【动手学强化学习】02多臂老虎机
问题定义
强化学习关注的是在于环境交互中学习,是一种试错学习的范式。在正式进入强化学习之前,我们先来了解多臂老虎机问题。该问题也被看作简化版的强化学习,帮助我们更快地过度到强化学习阶段。
有一个拥有 K K K 根拉杆的老虎机,拉动每根拉杆都有着对应奖励 R R R,且这些奖励可以进行累加。在各根拉杆的奖励分布未知的情况下,从头开始尝试,在进行 T T T 步操作次数后,得到尽可能高的累计奖励。

对于每个动作 a a a,我们定义其期望奖励是 Q ( a ) Q(a) Q(a)。是,至少存在一根拉杆,它的期望奖励不小于拉动其他任意一根拉杆,我们将该最优期望奖励表示为
Q ∗ = max a ∈ A Q ( a ) Q^* = \max_{a \in A}Q(a) Q∗=a∈AmaxQ(a)
为了更为直观的表示实际累计奖励和真实累计奖励之间的误差,我们引入懊悔概念,用来表示它们之间的差值。
R ( a ) = Q ∗ − Q ( a ) R(a) = Q^* - Q(a) R(a)=Q∗−Q(a)
下面我们编写代码来实现一个拉杆数为 10 的多臂老虎机。其中拉动每根拉杆的奖励服从伯努利分布(Bernoulli distribution),即每次拉下拉杆有的概率获得的奖励为 1,有的概率获得的奖励为 0。奖励为 1 代表获奖,奖励为 0 代表没有获奖。
import numpy as np
import matplotlib.pyplot as plt
class BernouliiBandit:def __init__(self, K):self.probs:np.ndarray = np.random.uniform(size=K) # type: ignore # 随机生成K个0~1的数,作为拉动每根拉杆的获奖 ## 概率self.best_idx = np.argmax(self.probs) # 获奖概率最大的拉杆self.best_prob = self.probs[self.best_idx] # 最大的获奖概率self.K = Kdef step(self, k):if np.random.rand() < self.probs[k]:return 1else:return 0
接下来我们用一个 Solver 基础类来实现上述的多臂老虎机的求解方案。
class Solver:def __init__(self, bandit) -> None:self.bandit = banditself.counts = np.zeros(self.bandit.K)self.regret = 0self.actions = []self.regrets = []def update_regret(self, k):self.regret += self.bandit.best_prob - self.bandit.probs[k]self.regrets.append(self.regret)def run_one_step(self):return NotImplementedErrordef run(self, num_steps):for _ in range(num_steps):k:int = self.run_one_step() #type:ignoreself.counts[k] += 1self.actions.append(k)self.update_regret(k)
解决方法
这个问题的难度在于探索和利用的平衡。一个最简单的策略就是一直选择第 k k k 根拉杆,但这样太依赖运气,万一是最差的一根,就会死翘翘;或者每次都随机选,这种方式只可能得到平均期望,而不会得到最优期望。因此探索和利用要相互权衡才有可能得到最好的结果。
