Word Embeddings
Count-based Approach

Term-document matrix: Document vectors
Two ways to extract information from the matrix:
- Column-wise: a document is represented by a |V|-dim vector (V: vocabulary)

Widely used in information retrieval:
-
find similar documents 查找類似的文件
- Two documents that are similar will tend to have similar words

-
find documents close to a query 查找附近的查詢的文件
- Consider a query as a document

- Row-wise: a word is represented by a |D|-dim vector (D: document set

Term-term matrix
we have seen it before (co-occurrence vectors): Count how many times a word u appearing with a word v

- raw frequency is bad 原始頻率不良
- Not all contextual words are equally important: of, a, … vs. sugar, jam, fruit… 並非所有上下文單詞同樣重要
- Which words are important, which ones are not?
- infrequent words are more important than frequent ones (examples?
- ) 不頻繁的單詞比常見單詞更重要
- correlated words are more important than uncorrelated ones (examples?)
- …
→ weighing schemes (TF-IDF, PMI,…)
Weighing terms: TF-IDF (for term-document matrix)
-
tf (frequency count):
t f ( t , d ) = log 10 ( 1 + c o u n t ( t , d ) ) tf(t,d)=\log_{10}(1+count(t,d)) tf(t,d)=log10(1+count(t,d)) -
idf (inverse document frequency): popular terms (terms that appear in many documents) are down weighed
t f ( t , d ) = log 10 N d f ( t ) tf(t,d)=\log_{10}\frac{N}{df(t)} tf(t,d)=log10df(t)N -
TF - IDF:
t f − i d f ( t , d ) = t f ( t , d ) ∗ i d f ( t ) tf - idf(t,d) = tf(t,d) *idf(t) tf−idf(t,d)=tf(t,d)∗idf(t)

-
Many word pairs should have > 0 counts, but their corresponding matrix entries are 0s because of lacking data (data sparsity)
→ Laplace smoothing: adding 1 to every entry (pseudocount)
| Pros | Cons |
|---|---|
| Simple and intuitive | Word/document vectors are sparse (dims are |V|, vocabulary size, or |D|, number of documents, often from 2k to 10k) → difficult for machine learning algorithms |
| Dimensions are meaningful (e.g., each dim is a document / a contextual word) → easy to debug and interpret (Think about Explainable AI) | How to represent word meaning in a specific context? |
| (From sparse vectors to dense vectors)-> | Employ dimensionality reduction (e.g., latent semantic analysis - LSA) |
| Use a different approach: prediction (coming up next) |
Prediction-based Approach
Introduction to ANNs used to learn word embeddings
- two major count-based approach methods:
- term-document matrix 術語文檔矩陣
- term-term matrix 術語矩陣
- Raw frequency is bed
- using weighing schemes to “correct” counts使用稱重方案
- using smoothing to take into account “unseen” events使用平滑來考慮看不見的事件
Formalisation
Assumptions:
● each word w ∈ V is represented by a vector v ∈ R d (d is often smaller than 3k)
● there is a mechanism to compute the probability Pr (w|u 1 , u 2 , …, u l) of the event that a target word w appears in a context (u 1 , u 2 , …, u l ).
Task: find a vector v for each word w such that those probabilities are as high as
possible for each w and its context (u 1 , u 2 , …, u l ).
We use a neural network with parameters θ to compute the probability by minimizing the cross-entropy loss使用具有最小參數θ的神經網絡。透過最小化交叉熵損失來計算概率
L ( θ ) = − ∑ ( w , u 1 , … , u l ) ∈ D train log Pr ( w ∣ u 1 , … , u l ) L(\theta) = -\sum_{(w, u_1, \ldots, u_l) \in D_{\text{train}}} \log \Pr(w \mid u_1, \ldots, u_l) L(θ)=−∑(w,u1,…,ul)∈DtrainlogPr(w∣u1,…,ul)
Bengio

