Adapting to Length Shift: FlexiLength Network for Trajectory Prediction

概要
轨迹预测在各种应用中发挥着重要作用,包括自动驾驶、机器人技术和场景理解。现有方法通常采用标准化的输入时长,集中于开发紧凑神经网络,以提高在公共数据集上的预测精度。然而,当这些模型在不同观测长度下进行评估时,可能会发生显著的“观测长度偏移”现象,导致性能大幅下降。为了解决这一问题,团队引入一个通用且有效的框架——灵活长度网络(FLN),以增强现有轨迹预测技术对不同观测时段的鲁棒性。具体地,FLN整合了具有不同观测长度的轨迹数据,通过灵活长度校准(FLC)获取不随时间变化而发生变化的特征,并采用灵活长度适应(FLA)进一步优化这些特征,以实现更准确的轨迹预测。在ETH/UCY、nuScenes和Argoverse 1三个数据集上的全面实验证明了FLN框架的有效性和灵活性。
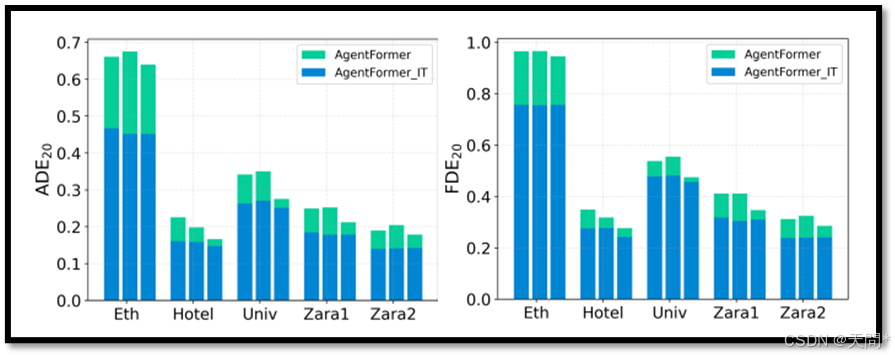
图1。“观测长度偏移”现象是轨迹预测任务中的一个常见问题。AgentFormer模型使用8个时间步的标准观测长度进行训练,并在不同时长下进行测试,以与孤立训练(IT)进行比较。对于每个数据集,从左到右的柱状图组分别对应观测长度为2、4、6个时间步时的结果。
介绍
轨迹预测的目标是基于过去的观测状态预测主体的未来位置,从而理解其运动和行为模式。在许多现实世界的应用中,例如自动驾驶[21, 23, 59, 77]、机器人技术[10, 36]以及场景理解[11, 69],轨迹预测至关重要但极具挑战性。近年来,深度学习的进展显著提高了轨迹预测的准确性[2, 4, 8, 9, 17, 27, 38, 44, 47, 50, 52, 65, 66, 76]。然而,实现良好的预测性能通常需要复杂的模型和大量的计算资源。事实上,许多目前最先进的方法都是在具有固定观测长度的公共数据集[7, 55, 61, 74]上开发的,未能考虑到训练条件与多样化现实场景之间可能存在的差异。因此,固定的训练导致模型在具体实践中往往过于僵化,尤其是环境或观测变量发生变化时。
近来,一些研究探讨了关于轨迹预测模型的训练与测试不一致的问题。例如,文献[68]针对因遮挡或有限视角导致观测不完整的情况,并提出了一种结合轨迹插补和预测的方法。其他研究工作[5, 24, 26, 67]则专注于解决测试环境与训练环境不同的领域偏移挑战。此外,还有一些研究[34, 40, 54]关注可用观测数据有限的情况,例如仅1至2个数据点可用。这些方法试图从不同角度缓解训练与测试之间的差距。在承认这些努力的同时,我们着重解决训练与测试差距的重要性。在本文中,我们专注于尚未充分研究的观测长度差异问题。
对于一些知名架构,如RNN[22]和Transformer[57],可以用一种简单的解决方案判断其处理不同长度输入的能力:用标准输入长度的数据训练模型,然后在不同的输入长度下进行评估。这种解决方案与孤立训练(IT)形成对比,后者在特定的观测长度下训练模型,并用相同的输入长度的数据进行评估。我们使用基于Transformer的方法AgentFormer[73]在ETH/UCY数据集[31, 46]上进行了实验,结果如图1所示。结果揭示了这两种解决方案间明显的性能差异,表明在非训练长度下进行评估时性能会下降。我们将这种现象称为“观测长度偏移”。需要注意的是,尽管孤立训练的性能略有提高,但它需要针对不同的观测长度进行多次训练,这一现象引起以下两个关键问题:
1、这种性能差异背后的根本原因是什么?
2、是否可以在不进行重大修改或大幅增加计算成本的情况下解决这一问题?
启发自这两个问题,并考虑到基于Transformer的模型在轨迹预测任务中的流行性,我们对基于Transformer的轨迹预测方法进行了深入分析,揭示了两个主要原因,我们将其总结为位置编码偏差和归一化偏移。基于这些发现,我们提出一个稳健且灵活的框架——灵活长度网络(FLN),以克服观测长度偏移问题。FLN能够有效整合来自不同观测长度的轨迹数据,通过灵活长度校准(FLC)创建不随时间变化而发生变化的表示,并应用灵活长度适应(FLA)来增强这些表示,从而提高轨迹预测的精度。值得注意的是,FLN只需一次训练,无需进行重大修改,但能够灵活适应不同的观测长度,从而回答了第二个问题。
尽管一些研究关注了位置编码偏差[13, 42]和归一化偏移[71, 72],但我们的工作专注于观测长度偏移问题,这是一个在轨迹预测中常被忽视的问题。我们提出了灵活长度网络(FLN)作为一个实用且非平凡的解决方案,尤其在现实场景中具有重要价值。不同于孤立训练(IT),后者在适应不同观测长度时耗时且占用大量内存,FLN提供了一个更高效的资源利用方案。尽管现代架构能够处理各种输入长度,但它们通常会遭受性能差异的问题,而FLN有效地弥补了这一差距,同时保留了原始模型设计。此外,FLN还可以应用于目前几乎所有基于Transformer架构的现有模型。团队的主要贡献总结如下:
1)识别并深入分析轨迹预测中的观测长度偏移现象,明确了导致性能下降的因素,指明了解决方案的方向。
2)提出只需一次训练的稳健且高效的灵活长度网络(FLN)。它包括灵活长度校准(FLC)和灵活长度适应(FLA),用于学习时间不变的表示,以提升不同观测长度下的预测性能。
3)通过在多个数据集上的全面实验证明了FLN的有效性和通用性。FLN在不同观测长度下均展现出相对于孤立训练(IT)的一致优越性。
相关工作
轨迹预测
