NLP 八股 DAY1:BERT
BERT全称:Pre-training of deep bidirectional transformers for language understanding,即深度双向Transformer。

模型训练时的两个任务是预测句⼦中被掩盖的词以及判断输⼊的两个句⼦是不是上下句。在预训练 好的BERT模型后⾯根据特定任务加上相应的⽹络,可以完成NLP的下游任务,⽐如⽂本分类、机器 翻译等。Masked LM和Next Sentence Prediction。
只使⽤了transformer的encoder部分,它的整体框架是由多层transformer的encoder堆叠⽽成的。 每⼀层的encoder则是由⼀层muti-head-attention和⼀层feed-forword组成,⼤的模型有24层, 每层16个attention heads,⼩的模型12层,每层12个attention heads。feed-forward的维度是4 * d_model也就是4 * 768 = 3072。
在BERT中,输⼊的向量是由三种不同的embedding求和⽽成,分别是: a. wordpiece embedding:词嵌⼊,WordPiece是指将单词划分成⼀组有限的公共⼦词单元,能在单词的有效性和字符的灵活性之间取得⼀个折中的平衡; b. position embedding:不是三⻆函数⽽是⼀个跟着训练学出来的向量,也就是nn.Embedding; c. segment embedding:⽤于区分两个句⼦的向量表示。这个在问答等⾮对称句⼦中是⽤区别的。
BERT常⻅⾯试问题:bert的具体⽹络结构,以及训练过程,bert为什么⽕,它在什么的基础上改进 了些什么?
答:bert是⽤了transformer的encoder侧的⽹络,作为⼀个⽂本编码器,使⽤⼤规模数据进⾏预训练,预训练使⽤两个loss,⼀个是mask LM,遮蔽掉源端的⼀些字,然后根据上下⽂去预测这些字;⼀个是next sentence,判断两个句⼦是否在⽂章中互为上下句,然后使⽤了⼤规模的语料去预训练。在它之前是GPT,GPT是⼀个单向语⾔模型的预训练过程(它和gpt的区别就是bert为啥叫双向bi-directional),更适⽤于⽂本⽣成。
mask的具体做法:Masked LM 即掩码语⾔模型,它和⼀般的语⾔模型如N元语⾔模型不同。 a. N元语⾔模型第 i 个字的概率和它前 i-1 个字有关,也就是要预测第 i 个字,那么模型就得先从头到尾依次预测出第1个到第 i-1 个字,再来预测第 i 个字;这样的模型⼀般称为⾃回归模型 (Autoregressive LM)。 b. ⽽Masked LM 通过随机将句⼦中的某些字MASK掉,然后通过该MASK掉的字的上下⽂来预测 该字,我们称这样的语⾔模型为⾃编码语⾔模型(Autoencoder LM)。Bert 的 MASK 机制是 这样的:它以token为单位随机选择句⼦中 15%的 token,然后将其中 80% 的 token 使⽤ [MASK] 符号进⾏替换,将 10% 使⽤随机的其他 token 进⾏替换,剩下的10%保持不变。
更细节的阐述:在⼀个句⼦中,随机选中⼀定百分⽐(实际是15%)的token,将这些token⽤" [MASK]"替换。然后⽤分类模型预测"[MASK]"实际上是什么词。作者发现,在pre-training阶段, ⼀句话中有15%的token被选中,然后将这些token⽤"[MASK]"替换。⽽在fine-tuning阶段,给 BERT模型的输⼊并没有token被"[MASK]"替换。为了减少pre-training与fine-tuning阶段的差异, 在pre-training阶段,对MLM任务进⾏改进:在被选中的15%的token中,有80%被替换为" [MASK]",有10%被替换为⼀个随机token,有10%保持不变。如下所示:
 具体怎么做分类:输⼊[CLS]我 mask 中 mask 天 安 ⻔[SEP],预测句⼦的mask,多分类问题。
具体怎么做分类:输⼊[CLS]我 mask 中 mask 天 安 ⻔[SEP],预测句⼦的mask,多分类问题。
NSP任务:下⼀个句⼦预测,⽤于判断两个句⼦是否互为上下⽂。输⼊[CLS]a[SEP]b[SEP],预测b 是否为a的下⼀句,即⼆分类问题。
具体实现:因为与⽂本中已有的其它词相⽐,CLS这个⽆明显语义信息的符号会更“公平”地融合⽂ 本中各个词的语义信息,从⽽更好的表示整句话的语义。
 11. BERT和transformer
11. BERT和transformer
a. 相同点:
- ⅰ. 基础架构相同,BERT使⽤Transformer作为编码器;
- ⅱ. 都使⽤了位置编码;
