DeepSeek-R1 大模型本地部署指南

文章目录
- 一、系统要求
- 硬件要求
- 软件环境
- 二、部署流程
- 1. 环境准备
- 2. 模型获取
- 3. 推理代码配置
- 4. 启动推理服务
- 三、优化方案
- 1. 显存优化技术
- 2. 性能加速方案
- 四、部署验证
- 健康检查脚本
- 预期输出特征
- 五、常见问题解决
- 1. CUDA内存不足
- 2. 分词器警告处理
- 3. 多GPU部署
- 六、安全合规建议
一、系统要求
硬件要求
部署前需确保硬件满足最低要求:NVIDIA显卡(RTX 3090及以上)、24GB显存、64GB内存及500GB固态存储。
| 资源类型 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 1080Ti | RTX 3090/A100(40GB+) |
| VRAM | 12GB | 24GB+ |
| 内存 | 32GB DDR4 | 64GB DDR4 |
| 存储 | 100GB SSD | 500GB NVMe SSD |
软件环境
软件环境需安装Ubuntu 22.04系统、CUDA 11.7+驱动、Python 3.9及PyTorch 2.1框架,建议使用conda创建独立虚拟环境,安装transformers、accelerate等核心依赖库,并配置Flash Attention等加速组件。
- CUDA 11.7+
- cuDNN 8.5+
- Python 3.8-3.10
- PyTorch 2.0+
二、部署流程
1. 环境准备
# 创建虚拟环境
conda create -n deepseek-r1 python=3.9 -y
conda activate deepseek-r1# 安装基础依赖
pip install torch==2.1.2+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
pip install transformers==4.35.0 accelerate sentencepiece
2. 模型获取
通过官方授权获取模型访问权限后,使用Git LFS克隆HuggingFace仓库下载模型文件(约70GB)。下载完成后需进行SHA256哈希校验,确保模型完整性。模型目录应包含pytorch_model.bin主权重文件、tokenizer分词器及配置文件,部署前需确认文件结构完整。
通过官方渠道获取模型权重(需申请权限):
git lfs install
git clone https://huggingface.co/deepseek-ai/deepseek-r1-7b-base
3. 推理代码配置
编写基础推理脚本,使用AutoModelForCausalLM加载模型至GPU,通过tokenizer处理输入文本。生产环境建议集成FastAPI搭建RESTful服务,配置Gunicorn多进程管理,启用HTTPS加密通信。启动时需设置温度参数(temperature)、重复惩罚系数(repetition_penalty)等生成策略,平衡输出质量与多样性。
创建inference.py:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchmodel_path = "./deepseek-r1-7b-base"
device = "cuda" if torch.cuda.is_available() else "cpu"# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16,device_map="auto"
)# 推理示例
prompt = "北京的著名景点有哪些?"
inputs = tokenizer(prompt, return_tensors="pt").to(device)outputs = model.generate(**inputs,max_new_tokens=500,temperature=0.7,do_sample=True
)print(tokenizer.decode(outputs[0], skip_special_tokens=True))
4. 启动推理服务
# 基础启动
python inference.py# 启用量化(节省显存)
python inference.py --load_in_4bit# API服务模式(需安装fastapi)
uvicorn api:app --port 8000
三、优化方案
1. 显存优化技术
| 技术 | 命令参数 | VRAM节省量 |
|---|---|---|
| 4-bit量化 | --load_in_4bit | 60% |
| 8-bit量化 | --load_in_8bit | 40% |
| 梯度检查点 | --use_gradient_checkpointing | 25% |
2. 性能加速方案
针对显存限制可采用4/8-bit量化技术,降低50%-75%显存占用。启用Flash Attention 2加速注意力计算,提升30%推理速度。多GPU环境使用Deepspeed进行分布式推理,通过TensorRT转换模型提升计算效率。同时配置显存分块加载机制,支持大文本生成场景。
# 使用Flash Attention 2
pip install flash-attn --no-build-isolation
model = AutoModelForCausalLM.from_pretrained(..., use_flash_attention_2=True)# 启用TensorRT加速
pip install transformers[torch-tensorrt]
model = torch_tensorrt.compile(model, inputs=...)
四、部署验证
健康检查脚本
import requestsAPI_ENDPOINT = "http://localhost:8000/generate"def health_check():test_payload = {"prompt": "你好","max_tokens": 50}response = requests.post(API_ENDPOINT, json=test_payload)return response.json()print("Service status:", health_check()["status"])
预期输出特征
- 响应时间:<5秒(首次加载除外)
- Token生成速度:>20 tokens/sec(3090)
- 显存占用波动范围:±5%
五、常见问题解决
1. CUDA内存不足
# 解决方案:启用分块加载
model = AutoModelForCausalLM.from_pretrained(...,device_map="auto",offload_folder="offload",offload_state_dict=True
)
2. 分词器警告处理
tokenizer = AutoTokenizer.from_pretrained(model_path,trust_remote_code=True,use_fast=False
)
3. 多GPU部署
# 指定GPU设备
CUDA_VISIBLE_DEVICES=0,1 python inference.py --tensor_parallel_size=2
六、安全合规建议
- 网络隔离:建议在内网环境部署
- 访问控制:配置API密钥认证
- 日志审计:记录所有推理请求
- 内容过滤:集成敏感词过滤模块
注意事项:
- 模型权重需从官方授权渠道获取
- 首次运行会自动下载分词器文件(约500MB)
- 建议使用NVIDIA驱动版本525.85+
- 完整部署流程耗时约30-60分钟(依赖网络速度)
相关文章:
DeepSeek-R1 大模型本地部署指南
文章目录 一、系统要求硬件要求软件环境 二、部署流程1. 环境准备2. 模型获取3. 推理代码配置4. 启动推理服务 三、优化方案1. 显存优化技术2. 性能加速方案 四、部署验证健康检查脚本预期输出特征 五、常见问题解决1. CUDA内存不足2. 分词器警告处理3. 多GPU部署 六、安全合规…...