贪心算法
完全贪婪算法即在每一时刻采取期望奖励估值最大的动作(拉动拉杆),这就是纯粹的利用,而没有探索,所以我们通常需要对完全贪婪算法进行一些修改,其中比较经典的一种方法为 ϵ \epsilon ϵ -Greedy 算法。 ϵ \epsilon ϵ -Greedy 在完全贪婪算法的基础上添加了噪声,每次以概率 ϵ \epsilon ϵ 选择以往经验中期望奖励估值最大的那根拉杆(利用),以概率 ϵ \epsilon ϵ 随机选择一根拉杆(探索)
class EpsilonGreedy(Solver):def __init__(self, bandit, epsilon=0.1, init_prob=1.0):super(EpsilonGreedy, self).__init__(bandit)self.epsilon = epsilonself.estimates = np.array([init_prob]*self.bandit.K)def run_one_step(self):if np.random.random() < self.epsilon:k = np.random.randint(0, self.bandit.K)else:k = np.argmax(self.estimates)r = self.bandit.step(k)self.estimates[k] += 1.0/(self.counts[k] + 1) * (r - self.estimates[k])return k
为了更加直观的展示,可以把每一时间步的累积函数绘制出来。
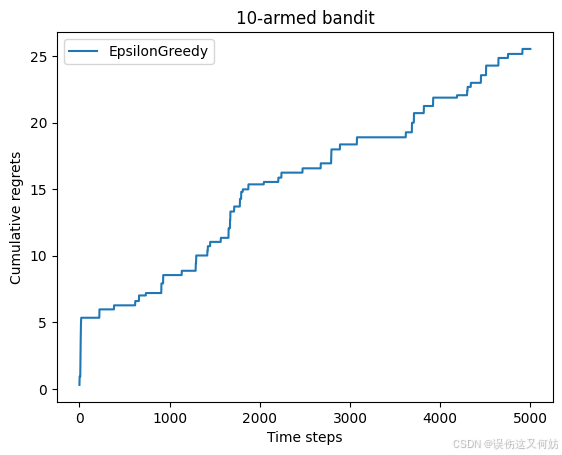
def plot_results(solvers, solver_names):for idx, solver in enumerate(solvers):time_list = range(len(solver.regrets))plt.plot(time_list, solver.regrets, label=solver_names[idx])plt.xlabel('Time steps')plt.ylabel('Cumulative regrets')plt.title('%d-armed bandit' % solvers[0].bandit.K)plt.legend()plt.show()np.random.seed(1)
epsilon_greedy_solver = EpsilonGreedy(bandit_10_arm, epsilon=0.01)
epsilon_greedy_solver.run(5000)
print('epsilon-贪婪算法的累积懊悔为:', epsilon_greedy_solver.regret)
plot_results([epsilon_greedy_solver], ["EpsilonGreedy"])
上置信界算法
上置信界算法是一种经典的基于不确定性的策略算法,它的思想用到了一个非常著名的数学原理:霍夫丁不等式。
在霍夫丁不等式中,令 ( X 1 , … , X n ) (X_1, \dots, X_n) (X1,…,Xn) 为 n n n 个独立同分布的随机变量,取值范围为 ([0,1]),其经验期望为:
x ˉ n = 1 n ∑ j = 1 n X j \bar{x}_n = \frac{1}{n} \sum_{j=1}^{n} X_j xˉn=n1j=1∑nXj
则有:
P { E [ X ] ≥ x ˉ n + u } ≤ e − 2 n u 2 \mathbb{P} \left\{ \mathbb{E}[X] \geq \bar{x}_n + u \right\} \leq e^{-2nu^2} P{E[X]≥xˉn+u}≤e−2nu2
