数据结构:Map Set(一)
目录
一、搜索树
1、概念
2、查找
3、插入
4、删除
二、搜索
1、概念及场景
2、模型
(1)纯key模型
(2)Key-Value模型
三、Map的使用
1、什么是Map?
2、Map的常用方法
(1)V put(K key, V value)
(2)V get(Object key)
(3)V getOrDefault(Object key, V defaultValue)
(4)V remove(Object key)
(5)Set keySet()
(6)Collection values()
(7)Set> entrySet()
(8)boolean containsKey(Object key)
(9)boolean containsValue(Object value)
四、Set的使用
1、什么是Set?
2、Set的常用方法
(1)boolean add(E e)
(2)void clear()
(3)boolean contains(Object o)
(4)Iterator iterator()
(5)boolean remove(Object o)
(6)int size()
(7)boolean isEmpty()
(8)Object[] toArray()
(9)boolean containsAll(Collection c)
(10)boolean addAll(Collection c)
在前面我们已经学完了数据结构中常见的排序算法,而今天我们就要开始学习数据结构上新的里程碑——Map & Set。
一、搜索树
1、概念
二叉搜索树又称二叉排序树,它或者是一棵空树,并且这棵树具有以下这些性质:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
如下这棵树就是一棵二叉搜索树:

既然作为一棵树那么它也一定具有查找,插入和删除的功能,那么接下来就让我们来依次实现这些操作吧
由于是要我们自己来实现,那我们肯定要先做一下准备工作,我们要创建创建搜索树的结点和根结点
public class BinarySearchTree {static class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int val) {this.val = val;}}//当前搜索树的根节点public TreeNode root = null;
}2、查找
这个操作就很简单了,我们只需要遍历这棵二叉搜索树判断是否有结点的val值与我们给的val值相等即可。
当然上述是对于一棵普通的二叉树的查找方式,而我们的二叉搜索树又称二叉排序树,那么它一定是有一定顺序的,所以查找方式也是有一定不同的根据上述的性质我们直到左子树的值都小于根节点的值,右子树的值多大于根节点的值,并且每棵子树也都是二叉搜索树。
1、我们可以先定义一个cur存储root,进行遍历
2、如果我们 cur的值小于我们要查找的值,就上我们的右子树上去找
cur.val < val 执行 cur = cur.right
3、如果我们 cur的值大于我们要查找的值,就上我们的左子树上去找
cur.val > val 执行 cur = cur.left
4、如果我们 cur的值等于于我们要查找的值,就返回cur
cur.val == val 执行 return cur
5、如果树为空或者没有要查找的值,就返回null
public TreeNode search(int val) {TreeNode cur = root;while (cur != null) {if(cur.val < val) {cur = cur.right;}else if(cur.val > val) {cur = cur.left;}else {return cur;}}return null;}
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为: O(logN)
最差情况下,二叉搜索树退化为单支树,其平均比较次数为: N
3、插入
1、我们要先判断是否为空树,如果为空树,那么我们此时要插入的结点就是我们的根结点
2、不为空树,我们就创建两个结点,prev和cur,cur用来遍历二叉搜索树,prev用来存储cur遍历到结点的根结点。
3、我们要先进行插入数据大小的判断如果大于cur.val,先让prev指向cur,然后让cur往右走,小于先让prev指向cur,然后让cur往左走。
4、如果我们在遍历的过程中发现我们要插入的值在二叉搜索树中存在,就直接返回不用插入。
5、如果cur指向null了,我们就代表可以进行插入了,跳出循环
6、跳出循环后,此时prev就是我们cur的父结点,我们要进行判断是在prev左边还右边进行插入
如果prev的值小于val,在prev的右边进行插入
prev.val < val 执行 prev.right =newTreeNode
如果prev的值大于val,在prev的左边进行插入
prev.val > val 执行 prev.left = newTreeNode
public void insert(int val) {TreeNode newTreeNode =new TreeNode(val);if(root == null){root = newTreeNode;return;}TreeNode cur = root;TreeNode prev = null;while(cur != null){if(cur.val > val){prev = cur;cur = cur.right;}else if(cur.val < val){prev = cur;cur = cur.left;}else{return;}}if(prev.val < val){prev.right =newTreeNode;}if(prev.val > val){prev.left = newTreeNode;}}
4、删除
对于删除的操作,我们还是要先找到要删除的结点,我们还是利用cur和prev两个结点,cur用来查找要删除的结点,prev用来记录,我们遍历过程中cur的父节点,而当我们找到这个要删除的结点后,我们还要面临几种情况:
1、cur.left == null

