Python - 爬虫利器 - BeautifulSoup4常用 API
文章目录
- 前言
- BeautifulSoup4 简介
- 主要特点:
- 安装方式:
- 常用 API
- 1. 创建 BeautifulSoup 对象
- 2. 查找标签
- find(): 返回匹配的第一个元素
- find_all(): 返回所有匹配的元素列表
- select_one() & select(): CSS 选择器
- 3. 访问标签内容
- text 属性: 获取标签内纯文本
- get_text(): 同样作用于获取文本
- attrs 属性: 获取标签的所有属性
- [attribute]: 直接访问某个属性值
- 4. 修改文档
- 添加新标签
- 删除标签
- 替换标签
- 5. 导航树结构
- parent: 上级父节点
- children: 下级子节点迭代器
- siblings: 并列兄弟节点
- 实战小技巧(关键点)
- F12打开控制台
- 复制对应图片的css选择器
- 直接代码中使用
- 结束语
前言
在时光的长河里,每一滴水都是昨日的星辰,映照着永不重复的今天。
BeautifulSoup4 简介
BeautifulSoup4(通常简称为 BS4)是一个用于解析 HTML 和 XML 文档的 Python 库。它的设计目的是简化从复杂网页中提取数据的过程。BeautifulSoup4 可以处理各种各样的标记语言,并提供了一个简单的接口来进行文档导航、搜索和修改。
主要特点:
- 跨平台支持: Beautiful Soup 支持 Windows、Linux、Mac OS X 等多个操作系统。
- 兼容性强: 支持多种解析器,包括 Python 内置的标准库解析器 (
html.parser)、第三方解析器lxml和html5lib。 - 易于学习: 提供了简单且直观的 API,适合初学者使用。
- 强大功能: 包含丰富的函数和方法,可以帮助开发者高效地完成任务。
安装方式:
你可以通过 pip 工具轻松安装 BeautifulSoup4:
pip install beautifulsoup4
常用 API
以下是 BeautifulSoup4 中一些常用的 API 方法和功能:
1. 创建 BeautifulSoup 对象
首先,你需要创建一个 BeautifulSoup 对象来解析 HTML 或 XML 文档。
from bs4 import BeautifulSoup# 使用默认的 html.parser 解析器
html_doc = "<html><head><title>Example Page</title></head><body id='id'><a href='123'></a><p class='my-class child-class'><i>444</i><h1>Hello World</h1></p></body></html>"
soup = BeautifulSoup(html_doc, 'html.parser')# 打印解析后的结果
print(soup.prettify())
2. 查找标签
可以通过标签名称或其他属性来查找特定的元素。
find(): 返回匹配的第一个元素
first_paragraph = soup.find('p')
print(first_paragraph) # 输出: <p>Hello World</p>
find_all(): 返回所有匹配的元素列表
all_headings = soup.find_all(['h1', 'h2'])
for heading in all_headings:print(heading.text)
select_one() & select(): CSS 选择器
css_selector_example = soup.select_one('.my-class')
print(css_selector_example)css_selectors_examples = soup.select('#id > .child-class')
for element in css_selectors_examples:print(element.text)
3. 访问标签内容
访问标签内的文本和其他属性。
text 属性: 获取标签内纯文本
text_content = first_paragraph.text
print(text_content) # 输出: Hello World
get_text(): 同样作用于获取文本
get_text_content = first_paragraph.get_text()
print(get_text_content) # 输出: Hello World
attrs 属性: 获取标签的所有属性
attributes = first_paragraph.attrs
print(attributes) # 如果没有其他属性,则为空字典 {}
[attribute]: 直接访问某个属性值
link_tag = soup.a
href_value = link_tag['href']
print(href_value)
4. 修改文档
除了查询外,还可以动态地添加、删除或修改文档中的节点。
添加新标签
new_tag = soup.new_tag("b")
new_tag.string = "Bold Text"
first_paragraph.append(new_tag)
print(first_paragraph) # 输出: <p>Hello World<b>Bold Text</b></p>
删除标签
tag_to_remove = soup.b
tag_to_remove.decompose()
print(first_paragraph) # 输出: <p>Hello World</p>
替换标签
replacement_tag = soup.new_tag("i")
replacement_tag.string = "Italic Text"
first_paragraph.i.replace_with(replacement_tag)
print(first_paragraph) # 输出: <p>Hello World<i>Italic Text</i></p>
5. 导航树结构
BeautifulSoup 还提供了多种方法来遍历和操作 DOM 树。
parent: 上级父节点
parent_node = first_paragraph.parent
print(parent_node.name) # 输出: body
children: 下级子节点迭代器
children_nodes = list(first_paragraph.children)
for child in children_nodes:print(child)
siblings: 并列兄弟节点
next_sibling = first_paragraph.next_sibling
previous_sibling = first_paragraph.previous_sibling
print(next_sibling)
print(previous_sibling)
实战小技巧(关键点)
实际情况下,很多节点不好找到,可以利用浏览器功能,可以直接复制css选择器
F12打开控制台

