左移架构 -- 从攒批,湖仓到使用数据流的实时数据产品
编辑导读: 这篇文章翻译自 Kai Waehner的 《The Shift Left Architecture – From Batch and Lakehouse to Real-Time Data Products with Data Streaming》。文章通过数据产品的概念引出了如何创建可重复使用的数据产品使企业能够从当前和未来的数据中获得价值。基于构建数据产品发挥数据价值的基本思想,作者提出了利用Apache Kafka 以及 Flink 来构建左移架构,在data pipeline的前端尽早构建优质的数据产品,并且将原始实时数据流通过iceberg格式进行入湖和后续的分析消费。该文充分说明了 Apache Kafka 在当前现代化的左移数据栈中如何发挥重要的作用。AutoMQ[1] 是全球唯一一款与 Apache Kafka 100% 完全兼容的新一代 Kafka,可以做到10倍成本降低和极速的弹性,因此以下方法论也完全适用于 AutoMQ,欢迎使用我们 Github 开源的社区版本或者联系我们进行商业试用。
数据整合是每个企业面临的重大挑战。批处理和反向ETL是数据仓库、数据湖等存储方案中的常见方法。这些方法可能带来数据不一致、计算成本高和信息过时等后果。本文介绍了一种新的设计模式来解决这些问题:左移架构(the Shift Left Architecture)。左移架构通过实时数据产品实现数据网格(Data Mesh),利用 Apache Kafka、Flink 和 Iceberg 统一事务性和分析性工作负载。一致的信息通过流式处理或提取到 Snowflake、Databricks、Google BigQuery 或任何分析/AI 平台。以此提高灵活性,降低成本,并实现数据驱动的公司文化,提高创新软件应用的上市速度。

数据产品 - 数据网格的基础
在数据网格中,数据产品是一个关键概念,它代表了从传统的集中式数据管理向去中心化方法的转变。
麦肯锡认为:“如果企业能像管理消费品一样管理数据(无论是数字数据还是物理数据),就能从数据投资中收获短期价值并为明天迅速获得更多价值铺平道路。创建可重复使用的数据产品和拼接数据技术的模式,使企业能够从当前和未来的数据中获得价值。”:

麦肯锡认为,数据产品方法可以带来巨大的效益:
-
新业务用例的交付速度可提高 90%。
-
包括技术、开发和维护在内的总成本可降低 30%。
-
更低的风险和数据管理负担。
从技术角度看数据产品
下面从技术角度介绍数据网格中的数据产品:
-
去中心化的数据所有权:每个数据产品由一个特定的领域团队所有。应用程序之间是真正解耦的。
-
源于运行和分析系统:数据产品包括来自任意数据源的信息,包括最关键的系统和分析/报告平台。
-
自包含和可发现:数据产品不仅包括原始数据,还包括相关的元数据、文档和 API。
-
标准化接口:数据产品遵循标准化的接口和协议,确保数据网格中的其他数据产品和消费端可以轻松访问和使用。
-
数据质量:大多数使用案例都受益于实时数据。数据产品可确保实时和批处理应用中的数据一致性。
-
价值驱动:数据产品的创建和维护由业务价值驱动。
从本质上讲,数据网格框架中的数据产品将数据转化为可管理的高质量资产,便于整个组织访问和使用,从而促进更灵活、可扩展的数据生态系统。
反模式(Anti Pattern):批处理和反向 ETL
所谓“现代”的数据栈利用传统的 ETL 工具或数据流将数据输入数据湖、数据仓库或湖仓。最终导致一个一团乱麻的架构,其中包含混合了分析和操作技术,用于批处理和实时工作负载的各种集成工具:

