C++通用算法
1.概述
根据名字就知道如何使用相关算法,比如copy函数,就是复制的意思,它需要一个范围,以及要复制的位置
copy(begin, end, container_begin);
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;int main(int argc, char** argv) {
vector<int> data(10);//创建一个大小为10的向量
cout << data.capacity() << endl;
int arr[10] = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
copy(begin(arr), end(arr), data.begin());//copy(起点,终点,容器开头);
for(auto it : data){
cout << it << " ";
}
cout << endl;
return 0;
}copy函数需要容器的起点,这样就要求我们提前设定容器的大小,比如上面的代码,设定了容器的大小为10,有时候我们并知道需要copy多少数据,所以
我们可以使用back_inserter(),这个函数返回一个特殊的迭代器,插入的时候,容器会自动扩大,插入到前面数据的后面
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;
int main(int argc, char** argv) {
vector<int> data;
int d[] = {1,2,3,4,5,6,7,8,9,10};
copy(begin(d), end(d), back_inserter(data));
for(int i : d){
cout << i << endl;
}
return 0;
}(1)判定函数
很多算法需要一个返回bool类型的函数,根据函数来自定义算法的工作过程,比如:
remove_copy_if(),除了限定范围,还要指定函数,返回为false的数据会被复制
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;
bool compare(int x){
return x > 6;
}
int main(int argc, char** argv) {
vector<int> data;
int d[] = {1,2,3,4,5,6,7,8,9,10};
remove_copy_if(begin(d), end(d), back_inserter(data), compare);//复制小于6的数据
for(int i : data){
cout << i << endl;
}
return 0;
}类似的还有replace_copy_if(起点,终点,容器起点,函数,替代数据)
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;
bool compare(int x){
return x > 6;
}
int main(int argc, char** argv) {
vector<int> data;
int d[] = {1,2,3,4,5,6,7,8,9,10};
replace_copy_if(begin(d), end(d), back_inserter(data), compare, 10);
for(int i : data){
cout << i << endl;
}
return 0;
}而replace_if则是改变原始的数据,而不是输出到新的容器
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;
bool compare(int x){
return x > 6;
}
int main(int argc, char** argv) {
vector<int> data;
int d[] = {1,2,3,4,5,6,7,8,9,10};
replace_if(begin(d), end(d),compare, 10);
for(int i : d){
cout << i << endl;
}
return 0;
}(2)流迭代器
流迭代器把数据当作流进行操作
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
using namespace std;
bool compare(int x){return x > 6;
}
int main(int argc, char** argv)
{vector<int> data;int d[] = {1,2,3,4,5,6,7,8,9,10};copy(begin(d), end(d), ostream_iterator<int>(cout,"\n"));//直接输出到coutreturn 0;
}输出流迭代器重载拷贝-复制操作符,该重载操作符向相应的流写入数据,当然我们也可以使用其他的流来操作数据
比如输入流来操作输入数据到某个容器或者相应的流.
2.函数对象
有时候需要根据对象调用函数,以对象名作为函数进行调用,这样做的好处是,对于需要多个参数才能实现的功能,可以通过函数对象实现
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
#include<fstream>
using namespace std;
class MyFunction{
private:
int value;
public:
MyFunction(int i):value(i){}
bool operator()(int x){
return x > value;
}
};
int main(int argc, char** argv){
int arr[] = {1,2,3,4,5,6,7,8,9,10};
vector<int> data;
MyFunction fun(5);//函数对象
remove_copy_if(begin(arr), end(arr), back_inserter(data), fun);//复制小于等于5的数据
for(int i : data){
cout << i << " ";
}
}2.1自动创建函数对象
头文件<functional>定义了大量的通用的函数对象,其中函数对象适配器可以调整函数对象。
比如greater是一个二元函数对象,也就是有两个参数,当第一个参数大于第二个参数时返回true,从greater重写上面的程序,还不够,需要函数
对象适配器调整参数,这里使用bind2nd,可以调整greater函数的第二个参数
#include <iostream>
#include<vector>
#include<algorithm>
#include<iterator>
#include<fstream>
using namespace std;
int main(int argc, char** argv){int arr[] = {1,2,3,4,5,6,7,8,9,10};vector<int> data;remove_copy_if(begin(arr), end(arr), back_inserter(data), bind2nd(greater<int>(),5));for(int i : data){cout << i << " ";}return 0;
}bind2nd创建一个binder2nd函数对象,这个对象储存和传递两个参数给bind2nd,第一个参数是二元函数或者函数对象。这里的函数不能任意定义,必须是
按照一种特殊的形式来定义。
int arr[] = {1,1,1,4,5,6,7,8,9,10};
vector<int> data;
