从 ClickHouse 到 Apache Doris:在网易云音乐日增万亿日志数据场景下的落地
导读:日志数据已成为企业洞察系统状态、监控网络安全及分析业务动态的宝贵资源。网易云音乐引入 Apache Doris 作为日志库新方案,替换了 ClickHouse。解决了 ClickHouse 运维复杂、不支持倒排索引的问题。目前已经稳定运行 3 个季度,规模达到 50 台服务器, 倒排索引将全文检索性能提升7倍,2PB 数据,每天新增日志量超过万亿条,峰值写入吞吐 6GB/s 。
网易云音乐每天都会产生大量用户行为数据、业务数据及日志数据,这些数据在异常行为跟踪、客诉问题定位、运行状态监控、性能优化等方面扮演守护者的角色。面对每日万亿级别数据的增量,网易云音乐早期的日志库以 ClickHouse 为核心构建,但面临运维成本高、并发查询能力不足、写入性能不稳定、使用费用高昂等问题,在新需求的满足上稍显吃力。
为寻找更优质解决方案,结合当前的业务需求, 网易云音乐引入 Apache Doris 作为日志库新方案,替换了 ClickHouse。解决了 ClickHouse 运维复杂、不支持倒排索引的问题。目前已经稳定运行 3 个季度,规模达到 50 台服务器, 倒排索引将全文检索性能提升7倍,2PB 数据,每天新增日志量超过万亿条,峰值写入吞吐 6GB/s 。 本文将介绍从 ClickHouse 到 Apache Doris 的迁移思考及调优实践,并分享网易云音乐如何在运维效率、并发能力、查询响应以及存储性能上实现全方位提升。
早期架构及挑战
云音乐数据平台主要包括客户端日志、服务端日志、数据平台相关组件运行日志这几类:
- 客户端 / 服务端日志: 客户端 / 服务端产生的日志是数据体系的核心基础数据之一,日增数据达万亿级别,存储占用数百 TB。几乎所有业务场景均由该类数据构建。
- 数据平台相关组件运行日志: 任务及相关组件日志是数据平台内部的核心数据之一,每天约 1TB 的数据规模。这些日志能够及时反映数据平台的运行状态、性能指标、异常情况等,是实现平台智能化运维的核心资产。
对于上述日志数据的处理,早期以 ClickHouse 为核心构建了日志库、并设计了如下两条数据处理链路。这些数据通过日志采集、清洗、加工后写入日志库中,由日志库进行明细和聚合查询,为异常用户行为、社区热点监控、任务异常分析、任务预警、大盘监控业务场景提供服务。


上述两类日志数据,均要求在实时任务加工处理后写入到日志库,这对日志库的稳定性、可用性、性能、容错等能力都提出了较高要求。而之前日志库以 ClickHouse 为核心构建,在使用中暴露出一些痛点问题,在性能及稳定性的满足上稍显吃力:
- 运维成本高:早期为两条处理链路,同时也带来了双倍维护成本,此外,早期链路在面对坏盘、宕机、扩容等场景时,需要手动进行数据均衡和数据恢复,有些场景甚至需要在写入任务时配合重启操作。
- 使用门槛高:ClickHouse 除了有基本的本地表和和分布式表概念外,还提供了 MergeTree/ReplacingMergeTree/SummingMergeTree 等多个引擎,需根据不同情况选择不同的引擎,比如多副本需要使用 ReplicatedXX 引擎,这对于新人而言使用门槛及成本均比较高。
- 并发查询能力不足:在并发查询较多场景下,查询性能下降明显,无法支持业务需求。
- 写入稳定性较差:当单节点宕机或坏盘时,写入任务会出现 Failover,个别场景还需要人工介入对写入任务进行重启。
- 收费较高:由于历史原因,ClickHouse 使用的相关云服务,成本高昂。
Apache Doris 日志场景调研
基于上述问题、技术栈痛点,结合当前的业务需求,网易云音乐最终选择 Doris 作为日志库的新方案,替换原先架构中的 ClickHouse。 Apache Doris 具备运维便捷、高并发能力优异、大规模数据写入性能稳定等特点,非常符合选型要求。不仅如此,Apache Doris 所提供的冷热存储以及数据湖能力也与后续重点技术发展方向高度契合。
- 简单易用运维难度低:工程师和数据分析师对于 SQL 非常熟悉,经验可以复用,不需要学习新的技术栈即可快速上手。同时 Doris 具备完善的分布式集群管理,集群本身易于运维、支持横向拓展的存储方案。
- 高吞吐、低延迟日志写入:支持每天百 TB 级、GB/s 级日志数据持续稳定写入,同时保持延迟 1s 以内, 确保数据的实时性和高效性。
- 高性能日志全文检索分析: 支持倒排索引和全文检索,对于日志场景中常见的查询(如关键词检索明细、趋势分析等)能够实现秒级响应,为用户提供极致的查询体验。
- 海量日志数据低成本存储:支持 PB 级海量数据的存储,并支持将冷数据存储到 S3 或 HDFS 等低成本存储介质,存储成本进一步降低。
- 开放、易用的上下游生态:上游通过 Stream Load 通用 HTTP API 对接常见的日志采集系统和数据源 Logstash、Filebeat、Fluentbit、Kafka 等,下游通过标准 MySQL 协议和语法对接各种可视化分析 UI,比如可观测性 Grafana、BI 分析 Superset、类 Kibana 的日志检索 SelectDB WebUI ,为用户打造全方位的日志存储与分析生态。
基于 Apache Doris 的日志平台实践
01 整体架构
由于 ClickHouse 和 Doris 均采用关系数据库模型及 SQL,因此架构变化很小、迁移也比较简单。在新架构中,使用 Apache Doris 替代 ClickHouse 作为日志存储和分析引擎,只需调整上游 Flink 写入程序,将日志写入 Doris,并更新下游日志查询的 SQL 语句即可。

