2025-arXiv-OmniThink:通过思考扩展机器写作的知识边界
arXiv | https://arxiv.org/abs/2501.09751
GitHub | https://github.com/zjunlp/OmniThink
项目主页 | https://zjunlp.github.io/project/OmniThink/
ModelScope 在线 Demo | https://www.modelscope.cn/studios/iic/OmniThink
摘要:
大语言模型驱动的机器写作通常依赖于检索增强生成(RAG)。 然而,这些方法仍然局限于模型预定义范围的边界内,限制了内容生成中的丰富信息。具体而言,单纯的检索信息往往缺乏深度、实用性和重复性,这会负面影响生成文章的质量,导致文章浅薄、重复且缺乏原创性。
为解决这些问题,我们提出了 OmniThink 机器写作框架,该框架模拟了人类逐步深化知识的迭代扩展和反思过程。OmniThink 的核心理念是模拟学习者在逐步深化对主题知识理解时的认知行为。实验结果表明,OmniThink 在提高生成文章的知识密度的同时,不会牺牲连贯性和深度等指标。人类评估和专家反馈进一步突显了 OmniThink 在应对长文生成中的现实挑战方面的潜力。
一、引言
写作是一个持续的过程,涉及收集信息和思考。近年来,LLMs 在机器写作方面取得了显著进展,例如在开放领域长文生成或特定主题的报告生成方面。为了获取有用的信息,早期尝试使用检索增强生成(RAG)来扩展给定主题的新信息。然而,传统的 RAG 依赖于固定的一套检索策略,这在生成方面缺乏多样性,无法充分探索主题,导致对主题的理解碎片化且不完整。为了解决这一问题,STORM 和 CoSTORM 提出了角色扮演方法,旨在扩展视角,即从多个角度收集信息,从而扩展信息空间。
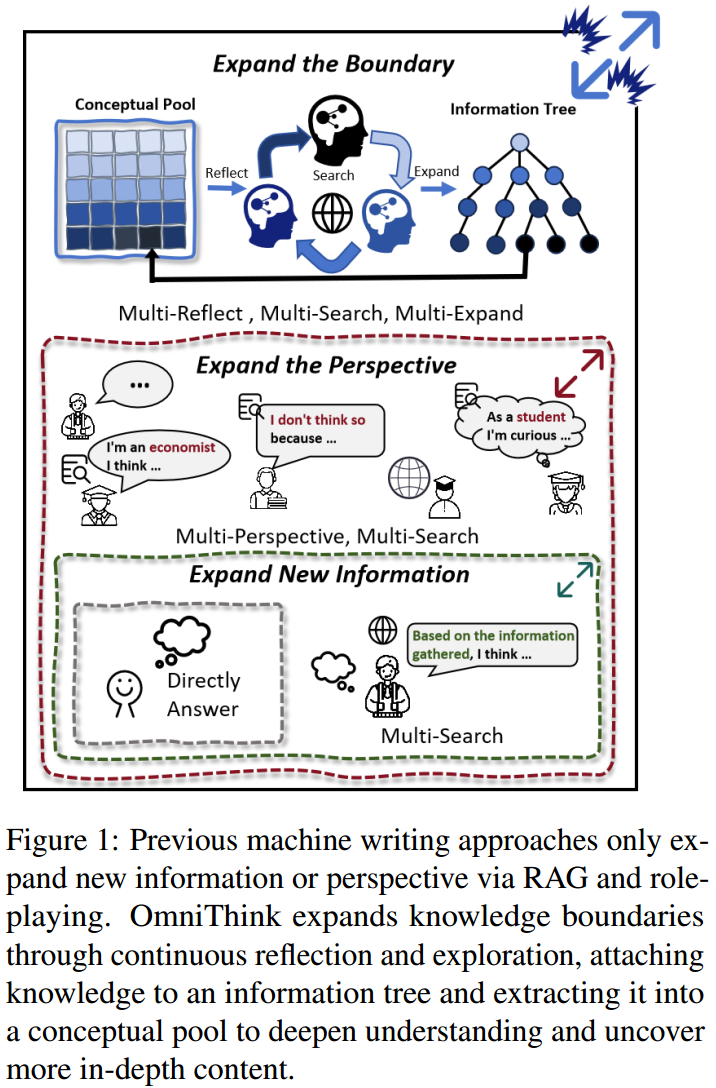
然而,这些方法仍然局限于个人角色的范围内进行思考,难以产生深刻的内容并突破自身的知识边界。特别是,检索到的信息往往缺乏深度、实用性和冗余性,直接影响生成文章的质量,导致内容浅薄、重复且缺乏原创性。人类在写作过程中可以自然地避免这些问题,人类作家不断反思已收集的信息和个人经验,从而重新组织、筛选和精炼其认知框架。这一过程促使作家不断调整写作方向和心理路径,最终使人类作者能够生成更为深刻、细腻和原创的内容。
基于此,我们提出了 OmniThink 这一新的机器写作框架,模仿人类认知过程中的迭代扩展与反思。OmniThink 的核心理念是模拟学习者在逐渐深化对复杂主题的理解过程中扩展知识边界的行为模式。 通过不断反思之前检索到的信息,OmniThink 能够确定进一步扩展的最佳步骤。这种扩展反思机制使得检索策略能够动态调整,从而促进对相关信息更为全面和深入的探索。一旦收集到多样化的信息,OmniThink 将进入提纲构建和文章生成阶段。这一迭代思考过程能够产生质量更高、知识密度更高、包含有用、深入和原创内容的文章。
二、背景
2.1 任务定义
我们专注于机器写作中的开放领域长文生成任务,该任务涉及从开放领域检索信息并综合生成一篇连贯的文章。
给定输入主题 T T T,开放领域长文生成的目标是生成一篇长文章 A A A。 当前的标准方法包括两个主要步骤:
- (i)使用搜索引擎 S S S 检索与主题 T T T 相关的信息 I = S ( T ) I = S(T) I=S(T);
- (ii)根据检索到的信息 I I I 和输入主题 T T T 生成大纲 O = Generate ( I , T ) O = \text{Generate}(I, T) O=Generate(I,T)。最后,使用大纲生成文章 A = Generate ( O , I ) A = \text{Generate}(O, I) A=Generate(O,I)。
2.2 重新审视先前的方法
先前的研究在提高开放域长文本生成的质量方面做出了大量努力。
- Co-STORM 在步骤(i)中引入了一种用户参与的圆桌讨论机制,以增强检索信息的多样性。
- STORM 在步骤(ii)中提出了一种提问机制,以提高生成提纲的质量和相关性。
尽管在开放域长文本生成方面取得了显著进展,但仍存在一个持续的挑战:生成的内容经常出现过度重复且缺乏实质性信息。
本文展示了由 STORM 生成的一个案例,其骨干模型为 GPT-4o:

在本文中,“AlphaFold 由 DeepMind 开发” 这一说法在多个地方重复出现,而在初次提及时只需出现一次即可。
2.3 文章的知识密度
以往的研究主要关注文章的相关性和正确性,但没有考虑文章是否具有足够的深度。许多生成的文章包含大量冗余信息,这与人类写作的方式存在很大不一致。为解决这一问题,我们引入了**知识密度(Knowledge Density, KD)**的概念,定义为有意义的内容与文本总体体积的比例,具体公式为:
K D = ∑ i = 1 N k i ⋅ U ( k i ) L KD=\frac{\sum_{i=1}^Nk_i\cdot U(k_i)}{L} KD=L∑i=1Nki⋅U(ki)
其中 N N N 为文档中识别出的总原子知识单元数量。函数 U ( k i ) U(k_i) U(ki) 表示第 i i i 个单元信息 k i k_i ki 是否唯一。 L L L 代表文本的总长度。在该公式中,分子表示从长文章中提取的唯一原子知识单元的总和,分母对应于文章的长度。
知识密度度量的价值在于其能够从信息获取的角度衡量生成文本的阅读成本。读者遇到低知识密度的内容时,往往会因冗余或无关细节而感到疲劳、沮丧或失去兴趣。相反,高知识密度的内容能够提供精简的体验,从而实现高效的知识传递。
先前的方法在处理提出的知识密度方面表现有限,原因在于开放域长文本生成中生成的内容必须基于检索到的信息。当检索到的信息不够多样化时,这些信息往往包含大量冗余和重复的内容,导致生成的文章出现重复和冗余现象。我们可以通过在步骤(i)中引入推理和规划来解决这一问题,将处理收集到的内容以提取非重叠、高密度的信息。
三、OmniThink
机器写作框架 OmniThink 模拟了人类迭代反思和扩展的过程。OmniThink 可以分为三个步骤:信息获取、提纲构建和文章撰写。
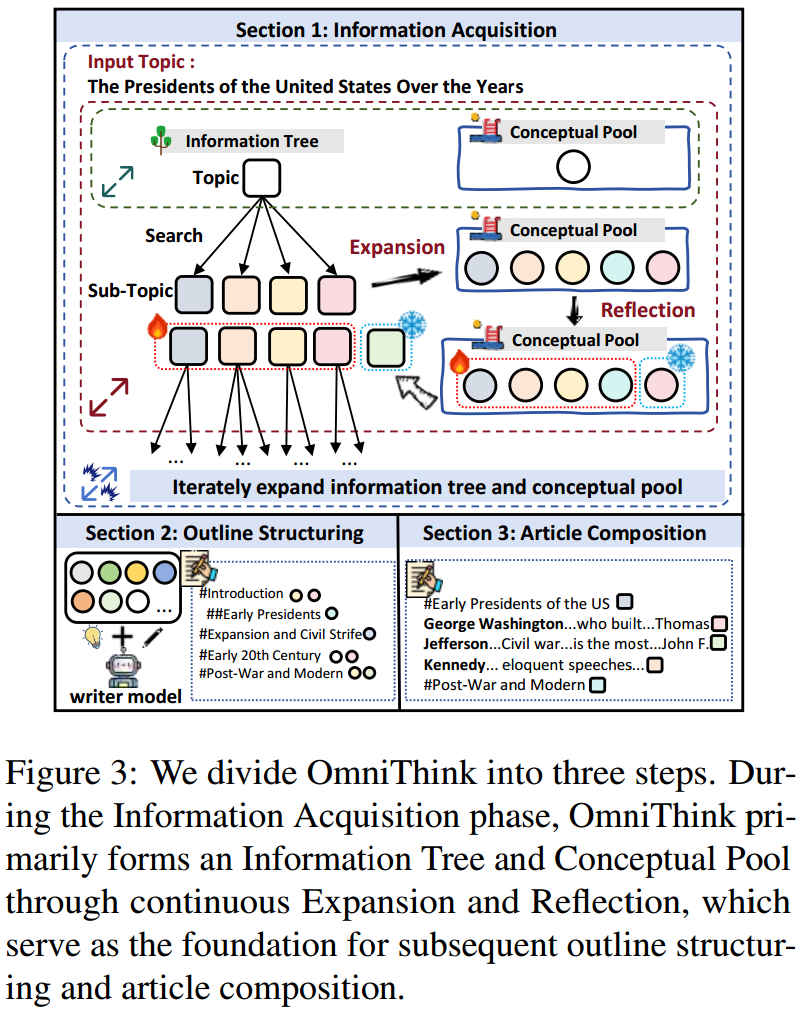
3.1 信息获取
为了获取多样且全面的信息,OmniThink 模仿人类的学习过程,通过迭代的扩展与反思逐步深化对主题的理解。这一迭代过程最终构建了一个信息树 T T T,该信息树以结构化和层级的方式组织检索到的信息,并构建了一个概念池 P P P,代表了在时间步 m m m 时 LLM 对主题的理解。
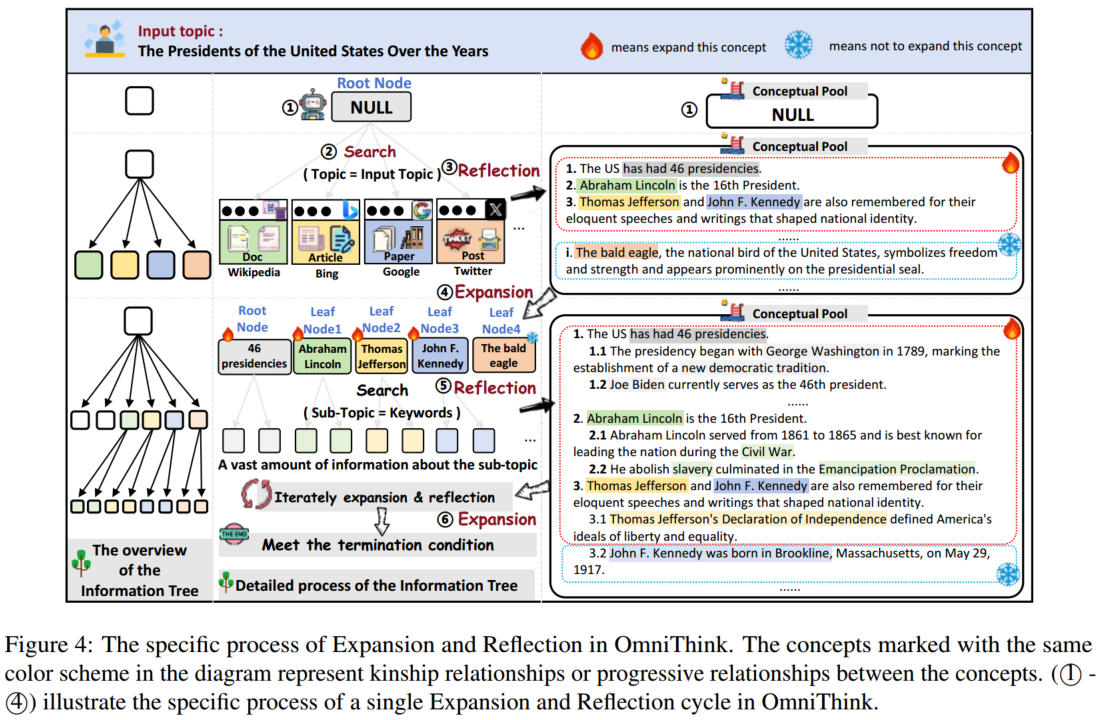
**初始化过程:**交互过程始于根据输入的主题 T T T 初始化根节点。OmniThink 首先利用搜索引擎(Google 或 Bing)检索与 T T T 相关的信息,并使用检索到的知识构建信息树的初始根节点 N r N_r Nr。 N r N_r Nr 中的初始信息随后被组织和分析,形成初步的概念池 P 0 P_0 P0,这构成了 OmniThink 对主题的基础理解,并指导后续的扩展与反思过程。
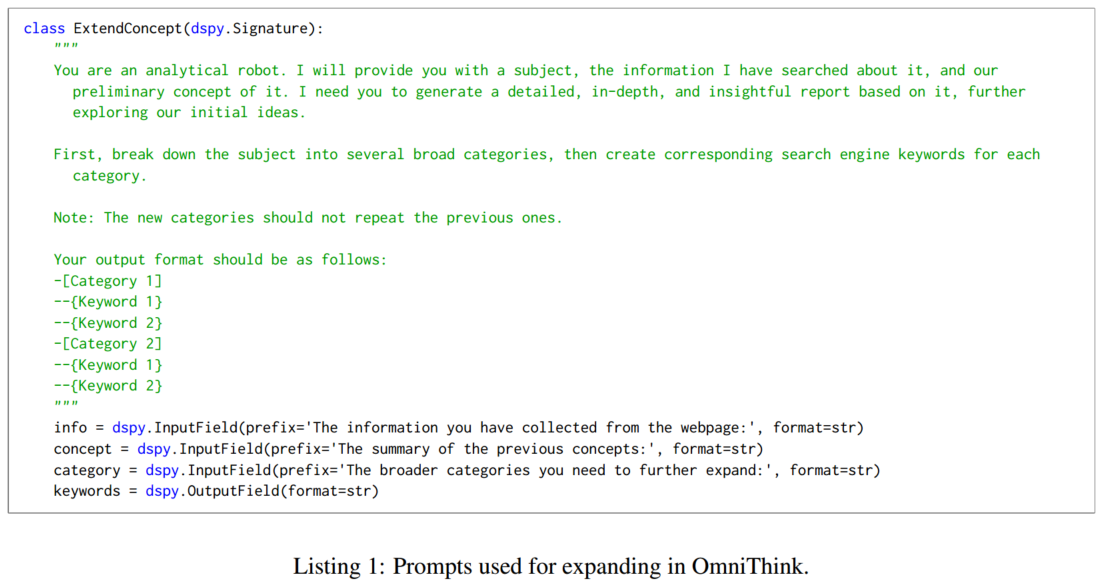