greater<int> g;
auto b = bind2nd(g, 5);
cout << count_if(begin(arr), end(arr), b) << endl;equal_to是一个标准二元函数对象
not1是一个函数对象适配器,它对一元函数对象的值进行设置
C++提供了许多函数对象,比如加减乘除,取余,大于,小于,不等于,等等
2.2 可调整的函数对象
在前面,我们介绍了函数适配器,用来调整函数对象的值,之所以可以调整,是因为他们使用了一套公用的规则,
比如bind2nd就需要知道函数对象的参数类型和返回类型,使用bind2nd来操作自定义的函数对象,除非自定义的对象使用C++约定的规则,否则无法成功
对于一元函数对象,类型名是argument_type和result_type,
对于二元函数对象,类型名是first_argumen_type和second_argument_type和result_type
bind1st的重载函数定义如下:
typename Op::result_type operator()(const typename Op::second_argument_type& x) const
为这些类提供类型名的函数对象被称为可调整的函数对象
C++提供了两个类来提供这些类型,程序员自定义的函数对象通过继承的方式,可以使用这些类型,这两个类分别是
unary_function和binary_function
unary_function的定义:
template<class arg, class Result>
struct unary_function{
typedef Arg argument_type;
typedef Result result_type;
};
binary_function的定义类似,不过变成了first_argumen_type和second_argument_type和result_type
2.3 函数指针适配器
函数可以通过函数名来调用,但是有很大的局限性。有时候需要函数指针来调用函数,这是可能用到函数指针适配器,它可以把函数指针转化为函数对象
ptr_fun就是函数指针适配器,但是它只能封装一元函数或者二元函数
它的定义如下:
template<class Arg, class Result>
pointer_to_unary_function<Arg, Result>
ptr_fun(Result (*fptr)(Arg){
return pointer_to_unary_function<Arg, Result>(fptr);
}
函数模板可以推测出函数的返回值类型和函数的参数类型,然后返回一个函数对象
而pointer_to_unary_function是一个函数对象,其定义如下:
template<class Arg, class Result>
class pointer_to_unary_function: public unary_function<Arg, Result>{
Result (*fptr)(Arg);//储存函数
public:
pointer_to_unary_function(Result (*x)(Arg) : fptr(x){}
Result operator()(Arg x)const{
return fptr;
}
};
结合上面两份代码可知,ptr_fun通过接受一个函数,推测出函数的类型,然后生成一个pointer_to_unary_function函数对象,调用对象函数
使用这种方法调用函数有一个缺陷,就是可能会产生二义性,比如函数重载了,此刻就需要模板特化
使用例子:
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
using namespace std;
int isEven(int a){return a % 2 == 0;
}
int main(int argc, char** argv) {int arr[] = {1,2,3,4,5,6,7,8,9,10};vector<int>buf;transform(begin(arr), end(arr), back_inserter(buf), ptr_fun(isEven));for(int i : buf){cout << i << endl;}return 0;
}for_each函数:for_each(起点,终点,操作);这个函数把一段序列的对象调用到操作上,这个操作可以自定义。
比如输出一个数组
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
using namespace std;
void print(int a){
cout << a << endl;
}
int main(int argc, char** argv)
{int arr[] = {1,2,3,4,5,6,7,8,9,10};ostream_iterator<int> out(cout, " ");for_each(begin(arr), end(arr), print);return 0;
}我们也可以通过这个方法来实现多态,通过mem_fun函数实现
另外还有mem_fun_ref。
他们之间不同点在于,mem_fun需要对象是指针,而mem_fun_ref需要对象是普通对象
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
using namespace std;
class Base{
public:virtual void print() = 0;virtual ~Base(){}
};class One:virtual public Base{
public:
void print(){cout << "One" << endl;
}
};class Two: virtual public Base{
public:void print(){cout << "Two" << endl;}
};int main(int argc, char** argv)
{vector<Base*> vs;vs.push_back(new One);vs.push_back(new Two);for_each(begin(vs), end(vs), mem_fun(Base::print));//输出 One Two for(Base* i : vs){delete i;}return 0;
}下面作为对比
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
using namespace std;
class Angle{int value;public:Angle(int v): value(v){}void print(){cout << value << endl;}
};
int main(int argc, char** argv) {vector<Angle*> va;for(int i = 0; i < 5; i++){va.push_back(new Angle(i));}for_each(begin(va), end(va), mem_fun(Angle::print));//输出 One Two return 0;
}transform函数,起点到终点的序列,调用第四个参数的函数,保存在第三个参数,这个参数一般是序列的首地址
generate函数,让起点到终点的序列调用第三个参数的函数,并且把结果保存在序列中
2.4 编写自己的函数对象适配器
下面我们写一个程序,自动生成一个字符串序列,然后在主函数中转化为小数
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
#include<ctime>