轨迹预测的目标是基于主体的历史观测数据来预测它们未来的轨迹。主要关注点是理解这些主体之间的社交动态,这促使了各种方法的发展,例如利用图神经网络(GNNs)的研究[3, 28, 33, 39, 51, 53, 62]。未来轨迹固有的不确定性和多样性推动了生成模型的发展,包括生成对抗网络(GANs)[1, 19, 28, 32, 48]、条件变分自编码器(CVAEs)[25, 37, 49, 63, 64]以及扩散模型[18, 27, 38]等。这些模型在各种数据集上取得了令人鼓舞的结果。然而,这些方法大多优先考虑预测精度,而忽略了在现实应用中经常出现的差异,导致在不同条件下适应性降低。相比之下,我们的工作专注于观测长度的变化,这是许多现有方法面临的一个挑战。值得注意的是,一些基于循环神经网络(RNN)[12, 25, 49]和Transformer[16, 56, 70, 73]的方法可以处理不同长度的输入,但在观测长度变化时表现出局限性。我们的工作深入探讨了这一特定挑战,提出了一个全面的解决方案,不仅增强了现有方法的鲁棒性,还提高了它们在不同观测长度下的性能。、
训练-测试差异
训练和测试之间的差距可能以不同的方式呈现,无论是输入类型还是环境条件。最近的研究开始揭示轨迹预测中差异的各个方面。一些方法[5, 24, 26, 67]专注于训练和测试之间的环境变化,提供了创新的解决方案。另一种方法[60]处理测试期间缺少高精度(HD)地图的问题,采用知识蒸馏(KD)将地图知识从一个更加知情的教师模型转移到学生模型。最近探索的另一个方面是观测数据的完整性。像[34, 40, 54]这样的研究假设只有有限的观测轨迹数据,特别是仅有一到两帧数据可用于预测。这种假设导致了瞬时轨迹预测的概念。其他研究[30, 68]解决了由于真实环境中的遮挡或视野限制导致的观测数据不完整的问题。另一项最近的研究[45]尝试减少在任意时间配置下收集的数据集之间的内部差异。尽管这些方法已经认识到训练-测试差异的各个方面,但观测长度偏移的问题仍然相对未被探索。灵活长度框架以其通用性和有效性脱颖而出,提高了处理不同观测长度轨迹数据的能力。
即时测试适应性
即时测试适应性的目标是在测试期间使模型实时适应新的数据。一种常见方法包括引入一个辅助任务[14, 15, 43],该任务在目标域中使用简单的自监督技术,这通常需要在源域的训练过程中进行修改以包含该辅助任务。然而最近的策略[35, 58]使得在目标域中进行直接调整成为可能,避免了修改训练过程的需要。与这些方法不同,我们提出的框架只需要一次训练,消除了在训练期间进行调整或在推理期间进行额外调整的必要性。此外,灵活长度框架独立运行,无需在训练阶段使用评估数据。
框架模型
深入剖析以往模型性能下降的原因
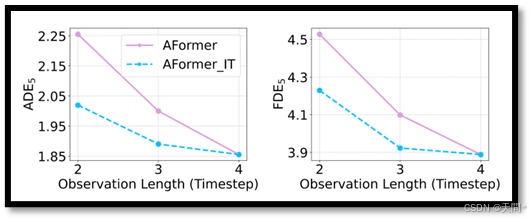
图2。AgentFormer模型的ADE5和FDE5结果,它在nuScenes数据集上使用4个时间步的标准观测长度进行训练,随后在2和3个时间步的较短的观测长度下进行测试。这些结果与通过孤立训练(IT)获得的结果进行了比较。
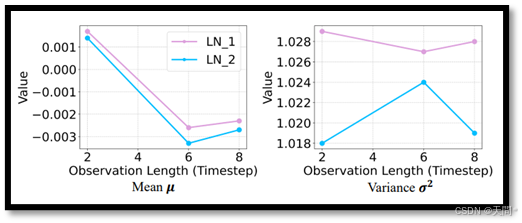
图3。在Eth数据集以2、6、8个时间步的观测长度分别孤立训练的AgentFormer模型中,Transformer编码器的两个不同层的层归一化统计信息。
观测长度偏移。当使用特定观测长度训练的模型在不同长度下进行测试时,“观测长度偏移”现象变得明显,如图1所示。为了进一步研究,我们使用nuScenes数据集[6]训练AgentFormer模型[73],并评估其在不同观测长度下的性能,如图2所示。结果表明,与孤立训练相比,当模型在不同观测长度下进行评估时,存在明显的性能差距。值得注意的是,当测试的观测长度接近训练的观测长度时,性能下降较小。
位置编码偏差。以往研究[20, 41]已经表明,由于缺乏归纳偏差,Transformer模型难以泛化到它们未曾遇到过的输入长度。其他研究[13, 42]将位置编码识别为限制模型对新长度泛化能力的关键因素,并建议对模型结构进行调整以增强位置编码。专注于基于Transformer的模型,我们分析了AgentFormer中的位置编码。对于时间步t的代理n,其位置编码特征τ^t_n(k)的计算公式如下:
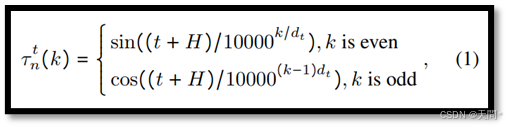
其中,k表示特征索引,dt是特征维度,H是观测长度。显而易见,如果在没有补偿的情况下简单地移除观测数据,会导致长度的变化,进而改变位置编码。因此,我们假设位置编码偏差是导致性能差距的一个关键因素。尽管其他基于Transformer的模型[75, 76]使用了完全可学习的位置嵌入,但后续的实验足以证明,这种类型的位置嵌入仍然是一个关键原因。
归一化偏移。以往的研究[71, 72]在图像和视频分类的背景下研究了归一化偏移问题。他们发现改变网络宽度会影响批量归一化(BN),导致聚合特征的均值和方差发生变化,并影响特征聚合的一致性。鉴于层归一化(LN)在基于Transformer的模型中被广泛使用,并且其操作方式与BN类似,我们假设LN统计信息的差异可能是影响对不同长度泛化能力的另一个因素。例如,如果一个模型使用观测长度H进行训练,而使用观测长度L进行测试,那么在测试期间输入到LN的将是中间特征f^L,从而产生以下输出:
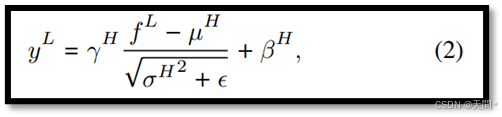
