【机器学习】常见采样方法详解
在机器学习领域,数据采样(Sampling)是一项至关重要的技术。它不仅影响模型的训练效率,还直接关系到模型的性能与泛化能力。本文将从基础概念出发,逐步深入介绍机器学习中常见的采样方法,帮助读者全面理解并应用这些技术。
目录
1. 什么是数据采样
2. 简单随机采样
3. 系统采样
4. 分层采样
5. 聚类采样
6. 过采样与欠采样
7. Bootstrapping采样
8. SMOTE及其变种
9. 总结与应用建议
1. 什么是数据采样
数据采样是指从原始数据集中按照一定的方法选择部分数据用于分析或模型训练的过程。在机器学习中,采样主要用于以下几个方面:
- 减小数据规模:处理海量数据时,通过采样减少计算资源消耗。
- 处理数据不平衡:在分类任务中,某些类别样本稀少,通过采样平衡类别分布。
- 提升模型泛化:通过不同的采样策略增强模型的鲁棒性。
- Bootstrapping与集成学习:用在如随机森林等集成模型中,生成多样化的训练集。
理解并正确应用不同的采样方法,是提升机器学习模型性能的关键步骤之一。
2. 简单随机采样
概述
**简单随机采样(Simple Random Sampling)**是一种最基本的采样方法,在这种方法中,每个样本被选中的概率相同,且相互独立。
应用场景
- 数据量适中,计算资源允许时。
- 数据分布均匀,无明显类别不平衡。
优点
- 实现简单,理论基础扎实。
- 在数据分布均匀的情况下,能够有效代表总体。
缺点
- 不适用于数据类别不平衡的情况,可能导致少数类样本进一步稀少。
- 随机性可能导致代表性不足,尤其在小样本情况下。
示例
假设有一个包含1000个样本的数据集,采用简单随机采样方式抽取200个样本用于训练。
import random
data = list(range(1000))
sampled_data = random.sample(data, 200)3. 系统采样
概述
**系统采样(Systematic Sampling)**是一种在预先确定的间隔(k)下,从有序数据集中选取样本的方法。首先随机选择一个起始点,然后每隔k个样本选择一个。
应用场景
- 数据已经按照某种顺序排列,如时间序列数据。
- 希望快速采样,减少计算开销。
优点
- 实现简单,效率高。
- 适用于处理有序数据,如时间序列。
缺点
- 如果数据存在周期性,与采样间隔k有共性的周期,可能导致样本偏差。
- 不如简单随机采样具有较好的随机性。
示例
从一个按时间顺序排列的1000个样本的数据集中,每隔5个样本选取一个,共200个样本。
import random
data = list(range(1000))
k = 5
start = random.randint(0, k-1)
sampled_data = data[start::k]4. 分层采样
概述
**分层采样(Stratified Sampling)**是一种在不同的子群体(层)中分别进行采样的方法,确保每个层都有足够的代表性。常用于处理类别不平衡的数据。
应用场景
- 数据集存在明显的类别或群体划分。
- 需要确保各类别样本比例的代表性。
优点
- 能有效处理类别不平衡问题。
- 每个层内的代表性更强,提升模型的泛化能力。
缺点
- 需要预先了解数据的层结构。
- 对层的划分方法敏感,划分不当可能影响采样效果。
示例
在一个二分类数据集中,正负类样本比例为1:9。通过分层采样,确保训练集中两类样本比例与整体数据一致。
from sklearn.model_selection import train_test_split
X = [...] # 特征
y = [...] # 标签
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, stratify=y, random_state=42 )5. 聚类采样
概述
**聚类采样(Cluster Sampling)**将总体划分为若干个集群(Cluster),然后随机选择部分集群中的全部样本作为样本集。这种方法适用于总体较大且分布分散的情况。
应用场景
- 数据分布具有明显的聚类特性,如地理数据。
- 采样成本较高,选择部分集群能够降低开销。
优点
- 采样效率高,减少计算资源消耗。
- 易于实施,尤其在地理等空间数据中应用广泛。
缺点
- 如果集群内部异质性大,可能导致样本代表性不足。
- 需要合理划分集群,避免样本偏差。
示例
假设有多个地区的数据,通过聚类采样选择部分地区的数据进行训练。
from sklearn.cluster import KMeans
import numpy as np
data = np.array([...]) # 特征
kmeans = KMeans(n_clusters=10, random_state=42).fit(data)
