LC-随机链表的复制、排序链表、合并K个升序链表、LRU缓存
随机链表的复制
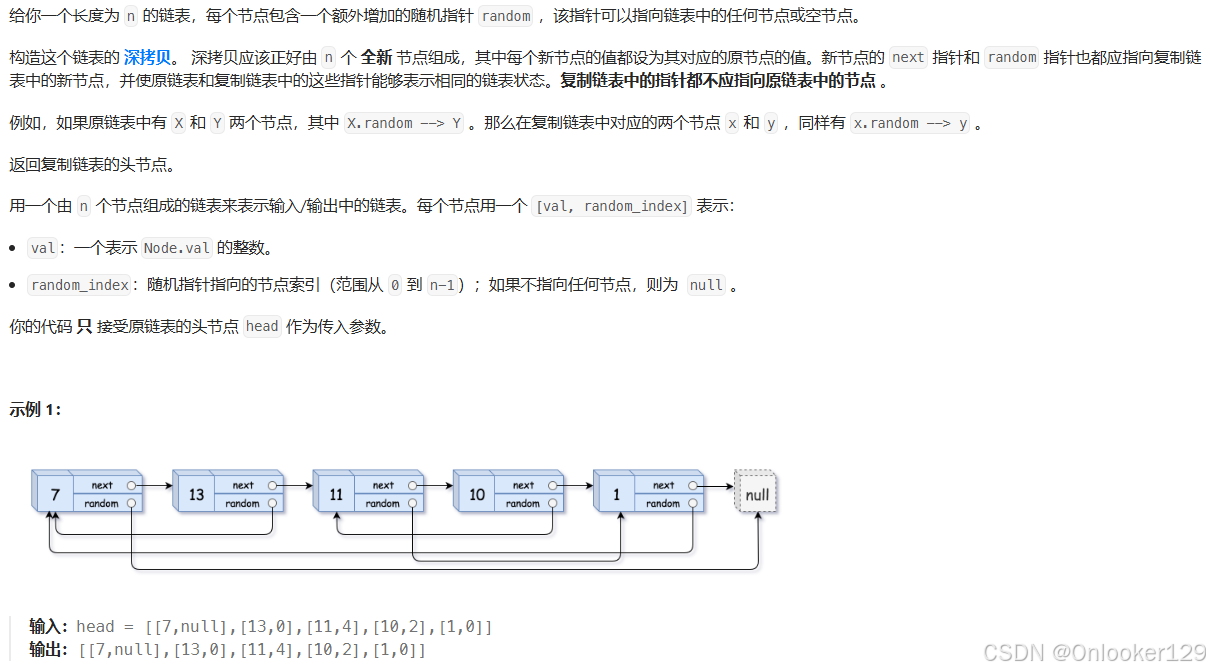
为了在 O(n) 时间复杂度内解决这个问题,并且使用 O(1) 的额外空间,可以利用以下技巧:
- 将新节点插入到原节点后面:我们可以将复制节点插入到原节点后面。例如,如果链表是
A -> B -> C,我们将链表改为A -> A' -> B -> B' -> C -> C',其中A'、B'、C'是A、B、C的拷贝节点。 - 复制
random指针:因为复制节点与原节点紧挨在一起,我们可以直接利用原节点的random指针,来为新节点复制random指针。 - 拆分链表:最后,我们将原链表和复制链表拆分成两个独立的链表。
/*
// Definition for a Node.
class Node {int val;Node next;Node random;public Node(int val) {this.val = val;this.next = null;this.random = null;}
}
*/class Solution {public Node copyRandomList(Node head) {if(head == null){return null;}//插入新节点到原节点后面Node cur = head;while(cur != null){Node copy = new Node(cur.val);//创建新节点copy.next = cur.next;//新节点的next指向原节点的nextcur.next = copy;//原节点的next指向新节点cur = copy.next;//移动到原节点的下一个节点}//复制random节点cur = head;while(cur != null){if(cur.random != null){cur.next.random = cur.random.next;//新节点的random指向原节点random对应的新节点}cur = cur.next.next;//跳到下一个原节点}//拆分链表,恢复原链表并生成新链表Node newHead = head.next;Node copyCur = newHead;cur = head;while(cur != null){cur.next = cur.next.next;//恢复原链表if(copyCur.next != null){copyCur.next = copyCur.next.next;//更新新链表的next指针copyCur = copyCur.next;}cur = cur.next;}return newHead;}
}排序链表
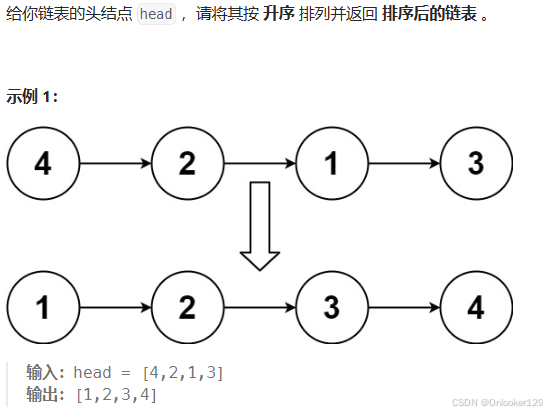
解题思路
- 归并排序:我们可以使用归并排序来对链表进行排序。归并排序的核心思想是将链表递归地分为两半,对两半分别进行排序,然后将排序后的两部分合并。
- 分割链表:我们可以通过快慢指针的方法找到链表的中间节点,从而分割链表。在
findMiddle方法中,slow应该是慢指针,每次移动一步;fast是快指针,每次移动两步。当fast到达链表末尾时,slow应该正好指向中间节点的前一个节点。 - 合并两个有序链表:归并排序的合并操作通常是合并两个有序链表。我们可以直接操作链表的
next指针来合并。
步骤
- 递归分割链表:通过快慢指针找到中间节点,将链表分为两部分。
- 排序子链表:对每个子链表递归调用归并排序。
- 合并两个有序链表:将两个排序后的子链表合并。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode sortList(ListNode head) {// 递归终止条件:如果链表为空或者只有一个节点,直接返回if (head == null || head.next == null) {return head;}// 1. 找到链表的中间节点ListNode mid = findMiddle(head);// 2. 将链表分为两部分ListNode left = head;ListNode right = mid.next;mid.next = null; // 切断链表,确保左右两部分互不影响// 3. 对两部分链表递归排序left = sortList(left);right = sortList(right);// 4. 合并两个有序链表return merge(left, right);}// 找到链表的中间节点(快慢指针)private ListNode findMiddle(ListNode head) {if (head == null || head.next == null) {return head;}ListNode slow = head;ListNode fast = head.next;while (fast != null && fast.next != null) {slow = slow.next;fast = fast.next.next;}return slow;}// 合并两个有序链表private ListNode merge(ListNode l1, ListNode l2) {ListNode dummy = new ListNode(0);ListNode cur = dummy;// 合并两个有序链表while (l1 != null && l2 != null) {if (l1.val < l2.val) {cur.next = l1;l1 = l1.next;} else {cur.next = l2;l2 = l2.next;}cur = cur.next;}// 如果有剩余节点,直接连接if (l1 != null) {cur.next = l1;} else {cur.next = l2;}return dummy.next;}
}
合并K个升序链表