其中,μ^H和σ^H^2是从输入长度为 H 的数据分布中得出的,而γ^H和β^H是在相同输入长度下训练期间学习到的参数。我们分别使用观测长度H和L训练AgentFormer模型,然后分析Transformer编码器中两个层归一化(LNs)的特征统计信息。图3中,可以明显观察到不同观测长度下的统计差异。重要的是,μ和σ是数据依赖的,这表明这些差异直接来源于数据本身。因此可以认为层归一化统计信息的变化是基于Transformer的模型中观测长度偏移现象的另一个原因。
灵活长度网络FLN
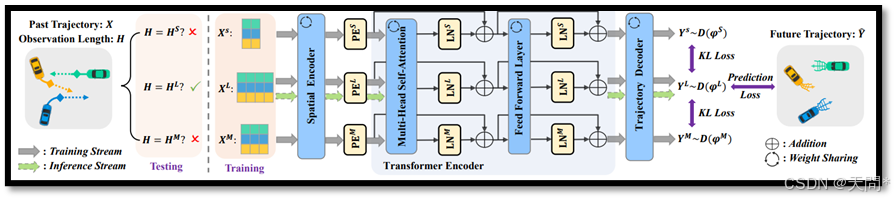
图4。灵活长度网络(FLN)示意图,简化了地图编码分支。训练期间,对于不同观测长度HS、HM和HL的输入,我们利用灵活长度校准(FLC)来获取不随时间变化而变化的表示。此外,采用灵活长度适应(FLA)将这些不变的表示与不同的子网络对齐,从而增强模型的能力。在推理期间,激活观测长度最接近的子网络。
问题描述
尽管术语上存在一些差异,但多主体轨迹预测的基本问题设置在现有方法中保持一致。本质上,目标是基于主体过去的观测状态X∈R^(N×H×F)来预测多个主体的未来轨迹Y∈R^(N×T×F)。N是主体数量,H是观测长度,T是预测时长,F是坐标维度,通常为2。
常见的方法旨在开发一个生成模型,记作pθ(Y∣X,I),其中I表示上下文信息,例如高精地图(HD maps)。如前所述,这些方法在评估时往往会因观测长度的变化而面临挑战。因此,我们的目标是开发一个能够在一系列输入长度H上进行评估的模型 pθ(Y∣X,I),并实现与孤立训练(IT)相似甚至更好的性能,其中H表示不同的观测长度集合。
灵活长度校准FLC
如第3节所述,当评估长度接近训练长度时,性能差距较小。这一观察结果启发我们在训练过程中引入不同长度的观测数据,并为从这些序列中提取特征而开发相应的子网络。给定一个观测轨迹序列X,我们可以通过截断或滑动窗口方法生成不同长度的序列。通过这种方式,我们可以收集三个序列:XS、XM 和 XL,分别对应短、中、长三种类型,其对应长度分别为HS、HM和HL。在训练期间,这三个序列分别输入到它们对应的子网络 FS(⋅)、FM(⋅)和FL(⋅)中进行处理。
图4展示了基于Transformer的架构上开发的灵活长度网络(FLN),简化了地图分支。我们将典型基于Transformer模型的组件共分为几个关键部分:空间编码器(SE)用于空间特征提取,位置编码器(PE)用于嵌入位置信息,Transformer编码器用于模型化时间依赖性,轨迹解码器用于生成轨迹。在训练期间,三个输入XS、XM和XL分别由它们各自的子网络 FS(⋅)、FM(⋅) 和 FL(⋅) 处理。在推理期间,仅激活与观测长度匹配的子网络。这种方法在FLN框架中建立了一个计算流,使得模型能够有效地在各种观测长度下进行评估。
子网络权重共享。给定三个轨迹样本XS、XM和XL,我们在所有子网络中对空间编码器、时间编码器和轨迹解码器使用共享权重,以找到一组参数θ来提取时空特征,如下所示:
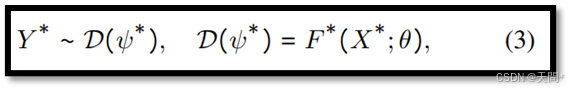
其中,∗∈{S,M,L},而D(ψ∗)表示由ψ∗参数化的分布,Y∗遵循该分布,例如双变量高斯分布或拉普拉斯混合分布[76]。
这种设计与孤立训练(IT)形成对比,它只需维护一组适用于各种长度的权重,在参数使用上更加高效。此外,这种共享权重策略通过隐式地向模型提供这三条观测序列属于同一轨迹的先验知识提升了性能。这使得模型对观测长度的变化更具韧性。
时间蒸馏。轨迹预测模型通常在使用更长的观测数据X^L时表现更好,因为其中包含更多的运动信息。因此我们将Y^L∼D(ψ^L)视为三个预测中最准确的一个。为更新F^L(⋅)的参数,我们采用负对数似然损失,表示如下:
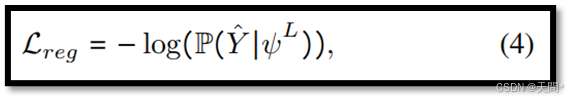
其中Y^是真实轨迹。需要注意的是,由于单条轨迹中通常存在多个主体,上述公式是一个简化版本,省略了每个时间步针对每个主体的平均值计算。
对于更新两个子网络FS(⋅)和FM(⋅)的参数,一种直接的方法是计算相应的负对数似然损失,如公式(4)所示。然而这种方法存在潜在的缺点,由于所有三个子网络共享权重,针对FL(⋅)的最优参数可能对FS(⋅)或FM(⋅)并不那么有效。此外优化ψS和ψM的对数似然损失也可能会影响FL(⋅)的性能。这是因为它们的输入XS和XM包含较少的运动信息,可能会导致拟合效果较差。采用KL散度损失[29]校准并整合ψS和ψM到计算过程中改善性能,如下所示:
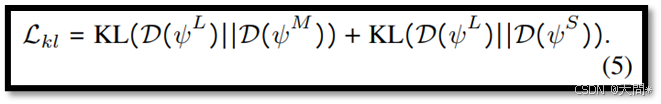
通过公式(5)更新共享子网络的权重,旨在使学生网络【D(ψ^M)和D(ψ^S)】的预测分布尽可能接近教师网络D(ψ^L)的预测分布。这一过程有助于将FL(⋅)中的有价值知识传递给FM(⋅)和FS(⋅)。我们FLN的整个参数集更新如下:
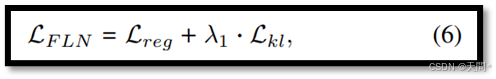
其中λ用于在反向传播过程中平衡这两个项,我们的实现中设置λ为1。
综合考虑子网络权重共享和时间蒸馏,Lreg为预测任务提供指导,而Lkl则为网络训练提供轨迹内的知识。这将促使D(ψL)、D(ψM)和D(ψS)展现出高度相似性,因为长度变化并不会改变某一特定轨迹的分布。通过这种方法,FLN不仅能够学习到时间不变的表示,还能确保实现的便捷性,因为它不需要对特征提取器进行任何更改。
灵活长度适应FLA
我们开发了灵活长度校准(FLC),以指导我们的灵活长度网络(FLN)学习时间不变的表示。此外,我们引入了灵活长度适应(FLA),以优化这些不变特征在不同子网络中的拟合效果,从而进一步提升它们的表示能力。