3.1.1 拓展
在时间步 m m m 时,OmniThink 分析信息树 T m T_m Tm 的所有叶节点 L m = { N 0 , N 1 , … , N n } L_m = \{N_0, N_1, …, N_n\} Lm={N0,N1,…,Nn}。这些叶节点首先被存储在概念缓冲区 P b P_b Pb 中,OmniThink 对每个节点进行评估,以确定是否需要进一步拓展。
-
对于需要扩展的节点,OmniThink 使用当前的概念池 P m P_m Pm 来识别更深层次的扩展区域或合适的扩展方向。
-
对于每个叶节点 N i N_i Ni,OmniThink 生成 k N i k_{N_i} kNi 个子节点 SUB ( N i ) = { S 0 , S 1 , … , S k N i } \text{SUB}(N_i) = \{S_0, S_1, …, S_{k_{N_i}}\} SUB(Ni)={S0,S1,…,SkNi} 用于扩展。每个子节点代表从当前节点 N i N_i Ni 中识别出的具体方面或子主题。
-
对于每个子节点,OmniThink 检索相关的信息并将其存储在相应的节点中,随后将子节点添加到更新后的信息树 T m + 1 T_{m+1} Tm+1。
T m + 1 = Combine ( T m , SUB ( N 0 ) , … , SUB ( N n ) ) T_{m+1} = \text{Combine}(T_m, \text{SUB}(N_0), …, \text{SUB}(N_n)) Tm+1=Combine(Tm,SUB(N0),…,SUB(Nn))
这种针对性的信息检索过程确保了 OmniThink 为每个子节点收集了全面而深入的内容,从而丰富了信息树的层次结构。
3.1.2 反思
OmniThink 将新检索到的信息反映到所有叶节点 L m + 1 = { N 0 , … , N n } L_{m+1} = \{N_0, …, N_n\} Lm+1={N0,…,Nn} 中。
- 从每个叶节点检索到的信息将被分析、筛选和综合,以提炼出核心见解 I m + 1 = { INS 0 , … , INS n } I_{m+1} = \{\text{INS}_0, …, \text{INS}_n\} Im+1={INS0,…,INSn}。
- 这些精炼的见解随后被纳入概念池 P m P_m Pm,该概念池在整个过程中不断更新和丰富。
P m + 1 = Merge ( I m + 1 , P m ) P_{m+1} = \text{Merge}(I_{m+1}, P_m) Pm+1=Merge(Im+1,Pm)
利用更新后概念池 P m + 1 P_{m+1} Pm+1,OmniThink 会迭代地扩展信息树的叶节点。