使用优先队列(最小堆)
优先队列可以帮助我们高效地获取当前最小的节点。我们将每个链表的头节点加入到优先队列中,然后依次从队列中取出最小的节点,将其加入到新链表中,接着将其下一个节点加入到队列中,直到所有节点都被处理完。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeKLists(ListNode[] lists) {//定义一个最小堆PriorityQueue<ListNode> pq = new PriorityQueue<>((a,b) -> a.val - b.val);//将所有链表的头节点加入堆中for(ListNode list : lists){if(list != null){pq.offer(list);}}ListNode dummy = new ListNode(0);ListNode current = dummy;//从堆中取出最小节点,并将其后续节点加入堆while(!pq.isEmpty()){ListNode node = pq.poll();current.next = node;current = current.next;if(node.next != null){pq.offer(node.next);//将当前节点的下一个节点加入堆中}}return dummy.next;}
}使用归并思想
归并的思想和合并两个有序链表的方法类似。每次从 k 个链表中合并两个链表,直到最终合并成一个链表。这个方法适用于链表数目较少的情况,因为其时间复杂度为 O(k log k)。
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val = val; }* ListNode(int val, ListNode next) { this.val = val; this.next = next; }* }*/
class Solution {public ListNode mergeKLists(ListNode[] lists) {if (lists == null || lists.length == 0) {return null;}return mergeKListsHelper(lists, 0, lists.length - 1);}// 分治法,合并两个链表private ListNode mergeKListsHelper(ListNode[] lists, int left, int right) {if (left == right) {return lists[left];}int mid = left + (right - left) / 2;ListNode leftMerged = mergeKListsHelper(lists, left, mid);ListNode rightMerged = mergeKListsHelper(lists, mid + 1, right);return mergeTwoLists(leftMerged, rightMerged);}// 合并两个有序链表private ListNode mergeTwoLists(ListNode l1, ListNode l2) {ListNode dummy = new ListNode(0);ListNode current = dummy;while (l1 != null && l2 != null) {if (l1.val < l2.val) {current.next = l1;l1 = l1.next;} else {current.next = l2;l2 = l2.next;}current = current.next;}if (l1 != null) {current.next = l1;} else {current.next = l2;}return dummy.next;}
}
LRU缓存