独立位置编码。我们在第3节中的分析指出,位置编码可能使得模型对观测长度产生混淆。为了应对这一问题,我们为每个子网络实现了独立位置编码。以AgentFormer[73]中的位置编码为例,我们定义了具有不同观测长度的输入的位置编码,如下所示:
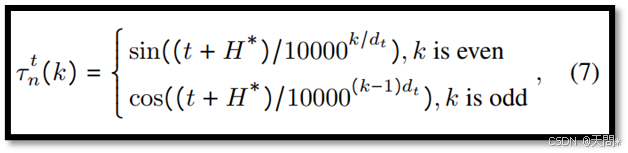
其中∗∈{L,M,S}。尽管最近基于Transformer的模型[75, 76]已经从传统的正弦模式转向完全可学习的位置嵌入,我们在每个子网络中采用了这种可学习的位置嵌入。因此对于每个输入序列X^S、X^M和X^L,我们分别定义了唯一的可学习位置编码τ^S、τ^M和τ^L。需要注意的是,为每个子网络实现独立位置编码是一种资源高效解决方案,它仅引入了可以忽略不计的参数和计算量的增加。
专门化的层归一化。 如第3节所述,归一化偏移是观测长度变化时性能差距的另一个原因。将X^S、X^M和X^L的中间特征分别记为f^S、f^M和f^L。我们为每个输入序列引入专门的层归一化,如下所示:
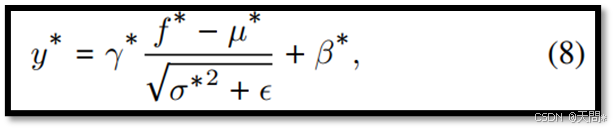
其中∗∈{S,M,L}。这种专门的归一化允许在训练期间独立学习γ和β,并针对每个序列分别计算μ和σ。此外,这种方法较高效,因为归一化通常涉及一个简单的变换,其参数量不到模型总参数的1%。
实验
设置
基线模型。我们提出的FLN是一个与基于Transformer的方法兼容的通用框架。我们选择了两种广泛认可的开源方法,AgentFormer[73]和HiVT [75],并将它们与我们的FLN集成。此外,为了进行更全面的比较,我们还包含了四个额外的基线模型:
(1)混合采样:在每次训练迭代中,我们为具有观察长度H^S、H^M、H^L的轨迹数据分配三个概率ρ^S、ρ^M、ρ^L用于训练。
(2)微调:模型使用观察长度H^L进行训练,然后使用另一个长度(H^S或H^M)微调直到收敛。
(3)联合训练:我们将来自三种观察长度H^S、H^M、H^L的轨迹样本扩展到训练数据集中,然后在不进行任何结构更改的情况下训练原始模型。
(4)独立训练:模型仅使用单一观察长度的轨迹数据H^S或H^M或H^L进行训练。
数据集。我们使用以下三个数据集:(1) ETH/UCY数据集[31,46]是行人轨迹预测的主要基准,包含五个数据集Eth、Hotel、Univ、Zara1和Zara2,采样频率为2.5Hz,轨迹交互密集。 (2) nuScenes数据集[74]是一个大型自动驾驶数据集,包含1000个场景,每个场景的标注频率为2Hz,并包含11个语义类别的高清地图。(3) Argoverse1[7]包含323,557个真实世界驾驶序列,采样频率为10Hz,并配有用于轨迹预测的高清地图。
评估协议。在三个数据集中我们使用平均位移误差ADE_K和最终位移误差FDE_K作为比较指标,其中K表示要预测的轨迹数量。每个数据集遵循自己的评估协议:(1)对于ETH/UCY,采用留一法设置是标准的,任务是从8个观察步预测12个未来时间步,K通常设置为20。 (2)在nuScenes数据集中,如AgentFormer所用,仅考虑车辆数据,从4个观察步预测12个未来步。K通常设置为5和10。(3)在Argoverse中1,序列被分割成5秒的间隔,基于20个观察步(2秒)预测30个未来步(3秒),涉及多个主体。使用验证集进行评估,K为6。
实现细节。对于每个数据集,我们定义了三种不同的观察长度(以时间步为单位)H={H^S、H^M、H^L}用于训练,其中H^L是标准评估协议中的默认长度,考虑到超出此长度的数据可能不可用。具体来说,我们为ETH/UCY使用H={2, 6, 8},为nuScenes使用H={2, 3, 4},为Argoverse 1使用H={10, 20, 30}。预测长度T保持标准设置中的定义。原型模型在观察长度H^L上进行训练,并在H^S和H^M上进行评估。独立训练(IT)是指分别在观察长度H^S、H^M和H^L上训练和评估模型。更多细节和实验结果在补充材料中提供。
主要结果
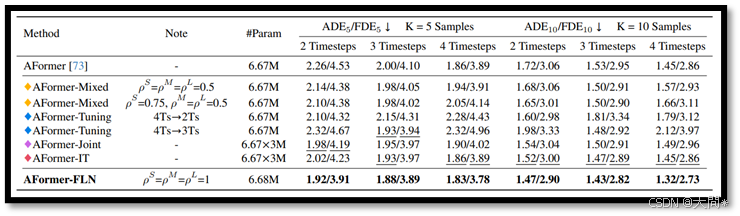
表1。在nuScenes数据集上与基线模型的比较,评估指标为ADE5/FDE5和ADE10/FDE10。最佳结果以粗体突出显示,次佳结果以下划线标出。
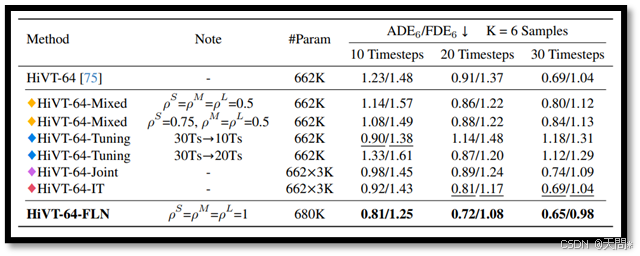
表2。在Argoverse 1验证集上与基线模型的比较,评估指标为ADE6/FDE6。最佳结果以粗体突出显示,次佳结果以下划线标出。
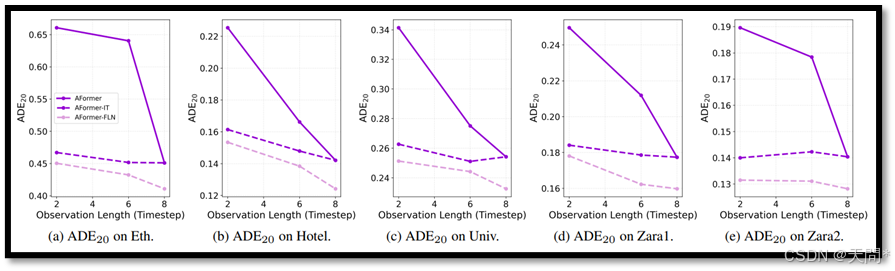
图5。使用AgentFormer模型在五个ETH/UCY数据集上的性能表现,以ADE20为衡量标准。这些结果与基线模型和独立训练(IT)的结果进行了比较,突显了我们的FLN所取得的显著改进。
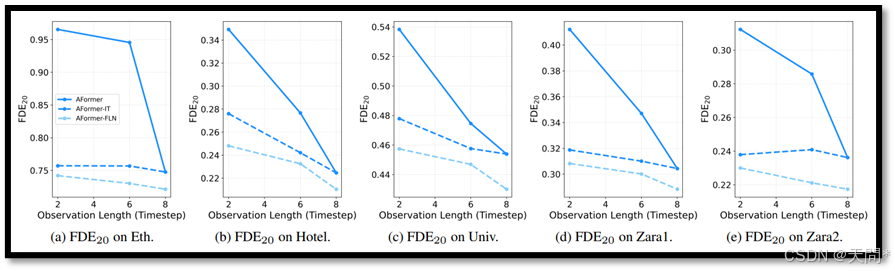
图6。使用AgentFormer模型在五个ETH/UCY数据集上的性能表现,以FDE20为衡量标准。这些结果与基线模型和独立训练(IT)的结果进行了比较,展示了我们的FLN所取得的显著改进。
