机器学习数学基础:29.t检验
t检验学习笔记
一、t检验的定义和用途
t检验是统计学中常用的假设检验方法,主要用于判断样本均值与总体均值间,或两个样本均值间是否存在显著差异。
在实际中应用广泛,例如在医学领域可用于比较两种药物的疗效;在教育领域,能评估不同教学方法对学生成绩的影响等,以此帮助判断实验或调查结果是否具有统计学意义。
二、t检验的基本原理
(一)t分布特性
t检验基于t分布。t分布是一种概率分布,与正态分布类似,但在样本量较小时,其尾部比正态分布更厚。这使得t分布在小样本情形下,能更好地应对样本的不确定性。
(二)t统计量计算
t检验的核心是计算t统计量。不同类型的t检验公式有所不同,但总体思路均是通过比较样本均值与总体均值,或两个样本均值的差异,同时考虑样本标准差和样本量,来衡量该差异是否显著。
以单样本t检验为例,公式为: t = X ˉ − μ S / n t\ =\frac{\bar{X}-\mu}{S/\sqrt{n}} t =S/nXˉ−μ。其中, X ˉ \bar{X} Xˉ是样本均值, μ \mu μ是总体均值, S S S是样本标准差, n n n是样本量。
若计算的t值较大,超出给定显著性水平下的临界值,意味着样本均值与总体均值差异显著,有理由拒绝原假设,认为样本并非来自该总体,或两样本所代表的总体均值存在差异。
三、t检验的分类及应用场景
(一)单样本t检验
- 目的:检验一个样本均值与已知总体均值是否有显著差异。
- 案例:已知某地区成年男性平均身高为175cm,现从该地区随机抽取50名成年男性,测得平均身高为178cm,标准差为10cm。判断这50名男性身高与该地区总体成年男性身高是否有显著差异。
- 计算过程
- 明确已知条件: X ˉ = 178 \bar{X}\ =178 Xˉ =178, μ = 175 \mu \ = 175 μ =175, S = 10 S \ = 10 S =10, n = 50 n \ = 50 n =50。
- 代入公式计算t值: t = 178 − 175 10 / 50 = 3 10 / 7.07 = 3 1.41 ≈ 2.13 t\ =\frac{178 - 175}{10/\sqrt{50}}\ =\frac{3}{10/7.07}\ =\frac{3}{1.41}\approx2.13 t =10/50178−175 =10/7.073 =1.413≈2.13。
- 确定自由度 d f = n − 1 = 50 − 1 = 49 df\ =n - 1\ =50 - 1\ =49 df =n−1 =50−1 =49,选定显著性水平 α = 0.05 \alpha \ = 0.05 α =0.05,查t分布表得临界值。
- 若t值大于临界值,拒绝原假设,认为这50名男性平均身高与总体平均身高有显著差异;若小于临界值,接受原假设,认为无显著差异。
- 计算过程
(二)独立样本t检验
- 目的:比较两个独立样本的均值,判断两个不同组(如实验组和对照组)间是否存在差异。
- 案例:对两种不同品牌电池进行续航测试,品牌A测试30个样本,平均续航10小时,标准差1.5小时;品牌B测试25个样本,平均续航9小时,标准差1.2小时。比较两种品牌电池续航能力是否有显著差异。
- 计算过程
- 构建数据: X ˉ 1 = 10 \bar{X}_{1}\ =10 Xˉ1 =10, S 1 = 1.5 S_{1}\ =1.5 S1 =1.5, n 1 = 30 n_{1}\ =30 n1 =30; X ˉ 2 = 9 \bar{X}_{2}\ =9 Xˉ2 =9, S 2 = 1.2 S_{2}\ =1.2 S2 =1.2, n 2 = 25 n_{2}\ =25 n2 =25。
- 计算合并方差 S p 2 = ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 n 1 + n 2 − 2 = ( 30 − 1 ) × 1. 5 2 + ( 25 − 1 ) × 1. 2 2 30 + 25 − 2 = 29 × 2.25 + 24 × 1.44 53 = 65.25 + 34.56 53 ≈ 1.88 S_{p}^{2}\ =\frac{(n_{1}-1)S_{1}^{2}+(n_{2}-1)S_{2}^{2}}{n_{1}+n_{2}-2}\ =\frac{(30 - 1)\times1.5^{2}+(25 - 1)\times1.2^{2}}{30 + 25 - 2}\ =\frac{29\times2.25+24\times1.44}{53}\ =\frac{65.25+34.56}{53}\approx1.88 Sp2 =n1+n2−2(n1−1)S12+(n2−1)S22 =30+25−2(30−1)×1.52+(25−1)×1.22 =5329×2.25+24×1.44 =5365.25+34.56≈1.88。