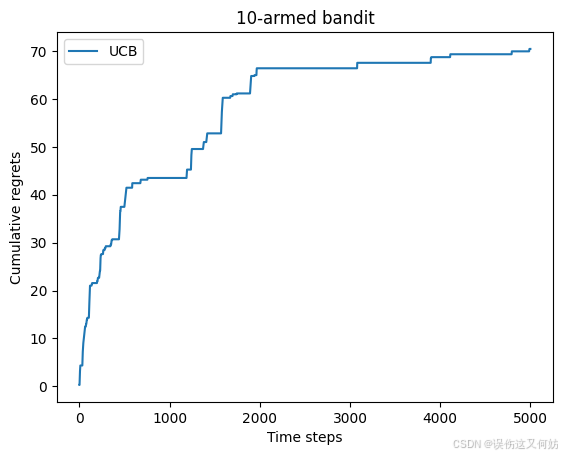
class UCB(Solver):def __init__(self, bandit, init_prob, coef):super(UCB, self).__init__(bandit)self.total_count = 0self.estimates = np.array([init_prob*1.0]*self.bandit.K)self.coef = coefdef run_one_step(self):self.total_count += 1ucb = self.estimates + self.coef * np.sqrt(np.log(self.total_count) / (2 * (self.counts + 1)))k = np.argmax(ucb)r = self.bandit.step(k)self.estimates[k] += (r - self.estimates[k]) / (self.counts[k] + 1)return k
np.random.seed(1)
UCB_solver = UCB(bandit_10_arm, 1, 1)
UCB_solver.run(5000)
print('上置信界算法的累积懊悔为:', UCB_solver.regret)
plot_results([UCB_solver], ["UCB"])
汤普森采样
先假设拉动每根拉杆的奖励服从一个特定的概率分布,然后根据拉动每根拉杆的期望奖励来进行选择。但是由于计算所有拉杆的期望奖励的代价比较高,汤普森采样算法使用采样的方式,即根据当前每个动作 的奖励概率分布进行一轮采样,得到一组各根拉杆的奖励样本,再选择样本中奖励最大的动作。可以看出,汤普森采样是一种计算所有拉杆的最高奖励概率的蒙特卡洛采样方法。
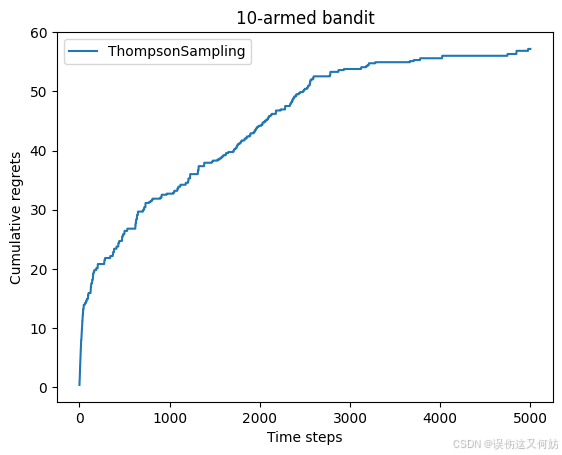
class ThompsonSampling(Solver):def __init__(self, bandit) -> None:super(ThompsonSampling, self).__init__(bandit)self._a = np.ones(self.bandit.K)self._b = np.ones(self.bandit.K)def run_one_step(self):samples = np.random.beta(self._a, self._b)k = np.argmax(samples)r = self.bandit.step(k)self._a[k] += rself._b[k] += (1-r)return knp.random.seed(1)
thompson_sampling_solver = ThompsonSampling(bandit_10_arm)
thompson_sampling_solver.run(5000)
print('汤普森采样算法的累积懊悔为:', thompson_sampling_solver.regret)
plot_results([thompson_sampling_solver], ["ThompsonSampling"])
相关文章:
【动手学强化学习】02多臂老虎机
问题定义 强化学习关注的是在于环境交互中学习,是一种试错学习的范式。在正式进入强化学习之前,我们先来了解多臂老虎机问题。该问题也被看作简化版的强化学习,帮助我们更快地过度到强化学习阶段。 有一个拥有 K K K 根拉杆的老虎机&#…...