与基线模型的比较。表1展示了在nuScenes数据集上使用AgentFormer模型的结果,其中我们的FLN框架优于所有基线模型,显示出其在适应不同观察长度方面的鲁棒性。值得注意的是,混合采样有助于缓解“观察长度偏移”问题,这从2和3时间步的观察长度上得到的结果改进中可以看出,与标准训练协议相比,表现有所提升。然而,这种改进是以4时间步观察长度的准确性降低为代价的。增加长度H^S的概率可以改善该长度上的性能,但相反,H^L上的性能会变得更差。这种模式表明存在一种权衡:在较短长度上获得更好的结果会导致在较长长度上的性能下降。可以发现,H^M上的性能相对稳定,可能是因为H^M和H^L的序列数据量保持不变,从而维持了这两个数据簇之间的一致关系。微调使基线方法能够达到与独立训练(IT)相当的性能,但忽略了来自其他长度的信息。至于联合基线,其性能与IT相似,甚至在K=5时,2时间步长度上的性能优于IT。然而,联合和IT基线的一个显著问题是由于重复的训练过程导致模型复杂性增加。相比之下,我们的FLN只需要进行一次训练,并且几乎没有额外的计算开销,但它允许在不同长度上进行评估,并获得更优的结果。
在不同数据集上的性能表现。此外,如图5和图6所示,在ETH/UCY基准上的评估表明,我们提出的FLN在不同观察长度上优于独立训练(IT)。我们还将FLN扩展到HiVT方法,该方法使用可学习的嵌入进行位置编码,并在Argoverse1验证集上对其进行了评估。表2中的结果显示,FLN在三种不同的观察长度上始终表现出色,证实了其在适应各种观察长度方面的鲁棒性。
泛化研究
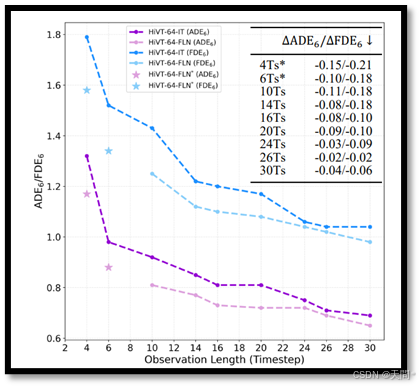
图7. FLN和IT在Argoverse1验证集上不同观察长度的性能表现,改进结果被列于表格中。观察长度超出10到30范围的结果用*标记。
我们已经证明,FLN在训练时的观察长度上优于独立训练(IT),但尚未在训练之外的长度上评估模型。受第3节发现的启发,随着观察长度接近标准输入长度,性能差距会逐渐缩小,我们引入了一种高效的推理方法,使得FLN能够在任意长度上进行评估。当遇到未见过的长度H^I时,我们首先计算其与H^S、H^M、H^L的差异,并激活长度差异最小的子网络。如果两个子网络的长度差异相同,则默认选择输入长度较长的那个。这种方法使FLN能够在一系列未见过的观察长度上进行评估。
由于我们将最大长度H^L设置为标准观察长度,因此由于预分割的原因,生成观察长度超过H^L的轨迹序列是具有挑战性的。在Argoverse 1验证集上,观察长度小于30时间步的结果如图7所示。这些结果清楚地表明,FLN在所有观察长度上均优于IT,甚至在10到30时间步范围之外也是如此。这验证了我们的FLN框架在处理训练中未包含的观察长度时的强大泛化能力。
消融研究
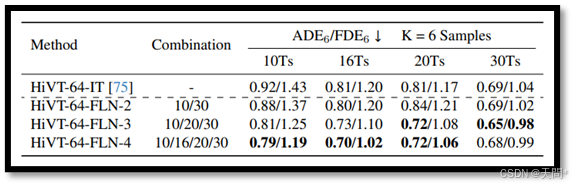
表3。FLN在Argoverse 1验证集上使用不同观察长度组合的性能表现。最佳结果以粗体突出显示。
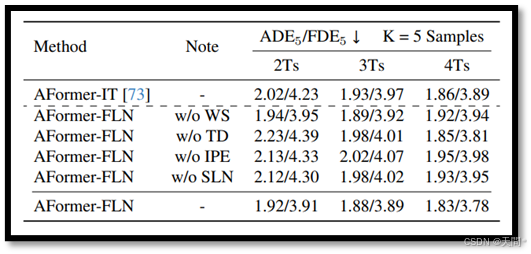
表4。在nuScenes数据集上对FLN进行的消融研究。WS、TD、IPE和SLN分别表示子网络权重共享、时间蒸馏、独立位置编码和专用层归一化。最佳结果以粗体突出显示。
长度组合。我们在Argoverse 1数据集上实现了不同的观察长度组合,如表3所示。观察结果显示,FLN-2在10和16时间步的长度上,其ADE6和FDE6指标优于独立训练(IT),并且在30时间步的长度上取得了相当的结果。然而,在20时间步的长度上,其性能不如IT,这可能是由于训练数据中缺少这一序列长度。FLN-3和FLN-4在所有观察长度上均优于IT。这种改进可以归因于存在具有中间观察长度的轨迹数据,这有助于缓解这一范围内的“观察长度偏移”问题。尽管FLN-4在10、16和20时间步的长度上表现优于FLN-3,但这也增加了额外的训练时间和资源。
模型设计。我们在nuScenes数据集上对FLN的每个组件进行了详细分析,如表4所示。我们首先移除了权重共享(w/o WS),为每个长度创建了独特的子网络。结果显示,在2和3时间步的观察长度上优于IT,但在4时间步的长度上表现较差。这表明共享权重使FLN能够更有效地捕获跨不同输入长度的时间不变特征。我们从FLN中移除了时间蒸馏(w/o TD),即不使用KL损失进行优化。这导致在2和3时间步的观察长度上性能不如IT,这表明我们的时间蒸馏(TD)设计是必要的。我们还测试了共享位置编码(w/o IPE)和共享层归一化(w/o SLN)。这两种情况都导致了性能下降,从而验证了我们独立位置编码(IPE)和专用层归一化(SLN)设计的重要性。
结论
在这篇论文中,我们通过引入灵活长度网络FLN来应对轨迹预测中观察长度偏移这一关键挑战。这一新颖的框架结合了灵活长度校准FLC和灵活长度适应FLA,为处理不同观察长度提供了一种通用解决方案,并且只需要进行一次训练。我们在ETH/UCY、nuScenes和Argoverse1等数据集上进行的广泛实验表明,FLN不仅在一系列观察长度上提高了预测的准确性和鲁棒性,而且始终优于独立训练(IT)。
FLN框架的一个局限性是,由于每次训练迭代需要处理多个输入序列,FLN会增加训练时间。展望未来,我们将专注于提高FLN的训练效率。
补充细节
我们使用AgentFormer模型[73]的开源代码和HiVT模型[75]的开源代码来评估我们提出的框架。我们利用提供的预训练模型来评估不同观察长度下的性能。具体地,对于HiVT模型,我们选择其较小的变体HiVT-64,并使用Argoverse 1验证集进行评估。所有模型均在NVIDIA Tesla V100 GPU上进行训练,并严格遵循其各自官方实现中指定的超参数。
训练损失。在我们的工作中,我们引入了灵活长度网络FLN框架,该框架旨在便于与基于Transformer的轨迹预测模型集成。我们通过使用AgentFormer和HiVT两种模型来展示其应用,并对其性能进行评估。AgentFormer模型是一个两阶段生成模型。在这两个阶段中,我们使用输出Y^L ∼ D(ψ^L),并遵循其原始损失函数。此外,我们引入了我们的时间蒸馏损失L_kl,并将平衡超参数λ设置为1。对于HiVT模型,其训练使用的是结合回归和分类的损失函数,我们同样应用输出Y^L ∼ D(ψ^L),并遵循其原始损失函数。我们的框架进一步扩展了这一点,并引入了我们的时间蒸馏损失L_kl,同时将平衡超参数λ设置为1。