- 计算t值: t = X ˉ 1 − X ˉ 2 S p 2 ( 1 n 1 + 1 n 2 ) = 10 − 9 1.88 × ( 1 30 + 1 25 ) = 1 1.88 × ( 5 + 6 150 ) = 1 1.88 × 11 150 ≈ 2.64 t\ =\frac{\bar{X}_{1}-\bar{X}_{2}}{\sqrt{S_{p}^{2}(\frac{1}{n_{1}}+\frac{1}{n_{2}})}}\ =\frac{10 - 9}{\sqrt{1.88\times(\frac{1}{30}+\frac{1}{25})}}\ =\frac{1}{\sqrt{1.88\times(\frac{5 + 6}{150})}}\ =\frac{1}{\sqrt{1.88\times\frac{11}{150}}}\approx2.64 t =Sp2(n11+n21)Xˉ1−Xˉ2 =1.88×(301+251)10−9 =1.88×(1505+6)1 =1.88×150111≈2.64。
- 确定自由度 d f = n 1 + n 2 − 2 = 30 + 25 − 2 = 53 df\ =n_{1}+n_{2}-2\ =30 + 25 - 2\ =53 df =n1+n2−2 =30+25−2 =53,根据显著性水平 α = 0.05 \alpha \ = 0.05 α =0.05查t分布表得临界值,比较t值与临界值判断是否有显著差异。
- 计算过程
(三)配对样本t检验
- 目的:比较配对样本(如同一组对象前后两次测试数据)的均值差异,判断某种处理或时间因素等对结果的影响。
- 案例:对15名学生进行培训前后成绩测试,培训前平均成绩75分,培训后80分,成绩差值标准差为5分。判断培训是否有效提高学生成绩。
- 计算过程
- 已知 d ˉ = 80 − 75 = 5 \bar{d}\ =80 - 75\ =5 dˉ =80−75 =5( d ˉ \bar{d} dˉ为成绩差值均值), S d = 5 S_{d}\ =5 Sd =5, n = 15 n \ = 15 n =15。
- 计算t值: t = d ˉ S d / n = 5 5 / 15 ≈ 3.87 t\ =\frac{\bar{d}}{S_{d}/\sqrt{n}}\ =\frac{5}{5/\sqrt{15}}\approx3.87 t =Sd/ndˉ =5/155≈3.87。
- 自由度 d f = n − 1 = 15 − 1 = 14 df\ =n - 1\ =15 - 1\ =14 df =n−1 =15−1 =14,根据 α = 0.05 \alpha \ = 0.05 α =0.05查t分布表得临界值,比较t值与临界值判断培训是否有效。
- 计算过程
四、t检验的步骤总结
(一)提出原假设( H 0 H_{0} H0)和备择假设( H 1 H_{1} H1)
- 单样本t检验: H 0 H_{0} H0: X ˉ = μ \bar{X}\ =\mu Xˉ =μ; H 1 H_{1} H1: X ˉ ≠ μ \bar{X}\neq\mu Xˉ=μ。
- 独立样本t检验: H 0 H_{0} H0: μ 1 = μ 2 \mu_{1}\ =\mu_{2} μ1 =μ2; H 1 H_{1} H1: μ 1 ≠ μ 2 \mu_{1}\neq\mu_{2} μ1=μ2。
- 配对样本t检验: H 0 H_{0} H0: μ d = 0 \mu_{d}\ =0 μd =0( μ d \mu_{d} μd为配对差值的总体均值); H 1 H_{1} H1: μ d ≠ 0 \mu_{d}\neq0 μd=0。
(二)计算t统计量
依据不同类型t检验的相应公式计算t值。
(三)确定自由度
