RL--2
强化学习当中最难的两个点是:
1.reward delay;
2.agent的行为会影响到之后看到的东西,所以agent要学会探索世界;
关于强化学习的不同类型,可以分为以下三种:
一种是policy based:可以理解为它是去学习一个很强的actor,由actor去指导下一步的行动;
一种是value-based:学习一个好的critic,这个critic其实就是价值函数,由价值函数去指导做下一步的行动;
还有一种是当下最流行的二者结合的方法叫actor+critic,也是PPO 用的方法;

policy based

首先我们用神经网络去学习一个actor,他需要根据环境观察到的state(obervation)去得到action的output;
加下来,我们要判断这个action好不好,靠的是环境反馈的reward;
对于一次的游戏体验而已,reward是每次action累计的return的总和;

但是,我们知道游戏具有随机性,每次的整个游戏过程我们记录为T(s1,a1,r1…);
哪怕我们使用同一个actor,由于游戏本身的随机性T也是不一样的;
但是不同的actor得到的T的概率和倾向性肯定是不一样的;
比如说如果你的actor是见到敌人就呆住,那么你的T大概率就是敌人一出现你就挂了;
所以我们不能拿单次游戏的reward作为此actor的reward,我们要进行多次游戏,这就好比在T的分布中进行采样;N次采样取平均作为这个actor的reward;

接下来我们的目标是优化actor的参数去最大化游戏反馈的reward;

注意Trajactery对应得reward跟待优化的参数没关系,他是环境的反馈,所以可不可导无所谓;


这里要注意R(T)是某个trajactory完成后的reward,而不是某个action的reward,这个也很好理解;

关于这里为什么要取log的解释是,不同的action采样到的频次不一样,模型会提升采样到的多的action的概率,哪怕reward没有很高,所以要除以概率本身,这样子本来比较高概率的action的grad就会变小

注意R(T)如果都是正值应该不会有问题,也就意味着每个action都会被激励,只是激励有大有小,但是如果说采样过程中有个action没有采样到,不知道action a的reward是多少,这就会导致action a的概率比较低,所以最好给reward减去一个bias,这个bias是我们自己设计的。这样reward有正有负之后,可以去掉采样不均匀带来的一些影响

所以整个policy based RL的整体流程就是:现有一个初始化参数的actor,然后去sample(其实就是跟环境交互的过程)获取路径、行动、反馈,再拿上面三个去训练model,更新参数,其实log后面那部分和我们正常的深度学习网络一样的,(input就是s,label就是action a)只是前面会乘以整个路径的reward的系数,也就是把reward作用在这个actor上;


如果我们的enviroments和reward是model的话,可以直接训练;但如果不是,不能微分的话,就用policy gradient硬train一发;

这里的critic其实就是价值函数;

如何衡量价值函数好不好?很简单,价值函数的衡量越接近实际的reward越好;

我们需要给每一个action合理的reward;上述的同一个trajectory里面的每个action都是相同reward显然不合理,一个action的reward首先跟以往历史的action的reward无关,其次随时间会递减reward的影响;下图中的advantage function是相对于其他action,在当前actor采用本action的credit;

关于on policy,也就是采样数据=》更新model=>采样数据=》更新model的循环;
因为我们每次要根据trajectory最终的reward去计算每个action的credit,所以要等到一批数据采集完才能更新,当前的数据一旦更新完model就不能在用了,因为它只适用于当前的policy model,更新后policy model就变了;所以这个过程很繁琐耗时间;
off policy的意思就是我们训练的model和我们采集数据的model不是同一个model,我们可以随意选取一个actor去采集数据(大量数据),分布的事情可以靠分布之间的变换解决(关于这个变换后面的视频没有具体看,下次可以补上)

我们观察数据的actor的分布和实际train的actor的分布不能差太多,差太多以下近似公式会不成立

上图最后一项是待优化的函数:顾名思义:当前actor根据s采取的action的概率乘以对应的credit,我们希望其越大越好;
上面说到,我们不希望采样数据的分布和训练的actor分布差别太大,那么就需要用到限制,TRPO是额外加出来的限制,不好训练,用的少,PPO就是把限制加入到优化函数里面去了;然后关于beta的值是个动态调整的值,我们会自己设一个LKL最大最小值,超过最大值,就调小beta,反之亦然;这里要注意的是,KL计算的不是参数之间的距离,而是behaivor之间的距离;通用采样数据的s和a就可以计算;

PPO

PPO2的加了个clip来做,意思就是看图:如果A>0是正激励,就希望P越大越好,但是也不要太大,如果A<0是负激励,就希望P越小越好,但是也不要太小;

PPO就是紫色的线,可以看到PPO算法在RL中算是非常稳定和性能好的;

相关文章:
RL--2
强化学习当中最难的两个点是: 1.reward delay; 2.agent的行为会影响到之后看到的东西,所以agent要学会探索世界; 关于强化学习的不同类型,可以分为以下三种: 一种是policy based:可以理解为它是…...