这一扩展与反思的迭代循环将持续进行,直到 OmniThink 判断已获取了足够的信息,或者达到了预定义的最大检索深度 K K K。这确保所获取的信息具有相关性、详细性和多样性,从而为生成结构化且信息丰富的文章奠定坚实的基础。
3.2 提纲构建
提纲是文章的核心,决定了内容方向、结构层次和逻辑推进。为了创建一个导向明确、结构清晰且逻辑连贯的提纲,对主题进行全面而深入的理解是至关重要的。
在上一部分 OmniThink 保持了一个与主题紧密相关的概念池,这实际上代表了 LLM 对主题的理解范围和深度。在生成内容提纲时,我们首先创建一个草稿提纲 O D O_D OD,然后要求 LLM 对概念池 P P P 中的内容进行细化和链接,最终形成最终的提纲 O = Polish ( O D , P ) O = \text{Polish}(O_D, P) O=Polish(OD,P)。通过这种方法,LLM 能够在提纲中全面涵盖主题的关键点,并确保文章在逻辑连贯性和内容一致性方面达到要求。
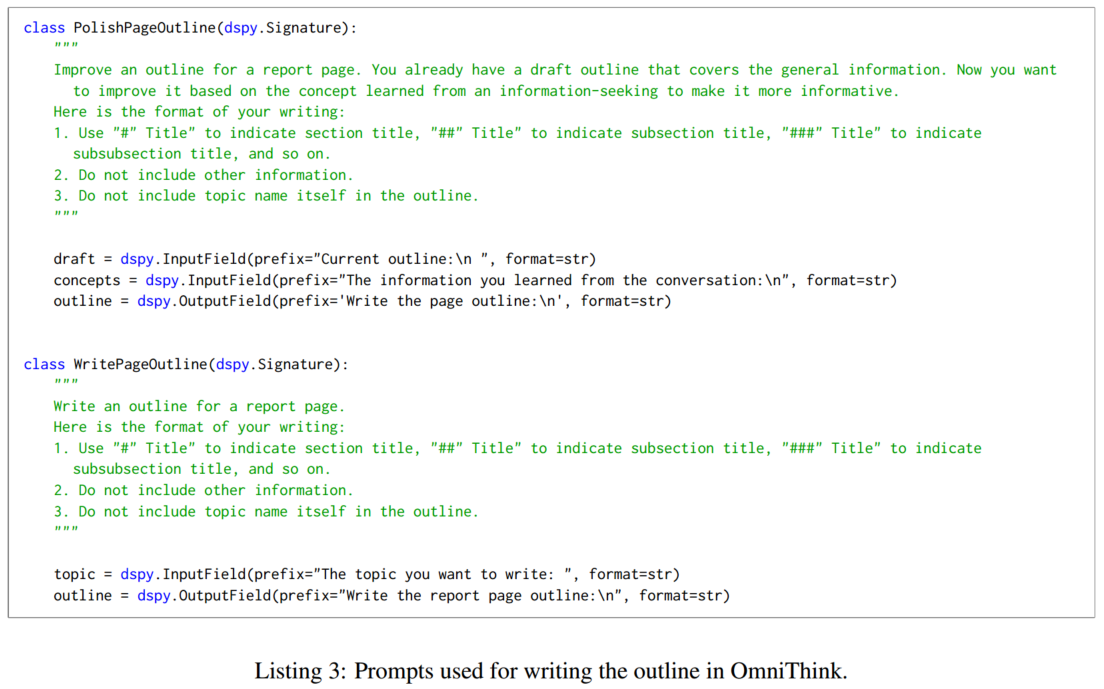
3.3 文章撰写
-
在完成提纲 O O O 后,我们开始为每一部分 S S S 编写内容,LLM 将并行工作,为每一部分编写内容。在编写每一部分的内容时,我们使用每一部分及其层次子部分的标题来通过计算语义相似度(Sentence-BERT 嵌入)从信息树中检索最相关的 K K K 篇文档。
-
获取相关的信息后提示 LLM 根据检索到的信息生成带有引用的内容。

