【Linux】多线程 -> 从线程概念到线程控制
线程概念
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”。
- 一切进程至少都有一个执行线程。
- 线程在进程内部运行,本质是在进程地址空间内运行。
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化。
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。
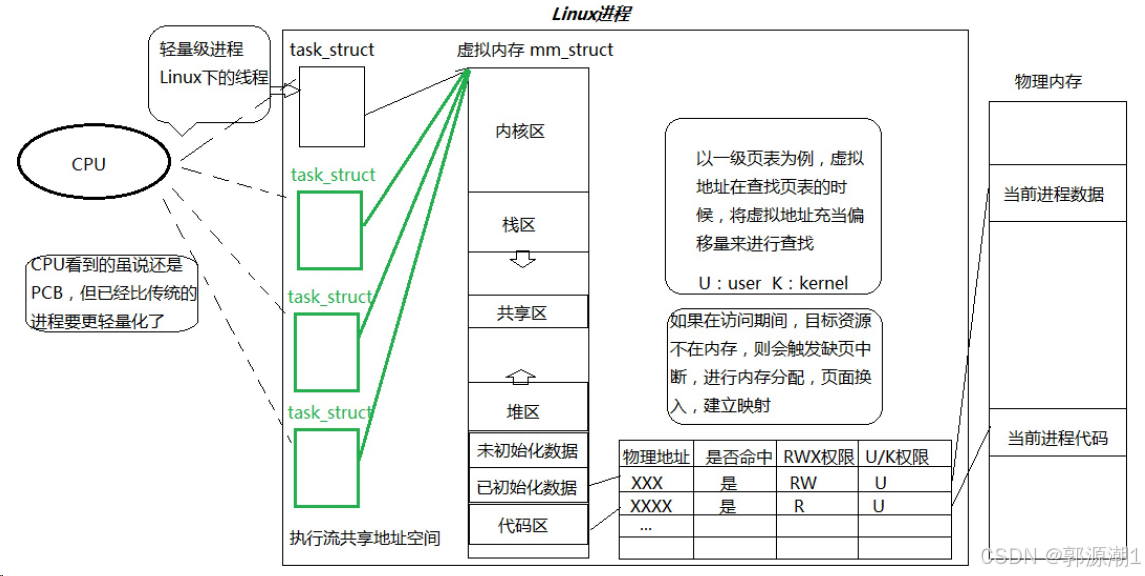
- Linux内核中没有真正意义的线程。
- Linux是用进程PCB来模拟线程的,是一种完全属于自己的一套线程方案。
- 站在CPU的视角,每一个PCB,都可以称之为轻量级进程。
- 进程是用来整体申请资源的,而线程是用来向进程要资源的。
- 线程是CPU调度的基本单位,进程是承担分配系统资源的实体。
使用进程PCB来模拟线程,这样做的好处是什么?
简单,维护成本大大降低,可靠高效。不需要再为线程创建对应的数据结构和算法。
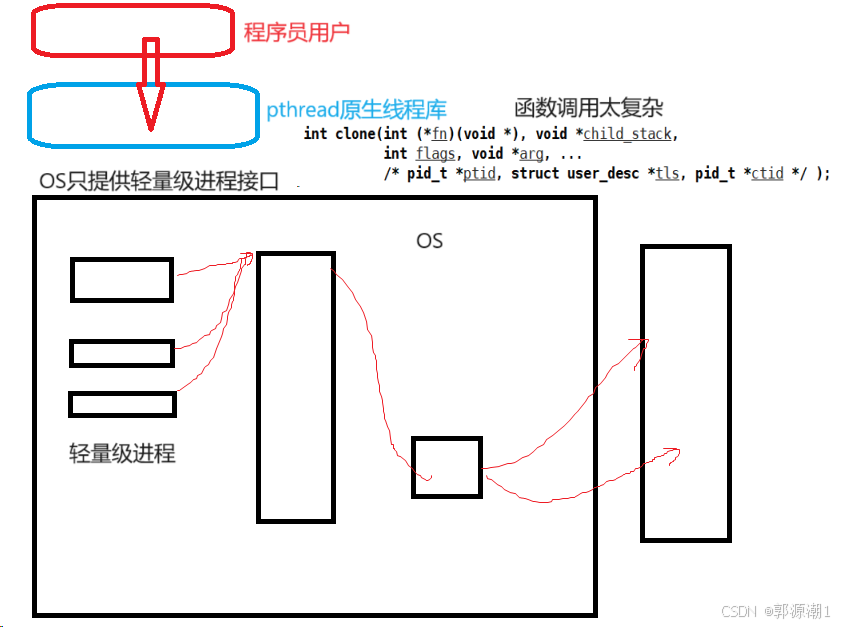
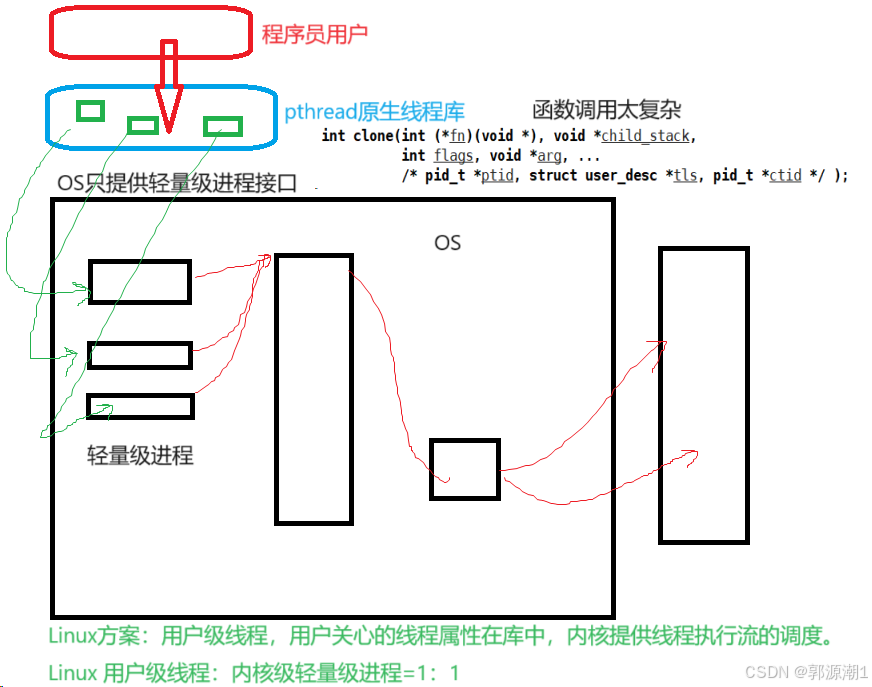
但是OS只认线程,用户(程序员)也只认线程而Linux无法直接提供创建线程的系统调用接口!只能给我们提供创建轻量级进程的接口!
pthread库
使用用户级线程库pthread库,对上(用户)提供对线程操作相关接口,对下(操作系统),访问底层相关接口,将对线程的操作转换为对轻量级进程的相关操作,任何Linux操作系统,都必须默认携带这个库,称之为原生线程库。使用户可以在不了解底层实现细节的情况下进行多线程编程。
pthread_create()
- 创建新线程。

thread:返回线程ID。
attr:设置线程属性(线程栈大小,调度策略等),指向pthread_attr_t 类型的结构体指针。设置为NULL,表示使用线程默认属性。
start_routine:函数地址,指向线程启动后要执行的函数。
arg:传递给start_routine的参数。由于start_routine函数的参数类型为void *,所以可以传递任意类型的数据,传递前转换为void *类型即可,在start_routine函数内部再将其转换回原来的类型。
成功返回0;失败返回错误码。
makefile:
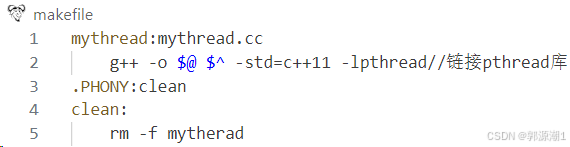
mythread.cc:
#include <iostream>
#include <cassert>
#include <pthread.h>
#include <unistd.h>
#include <cstdio>using namespace std;void *thread_routine(void *args)
{const char *name = (const char *)args;while (true){cout << "我是新线程,我正在运行! name: " << name << endl;sleep(1);}
}int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, thread_routine, (void *)"thread one");assert(0 == n);(void)n;// 主线程while (true){cout << "我是主线程,我正在运行!" << endl;sleep(1);}return 0;
}