2、cur.right==null

3、cur.left!=null&&cur.right!=null
我们先创建两个结点 target 存储cur.right 和 targetParent 存储 cur,如果我们想要进行删除,我们必须要确保我们删除后,此时结点之后的左右子树依然能够是二叉搜索树,所以我们要确定我们新的值要比左边大,又要比右边小,而这时我们有两种删除方法:
方法一:在左子树中找到左子树中的最大值(即左树的最右边的结点)
(因为左子树的最大值一定大于所有左子树的结点,并且因为最大值属于左树,左树的值是一定小于右树的,因此此时的最大值也一定是小于右树的),然后让他的值更新cur结点,最后我们只要删除这个结点即可
方法二:在右子树中找到右子树中的最小值(即右数的最左边的结点)
(因为右子树的最小值一定小于所有右子树的结点,并且因为最小值属于右树,右树的值是一定大于左树的,因此此时的最小值也一定是大于左树的),然后让他的值更新cur结点,最后我们只要删除这个结点即可

public void remove(int val){TreeNode cur = root;TreeNode prev = null;while (cur != null) {if(cur.val < val) {prev = cur;cur = cur.right;}else if(cur.val > val) {prev = cur;cur = cur.left;}else {removeNode(cur,prev);return ;}}}public void removeNode(TreeNode cur ,TreeNode prev){if(cur.left == null){if(cur == root ){root = root.right;}else if(cur == prev.left){prev.left = cur.right;}else if(cur == prev.right){prev.right = cur.right;}}else if(cur.right == null){if(cur == root ){root = root.left;}else if(cur == prev.left){prev.left = cur.left;}else if(cur == prev.right){prev.right = cur.left;}}else{TreeNode target = cur.right;TreeNode targetParent = cur;while(target.left != null){targetParent = target;target = target.left;}cur.val = target.val;if(targetParent.left == target){targetParent.left = target.right;}else{targetParent.right = target.right;}}}二、搜索
1、概念及场景
Map和set是⼀种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 以前常见的搜索方式有:
1、直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
2、二分查找,时间复杂度为,但搜索前必须要求序列是有序的
上述查找方式比较适合进行静态查找的方式,我们在这种方式下一般不会进行插入和删除的操作,
因此这就要引出我们的动态查找方式,而这章要讲的Map和Set就是一种适合动态查找的集合容器。
2、模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键 值对,所以模型会有两种:
(1)纯key模型
比如我们有一句英文:Failure is the fog through which we glimpse triumph.(透过失败的迷雾,才能瞥见胜利的光辉。)
而我们的纯key模型,就是查找我们的单词 fog 是否出现在这句英文中。
(2)Key-Value模型
而我们的Key-Value模型,就是统计这句英文中每个单词出现的次数,统计结果是每个单词都有与其对应的次数: <单词,单词出现的次数>
而接下来我们要介绍的Map中存储的就是key-value的键值对,Set中只存储了Key。
三、Map的使用
1、什么是Map?
Map是一个接口类,该类没有继承自Collection,该类中存储的是结构的键值对,并且K一定是唯一的,不能重复。
2、Map的常用方法
由于Map是是一个接口,不能自己进行实例化,我们需要使用TreeMap(红黑树)和HashMap(哈希桶)进行实例化。
(1)V put(K key, V value)
解释:设置 key 对应的 value