- 一旦所有部分生成完毕,将它们连接成一篇完整的草稿文章 A D = { S 1 , … , S n } A_D = \{S_1, …, S_n\} AD={S1,…,Sn}。
- 由于这些部分是并行生成的且其他部分的具体内容尚未明确,提示 LLM 处理连接的文章删除重复信息,并形成最终的文章 A = { S 1 ′ , … , S n ′ } A = \{S'_1, …, S'_n\} A={S1′,…,Sn′}。

四、实验
4.1 实验设置
**评估数据集:**WildSeek
- WildSeek 收集并筛选了与开源 STORM 网络应用程序相关的数据,每个条目包含一个特定的主题和用户的目标。
**基线方法:**RAG、oRAG、STORM、Co-STORM,基线结果基于 STORM 进行重现。
评估设置:
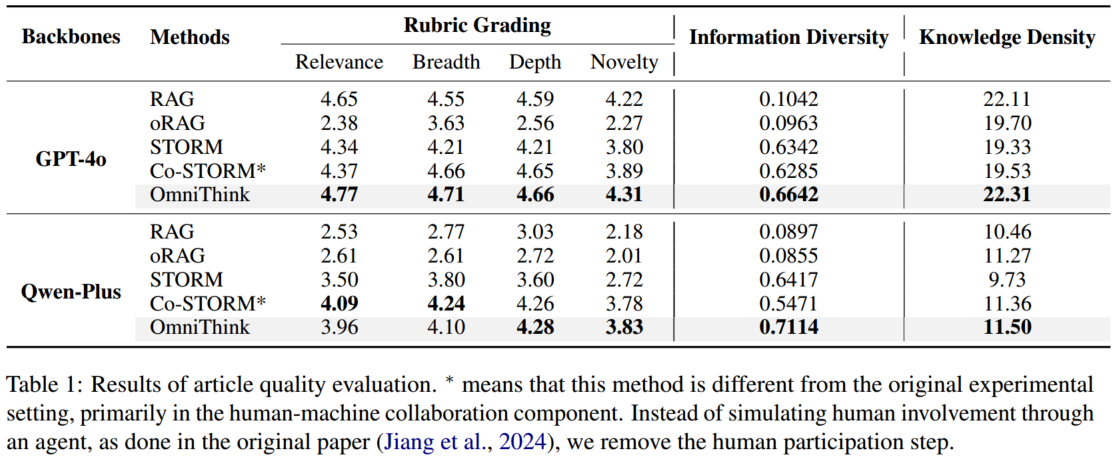
- 自动评估:使用 Prometheus2 对文章进行 0 到 5 分的评分,评估其相关性、广度、深度和新颖性。此外,我们还通过测量信息多样性(网页之间的余弦相似度差异)和知识密度来衡量信息丰富度。
- **人工评估:**随机选择了 20 个主题,并将通过我们方法生成的文章与基于自动评价综合表现最佳的基线 Co-STORM 生成的文章进行比较,在相同四个方面进行评分。
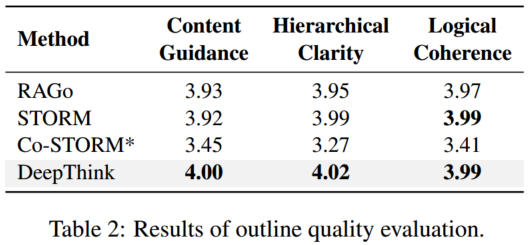
提纲评估标准:

文章评估标准:

参数设置:
- 基于 DSpy 框架构建了,提示:
- 温度设置为 1.0,top_p 设置为 0.9,Bing API,并将每个查询返回的网页数量参数设置为 5。
- 知识密度的计算,我们采用 Factscore3 作为基础模型,利用 GPT-4o-08-06 进行原子知识的分解。分解后,我们使用 GPT-4o-08-06 对拆分的原子知识进行去重。
- 为了避免搜索引擎变化带来的影响,表中所有结果均在 3 天内完成。
4.2 自动评估结果
4.2.1 文章生成
4.2.2 提纲生成
4.2.3 消融实验

4.2.4 拓展与反思分析
将用于拓展与反思的模型分别替换为性能较低的模型,并测量生成文章的各项指标性能下降的程度,作为拓展与反思过程对这些指标影响的指示器。
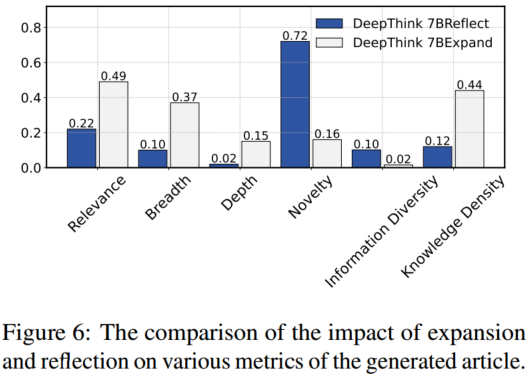
**持续反思扩展知识边界:**在新颖性和信息多样性方面,反思比拓展更重要
**拓展增强了知识的深度并提高了信息的相关性:**在广度和深度方面,拓展比反思更为重要。
4.2.5 思考深度分析
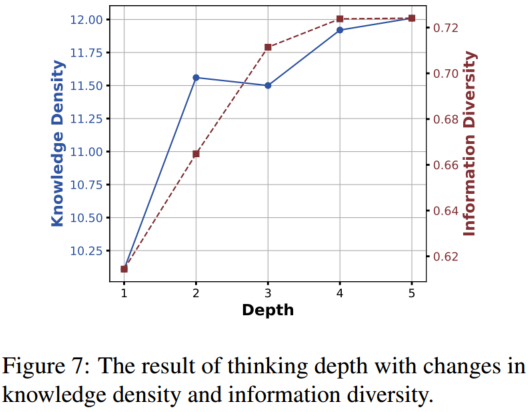
4.3 人工评估结果
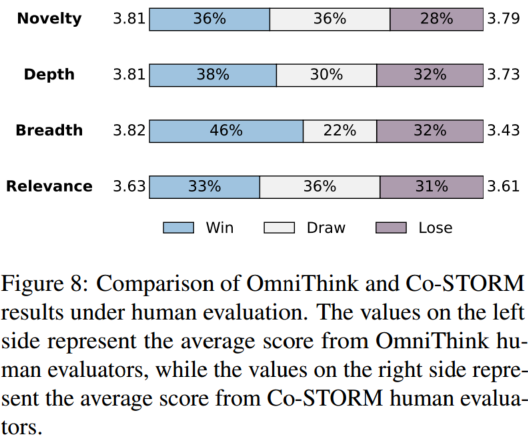
4.4 案例研究
由 OmniThink 生成的 AlphaFold 案例:

相关文章:
2025-arXiv-OmniThink:通过思考扩展机器写作的知识边界
arXiv | https://arxiv.org/abs/2501.09751 GitHub | https://github.com/zjunlp/OmniThink 项目主页 | https://zjunlp.github.io/project/OmniThink/ ModelScope 在线 Demo | https://www.modelscope.cn/studios/iic/OmniThink 摘要: 大语言模型驱动的机器写作通…...