可以看到这两个执行流PID相同,说明他们是属于同一个进程的。LWP(Light Weight Proces轻量级进程ID)不同。既然线程是CPU调度的基本单位,前提是线程要具有标识符来标定自己的唯一性。
PID和LWP相同的是主线程。PID和LWP不相同的是新线程。
- CPU调度的时候,是以哪一个ID为标识符表示特定的一个执行流呢?
LWP。OS在内部以LWP就可以完成对进程的区分。即便只有一个单进程,也有LWP,也就是OS调度的时候只关心LWP。
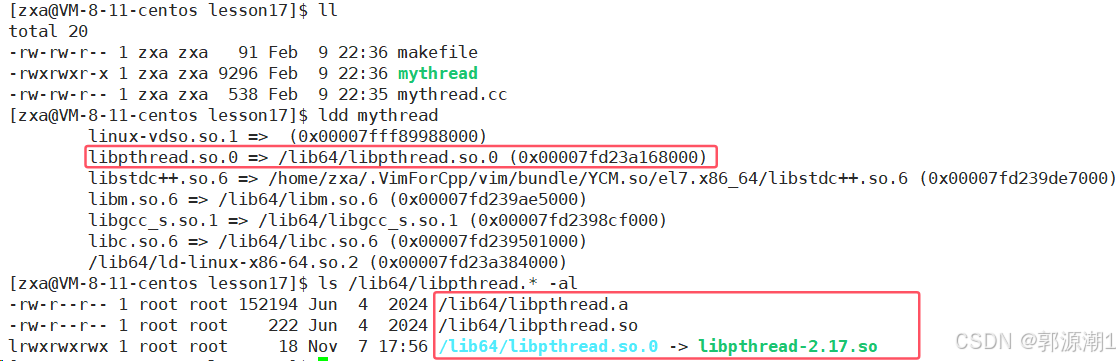
可以看到程序依赖的动态库(.so)和静态库(.a)。
线程一旦被创建,几乎所有的资源都是被线程共享的。在进程地址空间中,大部分区域都是被该进程内的多个线程所共享的。
如:代码段、数据段、堆、文件描述符表、信号处理方式、当前工作目录、用户ID和组ID。
mythread.cc:
#include <iostream>
#include <cstdio>
#include <cassert>
#include <pthread.h>
#include <unistd.h>using namespace std;int g_val = 0;string fun()
{return "我是一个独立的方法";
}// 新线程
void *thread_routine(void *args)
{const char *name = (const char *)args;while (true){fun();cout << "我是新线程, 我正在运行! name: " << name << " : "<< fun() << " : " << g_val++ << " &g_val : " << &g_val << endl;sleep(1);}
}int main()
{// typedef unsigned long int pthread_t;pthread_t tid;//这个tid是什么下面讲int n = pthread_create(&tid, nullptr, thread_routine, (void *)"thread one");assert(0 == n);(void)n;// 主线程while (true){char tidbuffer[64];snprintf(tidbuffer, sizeof(tidbuffer), "0x%x", tid);cout << "我是主线程, 我正在运行!, 我创建出来的线程的tid: " << tidbuffer << " : " << g_val << " &g_val : " << &g_val << endl;sleep(1);}return 0;
}
- 线程也一定要有自己的私有资源,什么资源是线程私有的呢?
线程私有资源
1、私有上下文数据结构
- 线程的上下文数据结构包含了线程在执行过程中的各种状态信息,这些信息是线程独有的,用于记录线程当前的执行进度和状态,确保线程在被调度执行时能够正确恢复之前的执行状态。(如寄存器值)
2、独立的栈结构
- 每个线程都有自己独立的栈空间,这是线程执行过程中用于存储局部变量、函数调用信息等的内存区域。
3、“TCB”属性
- 类似与进程PCB的“TCB”,用于存储线程相关属性,是线程私有的。(如线程ID、线程状态、调度优先级)
4、信号掩码
- 线程可以有自己独立的信号掩码,用于指定哪些信号会被阻塞。不同线程可以根据自己的需求设置不同的信号掩码,以控制对信号的处理。
5、errno变量
- 在 C 语言编程中,errno是一个全局变量,用于存储最近一次系统调用或库函数调用的错误码。但在多线程环境下,每个线程有自己独立的errno副本,这样可以避免不同线程之间的错误码相互干扰。
线程优点
- 创建一个新线程的代价要比创建一个新进程小得多。
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多。
- 线程占用的资源要比进程少很多。
- 能充分利用多处理器的可并行数量。
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务。
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程/进程切换
“线程与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多”
- 进程切换,需要切换 PCB、虚拟地址空间、页表、上下文。
- 线程切换,需要切换PCB、上下文。
页表就是保存在寄存器里的地址(寄存器里的一个值),虚拟地址空间也是PCB里的一个地址,PCB切换了虚拟地址空间也就切换了。进程切换的成本好像并不高。
- 那么为什么说线程切换与进程切换相比需要OS做的工作少很多呢?
线程切换cache不用太多的更新,但是进程切换,cache会全部更新。
Cache原理
- cache即高速缓冲存储器。它是一种特殊的高速存储器,用于减少CPU访问主存时的等待时间,提高 CPU 与主存之间的数据传输效率。
局部性原理:Cache 的工作基于程序访问的局部性原理,该原理包括时间局部性和空间局部性。时间局部性指的是程序在一段时间内可能会多次访问同一数据,比如循环中的变量;空间局部性则是指程序在访问某个数据时,很可能会紧接着访问其附近的数据,例如数组的顺序访问。
Cache 映射:Cache 将主存中的数据块按照一定的映射规则存储到 Cache 中。当 CPU 需要访问主存中的数据时,首先会在 Cache 中查找,如果数据存在于 Cache 中(即命中),则直接从 Cache 中读取,大大减少了访问时间;如果数据不在 Cache 中(即未命中),则需要从主存中读取该数据,并将其所在的数据块调入 Cache,以备后续可能的再次访问。
线程切换与Cache
- Cache 复用优势:当一个进程内进行线程切换时,由于同一进程内的多个线程共享进程的地址空间和大部分资源,这些线程所访问的热点数据通常是相似的。所以在 Cache 中已经缓存的热点数据对于不同线程来说都可能是有用的。线程切换时,不需要对 Cache 进行切换操作,新线程可以直接复用 Cache 中已有的数据,这大大提高了数据的访问效率。
- 减少 Cache 缺失开销:线程切换不涉及 Cache 数据的替换和重新加载,降低了 Cache 缺失的概率。Cache 缺失会导致 CPU 需要从主存中读取数据,这会带来较大的时间开销。线程切换时能继续使用 Cache 中的数据,就避免了这种因 Cache 缺失而产生的额外开销,使得系统整体性能更优。
进程切换与Cache
- Cache 失效问题:进程拥有独立的地址空间,不同进程访问的数据通常是不同的。当进行进程切换时,原来进程在 Cache 中缓存的数据对于新进程来说可能是无用的,这些数据会被视为失效数据。为了给新进程的缓存数据腾出空间,Cache 中的原有数据可能会被替换出去。
- 重新缓存成本高:新进程开始执行后,由于 Cache 中没有其所需的热点数据,需要重新从主存中读取数据并缓存到 Cache 中。这个重新缓存的过程需要花费一定的时间,在这段时间内,CPU 可能会处于等待状态,导致系统效率降低。而且当原来的进程再次被调度执行时,又需要重新缓存它所需的数据,进一步增加了时间开销。
线程缺点
1、性能损失
- 一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
2、健壮性降低
- 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
3、缺乏访问控制
- 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
4、编程难度提高
- 编写与调试一个多线程程序比单线程程序困难得多。
验证线程的健壮性问题:
- 如果一个线程出现异常了,会影响其他线程吗?为什么?
mythread.cc:
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>using namespace std;void *start_routine(void *args)
{//如果一个线程异常了,会影响其他线程吗?string name = static_cast<const char *>(args); // 安全的进行强制类型转换while (true){cout << "new thread create success, name: " << name << endl;sleep(1);int *p = nullptr;*p = 0;}
}int main()
{pthread_t id;pthread_create(&id, nullptr, start_routine, (void *)"thread new");while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}
可以看到,一个线程出现异常会直接影响其他线程,说明线程健壮性或者鲁棒性较差。
为什么呢?信号是整体发送给进程的,当当前进程发生异常时,因为所有线程的PID都一样,所以OS会给所有线程发送相应的信号。一个进程创建时要申请资源,异常退出时要回收资源,进程的资源都被释放了,线程赖以生存的资源也不存在了,所以其他线程也要退出。
线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出。
线程用途
- 合理的使用多线程,能提高计算密集型程序(如:CPU、加密、解密、算法等)的执行效率。比如要对一个10g的文件进行压缩,单进程可能只能用一个CPU资源或者一部分CPU资源,读取、压缩、写入操作是顺序执行的,没有并行性。如果是多线程的话,可以使用两个线程在不同的CPU核心上并行执行,同时压缩,一个线程压缩5g。
- 合理的使用多线程,能提高IO密集型程序(如:外设、访问磁盘、显示器、网络)的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
线程创建
-
pthread_create()


fork和vfork都是创建子进程,vfork创建的子进程和父进程共享地址空间,其实就是轻量级进程的概念。操作系统提供的创建轻量级进程的接口是clone(),函数调用太复杂。用户也不使用。