在conda环境下,安装Pytorch和CUDA
系统 : Ubuntu20.04 显卡:NVIDIA GTX1650 显卡驱动已经装好(命令 nvidia-smi 查看显卡配置) (主要看一下第一行的参数,最大支持的CUDA版本为12.4 ) Aanconda 版本(安装指南)(似乎…...

Java里int和Integer的区别?
大家好,我是锋哥。今天分享关于【Java里int和Integer的区别?】面试题。希望对大家有帮助; Java里int和Integer的区别? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Java 中,int 和 Integer 都是用来表…...

【第13章:自监督学习与少样本学习—13.4 自监督学习与少样本学习的未来研究方向与挑战】
凌晨三点的实验室里,博士生小张盯着屏幕上的训练曲线——他设计的跨模态少样本学习模型在医疗影像诊断任务上突然出现了诡异的性能断崖。前一秒还在92%的准确率高位运行,下一秒就暴跌到47%。这个看似灾难性的现象,却意外揭开了自监督学习与少样本学习技术深藏的核心挑战… 一…...

【NLP】文本预处理
目录 一、文本处理的基本方法 1.1 分词 1.2 命名体实体识别 1.3 词性标注 二、文本张量的表示形式 2.1 one-hot编码 2.2 word2vec 模型 2.2.1 CBOW模式 2.2.2 skipgram模式 2.3 词嵌入word embedding 三、文本数据分析 3.1 标签数量分布 3.2 句子长度分布 3.3 词…...
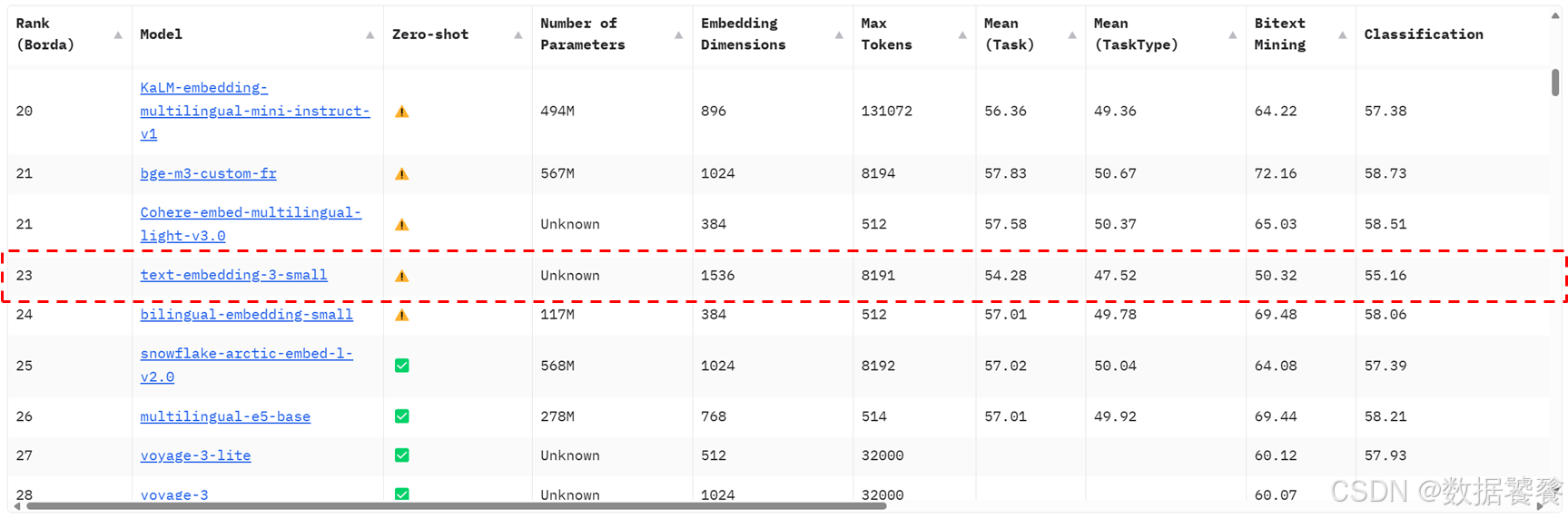
deepseek r1从零搭建本地知识库10:嵌入模型和知识库建设
一、嵌入模型(Embedding Model)是什么? 1. 定义 嵌入模型是一种将文本、图像、音频等非结构化数据转化为**低维稠密向量(Dense Vector)**的算法模型,这些向量(通常几百到几千维)能够…...