- ⅲ. 都是多层堆叠的层级结构。
b. 不同点:
- ⅰ. 训练⽅式不同,Transformer在训练时,输⼊序列从左到右进⾏处理,逐步⽣成输出。这意 味着在⽣成每个位置的隐藏表示时,只能依赖于已经⽣成的左侧部分;BERT: 使⽤了双 向(双向上下⽂)的训练⽅式。它通过遮蔽输⼊⽂本中的⼀些词,然后预测这些词的上下 ⽂,从⽽使模型能够考虑到每个词的上下⽂信息。
- ⅱ. 此外还有输出层的差异:Transformer通常在输出层使⽤Softmax函数进⾏概率分布的计 算,适⽤于分类任务,BERT常⽤于⽣成上下⽂相关的词嵌⼊,⽽不是直接在输出层进⾏分 类。
BERT采⽤LayerNorm结构,和BatchNorm的区别主要是做规范化的维度不同
- a. BatchNorm针对⼀个batch⾥⾯的数据进⾏规范化,针对单个神经元进⾏,⽐如batch⾥⾯有64 个样本,那么规范化输⼊的这64个样本各⾃经过这个神经元后的值(64维)。图像领域⽤BN⽐ 较多的原因是因为每⼀个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被⼀起规范化。
- b. LayerNorm则是针对单个样本,不依赖于其他数据,常被⽤于⼩mini-batch场景、动态⽹络场 景和 RNN,特别是⾃然语⾔处理领域,就BERT来说就是对每层输出的隐层向量(768维)做规范化。
Attention时为啥要除以根号下dk:作者在论⽂中的解释是点积后的结果⼤⼩是跟维度成正⽐的,所以经过softmax以后,梯度就会变很⼩,除以根号下dk后可以让attention的权重分布⽅差为1,⽽不是dk。
NLP中构造词表
- a. 传统构造词表的⽅法,是先对各个句⼦进⾏分词,然后再统计并选出频数最⾼的前N个词组成词表。
- b. 存在问题: ⅰ. 模型预测的词汇是开放的,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将 ⽆法处理及⽣成; ⅱ. 词表中的低频词/稀疏词在模型训练过程中⽆法得到充分训练,进⽽模型不能充分理解这些 词的语义; ⅲ. ⼀个单词因为不同的形态会产⽣不同的词,但是在词表中这些词会被当作不同的词处理, ⼀⽅⾯增加了训练冗余,另⼀⽅⾯也造成了⼤词汇量问题。
上述问题的⼀种解决思路是使⽤字符粒度来表示词表,虽然能够解决OOV问题,但单词被拆分成字 符后,⼀⽅⾯丢失了词的语义信息,另⼀⽅⾯,模型输⼊会变得很⻓,这使得模型的训练更加复杂 难以收敛。针对上述问题,Subword(⼦词)模型⽅法被提出。它的划分粒度介于词与字符之间,⽐如 可以将”looking”划分为”look”和”ing”两个⼦词,⽽划分出来的"look",”ing”⼜能够⽤来构造其它 词,如"look"和"ed"⼦词可组成单词"looked",因⽽Subword⽅法能够⼤⼤降低词典的⼤⼩,同时对 相近词能更好地处理。
⽬前有三种主流的Subword算法,它们分别是:Byte Pair Encoding (BPE), WordPiece和Unigram Language Model。
理解BERT中的三部分输⼊:(1)wordpiece embedding:词嵌⼊,使⽤wordpiece⽅法对语料进 ⾏分词并编码;(2)position embedding:不是三⻆函数⽽是⼀个跟着训练学出来的向量,也就是 nn.Embedding;(3)segment embedding⽤于处理句⼦对任务,对输⼊序列中的每个单词标记其 所属句⼦,通常使⽤ 0 和 1 表示两个句⼦,然后通过嵌⼊层将每个句⼦标记转换为⼀个向量表示。
当⼀个batch的数据输⼊模型的时候,⼤⼩为(batch_size, max_len, embedding),其中batch_size 为batch的批数,max_len为每⼀批数据的序列最⼤⻓度,embedding则为每⼀个单词或者字的 embedding维度⼤⼩。⽽Batch Normalization是在batch间选择同⼀个位置的值做归⼀化,相当于 是对batch⾥相同位置的字或者单词embedding做归⼀化,Layer Normalization是在⼀个Batch⾥⾯ 的每⼀⾏做normalization,相当于是对每句话的embedding做归⼀化。显然,LN更加符合处理⽂本 的直觉。
相关文章:
NLP 八股 DAY1:BERT
BERT全称:Pre-training of deep bidirectional transformers for language understanding,即深度双向Transformer。 模型训练时的两个任务是预测句⼦中被掩盖的词以及判断输⼊的两个句⼦是不是上下句。在预训练 好的BERT模型后⾯根据特定任务加上相应的⽹…...