#include<cstdlib>
#include<string>
using namespace std; //生成一个随机的数字字符串
class NumStringGen{const int sz;
public:NumStringGen(int ssz): sz(ssz){}string operator()(){string digits("0123456789");const int ndigits = digits.size();string r(sz,' ');r[0] = digits[rand()% (ndigits - 1)] + 1; for(int i = 0; i < sz; ++i){if(sz >= 3 && i == sz/2)r[i] = '.';elser[i] = digits[rand() % ndigits];}return r;}}; //输出整个序列
template<class Iter>
void print(Iter first, Iter last, const char* nm = "",const char* sep = "\n",ostream& os = cout){if(nm != 0 && *nm != '\0')os << nm << ": " << sep;typedef typename iterator_traits<Iter>::value_type T;copy(first, last, ostream_iterator<T>(cout, sep));os << endl;
} int main(int argc, char** argv) {const int sz = 9;vector<string> vs(sz);srand(time(0));NumStringGen fun(sz);//生成字符串,结果添加到vs generate(begin(vs), end(vs), fun);//生成
// print(vs.begin(), vs.end());//输出生成的函数 const char* vcp[sz];transform(vs.begin(), vs.end(), vcp, mem_fun_ref(string::c_str)); print(begin(vcp), end(vcp));//将字符换转化为小数vector<double> vd;transform(begin(vcp), end(vcp), back_inserter(vd), atof);print(begin(vd), end(vd));return 0;
}
//我们选生成了对应的字符串序列,然后再转化为数字,这里我们可以把两个操作合二为一
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
#include<ctime>
#include<cstdlib>
#include<string>
using namespace std; //生成一个随机的数字字符串
class NumStringGen{const int sz;
public:NumStringGen(int ssz): sz(ssz){}string operator()(){string digits("0123456789");const int ndigits = digits.size();string r(sz,' ');r[0] = digits[rand()% (ndigits - 1)] + 1; for(int i = 0; i < sz; ++i){if(sz >= 3 && i == sz/2)r[i] = '.';elser[i] = digits[rand() % ndigits];}return r;}}; //输出整个序列
template<class Iter>
void print(Iter first, Iter last, const char* nm = "",const char* sep = "\n",ostream& os = cout){if(nm != 0 && *nm != '\0')os << nm << ": " << sep;typedef typename iterator_traits<Iter>::value_type T;copy(first, last, ostream_iterator<T>(cout, sep));os << endl;
} //R是返回值的参数类型,E是函数形参类型
template<class R, class E, class F1, class F2>
class unary_composer{F1 f1;F2 f2;
public:unary_composer(F1 fone, F2 ftwo): f1(fone), f2(ftwo){}R operator()(E x){return f1(f2(x));}
};//函数适配器,根据生成一个函数对象,然后在对象中调用对象的函数重载
template<class R, class E, class F1, class F2>
unary_composer<R, E, F1, F2> compose(F1 f1, F2 f2){return unary_composer<R, E, F1, F2>(f1, f2);
}int main(){double x = compose<double, const string&>(atof, mem_fun_ref(&string::c_str))("12.34");cout << x << endl;
}总结ptr_fun,mem_fun,mem_fun_ref
ptr_fun针对普通函数 fun()
mem_fun针对成员函数,但是需要指针调用 p->fun()
mem_fun_ref针对成员函数,但是不需要指针调用p.fun()
下面的代码对上面的代码进行了简单化,不需要那么多的类型推断
#include <iostream>
#include<algorithm>
#include<iterator>
#include<vector>
#include<functional>
#include<ctime>
#include<cstdlib>
#include<string>
using namespace std; //生成一个随机的数字字符串
class NumStringGen{const int sz;
public:NumStringGen(int ssz): sz(ssz){}string operator()(){string digits("0123456789");const int ndigits = digits.size();string r(sz,' ');r[0] = digits[rand()% (ndigits - 1)] + 1; for(int i = 0; i < sz; ++i){if(sz >= 3 && i == sz/2)r[i] = '.';elser[i] = digits[rand() % ndigits];}return r;}
}; //输出整个序列
template<class Iter>
void print(Iter first, Iter last, const char* nm = "",const char* sep = "\n",ostream& os = cout){if(nm != 0 && *nm != '\0')os << nm << ": " << sep;typedef typename iterator_traits<Iter>::value_type T;copy(first, last, ostream_iterator<T>(cout, sep));os << endl;