我们发现Map还会根据我们的key值自动排序
(2)V get(Object key)
解释:返回 key 对应的 value

(3)V getOrDefault(Object key, V defaultValue)
解释:返回 key 对应的 value,key不存在,返回默认值

(4)V remove(Object key)
解释:删除 key 对应的映射关系

(5)Set<K> keySet()
解释:返回所有 key 的不重复集合

(6)Collection<V> values()
解释:返回所有 value 的可重复集合

(7)Set<Map.Entry<K,V>> entrySet()
解释:返回所有的 key-value 映射关系
在对他进行讲解前我们要先对Map.Entry<K,V>进行说明
Map.Entry是Map内部实现的用来存放键值对映射关系的内部类,该内部类中主要提供了的获取,value的设置以及Key的比较方式
方法 解释 K getKey() 返回 entry 中的 key V getValue() 返回 entry 中的 value V setValue(V value) 将键值对中的value替换为指定value

(8)boolean containsKey(Object key)
解释:判断是否包含 key

(9)boolean containsValue(Object value)
解释:判断是否包含 value

注意事项:
1、Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者 HashMap
2、Map中存放键值对的Key是唯一的,value是可以重复的
3、在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但是HashMap的key和value都可以为空。
4、Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
5、Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
6、Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然 后再来进行重新插入。



四、Set的使用
1、什么是Set?
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
2、Set的常用方法
(1)boolean add(E e)
解释:添加元素,但重复元素不会被添加成功

(2)void clear()
解释:清空集合

(3)boolean contains(Object o)
解释:判断o是否在集合中

(4)Iterator<E> iterator()
解释:返回迭代器,通过迭代器进行打印

(5)boolean remove(Object o)
解释:删除集合中的 o

(6)int size()
解释:返回set中元素的个数

(7)boolean isEmpty()
解释:检测set是否为空,空返回true,否则返回false

(8)Object[] toArray()
解释:将set中的元素转换为数组返回

(9)boolean containsAll(Collection<?> c)
解释:集合c中的元素是否在set中全部存在,是返回true,否则返回false

(10)boolean addAll(Collection<?extends E> c)
解释:将集合c中的元素添加到set中,可以达到去重的效果

注意事项:
1、Set是继承自Collection的一个接口类
2、Set中只存储了key,并且要求key一定要唯一
3、TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
4、Set最大的功能就是对集合中的元素进行去重
5、实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在 HashSet的基础上维护了一个双向链表来记录元素的插入次序。
6、Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
7、TreeSet中不能插入null的key,HashSet可以。

好了,今天的分享就到这里了还请大家多多关注,我们下一篇见!
相关文章:

