Docker安装分布式vLLM
Docker安装分布式vLLM
1 介绍
vLLM是一个快速且易于使用的LLM推理和服务库,适合用于生产环境。单主机部署会遇到显存不足的问题,因此需要分布式部署。
分布式安装方法
https://docs.vllm.ai/en/latest/serving/distributed_serving.html
2 安装方法
⚠️ 注意:前期一定要把docker环境、运行时和GPU安装好。
CUDA Version: 12.4
vllm:v0.7.2
2.1 下载镜像
# 下载镜像,镜像比较大
docker pull vllm/vllm-openai:v0.7.2
下载分布式部署的脚本
https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh
run_cluster.sh文件
#!/bin/bash# Check for minimum number of required arguments
if [ $# -lt 4 ]; thenecho "Usage: $0 docker_image head_node_address --head|--worker path_to_hf_home [additional_args...]"exit 1
fi# Assign the first three arguments and shift them away
DOCKER_IMAGE="$1"
HEAD_NODE_ADDRESS="$2"
NODE_TYPE="$3" # Should be --head or --worker
PATH_TO_HF_HOME="$4"
shift 4# Additional arguments are passed directly to the Docker command
ADDITIONAL_ARGS=("$@")# Validate node type
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; thenecho "Error: Node type must be --head or --worker"exit 1
fi# Define a function to cleanup on EXIT signal
cleanup() {docker stop nodedocker rm node
}
trap cleanup EXIT# Command setup for head or worker node
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; thenRAY_START_CMD+=" --head --port=6379"
elseRAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi# Run the docker command with the user specified parameters and additional arguments
docker run \--entrypoint /bin/bash \--network host \--name node \--shm-size 10.24g \--gpus all \-v "${PATH_TO_HF_HOME}:/root/.cache/huggingface" \"${ADDITIONAL_ARGS[@]}" \"${DOCKER_IMAGE}" -c "${RAY_START_CMD}"
2.2 创建容器
两台主机的IP如下,主节点宿主机IP:192.168.108.100,工作节点宿主机IP:192.168.108.101。
主节点(head节点)运行分布式vLLM脚本
官网的说明
# ip_of_head_node:主节点容器所在宿主机的IP地址
# /path/to/the/huggingface/home/in/this/node: 映射到到容器中的路径
# ip_of_this_node:当前节点所在宿主机的IP地址
# --head:表示主节点
bash run_cluster.sh \vllm/vllm-openai \ip_of_head_node \--head \/path/to/the/huggingface/home/in/this/node \-e VLLM_HOST_IP=ip_of_this_node
本机执行
bash run_cluster.sh \vllm/vllm-openai:v0.7.2 \192.168.108.100 \--head \/home/vllm \-e VLLM_HOST_IP=192.168.108.100 \> nohup.log 2>&1 &
工作节点(worker节点)运行分布式vLLM脚本
官网的说明
# ip_of_head_node:主节点容器所在宿主机的IP地址
# /path/to/the/huggingface/home/in/this/node: 映射到到容器中的路径
# ip_of_this_node:当前节点所在宿主机的IP地址
# --worker:表示工作节点
bash run_cluster.sh \vllm/vllm-openai \ip_of_head_node \--worker \/path/to/the/huggingface/home/in/this/node \-e VLLM_HOST_IP=ip_of_this_node
本机执行
bash run_cluster.sh \vllm/vllm-openai:v0.7.2 \192.168.108.100 \--worker \/home/vllm \-e VLLM_HOST_IP192.168.108.101 \> nohup.log 2>&1 &
查看集群的信息
# 进入容器
docker exec -it node /bin/bash# 查看集群信息
ray status
# 返回值中有GPU数量、CPU配置和内存大小等
======== Autoscaler status: 2025-02-13 20:18:13.886242 ========
Node status
---------------------------------------------------------------
Active:1 node_89c804d654976b3c606850c461e8dc5c6366de5e0ccdb360fcaa1b1c1 node_4b794efd101bc393da41f0a45bd72eeb3fb78e8e507d72b5fdfb4c1b
Pending:(no pending nodes)
Recent failures:(no failures)Resources
---------------------------------------------------------------
Usage:0.0/128.0 CPU0.0/4.0 GPU0B/20 GiB memory0B/19.46GiB object_store_memoryDemands:(no resource demands)
3 安装模型
⚠️ 本地有4张GPU卡。
官网说明
# 启动模型服务,可根据情况设置模型参数
# /path/to/the/model/in/the/container:模型路径
# tensor-parallel-size:张量并行数量,模型层内拆分后并行计算;
# pipeline-parallel-size:管道并行数量,模型不同层拆分后并行计算,在单个显存不够时可以设置此参数
vllm serve /path/to/the/model/in/the/container \--tensor-parallel-size 8 \--pipeline-parallel-size 2
本机执行
将下载好的Qwen2.5-7B-Instruct模型,放在“/home/vllm”目录下
# 进入节点,主节点和工作节点都可以
docker exec -it node /bin/bash# 执行命令参数
nohup vllm serve /root/.cache/huggingface/Qwen2.5-7B-Instruct \--served-model-name qwen2.5-7b \--tensor-parallel-size 2 \--pipeline-parallel-size 2 \> nohup.log 2>&1 &
在宿主机上调用参数
curl http://localhost:8000/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-d '{"model": "qwen2.5-7b","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "介绍一下中国,不少于10000字"}],"stream": true
}'
相关文章:

Docker安装分布式vLLM
Docker安装分布式vLLM 1 介绍 vLLM是一个快速且易于使用的LLM推理和服务库,适合用于生产环境。单主机部署会遇到显存不足的问题,因此需要分布式部署。 分布式安装方法 https://docs.vllm.ai/en/latest/serving/distributed_serving.html2 安装方法 …...
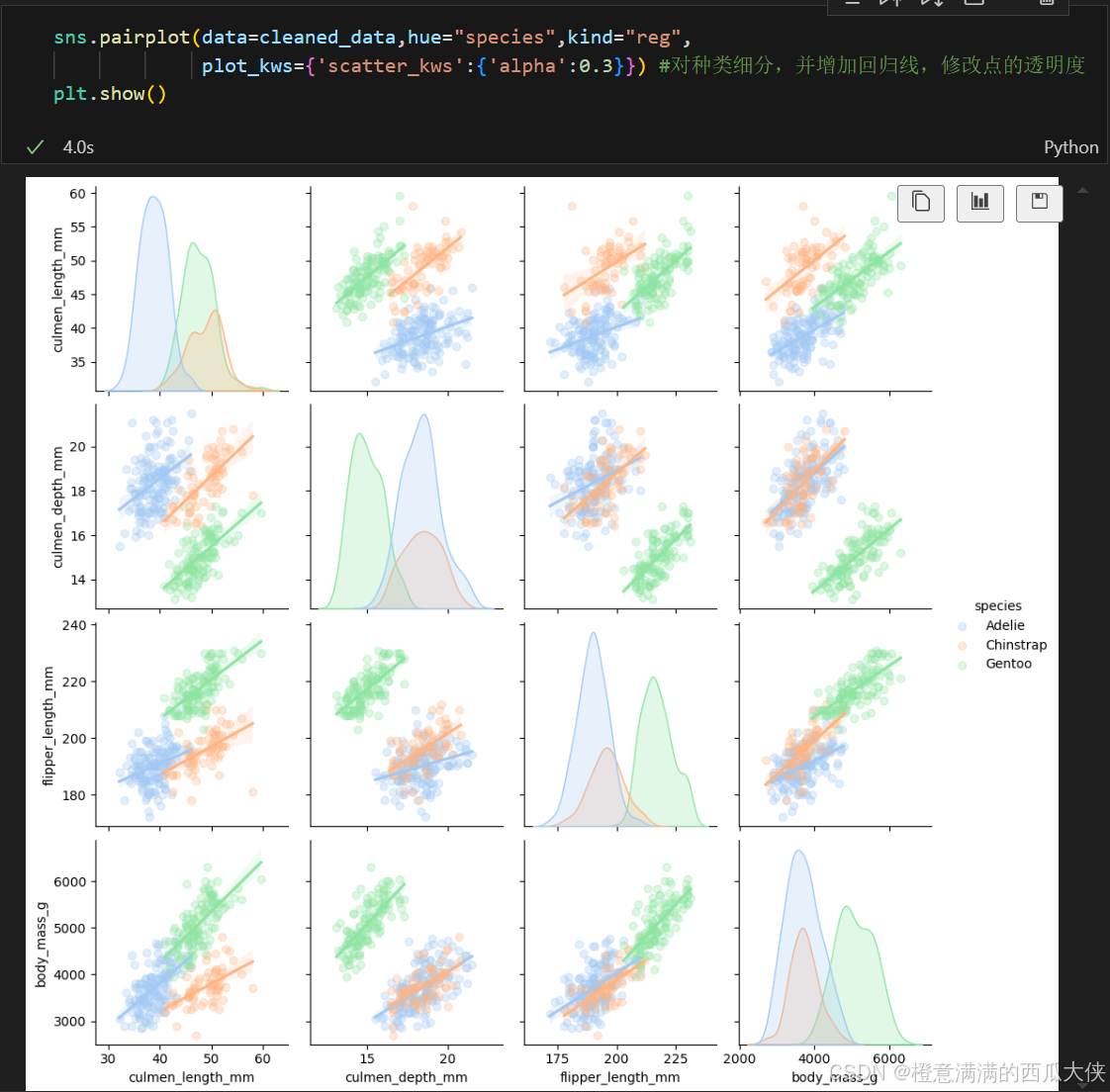
可视化实操记录(自用)
流程 读取数据 original_data pd.read_csv(“Penguins.csv”) original_data.head() 评估和清理数据 cleaned_data original_data.copy() #备份 结构 original_data.sample(5) 数据符合“每个变量为一列,每个观察值为一行,每种类型的观察单位为一…...