【网络编程】之Udp网络通信步骤
【网络编程】之Udp网络通信步骤 TCP网络通信TCP网络通信的步骤对于服务器端对于客户端 TCP实现echo功能代码实现服务器端getsockname函数介绍 客户端效果展示 对比两组函数 TCP网络通信 TCP网络通信的步骤 对于服务器端 创建监听套接字。(调用socket函数ÿ…...

Java 基于 SpringBoot+Vue 的家政服务管理平台设计与实现
博主介绍:✌程序员徐师兄、8年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战*✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

架构——Nginx功能、职责、原理、配置示例、应用场景
以下是关于 Nginx 的功能、职责、原理、配置示例、应用场景及其高性能原因的详细说明: 一、Nginx 的核心功能 1. 静态资源服务 功能:直接返回静态文件(如 HTML、CSS、JS、图片、视频等)。配置示例:server {listen 80…...

Spring Boot中使用Flyway进行数据库迁移
文章目录 概要Spring Boot 集成 FlywayFlyway 其他用法bug错误Flyway版本不兼容数据库存在表了Flyway 的校验和(Checksum)不匹配 概要 在 Spring Boot 项目开发中,数据库的变更不可避免。手动执行 SQL 脚本不仅容易出错,也难以维…...

CAS单点登录(第7版)9.属性
如有疑问,请看视频:CAS单点登录(第7版) 属性 属性定义 概述 属性定义 从身份验证或属性存储库源获取和解析 CAS 中属性的定义时,往往使用其名称进行定义和引用,而无需任何其他元数据或修饰。例如&#…...

137,【4】 buuctf web [SCTF2019]Flag Shop
进入靶场 都点击看看 发现点击work会增加¥ 但肯定不能一直点下去 抓包看看 这看起来是一个 JWT(JSON Web Token)字符串。JWT 通常由三部分组成,通过点(.)分隔,分别是头部(Header&…...

P9853 [入门赛 #17] 方程求解
P9853 [入门赛 #17] 方程求解 - 洛谷 题目描述 小A有n个关于x的方程,第i个方程形如aixibici。方程的解x均为正整数,例如下面几个方程都是符合要求的方程: 2x 4 10 -3x 13 10 4x - 8 16 其中,第一组方程的解为x1…...

【网络安全 | 漏洞挖掘】跨子域账户合并导致的账户劫持与删除
未经许可,不得转载。 文章目录 概述正文漏洞成因概述 在对目标系统进行安全测试时,发现其运行着两个独立的域名——一个用于司机用户,一个用于开发者/企业用户。表面上看,这两个域名各自独立管理账户,但测试表明它们在处理电子邮件变更时存在严重的逻辑漏洞。该漏洞允许攻…...

spring集成activiti流程引擎(源码)
前言 activiti工作流引擎项目,企业erp、oa、hr、crm等企事业办公系统轻松落地,请假审批demo从流程绘制到审批结束实例。 源码获取:本文末个人名片直接获取。 一、项目形式 springbootvueactiviti集成了activiti在线编辑器,流行…...

ROS基本功能
1.Topic话题与Message消息(主要通讯方式) 基本规则 发布消息的步骤 常用工具 话题的订阅 使用launch启动多个节点...

C++基础系列【13】类的成员初始化
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...

Redis 03章——10大数据类型概述
一、which10 (1)一图 (2)提前声明 这里说的数据类型是value的数据类型,key的类型都是字符串 官网:Understand Redis data types | Docs (3)分别是 1.3.1redis字符串࿰…...

Ubuntu 上安装 Elasticsearch 7.6.0
要在 Ubuntu 24.04 上安装 Elasticsearch 7.6.0,可以按照以下步骤进行: 步骤 1: 更新系统依赖 确保系统是最新的,并安装必要的依赖包: sudo apt update sudo apt upgrade -y sudo apt install -y apt-transport-https openjdk-1…...

Android ListPreference使用
Android ListPreference使用 参考 添加链接描述 导入 androidx.preference.ListPreferenceListPreference是Android中的一个Preference子类,用于显示一个可选择的列表,并且可以保存用户所选择的值。它继承自DialogPreference,可以在用户点击时弹出一个对话框,显示可选择的…...

Java 大视界 -- 绿色大数据:Java 技术在节能减排中的应用与实践(90)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

计算四个锚点TOA定位中GDOP的详细步骤和MATLAB例程
该MATLAB代码演示了在三维空间中,使用四个锚点的TOA(到达时间)定位技术计算几何精度衰减因子(GDOP)的过程。如需帮助,或有导航、定位滤波相关的代码定制需求,请联系作者 文章目录 DOP计算原理MATLAB例程运行结果示例关键点说明扩展方向另有文章: 多锚点Wi-Fi定位和基站…...

英码科技基于昇腾算力实现DeepSeek离线部署
DeepSeek-R1 模型以其创新架构和高效能技术迅速成为行业焦点。如果能够在边缘进行离线部署,不仅能发挥DeepSeek大模型的效果,还能确保数据处理的安全性和可控性。 英码科技作为AI算力产品和AI应用解决方案服务商,积极响应市场需求࿰…...
CTex安装和使用(1)
CTeX是一款基于TeX/LaTeX的集成开发环境(IDE),主要用于文档排版,特别是在处理复杂的数学公式和学术论文方面具有显著优势。以下是CTeX的一些基本信息: 功能 文档编辑 :提供了一个友好的界面用于编辑LaTeX…...