演示synchronized锁机制用法的简单Demo
演示synchronized锁机制用法的简单Demo。我们以"银行开户"场景为例:每个用户只能创建一个账户(模拟类似原代码中每个用户只能有一个私有空间的限制)。 第1步:创建项目结构 demo-lock ├── src/main/java/com/exampl…...

Datawhale 数学建模导论二 笔记1
第6章 数据处理与拟合模型 本章主要涉及到的知识点有: 数据与大数据Python数据预处理常见的统计分析模型随机过程与随机模拟数据可视化 本章内容涉及到基础的概率论与数理统计理论,如果对这部分内容不熟悉,可以参考相关概率论与数理统计的…...

差分解方程
差分解方程 差分法在数值求解偏微分方程(PDEs)和常微分方程(ODEs)时,可以分为隐式格式和显式格式。以下是两者的主要区别: 显式格式(Explicit Scheme) 时间推进: 显式格…...

EasyExcel 复杂填充
EasyExcel Excel表格中用{}或者{.} 来表示包裹要填充的变量,如果单元格文本中本来就有{、}左右大括号,需要在括号前面使用斜杠转义\{ 、\}。 代码中被填充数据的实体对象的成员变量名或被填充map集合的key需要和Excel中被{}包裹的变量名称一致。 …...

ESP32通过MQTT连接阿里云平台实现消息发布与订阅
文章目录 前言 一、准备工作 二、阿里云平台配置 三、代码实现 总结 前言 本文将介绍如何使用ESP32开发板通过MQTT协议连接阿里云物联网平台,并实现消息的发布与订阅功能。我们将使用Arduino IDE进行开发,并借助PubSubClient库实现MQTT通信。 一、准备…...

NVIDIA Jetson Orin Nano 刷机过程
1. 背景 新到手 NVIDIA Jetson Orin Nano 插上显示屏,显示如下: 这是UEFI Shell,UEFI Shell(统一可扩展固件接口外壳程序)是一种基于UEFI规范的交互式命令行工具,它运行在UEFI固件环境中,为用…...

C#学习之数据转换
目录 一、创作说明 二、数据类型之间的转换 1.数据类型之间的转换表格 2.代码示例 三、进制之间的转换 1.进制之间的转换表格 2.代码示例 四、ASCII 编码和字符之间的转换 1.ASCII 编码和字符之间的转换表格 2.代码示例 五、总结 一、创作说明 C#大多数时候都是和各…...

typecho快速发布文章
typecho_Pytools typecho_Pytools工具由python编写,可以快速批量的在本地发布文章,不需要登陆后台粘贴md文件内容,同时此工具还能查看最新的评论消息。… 开源地址: GitHub Gitee 使用教学:B站 一、主要功能 所有操作不用登陆博…...

深度学习R4周:LSTM-火灾温度预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 任务: 数据集中提供了火灾温度(Tem1)、一氧化碳浓度(CO 1)烟雾浓度(Soot 1)…...

探索Java中的集合类_特性与使用场景
1. 引言 1.1 Java集合框架概述 Java集合框架(Java Collections Framework, JCF)是Java中用于存储和操作一组对象的类和接口的统称。它提供了多种数据结构来满足不同的需求,如列表、集合、映射等。JCF的核心接口包括Collection、List、Set、Queue和Map,以及它们的各种实现…...