思路:
- 哈希表(HashMap):用于存储缓存的 key-value 对,通过 key 快速查找对应的值。哈希表中的每个元素将指向双向链表中的一个节点,这样可以在 O(1) 时间内访问链表节点。
- 双向链表(Doubly Linked List):用于表示缓存的使用顺序。最近使用的元素放在链表的头部,最久未使用的元素放在链表的尾部。当缓存达到容量限制时,我们可以从尾部移除最久未使用的元素。
操作:
get(key):- 如果
key存在缓存中,则返回该值,并将该节点移动到双向链表的头部(表示最近使用)。 - 如果
key不存在,返回 -1。
- 如果
put(key, value):- 如果
key已经存在,更新其值,并将该节点移动到链表的头部。 - 如果
key不存在,插入新节点,并将其添加到链表头部。如果缓存已满,移除链表尾部的节点(最久未使用)。
- 如果
设计步骤:
- 构造双向链表:节点存储
key和value,同时拥有指向前一个节点和后一个节点的指针。 - 哈希表存储:将
key和对应的链表节点关联起来,以便快速查找。 - 维护链表的顺序:每次访问节点时,将其移动到链表头部。
class LRUCache {class Node{int key,value;Node prev,next;public Node(int key,int value){this.key = key;this.value = value;}}public Map<Integer,Node> cache;private int capacity;private Node head,tail;public LRUCache(int capacity) {this.capacity = capacity;this.cache = new HashMap<>();head = new Node(0,0);tail = new Node(0,0);head.next = tail;tail.prev = head;}//从链表中移除节点private void remove(Node node){node.prev.next = node.next;node.next.prev = node.prev;}//将节点插入到头部private void insertToHead(Node node){node.next = head.next;node.prev = head;head.next.prev = node;head.next = node;}//获取缓存中的值public int get(int key) {if(cache.containsKey(key)){Node node = cache.get(key);remove(node);//移除节点insertToHead(node);//将节点移到头部return node.value;}return -1;}//插入或更新节点public void put(int key, int value) {if(cache.containsKey(key)){//更新节点的值Node node = cache.get(key);node.value = value;remove(node);insertToHead(node);}else{if(cache.size() >= capacity){//缓存已满,删除尾部节点Node tailNode = tail.prev;remove(tailNode);cache.remove(tailNode.key);}//插入新节点Node newNode = new Node(key,value);cache.put(key,newNode);insertToHead(newNode);//插入到头部}}}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/相关文章:
LC-随机链表的复制、排序链表、合并K个升序链表、LRU缓存
随机链表的复制 为了在 O(n) 时间复杂度内解决这个问题,并且使用 O(1) 的额外空间,可以利用以下技巧: 将新节点插入到原节点后面:我们可以将复制节点插入到原节点后面。例如,如果链表是 A -> B -> C,…...

静态页面在安卓端可以正常显示,但是在ios打开这个页面就需要刷新才能显示全图片
这个问题可能有几个原因导致,我来分析一下并给出解决方案: 首要问题是懒加载实现方式的兼容性问题。当前的懒加载实现可能在 iOS 上不够稳定。建议修改图片懒加载的实现方式: // 使用 Intersection Observer API 实现懒加载 function initLazyLoading() {const imageObserver…...
【ESP32指向鼠标】)
四元数如何用于 3D 旋转(代替欧拉角和旋转矩阵)【ESP32指向鼠标】
四元数如何用于 3D 旋转(代替欧拉角和旋转矩阵) 在三维空间中,物体的旋转可以用 欧拉角、旋转矩阵 或 四元数 来表示。 四元数相比于欧拉角和旋转矩阵有 计算更高效、避免万向锁、存储占用少 等优点,因此广泛用于 游戏开发、机器…...

JavaScript 内置对象-日期对象
在JavaScript中,处理日期和时间是一个常见的需求。无论是显示当前时间、计算两个日期之间的差异,还是格式化日期字符串,Date 对象都能提供强大的支持。本文将详细介绍 Date 对象的使用方法,包括创建日期实例、获取和设置日期值、以…...