clusters = kmeans.labels_ selected_clusters = random.sample(range(10), 3)
sampled_data = data[np.isin(clusters, selected_clusters)]6. 过采样与欠采样
在处理类别不平衡的数据集时,常采用过采样(Oversampling)和欠采样(Undersampling)方法来平衡各类别的样本数量。
6.1 欠采样(Undersampling)
欠采样通过减少多数类样本数量,使其与少数类样本数量接近。
优点
- 简单易行,减少计算开销。
- 可能提高模型对少数类的敏感度。
缺点
- 可能丢失有用的多数类信息,导致模型性能下降。
- 对于原本数据量较少的少数类,可能过于稀缺。
示例
在一个二分类数据集中,通过随机删除多数类样本,达到类别平衡。
from imblearn.under_sampling
import RandomUnderSampler
rus = RandomUnderSampler(random_state=42)
X_res, y_res = rus.fit_resample(X, y)6.2 过采样(Oversampling)
过采样通过增加少数类样本数量,使其与多数类样本数量接近。常见方法包括复制现有少数类样本或生成合成样本。
优点
- 保留多数类全部信息,避免信息丢失。
- 通过合成样本提高模型对少数类的识别能力。
缺点
- 简单复制可能导致过拟合。
- 合成样本方法(如SMOTE)复杂度较高。
示例
通过随机复制少数类样本,实现类别平衡。
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=42)
X_res, y_res = ros.fit_resample(X, y)7. Bootstrapping采样
概述
Bootstrapping是一种自助采样方法,通过有放回地从原始数据集中随机抽取样本,生成多个不同的训练集。这种方法广泛应用于统计推断和集成学习中,如随机森林。
应用场景
- 估计模型的稳定性与泛化能力。
- 集成学习中的基学习器训练。
优点
- 增强模型的泛化能力,减少过拟合。
- 易于并行化,实现高效训练。
缺点
- 可能引入重复样本,增加计算冗余。
- 对原始数据分布的依赖较强,样本多样性有限。
示例
在随机森林中,每棵决策树通过Bootstrapping采样生成不同的训练集。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, bootstrap=True, random_state=42)
rf.fit(X, y)8. SMOTE及其变种
8.1 介绍
**SMOTE(Synthetic Minority Over-sampling Technique)**是一种通过插值生成少数类合成样本的过采样方法。它通过在特征空间中对少数类样本进行插值,生成新的合成样本,缓解类别不平衡问题。
8.2 优点
- 生成的合成样本更加多样化,减少过拟合风险。
- 能有效提升模型对少数类的识别能力。
8.3 缺点
- 可能在边界区域生成噪声样本,影响模型性能。
- 对高维数据效果不佳,计算复杂度较高。
8.4 示例
使用SMOTE生成合成少数类样本。
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_res, y_res = smote.fit_resample(X, y)8.5 SMOTE的变种
为了克服SMOTE的一些局限性,研究者提出了多种变种方法,如Borderline-SMOTE、ADASYN等。
- Borderline-SMOTE:仅对边界区域的少数类样本进行过采样,避免在内部区域生成无意义样本。
- ADASYN(Adaptive Synthetic Sampling):根据困难度自动调整某些少数类样本的过采样力度,注重生成难以分类的样本。
示例:使用Borderline-SMOTE
from imblearn.over_sampling import BorderlineSMOTE
bsmote = BorderlineSMOTE(random_state=42)
X_res, y_res = bsmote.fit_resample(X, y)9. 总结与应用建议
在机器学习中,数据采样方法的选择对模型性能具有重要影响。以下是一些应用建议:
- 了解数据分布:在选择采样方法前,需深入了解数据的分布特征,如类别比例、样本数量等。
- 平衡与代表性的权衡:过采样和欠采样方法需要在平衡类别和保持数据代表性之间找到合适的平衡点。
- 多尝试不同方法:不同采样方法适用于不同场景,多尝试并交叉验证可找到最佳方案。
- 结合集成学习:如Bootstrapping与随机森林等结合,提升模型稳定性与泛化能力。
- 注意过拟合:特别是在过采样方法中,需警惕合成样本导致的过拟合问题,通过正则化等手段加以缓解。
相关文章:

【机器学习】常见采样方法详解
在机器学习领域,数据采样(Sampling)是一项至关重要的技术。它不仅影响模型的训练效率,还直接关系到模型的性能与泛化能力。本文将从基础概念出发,逐步深入介绍机器学习中常见的采样方法,帮助读者全面理解并…...

使用瑞芯微RK3588的NPU进行模型转换和推理
使用边缘设备进行算法落地时,通常要考虑模型推理速度,NVIDA系列平台可以使用TensorRT和CUDA加速,瑞芯微RK3588的板子上都是Arm的手机GPU,虽然没有类似CUDA的加速计算方式,但是提供了NPU进行加速推理,本文说…...

Flutter项目试水
1基本介绍 本文章在构建您的第一个 Flutter 应用指导下进行实践 可作为项目实践的辅助参考资料 Flutter 是 Google 的界面工具包,用于通过单一代码库针对移动设备、Web 和桌面设备构建应用。在此 Codelab 中,您将构建以下 Flutter 应用。 该应用可以…...

【算法学习】DFS与BFS
目录 一,深度优先搜索 1,DFS 2,图的DFS遍历 (1),递归实现(隐士栈) (2),显示栈实现(非递归) 二,广度优先搜索 1,BFS 2,图的BF…...

100.16 AI量化面试题:监督学习技术在量化金融中的应用方案
目录 0. 承前1. 解题思路1.1 应用场景维度1.2 技术实现维度1.3 实践应用维度 2. 市场预测模型2.1 趋势预测2.2 模型训练与评估 3. 风险评估模型3.1 信用风险评估 4. 投资组合优化4.1 资产配置模型 5. 回答话术 0. 承前 本文通过通俗易懂的方式介绍监督学习在量化金融中的应用&a…...

基于deepseek api和openweather 天气API实现Function Calling技术讲解
以下是一个结合DeepSeek API和OpenWeather API的完整Function Calling示例,包含意图识别、API调用和结果整合: import requests import json import os# 配置API密钥(从环境变量获取) DEEPSEEK_API_KEY os.getenv("DEEPSEE…...

线性数据结构解密:数组的定义、操作与实际应用
系列文章目录 01-从零开始掌握Python数据结构:提升代码效率的必备技能! 02-算法复杂度全解析:时间与空间复杂度优化秘籍 03-线性数据结构解密:数组的定义、操作与实际应用 文章目录 系列文章目录前言一、数组的定义与特点1.1 数组…...

CentOS搭建PPPOE服务器
一、安装软件包 yum -y install rp-pppoe 二、配置服务器 1.修改配置文件 打开/etc/ppp/pppoe-server-options文件 nano /etc/ppp/pppoe-server-options 编辑为以下内容: # PPP options for the PPPoE server # LIC: GPL require-pap require-chap login …...

【报错】解决 RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE 报错问题
解决 RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE 报错问题 写在最前面问题描述可能的原因分析解决方案该命令的作用 结论 写在最前面 在多用户使用的服务器上,导致的环境变量的冲突和不匹配问题, 代码没有问题,但程序运行异常。…...

【C语言】C语言 文具店商品库存管理系统(源码+数据文件)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。 系列文章目录 目录 系列文章目录一、设计要求1. 项…...

LangChain系列: 使用工具和工具包构建代理实战教程
让我们在LangChain中构建简单代理示例,以帮助我们理解代理的基本概念和构建块。通过保持简单,我们可以更好地掌握这些代理背后的基本思想,使我们能够在未来构建更复杂的代理。 什么是代理 LangChain官方文档有非常好的章节来介绍其代理的高级…...
)
布隆过滤器(简单介绍)
布隆过滤器(Bloom Filter) 是一种高效的概率型数据结构,用于快速判断一个元素是否可能存在于某个集合中。它的核心特点是空间效率极高,但存在一定的误判率(可能误报存在,但不会漏报)。 核心原理…...

C++ 利器:inline 与 nullptr
探秘 C 利器:inline 与 nullptr 引言 在 C 的浩瀚海洋中,有着许多实用且强大的特性,它们如同夜空中闪烁的繁星,照亮了开发者前行的道路。今天,我们要深入探索其中两颗耀眼的星星:inline 关键字和 nullptr …...