【广州大学主办,发表有保障 | IEEE出版,稳定EI检索,往届见刊后快至1个月检索】第二届电气技术与自动化工程国际学术会议 (ETAE 2025)
第二届电气技术与自动化工程国际学术会议 (ETAE 2025) The 2nd International Conference on Electrical Technology and Automation Engineering 大会官网:http://www.icetae.com/【更多详情】 会议时间:2025年4月25-27日 会议地点:…...

机器学习:01数学基础教程
函数 极限 按照一定次数排列的一列数:“,“,…,"…,其中u 叫做通项。 对于数列{Un}如果当n无限增大时,其通项无限接近于一个常数A,则称该数列以A为极限或称数列收敛于A,否则称数列为发散, 极限值 左…...

仿叮咚买菜鸿蒙原生APP
# DingdongShopping 这是一个原生鸿蒙版的仿叮咚买菜APP项目 鸿蒙Next发布至今已经有一年多的时间了,但有时候我们想要实现一些复杂的功能或者效果,在开发文档上查阅一些资料还是比较费时的,有可能还找不到我们想要的内容。而社会层面上分享…...

WordPress“更新失败,响应不是有效的JSON响应”问题的修复
在使用WordPress搭建网站时,许多人在编辑或更新文章时,可能会遇到一个提示框,显示“更新失败,响应不是有效的JSON响应”。这个提示信息对于不了解技术细节的用户来说,太难懂。其实,这个问题并不复杂&#x…...
 -> Unit)
kotlin的onFailure: () -> Unit
在Kotlin中,onFailure: () -> Unit表示一个没有参数且返回类型为Unit的函数。 在Kotlin中,Unit类型用于表示那些没有返回值的函数。具体来说,() -> Unit表示一个没有参数的函数,其返回类型为Unit。这种函数通常用于表示…...

通过网线将Keysight DSOX4154A示波器信号传输至电脑的Step
一、硬件连接 连接网线 使用标准以太网线(Cat5e或更高)连接示波器背面的 LAN端口 至电脑或同一局域网的交换机/路由器。 二、示波器网络配置 进入网络设置菜单 点击示波器前面板右上角 【Utility】 → 【I/O】 → 【LAN Settings】。 配置IP地址 自…...

midjourney 一 prompt 提示词
midjourney 不需要自然语言的描述,它只需要关键词即可。 一个完整的Midjourney prompt通常包括三个部分 图片提示(Image Prompts)、文本提示(Text Prompt)和参数(Parameters)。 1、图片提示(…...
)
微信小程序 - 网络请求基础路径集中管理(基础路径集中管理策略、动态切换基础路径)
一、基础路径集中管理 在微信小程序项目开发中,经常会将请求的基础路径集中管理 这样可以避免在多个页面中重复定义,同时也方便后续维护与修改 二、基础路径集中管理策略 1、使用全局变量 微信小程序提供了 App 对象,可以在 app.js 中定义…...

C#的委托delegate与事件event
在C#中,delegate(委托)和 event(事件)是两个非常重要的概念,它们主要用于实现回调机制和事件驱动编程。下面详细介绍它们的原理和使用场景。 1. Delegate(委托) 1.1 委托的原理 委托…...

apache artemis安装
安装apache artemis https://xxzkid.github.io/2025/apache-artemis-install...

Lightning基础训练尝试实例
一、训练任务概述 动机:由于后续的课题中会用到类似图像去噪的算法,考虑先用U-Net,这里做一个前置的尝试。 训练任务:分割出图像中的细胞。 数据集:可私 数据集结构: 二、具体实现 U-Net的网络实现是现…...
)
osgearth视点坐标及鼠标交点坐标的信息显示(七)
核心函数如下: void COSGObject::addViewPointLabel() {//mRoot->addChild(osgEarth::Util::Controls::ControlCanvas::get(mViewer));//放开这句,球就卡住了。 为什么,shitosgEarth::Util::Controls::ControlCanvas* canvas = osgEarth::Util::Controls::ControlCanvas…...

动态规划 之 背包问题
文章目录 0-1背包问题2915.和为目标值的最长子序列的长度494.目标和 完全背包问题322.零钱兑换518.零钱兑换II 多重背包2585.获得分数的方法数 分组背包1155.掷骰子等于目标和的方法数 背包问题是动态规划一个很重要的一类题目,主要分为0-1背包问题以及完全背包问题…...