反向 ETL 是将信息从数据湖导入操作应用程序和其他分析工具所必需的。正如我之前所写的那样,数据湖和反向 ETL 的结合是企业架构的一种反模式。这主要是由于反向 ETL 造成了成本和组织效率的低下。事件驱动型数据产品可以实现更简单、更具成本效益的架构。
需要批处理和反向 ETL 模式的一个关键原因是 Lambda 架构的普遍使用: 这是一种使用不同层分别处理实时和批处理的数据处理架构。这种架构仍然广泛存在于企业架构中。这不仅适用于 Hadoop/Spark 和 Kafka 等大数据用例,也适用于与基于文件的传统单体或 Oracle 数据库等事务处理系统的集成。
与之相反,Kappa 架构使用单一技术栈处理实时和批处理。总而言之,通过使用数据流平台将传统技术引入事件驱动架构,实现Kappa 架构是有可能的。其中,变更数据捕获 (CDC) 是最常用的辅助工具之一。了解更多关于 Kappa 取代 Lambda 架构的信息,请参阅文章“Kappa 取代 Lambda 架构”。
数据湖、数据仓库和湖仓中的传统 ELT
如今似乎没有人仍在使用数据仓库了。每个人都在谈论将数据仓库和数据湖合二为一的湖仓。无论你使用或更倾向于哪种术语,如今的集成流程都大致如下:

即使是将所有原始数据导入数据仓库/数据湖/湖仓这一步就会面临一些挑战:
-
更新速度较慢:数据管线越长,使用的工具越多,数据产品的更新速度就越慢。
-
上市时间更长:因为每个业务部门都被迫反复执行相同或类似的处理步骤,而不是从整理好的数据产品中直接获取,所以带来了重复开发工作。
-
成本增加:分析平台收费账单的主力是计算而非存储。业务部门使用 DBT 越多,分析 SaaS 提供商就越有利可图。
-
重复劳动:大多数企业拥有多个分析平台,包括不同的数据仓库、数据湖和人工智能平台。ELT 意味着一遍又一遍进行相同的处理。
-
数据不一致:反向 ETL、零 ETL 和其他集成模式会使您的分析应用程序,特别是操作应用程序看到不一致的信息。您无法将实时消费端或移动应用 API 连接到批处理层,并期望得到一致的结果。
使用 Kafka、Snowflake、Databricks、BigQuery 等进行数据集成、零 ETL 和反向 ETL
上文提到的缺点都是真实存在的!在过去的几个月里,我遇到的每一个客户,没有一个不同意我的观点,也没有一个人告诉我这些挑战不存在。了解更多信息,请查看我的关于使用 Apache Kafka 进行数据流分析和使用 Snowflake 进行分析的博客系列:
-
Snowflake 集成模式:零 ETL 和反向 ETL 与 Apache Kafka 的对比
-
Apache Kafka 的 Snowflake 数据集成选项(包括 Iceberg)
-
Apache Kafka + Flink + Snowflake:经济高效的分析和数据管理
该系列博客可适用于任何其他分析引擎。无论您使用的是 Snowflake、Databricks、Google BigQuery 还是多个分析和人工智能平台的组合,本系列博客都值得一读。
数据混乱造成了数据不一致、信息过时和成本不断增加,解决这些问题的方法就是左移架构。
左移——从运营和分析数据产品到数据流
左移架构可从可靠、可扩展的数据产品中获得一致的信息并降低计算成本。使用左移架构能帮助采用任何技术(Java、Python、iPaaS、Lakehouse、SaaS或任何你能想到的技术)和通信范式(实时、批处理、请求-响应 API)的操作和分析应用程序更快地进入市场:

将数据处理转移到数据流平台可以实现以下功能:
-
在事件发生时持续捕获数据并进行数据流处理
-
创建数据合约,以便与任何应用程序或分析/人工智能平台实现向下兼容并提高信任度
-
通过数据合约和策略执行,在上游持续清理、整理和质量检查数据
-
即时将数据转化为多重文本,以最大限度地提高可重用性(同时仍允许下游消费者在原始数据产品和经过整理的数据产品之间进行选择)
-
构建值得信赖的数据产品,这些产品对于任何交易型和分析型消费者(无论实时消费还是稍后通过批量或请求-响应 API 消费)而言都是有即时价值、可重复使用和有一致性的。
在工作负载左移的同时,开发人员/数据工程师/数据科学家通常仍可使用他们最喜欢的接口(如 SQL)或编程语言(如 Java 或 Python),这一点至关重要。
使用 Apache Kafka、Flink 和 Iceberg 的左移架构
数据流是左移架构的核心基础,可实现可靠、可扩展、数据质量高的实时数据产品。以下架构展示了 Apache Kafka 和 Flink 如何连接任何数据源、整理数据集(又称流处理/流 ETL)并与任何操作或分析数据汇共享处理后的事件:

该架构展示了 Apache Iceberg 表作为备选消费者。Apache Iceberg 是一种开放的表格格式,专为高效可靠地管理大规模数据集而设计。Iceberg 提供 ACID 事务、模式演变和分区功能。它优化了数据存储和查询性能,使其成为数据湖和复杂分析工作流的理想选择。Iceberg 已经发展为事实标准,得到了大多数主要云和数据管理供应商的支持,包括 AWS、Azure、GCP、Snowflake、Confluent,未来可能更多(例如收购 Tabular 后的 Databricks)。
从数据流视角看,Iceberg表只需点击一下按钮就能从Kafka Topic和其图式中获得(使用Confluent的Tableflow - 我相信其他供应商很快也会有自己的解决方案)。Iceberg的一个巨大优势是数据只需要存储一次(通常在像Amazon S3这样的高效并且可扩展的对象存储中)。每个下游应用都可以使用自己的技术来消费数据,无需任何额外的编码或连接器。例子包括Snowflake或Databricks这样的数据湖仓或Apache Flink这样的数据流引擎。
视频:左移架构
我在一个十分钟短视频中总结了上述的左移架构及其示例,如果你更喜欢聆听内容,可以参考这个视频。
Apache Iceberg – 新一代湖仓表格格式的事实标准?
Apache Iceberg 是一个巨大的话题,对于企业架构、终端用户和云供应商来说,都是一个真正的游戏规则颠覆者。我将写另一篇专门的博客,包括一些有趣的主题,如:
-
Confluent 将 Iceberg 表格嵌入其数据流平台的产品策略
-
Snowflake 的开源 Iceberg 项目:Polaris
-
Databricks 收购了 Tabular(Apache Iceberg 背后的公司),并与 Delta Lake 及其开源 Unity Catalog 的关系预期的表格式
-
表格格式标准化的(可能)未来、目录战争,及其他附加解决方案,如 Apache Hudi 或 Apache XTable,以实现湖泊表格格式的全方位可互操作性。
请保持关注,订阅我的LinkedIn Newsletter以接收新文章。
左移架构的商业价值
Apache Kafka 是构建 Kappa 架构的数据流事实上的标准。Data Streaming Landscape 分析展示了各种开源技术和云计算供应商。其中,数据流被认为是一个全新的软件类别。根据 Forrester 发布的 “The Forrester Wave™:2023年第四季度流数据平台”报告显示:该领域的领导者是微软、谷歌和 Confluent,其次是甲骨文、亚马逊、Cloudera 和其他一些公司。
在企业架构中更多地使用数据流平台和 Kafka、Flink 等技术构建数据产品,可以创造巨大的商业价值:
-
降低成本:降低一个甚至多个数据平台(数据湖、数据仓库、湖房、人工智能平台等)的计算成本。
-
减少开发工作量:流式 ETL、数据整理和数据质量控制已在事件创建后即时执行,且仅需执行一次。
-
更快上市:专注于新的业务逻辑,而不是重复性的 ETL 工作。
-
灵活性:根据不同用例选择最佳和/或最具成本效益的技术。
-
创新性:业务部门可以选择任何编程语言、工具或 SaaS,从数据产品中进行实时或批量消费,进行尝试或快速扩展。
事务性工作负载和分析性工作负载的统一最终成为可能。基于此可以实现良好的数据质量、加快创新产品的上市时间并降低整个数据管线的成本。数据一致性在所有应用程序和数据库中都很重要。参见文章: A Kafka Topic with a data contract (= Schema with policies) brings data consistency out of the box!
参考资料
[1] AutoMQ: https://www.automq.com
[2]The Shift Left Architecture – From Batch and Lakehouse to Real-Time Data Products with Data Streaming: https://www.kai-waehner.de/blog/2024/06/15/the-shift-left-architecture-from-batch-and-lakehouse-to-real-time-data-products-with-data-streaming/
相关文章:
左移架构 -- 从攒批,湖仓到使用数据流的实时数据产品
编辑导读: 这篇文章翻译自 Kai Waehner的 《The Shift Left Architecture – From Batch and Lakehouse to Real-Time Data Products with Data Streaming》。文章通过数据产品的概念引出了如何创建可重复使用的数据产品使企业能够从当前和未来的数据中获得价值。基于构建数据产…...