在实际上线过程中,网易云音乐进行了 Doris 和 ClickHouse 为期两周的双跑测试。在此期间,针对最近两周的数据进行了记录数、用户等字段的统计,以及实际明细查询的抽样对比,以验证数据的一致性。经过校验,Doris 能够安全地替代原有的 ClickHouse。
02 存储设计
表结构设计是日志平台的关键因素,其中排序、分区、分桶、压缩、索引等设计将对性产生显著影响。
- 分区:基于
dt字段按天分区,使用 Dynamic Partition 功能自动创建和删除分区。 - 分桶:采用 RANDOM 随机分桶,既保证了各分桶的数据均衡,也能大幅提升写入性能。
- 排序:使用
application_id、log_type、container_id、logs_timestamp、log_level、host_name作为排序键。这是由于大多数查询会指定application_id、log_type、container_id,排序后能快速定位到所需数据,跳过不必要的数据。 - 索引:对需要全文检索的日志文本字段
message和exception_message创建倒排索引,加速关键词检索。 - 压缩:采用 Doris ZSTD 压缩算法,相比 ClickHouse 默认的 LZ4 压缩算法,能够节省 30% 以上的存储空间。
- Compaction:因为日志也是一种特殊的时序数据,因此采用
time_series compaction策略,利用时序数据局部性特点减少 Compaction 写放大,节省 CPU 和 IO 资源。
具体的建表语句参考如下:
CREATE TABLE log_table (application_id VARCHAR(*) NULL COMMENT '应用id',log_type VARCHAR(*) NULL COMMENT '日志类型/jm/tm',container_id VARCHAR(*) NULL COMMENT 'container_id',logs_timestamp BIGINT NULL COMMENT '日志产生时间',log_level VARCHAR(*) NULL COMMENT '日志级别',host_name VARCHAR(*) NULL COMMENT '主机名',exception_log TEXT NULL COMMENT '异常日志',job_id INT NULL COMMENT '任务id',message TEXT NULL COMMENT '日志内容',tag TEXT NULL COMMENT '日志关键指标',log_file_path TEXT NULL COMMENT '日志存储路径',exception_class_name TEXT NULL COMMENT '异常类名',exception_type TEXT NULL COMMENT '异常类型',exception_message TEXT NULL COMMENT '异常msg',exception_caused_by TEXT NULL COMMENT '异常caused_by',dt date NULL COMMENT '天',hh TEXT NULL COMMENT '小时',mm TEXT NULL COMMENT '分钟',INDEX idx_exception_message (exception_message) USING INVERTED PROPERTIES("parser" = "english"),INDEX idx_message (message) USING INVERTED PROPERTIES("parser" = "english")
) ENGINE=OLAP
DUPLICATE KEY(application_id, log_type, container_id, logs_timestamp, log_level, host_name)
COMMENT 'OLAP'
PARTITION BY RANGE(dt)()
DISTRIBUTED BY RANDOM BUCKETS 100
PROPERTIES ("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.start" = "-7","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "100","dynamic_partition.create_history_partition" = "true","compression" = "ZSTD","compaction_policy" = "time_series"
);
03 写入改造和优化
原来架构中,日志数据通过 Flink 写入 ClickHouse。新的架构中,由于 Doris 提供了 Doris Flink Connector,仍然可以沿用 Flink 来写数据,只需要进行少量调整。
客户端写入性能调优
目前使用 Apache Flink 1.12 版本,Doris Flink Connector 使用的是 branch-for-flink-before-1.13 分支。写入流程如下图:

每条上游数据写入 ArrayList 中,当 ArrayList 中数据的条数 sink.batch.size 或大小 sink.batch.bytes 达到阈值后,触发 flush 操作,同时还会启动 daemon 线程,定时 sink.batch.interval 做 flush 操作。在 flush 操作中,会将 ArrayList 中的数据按 JSON 或 CSV 的方式序列化为 String 格式,如果开启压缩 compress_type(只有 csv 格式支持 gz 压缩),可将 String 序列化为压缩后的字节数组,最后将数据通过 StreamLoad 的方式写入到 BE 节点。
基于该写入流程,网易云音乐进行了稳定性及性能压测,在压测过程中,发现几个问题:
- 默认
batch size太小,会导致吞吐量较低,数据延迟问题严重;而如果将batch size设置太高(500MB 等),又会导致 Flink TM 端 OOM。 - 写入 tablet 太多时,元数据产生也较多,不仅影响写入性能,还可能出现
txn数超限等问题。 - Flink 的 subTask 在初始化后,所写入的 BE 是确定的,除非产生异常需要重新选择 BE,否则不会主动变更 BE,这就导致 BE 间负载不均衡。
- BE 在进行滚动变更重启时,Flink 任务会失败。
- 监控指标缺失,无法量化客户端各阶段耗时。
基于上述问题,网易云音乐进行了如下优化:
- 在 append 数据操作时,直接写入压缩流,无需经过 ArrayList 中转。这种方式可大幅降低内存的使用,相比之前,TM 内存的占用从 8G -> 4G。
- 开启单 tablet 导入功能(要求表必须使用 random bucket 策略),可极大提升写入性能。
- 每个 batch flush 完成后,随机选择一个 BE 节点写入数据,解决 BE 写入不均衡问题,相较之前导入性能有 70% 的提升。(效果见下图 ,4/30 起为优化后数据)。
- 调整 failover 策略,同时优化重试逻辑,并增加每次重试的时间间隔,提高系统容错能力。
- 添加客户端全链路监控指标,监测 addBatch/压缩/flush/发送等各阶段耗时,可快速定位主要耗时过程。

HDD 硬盘元数据性能调优
Flink 写入 Doris 任务偶尔会出现延迟告警,查询日志发现 Stream Load 耗时从 5s 突增到 35s 左右。通过 Doris 大盘监控发现 Be Alive 指标抖动严重,接着通过 FE 的日志 grep "finished to handle tablet report from backend" log/fe.log | tail -n 100 查看 FE 处理 BE 心跳耗时情况,发现处理 BE 的耗时超 20s。
通过分析 FE 处理 BE 心跳的各步骤,发现大部分处理逻辑都是异步的,只有同步 tablet 元数据的逻辑是同步的。我们通过 grep "tablets in db" log/fe.log | tail -n 100查看相关耗时日志,发现该阶段耗时超 20s,基本可确定是在同步元数据阶段出现的严重耗时。

进一步的,通过 jstack 打印 FE 的线程栈,可发现 ReportHandler 在处理心跳时,只有 sync meta 一个地方是同步的,正在等待锁、获取锁的逻辑是 flush 元数据。同时,FE 磁盘的 ioutil 达到 50%以上。因此,基本确定问题是由于刷元数据导致性能降低。
在查阅源码和 bdbje 数据库的优化措施后,决定对 3 台 Follower FE 调整为异步刷盘:master_sync_policy=WRITE_NO_SYNC 和 replica_sync_policy=WRITE_NO_SYNC,最终实现 4 倍性能的提升。