自动化遇到的问题记录(遇到问题就更)
总结回归下自己这边遇到的一些问题 “EOF错误”,获取不到csv里面的内容 跑多csv文件里的场景,部分场景的请求值为 1、检查csv文件里不能直接是[]开头的参数,把[]改到ms平台的请求参数里 2、有时可能是某个参数值缺了双引号的其中一边 met…...

【云安全】云原生- K8S kubeconfig 文件泄露
什么是 kubeconfig 文件? kubeconfig 文件是 Kubernetes 的配置文件,用于存储集群的访问凭证、API Server 的地址和认证信息,允许用户和 kubectl 等工具与 Kubernetes 集群进行交互。它通常包含多个集群的配置,支持通过上下文&am…...

【愚公系列】《Python网络爬虫从入门到精通》008-正则表达式基础
标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度…...
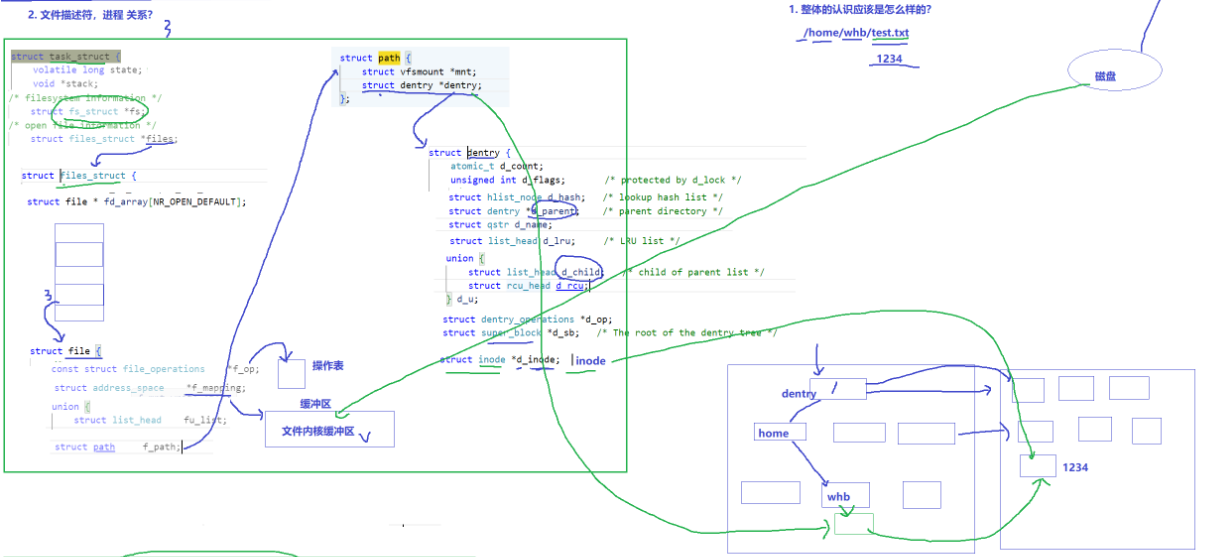
【Linux】Ext2文件系统、软硬链接
Ext2文件系统 一.理解硬件1.磁盘、服务器、机柜、机房2.磁盘的物理结构3.磁盘的存储结构4.磁盘的逻辑结构1.理解过程2.真实过程 5.CHS地址、LBA地址转换 二.引入文件系统1.引入"块"概念2.引入"分区"概念3.引入"inode"概念 三.Ext2文件系统1.宏观…...

ATF系统安全从入门到精通
CSDN学院课程连接:https://edu.csdn.net/course/detail/39573...

【算法专场】哈希表
目录 前言 哈希表 1. 两数之和 - 力扣(LeetCode) 算法分析 算法代码 面试题 01.02. 判定是否互为字符重排 编辑算法分析 算法代码 217. 存在重复元素 算法分析 算法代码 219. 存在重复元素 II 算法分析 算法代码 解法二 算法代码 算法…...

Beszel监控Docker安装
一、Beszel Hub安装 #Beszel Hub安装 mkdir -p ./beszel_data && \ docker run -d \--name beszel \--restartunless-stopped \-v ./beszel_data:/beszel_data \-p 8090:8090 \henrygd/beszel#创建账号 账号/密码:adminadmin.com/adminadmin.com 二、Besz…...
:从入门到精通的完整指南)
如何学习Elasticsearch(ES):从入门到精通的完整指南
如何学习Elasticsearch(ES):从入门到精通的完整指南 嘿,小伙伴们!如果你对大数据搜索和分析感兴趣,并且想要掌握Elasticsearch这一强大的分布式搜索引擎,那么你来对地方了!本文将为…...