给一个单体项目加装Feign
1.导入pom坐标 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId><version>4.1.2</version> </dependency> 2.主函数注解 EnableFeignClients public cl…...

可以使用Deepseek R1模型的平台集锦
最近Deepseek掀起了AI浪潮,就在今天百度文心一言和ChatGPT宣布要在近期实施免费开放,日渐减少的用户。Deepseek这么火爆,其官网却一直遭受攻击,访问速度很慢。自己本地部署,又负担不起硬件费用,相比之下&am…...
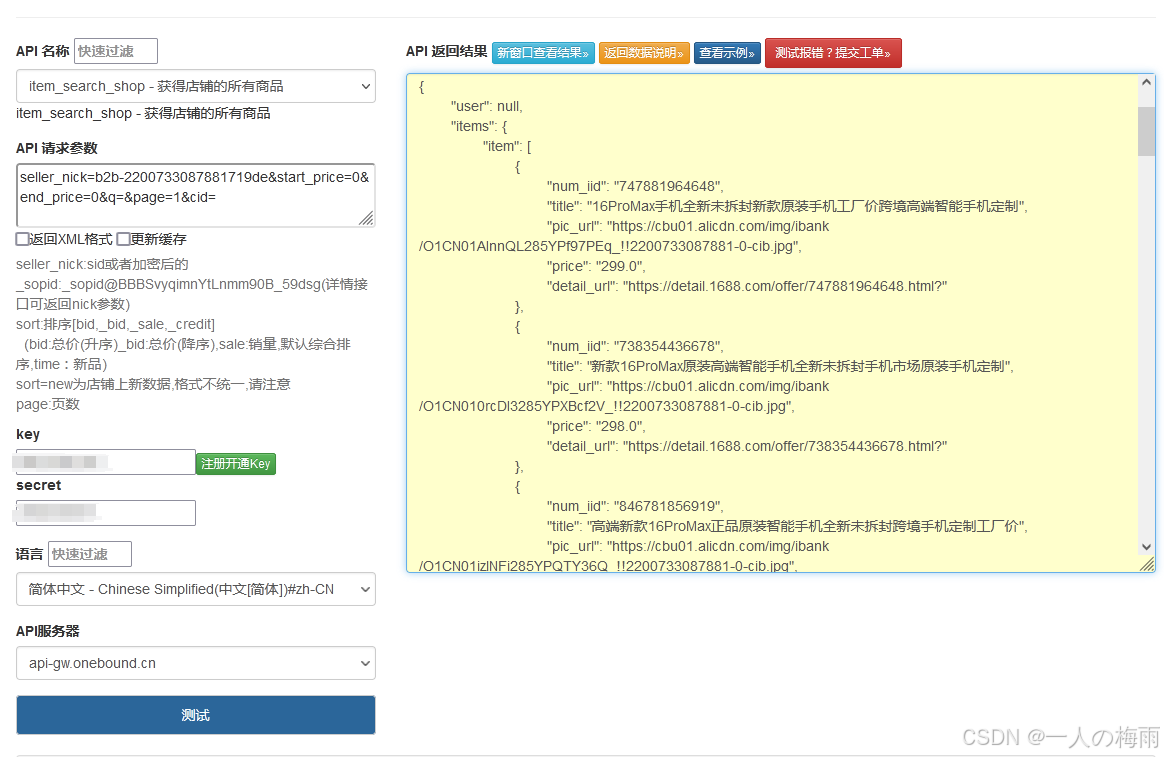
“探索1688平台:高效获取店铺商品信息的实用指南“
在电商领域,获取店铺所有商品信息对于商家进行数据分析、库存管理、竞品分析等方面具有重要意义。1688平台作为中国领先的B2B电商平台,提供了丰富的API接口供开发者使用,其中就包括获取店铺所有商品信息的接口。本文将详细介绍如何使用该接口…...

在fedora41中安装钉钉dingtalk_7.6.25.4122001_amd64
在Fedora-Workstation-Live-x86_64-41-1.4中安装钉钉dingtalk_7.6.25.4122001_amd64.deb 到官网下载钉钉Linux客户端com.alibabainc.dingtalk_7.6.25.4122001_amd64.deb https://page.dingtalk.com/wow/z/dingtalk/simple/ddhomedownload#/ 一、直接使用dpkg命令安装deb包报错…...