} //使用继承的方式,自动推断参数的类型
template<typename F1, typename F2>
class unary_composer: public unary_function<typename F2::argument_type, typename F1::result_type >
{F1 f1;F2 f2;
public:unary_composer(F1 fone, F2 ftwo): f1(fone), f2(ftwo){}typename F1::result_type operator()(typename F2::argument_type x){return f1(f2(x));}
};//函数适配器,根据生成一个函数对象,然后在对象中调用对象的函数重载
template<class F1, class F2>
unary_composer<F1, F2> compose(F1 f1, F2 f2){return unary_composer<F1, F2>(f1, f2);
}int main(){const int sz = 9;vector<string> vs(sz);srand(time(0));NumStringGen fun(sz);//生成字符串,结果添加到vs generate(begin(vs), end(vs), fun);//生成
// print(vs.begin(), vs.end());//输出生成的函数 //将字符换转化为小数vector<double> vd;transform(begin(vs), end(vs), back_inserter(vd), compose(ptr_fun(atof), mem_fun_ref(&string::c_str)));print(begin(vd), end(vd));return 0;
}
总结函数对象适配器:
bind1st对函数的第一个参数设置
bind2nd对函数的第二个参数设置
使用的方式与自定义的一样,都是生成一个函数对象,然后调用重载函数
3.STL算法简介
3.1 迭代器
(1)InputIterator 输入迭代器,可以使用++和*来前向移动,也可以使用==和!=来判断位置
(2)OutputIterator 输出迭代器,可以++和*来前向迭代,但是不能使用==和!=,这是因为输入迭代器没有判断末尾的标志,这个经常配合back_inserter一起使用,back_inserter的返回类型就是这个
(3)ForwardIterator 前面两个迭代器只能单独写入或者输出,这个迭代器可以同时读写,而且可以使用==和!=还要++和*来进行迭代,不过这个是前向迭代器,只能++
(4)BidirectionaIterator是一个支持--的ForwordIterator
(5)RandomAccessIterator支持一切普通指针的所有操作
3.2 填充和生成
这些算法能够自动用一个值来填充容器
(1) void fill(ForwardIterator first, ForwardIterator last, const T& value);
容器开头和结尾被指定函数对象填充
(2)void file_n(ForwardIterator first, Size n,const T& value);
容器从开头到第n容器被指定函数对象填充
(3)void generate(ForwardIterator first, ForwardIterator last, Generator gen)
容器的对象挨个调用生成器,将结果保存在容器的对象中
(4)void generate_n(ForwardIterator first, Size n, Generator gen);
3.3计数
(1)IntergralValue count(InputIterator first, OutputIterator last, const EqualityComparable& value);
计算first到last等于value的数量
(2)IntergralValue count_if(InputIterator first, OutputIterator last,Predicate pred);
返回能使pred返回true的元素的个数
3.4操作序列
(1)OutputIterator copy(InputIterator first, InputIterator last, OutputIterator destination);
使用赋值,从first到last复制序列到 destination
(2) BidirectionaIterator2 copy_backward(BidirectionaIterator1 first, BidirectionaIterator1 last, BidirectionaIterator2 destinationEnd);
和copy函数一样,但是这个操作是以相反的顺序复制元素,destinationEnd是容器的末尾迭代器,容器必须有足够的空间
int buf[] = {1,2,3,4,5,6,7,8,9,10};vector<int> v(10); copy_backward(begin(buf), end(buf), v.end());print(v.begin(), v.end(),"V"," ");cout << endl;输出 1 2 3 4 5 6 7 8 9 10
但是,它是从10开始复制倒1
(3)void reverse(BidirectionaIterator first, BidirectionaIterator last);
反转原序列
(4)BidirectionaIterator reverse_copy(BidirectionaIterator first, BidirectionaIterator last, OutputIterator destination);
复制反转序列到 destination
int main(){
int buf[] = {1,2,3,4,5,6,7,8,9,10};
vector<int> v(10);
reverse_copy(begin(buf), end(buf), v.begin());
print(v.begin(), v.end(),""," ");//输出10 9 8 7 6 5 4 3 2 1
return 0;
}(5)ForwardIterator2 swap_ranges(ForwardIterator1 first, ForwardIterator1 last, ForwardIterator2 first2);
交换first和last范围内的元素
int main(){int buf[] = {1,2,3,4,5,6,7,8,9,10};vector<int> v(10);swap_ranges(begin(buf), end(buf), v.begin());print(v.begin(), v.end(),"V"," ");//输出1 2 3 4 5 6 7 8 9 10cout << endl;print(begin(buf), end(buf), "buf", " ");//输出 0 0 0 0 0 0 0 0 0 cout << endl;
return 0;
}(6)void rorate(ForwardIterator first, ForwardIterator middle, ForwardIterator last);
将first到middle的序列放在last后面
vector<int> v({1,2,3,4,5,6,7,8,9,10});vector<int>::iterator it = v.begin();
it += 2;
rotate(begin(v), it, end(v));