04 查询改造和优化
由于 ClickHouse 和 Doris 都支持 SQL,查询的变化不大,主要区别在于,Doris 支持倒排索引和全文检索的函数,可用全文检索代替 LIKE 字符串匹配。
- 普通的查询
select logs_timestamp,message from log_table
where dt>= '2024-07-29'
and application_id='sloth-f52a7cda-50f8-4092-b6e7-6c9d8ce82c7b'
and log_type='jobmanager'
and container_id='sloth-f52a7cda-50f8-4092-b6e7-6c9d8ce82c7b-6457b684bf-vcrjb'
and logs_timestamp>=1722241811000 and logs_timestamp < 1722241819000
order by logs_timestamp desc limit 500 offset 0;
- 全文检索的查询,
message MATCH_ANY 'Exception Failed'匹配 Exception 或者 Failed 关键词。
-- match 全文检索查询:
SELECT logs_timestamp,message FROM log_table
WHERE dt>= '2024-07-29'
and application_id='sloth-f52a7cda-50f8-4092-b6e7-6c9d8ce82c7b'
and log_type='jobmanager'
and container_id='sloth-f52a7cda-50f8-4092-b6e7-6c9d8ce82c7b-6457b684bf-vcrjb'
and message MATCH_ANY 'Exception Failed'
and logs_timestamp>=1722241811000
and logs_timestamp < 1722241819000
order by logs_timestamp desc limit 500 offset 0-- like 模糊匹配查询:
message LIKE '%Exception%' OR message LIKE '%Failed%'
05 其他调优实践
使用 partition balance 策略让 BE 之间数据更加均衡
随着导入任务的不断增多,系统在高峰期开始出现了延迟。通过监控发现,个别 BE 的出入流量远高于其他 BE,进一步分析脚本得知,是由于当天分区的 tablet 在 BE 之间分布不均衡导致。
为解决这一问题,网易云音乐决定改用 Partition 策略 tablet_rebalancer_type=partition。该策略可将每天的分区 tablet 均匀分布到各 BE 上,避免局部负载过高的问题。这也要求写入任务必须保证数据在单分区内的 bucket 是均匀分布的,而当前的日志场景正好满足这一要求。下图为优化后数据(6 月 11 日在进行滚动变更,抖动较为严重,6 月 13 日后为稳定数据):

调整参数让磁盘之间更加均衡
-
重度不均衡
从下图可以看出,个别 BE 的 Compaction Score 非常高,同时这些 BE 的某些磁盘 I/O 利用率持续保持在 100%。与社区同学交流后得知,这主要是由于 BE 磁盘选择策略与 trash 清理机制之间的相互影响所致。
具体来说,尽管 BE 选择磁盘的策略是 round-robin,但当磁盘空间使用率超过 80% 时,系统会强制触发 trash 清理机制,这会导致某些磁盘的使用率急剧下降,从而使新的 tablet 更多地被分配到这些“低负载”磁盘上,导致这些磁盘负载持续升高。

进一步的,通过 BE 提供的查询 tablet 分布 OpenAPI,发现该 BE 上大流量表当天分区的 tablet 分布情况如下图所示,存在磁盘之间不均衡问题。