本地大模型编程实战(19)RAG(Retrieval Augmented Generation,检索增强生成)(3)
文章目录 准备创建矢量数据库对象创建 LangGraph 链将检索步骤转化为工具定义节点构建图 见证效果qwen2.5llama3.1MFDoom/deepseek-r1-tool-calling:7b 总结代码参考 上一篇文章我们演练了一个 用 langgraph 实现的 RAG(Retrieval Augmented Generation,检索增强生成) 系统。本…...

DeepSeek与ChatGPT:AI语言模型的全面对决
DeepSeek与ChatGPT:AI语言模型的全面对决 引言:AI 语言模型的时代浪潮一、认识 DeepSeek 与 ChatGPT(一)DeepSeek:国产新星的崛起(二)ChatGPT:AI 界的开拓者 二、DeepSeek 与 ChatGP…...

2024年年终总结
2024年终于过去了,这绝对是我人生中最惨痛的一年!被小人欺骗、被庸人耽误、被自己蠢到!不由的让我想起了22年那次算命,算命先生说我十年低谷期,如果从15年进创业公司开始,24年是最后一年,果然应…...

利用 Valgrind 检测 C++ 内存泄露
Valgrind 是一款运行在 Linux 系统上的编程工具集,主要用于调试和分析程序的性能、内存使用等问题。其中最常用的工具是 Memcheck,它可以帮助检测 C 和 C 程序中的内存管理错误,如内存泄漏、使用未初始化的内存、越界访问等。 安装 这里我以…...

Python中的HTTP客户端库:httpx与request | python小知识
Python中的HTTP客户端库:httpx与request | python小知识 在Python中,发送HTTP请求和处理响应是网络编程的基础。requests和httpx是两个常用的HTTP库,它们都提供了简洁易用的API来发送HTTP请求。然而,httpx作为新一代的HTTP客户端…...
【Python】Python入门基础——环境搭建
学习Python,首先需要搭建一个本地开发环境,或是使用线上开发环境(各类练习网站),这里主要记录本地开发环境的配置。 目录: 一、下载和安装python解释器 官网下载地址:Download Python | Pytho…...

2025 pwn_A_childs_dream
文章目录 fc/sfc mesen下载和使用推荐 fc/sfc https://www.mesen.ca/docs/ mesen2安装,vscode安装zg 任天堂yyds w d 左右移动 u结束游戏 i崩溃或者卡死了 L暂停 D658地方有个flag 发现DEEE会使用他。且只有这个地方,maybe会输出flag,应…...

面试题整理:操作系统
文章目录 操作系统操作系统基础1. 操作系统的功能?2. 什么是用户态和内核态? 进程和线程1. 是什么?区别?2. ⭐线程间的同步的方式有哪些?3. PCB 是什么?包含哪些信息?4. 进程的状态有哪些&#…...

构建未来教育的基石:智慧校园与信息的重要性
随着科技的迅猛发展,教育领域正经历一场深刻的变革。在这个过程中,“智慧校园”作为教育信息化的重要实践,扮演着不可或缺的角色。智慧校园不仅仅是硬件设施的升级,更是一种全新的教育理念,强调利用信息技术优化教育资…...

C# 控制台相关 API 与随机数API
C# 控制台相关 API 与随机数API 控制台输入输出 功能说明 Console.WriteLine(string): 输出字符串并换行Console.Write(string, string): 输出字符串不换行Console.ReadLine(): 等待用户输入并返回字符串Console.ReadKey(bool).KeyChar: 读取按键,指定是否显示输…...

【踩坑】⭐️MyBatis的Mapper接口中不建议使用重载方法
目录 🍸前言 🍻一、背景 🍹二、问题处理 💞️三、处理方法 🍸前言 小伙伴们大家好,很久没有水..不是,写文章了,都收到系统的消息了;我算下时间,上周是单休…...

CSS Grid 网格布局,以及 Flexbox 弹性盒布局模型,它们的适用场景是什么?
CSS Grid网格布局和Flexbox弹性盒布局模型都是现代CSS布局的重要工具,它们各自具有独特的优势和适用场景。 作为前端开发工程师,理解这些布局模型的差异和适用场景对于编写高效、可维护的代码至关重要。 CSS Grid网格布局 适用场景: 复杂…...

HDFS体系结构
HDFS 支持主从结 构 , 主节 点 称为 NameNode ,从节点称为 DataNode HDFS中还包含一个 SecondaryNameNode 进程,只要辅助主节点 公司BOSS:NameNode (NN) 秘书:SecondaryNameNode (2NN) 员工&a…...