[JVM篇]分代垃圾回收
分代垃圾回收 分代收集法是目前大部分 JVM 所采用的方法,其核心思想是根据对象存活的不同生命周期将内存划分为不同的域,一般情况下将 GC 堆划分为老生代(Tenured/Old Generation)和新生代(Young Generation)。老生代的特点是每次垃圾回收时只有少量对象…...
Dify本地安装
目录 方式一docker安装: 方式二源码安装: Dify本地安装可以用docker方式,和源码编译方式。 先到云厂商平台申请一台Centos系统云主机,网络选择海外,需要公网IP,再按一下流程操作: 方式一doc…...
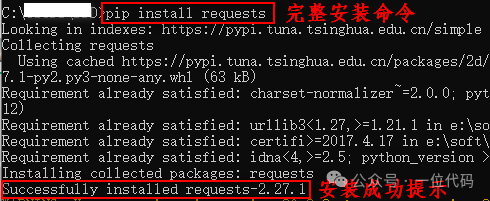
python | 两招解决第三方库安装难点
前言 python 被广泛应用的原因之一,便是拥有大量的第三方库,涵盖 web 开发、数据分析和机器学习等多个方面。 对于多数初学者来说,如何成功安装 python 第三方库成为了一大难点,总是因各种原因导致安装失败。 本文以自身经验&a…...

stm32mp15x 之 M4 使用 canfd
目录 序配置添加注坑参考 序 在使用 stm32mp15x 系列时,M4 有不少的坑,这里简单聊聊使用 canfd 时遇到的一些问题。 配置 这里使用 PLL4R 为 100M,用于 CANFD 的时钟 canfd 速率配置成 1M ,5M,其中数据传输速率为 5M…...

第七天:数据提取-正则表达式
每天上午9点左右更新一到两篇文章到专栏《Python爬虫训练营》中,对于爬虫有兴趣的伙伴可以订阅专栏一起学习,完全免费。 键盘为桨,代码作帆。这趟为期30天左右的Python爬虫特训即将启航,每日解锁新海域:从Requests库的…...
)
Python入门全攻略(六)
文件操作 文件路径 绝对路径:D:\pythonLearing\fileOperating.exe 相对路径:./fileOperating.exe # ./表示当前目录 # ../表示上一级目录 字符编码 字符集编码说明ASCll 最早的字符编码标准之一,基于拉丁字母的字符集,一共有128个字符GBK(国际码)用于简体中文的字符编码,…...

MongoDB副本集
副本集架构 对于mongodb来说,数据库高可用是通过副本集架构实现的,一个副本集由一个主节点和若干个从节点所组成。 客户端通过数据库主节点写入数据后,由从节点进行复制同步,这样所有从节点都会拥有这些业务数据的副本࿰…...

登录弹窗效果
1,要求 点击登录按钮,弹出登录窗口 提示1:登录窗口 display:none 隐藏状态; 提示2:登录按钮点击后,触发事件,修改 display:block 显示状态 提示3:登录窗口中点击关闭按钮࿰…...
C++上机_日期问题
1.求下一天的年月日 问题 已知某天的年月日,求下一天的年月日。 思路 参数:年,月,日(int) 返回值:void 处理:根据参数所给年月日,求下一天的年月日 思路: 1、定义一个数组&a…...

应对DeepSeek总是服务器繁忙的解决方法
最近由于访问量过大,DeepSeek服务器官网经常弹出:“服务器繁忙,请稍后再试”的提示,直接卡成PPT怎么办?服务器繁忙直接看到视觉疲劳: 解决DeepSeek卡顿问题 DeepSeek使用卡顿问题,是因为访问量…...

web第三次作业
弹窗案例 1.首页代码 <!DOCTYPE html><html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>综合案例</title><st…...

力扣 438.找到字符串中所有字母异位词
题目: 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 示例 1: 输入: s "cbaebabacd", p "abc" 输出: [0,6] 解释: 起始索引等于 0 的子串是 "cb…...
【Python】Python入门——基础语法及顺序语句
Python入门——基础语法及顺序语句 官方文档地址:https://docs.python.org/zh-cn/3/tutorial/index.htmlPython 是一门易于学习、功能强大的编程语言。它提供了高效的高级数据结构,还能简单有效地面向对象编程。Python 优雅的语法和动态类型以及解释型语…...

2.2 反向传播:神经网络如何“学习“?
一、神经网络就像小学生 想象一个刚学算术的小学生,老师每天布置练习题,学生根据例题尝试解题,老师批改后指出错误。神经网络的学习过程与此相似: 输入层:相当于练习题(如数字图片)输出层&…...

frp-tool,客户端frp命令行工具
在日常开发和运维过程中,端口转发和配置管理是常见的需求。 如果有自己一台服务器,并且已经开放好端口,配置好token后,这个工具一定能帮到你。 今天给大家推荐一款非常好用的frpc命令行工具,它是一个用Python编写的命令…...