Linux-文件IO
1.open函数 【1】基本概念和使用 #include <fcntl.h> int open(const char *pathname,int flags); int open(const char *pathname,int flags,mode_t mode); 功能: 打开或创建文件 参数: pathname //打开的文件名 f…...

3d pose 学习笔记2025
目录 champ nlf 3dpose 2025 55个关键点 推理代码: 要设置环境变量: 依赖项metrabs 渲染代码: tram4d 脚也不是特别好 GVHMR脚对不齐 推理代码: multiperson 2023年 genhmr还没开源: champ https://zhuanlan.zhihu.com/p/700326554 nlf 3dpose 2025 55个关键点…...

LC-随机链表的复制、排序链表、合并K个升序链表、LRU缓存
随机链表的复制 为了在 O(n) 时间复杂度内解决这个问题,并且使用 O(1) 的额外空间,可以利用以下技巧: 将新节点插入到原节点后面:我们可以将复制节点插入到原节点后面。例如,如果链表是 A -> B -> C,…...

静态页面在安卓端可以正常显示,但是在ios打开这个页面就需要刷新才能显示全图片
这个问题可能有几个原因导致,我来分析一下并给出解决方案: 首要问题是懒加载实现方式的兼容性问题。当前的懒加载实现可能在 iOS 上不够稳定。建议修改图片懒加载的实现方式: // 使用 Intersection Observer API 实现懒加载 function initLazyLoading() {const imageObserver…...
【ESP32指向鼠标】)
四元数如何用于 3D 旋转(代替欧拉角和旋转矩阵)【ESP32指向鼠标】
四元数如何用于 3D 旋转(代替欧拉角和旋转矩阵) 在三维空间中,物体的旋转可以用 欧拉角、旋转矩阵 或 四元数 来表示。 四元数相比于欧拉角和旋转矩阵有 计算更高效、避免万向锁、存储占用少 等优点,因此广泛用于 游戏开发、机器…...

JavaScript 内置对象-日期对象
在JavaScript中,处理日期和时间是一个常见的需求。无论是显示当前时间、计算两个日期之间的差异,还是格式化日期字符串,Date 对象都能提供强大的支持。本文将详细介绍 Date 对象的使用方法,包括创建日期实例、获取和设置日期值、以…...

本地大模型编程实战(19)RAG(Retrieval Augmented Generation,检索增强生成)(3)
文章目录 准备创建矢量数据库对象创建 LangGraph 链将检索步骤转化为工具定义节点构建图 见证效果qwen2.5llama3.1MFDoom/deepseek-r1-tool-calling:7b 总结代码参考 上一篇文章我们演练了一个 用 langgraph 实现的 RAG(Retrieval Augmented Generation,检索增强生成) 系统。本…...

DeepSeek与ChatGPT:AI语言模型的全面对决
DeepSeek与ChatGPT:AI语言模型的全面对决 引言:AI 语言模型的时代浪潮一、认识 DeepSeek 与 ChatGPT(一)DeepSeek:国产新星的崛起(二)ChatGPT:AI 界的开拓者 二、DeepSeek 与 ChatGP…...

2024年年终总结
2024年终于过去了,这绝对是我人生中最惨痛的一年!被小人欺骗、被庸人耽误、被自己蠢到!不由的让我想起了22年那次算命,算命先生说我十年低谷期,如果从15年进创业公司开始,24年是最后一年,果然应…...

利用 Valgrind 检测 C++ 内存泄露
Valgrind 是一款运行在 Linux 系统上的编程工具集,主要用于调试和分析程序的性能、内存使用等问题。其中最常用的工具是 Memcheck,它可以帮助检测 C 和 C 程序中的内存管理错误,如内存泄漏、使用未初始化的内存、越界访问等。 安装 这里我以…...