数据结构:Map Set(一)
目录 一、搜索树 1、概念 2、查找 3、插入 4、删除 二、搜索 1、概念及场景 2、模型 (1)纯key模型 (2)Key-Value模型 三、Map的使用 1、什么是Map? 2、Map的常用方法 (1)V put(K …...
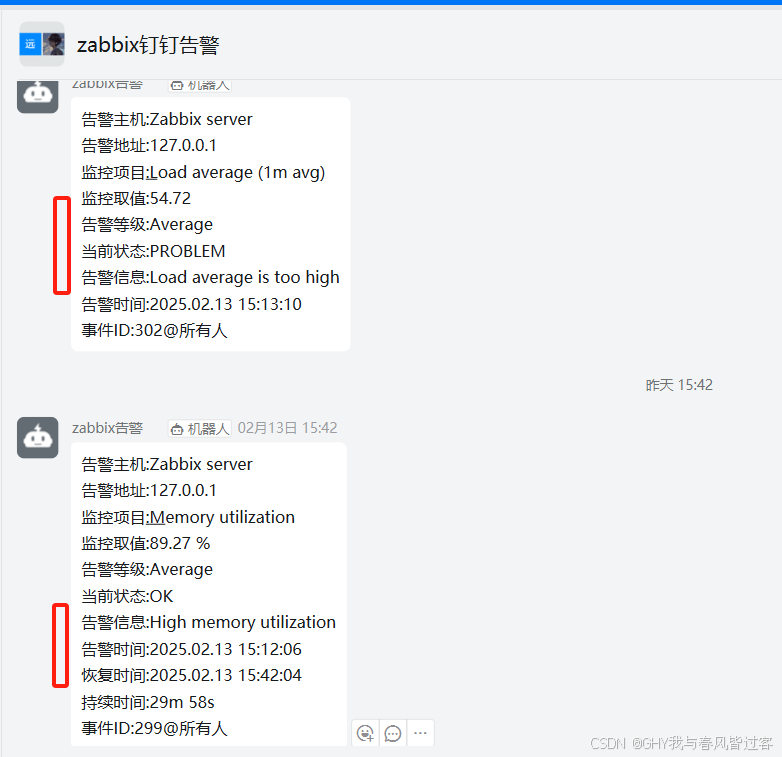
zabbix 监控系统 配置钉钉告警
步骤1:创建钉钉群 步骤2:创建机器人 点击群设置 然后下划选择机器人。 点击添加机器人 选择自定义机器人 点击添加 1、设置机器人的名字和群组 2、设置自定义关键字 zabbix 告警 报警 恢复 3、点击我已阅读并同意 4、点击完成 生成webhook 链接 注…...

跟着李沐老师学习深度学习(十一)
经典的卷积神经网络 在本次笔记中主要介绍一些经典的卷积神经网络模型,主要包含以下: LeNet:最早发布的卷积神经网络之一,目的是识别图像中的手写数字;AlexNet: 是第一个在大规模视觉竞赛中击败传统计算机…...

32单片机学习记录4之串口通信
32单片机学习记录4之串口通信 前置 STM32的GPIO口有通用模式,复用模式,模拟模式三种,加上输入输出就是有6中对应的模式。 我学习了通用模式,会使用GPIO口使用一些简单外设,如LED,独立按键,红外…...

微信小程序 - 组件和样式
组件和样式介绍 在开 Web 网站的时候: 页面的结构由 HTML 进行编写,例如:经常会用到 div、p、 span、img、a 等标签 页面的样式由 CSS 进行编写,例如:经常会采用 .class 、#id 、element 等选择器 但在小程序中不能…...

JavaScript 发起网络请求 axios、fetch、async / await
目录 fetch 发送 GET 请求(fetch) 发送 POST 请求(fetch) 处理后台异常响应 async / await async await 发送 GET 请求(async / await fetch) 发送 POST 请求(async / await fetch&…...

本地搭建自己的专属客服之OneApi关联Ollama部署的大模型并创建令牌《下》
这里写目录标题 OneApi1、渠道设置2、令牌创建 配置文件修改修改配置文件docker-compose.yml修改config.json到此结束 上文讲了如何本地docker部署fastGtp,相信大家也都已经部署成功了!!! 今天就说说怎么让他们连接在一起 创建你的…...

Win10环境借助DockerDesktop部署最新MySQL9.2
Win10环境借助DockerDesktop部署最新MySQL9.2 前言 作为一杆主要撸Java的大数据平台开发攻城狮,必不可少要折腾各种组件,环境和版本一直是很头疼的事情。虽然可以借助Anaconda来托管Python的环境,也可以使用多个虚拟机来部署不同的环境&…...

【Maven】多module项目优雅的实现pom依赖管理
【Maven】多module项目优雅的实现pom依赖管理 【一】方案设计原则【二】项目结构示例【三】实现思路【1】可能的问题点:【2】解决方案的思路:【3】需要注意的地方:【4】可能的错误: 【四】实现案例【1】父POM设计(pare…...