CBOW:
CBOW 模型的工作原理
-
輸入 (Input Layer):
- 給定一個目標詞 w t w_t wt ,選取其 前 m 個詞 和 後 m 個詞 作為上下文詞 (context words)。
- 這些詞會從詞嵌入矩陣 CCC 中查找對應的詞向量。
-
投影層 (Projection Layer)
- 將這些上下文詞對應的詞向量取平均: y = average ( w t − 1 , . . . , w t − m , w t + 1 , . . . , w t + m ) y = \text{average}(w_{t-1}, ..., w_{t-m}, w_{t+1}, ..., w_{t+m}) y=average(wt−1,...,wt−m,wt+1,...,wt+m)
- 這一步沒有非線性變換 (例如 ReLU 或 tanh),只是簡單的平均。
-
輸出層 (Output Layer)
- 計算該平均向量 y y y 與詞彙矩陣 W W W 的線性變換,並使用 softmax 來預測中心詞 wtw_twt: P ( w t ∣ w t − 1 , . . . , w t − m , w t + 1 , . . . , w t + m ) = softmax ( W y ) P ( w t ∣ w t − 1 , . . . , w t − m , w t + 1 , . . . , w t + m ) = s o f t m a x ( W y ) P(w_t | w_{t-1}, ..., w_{t-m}, w_{t+1}, ..., w_{t+m}) = \text{softmax}(Wy)P(wt∣wt−1,...,wt−m,wt+1,...,wt+m)=softmax(Wy) P(wt∣wt−1,...,wt−m,wt+1,...,wt+m)=softmax(Wy)P(wt∣wt−1,...,wt−m,wt+1,...,wt+m)=softmax(Wy)
- Softmax 的輸出是一個機率分佈,表示詞彙表 (vocabulary) 中每個詞作為中心詞的可能性。
CBOW 的特點
- 上下文到目標詞:它是從上下文詞預測中心詞(這與 Skip-gram 相反,Skip-gram 是用中心詞預測周圍的上下文詞)。
- 計算高效:由於使用平均詞向量,CBOW 計算速度通常比 Skip-gram 更快,尤其是在大語料庫上訓練時。
- 適合大規模語料庫:CBOW 在大語料庫下通常表現更穩定,適合訓練大詞彙的詞向量。
CBOW 在 NLP 任務中的影響
- 詞向量學習:CBOW 提供了一種高效的方式來學習詞向量,後來影響了 GloVe、FastText 等模型的發展。
- 語意計算:學到的詞向量可以用來計算詞語之間的語義相似性,例如餘弦相似度 (cosine similarity)。
- 下游應用:CBOW 訓練出的詞向量可以應用於 文本分類、情感分析、機器翻譯 等 NLP 任務。




| CBOW | Skip-gram | |
|---|---|---|
| 目标 | 用上下文词预测中心词 | 用中心词预测上下文词 |
| 计算速度 | 快 | 慢(因为对每个中心词要预测多个上下文词) |
| 适用场景 | 大数据、大语料库 | 小数据、小语料库 |
| 效果 | 适合学习常见词的词向量 | 在低频词的词向量学习上更优 |
word2vec
- Skip-gram model
- “a baby step in Deep Learning but a giant leap towards Natural Language Processing”
- can capture linear relational meanings (i.e., analogy):
- king - man + women = queen


Problems : biases (gender, ethnic, …)
- Word embeddings are learned from data → they also capture biases implicitly appearing in the data
- Gender bias:
- “computer_programmer” is closer to “man” than “woman”
- “homemaker” is closer to “woman” than “man”
- Ethnic bias:
- African-American names are associated with unpleasant words (more than European-American names)
- …
→ Debiasing embeddings is a hot (and very needed) research topic
Dealing with unknown words
- Many words are not in dictionaries
- New words are invented everyday
- Solution 1: using a special token #UNK # for all unknown words
- Solution 2: using characters/sub-words instead of words
- Characters (c-o-m-p-u-t-e-r instead of computer)
- Subwords (com-omp-mpu-put-ute-ter instead of computer)
Word embeddings in a specific context
- The meaning of a word standing alone can be different than its meaning in a specific context
- He lost all of his money when the bank failed.
- He stood on the bank of Amstel river and thought about his future.
- Solution: w |c = f (w, c)
- Solution 1: f is continuous w.r.t. c (contextual embeddings, e.g., ELMO, BERT - next week)
- Solution 2: f is discrete w.r.t. c (e.g., word sense disambiguation - coming up in the next video)
Summary
- Prediction-based approaches require neural network models, which are not
intuitive as count-based ones - Low dimensional vectors (about 200-400 dimensions)
- Dimensions are not easy to interpret
- Robust performance for NLP tasks
延伸:Word Embeddings 進化
-
靜態詞嵌入(Static Embeddings):
- Word2Vec、GloVe、FastText
- 缺點:一個詞的向量固定,不能根據不同上下文改變語義(如「bank」的不同意思)。
-
上下文敏感的詞嵌入(Contextualized Embeddings):
- ELMo、BERT、GPT
- 解決了詞義多義性(Polysemy)問題,能夠根據上下文動態調整詞向量。
Contextualised Word Embedding
Static map 靜態地圖
f trained on large corpus Based on co-occurrence of words

相关文章:
Word Embeddings
Count-based Approach Term-document matrix: Document vectors Two ways to extract information from the matrix: Column-wise: a document is represented by a |V|-dim vector (V: vocabulary) Widely used in information retrieval: find similar documents 查找類似…...