按照不同类型t检验的自由度计算公式确定,如单样本和配对样本t检验自由度为 n − 1 n - 1 n−1,独立样本t检验自由度为 n 1 + n 2 − 2 n_{1}+n_{2}-2 n1+n2−2。
(四)查找临界值
根据选定的显著性水平和自由度,查阅t分布表找到临界值。
(五)做出决策
比较计算的t值与临界值,t值大于临界值,拒绝原假设;t值小于临界值,接受原假设。
五、注意事项
(一)数据正态性
t检验通常要求数据服从正态分布,小样本时尤其重要。若数据明显不服从正态分布,可能需进行数据转换或采用非参数检验方法。
(二)方差齐性
独立样本t检验中,一般要求两样本方差相等(方差齐性)。可通过方差齐性检验判断,不满足时可能需用校正的t检验方法。
(三)样本独立性
独立样本t检验中,样本应相互独立,无关联或依赖关系;配对样本t检验中,配对的合理性和准确性很关键,要确保配对依据合理有效。
六、原假设与备择假设的设定原则
(一)完备且对立原则
原假设和备择假设构成完备事件组且相互对立,在假设检验中必有且仅有一个成立。例如,判断硬币是否均匀, H 0 H_{0} H0:硬币均匀(正面朝上概率 p = 0.5 p \ = 0.5 p =0.5); H 1 H_{1} H1:硬币不均匀( p ≠ 0.5 p\neq0.5 p=0.5),涵盖所有情况且不能同时成立。
(二)先备择后原假设原则
通常先确定备择假设,因其往往是研究者关心、欲支持或证实的内容,相对更易明确。比如,研究者猜测新药物比传统药物疗效好, H 1 H_{1} H1:新药物疗效优于传统药物; H 0 H_{0} H0:新药物疗效不比传统药物好。
(三)等号原则
等号“ = \ = =”总放在原假设上。原假设一般表示变量间无差异、无影响或参数等于特定值等情况。例如,比较两总体均值, H 0 H_{0} H0: μ 1 = μ 2 \mu_1 \ = \mu_2 μ1 =μ2; H 1 H_{1} H1: μ 1 ≠ μ 2 \mu_1\neq\mu_2 μ1=μ2。
(四)主观性原则
假设确定具主观性,不同研究者因研究目的、背景知识和角度不同,对同一实际问题可能提出相反假设,但都应符合最终目的。比如,研究政策对经济增长影响,关注政策是否有效时, H 0 H_{0} H0:政策对经济增长无影响, H 1 H_{1} H1:政策对经济增长有影响;关注政策是否有负面效果时, H 0 H_{0} H0:政策对经济增长无负面影响, H 1 H_{1} H1:政策对经济增长有负面影响。
(五)目的导向原则
假设检验主要是收集证据拒绝原假设。原假设通常是被怀疑、需样本数据提供证据否定的假设。有足够证据时拒绝原假设,接受备择假设;无充分证据时,不意味着完全接受原假设,只是暂时无理由否定。
七、单尾概率和双尾概率在t检验中的应用
(一)单尾概率在t检验中的应用
案例背景:某公司研发了一种新型减肥药物,为了检验其效果,随机选取了50名肥胖患者作为样本进行临床试验。已知未使用该药物时,肥胖人群的平均体重下降量为0kg(可视为总体均值)。经过一段时间使用后,测得这50名患者的平均体重下降了3kg,标准差为1.5kg。公司想要了解这种新型减肥药物是否能显著降低体重,即只关心体重是否下降,不关心是否会使体重增加,此时采用单尾t检验。
假设设定:
- 原假设 H 0 H_0 H0: μ ≥ 0 \mu \geq 0 μ≥0(药物没有显著降低体重,即总体平均体重下降量大于等于0)
- 备择假设 H 1 H_1 H1: μ < 0 \mu < 0 μ<0(药物显著降低体重,即总体平均体重下降量小于0)
检验过程:
- 计算t统计量:已知 X ˉ = 3 \bar{X} \ = 3 Xˉ =3(样本均值), μ = 0 \mu \ = 0 μ =0(总体均值), S = 1.5 S \ = 1.5 S =1.5(样本标准差), n = 50 n \ = 50 n =50(样本量),根据单样本t检验公式 t = X ˉ − μ S / n t\ =\frac{\bar{X}-\mu}{S/\sqrt{n}} t =S/nXˉ−μ,可得 t = 3 − 0 1.5 / 50 ≈ 14.14 t\ =\frac{3 - 0}{1.5/\sqrt{50}}\approx14.14 t =1.5/503−0≈14.14。