【mybatis】基本操作:详解Spring通过注解和XML的方式来操作mybatis
mybatis 的常用配置 配置数据库连接 #驱动类名称 spring.datasource.driver-class-namecom.mysql.cj.jdbc.Driver #数据库连接的url spring.datasource.urljdbc:mysql://127.0.0.1:3306/mybatis_test characterEncodingutf8&useSSLfalse #连接数据库的名 spring.datasourc…...

终极指南:如何快速配置和优化yuzu Switch模拟器
终极指南:如何快速配置和优化yuzu Switch模拟器 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu yuzu是一款功能强大的任天堂Switch模拟器,能够在PC上流畅运行Switch游戏。本指南将帮助你从零…...
)
告别官方手册!i.MX6ULL SD卡启动盘制作保姆级教程(含dd命令详解与分区避坑)
i.MX6ULL SD卡启动盘制作实战指南:从原理到避坑全解析 引言 第一次拿到i.MX6ULL开发板时,很多开发者都会面临一个看似简单却暗藏玄机的任务——制作SD卡启动盘。官方文档虽然提供了步骤,但往往缺乏对底层原理的解释,导致新手在遇到…...

研究生组会多久开一次合理?
研究生组会每1至2周举行一次较为合理,具体频率应根据学科特点、研究进度和团队需求动态调整。不同学科的组会频率建议: 理工科(实验类):建议每周一次。实验数据更新快,高频组会有助于及时发现问题、…...

地磁暴如何影响卫星电机控制与轨道动力学:SpaceX星链卫星损失事件深度解析
1. 项目概述:当太阳风暴成为卫星的“隐形杀手” 2022年2月,SpaceX经历了一次代价高昂的教训。他们刚刚发射的一批49颗星链(Starlink)卫星,在进入预定轨道的初期,遭遇了一场突如其来的地磁暴。结果ÿ…...

5月19日Fitbit应用更名Google Health,功能升级、隐私有保障,高级版费用调整
Fitbit应用重大改版周四,于2021年完成对Fitbit收购的谷歌宣布,Fitbit应用程序即将迎来重大改版,甚至连名字都将改变,它将于5月19日更名为Google Health。谷歌产品管理总监泰勒赫尔格伦(Taylor Helgren)对CN…...

G-Helper终极指南:华硕笔记本轻量控制工具从入门到精通
G-Helper终极指南:华硕笔记本轻量控制工具从入门到精通 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, E…...

抖音直播间弹幕数据抓取技术深度解析:如何绕过复杂签名机制实现实时数据采集
抖音直播间弹幕数据抓取技术深度解析:如何绕过复杂签名机制实现实时数据采集 【免费下载链接】DouyinLiveWebFetcher 抖音直播间网页版的弹幕数据抓取(2025最新版本) 项目地址: https://gitcode.com/gh_mirrors/do/DouyinLiveWebFetcher …...

构建模块化技能编排系统:Prime-Weaver架构设计与工程实践
1. 项目概述与核心价值最近在梳理个人技能栈和项目经验时,我重新审视了一个名为“prime-weaver-skill”的仓库。这个项目名称听起来有点抽象,但它的核心思想非常明确:构建一个能够将多种基础能力(Prime)高效编织&#…...

基于AST的重复代码检测与自动化重构工具code-deduplicator详解
1. 项目概述:告别代码“复制粘贴”,让重构自动化在多年的开发经历中,我见过太多因为“复制粘贴”而变得臃肿不堪的代码库。一段逻辑,因为业务场景的细微差异,或者仅仅是因为不同开发者在不同时间点的“偷懒”ÿ…...

FPGA与EtherSound在专业音频设备中的低延迟实现
1. FPGA与EtherSound技术概述在专业音频设备开发领域,实时性和信号保真度是两大核心诉求。传统基于通用处理器的架构往往难以同时满足这两点要求,而FPGA(现场可编程门阵列)因其独特的硬件可编程特性和并行计算能力,正逐…...