print(v.begin(), v.end(),"V"," ");//输出3 4 5 6 7 8 9 10 1 2
cout << endl;(7)OutputIterator rotate_copy(ForwardIterator first, ForwardIterator middle, ForwardIterator last, OutputIterator destination);
作用和上面一样,只不过是把结果复制到 destination
int buf[] = {1,2,3,4,5,6,7,8,9,10};
vector<int> v1;
copy(begin(buf), end(buf), back_inserter(v1));
print(v1.begin(), v1.end(),"v1"," ");//输出1 2 3 4 5 6 7 8 9 10
vector<int>::iterator it = begin(v1);
it += 4;
vector<int> v2(10);
rotate_copy(begin(v1),it,end(v1),v2.begin());
print(v1.begin(),v1.end(),"v1"," ");//输出 1 2 3 4 5 6 7 8 9 10
print(v2.begin(),v2.end(),"v2"," ");//输出 5 6 7 8 9 10 1 2 3 4
cout << endl;下面的四个算法是排列,元素有n个,则结果有n!个组合
(8).bool next_permutation(BidirectionaIterator first, BidirectionaIterator last);
int buf[] = {1,2,3,4};
int num = 4 * 3 * 2 * 1;
for(int i = 0; i < num; i++){
next_permutation(begin(buf), end(buf));
cout << "i = " << i+1 << " ";
print(begin(buf),end(buf),"buf"," ");
}输出24种排列,而且是以升序的方式输出
(9).bool next_permutation(BidirectionaIterator first, BidirectionaIterator last, StrictWeakOrdering binary_pred);
按照上面的是自定义的大于号运算,但是也可以用binary_pred定义,这是一个自定义的函数对象,比如可以设定为greater
(10)bool prev_permutation(BidirectionaIterator first, BidirectionaIterator last);
(11)bool prev_permutation(BidirectionaIterator first, BidirectionaIterator last, StrictWeakOrdering binary_pred);
上面四种算法其实没啥区别,第一个是升序排列,第三个是降序排列,第二,四是按照自定义的函数对象要求排列
返回值要看是否有各自的前驱或者后驱,如果没用则返回false,一般来讲是因为排列结束了才会返回false
下面两种是随机排列
(12)void random_shuffle(RandAccessIterator first, RandAccessIterator end);
使用默认的随机发生器,它会产生均匀分布的结果
int buf[] = {1,2,3,4};
for(int i = 0; i < 5; i++){
random_shuffle(begin(buf), end(buf));
print(begin(buf), end(buf),""," ");//输出的排列会被打乱
}(13)void random_shuffle(RandAccessIterator first, RandAccessIterator end,Predicate pred)
使用用户自定义的函数对象
下面两个是划分
(14).BidirectionaIterator partition(BidirectionaIterator frist, BidirectionaIterator last, predicate pred);
序列会按照函数对象pred的要求排列,序列元素满足pred要求的排在前面,不满足的排列在后面,但是原本的相对位置可能会变化,下面的函数在实现划分规则的同时,相对位置也不会变化
函数的返回值是划分位置,这个位置前面全都满足pred的要求
int buf[] = {1,2,3,4,5,6,7,8,9,10};
print(begin(buf),end(buf),""," ");
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));
vector<int>::iterator it = partition(begin(v), end(v), bind2nd(greater<int>(),6));
cout << "分界线:" << *it << endl;
print(v.begin(), v.end(), "", " ");
return 0;(15).BidirectionaIterator stable_partition(BidirectionaIterator frist, BidirectionaIterator last, predicate pred);
操作序列有复制,划分,排列组合,交换,颠倒。
3.5 查找与替换
(1) InputIterator find(InputIterator first, InputIterator last, cons EqualityComparable& value);
查找在first到last范围内等于value 的元素,返回第一个等于value的位置,如果不存在则返回last的位置,这是一直线性查找的方式
(2) InputIterator find_if(InputIterator first, InputIterator last, Predicate pred);
和上面那个一样,不过这次是要求函数对象,比如greater和less
(3)ForwardIterator adjacent_find(ForwardIterator first, ForwardIterator last);、
(4)ForwardIterator adjacent_find(ForwardIterator first, ForwardIterator last, Predicate pred);
struct test{bool operator()(int m, int n){cout << m << " " << n << endl;return m == n - 1; }
};
int main(){int buf[] = {1,2,3,3,5,6,7,8,9,10};print(begin(buf),end(buf),""," ");vector<int> v;copy(begin(buf), end(buf),back_inserter(v));vector<int>::iterator it = adjacent_find(v.begin(), v.end(), test());if(it == v.end()){cerr << "not find" << endl;return 0;}cout << *it << endl;return 0;
}这两个函数都是查找相邻的两个相等的元素,第一个函数是调用operator==,然后返回第一个元素的位置;
第二个函数会把相等的相邻元素放入Pred对象中,然后返回true或者false,如果满足条件,则返回第一个元素的位置