- 确定自由度 d f = n − 1 = 50 − 1 = 49 df \ = n - 1 \ = 50 - 1 \ = 49 df =n−1 =50−1 =49,假设选定显著性水平 α = 0.05 \alpha \ = 0.05 α =0.05,在t分布表中查找单尾概率 P ( 1 ) = 0.05 P(1)\ =0.05 P(1) =0.05对应的临界值(假设为 - 1.677,实际值需根据具体精确的t分布表确定)。
- 由于计算得到的t值 14.14 > − 1.677 14.14> - 1.677 14.14>−1.677,且在单尾检验中,这里是左侧单尾检验,当t值小于临界值时拒绝原假设,而此例中t值远大于临界值,说明样本数据不支持原假设,拒绝 H 0 H_0 H0,接受 H 1 H_1 H1,即认为这种新型减肥药物能显著降低体重。
(二)双尾概率在t检验中的应用
案例背景:研究人员想要比较两种不同品牌的灯泡使用寿命是否存在差异。分别从品牌A和品牌B的灯泡中随机抽取了30个和25个样本进行测试。品牌A灯泡样本的平均使用寿命为1000小时,标准差为50小时;品牌B灯泡样本的平均使用寿命为980小时,标准差为40小时。研究人员不确定哪个品牌的灯泡使用寿命更长或更短,只是关注它们之间是否有显著差异,所以采用双尾t检验。
假设设定:
- 原假设 H 0 H_0 H0: μ 1 = μ 2 \mu_1 \ = \mu_2 μ1 =μ2(两个品牌灯泡的总体平均使用寿命相等)
- 备择假设 H 1 H_1 H1: μ 1 ≠ μ 2 \mu_1 \neq \mu_2 μ1=μ2(两个品牌灯泡的总体平均使用寿命不相等)
检验过程:
- 计算t统计量:先计算合并方差 S p 2 = ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 n 1 + n 2 − 2 = ( 30 − 1 ) × 5 0 2 + ( 25 − 1 ) × 4 0 2 30 + 25 − 2 ≈ 2052.38 S_{p}^{2}\ =\frac{(n_1 - 1)S_1^{2}+(n_2 - 1)S_2^{2}}{n_1 + n_2 - 2}\ =\frac{(30 - 1)\times50^{2}+(25 - 1)\times40^{2}}{30 + 25 - 2}\approx2052.38 Sp2 =n1+n2−2(n1−1)S12+(n2−1)S22 =30+25−2(30−1)×502+(25−1)×402≈2052.38,再根据独立样本t检验公式 t = X ˉ 1 − X ˉ 2 S p 2 ( 1 n 1 + 1 n 2 ) = 1000 − 980 2052.38 × ( 1 30 + 1 25 ) ≈ 1.64 t\ =\frac{\bar{X}_1 - \bar{X}_2}{\sqrt{S_{p}^{2}(\frac{1}{n_1}+\frac{1}{n_2})}}\ =\frac{1000 - 980}{\sqrt{2052.38\times(\frac{1}{30}+\frac{1}{25})}}\approx1.64 t =Sp2(n11+n21)Xˉ1−Xˉ2 =2052.38×(301+251)1000−980≈1.64。
- 确定自由度 d f = n 1 + n 2 − 2 = 30 + 25 − 2 = 53 df \ = n_1 + n_2 - 2 \ = 30 + 25 - 2 \ = 53 df =n1+n2−2 =30+25−2 =53,选定显著性水平 α = 0.05 \alpha \ = 0.05 α =0.05,在t分布表中查找双尾概率 P ( 2 ) = 0.05 P(2)\ =0.05 P(2) =0.05对应的临界值(假设为 ± 2.006 \pm 2.006 ±2.006,实际值需根据具体精确的t分布表确定)。
- 由于计算得到的t值 1.64 1.64 1.64,其绝对值 ∣ 1.64 ∣ < 2.006 |1.64| < 2.006 ∣1.64∣<2.006,说明样本数据支持原假设,不拒绝 H 0 H_0 H0,即目前没有足够证据表明两个品牌灯泡的使用寿命存在显著差异。
综上,单尾概率适用于明确关注差异方向的研究,双尾概率适用于不确定差异方向,仅想知道是否存在差异的研究。
相关文章:

机器学习数学基础:29.t检验
t检验学习笔记 一、t检验的定义和用途 t检验是统计学中常用的假设检验方法,主要用于判断样本均值与总体均值间,或两个样本均值间是否存在显著差异。 在实际中应用广泛,例如在医学领域可用于比较两种药物的疗效;在教育领域&…...

HarmonyNext上传用户相册图片到服务器
图片选择就不用说了,直接用 无须申请权限 。 上传图片,步骤和android对比稍微有点复杂,可能是为了安全性考虑,需要将图片先拷贝到缓存目录下面,然后再上传,当然你也可以转成Base64,然后和服务…...

WebAssembly 3.0发布:浏览器端高性能计算迎来新突破!
“WebAssembly 3.0来了,浏览器端的高性能计算将彻底改变!”2025年,WebAssembly(Wasm)迎来了重大更新——WebAssembly 3.0正式发布。这次更新不仅支持多线程和SIMD指令集,还优化了内存管理,让浏览…...

计算机组成原理—— 外围设备(十三)
记住,伟大的成就往往诞生于无数次尝试和失败之后。每一次跌倒,都是为了让你学会如何更加坚定地站立;每一次迷茫,都是为了让你找到内心真正的方向。即使前路漫漫,即使困难重重,心中的火焰也不应熄灭。它代表…...

面试题之Vuex,sessionStorage,localStorage的区别
Vuex、localStorage 和 sessionStorage 都是用于存储数据的技术,但它们在存储范围、存储方式、应用场景等方面存在显著区别。以下是它们的详细对比: 1. 存储范围 Vuex: 是 Vue.js 的状态管理库,用于存储全局状态。 数据存储在内…...

window中git bash使用conda命令
window系统的终端cmd和linux不一样,运行不了.sh文件,为了在window中模仿linux,可以使用gui bash模拟linux的终端。为了在gui bash中使用python环境,由于python环境是在anaconda中创建的,所以需要在gui bash使用conda命…...
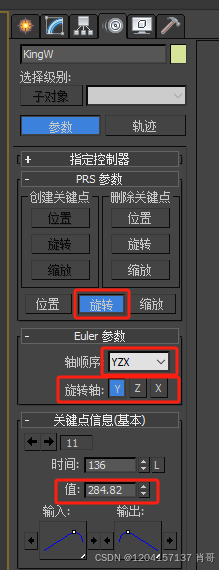
象棋掉落动画(局部旋转动画技巧)
1.被撞击阶段:根据被撞击速度,合理设置被撞距离 2.倒地阶段:象棋倒地的同时稍微前移 3.滚地阶段:象棋滚地后停止,在最后5帧内稍微回转一下。这里启用“PRS参数”的旋转来制作局部旋转动画...

Pycharm 2024在解释器提供的python控制台中运行py文件
2024版的界面发生了变化, run with python console搬到了这里:...

课题推荐:高空长航无人机多源信息高精度融合导航技术研究
高空长航无人机多源信息高精度融合导航技术的研究,具有重要的理论意义与应用价值。通过深入研究多源信息融合技术,可以有效提升无人机在高空复杂环境下的导航能力,为无人机的广泛应用提供强有力的技术支持。希望该课题能够得到重视和支持&…...