通过调整以下参数,来解决该问题:
trash_file_expire_time_sec = 0:关闭 trash,日志场景中每天数据量级非常大,且 trash 恢复比较困难,没有必要使用 trash。high_disk_avail_level_diff_usages = 0.8:BE 选择磁盘时,先根据磁盘的空间使用率划分级别,每个级别使用 round-robin 的方式分配,提升分级别的参数,可以将使用率高和低的盘强制放在一个级别中(风险提示:如果不确定是 trash 导致,可能存在个别盘打满的风险)
-
轻度不均衡
压测过程中,还发现存在轻度磁盘不均衡问题。这是由于 FE 的 balancer 机制,会选择 BE 磁盘使用率最小的 disk 进行迁移,从而导致存在部分不均衡问题。可暂时通过设置参数
disable_balance=false关闭 balancer 解决此问题。
监控运维
在落地过程中,运维方面主要进行以下三方向的建设:
- 可观测性:基于社区提供的的 Grafana 监控模版,对相关指标进行完善,构建了全面的可观测体系,实现对集群运行状况、关键指标的实时监控与分析。
- 自动化运维:依托内部的运维平台,构建了自动化告警、自动拉起、问题处理等逻辑。当系统出现异常时,系统可自动检测并采取相关措施,极大减轻了运维人员的工作负担。
- 自动化均衡:采取了自动化探测 tablet 磁盘是否分配均衡的策略,并针对不均衡的情况进行自动化迁移。这一能力确保了集群在扩容或停机维护时,能够自动达到最佳的负载均衡状态。
通过这三个方向的建设,进一步强化了 Doris 在运维层面的自动化和智能化能力,极大提升了整体的运维效率和可靠性。这不仅大幅减轻了运维人员的工作负担,也为系统稳定运行提供了有力保障。
升级收益
网易云音乐使用 Apache Doris 替换 ClickHouse 构建了新的日志平台,已经稳定运行三个季度,规模达到 50 台服务器、2PB 数据量。这次架构升级带来查询响应、并发能力、稳定性和运维效率等多方面可观的收益。
- 查询响应提升:整体 P99 查询延迟降低了 30%。特别是通过倒排索引加速,Doris 的全文检索 MATCH 查询性能比 LIKE 查询提升了 3-7 倍(在查询约 6TB 数据时,LIKE 查询耗时 7-9 秒,而 MATCH 查询仅需 1-3 秒)。此外,倒排索引的全文检索具备自动的大小写和单复数归一化能力,能够高效检索出更多相关日志。
- 查询并发提升:ClickHouse 并发查询数超过 200 时就会经常出现
Too many simultaneous queries错误,而 Apache Doris 能够支撑 500+ 并发查询。Doris 还可以对单次查询的数据量和并发数进行调整,以灵活应对不同场景下的并发要求。 - 写入稳定性提升:FE / BE 发生单点故障时,都能自动感知和重试恢复,保证服务高可用。
- 运维成本降低:在坏盘和宕机场景下,Doris 的自恢复能力结合进程自动拉起脚本,降低人工干预的运维成本。扩容或停机维护场景下,Doris 的自动均衡能力很强,扩容后随着 tablet 的自动均衡和老数据的清理,集群会自动达到均衡状态。
此外,网易云音乐在技术能力上也有良好的积累,积极与 Doris 社区同学深入沟通、解决关键性问题,同时也积极向社区提交相关 Issue 和 PR,共同推动 Doris 社区的建设与发展。
未来规划
当前,网易云音乐内部所应用 Doris 集群已达 100 余台(包括日志存储和其他数据分析场景),后续还将在更多场景中推广落地。未来还将着重从以下几方面发力:
- 利用 Doris 冷热分层存储等能力,在提高查询性能的同时进一步降低成本。
- 使用 Doris Workload Group能力,进行相关资源隔离,提升集群稳定,按优先级保障业务使用。
- 增加在线查询等更多应用场景,Doris 出色的并发查询能力将为这些场景提供强有力的支持。
- Doris 的数据湖扩展能力也是网易云音乐非常看重的能力,这为规划中的 One-SQL 数据架构奠定了坚实基础。
更多关于日志场景应用实践及优化经验已经沉淀到的《日志存储与分析解决方案白皮书》 中,感兴趣的同学可以下载参考。
相关文章:
从 ClickHouse 到 Apache Doris:在网易云音乐日增万亿日志数据场景下的落地
导读:日志数据已成为企业洞察系统状态、监控网络安全及分析业务动态的宝贵资源。网易云音乐引入 Apache Doris 作为日志库新方案,替换了 ClickHouse。解决了 ClickHouse 运维复杂、不支持倒排索引的问题。目前已经稳定运行 3 个季度,规模达到…...

STM32——HAL库开发笔记19(串口中断接收实验)(参考来源:b站铁头山羊)
本实验,我们以中断的方式使得串口发送数据控制LED的闪烁速度,发送1,慢闪;发送2,速度正常;发送3,快闪。 一、电路连接图 二、实现思路&CubeMx配置 1、实现控制LED的闪烁速度 uint32_t bli…...
技术浅析(二):自然语言处理)
清影2.0(AI视频生成)技术浅析(二):自然语言处理
清影2.0(AI视频生成)中的自然语言处理(NLP)技术是其核心组件之一,负责将用户输入的自然语言文本转化为机器可以理解的语义表示,从而指导后续的视频生成过程。 一、基本原理 1. 目标 清影2.0的NLP技术旨在将用户输入的自然语言文本转化为机器可以理解的语义表示,从而指…...