接下来我们试着创建多个线程。
mythread.cc:
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <pthread.h>
#include <unistd.h>using namespace std;void *start_routine(void *args)
{string name = static_cast<const char *>(args); // 安全的进行强制类型转换while (true){cout << "new thread create success, name: " << name << endl;sleep(1);}
}int main()
{vector<pthread_t> tids;
#define NUM 10for (int i = 0; i < NUM; i++){pthread_t tid;char namebuffer[64];snprintf(namebuffer, sizeof(namebuffer), "%s:%d", "thread", i);pthread_create(&tid, nullptr, start_routine, namebuffer);//sleep(1);}while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}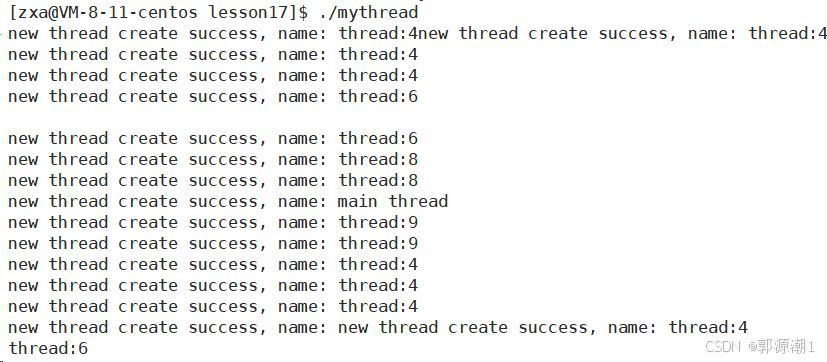
注意:可能导致:
1、名称重复问题
新线程被创建出来谁先运行并不确定,是由CPU调度器决定的。传递给"pthread_create"的是缓冲区的地址,namebuffer当作参数传递给线程函数start_routine。线程创建是异步操作,可能创建出来的线程还没来得及执行,主线程就开始执行了,namebuffer就会被覆盖,即新线程也许会在namebuffer被下一次循环覆盖后才开始执行。所以多个线程读取到的可能是同一个已经被修改的namebuffer,进而造成输出中多个线程输出相同的名称,像输出里多次出现的thread:4、thread:6、thread:8等。
2.、输出混乱问题
输出中出现类似 “new thread create success,name: new thread create success,name : thread:4 这样混乱的情况,是因为多个线程同时对标准输出(std::cout)进行写入操作。std::cout并非线程安全的,当多个线程同时向其写入数据时,就可能导致输出内容相互穿插、混乱。
我们将代码调整一下:
for (int i = 0; i < NUM; i++){pthread_t tid;char namebuffer[64];snprintf(namebuffer, sizeof(namebuffer), "%s:%d", "thread", i);pthread_create(&tid, nullptr, start_routine, namebuffer);sleep(1);} 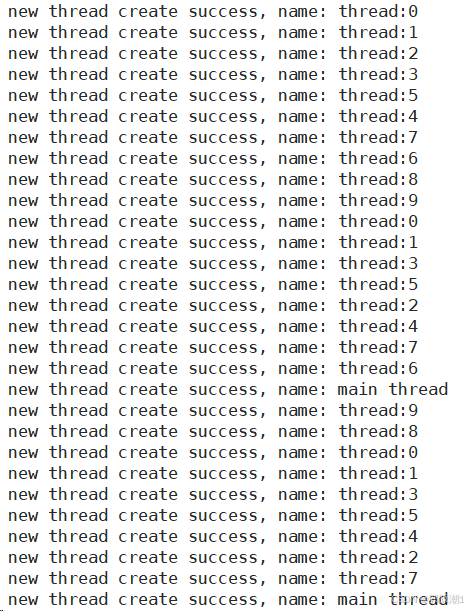
注意:
1、不加sleep
名称重复问题加剧:由于线程创建是异步的,且多个线程共享同一个namebuffer,如果不加sleep,线程创建速度会很快,namebuffer会被快速覆盖,更多的线程可能会读取到相同的被修改后的namebuffer,导致输出中名称重复的现象更加严重。
2、加sleep
名称重复问题缓解:每次创建线程后休眠 1 秒,给新线程足够的时间读取namebuffer中的名称,减少了namebuffer被覆盖的可能性,从而在一定程度上缓解了名称重复的问题。
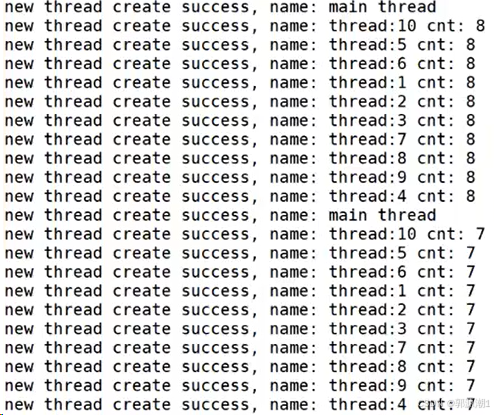
我们想创建多个线程,线程大部分资源都是共享的,所以这种定义局部变量缓冲区的方式其实是不太对的。应该使用下面这种方式:
mythread.cc:
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <pthread.h>
#include <unistd.h>using namespace std;// 当成结构体使用class ThreadData
{
public:pthread_t tid;char namebuffer[64];
};void *start_routine(void *args)
{sleep(1);vector<ThreadData *> threads;ThreadData *td = static_cast<ThreadData *>(args); // 安全的进行强制类型转换int cnt = 10;while (cnt){cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;sleep(1);}delete td;return nullptr;
}int main()
{#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);}while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}
可以将创建的线程打印出来看一下。
mythread.cc:
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <pthread.h>
#include <unistd.h>using namespace std;// 当成结构体使用class ThreadData
{
public:pthread_t tid;char namebuffer[64];
};void *start_routine(void *args)
{sleep(1);vector<ThreadData *> threads;ThreadData *td = static_cast<ThreadData *>(args); // 安全的进行强制类型转换int cnt = 10;while (cnt){cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;sleep(1);}delete td;return nullptr;
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << ":" << iter->tid << " success" << endl;}while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}
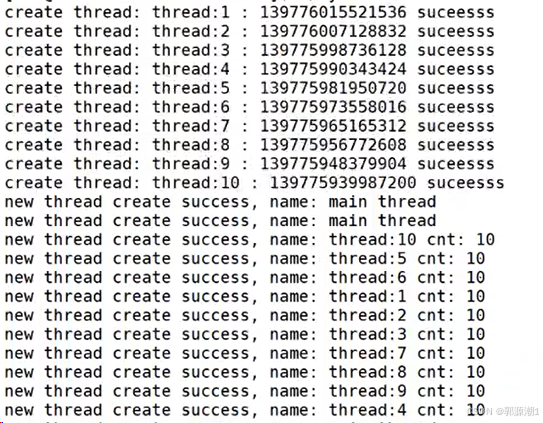
每一个线程都会new一个ThreadData对象。将该对象传递给pthread_create。作为start_routine的参数。
- 当线程执行start_toutine函数,内部的变量ThreadData *td、cnt会不会影响其他线程呢?
mythread.cc:
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <pthread.h>
#include <unistd.h>using namespace std;// 当成结构体使用class ThreadData
{
public:pthread_t tid;char namebuffer[64];
};void *start_routine(void *args)
{sleep(1);vector<ThreadData *> threads;ThreadData *td = static_cast<ThreadData *>(args); // 安全的进行强制类型转换int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt" << &cnt << endl;cnt--;//cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;sleep(1);}delete td;return nullptr;
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << ":" << iter->tid << " success" << endl;}while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}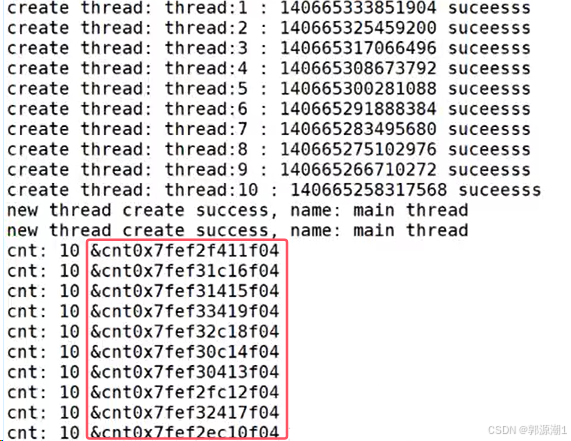
在语言级别上,在函数内部定义的变量属于局部变量,具有临时性,这里依旧使用。在多线程情况下,也没问题,每一个线程都有自己独立的栈结构!
在多线程环境中,每个线程都有自己独立的栈结构。这意味着每个线程调用同一个函数时,都会在自己的栈上为函数内部的局部变量分配内存,各个线程的局部变量是相互独立的,一个线程对其局部变量的操作不会影响其他线程的同名局部变量。
线程终止
-
return()
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <pthread.h>
#include <unistd.h>using namespace std;// 当成结构体使用class ThreadData
{
public:pthread_t tid;char namebuffer[64];
};void *start_routine(void *args)
{sleep(1);vector<ThreadData *> threads;ThreadData *td = static_cast<ThreadData *>(args); // 安全的进行强制类型转换int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt" << &cnt << endl;cnt--;//cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;sleep(1);//使用return终止return nullptr;}delete td;//return nullptr;
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << ":" << iter->tid << " success" << endl;}while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}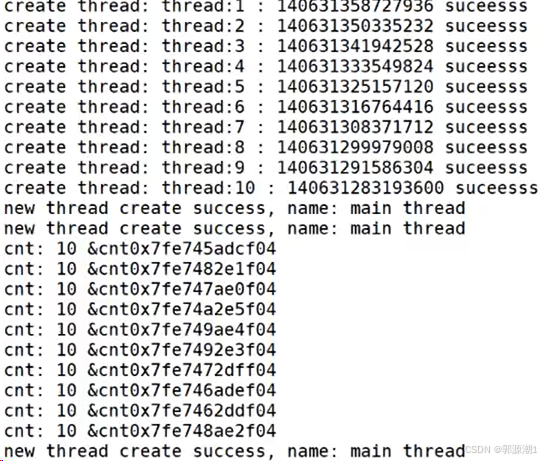
可以使用return直接终止线程。
-
pthread_exit()