【学术投稿-第五届应用数学、建模与智能计算国际学术会议】CSS伪类选择器深度解析:分类、应用与技巧
大会官网:www.cammic.org 大会时间:2025年3月21-23日 大会地点:中国-上海(上海大学宝山校区北大门乐乎新楼) 简介 第五届应用数学、建模与智能计算(CAMMIC 2025)将于2025年3月21-23日在中国…...
)
常用查找算法整理(顺序查找、二分查找、哈希查找、二叉排序树查找、平衡二叉树查找、红黑树查找、B树和B+树查找、分块查找)
常用的查找算法: 顺序查找:最简单的查找算法,适用于无序或数据量小的情况,逐个元素比较查找目标值。二分查找:要求数据有序,通过不断比较中间元素与目标值,将查找范围缩小一半,效率…...

Express 中 res 响应方法详解
一、res.send() 1. 功能 该方法用于发送各种类型的响应,包括字符串、对象、数组、Buffer 等。它会自动设置响应的 Content-Type 头。 2. 示例代码 const express require("express");const app express();app.get("/", (req, res) > {…...

DeepAR:一种用于时间序列预测的深度学习模型
介绍 DeepAR是一种基于递归神经网络(RNN)的时间序列预测模型,由亚马逊在2017年提出。它特别适用于处理多变量时间序列数据,并能够生成概率预测。DeepAR通过联合训练多个相关时间序列来提高预测性能,从而在实际应用中表…...

AELF区块链节点运维实战:从部署到验证者的完整技能树解析
1. 项目概述与核心价值最近在梳理一些主流公链的节点部署与运维技能时,发现了一个非常有意思的仓库:AElfProject/aelf-node-skill。这并非一个可以直接运行的软件包,而是一个专门针对aelf区块链节点运维的“技能树”或“知识库”。对于任何想…...

中科院深圳先进技术研究院等机构揭示网站生成智能体的致命盲区
这项由中国科学院深圳先进技术研究院、中国科学院大学、大连理工大学以及澳大利亚新南威尔士大学共同完成的研究,以预印本形式发布于2026年4月30日,论文编号为arXiv:2604.27419v1,分类于计算机人工智能领域。感兴趣的读者可通过该编号在arXiv…...
)
手把手教你用PCAN-USB Pro FD和PCAN-View监控CAN FD总线(附总线负载测试技巧)
深度解析PCAN-USB Pro FD与PCAN-View在CAN FD总线诊断中的实战应用 在汽车电子和嵌入式系统开发领域,CAN FD总线技术的普及为工程师带来了更高的数据传输效率和更复杂的调试挑战。当面对一个陌生的CAN FD网络时,如何快速掌握其通信状态、定位异常节点并评…...

NanoPi R6C评测:RK3588S迷你主机的性能与散热优化
1. NanoPi R6C硬件解析:一款重新定义紧凑型ARM主机的设计革新初次拿到NanoPi R6C时,其全金属外壳带来的质感远超我的预期。这款由FriendlyElec推出的迷你主机,搭载了Rockchip RK3588S SoC,尺寸仅比普通路由器稍大,却完…...

云原生不是选修课:AISMM模型预警——当前未启动L1评估的企业,2025Q2起将丧失等保三级合规资格
更多请点击: https://intelliparadigm.com 第一章:云原生不是选修课:AISMM模型预警——当前未启动L1评估的企业,2025Q2起将丧失等保三级合规资格 云原生已从技术趋势升级为合规刚性门槛。根据国家信息安全等级保护2.0制度与最新发…...

FastAPI CORS 跨域
FastAPI CORS 跨域学习笔记 一、什么是跨域问题 1. 同源策略 浏览器遵循同源策略(Same-Origin Policy),限制一个源的网页向另一个源发送请求。 同源 协议 域名 端口 三者一致:URL AURL B是否同源原因http://example.com/ahttp:…...

WarcraftHelper:魔兽争霸3终极兼容性修复指南,让经典游戏在现代电脑流畅运行
WarcraftHelper:魔兽争霸3终极兼容性修复指南,让经典游戏在现代电脑流畅运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还…...

5步掌握TIDAL无损音乐下载:tidal-dl-ng专业工具终极指南
5步掌握TIDAL无损音乐下载:tidal-dl-ng专业工具终极指南 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 想要在TIDAL平台上获取…...

Dbeaver SQL美化器使用指南
DBeaver 自带强大的 SQL 美化(格式化)功能,一键排版、可深度自定义,也能集成外部美化工具。一、快速使用(一键美化)快捷键(最常用)Windows/Linux:CtrlShiftFmacOS&#x…...

AISMM模型落地难题:3步构建动态竞争分析体系,90%企业已错过最佳窗口期
更多请点击: https://intelliparadigm.com 第一章:AISMM模型与竞争分析 AISMM(Artificial Intelligence Strategic Maturity Model)是一种面向企业级AI能力演进的五阶段评估框架,涵盖意识(Awareness&#…...