Python中的HTTP客户端库:httpx与request | python小知识
Python中的HTTP客户端库:httpx与request | python小知识 在Python中,发送HTTP请求和处理响应是网络编程的基础。requests和httpx是两个常用的HTTP库,它们都提供了简洁易用的API来发送HTTP请求。然而,httpx作为新一代的HTTP客户端…...
【Python】Python入门基础——环境搭建
学习Python,首先需要搭建一个本地开发环境,或是使用线上开发环境(各类练习网站),这里主要记录本地开发环境的配置。 目录: 一、下载和安装python解释器 官网下载地址:Download Python | Pytho…...

2025 pwn_A_childs_dream
文章目录 fc/sfc mesen下载和使用推荐 fc/sfc https://www.mesen.ca/docs/ mesen2安装,vscode安装zg 任天堂yyds w d 左右移动 u结束游戏 i崩溃或者卡死了 L暂停 D658地方有个flag 发现DEEE会使用他。且只有这个地方,maybe会输出flag,应…...

面试题整理:操作系统
文章目录 操作系统操作系统基础1. 操作系统的功能?2. 什么是用户态和内核态? 进程和线程1. 是什么?区别?2. ⭐线程间的同步的方式有哪些?3. PCB 是什么?包含哪些信息?4. 进程的状态有哪些&#…...

Yua Memory System:为AI伙伴构建有情感感知的记忆系统
1. 项目概述:为AI伙伴构建有“心跳”的记忆系统如果你正在开发一个AI伙伴,无论是聊天机器人、数字助手还是更复杂的虚拟角色,你肯定遇到过这个核心难题:如何让它记住你?不是那种机械地调取数据库的“记住”,…...

Go语言技能树构建:从并发编程到工程化实战的进阶指南
1. 项目概述:一个Go语言技能树的构建与评估框架最近在梳理团队内部的Go语言技术栈时,发现一个挺普遍的问题:大家对于“掌握Go语言”这个目标的理解差异很大。初级工程师可能觉得会用goroutine和channel就算入门了,而资深工程师则会…...

小米手表表盘制作神器:3步搞定个性化设计,无需任何编程基础
小米手表表盘制作神器:3步搞定个性化设计,无需任何编程基础 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 你是不是也曾为小米手表上单…...

终极Nintendo Switch游戏安装指南:Awoo Installer如何让游戏安装变得简单快速
终极Nintendo Switch游戏安装指南:Awoo Installer如何让游戏安装变得简单快速 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Sw…...

使用Node.js快速为Web应用集成多模型对话能力
使用Node.js快速为Web应用集成多模型对话能力 为Web应用添加智能对话功能,通常需要开发者处理复杂的模型API接入、密钥管理和计费问题。通过Taotoken平台提供的统一OpenAI兼容API,开发者可以简化这一过程,快速集成多种主流大模型,…...

构建工业级AI平台的关键技术和难点
构建工业级 AI 平台,本质上是在解决“AI 算法的随机性”与“工业生产的确定性”之间的矛盾。在「资产数字化 → 互联 → 共享 → 共生」框架下,通过系统工程,搭建一个具备“工业龙虾”特质的 AI 仿真环境。一、 关键技术:构建平台…...

不止是跑脚本:深度拆解Gowin UART参考设计的ModelSim自动化仿真流程
不止是跑脚本:深度拆解Gowin UART参考设计的ModelSim自动化仿真流程 当拿到Gowin官方提供的UART参考设计压缩包时,大多数开发者会直接双击do.bat完成仿真——这确实能快速验证功能,但如果你正在阅读本文,说明你早已不满足于"…...
)
告别CentOS 8!在Hyper-V上无缝迁移到CentOS Stream 9的保姆级指南(附避坑与配置优化)
从CentOS 8到Stream 9的Hyper-V迁移实战手册 当CentOS官方宣布CentOS 8将在2021年底停止维护时,许多依赖该系统的运维团队面临紧迫的迁移需求。作为CentOS的滚动更新版本,CentOS Stream 9不仅提供了持续的安全更新,还与RHEL 9保持高度同步&am…...

避坑指南:ESP32用Modbus读485设备,为什么你的软串口总收不到数据?
ESP32 Modbus通信避坑指南:软串口数据丢失的深层分析与解决方案 当你在ESP32项目中使用Modbus协议通过485接口读取传感器数据时,是否遇到过这样的场景:硬件连接正确,代码看似无误,但软串口(SoftwareSerial)就是收不到任…...

物理世界模型PhyGenesis:自动驾驶仿真的关键技术
1. 项目概述 PhyGenesis是一个基于物理规律的驾驶视频生成世界模型,它能够模拟真实世界中的驾驶场景,生成符合物理规律的连续视频帧。这个项目在自动驾驶仿真、驾驶员行为分析和智能交通系统测试等领域具有重要应用价值。 作为一名在计算机视觉和自动驾…...