Oracle序列(基础操作)
序列概念 序列是用于生成唯一、连续序号的对象。 序列可以是升序的,也可以是降序的。 使用CREATE SEQUENCE语句创建序列。 start with 1 指定第一个序号从1开始 increment by 1 指定序号之间的间隔为1 increment by -1 降序1000 999 998这样 maxvalue 2000 表…...

当你的Android设备‘睡不醒’:wakelock机制详解与常见问题排查
当你的Android设备“睡不醒”:wakelock机制详解与常见问题排查 你是否遇到过这样的情况:明明已经锁屏了,但手机电量却消耗得异常快?或者设备在应该休眠的时候依然保持活跃,导致发热和续航缩水?这些问题很可…...

Vibe Draw实时通信机制:SSE与WebSocket如何协同工作
Vibe Draw实时通信机制:SSE与WebSocket如何协同工作 【免费下载链接】vibe-draw 🎨 Turn your roughest sketches into stunning 3D worlds by vibe drawing 项目地址: https://gitcode.com/gh_mirrors/vi/vibe-draw Vibe Draw是一款能将粗略草图…...

SAFE框架:提升LLM长文本生成质量的关键技术
1. 项目背景与核心价值在大型语言模型(LLM)应用爆发式增长的当下,长文本生成一直是业界公认的技术难点。传统方法在处理超过2048个token的文本时,普遍面临三大痛点:上下文丢失、逻辑断层和风格漂移。我曾参与过多个企业…...

命令行光标增强工具:动态上下文感知与效率提升实践
1. 项目概述:一个为开发者量身定制的命令行光标增强套件如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你一定对那个单调闪烁的光标再熟悉不过了。无论是调试代码、管理服务器,还是…...

福布斯《2026 年 AI:自动化与未来职场十大预测》核心内容总结
2026 年生成式 AI 智能自动化从 “尝鲜” 进入企业规模化落地,不再只是工具,而是重塑岗位、工作方式、企业组织形态的核心变量;AI 不会完全取代人类,而是重构工作、人机分工重新洗牌。 十大核心预测浓缩总结 AI 智能体…...

新手首次在Taotoken平台获取API Key并完成模型调用的全指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手首次在Taotoken平台获取API Key并完成模型调用的全指南 对于初次接触大模型API的开发者来说,从注册平台到成功发出…...

StreamFX架构深度解析:现代OBS插件框架设计与技术实现
StreamFX架构深度解析:现代OBS插件框架设计与技术实现 【免费下载链接】obs-StreamFX StreamFX is a plugin for OBS Studio which adds many new effects, filters, sources, transitions and encoders! Be it 3D Transform, Blur, complex Masking, or even custo…...

掌握中兴光猫高级管理:专业级Telnet权限获取实现指南
掌握中兴光猫高级管理:专业级Telnet权限获取实现指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫设备的高级网络管理权限获取一直是技术爱好者和网络管理员关注…...

STC8H内置ADC的隐藏技巧:如何用1.19V基准源实现MCU供电电压监测?
STC8H内置ADC的隐藏技巧:如何用1.19V基准源实现MCU供电电压监测? 在物联网设备和便携式电子产品的设计中,电源管理一直是工程师们需要重点考虑的环节。尤其是对于电池供电的设备,实时监测MCU的供电电压不仅能够预警低电量状态&…...

告别日志混乱:用Kiwi Syslog Daemon的Rules和Filters,给Linux/Windows服务器日志自动分类归档
告别日志混乱:用Kiwi Syslog Daemon的Rules和Filters实现智能日志管理 在混合IT架构中,Windows和Linux服务器每天产生海量日志数据,关键错误信息往往被淹没在无关紧要的日志洪流中。Kiwi Syslog Daemon作为一款专业的日志管理工具,…...