#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <pthread.h>
#include <unistd.h>using namespace std;// 当成结构体使用class ThreadData
{
public:pthread_t tid;char namebuffer[64];
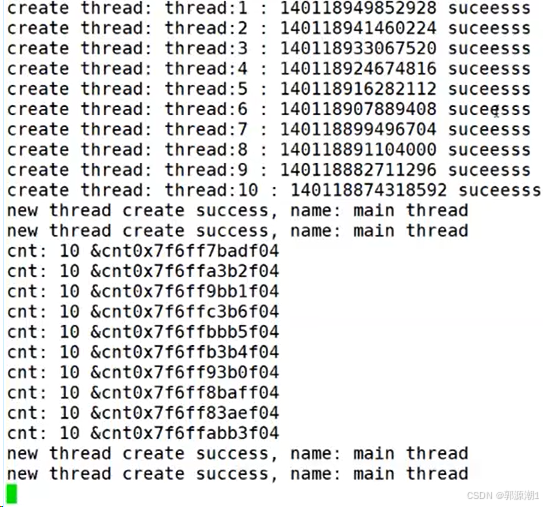
};void *start_routine(void *args)
{sleep(1);vector<ThreadData *> threads;ThreadData *td = static_cast<ThreadData *>(args); // 安全的进行强制类型转换int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt" << &cnt << endl;cnt--;//cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;sleep(1);//使用pthread_exit终止pthread_exit(nullptr);}delete td;//return nullptr;
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << ":" << iter->tid << " success" << endl;}while (true){cout << "new thread create success, name: main thread" << endl;sleep(1);}return 0;
}
线程等待
-
pthread_join()
线程也是要被等待的,如果不等待会造成类似僵尸进程的问题,内存泄漏。
1、获取新线程的退出信息。已经退出的线程,其空间没有被释放,仍然在进程的地址空间。
2、回收新线程对应的“TCB”等内核资源,防止内核泄漏(这个现象我们暂时无法查看)。

成功返回0;失败返回错误码。
mythread.cc:
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <cassert>
#include <pthread.h>
#include <unistd.h>using namespace std;// 当成结构体使用class ThreadData
{
public:pthread_t tid;char namebuffer[64];
};void *start_routine(void *args)
{// sleep(1);vector<ThreadData *> threads;ThreadData *td = static_cast<ThreadData *>(args); // 安全的进行强制类型转换int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt:" << &cnt << endl;cnt--;// cout << "new thread create success, name: " << td->namebuffer << " cnt: " << cnt-- << endl;sleep(1);// 使用return终止// return nullptr;}// delete td;pthread_exit(nullptr);
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << ":" << iter->tid << " success" << endl;}// 线程等待for (auto &iter : threads){int n = pthread_join(iter->tid, nullptr);assert(0 == n);cout << "join : " << iter->namebuffer << " success" << endl;delete iter;}cout << "main thread quit " << endl;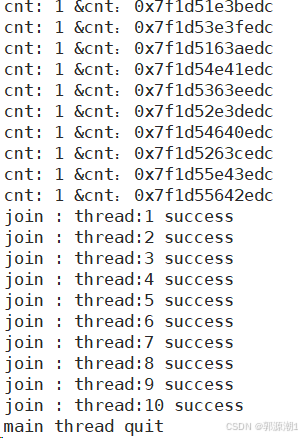
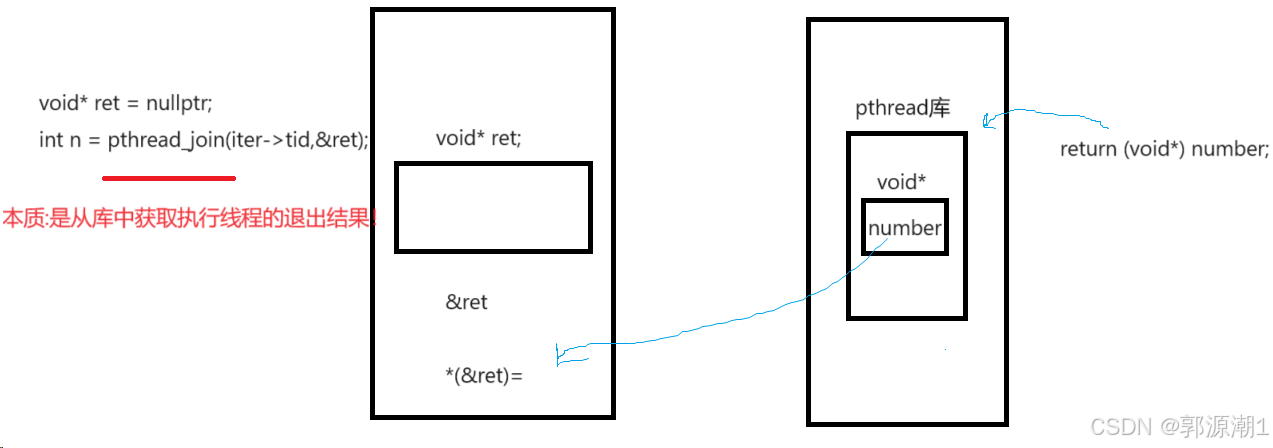
线程退出时的返回值问题
无论是return退出,还是调用pthread_exit返回,都要传入一个参数void*类型的。
![]()
当线程退出时,pthread_join获取线程的退出结果。
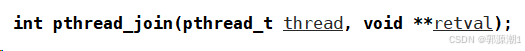
参数类型都是void*类型。
![]()
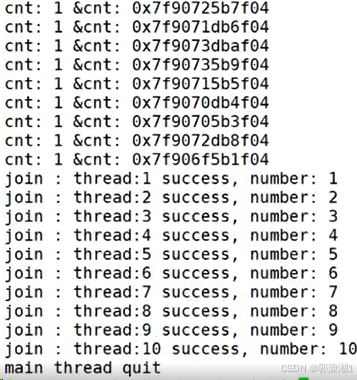
如果我们想在线程退出的时候,获取我们自定义的返回值线程编号。
mythread.cc:
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <cassert>
#include <pthread.h>
#include <unistd.h>using namespace std;class ThreadData
{
public:int number;pthread_t tid;char namebuffer[64];
};void *start_routine(void *args)
{ThreadData *td = static_cast<ThreadData *>(args); int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt:" << &cnt << endl;cnt--;sleep(1);}return (void* )td->number; //void* ret = (void*)td->number;//这里把int类型的8字节数据转换为4字节的指针会警告,但是我们不用管。
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();td->number = i + 1;snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << ":" << iter->tid << " success" << endl;}// 线程等待for (auto &iter : threads){void *ret = nullptr;//注意:是void*int n = pthread_join(iter->tid, &ret);//函数内部会做 eg:void** retp = &ret; *retp = return (void*) td->number;assert(0 == n);cout << "join : " << iter->namebuffer << " success, number: " << (long long)ret << endl;delete iter;}cout << "main thread quit " << endl;return 0;
}
- 既然假的地址,整数的地址都能被外部拿到,那么返回的是,堆空间的地址呢?对象的地址呢?
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <cassert>
#include <pthread.h>
#include <unistd.h>using namespace std;class ThreadData
{
public:int number;pthread_t tid;char namebuffer[64];
};class ThreadReturn
{
public:int exit_code;int exit_result;
};void *start_routine(void *args)
{ThreadData *td = static_cast<ThreadData *>(args); int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt:" << &cnt << endl;cnt--;sleep(1);}// return (void *)td->number; // void* ret = (void*)td->number;// 这里把int类型的8字节数据转换为4字节的指针会警告,但是我们不用管。// 既然假的地址,整数的地址都能被外部拿到,那么返回的是,堆空间的地址呢?对象的地址呢?ThreadReturn *tr = new ThreadReturn();// 假设tr->exit_code = 1;tr->exit_result = 222;return (void *)tr;// 注意:下面这种写法是错误的。// ThreadReturn tr;// tr->exit_code=1;// tr->exit_result=222;// return (void*)tr;// tr是在栈上开辟的空间,出了栈就被销毁了。
}int main()
{vector<ThreadData *> threads;
#define NUM 10for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();td->number = i + 1;snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << " : " << iter->tid << " success" << endl;}// 线程等待for (auto &iter : threads){ThreadReturn *ret = nullptr;// void *ret = nullptr; // 注意:是void*int n = pthread_join(iter->tid, (void **)&ret); // 函数内部会做 eg:void** retp = &ret; *retp = return (void*) td->number;assert(0 == n);// cout << "join : " << iter->namebuffer << " success, number: " << (long long)ret << endl;cout << "join : " << iter->namebuffer << " success, exit_code: " << ret->exit_code << ",exit_result: " << ret->exit_result << endl;delete iter;}cout << "main thread quit " << endl;// while (true)// {// cout << "new thread create success, name: main thread" << endl;// sleep(1);// }return 0;
}
调用该函数的线程将挂起等待,直到ID为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的:
- 如果thread线程通过return返回,value_ ptr所指向的单元里存放的是thread线程函数的返回值。
- 如果thread线程被别的线程调用pthread_ cancel异常终掉,value_ ptr所指向的单元里存放的是常数PTHREAD_ CANCELED。
- 如果thread线程是自己调用pthread_exit终止的,value_ptr所指向的单元存放的是传给pthread_exit的参数。
- 如果对thread线程的终止状态不感兴趣,可以传NULL给value_ ptr参数。

