生成API key】&#x…...

3.3 学习UVM中的uvm_driver 类分为几步?
文章目录 前言1. 定义2. 核心功能3. 适用场景4. 使用方法5. 完整代码示例5.1 事务类定义5.2 Driver 类定义5.3 Sequencer 类定义5.4 测试平台 6. 代码说明7. 总结 前言 以下是关于 UVM 中 uvm_driver 的详细解释、核心功能、适用场景、使用方法以及一个完整的代码示例ÿ…...

Python——批量图片转PDF(GUI版本)
目录 专栏导读1、背景介绍2、库的安装3、核心代码4、完整代码总结专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系列文章专栏:请点击——>Python办公自动化专…...

科技查新过不了怎么办
“科技查新过不了怎么办?” “科技查新不通过的原因是什么?” 想必这些问题一直困扰着各位科研和学术的朋友们,尤其是对于查新经验不够多的小伙伴,在历经千难万险,从选择查新机构、填写线上委托单到付费,…...
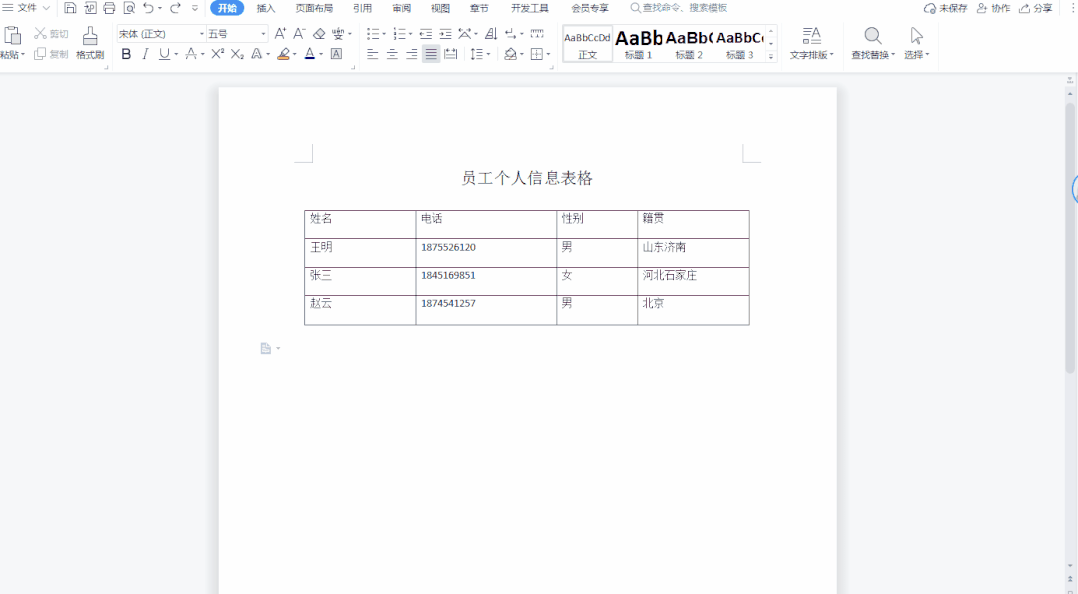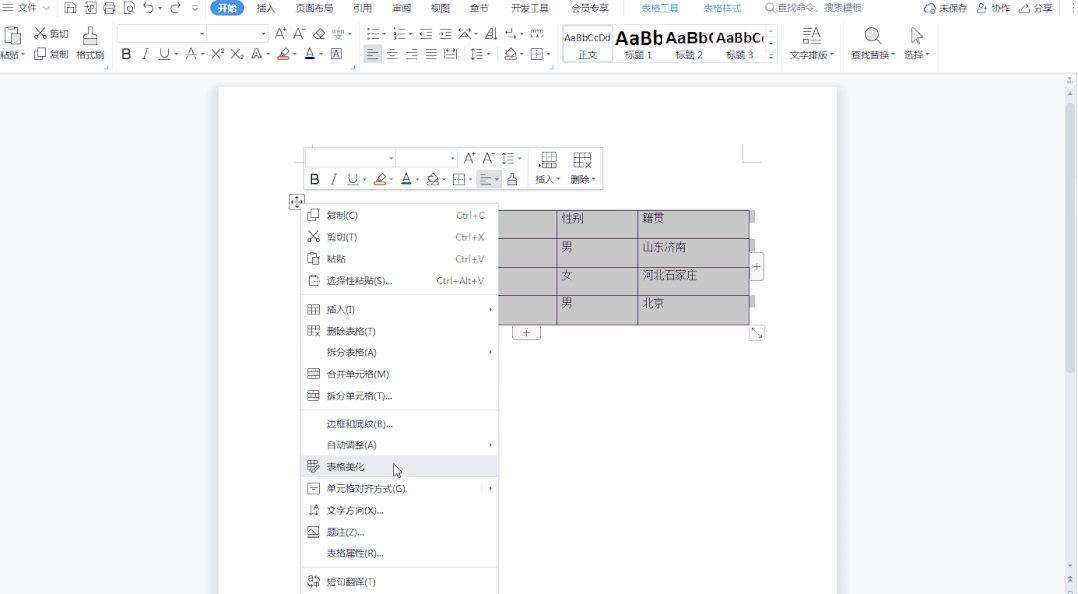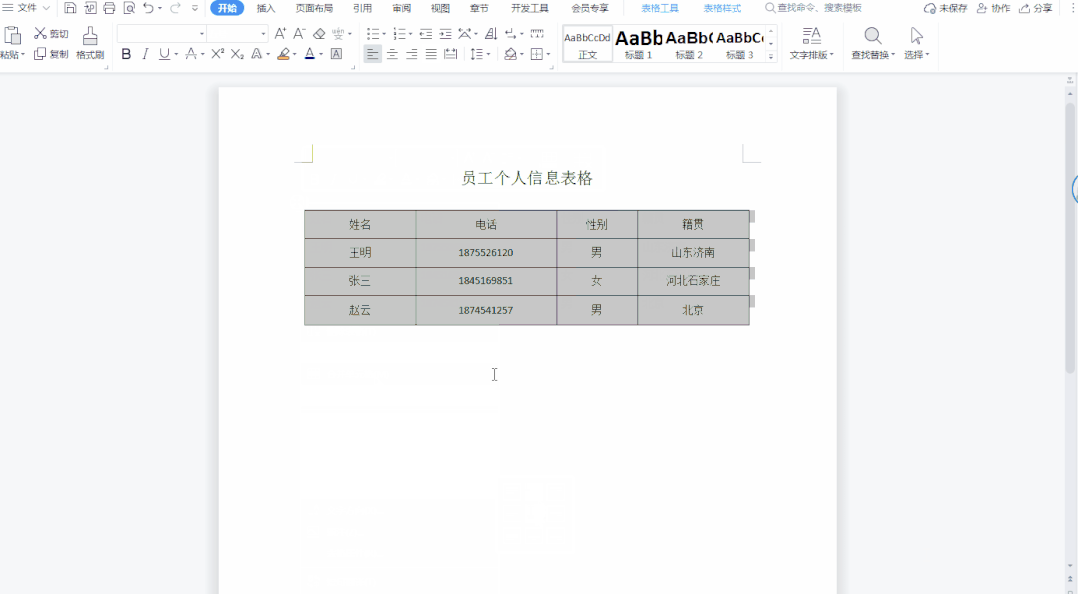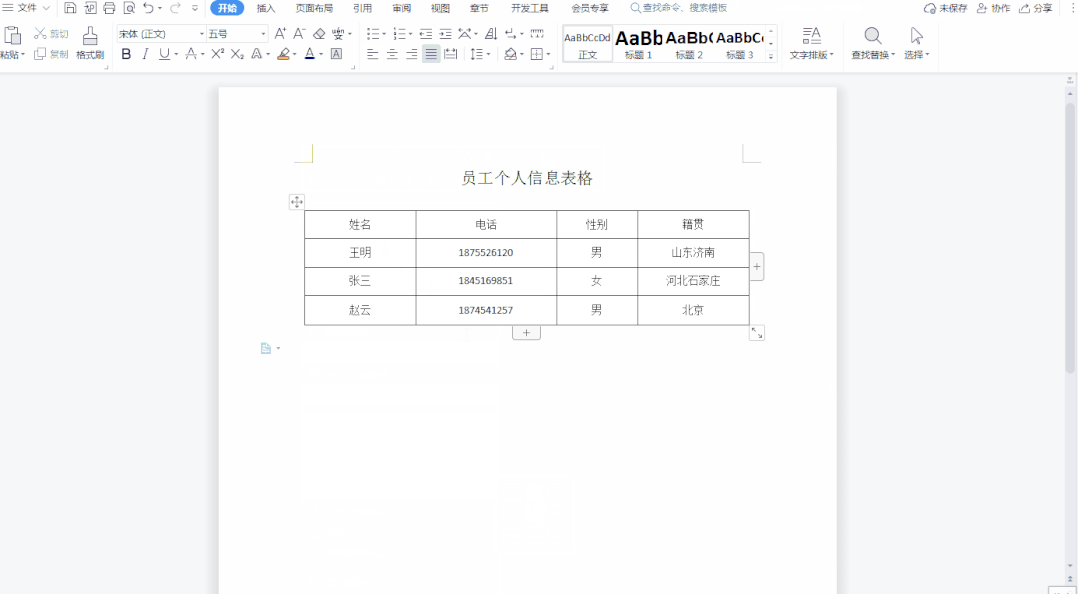
WPS中如何批量上下居中对齐word表格中的所有文字
大家好,我是小鱼。 在日常制作Word表格时,经常需要对表格中的内容进行排版。经常会把文字设置成左对齐、居中对齐或者是右对齐,这些对齐方式都比较好设置,有时制作的表格需要把文字批量上下居中对齐,轻松几步就可以搞…...