复制对应图片的css选择器

直接代码中使用
from bs4 import BeautifulSoup# 使用默认的 html.parser 解析器
html_doc = "<html></html>"
soup = BeautifulSoup(html_doc, 'html.parser')
# 只是为了示例 不可运行 以下是复制出来的内容
soup.select('#ice-container > div.tbpc-layout > div.screen-outer.clearfix > div.main > div.core.J_Core > div > div:nth-child(1) > div:nth-child(1) > div > div > div > div > div:nth-child(3) > div > div > a')
结束语
文章中API都验证过,可直接运行👽👽👽
运行有问题可联系作者评论交流🤭🤭🤭
风是自由的,你也是自由🤠🤠🤠
欢迎一起交流学习☠️☠️☠️
有帮助请留下足迹 一键三连🥰🥰🥰
爬虫大佬勿喷,欢迎指正问题😈😈😈
后面会做一系列的爬虫文章,请持续关注作者🤡🤡🤡。
相关文章:
Python - 爬虫利器 - BeautifulSoup4常用 API
文章目录 前言BeautifulSoup4 简介主要特点:安装方式: 常用 API1. 创建 BeautifulSoup 对象2. 查找标签find(): 返回匹配的第一个元素find_all(): 返回所有匹配的元素列表select_one() & select(): CSS 选择器 3. 访问标签内容text 属性: 获取标签内纯文本get_t…...

宝塔面板开始ssl后,使用域名访问不了后台管理
宝塔面板后台开启ssl访问后,用的证书是其他第三方颁发的证书 再使用 域名/xxx 的形式:https://域名:xxx/xxx 访问后台,结果出现如下,不管使用 http 还是 https 的路径访问都进不后台管理 这个时候可以使用 https://ip/xxx 的方式来…...
)
大一计算机的自学总结:前缀树(字典树、Trie树)
前言 前缀树,又称字典树,Trie树,是一种方便查找前缀信息的数据结构。 一、字典树的实现 1.类描述实现 #include <bits/stdc.h> using namespace std;class TrieNode { public:int pass0;int end0;TrieNode* nexts[26]{NULL}; };Tri…...

docker 安装的open-webui链接ollama出现网络错误
# 故事背景 部署完ollama以后,使用谷歌浏览器的插件Page Assist - 本地 AI 模型的 Web UI 可以比较流畅的使用DeepSeek,但是只局限于个人使用,想分享给更多的小伙伴使用,于是打算使用open-webui 来管理用户,经官网推荐…...

未来游戏:当人工智能重构虚拟世界的底层逻辑
未来游戏:当人工智能重构虚拟世界的底层逻辑 在《赛博朋克2077》夜之城的霓虹灯下,玩家或许已经注意到酒吧里NPC开始出现微表情变化;在《艾尔登法环》的开放世界中,敌人的战术包抄逐渐显露出类人智慧。这些细节预示着游戏产业正站…...

Redis集群主从切换源码解读
一切的开始 打开Redis5.0.5的源码中server.c,找到如下代码,这里运行了一个定时任务,每隔100毫秒执行一次。 /* Run the Redis Cluster cron. *//** 每隔100毫秒执行一次* 要求开启集群模式*/run_with_period(100) {if (server.cluster_enabl…...

javacv将mp4视频切分为m3u8视频并播放
学习链接 ffmpeg-demo 当前对应的 gitee代码 Spring boot视频播放(解决MP4大文件无法播放),整合ffmpeg,用m3u8切片播放。 springboot 通过javaCV 实现mp4转m3u8 上传oss 如何保护会员或付费视频?优酷是怎么做的? - HLS 流媒体加密 ffmpe…...

Golang学习笔记_33——桥接模式
Golang学习笔记_30——建造者模式 Golang学习笔记_31——原型模式 Golang学习笔记_32——适配器模式 文章目录 桥接模式详解一、桥接模式核心概念1. 定义2. 解决的问题3. 核心角色4. 类图 二、桥接模式的特点三、适用场景1. 多维度变化2. 跨平台开发3. 动态切换实现 四、与其他…...