- 这里有一个问题,线程退出的时候,为什么没有见到线程退出对应的退出信号呢?
线程出异常,收到信号,整个进程都会退出!pthread_join()默认认为函数会调用成功!不考虑异常问题,异常问题是进程考虑的问题!
线程取消
-
pthread_cacel()

线程是可以被取消的!注意:线程要被取消的前提是这个线程已经跑起来了正在执行。
#include <iostream>
#include <vector>
#include <string>
#include <cstdio>
#include <cassert>
#include <pthread.h>
#include <unistd.h>using namespace std;class ThreadData
{
public:int number;pthread_t tid;char namebuffer[64];
};class ThreadReturn
{
public:int exit_code;int exit_result;
};void *start_routine(void *args)
{// sleep(1);ThreadData *td = static_cast<ThreadData *>(args); int cnt = 10;while (cnt){cout << "cnt: " << cnt << " &cnt:" << &cnt << endl;cnt--;sleep(1);}return (void *)111;
}int main()
{vector<ThreadData *> threads;
#define NUM 10//线程创建for (int i = 0; i < NUM; i++){ThreadData *td = new ThreadData();td->number = i + 1;snprintf(td->namebuffer, sizeof(td->namebuffer), "%s:%d", "thread", i + 1);pthread_create(&td->tid, nullptr, start_routine, td);threads.push_back(td);}for (auto &iter : threads){cout << "create thread: " << iter->namebuffer << " : " << iter->tid << " success" << endl;}// 线程取消sleep(5);for (int i = 0; i < threads.size() / 2; i++){pthread_cancel(threads[i]->tid);cout << "pthread_cancel : " << threads[i]->namebuffer << " success" << endl;}// 线程等待for (auto &iter : threads){void *ret = nullptr;int n = pthread_join(iter->tid, &ret);assert(0 == n);cout << "join : " << iter->namebuffer << " success, exit_code: " << (long long)ret << endl;delete iter;}cout << "main thread quit " << endl;return 0;
}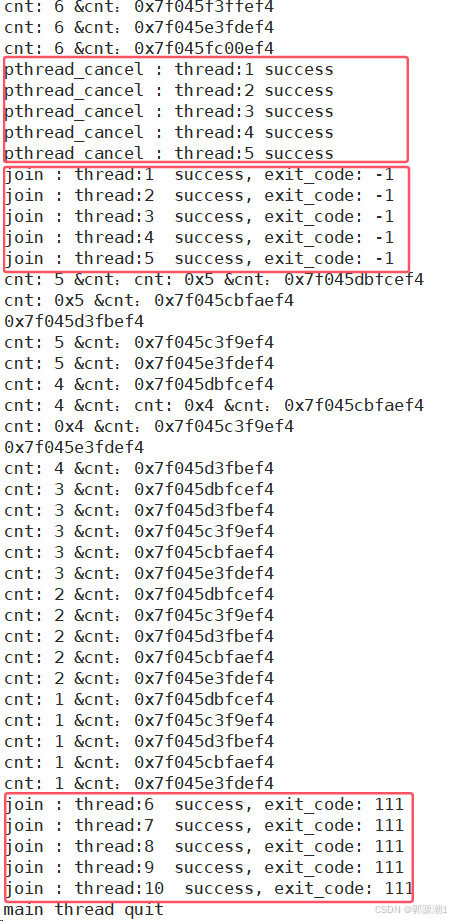
线程如果是被取消的,退出码为-1。
分离线程
线程是可以等待的,等待的时候,join的等待是阻塞式等待。如果我们不想等待呢?
默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
-
pthread_self()
获取线程ID。

mythread.cc:
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <string>
#include <pthread.h>// 获取线程id
std::string changeId(const pthread_t &thread_id)
{char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid;
}void *start_routine(void *args)
{std::string threadname = static_cast<const char *>(args);int cnt = 5;while (cnt--){std::cout << threadname << " running... " << changeId(pthread_self()) << std::endl;sleep(1);}return nullptr;
}int main()
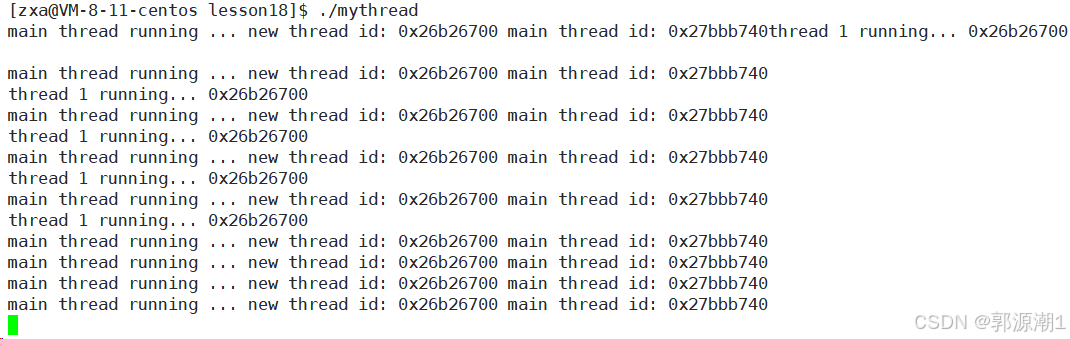
{pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread 1");std::string main_id = changeId(pthread_self());std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;int n = pthread_join(tid, nullptr);std::cout << "result: " << n << " : " << strerror(n) << std::endl;return 0;
}
-
pthread_detach()
分离线程。