相机开发调中广角和焦距有什么不一样
在相机中,调整广角和调整焦距是两个不同的概念,它们的作用和实现方式也不同。以下是两者的详细对比和解释: 1. 调整广角 定义 广角是指相机的视野范围(Field of View, FOV)。调整广角实际上是调整相机的视野范围。更广的视野意味着可以捕捉到更多的场景内容(更宽的画面)…...
krpano学习笔记,端口修改,krpano二次开发文档,krpano三维div信息展示,krpano热点显示文字
一、修改krpano端口 .\tour_testingserver -port8085 ,修改端口,指定启动时的端口 二、给krpano添加div展示信息 和场景一起转动,不是layer,layer是固定的,没啥用。 主要是onloaded里面的1个方法。 <action name…...

Jenkins 给任务分配 节点(Node)、设置工作空间目录
Jenkins 给任务分配 节点(Node)、设置工作空间目录 创建 Freestyle project 类型 任务 任务配置 Node 打开任务-> Configure-> General 勾选 Restrict where this project can be run Label Expression 填写一个 Node 的 Label,输入有效的 Label名字&#x…...

深入解析iOS视频录制(二):自定义UI的实现
深入解析 iOS 视频录制(一):录制管理核心MWRecordingController 类的设计与实现 深入解析iOS视频录制(二):自定义UI的实现 深入解析 iOS 视频录制(三):完…...

跳表的C语言实现
跳表(Skip List)是一种基于链表的动态数据结构,用于实现高效的查找、插入和删除操作。它通过引入多级索引来加速查找过程,类似于多级索引的有序链表。跳表的平均时间复杂度为 O(logn),在某些场景下可以替代平衡树。 以…...

Java Web开发实战与项目——Spring Security与权限管理实现
Web应用中,权限管理是系统安全的核心部分,确保用户只能访问他们被授权的资源。Spring Security是Spring框架中的一个安全框架,它提供了强大的认证和授权功能,用于实现用户认证和权限控制。本章节将详细讲解如何使用Spring Securit…...

单元测试方法的使用
import java.util.Date; import org.junit.Test; /** java中的JUnit单元测试* * 步骤:* 1.选中当前项目工程 --》 右键:build path --》 add libraries --》 JUnit 4 --》 下一步* 2.创建一个Java类进行单元测试。* 此时的Java类要求:①此类是公共的 ②此类提供一个公共的无参…...
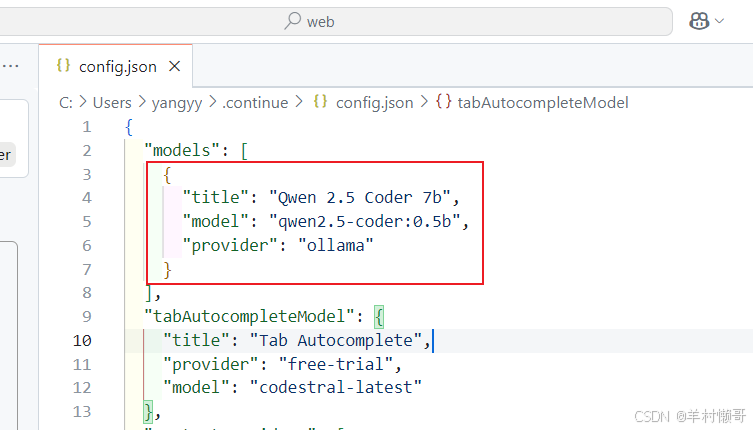
VScode内接入deepseek包过程(本地部署版包会)
目录 1. 首先得有vscode软件 2. 在我们的电脑本地已经部署了ollama,我将以qwen作为实验例子 3. 在vscode上的扩展商店下载continue 4. 下载完成后,依次点击添加模型 5. 在这里可以添加,各种各样的模型,选择我们的ollama 6. 选…...

flink写入hdfs数据如何保证幂等的?
在 Flink 中使用 HDFS Connector 将数据写入 HDFS 时,保证幂等性是一个重要的需求,尤其是在数据可靠性要求较高的场景下。以下是详细介绍如何通过 Flink 和 HDFS 的特性以及一些设计上的优化来实现幂等性。 一、Flink 的 Checkpoint 机制 Flink 的 Chec…...

newgrp docker需要每次刷新问题
每次都需要运行 newgrp docker 的原因: 当用户被添加到 docker 组后,当前会话并不会立即更新组信息,因此需要通过 newgrp docker 切换到新的用户组以使权限生效 如果不想每次都手动运行 newgrp docker,可以在终端中配置一个自动刷新的脚本。…...