Unity序列化多态数组
文档 Json序列化 脚本序列化 问题 Unity序列化数组时,只能存储基类内容,子类内容缺少。 Unity版本 2019.4.40 原因:Unity序列化不支持多态 测试类 将testarray类序列化时,多态列表personlist只转换了基类数据,子类…...

Spring Framework 中文官方文档
spring的部分中文文档。给总结在下面了: 看英文的大佬可以绕路了哈哈哈 一、 历史、设计理念、反馈、入门。 二、 IoC 容器、事件、资源、i18n、验证、数据绑定、类型转换、SpEL、AOP 三、 模拟对象、TestContext 框架、Spring MVC 测试、WebTestClient。 四、 事…...

力扣-二叉树-257 二叉树的所有路径
思路 除去根节点,每一层添加->val,然后使用前序遍历的顺序 代码 class Solution { public:vector<string> res;void getTreePaths(string s, TreeNode* root){s "->";s to_string(root->val);if(root->left nullptr &…...

如何调整 Nginx工作进程数以提升性能
🏡作者主页:点击! Nginx-从零开始的服务器之旅专栏:点击! 🐧Linux高级管理防护和群集专栏:点击! ⏰️创作时间:2025年2月15日14点20分 Nginx 的工作进程数࿰…...

FreeRTOS-rust食用指南
Rust 环境安装 rustup 是 Rust 的安装程序,也是它的版本管理程序,Linux 命令行下使用如下方式安装 # 安装 rustup curl --proto https --tlsv1.2 https://sh.rustup.rs -sSf | sh #更新 rustup rustup update# 版本检查 rustc -V cargo -VFreeRTOS-rust…...

如何使用智能化RFID管控系统,对涉密物品进行安全有效的管理?
载体主要包括纸质文件、笔记本电脑、优盘、光盘、移动硬盘、打印机、复印机、录音设备等,载体(特别是涉密载体)是各保密、机要单位保证涉密信息安全、防止涉密信息泄露的重要信息载体。载体管控系统主要采用RFID射频识别及物联网技术…...

0基础学LabVIEW
对于零基础的朋友来说,学习LabVIEW需要一个科学的学习路径和方法。通过观看优质的B站教程打好基础,再结合实际项目进行实践操作,能够快速提升LabVIEW的应用能力。以下是从入门到进阶的学习建议。 一、利用B站入门教程打基础 筛选优质教程…...

Go语言精进之路读书笔记(第二部分-项目结构、代码风格与标识符命名)
说明:《Go语言精进之路》第一部分-熟知Go语言的一切,不在博客中做读书笔记了,大家可以自己读一读,每个人心里都会有自己对Go语言的认识和理解。 直接从第二部分-项目接口、代码风格与标识符命名开始 第二章目录如下 第5条 使用…...

Windows server 2016 无法部署docker问题
根据流程winserver16安装docker ee,发现服务器管理器的添加角色和功能-功能中没有 container 根据流程winserver16安装docker desktop,发现安装 hyper-v 报错 原因: 本人测试用windows server 2016使用vmware搭建,而vmware本身可…...

智能AI之隐私安全,尤其是医疗
前言 智能AI能更好的服务我们的生活,各行各业都将会有她的影子。我们在依赖她的情况下,我们的隐私安全吗? 前两天分享了用她分析CT拍片、还有一份血检报告单,回复的确实比有些医生都说的专业全面。以至于我都有冲动依赖她开…...

【hot100】054螺旋矩阵
一、思路 这个题目主要有两个问题,一是什么时候切换方向,二是如何切换方向 问题一:此步移动完后,判断下一个元素,如果大于等于边界值(从0开始)或者小于边界值时或者访问数组为真时 问题二&am…...

【Java学习】类和对象
目录 一、选择取块解 二、类变量 三、似复刻变量 四、类变量的指向对象 五、变量的解引用访问 1.new 类变量(参) 2.this(参) 3.类变量/似复刻变量. 六、代码块 七、复制变量的赋值顺序 八、访问限定符 1.private 2.default 九、导类 一、选择取块解 解引用都有可以…...