【Docker】从瀑布开发到敏捷开发
引言 软件开发方法论是指导团队如何规划、执行和管理软件项目的框架。随着软件行业的不断发展,开发方法论也在不断演进。从传统的瀑布开发到现代的敏捷开发,软件开发方法论经历了深刻的变革。本文将详细探讨瀑布开发和敏捷开发的定义、特点、优缺点以及…...

若依框架二次开发——若依介绍、环境部署及更换项目包路径
文章目录 一、若依介绍1、项目简介2、主要特性3、技术选型4、内置功能5、文件结构6、配置文件7、核心技术介绍二、环境部署1、准备工作2、运行系统3、必要配置4、部署系统三、更换项目包路径1、更换目录名称2、更换顶级目录中的pom.xml3、更换项目所有包名称4、修改application…...

【DeepSeek】在本地计算机上部署DeepSeek-R1大模型实战(完整版)
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT&…...

996引擎-问题处理:三职业改单职业
996引擎-问题处理:三职业改单职业 问题解决方案顺便补充点单性别设置补充:可视化配置表参考资料问题 目前的版本: 引擎版本号:2024.8.7.0 三端配套客户端:3.40.9 传统PC客户端:23.12.07 配套数据库:64_24.8.7.0此版本需要通过可视化配置表...

Redis 发生宕机时,数据怎样恢复?
当 Redis 发生宕机时,数据恢复的核心依赖于其持久化机制和备份策略。以下是结合不同场景的恢复方法及原理: 一、通过持久化机制恢复数据 1. RDB(Redis Database)快照恢复 原理:RDB 通过生成内存数据的全量快照&#…...
)
【02】RUST项目(Cargo)
文章目录 rust项目与编译创建项目检查编译运行各级目录文件作用TODO各文件作用Cargo.tomlCargo.lockRUST项目一些关键字`mod``pub``use` (`as`)`pub use`重导出(re-exporting)`crate``suer`模块系统包 Pcakagescrate模块 Modules 和 usemain.rs的例子`lib.rs`的例子拆分文件为…...

二、通义灵码插件保姆级教学-IDEA(使用篇)
一、IntelliJ IDEA 中使用指南 1.1、代码解释 选择需要解释的代码 —> 右键 —> 通义灵码 —> 解释代码 解释代码很详细,感觉很强大有木有,关键还会生成流程图,对程序员理解业务非常有帮忙,基本能做到哪里不懂点哪里。…...

Docker使用指南与Dockerfile文件详解:从入门到实战
Docker使用指南与Dockerfile文件详解:从入门到实战 文章目录 **Docker使用指南与Dockerfile文件详解:从入门到实战****引言****第一部分:Docker 核心概念速览****1. Docker 基础架构****2. Docker 核心命令****第二部分:Dockerfile 文件深度解析****1. Dockerfile 是什么?…...

前端权限控制和管理
前端权限控制和管理 1.前言2.权限相关概念2.1权限的分类(1)后端权限(2)前端权限 2.2前端权限的意义 3.前端权限控制思路3.1菜单的权限控制3.2界面的权限控制3.3按钮的权限控制3.4接口的权限控制 4.实现步骤4.1菜单栏控制4.2界面的控制(1)路由导航守卫(2)动态路由 4.3按钮的控制…...

网络安全讲座之一:网络安全的重要性
第一讲内容主要对于安全的发展以及其重要性作了简明的阐述,并介绍了一些国内外知名的网络安全相关网站,并对于如何建立有效的安全策略给出了很好的建议,并让大家了解几种安全标准。 媒体经常报道一些有关网络安全威胁的令人震惊的事件&am…...

iOS主要知识点梳理回顾-3-运行时消息机制
运行时(runtime) 运行时是OC的重要特性,也是OC动态性的根本支撑。动态,如果利用好了,扩展性就很强。当然了,OC的动态性只能算是一个一般水平。与swift、java这种强类型校验的语言相比,OC动态性很…...

深度学习中的Checkpoint是什么?
诸神缄默不语-个人CSDN博文目录 文章目录 引言1. 什么是Checkpoint?2. 为什么需要Checkpoint?3. 如何使用Checkpoint?3.1 TensorFlow 中的 Checkpoint3.2 PyTorch 中的 Checkpoint3.3 transformers中的Checkpoint 4. 在 NLP 任务中的应用5. 总…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...