多模态识别和自然语言处理有什么区别
在科技飞速发展的当下,人工智能(AI)已经渗透到我们生活的方方面面。不知道大家有没有这样的经历:早上醒来,对着智能音箱说 “播放今天的新闻”,音箱不仅能识别你的语音,还能在播放新闻的同时&am…...
)
进阶——第十六蓝桥杯嵌入式熟练度练习(串口的小BUG补充-字符接受不完整和字符接受错误)
1.解决接受不完整问题 假如没接受完成,执行函数,就可能会把count直接清零,就会重新接受\ while (1){if(rx_count!0){uint8_t temprx_count;HAL_Delay(1);if(temprx_count)uart_proc(); }key_proc();rxclear_proc();/* USER CODE END WHILE…...

数据结构-链式二叉树
文章目录 一、链式二叉树1.1 链式二叉树的创建1.2 根、左子树、右子树1.3 二叉树的前中后序遍历1.3.1前(先)序遍历1.3.2中序遍历1.3.3后序遍历 1.4 二叉树的节点个数1.5 二叉树的叶子结点个数1.6 第K层节点个数1.7 二叉树的高度1.8 查找指定的值(val)1.9 二叉树的销毁 二、层序…...

【git-hub项目:YOLOs-CPP】本地实现01:项目构建
目录 写在前面 项目介绍 最新发布说明 Segmentation示例 功能特点 依赖项 安装 克隆代码仓库 配置 构建项目 写在前面 前面刚刚实现的系列文章: 【Windows/C++/yolo开发部署01】 【Windows/C++/yolo开发部署02】 【Windows/C++/yolo开发部署03】 【Windows/C++/yolo…...

250213-RHEL8.8-外接SSD固态硬盘
It seems that the exfat-utils package is still unavailable, even after enabling the RPM Fusion repository. This could happen if the repository metadata hasn’t been updated or if the package isn’t directly available in the RPM Fusion repository for RHEL 8…...

如何本地部署DeepSeek?
DeepSeek:智能时代的得力助手 在人工智能技术飞速发展的今天,DeepSeek 作为一款由国内顶尖团队研发的 AI 工具,凭借其卓越的性能和丰富的功能,逐渐在众多同类产品中脱颖而出,成为众多用户在工作和学习中的得力助手。 …...

leetcode:627. 变更性别(SQL解法)
难度:简单 SQL Schema > Pandas Schema > Salary 表: ----------------------- | Column Name | Type | ----------------------- | id | int | | name | varchar | | sex | ENUM | | salary | int …...

51单片机(国信长天)矩阵键盘的基本操作
在CT107D单片机综合训练平台上,首先将J5处的跳帽接到1~2引脚,使按键S4~S19按键组成4X4的矩阵键盘。在扫描按键的过程中,发现有按键触发信号后(不做去抖动),待按键松开后,在数码管的第一位显示相应的数字:从左至右&…...

封装一个sqlite3动态库
作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、项目案例 二…...
Transformer以及BERT阅读参考博文
Transformer以及BERT阅读参考博文 Transformer学习: 已有博主的讲解特别好了: 李沐:Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili知乎:Transformer模型详解(图解最完整版) - 知乎 个人杂想&…...

AI学习记录 - 最简单的专家模型 MOE
代码 import torch import torch.nn as nn import torch.nn.functional as F from typing import Tupleclass BasicExpert(nn.Module):# 一个 Expert 可以是一个最简单的, linear 层即可# 也可以是 MLP 层# 也可以是 更复杂的 MLP 层(active function 设…...