蜂鸟视图发布AI智能导购产品:用生成式AI重构空间服务新范式
在人工智能技术飞速发展的今天,北京蜂鸟视图正式宣布推出基于深度求索(DeepSeek)等大模型的《AI智能导购产品》,通过生成式AI与室内三维地图的深度融合,重新定义空间场景的智能服务体验。 这一创新产品将率先应用于购物…...

AI服务器散热黑科技:让芯片“冷静”提速
AI 服务器为何需要散热黑科技 在人工智能飞速发展的当下,AI 服务器作为核心支撑,作用重大。从互联网智能推荐,到医疗疾病诊断辅助,从金融风险预测,到教育个性化学习,AI 服务器广泛应用,为各类复…...

数据结构-栈、队列、哈希表
1栈 1.栈的概念 1.1栈:在表尾插入和删除操作受限的线性表 1.2栈逻辑结构: 线性结构(一对一) 1.3栈的存储结构:顺序存储(顺序栈)、链表存储(链栈) 1.4栈的特点: 先进后出(fisrt in last out FILO表),后进先出 //创建栈 Stacklist create_stack() {Stacklist lis…...

安装海康威视相机SDK后,catkin_make其他项目时,出现“libusb_set_option”错误的解决方法
硬件:雷神MIX G139H047LD 工控机 系统:ubuntu20.04 之前运行某项目时,处于正常状态。后来由于要使用海康威视工业相机(型号:MV-CA013-21UC),便下载了并安装了该相机的SDK,之后运行…...
【鸿蒙】ArkUI-X跨平台问题集锦
系列文章目录 【鸿蒙】ArkUI-X跨平台问题集锦 文章目录 系列文章目录前言问题集锦1、HSP,HAR模块中 无法引入import bridge from arkui-x.bridge;2、CustomDialog 自定义弹窗中的点击事件在Android 中无任何响应;3、调用 buildRouterMode() 路由跳转页面前…...

大模型驱动的业务自动化
大模型输出token的速度太低且为统计输出,所以目前大模型主要应用在toP(人)的相关领域;但其智能方面的优势又是如此的强大,自然就需要尝试如何将其应用到更加广泛的toM(物理系统、生产系统)领域中…...

ocr智能票据识别系统|自动化票据识别集成方案
在企业日常运营中,对大量票据实现数字化管理是一项耗时且容易出错的任务。随着技术的进步,OCR(光学字符识别)智能票据识别系统的出现为企业提供了一个高效、准确的解决方案,不仅简化了财务流程,还大幅提升了…...

[数据结构]红黑树,详细图解插入
目录 一、红黑树的概念 二、红黑树的性质 三、红黑树节点的定义 四、红黑树的插入(步骤) 1.为什么新插入的节点必须给红色? 2、插入红色节点后,判定红黑树性质是否被破坏 五、插入出现连续红节点情况分析图解(看…...

【机器学习】超参数调优指南:交叉验证,网格搜索,混淆矩阵——基于鸢尾花与数字识别案例的深度解析
一、前言:为何要学交叉验证与网格搜索? 大家好!在机器学习的道路上,我们经常面临一个难题:模型调参。比如在 KNN 算法中,选择多少个邻居(n_neighbors)直接影响预测效果。 • 蛮力猜…...

Burp Suite基本使用(web安全)
工具介绍 在网络安全的领域,你是否听说过抓包,挖掘漏洞等一系列的词汇,这篇文章将带你了解漏洞挖掘的热门工具——Burp Suite的使用。 Burp Suite是一款由PortSwigger Web Security公司开发的集成化Web应用安全检测工具,它主要用于…...
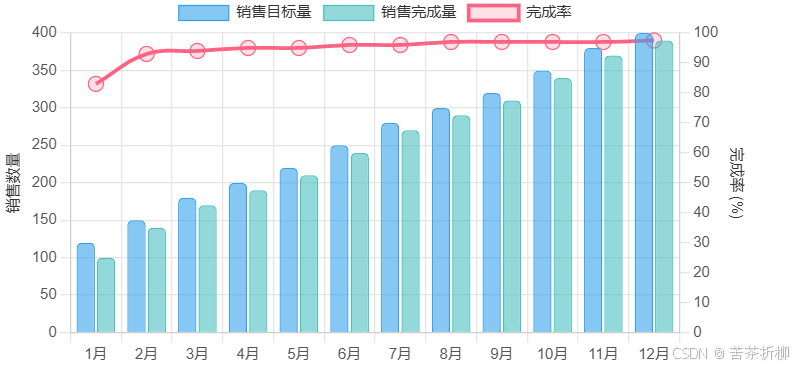
React实现自定义图表(线状+柱状)
要使用 React 绘制一个结合线状图和柱状图的图表,你可以使用 react-chartjs-2 库,它是基于 Chart.js 的 React 封装。以下是一个示例代码,展示如何实现这个需求: 1. 安装依赖 首先,你需要安装 react-chartjs-2 和 ch…...