二叉树的遍历方式和子问题思路
目录 二叉树的遍历: 前序遍历: 中序遍历: 后序遍历: 二叉树的基本操作: 求树的结点个数(递归遍历思路): 求树的结点个数(子问题思路): 求树的…...

运用Deek Seeker协助数据分析
我的数据源有两张表,一个是每日销售表(字段有日期、产品名称、实际销量),一个是每月目标表(字段有年度月份、产品名称、目标销量);我的需求是,按月、按年来统计每个产品的目标完成情况请问用PowerBl进行分析,应该如何建立数据模型…...

服务器之连接简介(Detailed Explanation of Server Connection)
一台服务器最大能支持多少连接?一台客户端机器最多能发起多少条连接?? 我们知道TCP连接,从根本上看其实就是client和server端在内存中维护的一组【socket内核对象】(这里也对应着TCP四元组:源IP、源端口、…...

低空经济:开启未来空中生活的全新蓝海
引言 随着科技的进步,我们不再仅仅依赖地面交通和传统物流。你是否曾幻想过,未来的某一天,快递、外卖可以像魔法一样直接从空中送到你手中?或者,你能乘坐小型飞行器,快速穿梭于城市之间,告别拥堵…...

主动视觉可能就是你所需要的:在双臂机器人操作中探索主动视觉
AV-ALOHA 系统使用用于 AV 的 VR 耳机实现直观的数据收集,并且 用于作的 VR 控制器或引线臂。这有助于捕捉全身和头部 远程作我们的真实和模拟系统的运动,记录来自 6 个的视频 不同的摄像头,并为我们的 AV 仿制学习策略提供训练数据。 加州大…...

洛谷 P6419 COCI2014/2015 #1 Kamp 题解
题意 一颗树 n n n 个点, n − 1 n-1 n−1 条边,经过每条边都要花费一定的时间,任意两个点都是联通的。 有 k k k 个人(分布在 k k k 个不同的点)要集中到一个点举行聚会。 聚会结束后需要一辆车从举行聚会的这点…...