(5).ForwardIterator find_first_of(ForwardIterator first1, ForwardIterator last1, forward_iterator first2, forward_iterator first2)
(6).ForwardIterator find_first_of(ForwardIterator first1, ForwardIterator last1, forward_iterator first2, forward_iterator first2, BinaryPredicate binary_pred);
这两个函数也是线性查找,查找第二个范围是否出现了第一个范围的元素,使用的是operator==,找到了则返回第一个序列的找到的位置,否则返回第一个序列的end,
不同之处在于,第二个函数会使用自定义个函数对象来定义规则
(7)ForwardIterator search(ForwardIterator first1, ForwardIterator last1, forward_iterator first2, forward_iterator first2);
(8)ForwardIterator search(ForwardIterator first1, ForwardIterator last1, forward_iterator first2, forward_iterator first2, BinaryPredicate binary_pred);
这两个函数也是线性查找,查找第二个范围的元素,是否在第一个范围的范围内,也就是第二个范围是第一个范围的子集,而且顺序也要一致,第一个函仍然是调用==,
第二个函数按照自定义的方式
找到则返回第一个序列找到的位置,找不到则返回end位置
//v1是v的一个子集
int buf[] = {1,2,3,3,5,6,1,1,15,10};
print(begin(buf),end(buf),""," ");
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));
vector<int> v2({5,6});
vector<int>::iterator b = v.begin() + 4.;
vector<int>::iterator it = search(v.begin(),v.end(), v2.begin(), v2.end());
if(it == v.end()){
cerr << "not find" << endl;
return 0;
}cout << *(it + 1) << endl;//找到了输出6(9)ForwardIterator find_end(ForwardIterator first1, ForwardIterator last1, forward_iterator first2, forward_iterator first2);
(10)ForwardIterator find_end(ForwardIterator first1, ForwardIterator last1, forward_iterator first2, forward_iterator first2, BinaryPredicate binary_pred);
这两个函数与search函数差不多,只不过它查找该自己最后 出现的位置,然后返回最后位置的第一个元素的迭代器
(11)ForwardIterator search_n(ForwardIterator first, ForwardIterator last, Size count, const T& value);
(12)ForwardIterator search_n(ForwardIterator first, ForwardIterator last, Size count,const T& value, BinaryPredicate pred);
这两个函数都是在范围里搜索连续count个与value相等的值,找到了就返回第一个相等的迭代器,找不到则返回last.
第二个稍微有点不一样的是,需要value同时满足自定义规则pred,这是一个函数对象,函数的第二个参数会接受value,而第一个参数在first中查找
第一个函数的例子
int buf[] = {1,2,3,3,5,6,1,1,15,10};
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));
print(v.begin(), v.end(),"v"," ");
vector<int>::iterator it = search_n(v.begin(),v.end(), 2,1);//查找两个连续为1的子序列
if(it == v.end()){
cerr << "not find" << endl;
return 0;
}
cout << *(it) << endl;上面的这个程序可以查找到两个连续为1的子序列,但是找不到2以上的,当count>=3时,则会输出not found
第二个函数的例子
struct test{
bool operator()(int m, int n){
cout <<"m = " << m << " value =" << n << endl;
return m == n - 1;
}
};
int main(){
int buf[] = {1,2,3,3,5,6,1,1,15,10};
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));
print(v.begin(), v.end(),"v"," ");
vector<int>::iterator it = search_n(v.begin(),v.end(), 2,2,test());
if(it == v.end()){
cerr << "not find" << endl;
return 0;
}
cout << *(it) << endl;
}test的条件时m = n-1;
则程序会令n = value,也就是2, 然后查找有没有连续的两个数字满足这个条件,里面只有一个子集满足,也就是1,1
(13) ForwardIterator min_element(ForwardIterator first, ForwardIterator last)
(14)ForwardIterator min_element(ForwardIterator first, ForwardIterator last, BinaryPredicate pred);
第一个函数在范围内查找最小值,最小值可能有多个,但是返回第一个位置的迭代器,这个函数使用的时operator<
int buf[] = {1,2,3,3,5,6,1,1,15,10};
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));
print(v.begin(), v.end(),"v"," ");
vector<int>::iterator it = min_element(v.begin(),v.end());
if(it == v.end()){
cerr << "not find" << endl;
return 0;
}
cout << *(it) << endl;
//输出1 第二个函数会使用自定义的比较规则
struct test{
bool operator()(int m, int n){
cout <<"m = " << m << " value =" << n << endl;
return m == n;
}
};
int main(){