前端vue引入特殊字体不生效
引入特殊字体ttf,TTF等发现开发环境中生效,项目部署后不生效何解? 1. 本地生效的原因 本地使用的是本地的资源,控制台可以看到对ttf文件的请求与加载。 2.部署后不生效的原因与解决 控制台可以看到对ttf资源文件的请求加载失败…...

【Linux】--- 基础开发工具之yum/apt、vim、gcc/g++的使用
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: Linux网络编程 本篇博客我们来认识一下Linux中的一些基础开发工具 --- yum,vim,gcc/g。 🏠 yum 🎸 什么是yum 当用户想下载软…...

WEB安全--SQL注入--INTO OUTFILE
一、INTO OUTFILE 函数语法: SELECT column1, column2, INTO OUTFILE file_path FROM your_table WHERE your_conditions; 使用此方式在SQL注入的过程中可以: 1、上传shell得到数据库的后端的操作权限 2、爆出数据库的信息 二、使用该函数的条件&#…...

如何从0开始将vscode源码编译、运行、打包桌面APP
** 网上关于此的内容很少,今天第二次的完整运行了,按照下文的顺序走不会出什么问题。最重要的就是环境的安装,否则极其容易报错,请参考我的依赖版本以及文末附上的vscode官方指南 ** 第一步:克隆 VSCode 源码 首先…...

关于视频去水印的一点尝试
一. 视频去水印的几种方法 1. 使用ffmpeg delogo滤镜 delogo 滤镜的原理是通过插值算法,用水印周围的像素填充水印的位置。 示例: ffmpeg -i input.mp4 -filter_complex "[0:v]delogox420:y920:w1070:h60" output.mp4 该命令表示通过滤镜…...
?请简要描述架构和关键代码实现?)
如何在 Java 应用中实现数据库的主从复制(读写分离)?请简要描述架构和关键代码实现?
在Java应用中实现数据库主从复制(读写分离) 一、架构描述 (一)整体架构 主库(Master) 负责处理所有的写操作(INSERT、UPDATE、DELETE等)。它是数据的源头,所有的数据变…...
【css】width:100%;padding:20px;造成超出100%宽度的解决办法 - box-sizing的使用方法 - CSS布局
问题 修改效果 解决方法 .xx {width: 100%;padding: 0 20px;box-sizing: border-box; } 默认box-sizing: content-box下, width 内容的宽度 height 内容的高度 宽度和高度的计算值都不包含内容的边框(border)和内边距(padding&…...

【TI C2000】F28002x的系统延时、GPIO配置及SCI(UART)串口发送、接收
【TI C2000】F28002x的系统延时、GPIO配置及SCI(UART)串口发送、接收 文章目录 系统延时GPIO配置GPIO输出SCI配置SCI发送、接收测试附录:F28002x开发板上手、环境配置、烧录及TMS320F280025C模板工程建立F28002x叙述烧录SDK库文件说明工程建…...

【PyQt】信号与槽机制
PyQt信号与槽机制详解 🚀 一、信号与槽类型 🔌 1. 内置信号 📡 # 按钮点击信号 🖱️ QPushButton.clicked# 文本输入变化信号 ⌨️ QLineEdit.textChanged# 窗口关闭信号 🚪 QWidget.closeEvent2. 自定义信号 ✨ c…...

STM32 是什么?同类产品有哪些
STM32 是什么? STM32 是由意法半导体(STMicroelectronics)推出的基于 ARM Cortex-M 内核 的 32 位微控制器(MCU)系列。它专为高性能、低功耗的嵌入式应用设计,广泛应用于以下领域: 工业控制&am…...

20250213编译飞凌的OK3588-C_Linux5.10.209+Qt5.15.10_用户资料_R1
20250213编译飞凌的OK3588-C_Linux5.10.209Qt5.15.10_用户资料_R1 2025/2/13 11:43 缘起:飞凌发布了高版本内核的适配OK3588-C的Buildroot的SDK:OK3588-C_Linux5.10.209Qt5.15.10_用户资料_R1。 但是编译异常了。 于是按照百度升级libc6,可以…...