TestHubo基础教程-创建项目
TestHubo是一款国产开源一站式测试工具,涵盖功能测试、接口测试、性能测试,以及 Web 和 App 测试,可以满足不同类型项目的测试需求。本文将介绍如何快速创建第一个项目,以快速入门上手。 1、创建项目 在 TestHubo 中,…...

JS 链表
文章目录 链表题的一些总结两种链表定义set存储链表节点,存的是整个空间同时处理长短不一的两个链表处理方法 while(l1 || l2)处理方法 while(l1 & l2) dummyhead的使用 链表题的一些总结 两种链表定义 class class ListNode {val;next null;constructor(va…...

数据结构(陈越,何钦铭)第三讲 树(上)
3.1 树与数的表示 3.1.1 顺序查找 int SequentialSearch(List Tbl,ElementType K){int i;Tbl->Element[0]K;for(iTbl->Length;Tbl->Element[i]!K;i--);return i; } typedef struct LNode *List; struct LNode{ElementType Element[MAXSIZE];int Length; };3.1.2 二分…...

企业文件安全:零信任架构下的文件访问控制
在企业数字化转型的进程中,传统的文件访问控制模型已难以满足日益复杂的网络安全需求。零信任架构作为一种新兴的安全理念,为企业的文件安全访问提供了全新的解决方案。 一、传统文件访问控制的局限性 传统的文件访问控制主要基于网络边界,…...
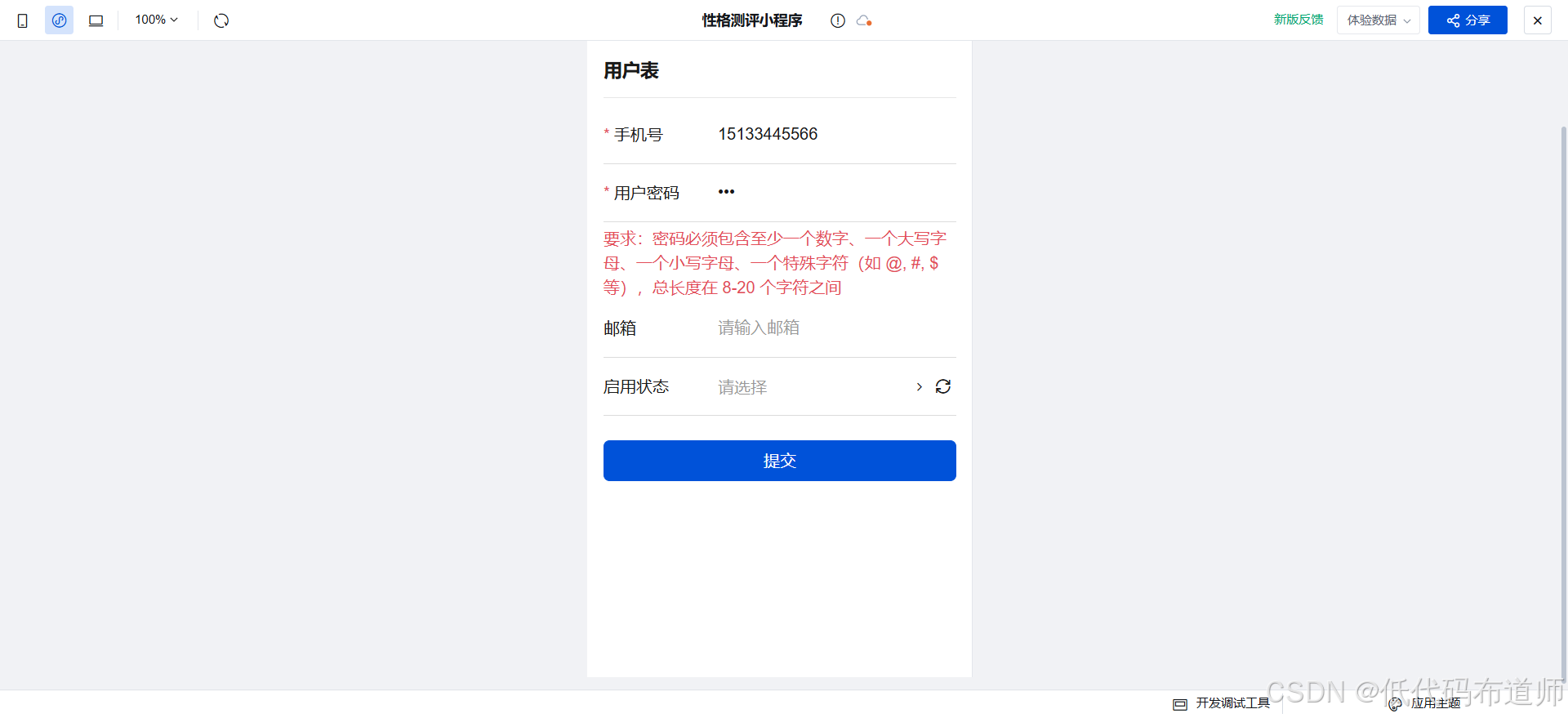
性格测评小程序06用户注册校验
目录 1 必填校验2 验证密码强度3 账号唯一性校验最终效果总结 上一篇我们介绍了用户注册的功能,注册的时候对密码进行了加密。除了密码加密外还需要验证账号的唯一性和密码强度的问题,本篇我们介绍一下如何在表单提交的时候增加自定义校验的能力。 1 必填…...