专用层归一化研究
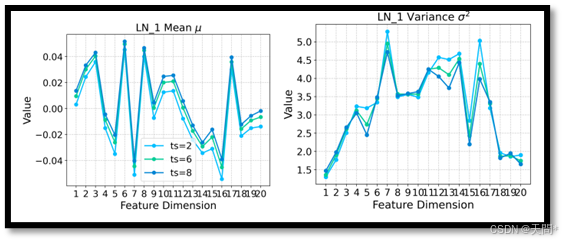
图8。AgentFormer模型中轨迹解码器的第一个层归一化层的统计信息,该模型分别在Eth数据集上针对2、6和8时间步的观察长度进行了独立训练(IT)。
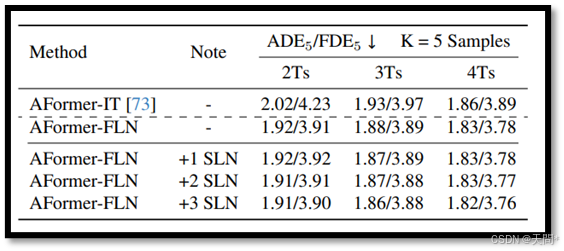
表5. 在nuScenes数据集上对AgentFormer模型进行的专用层归一化研究。其中,“+L SLN”表示在轨迹解码器中应用L个额外的专用层归一化层。
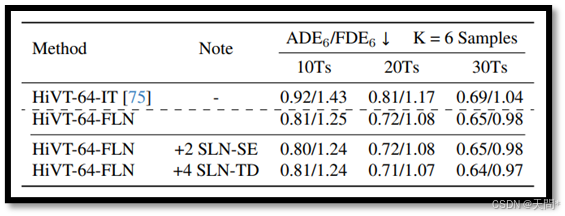
表6. 使用Argoverse 1验证集对HiVT-64模型进行的专用层归一化研究。其中,“+2 SLN-SE”表示在HiVT的空间编码器中的Agent-Agent交互模块中增加2个专用层归一化层;“+4 SLN-TD”表示在轨迹解码器中增加4个额外的专用层归一化层。
在我们的分析中,我们将典型的基于Transformer的轨迹预测模型的组件分为几个关键部分:一个空间编码器用于提取空间特征;一个位置编码器用于嵌入位置信息;一个Transformer编码器用于建模时间依赖性;以及一个轨迹解码器用于生成预测轨迹。尽管这些组件的设计各不相同,包括Transformer编码器之外的层归一化LN层,我们对这些不同模型部分中的LN层进行了研究。实验表明,Transformer编码器中的LN偏移是性能下降的主要原因。
对于AgentFormer模型,它在其Transformer编码器中包含两个LN层,以及在轨迹解码器中包含三个LN层。我们在Eth数据集[31, 46]上分别针对2、6和8时间步的观察长度对AgentFormer模型进行独立训练,然后使用相同的轨迹分别通过这三个训练好的模型,并分析轨迹解码器中第一个LN层的LN统计信息。该层的输入特征维度为20×256,我们在图8中绘制了这些值在20个维度上的分布,因为LN影响最后一个维度。我们的观察结果显示,在不同观察长度下,统计方差极小,表明从同一轨迹在不同观察长度下提取的特征表示具有非常相似的统计结构,用于后续的解码。我们在nuScenes数据集[74]上进行了进一步的实验,详细内容见表5,实验中在轨迹解码器中额外应用了三个专用的LN层。在轨迹解码器的第一个LN层中应用专用LN几乎可以获得相同的性能。在轨迹解码器中增加两个或三个专用LN层仅显示出微小的改进。因此,我们决定仅在Transformer编码器中实现专用LN层,以平衡性能与模型复杂性。
HiVT模型在其每个组件中使用了多个LN层。然而,我们的观察表明,显著的统计差异主要出现在Transformer编码器中。我们在Argoverse 1[7]验证集上进行了额外的实验,详细内容见表6,实验涉及在不同组件中使用额外的专用LN层。结果与我们在AgentFormer模型中的观察一致。因此,我们决定仅在时序Transformer编码器中实现两个专用LN层。
总之,当观察长度不同时,归一化偏移通常发生在Transformer编码器(时序建模)中,这种偏移也是性能下降的原因之一。这一发现与论文主体部分讨论的经验结果一致。
归一化偏移问题
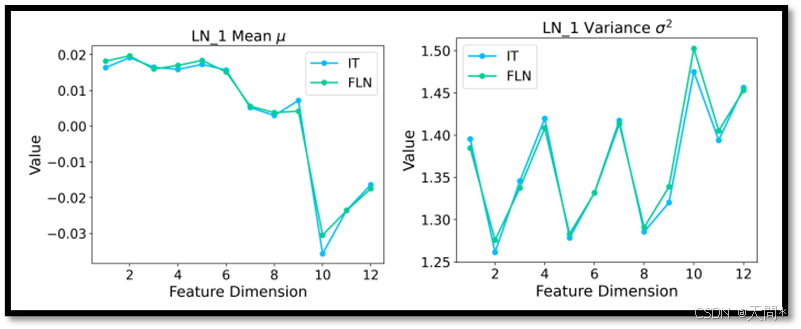
图9。AgentFormer模型中Transformer编码器第一层的层归一化统计信息,该模型通过独立训练(IT)在4时间步的观察长度上进行训练。IT和FLN均在相同的4时间步观察长度上进行评估。
为了进一步验证我们的灵活长度网络FLN能够缓解归一化偏移问题,我们分析了独立训练IT和FLN之间的层归一化LN层统计信息。这两种方法均使用AgentFormer模型在nuScenes数据集上进行训练。我们使用了一条包含3个主体、观察时长为4时间步的相同轨迹,并分别通过IT和FLN模型进行处理。这些模型中的第一层LN接收一个维度为12×256的中间输入特征。由于LN沿最后一个维度操作,因此图9中展示的统计结果是沿着12维轴呈现的。两条曲线的对齐表明,统计值非常相似,证明了FLN在缓解归一化偏移问题方面的有效性。
定量结果
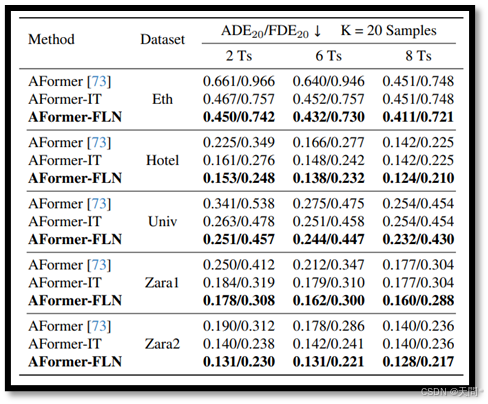
表7。在ETH/UCY数据集上与基线模型的比较,评估指标为ADE20/FDE20。最佳结果以粗体突出显示。
在“实验”部分,我们通过各种图表展示了我们提出的灵活长度网络FLN在ETH/UCY数据集上的性能表现。此外,我们还在表7中提供了相应的定量结果,供进一步参考。显而易见的是,在所有五个数据集中,我们的FLN在不同观察长度上始终优于独立训练IT的结果。
可视化结果
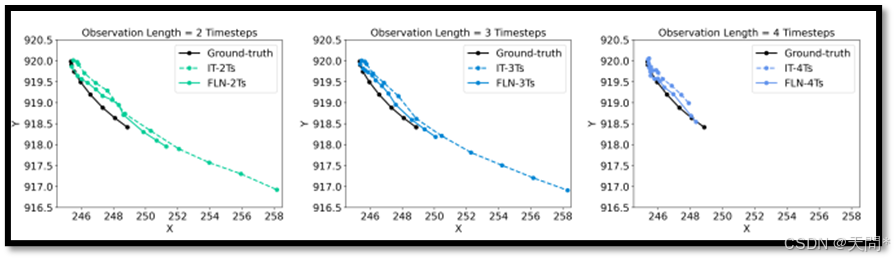
图10。由独立训练IT和我们的灵活长度网络FLN预测的轨迹的可视化结果。
图10中,我们使用AgentFormer模型在nuScenes数据集上展示了轨迹预测的可视化结果。这些可视化结果展示了相同的轨迹,但具有不同的观察长度。我们专注于一个单一的主体,并保持图像大小以方便比较。这些可视化清楚地表明,我们的灵活长度网络FLN在各种观察长度上均优于独立训练IT,从而证实了FLN在处理具有不同观察长度的输入时的有效性。
参考