mythread.cc:
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <string>
#include <pthread.h>// 获取线程id
std::string changeId(const pthread_t &thread_id)
{char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid;
}void *start_routine(void *args)
{std::string threadname = static_cast<const char *>(args);pthread_detach(pthread_self());//设置自己为分离状态int cnt = 5;while (cnt--){std::cout << threadname << " running... " << changeId(pthread_self()) << std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread 1");std::string main_id = changeId(pthread_self());std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;//一个线程默认是joinable的,如果设置了分离状态,不能进行等待了int n = pthread_join(tid, nullptr);std::cout << "result: " << n << " : " << strerror(n) << std::endl;return 0;
}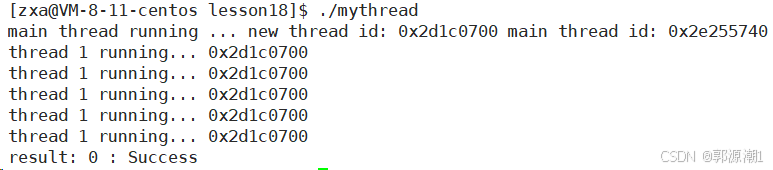
- 新线程不是分离了吗?怎么还是被join了。
新线程和主线程创建出来,谁先运行并不确定。那么就可能存在,新线程还没有pthread_detach分离,主线程就已经pthread_join阻塞等待了,新线程再分离,主线程也不知道。
我们来证明一下上面的说法,让主线程慢一下sleep两秒,新线程此时一定已经分离了。
mythread.cc:
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <string>
#include <pthread.h>// 获取线程id
std::string changeId(const pthread_t &thread_id)
{char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid;
}void *start_routine(void *args)
{std::string threadname = static_cast<const char *>(args);pthread_detach(pthread_self());//设置自己为分离状态int cnt = 5;while (cnt--){std::cout << threadname << " running... " << changeId(pthread_self()) << std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread 1");std::string main_id = changeId(pthread_self());std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;sleep(2);//一个线程默认是joinable的,如果设置了分离状态,不能进行等待了int n = pthread_join(tid, nullptr);std::cout << "result: " << n << " : " << strerror(n) << std::endl;return 0;
}
这样做是不是有点不太好啊,新线程要分离,主线程还要sleep慢一点。其实在分离线程可以让主线程分离新线程。
mythread.cc:
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <string>
#include <pthread.h>// 获取线程id
std::string changeId(const pthread_t &thread_id)
{char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid;
}void *start_routine(void *args)
{std::string threadname = static_cast<const char *>(args);//pthread_detach(pthread_self());//设置自己为分离状态int cnt = 5;while (cnt--){std::cout << threadname << " running... " << changeId(pthread_self()) << std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread 1");std::string main_id = changeId(pthread_self());pthread_detach(tid);std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;//sleep(2);//一个线程默认是joinable的,如果设置了分离状态,不能进行等待了int n = pthread_join(tid, nullptr);std::cout << "result: " << n << " : " << strerror(n) << std::endl;return 0;
}
一旦设置为分离状态,主线程就不需要等待了可以做自己的事情,不用再关心新线程了。joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
mythread.cc:
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <string>
#include <pthread.h>// 获取线程id
std::string changeId(const pthread_t &thread_id)
{char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid;
}void *start_routine(void *args)
{std::string threadname = static_cast<const char *>(args);// pthread_detach(pthread_self());//设置自己为分离状态int cnt = 5;while (cnt--){std::cout << threadname << " running... " << changeId(pthread_self()) << std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread 1");std::string main_id = changeId(pthread_self());pthread_detach(tid);std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;// sleep(2);// 一个线程默认是joinable的,如果设置了分离状态,不能进行等待了// int n = pthread_join(tid, nullptr);// std::cout << "result: " << n << " : " << strerror(n) << std::endl;while (true){std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;sleep(1);}return 0;