数据结构:图论入门
图论起源于欧拉对哥尼斯堡七桥问题的解决. 他构建的图模型将陆地用点来表示, 桥梁则用线表示, 如此一来, 该问题便转化为在图中能否不重复地遍历每条边的问题. 图论的应用 地图着色 在地图着色问题中, 我们用顶点代表国家, 将相邻国家之间用边相连. 这样, 问题就转化为用最少…...

有限状态系统的抽象定义及CEGAR分析解析理论篇
文章目录 一、有限状态系统的抽象定义及相关阐述1、有限状态系统定义2、 有限状态系统间的抽象关系(Abstract)2.1 基于函数的抽象定义2.2 基于等价关系的抽象定义 二、 基于上面的定义出发,提出的思考1. 为什么我们想要/需要进行抽象2. 抽象是…...

Apache Hive用PySpark统计指定表中各字段的空值、空字符串或零值比例
from pyspark.sql import SparkSession from pyspark.sql.functions import col, coalesce, trim, when, lit, sum from pyspark.sql.types import StringType, NumericType# 初始化SparkSession spark SparkSession.builder \.appName("Hive Data Quality Analysis"…...

为ae做片段视频项目配置专属AI模型并控制成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为AE做片段视频项目配置专属AI模型并控制成本 对于小型视频工作室或独立制作人而言,在After Effects等工具中处理大量视…...

macOS桌面歌词终极解决方案:LyricsX 2.0完整指南
macOS桌面歌词终极解决方案:LyricsX 2.0完整指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 你是否曾经在听音乐时,想要跟着歌词一起唱却发现…...

taotoken控制台提供的api调用审计与用量分析功能体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken控制台提供的api调用审计与用量分析功能体验 对于需要统一管理多个大模型API调用的团队而言,清晰掌握调用情况…...

企业级长文档AI落地避坑指南,从PDF解析失真到语义断裂修复——Claude 2026六大隐性能力详解
更多请点击: https://intelliparadigm.com 第一章:PDF解析失真问题的根源与本质诊断 PDF 文件虽为“便携式文档格式”,但其内部结构高度异构——文本可能嵌入在图形路径中、字体被子集化或完全缺失、字符编码映射断裂,甚至存在跨…...

基于EVE ESI API与AI Agent的自动化游戏监控与数据分析实践
1. 项目概述:为AI助手注入EVE宇宙的灵魂 如果你是一名《EVE Online》的玩家,同时又对AI自动化工具感兴趣,那么你很可能和我一样,长期被一个矛盾所困扰:一方面,EVE这个沙盒宇宙充满了需要监控和管理的日常事…...

Windows内核级虚拟串口驱动com0com:构建无限虚拟COM端口对的终极解决方案
Windows内核级虚拟串口驱动com0com:构建无限虚拟COM端口对的终极解决方案 【免费下载链接】com0com Null-modem emulator - The virtual serial port driver for Windows. Brought to you by: vfrolov [Vyacheslav Frolov](http://sourceforge.net/u/vfrolov/profil…...

微信自动化终极指南:5个强大功能助你高效管理微信数据
微信自动化终极指南:5个强大功能助你高效管理微信数据 【免费下载链接】wechat-toolbox WeChat toolbox(微信工具箱) 项目地址: https://gitcode.com/gh_mirrors/we/wechat-toolbox 还在为繁琐的微信数据管理而烦恼吗?微信…...

深度重构黑苹果系统架构:OpenCore实战解析与性能优化
深度重构黑苹果系统架构:OpenCore实战解析与性能优化 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 在传统PC硬件与macOS系统兼容性的技术探索中…...

高效自动化安装:Windows平台ADB与Fastboot驱动完整配置指南
高效自动化安装:Windows平台ADB与Fastboot驱动完整配置指南 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/…...

Taotoken 官方价折扣与活动价助力个人开发者降低创新门槛
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 官方价折扣与活动价助力个人开发者降低创新门槛 对于个人开发者和学生而言,探索大模型应用的最大挑战之一往往…...