LM_Funny-2-01 递推算法:从数学基础到跨学科应用
目录 第一章 递推算法的数学本质 1.1 形式化定义与公理化体系 定理1.1 (完备性条件) 1.2 高阶递推的特征分析 案例:Gauss同余递推4 第二章 工程实现优化技术 2.1 内存压缩的革新方法 滚动窗口策略 分块存储技术 2.2 异构计算加速方案 GPU并行递推 量子计…...
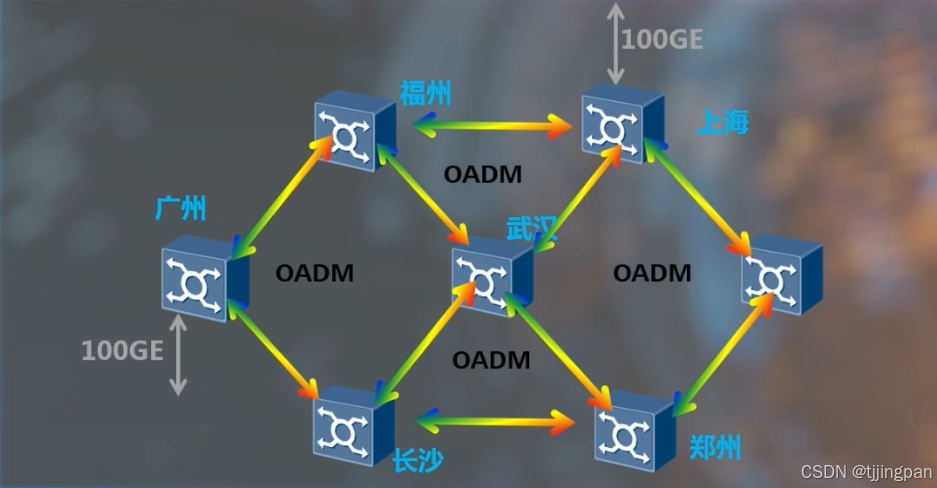
WDM_OTN_基础知识_波分站点与组网类型
为了便于理解,我们用高铁来打个比方,这是郑州与武汉的高铁,中间经过了许昌孝感等很多个站点,郑州武汉作为始发站和终点站,所有人员都是上车或下车,而许昌等中间站点,既有人员上下车,…...

机器视觉--索贝尔滤波
引言 在图像处理领域,边缘检测是一项至关重要的任务,它能够帮助我们识别图像中不同区域的边界,为后续的目标识别、图像分割等操作奠定基础。索贝尔滤波(Sobel Filter)作为一种经典的边缘检测算法,因其简单…...

网络分析仪E5071C的回波损耗测量
回波损耗(Return Loss)是评估射频/微波元件(如滤波器、天线、电缆等)信号反射特性的关键参数,反映端口阻抗匹配性能。E5071C矢量网络分析仪(VNA)通过以下步骤实现高精度回波损耗测量:…...

力扣-二叉树-98 验证二叉搜索树
思路 第一个特性,二叉搜索树的中序遍历是有序的,第二个特性,利用两个指针判断大小关系 代码 class Solution { public:TreeNode* pre NULL;bool isValidBST(TreeNode* root) {if(root NULL) return true;bool left isValidBST(root->…...

【动态规划】详解 0-1背包问题
文章目录 1. 问题引入2. 从 dfs 到动态规划3. 动态规划过程分析4. 二维 dp 的遍历顺序5. 从二维数组到一维数组6. 一维数组的遍历次序7. 背包的遍历顺序8. 代码总结9. 总结 1. 问题引入 0-1 背包是比较经典的动态规划问题,这里以代码随想录里面的例子来介绍下。总的…...

【Java线程池与线程状态】线程池分类与最佳实践
解析Java线程池与线程状态变化,结合运行机制与业务场景对照,帮助形成系统性知识。 一、线程池核心要素(五维模型) 采用「参数配置→处理流程→工作模式」三层递进结构 核心参数(线程池DNA) corePoolSiz…...
多头自注意力机制)
【小白学AI系列】NLP 核心知识点(八)多头自注意力机制
文章目录 **多头自注意力机制(Multi-Head Self-Attention)****核心概念** **1. 自注意力机制(Self-Attention)****2. 多头机制(Multi-Head Attention)****3. 为什么要用多头注意力机制?****4. 公…...