在 Vue 项目中使用 SQLite 数据库的基础应用
目录 一、环境准备二、数据库连接与操作1. 创建数据库连接2. 创建表3. 插入数据4. 查询数据5. 更新数据6. 删除数据 三、在 Vue 组件中使用 SQLite 一、环境准备 安装 Node.js 和 npm:确保已安装 Node.js 和 npm。 创建 Vue 项目:使用 Vue CLI 创建一个…...
)
AI会话问答的页面滚动处理(参考deepseek页面效果)
近期在接入deepseekR1的深度思考,研究了下deepseek官网的滚动效果,大概如下:用户发出消息后,自动滚动到页面最底部,让最新消息展示在视野中,这时候,我们先处理一次滚动: const scrol…...

GRN前沿:DGCGRN:基于有向图卷积网络的基因调控网络推理
1.论文原名:Inference of gene regulatory networks based on directed graph convolutional networks 2.发表日期:2024 DGCGRN框架 中心节点和节点的构建 局部增强策略 1. 问题背景 在基因调控网络中,许多节点的连接度较低(即…...

MongoDB 入门操作指南
文章目录 MongoDB 入门操作指南1. 连接到 MongoDB 数据库2. 查看当前数据库3. 显示所有数据库4. 切换或创建数据库5. 查看当前数据库中的所有集合6. 创建集合7. 插入文档插入单个文档插入多个文档 8. 查询文档查询所有文档查询匹配条件的文档格式化查询输出 9. 更新文档更新单个…...

共享设备管理难?MDM助力Kiosk模式一键部署
目录 1. 简化设备部署与配置:实现一键式部署 2. 自动化应用更新与内容推送:确保设备始终保持最新状态 3. 权限控制与设备安全:防止滥用与数据泄露 4. 远程管理与故障诊断:保障设备长期稳定运行 5. 数据分析与报告:…...

HttpClient-Java程序中发送Http请求
配置 <dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version> </dependency> ps:aliyun-sdk-oss中已引入上述配置 HttpClient的核心API: Htt…...

硬件-电源-隔离与非隔离的区别
文章目录 一:隔离电源与非隔离电源1.1 充电器触电新闻1.2 电路拓扑1.3 隔离电源与非隔离电源的优缺点1.3 隔离电源与非隔离电源的选择1.3.1 隔离电源1.3.2 非隔离电源 二:注意事项2.1 隔离电源结构图2.1 隔离耐压测试方法 三:感悟道友&#x…...

Kubernetes 最佳实践:Top 10 常见 DevOps/SRE 面试问题及答案
1. 如何在 Kubernetes 中设置资源请求和限制? 资源请求确保容器有最小资源量(CPU/内存),而限制则强制容器消耗的最大资源量。这有助于高效资源分配并防止资源争用。 示例: resources:requests:memory: "256Mi&…...

Training for Computer Use
Training for Computer Use 核心事件:多家科技公司推出能操控计算机的智能体,字节跳动和清华大学团队引入UI - TARS模型,展示了训练模型实现计算机操控能力的新成果。 UI - TARS模型 基本信息:是视觉 - 语言模型Qwen2 - VL的微调版…...

PH热榜 | 2025-02-14
1. Beatoven.ai 标语:能创作完美背景音乐的AI作曲家 介绍:Beatoven.ai 能根据简单的提示生成惊艳的背景音乐,用于你的内容创作。它是由世界各地的真实音乐家倾力打造(并使用了大量数据)。无需任何音乐专业知识&#…...

工业物联网远程监控系统优化方案,基于巨控GRM553Y-CHE
工业物联网远程监控系统优化方案 ——基于巨控GRM553Y-CHE的西门子S7-1500 PLC多站点无线集成方案 1. 项目背景与概述 巨控科技作为工业物联网解决方案提供商,专注于PLC无线通信与远程监控技术研发,其YunPLC安全平台已服务超30,000工业终端,…...