int buf[] = {13,2,3,3,5,6,1,1,15,10};
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));
print(v.begin(), v.end(),"v"," ");
vector<int>::iterator it = min_element(v.begin(),v.end(),test());
if(it == v.end()){
cerr << "not find" << endl;
return 0;
}
cout << *(it) << endl;
}我在这里自定义了比较规则,使用test函数对象,且没用比较符<,而是==
则会查找与第一个元素相等的位置,但是总是返回那个元素的位置,没意义的程序,只是解释这个函数的运算规则
(13) ForwardIterator max_element(ForwardIterator first, ForwardIterator last)
(14)ForwardIterator max_element(ForwardIterator first, ForwardIterator last, BinaryPredicate pred);
和上面一样的,只不过时查找最大值了。
(15)void replace(ForwardIterator first, ForwardIterator last, const T& old_value, const T& new_value);
(16)void replace_if(ForwardIterator first, ForwardIterator last, Predicate pred, const T& new_value);
(17)OutputIterator replace_copy(ForwardIterator first, ForwardIterator last, OutputIterator result,const T& old_value, const T& new_value );
(18)OutputIterator replace_copy_if(ForwardIterator first, ForwardIterator last, OutputIterator result,Predicate pred, const T& new_value );
看过前面的算法形势应该不难理解这几个算法的意义,这四个算法是替代算法
第一个函数是在范围内,将old_value替换为new_value,调用的是operator==
第二个函数是在范围内,使用自定义的规则将满足规则的元素替换为new_value
第三个函数是将old_value替换为new_value,然后把结果输入到result
第四个函数是将满足自定义条件的元素替换为new_value,然后把结果复制到result
前两个函数会对原序列更改 ,后两个不会对原序列修改,而是把结果复制到新的序列
int buf[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
vector<int> v;
copy(begin(buf), end(buf),back_inserter(v));//复制原序列
print(v.begin(), v.end(),"v"," ");
vector<int> v1(v);
vector<int> v2(v);
vector<int> v3;
vector<int> v4;
replace(v.begin(), v.end(), 3, 0);//将v的3替换为0
print(v.begin(), v.end(),"v"," ");
replace_if(v1.begin(), v1.end(), bind2nd(less<int>(), 5), 0);//将v1小于5的数字替换为0
print(v1.begin(), v1.end(),"v1"," ");
replace_copy(v2.begin(), v2.end(), back_inserter(v3), 4, 0);//将v2等于4的元素替换为0,并且复制到v3
print(v2.begin(), v2.end(),"v2"," ");//v2不变
print(v3.begin(), v3.end(),"v3"," ");//v3变换
replace_copy_if(v2.begin(), v2.end(), back_inserter(v4), bind2nd(greater<int>(),3), 0);//将v2大于3的元素替换为0
print(v2.begin(), v2.end(),"v2"," ");//v2不变
print(v4.begin(), v4.end(),"v4"," ");//v4变化 3.6 比较范围
(1) bool equal(InputIterator first1, InputIterator last1, InputIterator first2);
(2)bool equal(InputIterator first1, InputIterator last1, InputIterator first2, BinaryPredicate BinaryPredicate binary_pred);
这个有点类似于search,但是search需要两个范围,查找第二个范围在第一个范围出现的位置
但是这两个函数需要两个相等的范围,指定了第一个范围,和第二个范围的开头,这是因为第二个范围需要第一个范围来设定。如果找到了,则返回true
第一个函数调用的是operator==
第二个函数调用的是自定义规则
(3)bool lexicographical_compare(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2);
(4)bool lexicographical_compare(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, BinaryPredicate binary_pred);
这两个函数是按照字典比较的顺序来判断第一个范围是否小于第二个范围,如果小于则返回true,两个范围不需要相等
char str1[] = "abc";
char str2[] = "abcd";
vector<char> v1;
vector<char> v2;
copy(begin(str1), end(str1), back_inserter(v1));
copy(begin(str2), end(str2), back_inserter(v2));
cout << lexicographical_compare(v1.begin(),v2.end(),v2.begin(),v2.end());
//输出1(5)pair<InputIterator,InputIterator> mismatch(InputIterator first1, InputIterator last1, InputIterator first2);
(6)pair<InputIterator,InputIterator> mismatch(InputIterator first1, InputIterator last1, InputIterator first2, BinaryPredicate binary_pred);
mismatch是比较两个序列不同的部分,同样需要两个长度相等的序列,然后找出序列不同的位置,返回值是pair,这是一个模板类,成员是两个迭代器,一个是first,另一个是second
返回值pair第一个值first指向第一个序列找到的地方,second指向第二个序列找到的地方
string str1 = "abcdefg";