从低清到4K的魔法:FlashVideo突破高分辨率视频生成计算瓶颈(港大港中文字节)
论文链接:https://arxiv.org/pdf/2502.05179 项目链接:https://github.com/FoundationVision/FlashVideo 亮点直击 提出了 FlashVideo,一种将视频生成解耦为两个目标的方法:提示匹配度和视觉质量。通过在两个阶段分别调整模型规模…...
)
别再折腾了!Windows 11下STM32开发环境一站式搭建指南(MDK5.38 + DAP/ST-Link + CH340)
Windows 11下零痛感STM32开发环境全栈配置手册 刚拿到STM32开发板的新手开发者,往往会在环境搭建阶段经历各种"玄学问题":MDK版本兼容性报错、仿真器驱动冲突、串口识别异常...这些看似简单的准备工作,实际可能消耗数天时间。本文将…...

视觉创作实战:从创意构思到成品输出的实操全指南
当前数字内容传播场景中,视觉内容的信息传递效率是纯文字的6倍以上。不管是电商运营做商品主图,技术博主做专栏封面,还是企业市场做活动海报,都需要具备基础的视觉创作能力。多数非专业创作者的卡点,往往不是没有创意&…...

Windows+CUDA 12.2+Anaconda环境:手把手教你从创建虚拟环境到成功验证PyTorch安装
Windows系统下CUDA 12.2与PyTorch环境配置全指南 在深度学习项目开发中,环境配置往往是第一个拦路虎。特别是当硬件与软件版本不匹配时,新手很容易陷入无休止的依赖冲突和安装失败循环。本文将带你完整走通Windows 11系统下CUDA 12.2与PyTorch的环境配置…...

MarkdownView高级特性探索:链接处理、渲染回调与滚动控制
MarkdownView高级特性探索:链接处理、渲染回调与滚动控制 【免费下载链接】MarkdownView Markdown View for iOS. 项目地址: https://gitcode.com/gh_mirrors/ma/MarkdownView MarkdownView是一款专为iOS平台设计的高效Markdown渲染组件,它不仅提…...

开源色彩管理革命:OpenColorIO配置为ACES的终极指南
开源色彩管理革命:OpenColorIO配置为ACES的终极指南 【免费下载链接】OpenColorIO-Config-ACES 项目地址: https://gitcode.com/gh_mirrors/op/OpenColorIO-Config-ACES 在数字内容创作领域,色彩一致性是专业制作的生命线。OpenColorIO配置为ACE…...

Tidyverse 2.0自动化报告不是“升级”,而是范式革命:基于17个CRAN包依赖图谱与38家上市公司落地数据实证
更多请点击: https://intelliparadigm.com 第一章:Tidyverse 2.0自动化报告的范式革命本质 Tidyverse 2.0 并非简单版本迭代,而是以“声明式报告流水线”取代“命令式脚本拼接”的范式跃迁。其核心在于将数据获取、转换、可视化与文档生成统…...

月饼机排名:企业选购选型关键策略深度解析
月饼机排名与企业选购选型全攻略:高频疑问解答,选对设备少走弯路"月饼机排名≠选购唯一标准,企业选型更需结合生产需求与设备适配性" 很多企业在选购月饼机时,容易陷入排名误区,忽略实际生产场景的匹配&…...

到底什么资格,才算真正的资深 Java 开发专家
目录 前言 一、破除认知误区:绝大多数 Java 开发者,达不到资深专家门槛 1.1 初级 / 中级 / 高级 / 资深专家 核心能力差异 1.2 伪「资深 Java」典型特征 二、核心资质一:夯实底层根基,吃透 Java 基础与 JVM 底层原理 2.1 高…...

论文图表不用愁,Paperxie 科研绘图一键搞定
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/科研绘图https://www.paperxie.cn/drawinghttps://www.paperxie.cn/drawing 写毕业论文时,最磨人的环节之一,大概就是绘制图表了。对着 Excel 反复调整数据格式,用 Visio…...

避坑指南:STM32H7的SD卡虚拟U盘项目,为什么加了FreeRTOS后USB读写就挂了?
STM32H7虚拟U盘开发实战:FreeRTOS环境下USB与SD卡协同设计精要 在嵌入式存储解决方案中,将SD卡通过USB接口模拟为U盘是常见需求。当项目从裸机迁移到FreeRTOS环境时,原本稳定的USB大容量存储类(MSC)功能可能突然失效—…...