报名丨Computer useVoice Agent :使用 TEN 搭建你的 Mac Assistant
与 TEN 相聚在「LET’S VISION 2025」大会,欢迎来展位上跟我们交流。这次我们还准备了一场聚焦「computer use」的工作坊,功能新鲜上线,线下首波体验! 📅 TEN 展位:2025年3月1日-2日 TEN workshop&#x…...

从《EE Times》看电子工程师的变迁:技术浪潮与职业坚守
1. 从一份行业报纸的生日说起:我们为何怀念《EE Times》?前几天,我偶然翻到一篇旧文,是《EE Times》前主编史蒂夫韦茨纳在2013年,为这份报纸创刊40周年写的一篇回顾。文章不长,但字里行间那种对行业黄金时代…...

AI驱动的学术研究技能:自动化文献综述与深度分析工作流
1. 项目概述:一个为AI智能体设计的深度学术研究技能如果你是一名研究生、科研人员,或者任何需要快速、系统地梳理某个领域文献的人,那么你肯定体会过那种面对海量论文时的无力感。传统的流程是:打开Google Scholar,输入…...

一次断电引发的血案:深度复盘CentOS 7 LVM分区下fstab丢失的排查与修复全记录
CentOS 7 LVM环境下fstab丢失的深度修复指南 当服务器遭遇意外断电时,文件系统损坏往往是最令人头疼的问题之一。最近处理的一起CentOS 7系统宕机案例,由于断电导致/etc/fstab文件丢失,系统无法正常启动。本文将详细记录整个排查和修复过程&a…...

开发AI应用时借助Taotoken模型广场快速进行模型选型与测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时借助Taotoken模型广场快速进行模型选型与测试 在开发基于大语言模型的应用或功能时,一个常见的挑战是如何…...
)
别再裸奔了!手把手教你给Nacos 2.x加上用户密码和权限隔离(附Spring Boot配置)
Nacos 2.x安全加固实战:从零构建企业级权限体系 在微服务架构快速迭代的初期,许多团队为了开发效率往往选择"裸奔"模式运行Nacos——不开启任何鉴权机制。这种看似便捷的做法实则暗藏巨大风险:配置信息泄露、服务被恶意注销、敏感数…...

LeAgent多智能体协作框架:从任务规划到实战部署的完整指南
1. 项目概述:当AI学会“派活”,一个智能体协作框架的诞生最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个核心痛点:单个智能体能力再强,面对复杂任务也常常力不从心。比如,你…...
)
MySQL 安装后安全加固实操:从空密码警告到配置安全远程访问(Ubuntu 18.04 + MySQL 5.7)
MySQL 安全加固实战:从空密码警告到生产级配置 在Ubuntu服务器上部署MySQL数据库时,许多开发者会惊讶地发现安装后竟然可以直接用mysql -uroot无密码登录。这种默认配置在生产环境中无异于敞开大门邀请不速之客。本文将带你完成从基础安装到生产级安全配…...
)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集) 刚入坑深度学习的开发者,最头疼的莫过于环境配置。明明按照教程一步步安装了PyTorch或TensorFlow,却在代码运行时看到CUDA不可用…...

收藏!AI时代程序员薪资分化严重?3个月转型AI工程,求职成功率提升60%!
文章指出AI时代程序员薪资两极分化,顶级AI人才年薪破亿,而普通开发者求职困难。文章强调这不是行业寒冬,而是结构性变革。建议程序员提升AI工程能力,转型AI工程师,成功案例显示求职成功率提升60%,薪资涨幅3…...

Vue.Draggable终极指南:掌握拖拽数据同步的5大核心策略
Vue.Draggable终极指南:掌握拖拽数据同步的5大核心策略 【免费下载链接】Vue.Draggable Vue drag-and-drop component based on Sortable.js 项目地址: https://gitcode.com/gh_mirrors/vu/Vue.Draggable Vue.Draggable是一个基于Sortable.js的强大Vue.js拖拽…...