急停信号的含义
前言: 大家好,我是上位机马工,硕士毕业4年年入40万,目前在一家自动化公司担任软件经理,从事C#上位机软件开发8年以上!我们在开发C#的运动控制程序的时候,一个必要的步骤就是确认设备按钮的急停…...

单调队列queue
1.单调队列(Monotonic Queue) 单调队列是一种特殊的队列,它的元素按照单调性(递增或递减)的顺序排列。简单来说,单调队列会维护一个元素单调递增或递减的顺序,在队列中元素会根据当前队列的元素…...
【漫话机器学习系列】091.置信区间(Confidence Intervals)
置信区间(Confidence Intervals)详解 1. 引言 在统计学和数据分析中,我们通常希望通过样本数据来估计总体参数。然而,由于抽样的随机性,我们不可能得到精确的总体参数,而只能通过估计值(如均值…...

UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x99
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x99 这个错误通常发生在你尝试使用 GBK 编码来解码一个包含非GBK编码字符的文件时。GBK 是一种用于简体中文的字符编码方式,它不支持所有可能的 Unicode 字符。 解决方法 明确文件的正确编码:首…...

DeepSeek应用——与word的配套使用
目录 一、效果展示 二、配置方法 三、使用方法 四、注意事项 1、永久化使用 2、宏被禁用 3、office的生成失败 记录自己学习应用DeepSeek的过程...... 这个是与WPS配套使用的过程,office的与这个类似: 一、效果展示 二、配置方法 1、在最上方的…...

递归乘法算法
文章目录 递归乘法题目链接题目详解解题思路:代码实现: 结语 欢迎大家阅读我的博客,给生活加点impetus!! 让我们进入《题海探骊》,感受算法之美!! 递归乘法 题目链接 在线OJ 题目…...
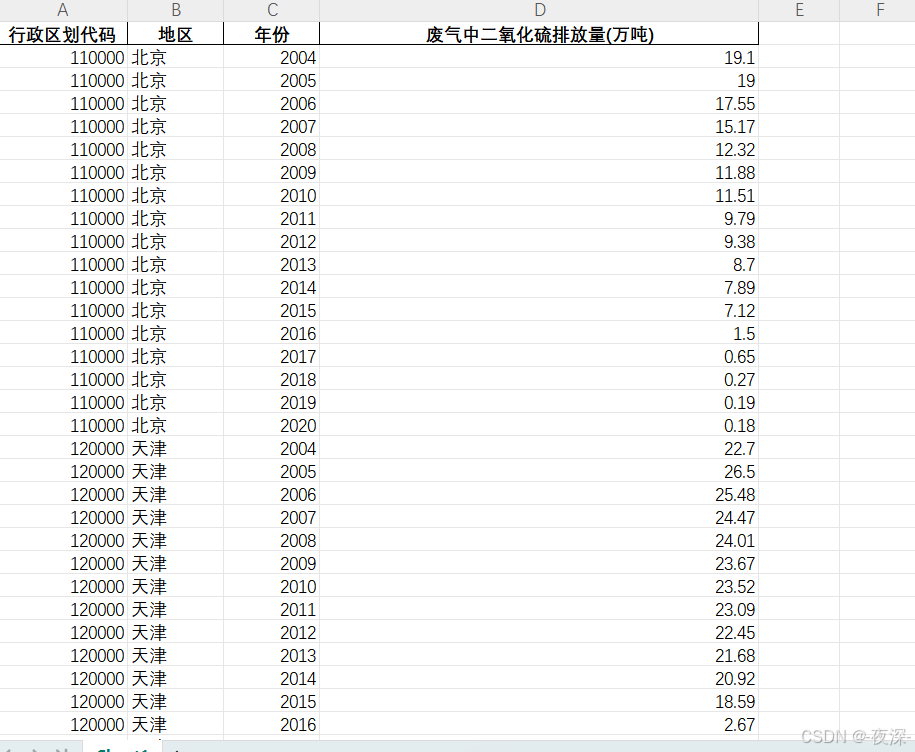
【免费】2004-2020年各省废气中废气中二氧化硫排放量数据
2004-2020年各省废气中废气中二氧化硫排放量数据 1、时间:2004-2020年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、废气中二氧化硫排放量(万吨) 4、范围:31省 5、指标说明:二氧化硫排放量指…...