学习笔记——word中图目录、表目录 标题引用
目标1: 建立——图1-1 引用——图1-1 1在word文档中的引用——>插入题注 新建标签,然后命名为“图1-“。 点击确认,即可插入如图所示 图1- 1 春天 需要把图1-和后面那个1中间的空格删除,即 图1-1 春天 2怎么去引用这个“…...

02华夏之光永存・开源:黄大年茶思屋榜文解法「第24期 第2题」 基于自动控制闭环的网络自适应技术专项完整解法
02华夏之光永存・开源:黄大年茶思屋榜文解法「第24期 第2题」 基于自动控制闭环的网络自适应技术专项完整解法 一、摘要 本题归属ADN自动驾驶网络闭环自适应调度领域,全球现代工程技术已触达绝对天花板,现有开环调度框架、流量预测模型、传统…...

战略级开源项目管理平台:OpenProject赋能团队协作的智能化解决方案
战略级开源项目管理平台:OpenProject赋能团队协作的智能化解决方案 【免费下载链接】openproject OpenProject is the leading open source project management software. 项目地址: https://gitcode.com/GitHub_Trending/op/openproject 在数字化转型浪潮中…...

量子计算开发者职业转型五大关键步骤:软件测试从业者的进阶指南
当量子计算从实验室的理论构想,逐步走向金融、医药、能源等产业的应用舞台,软件测试从业者正站在职业转型的关键路口。量子计算带来的不仅是算力革命,更是测试范式的根本性重构——从经典的确定性验证,转向量子世界的概率性、复杂…...

DELL SCv3020存储风扇狂转,别急着换风扇!一个U盘+串口线搞定密码重置和脑裂诊断
DELL SCv3020存储风扇狂转故障排查实战指南 当企业级存储设备突然发出飞机起飞般的噪音,办公室里所有人的目光都会聚焦在IT运维人员身上。DELL SCv3020存储阵列的风扇狂转问题看似是硬件故障,但经验丰富的系统管理员知道,这往往隐藏着更深层次…...

保姆级教程:用Python脚本搞定VisDrone和CARPK数据集,为YOLOv5/8训练做预处理
从零构建YOLO-ready数据集:VisDrone与CARPK预处理实战指南 当无人机视角遇上目标检测算法,数据预处理成为模型效果的第一道门槛。VisDrone和CARPK作为两个典型的航拍数据集,前者包含11类复杂目标与特殊忽略区域,后者则采用绝对坐标…...

基于安卓的美食探店与菜谱分享系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在设计并实现一款基于安卓平台的集成化美食探店与菜谱分享系统以解决当前餐饮信息获取与共享过程中存在的多重问题。随着移动互联网技术的普及及智能手机…...
)
拒绝低效摸索!地球科学数据分析实战指南(Python+Xarray+Dask+机器学习)
模块一Python与地球科学AI编程基础专题一、Python for Earth Science快速入门与AI编程助手1、面向地球科学的Python编程基础(精简回顾,强调数据处理)2、科学计算基础:NumPy、SciPy、Pandas3、数据可视化技术:Matplotli…...

LA7-D3064继电器
LA7-D3064 是施耐德电气 TeSys 系列中的热过载继电器适配器/底座,主要用于与热过载继电器配合,为电机提供过载、断相等保护功能。以下是该模块的15条主要产品特点:中间15条特点:属于施耐德 TeSys Deca 系列,专为电机过…...
:eBPF运行时鉴权 + OCI Artifact签名 + 医疗专用CVE-2024补丁基线)
医疗DevSecOps终极防线(Docker 27合规认证黄金三角模型):eBPF运行时鉴权 + OCI Artifact签名 + 医疗专用CVE-2024补丁基线
更多请点击: https://intelliparadigm.com 第一章:医疗DevSecOps终极防线与Docker 27合规认证黄金三角模型概览 在医疗信息化高速演进的当下,DevSecOps不再仅是效率工具,而是贯穿等保2.0、GDPR、HIPAA及中国《医疗器械软件注册审…...
实现SFTP文件传输的保姆级教程)
告别libssh2!用QT5和QSsh库(Botan分支)实现SFTP文件传输的保姆级教程
告别libssh2!用QT5和QSsh库(Botan分支)实现SFTP文件传输的保姆级教程 在QT项目中实现SFTP文件传输时,开发者通常会面临一个关键选择:是继续使用传统的libssh2库,还是转向更符合QT风格的QSsh库?如…...