《DeepSeek训练算法:开启高效学习的新大门》
在人工智能的浪潮中,大语言模型的发展日新月异。DeepSeek作为其中的佼佼者,凭借其独特的训练算法和高效的学习能力,吸引了众多目光。今天,就让我们深入探究DeepSeek训练算法的独特之处,以及它是如何保证模型实现高效学…...

promise用法总结以及手写promise
JavaScript中的 Promise 是用于处理异步操作的对象,它代表了一个异步操作的最终完成(或失败)及其结果值。Promise 是异步编程的一种更简洁和更可读的方式,避免了回调地狱的问题。 Promise 的基本概念 一个 Promise 是一个表示异步…...

春招项目=图床+ k8s 控制台(唬人专用)
1. 春招伊始 马上要春招了,一个大气的项目(冲击波项目)直观重要,虽然大家都说基础很重要,但是一个足够新颖的项目完全可以把你的简历添加一个足够闪亮的点。 这就不得不推荐下我的 k8s 图床了,去年折腾快…...

Android 11.0 系统settings添加ab分区ota升级功能实现二
1.概述 在11.0的系统rom定制化开发中,在进行系统ota升级的功能中,在10.0以前都是使用系统 RecoverySystem的接口实现升级的,现在可以实现AB分区模式来进行ota升级的,但是 必须需要系统支持ab分区升级的模式才可以的,接下来分析下看怎么样进行ota升级功能实现 2.系统sett…...

【Spring+MyBatis】_图书管理系统(上篇)
目录 1. MyBatis与MySQL配置 1.1 创建数据库及数据表 1.2 配置MyBatis与数据库 1.2.1 增加MyBatis与MySQL相关依赖 1.2.2 配置application.yml文件 1.3 增加数据表对应实体类 2. 功能1:用户登录 2.1 约定前后端交互接口 2.2 后端接口 2.3 前端页面 2.4 单…...

什么是3D视觉无序抓取?
3D视觉无序抓取是一种结合三维视觉技术、机器人控制与智能算法的工业自动化解决方案,旨在实现机器人对散乱、无序堆放的物体进行自主识别、定位和抓取的操作。其核心是通过3D视觉系统获取物体的三维空间信息,结合路径规划与避障算法,引导机械臂完成高精度抓取任务,无需依赖…...

【Java】理解字符串拼接与数值运算的优先级
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: Java 文章目录 💯前言💯代码分析1. 第一句输出2. 第二句输出3. 第三句输出 💯关键概念与深入分析1. 字符串拼接的优先级2. 运算符的优先级与结合性3. 字符串拼接与数值运算的结合 &…...

[250217] x-cmd 发布 v0.5.3:新增 DeepSeek AI 模型支持及飞书/钉钉群机器人 Webhook 管理
目录 X-CMD 发布 v0.5.3📃Changelog🧩 deepseek🧩 feishu|dingtalk📦 x-cmd✅ 升级指南 X-CMD 发布 v0.5.3 📃Changelog 🧩 deepseek 新增 deepseek 模块,用户可通过 deepseek 直接请求使用 …...

渗透利器:Burp Suite 联动 XRAY 图形化工具.(主动扫描+被动扫描)
Burp Suite 联动 XRAY 图形化工具.(主动扫描被动扫描) Burp Suite 和 Xray 联合使用,能够将 Burp 的强大流量拦截与修改功能,与 Xray 的高效漏洞检测能力相结合,实现更全面、高效的网络安全测试,同时提升漏…...

Linux、Docker与Redis核心知识点与常用命令速查手册
Linux、Docker与Redis核心知识点与常用命令速查手册 一、Linux基础核心 1. 核心概念 文件系统:采用树形结构,根目录为/权限机制:rwx(读/写/执行)权限,用户分为owner/group/others软件包管理: …...
)
DeepSeek HuggingFace 70B Llama 版本 (DeepSeek-R1-Distill-Llama-70B)
简简单单 Online zuozuo :本心、输入输出、结果 文章目录 DeepSeek HuggingFace 70B Llama 版本 (DeepSeek-R1-Distill-Llama-70B)前言vllm 方式在本地部署 DeepSeek-R1-Distill 模型SGLang 方式在本地部署 DeepSeek-R1-Distill 模型DeepSeek-R1 相关的 Models,以及 Huggin…...