从科幻到芯片:用FPGA与MCU构建《红矮星号》数字逻辑系统
1. 项目概述:一次怀旧之旅与可编程逻辑的意外共鸣最近,我经历了一次纯粹由个人兴趣驱动的“考古”发现,它让我这个在电子设计自动化(EDA)和可编程逻辑领域浸淫了二十多年的老工程师,感到了一种久违的、孩子…...

人工智能、机器学习、深度学习及神经网络基础
第一部分:课程导入(2分钟)我们用45分钟从零入门,彻底搞懂人工智能、机器学习、深度学习到底是什么、有什么区别,同时了解现在AI都用在哪些地方、开发AI常用什么工具,最后弄懂所有AI技术最底层的核心原理——…...

临沂口碑好的展会老根红木哪家专业
在临沂,展会是家居建材行业交流与发展的重要平台,而老根红木等品牌在其中表现卓越,赢得了良好的口碑。下面,让我们深入了解这些专业品牌的魅力所在。一、老根红木背后的强大品牌支撑老根红木隶属于山东老根文化传媒有限公司&#…...

梳理一下前端模块化规范:CommonJS ESM AMD CMD UMD
前端模块化规范在发展过程中出现过多种规范,大多开发者都对这些名词有个印象,但问起来又有些模糊。本文的目的是做一个梳理,帮助记忆。先上一张对比表:类型核心定位语法关键词适用环境特点CommonJS(CJS)Nod…...
)
SAP销售模块实战:三种业务场景下,如何精准抓取销售成本与收入数据(附SQL思路)
SAP销售模块实战:三种业务场景下精准抓取销售成本与收入数据的SQL实现 销售毛利分析是企业经营决策的核心依据,但在SAP系统中直接获取这些数据却充满挑战。作为经历过多个行业项目的实施顾问,我发现不同成本结转方式会导致数据分布在完全不同…...
)
别再让PostgreSQL连接数爆了!手把手教你用pgBouncer 1.24.1给数据库‘减负’(附日志自动清理脚本)
PostgreSQL连接池实战:用pgBouncer 1.24.1破解高并发瓶颈 当你的应用用户量突破十万级大关时,是否经常在凌晨被"too many connections"的告警惊醒?这就像高峰期的地铁站,每个乘客(客户端连接)都…...

Geodesic:容器化DevOps工具箱,彻底解决环境不一致难题
1. 项目概述 如果你在团队里搞过基础设施即代码,肯定遇到过这种场景:新来的同事花了两天时间配环境,结果因为本地装的 Terraform 版本和 CI/CD 流水线里的差了 0.1.0,一个 plan 跑出来的结果天差地别;或者你本地的 …...

Godot游戏引擎集成MCP协议:AI智能体辅助开发实战指南
1. 项目概述:当游戏引擎遇见AI智能体如果你是一位游戏开发者,或者对AI应用开发感兴趣,最近可能已经感受到了一个趋势:AI智能体(Agent)正在从云端走向本地,从通用走向垂直。而游戏开发࿰…...

2025届毕业生推荐的十大AI学术工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 若要针对知网 AI 检测系统的反查机制来优化文稿,可从以下这些维度着手。其一&…...

手机号码定位系统:基于ASP.NET的开源解决方案深度解析
手机号码定位系统:基于ASP.NET的开源解决方案深度解析 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirr…...