}
初步重新认识线程库(语言版)
C++也支持多线程。
makefile:
mythread.cc:
#include <iostream>
#include <unistd.h>
#include <thread>void thread_run()
{while (true){std::cout << "我是新线程..." << std::endl;sleep(1);}
}int main()
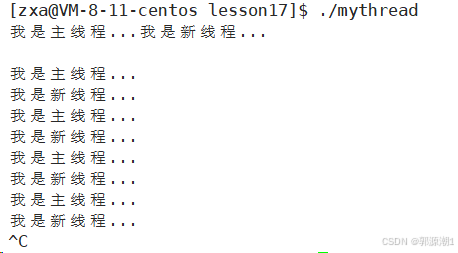
{std::thread t1(thread_run);while (true){std::cout << "我是主线程..." << std::endl;sleep(1);}t1.join();return 0;
}
makefile:
任何语言,在Linux中如果要实现多线程,必定要使用pthread库。
- 如何看待C++11中的多线程呢?
C++11的多线程,在Linux环境中,本质是对pthread库的封装。
语言能对pthread库做封装,这份代码在WINDOWS下也能运行,在WINDOWS中,语言帮我们解决了平台的差异化问题,是跨平台的。使用原生线程库创建线程叫做不可跨平台,只能在Linux下跑。
线程ID
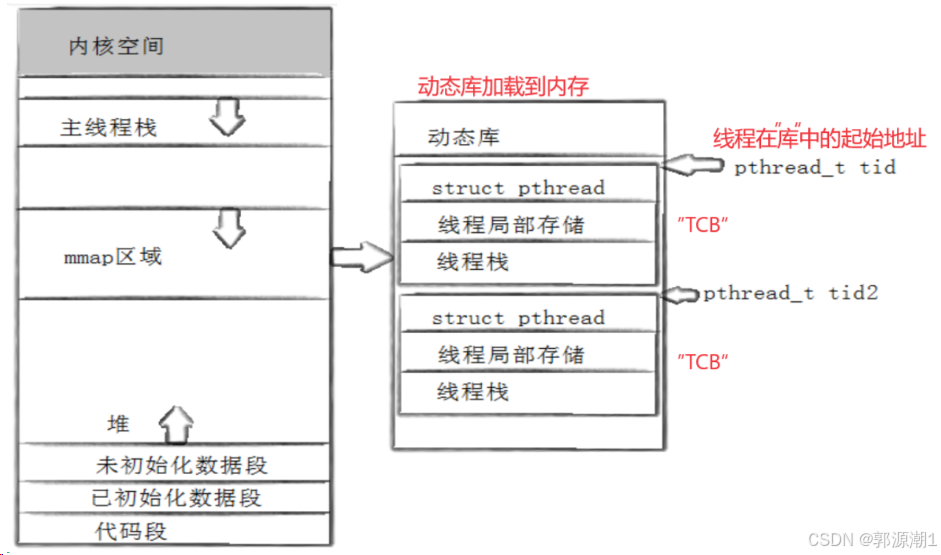
pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。
每个线程都有自己的独立栈结构。但是主线程的进程地址空间栈只有一个。
- 如何保证每个线程都有自己独立的栈结构呢?
原生线程库中,可能要存在多个线程,你用这个接口创建线程,别人可能同时在使用。原生线程库也要对线程做管理,先描述(线程属性(线程id,独立栈),比较少)再组织。
可以理解为线程是库实现了一部分,OS实现了一部分。当我们每创建一个线程,库都要创建线程所对应的结构体来进行线程控制。每一个结构体对应一个轻量级进程。在Linux中,这种线程称为用户级线程。
库不关心线程怎么调度,只关心线程是谁,线程id,栈大小等其他属性。
- 用户级线程id究竟是什么?
线程被创建出来之后,根据线程id就能找到这个线程,和线程对应的属性。用地址标识线程,当用户想使用某个线程时,拿着线程id就可以对线程进行相关操作了。
线程执行完,库自动将线程返回结果填到,该线程id指向的共享区的某个空间。join的时候根据线程id就能拿到发过来的返回值。
所以,主线程的栈是在进程地址空间,其他线程的栈在mmap区域中。
创建轻量级进程是库创建的,创建完之后,将线程id起始地址传给void *child_stack。底层在使用时使用的就是当前线程的栈而不是主线程的栈。
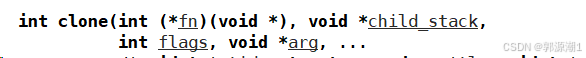
总结:
- 主线程是进程启动时默认创建的线程,它的栈空间通常由操作系统在创建进程时分配。这个栈空间用于存储主线程执行过程中的局部变量、函数调用信息(如返回地址、参数等)。主线程栈的大小一般由操作系统或编译环境决定,并且在进程的地址空间中有明确的位置。
- 当使用线程库创建线程时,库会负责为新线程分配栈空间。这个栈空间是在进程的地址空间内进行分配的,并且是新线程独有的,用来存储该线程的局部变量、函数调用上下文等信息。
- 在底层调用clone系统调用创建线程时,需要把新线程栈的起始地址传递给clone函数。在pthread库的实现中,会将分配好的栈的起始地址传递给相关的底层函数。
线程库的作用
线程库在创建线程时,会向操作系统请求分配一块内存区域作为新线程的栈。线程库负责管理线程栈的分配和释放,确保每个线程都有足够的栈空间来执行其代码。
线程的局部存储
mythread.cc:
#include <iostream>
#include <unistd.h>
#include <cstring>
#include <string>
#include <pthread.h>int g_val = 100;// 获取线程id
std::string changeId(const pthread_t &thread_id)
{char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid;
}void *start_routine(void *args)
{std::string threadname = static_cast<const char *>(args);// pthread_detach(pthread_self());//设置自己为分离状态int cnt = 5;while (true){std::cout << threadname << " running... " << changeId(pthread_self()) << " g_val: " << g_val << " &g_val " << &g_val << std::endl;g_val++;sleep(1);}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread 1");std::string main_id = changeId(pthread_self());pthread_detach(tid);std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << std::endl;// sleep(2);// 一个线程默认是joinable的,如果设置了分离状态,不能进行等待了// int n = pthread_join(tid, nullptr);// std::cout << "result: " << n << " : " << strerror(n) << std::endl;while (true){std::cout << "main thread running ... new thread id: " << changeId(tid) << " main thread id: " << main_id << " g_val: " << g_val << " &g_val " << &g_val << std::endl;sleep(1);}return 0;
}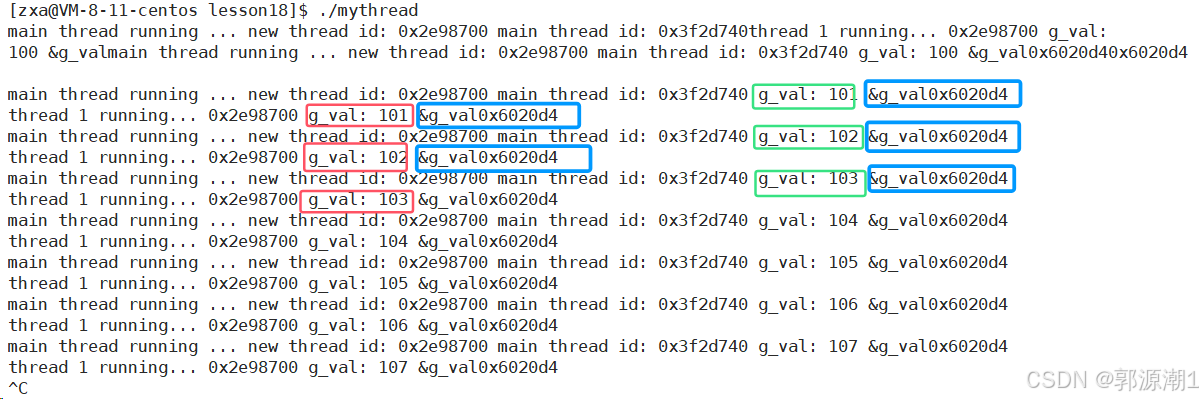
全局变量g_val被两个线程共享。
添加__thread,可以将一个内置类型设置为局部存储。
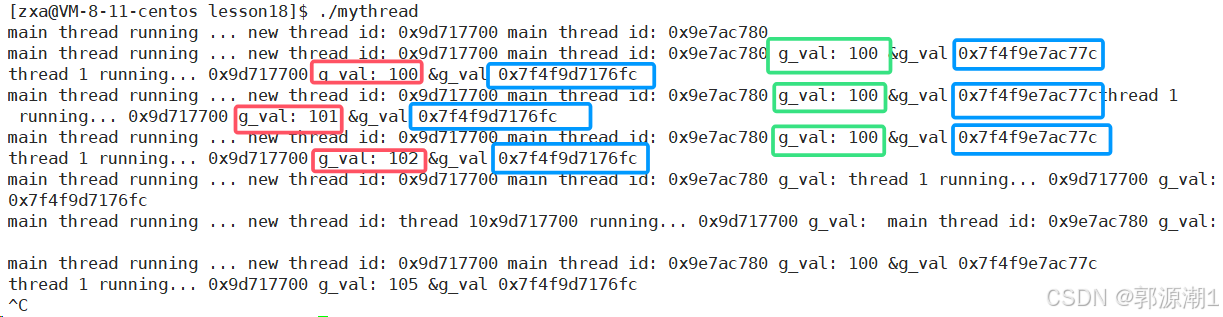
依旧是全局变量,只不过在编译的时候,给每个线程都有一份,这样线程在访问这个变量时,就不会互相影响。它为每个线程分配独立的变量副本,每个线程对该变量的操作不会影响其他线程中的同名变量。
- 第一次地址0x6020d4,第二次地址0x74f9d7176fc。地址差别这么大?
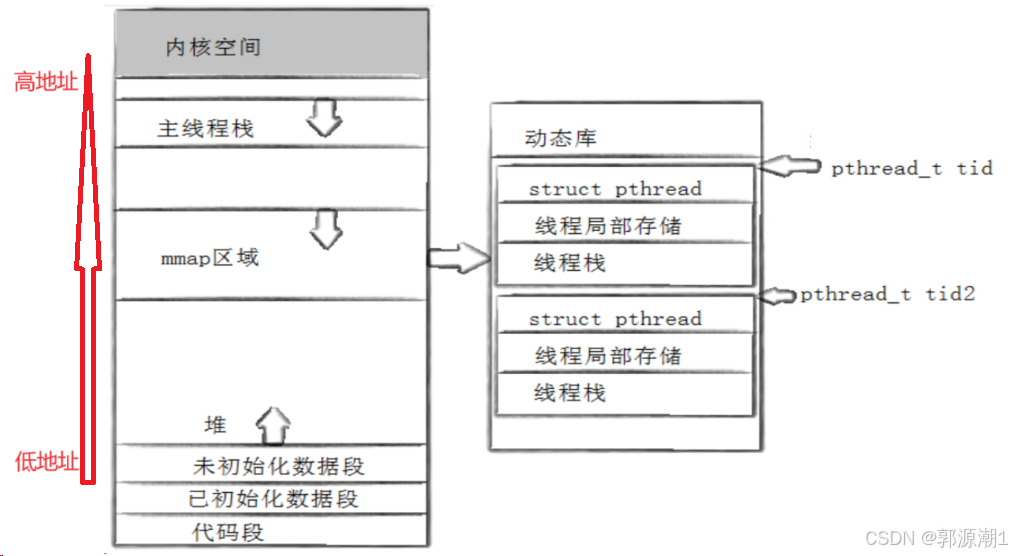
第一次全局变量在已初始化区域,为低地址,第二次将它设置为局部存储是在mmap区域,为高地址。
以上是线程控制的全部内容,关于线程更多的细节问题请看下篇...
相关文章:
【Linux】多线程 -> 从线程概念到线程控制
线程概念 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”。一切进程至少都有一个执行线程。线程在进程内部运行,本质是在进程地址空间内运行。在Linux系统中,在CPU眼…...