实战演练:基于快马平台构建一个可交互的电商导购智能体应用
最近在尝试做一个电商导购智能体的项目,发现用InsCode(快马)平台来实现特别方便。这个智能体不仅能展示商品,还能通过对话理解用户需求,给出个性化推荐。下面分享下我的实现过程和经验。 项目整体设计思路 首先明确核心功能:既要…...

Python模型微调效率提升300%:从数据预处理到梯度裁剪的5步工业级优化流程
更多请点击: https://intelliparadigm.com 第一章:Python模型微调效率提升300%:从数据预处理到梯度裁剪的5步工业级优化流程 在真实生产环境中,微调大型语言模型常因I/O瓶颈、内存冗余和梯度震荡导致训练吞吐量低下。我们通过一套…...

程序员也能看懂的古代天文历法:从《资治通鉴》里的“阏逢执徐”到现代农历算法
程序员也能看懂的古代天文历法:从《资治通鉴》里的“阏逢执徐”到现代农历算法 翻开《资治通鉴》开篇的"起著雍摄提格,尽玄黓困敦",或是遇到古籍中"岁在阏逢执徐"的记载时,程序员的第一反应可能是:…...

Three.js 代码云效果 | 三维可视化 / AI 提示词
Three.js 代码云效果 | 三维可视化 / AI 提示词 📋 AI 提示词 使用 Three.js 的 ShaderMaterial 创建代码云效果,通过多个代码纹理的随机切换和下落动画,实现代码雨的视觉效果。🖼️ 效果预览 🎮 案例演示 立即体验…...

内存增强语言模型:TRIBL2与IGTree架构对比与实践
1. 项目背景与核心价值在自然语言处理领域,内存增强型语言模型近年来展现出独特的优势。TRIBL2和IGTree作为两种典型的内存架构,通过外部记忆模块扩展了传统神经网络的上下文处理能力。这类模型特别适合需要长期依赖关系的任务场景,比如对话系…...

GPRS技术原理与测试方法全解析
1. GPRS技术原理深度解析GPRS(General Packet Radio Service)作为2G向3G过渡的关键技术,彻底改变了传统GSM网络的电路交换模式。我在2005年首次接触GPRS模块开发时,这种"永远在线"的特性让远程数据采集项目变得可行。其…...
)
别再死记硬背ARMA公式了!用Python的statsmodels库实战时间序列预测(含代码)
别再死记硬背ARMA公式了!用Python的statsmodels库实战时间序列预测(含代码) 时间序列分析是金融、气象、电商等领域不可或缺的工具,而ARMA模型作为经典方法,常让学习者陷入公式记忆的泥潭。本文将以航空乘客数据集为例…...

【不喜欢运动的人可以放心了】一生心跳10亿次:从鼩鼱到大象,一个跨越230物种的生命数学不变量
论文来源:arXiv:2604.27856 (2026) | Mesfin Taye 一、开篇:两种极端的生命,同一个心跳总数 想象一只侏儒鼩鼱(Suncus etruscus)。它体重约2克,比一个回形针还轻。为了维持这具微小身体的运转,…...

Sunshine游戏串流服务器:技术架构解析与实战部署指南
Sunshine游戏串流服务器:技术架构解析与实战部署指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,为Moonlig…...

XIAO双通道Wi-Fi电能表:家庭能源监控利器
1. 项目概述:XIAO双通道Wi-Fi交流电能表最近在折腾家庭能源监控系统时,发现Seeed Studio新推出的XIAO双通道Wi-Fi交流电能表是个很有意思的设备。这款基于ESP32-C6模组的电能表配备了两个100A电流互感器(CT钳),可以直接接入Home Assistant实现…...