相关文章:
Adapting to Length Shift: FlexiLength Network for Trajectory Prediction
概要 轨迹预测在各种应用中发挥着重要作用,包括自动驾驶、机器人技术和场景理解。现有方法通常采用标准化的输入时长,集中于开发紧凑神经网络,以提高在公共数据集上的预测精度。然而,当这些模型在不同观测长度下进行评估时&#…...

张量循环运算:内存溢出原因及解决
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 内存溢出解决方法致谢 内存溢出 使用AlexNet遍历大量图像进行指标运算(LP…...

【Qt】:概述(下载安装、认识 QT Creator)
🌈 个人主页:Zfox_ 🔥 系列专栏:Qt 目录 一:🔥 介绍 🦋 什么是 QT🦋 QT 发展史🦋 Qt版本🦋 QT 优点 一:🔥 搭建Qt开发环境 ǹ…...

11、《Web开发性能优化:静态资源处理与缓存控制深度解析》
Web开发性能优化:静态资源处理与缓存控制深度解析 一、性能优化的核心战场:静态资源处理 现代Web应用静态资源体积占比普遍超过70%,以典型Vue项目为例: dist/ ├─ css/ # 38% 体积 ├─ js/ # 45% 体积 └─ img…...
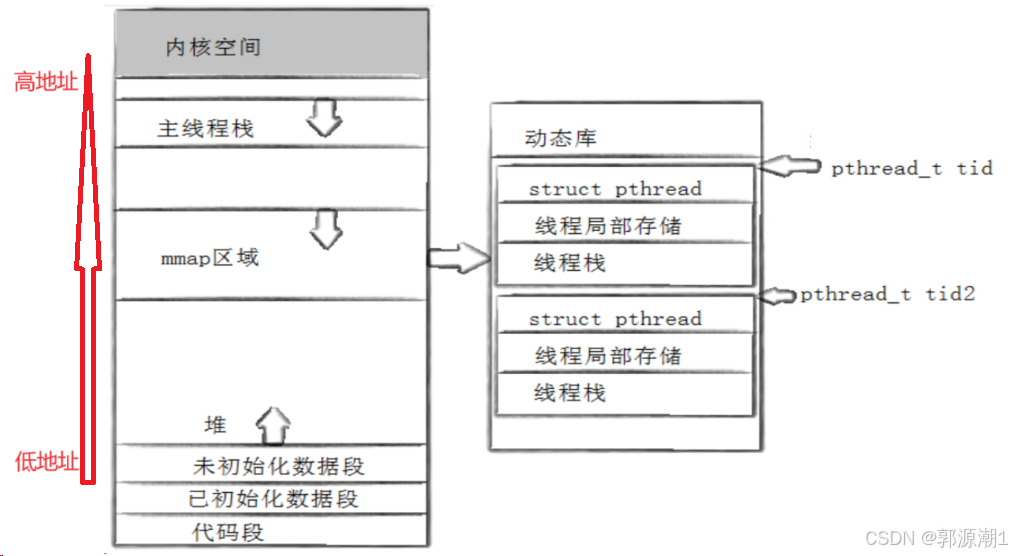
【Linux】多线程 -> 从线程概念到线程控制
线程概念 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”。一切进程至少都有一个执行线程。线程在进程内部运行,本质是在进程地址空间内运行。在Linux系统中,在CPU眼…...

用什么办法能实现ubuntu里面运行的自己开发的python程序能自动升级。
要实现Ubuntu中自己开发的Python程序自动升级,可以通过以下几种方式: 1. 使用 Git 仓库 定时任务 如果你的Python程序托管在Git仓库中,可以通过定时拉取最新代码来实现自动升级。 步骤: 确保Python程序在Git仓库中。在Ubuntu上…...

java处理pgsql的text[]类型数据问题
背景 公司要求使用磐维数据库,于是去了解了这个是基于PostgreSQL构建的,在使用时有场景一条图片数据中可以投放到不同的页面,由于简化设计就放在数组中,于是使用了text[]类型存储;表结构 #这是一个简化版表结构&…...

LeetCode 热门100题-字母异位词分组
2.字母异位词分组 题目描述: 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs ["eat", "tea", "tan&q…...