AI大模型的技术突破与传媒行业变革
性能与成本:AI大模型的“双轮驱动” 过去几年,AI大模型的发展经历了从实验室到产业化的关键转折。2025年初,以DeepSeek R1为代表的模型在数学推理、代码生成等任务中表现超越国际头部产品,而训练成本仅为传统模型的几十分之一。这…...

vscode/cursor+godot C#中使用socketIO
在 Visual Studio Code(VS Code)中安装 NuGet 包(例如SocketIOClient),你可以通过以下几种方法: 方法 1:使用dotnet cli 打开终端:在 VS Code 中按下Ctrl 或者通过菜单View -> Terminal打开终端。 导…...

分段线性插值
分段线性插值 分段线性插值,就是将插值点用折线段连接起来逼近f(x)。设已知节点 a x 0 < x 1 < ⋅ ⋅ ⋅ < x n b ax_0<x_1<<x_nb ax0<x1<⋅⋅⋅<xnb上的函数值 f 0 , f 1 , . . . , f n f_0,f_1,...,f_n f0,f1,...,fn&a…...

agentsrc-py:为AI编程助手注入精准源代码上下文,消除代码幻觉
1. 项目概述:为AI编程助手注入“源代码级”的上下文如果你和我一样,深度依赖像 Cursor、Claude Code 这类 AI 编程助手来提升开发效率,那你一定也踩过同样的坑:当你让助手帮你写一个基于 Pydantic 的数据验证,或者调用…...

Gemini 3 Pro 给了10Mtoken context,60% 这个数字让我换回了记忆方案
我前阵子做一个法律咨询助手 demo,把客户和律师的 30 万字会话历史一次性塞进 Gemini 3 Pro 的 context 窗口。Gemini 3 Pro 的 10M token 窗口听起来像是"agent memory 已经被 context 长度解决了"——直到我跑了第一组真实问题。 客户问"我们上次…...

基于OpenAssistantGPT SDK快速构建智能对话机器人:架构、工具与实战
1. 项目概述:一个能让你快速“组装”智能对话机器人的SDK如果你正在开发一个需要集成对话AI功能的应用,比如一个客服系统、一个智能助手,或者一个带有聊天界面的工具,那么你大概率会遇到一个共同的烦恼:从零开始对接大…...

Emby自定义CSS和JS插件:3步打造个性化媒体服务器界面
Emby自定义CSS和JS插件:3步打造个性化媒体服务器界面 【免费下载链接】Emby.CustomCssJS Easy to manage your Custom JavaScript and Css to modify Emby 项目地址: https://gitcode.com/gh_mirrors/em/Emby.CustomCssJS Emby.CustomCssJS是一款专为Emby媒体…...

D2RML终极指南:暗黑破坏神2重制版多开神器,告别繁琐登录!
D2RML终极指南:暗黑破坏神2重制版多开神器,告别繁琐登录! 【免费下载链接】D2RML Diablo 2 Resurrected Multilauncher 项目地址: https://gitcode.com/gh_mirrors/d2/D2RML 还在为《暗黑破坏神2:重制版》多账户切换而烦恼…...

如何在Unity中轻松处理点云数据:Pcx插件完整教程指南
如何在Unity中轻松处理点云数据:Pcx插件完整教程指南 【免费下载链接】Pcx Point cloud importer & renderer for Unity 项目地址: https://gitcode.com/gh_mirrors/pc/Pcx 想要在Unity中处理海量的点云数据却不知从何下手?🤔 今天…...

从装备混乱到极致有序:TQVaultAE如何彻底改变你的泰坦之旅体验
从装备混乱到极致有序:TQVaultAE如何彻底改变你的泰坦之旅体验 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在《泰坦之旅》中面对满屏的传奇装备不知…...

Maestro:基于声明式YAML的轻量级流程编排工具实践指南
1. 项目概述:一个面向开发者的流程编排利器 最近在梳理团队内部一些重复性的开发运维流程时,我一直在寻找一个能让我“偷懒”的工具。这些流程往往涉及多个步骤:比如代码提交后,自动触发代码质量扫描、依赖安全检查、构建Docker镜…...

STM32F103看门狗实战:用LED灯验证IWDG与WWDG,实测精度差异与避坑指南
STM32F103看门狗实战:用LED灯验证IWDG与WWDG,实测精度差异与避坑指南 在嵌入式系统开发中,系统稳定性是至关重要的考量因素。想象一下,你精心设计的设备在野外运行数月后突然死机,而现场维护成本高昂——这种场景下&am…...

终极README文档生成器:5分钟创建专业开源项目文档
终极README文档生成器:5分钟创建专业开源项目文档 【免费下载链接】readme-md-generator 📄 CLI that generates beautiful README.md files 项目地址: https://gitcode.com/gh_mirrors/re/readme-md-generator readme-md-generator是一款强大的命…...