CNN-LSSVM卷积神经网络最小二乘支持向量机多变量多步预测,光伏功率预测
代码地址:CNN-LSSVM卷积神经网络最小二乘支持向量机多变量多步预测,光伏功率预测 CNN-LSSVM卷积神经网络最小二乘支持向量机多变量多步预测,光伏功率预测 一、引言 1、研究背景和意义 光伏发电作为可再生能源的重要组成部分,近…...

构建个人代码知识库:codesift工具的设计理念与高效实践
1. 项目概述:从代码仓库到个人知识库的进化最近在整理自己过去几年写过的代码片段、工具脚本和项目配置时,发现了一个普遍存在的痛点:这些零散的“智慧结晶”散落在硬盘的各个角落、不同的Git仓库里,甚至有些只存在于模糊的记忆中…...

AI Agent技能生成器:从零创建精准高效的SKILL.md文件
1. 项目概述:一个为AI Agent生成“技能说明书”的元技能如果你和我一样,经常在Claude Code、Cursor或者Codex这类AI编程助手工具里折腾,想让它帮你处理一些特定的、重复性的开发任务,那你肯定对“技能”(Skill…...

终极智能温控指南:FanControl风扇控制软件完整配置教程
终极智能温控指南:FanControl风扇控制软件完整配置教程 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

中性原子量子计算架构:原理、优势与应用
1. 中性原子量子计算架构概述量子计算作为后摩尔时代最具潜力的计算范式之一,其核心优势在于利用量子比特(Qubit)的叠加态和纠缠态实现并行计算。在众多物理实现方案中,中性原子量子架构近年来异军突起,展现出独特的工…...

别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神
别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神 当项目规模从几千行扩展到几十万行代码时,技术债务就像房间里的大象——人人都知道存在,却少有人主动清理。去年我们团队在重构一个核心模块时,发现其中隐藏的…...

Windows动态光标优化:LuumaCursorHelper工具包详解与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的小工具,起因是发现很多朋友在用LuumaCursor这款动态光标主题时,总会遇到一些“小麻烦”。比如,安装后光标在某些应用里不显示、动画卡顿,或者想自定义一下效果却无从下手。我自己也…...
)
SpringCloud微服务里,用Zuul网关聚合Swagger文档的完整配置流程(含踩坑记录)
SpringCloud微服务架构下Zuul网关聚合Swagger文档的实战指南 在微服务架构中,API文档的管理一直是个令人头疼的问题。想象一下,当你的系统由十几个甚至几十个微服务组成时,开发人员要记住每个服务的接口地址和文档路径几乎是不可能的任务。更…...
)
AI微服务治理新范式(Istio for AI技术栈深度拆解)
更多请点击: https://intelliparadigm.com 第一章:AI原生服务网格应用:2026奇点智能技术大会Istio for AI 在2026奇点智能技术大会上,Istio正式发布v1.22“Prometheus AI”版本,首次将LLM推理生命周期深度集成进数据平…...

SAP Fiori Launchpad Designer保姆级教程:手把手教你为ME29N采购订单审批创建自定义磁贴
SAP Fiori Launchpad Designer保姆级教程:手把手教你为ME29N采购订单审批创建自定义磁贴 当你所在的企业尚未部署HR模块,却需要快速启用ME29N采购订单审批功能时,SAP Fiori Launchpad Designer(FLPD_CUST)将成为你的得…...

美政府AI主管:Anthropic 将在 18 个月内成为人类历史最有价值公司
Anthropic 已经成为人工智能革命中最成功的案例之一,但这或许还不是全部。风险投资家兼美国政府人工智能和加密货币沙皇大卫萨克斯在 All-In播客节目中提出了一个惊人的说法:Anthropic 不仅有望成为科技界最强大的公司,而且有望成为人类历史上…...