耐张线夹压接图片智能识别
目录 一、图片压接部位定位1、图像准备2、人工标注3、训练4、推理5、UI界面 压接状态智能识别 一、图片压接部位定位 ,往往X射线照片是一个大图,进行图片压接部位定位目的是先找到需识别的部位,再进行识别时可排除其他图像部位的干扰&#x…...
)
ADC 的音频实验,无线收发模块( nRF24L01)
nRF24L01 采用 QFN20 封装,有 20 个引脚,以下是各引脚的详细介绍: 1. 电源引脚 ◦ VDD:电源输入端,一般接 3V 电源,为芯片提供工作电压,供电电压范围为 1.9V~3.6V。 ◦ VSS…...

企业SSL 证书管理指南
文章从以下几个部分展开 SSL证书的用途和使用场景SSL证书的申请类型和实现方式SSL证书的管理SSL证书的续签 一、SSL 证书的用途和使用场景 1.1 为什么要使用 SSL 证书? 1. 数据安全 🛡️- 在 HTTP 传输中,TCP 包可以被截获,攻…...

Python Pandas(7):Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。数据清洗与预处理的常见步骤: 缺失值处理:识别并…...

南京观海微电子----整流滤波电路实用
01 变压电路 通常直流稳压电源使用电源变压器来改变输入到后级电路的电压。电源变压器由初级绕组、次级绕组和铁芯组成。初级绕组用来输入电源交流电压,次级绕组输出所需要的交流电压。通俗的说,电源变压器是一种电→磁→电转换器件。即初级的交流电转化…...

【python】向Jira测试计划下,附件中增加html测试报告
【python】连接Jira获取token以及jira对象 # 往 jira 测试计划下面,上传测试结果html def put_jira_file(plain_id):# 配置连接jiraconn ConnJira()jira conn.jira_login()[2]path jira.issue(O45- plain_id)attachments_dir os.path.abspath(..) \\test_API…...

探索ChatGPT背后的前端黑科技
由于图片和格式解析问题,可前往 阅读原文 在人工智能与互联网技术飞速发展的今天,像ChatGPT这样的智能对话系统已经成为科技领域的焦点。它不仅能够进行自然流畅的对话,还能以多种格式展示内容,为用户带来高效且丰富的交互体验。然…...

Agents Go Deep 智能体深入探索
Agents Go Deep 智能体深入探索 核心事件 OpenAI发布了一款先进的智能体“深度研究”,它能借助网络搜索和推理生成研究报告。 最新进展 功能特性:该智能体依据数百个在线资源生成详细报告,目前仅支持文本输出,不过很快会增加对图…...

DeepSeek全生态接入指南:官方通道+三大云平台
DeepSeek全生态接入指南:官方通道三大云平台 一、官方资源入口 1.1 核心交互平台 🖥️ DeepSeek官网: https://chat.deepseek.com/ (体验最新对话模型能力) 二、客户端工具 OllamaChatboxCherry StudioAnythingLLM …...

c++TinML转html
cTinML转html 前言解析解释转译html类定义开头html 结果这是最终效果(部分):  前言 在python.tkinter设计标记语言(转译2-html)中提到了将Ti…...

STM32硬件SPI函数解析与示例
1. SPI 简介 SPI(Serial Peripheral Interface)即串行外设接口,是一种高速、全双工、同步的通信总线,常用于微控制器与各种外设(如传感器、存储器等)之间的通信。STM32 系列微控制器提供了多个 SPI 接口&a…...
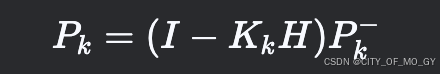
滤波器:卡尔曼滤波
卡尔曼滤波(Kalman Filter)是一种高效的递归算法,主要用于动态系统的状态估计。它通过结合系统模型和噪声干扰的观测数据,实现对系统状态的最优估计(在最小均方误差意义下)。以下从原理、使用场景和特点三个…...

不只是安装!用Docker一键搞定OpenVSLAM开发环境,顺便聊聊它的Web查看器怎么用
从零构建OpenVSLAM容器化开发环境:Web可视化与高效调试实战 在视觉SLAM研究领域,环境配置往往是阻碍开发者快速上手的首要障碍。不同版本的依赖库冲突、系统环境差异导致的运行失败,这些问题消耗了研究者大量本该用于算法创新的宝贵时间。本…...

终极指南:用ViGEmBus免费解决Windows游戏手柄兼容性难题
终极指南:用ViGEmBus免费解决Windows游戏手柄兼容性难题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况:…...

HDLbits进阶实战:FSM与移位寄存器在复杂时序电路中的四种设计范式
1. 有限状态机与移位寄存器协同设计基础 在数字电路设计中,有限状态机(FSM)和移位寄存器就像是一对黄金搭档。FSM负责控制流程,而移位寄存器则擅长处理数据流。当它们配合使用时,可以解决许多复杂的时序逻辑问题。 我刚…...

PlayCover完整指南:在Apple Silicon Mac上运行iOS应用与游戏的终极解决方案
PlayCover完整指南:在Apple Silicon Mac上运行iOS应用与游戏的终极解决方案 【免费下载链接】PlayCover Community fork of PlayCover 项目地址: https://gitcode.com/gh_mirrors/pl/PlayCover PlayCover是一个革命性的开源工具,专门为Apple Sili…...

编程应届生面试,HR最常问的20个问题,高分答案都在这里
文章目录前言一、自我认知类:HR想知道你是不是“对的人”问题1:请你做一个3分钟的自我介绍问题2:你最大的优点和缺点是什么?问题3:你为什么选择这个专业/行业?二、职业规划类:看你能不能在公司待…...

AI教材写作必备!低查重AI工具,一键生成20万字教材无压力!
写教材工具的选择困境与解决方案 在编写教材之前,选择合适的工具真的是“纠结无比”啊!如果选择办公软件的话,它的功能实在太限制,像框架搭建和格式规范都得亲自来弄;如果选专业的编写工具,操作又显得复杂…...
)
告别漫长等待:用Anaconda一行命令搞定XGBoost-GPU版安装(Windows/Linux通用)
告别漫长等待:用Anaconda一行命令搞定XGBoost-GPU版安装(Windows/Linux通用) 在机器学习领域,XGBoost因其出色的性能和广泛的应用场景而备受推崇。然而,当面对大规模数据集时,传统的CPU计算往往显得力不从心…...

对比直接使用厂商API,通过Taotoken聚合调用在运维与成本上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,通过Taotoken聚合调用在运维与成本上的优势 当开发者需要集成多个大语言模型时,直接对…...

5分钟快速上手:ComfyUI ControlNet预处理器终极指南
5分钟快速上手:ComfyUI ControlNet预处理器终极指南 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想要让AI图像生成完全按照你的想法来吗&am…...

如何让桌面宠物成为你的数字工作伙伴?DyberPet开源框架全解析
如何让桌面宠物成为你的数字工作伙伴?DyberPet开源框架全解析 【免费下载链接】DyberPet Desktop Cyber Pet Framework based on PySide6 项目地址: https://gitcode.com/GitHub_Trending/dy/DyberPet 你是否曾在长时间工作时感到孤独,渴望有个可…...