CANN/catlass Block Mmad基础模板
Block Mmad基础模板 【免费下载链接】catlass 本项目是CANN的算子模板库,提供NPU上高性能矩阵乘及其相关融合类算子模板样例。 项目地址: https://gitcode.com/cann/catlass 代码位置 [TOC] BlockMmad 功能说明 block层级mmad计算,非TLA实现&am…...

CANN/hixl HIXL接口文档
HIXL接口 【免费下载链接】hixl HIXL(Huawei Xfer Library)是一个灵活、高效的昇腾单边通信库,面向集群场景提供简单、可靠、高效的点对点数据传输能力。 项目地址: https://gitcode.com/cann/hixl 产品支持情况 产品是否支持Ascend …...

基于ONVIF协议与Python实现AI Agent视觉节点:AI Watcher项目实战
1. 项目概述:让摄像头成为AI的“眼睛”最近在折腾一个挺有意思的项目,叫AI Watcher。简单来说,它的目标是把一个普通的、支持ONVIF协议的监控摄像头,变成一个能被AI智能体(Agent)直接调用的“视觉节点”。这…...

激光三角法测距
激光三角测距原理详述 激光三角测距法作为低成本的激光雷达设计方案,可获得高精度、高性价比的应用效果,并成为室内服务机器人导航的首选方案,本文将对激光雷达核心组件进行介绍并重点阐述基于激光三角测距法的激光雷达原理。 激光雷达四大核…...

轻量化研究代理:基于Agent架构的自动化信息处理方案
1. 项目概述:轻量化研究代理的诞生背景与核心价值在信息爆炸的时代,无论是学术研究者、行业分析师,还是产品经理、内容创作者,都面临着一个共同的痛点:如何从海量的、碎片化的信息中,高效地筛选、整合、提炼…...

Xbox成就解锁器终极指南:免费开源工具轻松获取全游戏成就
Xbox成就解锁器终极指南:免费开源工具轻松获取全游戏成就 【免费下载链接】Xbox-Achievement-Unlocker Achievement unlocker for xbox games (barely works but it does) 项目地址: https://gitcode.com/gh_mirrors/xb/Xbox-Achievement-Unlocker 还在为Xbo…...

前端Token管理实战:基于jzOcb/token-guard的JWT安全实践
1. 项目概述:为什么我们需要一个Token守卫? 在构建现代Web应用,特别是前后端分离的架构时,身份认证与授权是绕不开的核心环节。JWT(JSON Web Token)因其无状态、自包含的特性,已成为实现这一环节…...

【Nginx】如何集成 Prometheus + Grafana 监控 Nginx?—— 从原理到生产落地的完整指南
如何集成 Prometheus + Grafana 监控 Nginx?—— 从原理到生产落地的完整指南 适用读者:已部署过基础 Nginx 服务、了解反向代理,但尚未系统掌握其可观测性建设的中高级后端或 SRE 工程师。 技术栈:Nginx 1.24+(开源版)、Prometheus 2.40+、Grafana 10+、Docker 24+ 一、…...
)
告别.pyc反编译:用Cython把Python项目编译成.pyd/.so的保姆级教程(Windows/Linux双平台)
告别.pyc反编译:用Cython实现Python项目跨平台编译与代码保护的终极指南 当你的Python项目从实验室走向商业环境时,源码保护就成为了不可回避的挑战。想象一下这样的场景:你花费数月开发的算法核心,在交付给客户后第二天就出现在…...

别再只会用J-Link了!手把手教你用ST-Link和OpenOCD调试RISC-V/ARM单片机
低成本玩转RISC-V/ARM开发:ST-Link搭配OpenOCD全攻略 从工具焦虑到实战突破 每次打开论坛看到讨论J-Link的强大功能时,手头只有ST-Link的你是否有过一丝犹豫?其实在RISC-V和ARM开发领域,价值几十元的ST-Link配合开源工具OpenOCD&a…...