【Azure 架构师学习笔记】- Azure Databricks (11) -- UC搭建
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 接上文 【Azure 架构师学习笔记】- Azure Databricks (10) – UC 使用 前言 由于ADB 的更新速度很快,在几个月之后重新搭建ADB 时发现UC 已经更新了很多,为了后续做ADB 的功…...
)
RTMP(Real-Time Messaging Protocol)
RTMP(Real-Time Messaging Protocol)是一种用于实时音视频和数据传输的协议,常见于直播和流媒体应用。 一 RTSP 协商消息 一、消息类型(Message Types) RTMP消息分为多种类型,通过Message Type ID标识&a…...

docker容器部署jar应用导入文件时候报缺少字体错误解决
如题,在导入文件时候报错如下: Handler dispatch failed; nested exception is java.lang.NoClassDefFoundError: Could not initialize class sun.awt.X11FontManager 经查是缺少对应字体,解决办法有两张: 第一种:…...

贪吃蛇解析
目录 文章结尾有代码可自取 Win32API 光标的隐藏 获取按键信息 控制光标位置 游戏开始前的准备 游戏准备及介绍 加载和欢迎界面 打印游戏指南 运行游戏 打印墙体和说明 设置蛇的各个信息 初始化及打印蛇 创造食物 运行游戏 1)打印得分情况 2&#…...

vue非组件的初学笔记
1.创建Vue实例,初始化渲染的核心 准备容器引包创建Vue实例new Vue() el用来指定控制的盒子data提供数据 2.插值表达式 作用利用表达式插值,将数据渲染到页面中 格式{{表达式}} 注意点 表达式的数据要在data中存在表达式是可计算结果的语句插值表达式…...

LeetCode 热题 100_单词搜索(60_79_中等_C++)(深度优先搜索(回溯))(初始化二维vector的大小)
LeetCode 热题 100_单词搜索(60_79) 题目描述:输入输出样例:题解:解题思路:思路一(深度优先搜索(回溯)): 代码实现代码实现(思路一&am…...

为什么bitsandbytes在Docker环境中编译时会出现CUDA版本不匹配问题?
为什么bitsandbytes在Docker环境中编译时会出现CUDA版本不匹配问题? 【免费下载链接】bitsandbytes Accessible large language models via k-bit quantization for PyTorch. 项目地址: https://gitcode.com/gh_mirrors/bi/bitsandbytes bitsandbytes作为PyT…...

Cerebro模块化集群主板:多架构计算节点协同设计解析
1. Cerebro集群主板概述Cerebro是一款革命性的模块化集群主板,专为需要多节点协同计算的场景设计。它最大的亮点在于能够同时支持四种不同类型的计算模块——NVIDIA Jetson系列、树莓派CM4/CM5以及Radxa CM5。这种设计理念源于Sparklab Solution团队在实际开发中遇到…...

如何在手机端使用嘎嘎降AI:移动端操作免费提交全流程完整图文教程
如何在手机端使用嘎嘎降AI:移动端操作免费提交全流程完整图文教程 第一次用降AI工具会遇到很多不确定的地方——传什么格式、选哪个模式、怎么验收效果。 这篇教程把常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com)&…...

AI代码安全审计:LLM如何革新传统SAST,提升漏洞检测效率
1. 项目概述:当AI成为代码的“安全审计员”最近在开源社区里,我注意到一个挺有意思的项目,叫kilogrametz/ai-security-audit。光看名字,你大概能猜到它想做什么:用人工智能(AI)来给代码做安全审…...

蓝牙耳机女款不伤耳朵怎么选?200-500元挂耳/耳夹/入耳实测,开发者多场景适配指南
针对女性用户久戴耳机耳道胀痛、开发者多场景使用不稳定的痛点,本文以技术科普真实实测为核心,测评200-500元价位挂耳、耳夹、入耳三类主流蓝牙耳机,聚焦不伤耳佩戴设计、蓝牙5.4/6.0传输、声学降噪等技术,结合代码编写、视频会议…...

基于Axon Hub构建高可用微服务消息枢纽:CQRS/EDA架构实践指南
1. 项目概述:一个为微服务架构而生的消息枢纽在微服务架构的实践中,服务间的通信是核心挑战之一。无论是同步的RPC调用,还是异步的事件驱动,都需要一个可靠、高效且易于管理的通信基础设施。今天要聊的这个项目looplj/axonhub&…...

5分钟快速上手:Windows系统iperf3网络性能测试完整指南
5分钟快速上手:Windows系统iperf3网络性能测试完整指南 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3是业界公认的专业网络性能…...

DIY 3D打印机电源与散热改造:从12V升级24V热床,告别加热慢
3D打印机热床升级实战:从12V到24V的极速升温方案 每次启动3D打印前,盯着缓慢爬升的热床温度计,你是否也经历过那种等待的煎熬?特别是使用大尺寸热床时,12V系统的功率瓶颈让预热时间动辄超过10分钟。这不仅是时间浪费&a…...

3分钟上手APK-Installer:Windows上最便捷的安卓应用安装方案
3分钟上手APK-Installer:Windows上最便捷的安卓应用安装方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法直接运行Android应用而苦…...

鸿蒙 HarmonyOS 6 | TextInput组件 ONE_TIME_CODE 验证码输入实战
前言 验证码输入是登录、注册、密码找回、支付确认里最常见的一类交互。这个场景看起来简单,真正做起来,体验差距却很明显。输入框类型选得不对,系统就不会把它识别成验证码场景,输入法优化、自动填充、无障碍提示这些能力都很难接…...