用什么办法能实现ubuntu里面运行的自己开发的python程序能自动升级。
要实现Ubuntu中自己开发的Python程序自动升级,可以通过以下几种方式: 1. 使用 Git 仓库 定时任务 如果你的Python程序托管在Git仓库中,可以通过定时拉取最新代码来实现自动升级。 步骤: 确保Python程序在Git仓库中。在Ubuntu上…...

java处理pgsql的text[]类型数据问题
背景 公司要求使用磐维数据库,于是去了解了这个是基于PostgreSQL构建的,在使用时有场景一条图片数据中可以投放到不同的页面,由于简化设计就放在数组中,于是使用了text[]类型存储;表结构 #这是一个简化版表结构&…...

LeetCode 热门100题-字母异位词分组
2.字母异位词分组 题目描述: 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs ["eat", "tea", "tan&q…...

耐张线夹压接图片智能识别
目录 一、图片压接部位定位1、图像准备2、人工标注3、训练4、推理5、UI界面 压接状态智能识别 一、图片压接部位定位 ,往往X射线照片是一个大图,进行图片压接部位定位目的是先找到需识别的部位,再进行识别时可排除其他图像部位的干扰&#x…...
)
ADC 的音频实验,无线收发模块( nRF24L01)
nRF24L01 采用 QFN20 封装,有 20 个引脚,以下是各引脚的详细介绍: 1. 电源引脚 ◦ VDD:电源输入端,一般接 3V 电源,为芯片提供工作电压,供电电压范围为 1.9V~3.6V。 ◦ VSS…...

企业SSL 证书管理指南
文章从以下几个部分展开 SSL证书的用途和使用场景SSL证书的申请类型和实现方式SSL证书的管理SSL证书的续签 一、SSL 证书的用途和使用场景 1.1 为什么要使用 SSL 证书? 1. 数据安全 🛡️- 在 HTTP 传输中,TCP 包可以被截获,攻…...

Python Pandas(7):Pandas 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。数据清洗与预处理的常见步骤: 缺失值处理:识别并…...

南京观海微电子----整流滤波电路实用
01 变压电路 通常直流稳压电源使用电源变压器来改变输入到后级电路的电压。电源变压器由初级绕组、次级绕组和铁芯组成。初级绕组用来输入电源交流电压,次级绕组输出所需要的交流电压。通俗的说,电源变压器是一种电→磁→电转换器件。即初级的交流电转化…...

【python】向Jira测试计划下,附件中增加html测试报告
【python】连接Jira获取token以及jira对象 # 往 jira 测试计划下面,上传测试结果html def put_jira_file(plain_id):# 配置连接jiraconn ConnJira()jira conn.jira_login()[2]path jira.issue(O45- plain_id)attachments_dir os.path.abspath(..) \\test_API…...

探索ChatGPT背后的前端黑科技
由于图片和格式解析问题,可前往 阅读原文 在人工智能与互联网技术飞速发展的今天,像ChatGPT这样的智能对话系统已经成为科技领域的焦点。它不仅能够进行自然流畅的对话,还能以多种格式展示内容,为用户带来高效且丰富的交互体验。然…...

Agents Go Deep 智能体深入探索
Agents Go Deep 智能体深入探索 核心事件 OpenAI发布了一款先进的智能体“深度研究”,它能借助网络搜索和推理生成研究报告。 最新进展 功能特性:该智能体依据数百个在线资源生成详细报告,目前仅支持文本输出,不过很快会增加对图…...

DeepSeek全生态接入指南:官方通道+三大云平台
DeepSeek全生态接入指南:官方通道三大云平台 一、官方资源入口 1.1 核心交互平台 🖥️ DeepSeek官网: https://chat.deepseek.com/ (体验最新对话模型能力) 二、客户端工具 OllamaChatboxCherry StudioAnythingLLM …...

c++TinML转html
cTinML转html 前言解析解释转译html类定义开头html 结果这是最终效果(部分):  前言 在python.tkinter设计标记语言(转译2-html)中提到了将Ti…...

STM32硬件SPI函数解析与示例
1. SPI 简介 SPI(Serial Peripheral Interface)即串行外设接口,是一种高速、全双工、同步的通信总线,常用于微控制器与各种外设(如传感器、存储器等)之间的通信。STM32 系列微控制器提供了多个 SPI 接口&a…...
滤波器:卡尔曼滤波
卡尔曼滤波(Kalman Filter)是一种高效的递归算法,主要用于动态系统的状态估计。它通过结合系统模型和噪声干扰的观测数据,实现对系统状态的最优估计(在最小均方误差意义下)。以下从原理、使用场景和特点三个…...
深度学习框架探秘|TensorFlow vs PyTorch:AI 框架的巅峰对决
在深度学习框架中,TensorFlow 和 PyTorch 无疑是两大明星框架。前面两篇文章我们分别介绍了 TensorFlow(点击查看) 和 PyTorch(点击查看)。它们引领着 AI 开发的潮流,吸引着无数开发者投身其中。但这两大框…...

Windows环境管理多个node版本
前言 在实际工作中,如果我们基于Windows系统开发,同时需要维护老项目,又要开发新项目,且不同项目依赖的node版本又不同时,那么就需要根据项目切换不同的版本。本文使用Node Version Manager(nvm࿰…...

opencascade 源码学习BRepBuilderAPI-BRepBuilderAPI
BRepBuilderAPI BRepBuilderAPI 是一个用于构建和操作 BRep(边界表示法,Boundary Representation)拓扑数据结构的工具类。它提供了高级接口,用于创建几何形状(如顶点、边、面、实体等)以及进行扫掠&#x…...

Vue 2 + Webpack 项目中集成 ESLint 和 Prettier
在 Vue 2 Webpack 项目中集成 ESLint 和 Prettier 可以帮助你规范代码风格并自动格式化代码。以下是详细的步骤: 1. 安装 ESLint 和 Prettier 相关依赖 在项目根目录下运行以下命令,安装 ESLint、Prettier 和相关插件: npm install --save…...
)
AI原生代码审查实战手册(2026奇点大会闭门报告首次解禁)
更多请点击: https://intelliparadigm.com 第一章:AI原生代码审查:2026奇点智能技术大会Code Review新范式 在2026奇点智能技术大会上,AI原生代码审查(AI-Native Code Review)正式取代传统人工规则引擎混合…...
——深入分析Ring AllReduce算法与带宽最优性)
训练篇第5节:NCCL(二)——深入分析Ring AllReduce算法与带宽最优性
理解Ring AllReduce,你就掌握了数据并行分布式训练的通信命脉 前言 上一节我们学习了分布式训练的三种并行策略,其中数据并行最核心的通信原语就是AllReduce。在深入篇中,我们简单介绍了NCCL和AllReduce,但那一节更侧重API使用。今天,我们将深入Ring AllReduce算法的内部…...

掌握Windows与Office智能激活:KMS_VL_ALL_AIO技术深度解析
掌握Windows与Office智能激活:KMS_VL_ALL_AIO技术深度解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office软件授权问题困扰吗?KMS_VL_ALL…...

别再手动改图号了!Word 2016 交叉引用功能,让你的论文排版效率翻倍
告别手动编号:用Word 2016交叉引用功能打造智能学术文档 在撰写学术论文或技术报告时,最令人头疼的莫过于图表编号的维护。想象一下这样的场景:你刚刚完成了一篇50页的论文,导师要求在第20页和第35页之间插入三张新图表——这意味…...

3步搭建企业级Webmail系统:Roundcube邮件客户端实战指南
3步搭建企业级Webmail系统:Roundcube邮件客户端实战指南 【免费下载链接】roundcubemail The Roundcube Webmail suite 项目地址: https://gitcode.com/gh_mirrors/ro/roundcubemail 在数字化办公环境中,安全高效的邮件系统是企业通信的基石。面对…...
从PIL到Tensor:用PyTorch transforms完整走一遍图像预处理流水线(附可视化对比图)
从PIL到Tensor:用PyTorch transforms完整走一遍图像预处理流水线(附可视化对比图) 当你第一次用PyTorch训练图像分类模型时,是否遇到过这样的困惑:明明代码能跑通,但模型效果总是不理想?问题很可…...

别再只盯着TOF了!从三角测距到相控阵,一文搞懂激光雷达的四种测距原理与选型避坑
激光雷达技术全景解析:从基础原理到工程选型实战指南 当扫地机器人精准绕开你的拖鞋,当自动驾驶汽车在暴雨中识别障碍物,背后都离不开一项关键技术——激光雷达。作为机器感知环境的"眼睛",激光雷达的性能直接决定了整个…...

Android.mk调试实战:巧用info/warning/error追踪编译变量
1. Android.mk调试的核心痛点与解决思路 当你面对一个由几十甚至上百个Android.mk文件组成的庞大编译系统时,最让人头疼的就是变量值的追踪和流程的调试。我遇到过最夸张的情况是,一个简单的编译选项传递竟然经过了5个mk文件的层层转手,最后出…...

高效OCR文字识别:Umi-OCR免费离线批量处理工具终极指南
高效OCR文字识别:Umi-OCR免费离线批量处理工具终极指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语…...

键盘连击终结者:免费开源工具KeyboardChatterBlocker完整使用指南
键盘连击终结者:免费开源工具KeyboardChatterBlocker完整使用指南 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 你的机械键…...