string str2 = "abcdsss";
pair<string::iterator, string::iterator> it = mismatch(str1.begin(), str1.end(),str2.begin());
cout << "第一个位置" << *it.first << endl;
cout << "第二个位置" << *it.second << endl;3.7 删除
删除算法的参数是迭代器。对于固定的数组来讲,是无法删除掉已经存在的空间的,所以删除算法会把删除的对象放在数组后面,而把没删除的对象放在前面,然后返回一个新的末尾迭代器。
这样,从
但是对于可变大小的序列,则能够使用erase这样的算法来删除。
(1).ForwardIterator remove(ForwardIterator first, ForwardIterator last, const&T value);
(2).ForwardIterator remove(ForwardIterator first, ForwardIterator last, predicate pred);
(3).ForwardIterator remove_copy(InputIterator first, InputIterator last, OutputIterator result, const&T value);
(4).ForwardIterator remove_copy_if(InputIterator first, InputIterator last, OutputIterator result, predicate pred);
//1.remove
int buf[] = {1,2,3,4,5,6,7,8,9,10};
auto ptr = remove(begin(buf), end(buf), 6);
print(begin(buf), ptr(buf),""," ");
print(begin(buf),end(buf),""," ");//这里会输出1 2 3 4 5 7 8 9 10 10 //2.remove_if
int buf[] = {1,2,3,4,5,6,7,8,9,10};
auto ptr = remove_if(begin(buf), end(buf), test());
print(begin(buf), ptr,""," ");
print(begin(buf), end(buf), "", " ");其他的两种没有什么区别
(5). ForwardIterator unique(ForwardIterator first, ForwardIterator last);
(6). ForwardIterator unique(ForwardIterator first, ForwardIterator last, BinaryPredicate binary_pred);
(7). ForwardIterator unique_copy(ForwardIterator first, ForwardIterator last, OutputIterator result);
(8). ForwardIterator unique_copy(ForwardIterator first, ForwardIterator last, OutputIterator result, BinaryPredicate binary_pred);
这是一种删除相邻值相等只保留一个相等元素的算法,如果要清除序列所有的相等的值,最好先进行排序。
int buf[] = {1,2,2,4,5,6,7,8,9,10};
auto ptr = unique(begin(buf), end(buf));
print(begin(buf), ptr,""," ");
print(begin(buf), end(buf), "", " ");3.8.排序
(1)void sort(RandAccessIterator first, RandAccessIterator last);
(2)void sort(RandAccessIterator first, RandAccessIterator last, StrictWeakOrdering binary_pred);
(3)void stable_sort(RandAccessIterator first, RandAccessIterator last);
(4)void stable_sort(RandAccessIterator first,RandAccessIterator last, StrictWeakOrdering binary_pred);
默认为升序排列,sort不是稳定排序,他可能交换相等元素的位置,stable_sort为稳定排序,保存相等元素的原位。
(5)partial_sort(RandAccessIterator first, RandAccessIterator middle, RandAccessIterator last);
(6)partial_sort(RandAccessIterator first, RandAccessIterator middle, RandAccessIterator last, StrictWeakOrdering binary_pred);
对[first, end]进行部分的排序,将排序的结果放入[first, middle)中,而对于剩下的部分,则不保证排序结果
(7)RandAccessIterator partial_sort_copy(RandAccessIterator first, RandAccessIterator last, RandAccessIterator Result_first, RandAccessIterator Result_last);
(8)RandAccessIterator partial_sort_copy(RandAccessIterator first, RandAccessIterator last, RandAccessIterator Result_first, RandAccessIterator Result_last, StrictWeakOrdering binary_pred);
对first和last范围的序列排序,并且复制到Result_first到Result_last中,如果Result_first-Result_last的范围比first-last要大,则只使用一部分排序并且复制
(9)void nth_element(RandAccessIterator first, RandAccessIterator nth, RandAccessIterator last);
(10)void nth_element(RandAccessIterator first, RandAccessIterator nth, RandAccessIterator last, StrictWeakOrdering binary_pred);
这个算法与 partial_sort有点类似,但是它比partial_sort做得工作少得多。它以nth为界,比这个数小,则放在左边,比这个数大,则放在右边
int buf[] = {1,2,3,4,5,6,7,8,9,10};
random_shuffle(begin(buf), end(buf));
print(begin(buf), end(buf), "原序列", " ");
vector<int> v(begin(buf), end(buf));
vector<int> v1(begin(buf), end(buf));
vector<int>::iterator it = v.begin();
it += 4;
partial_sort(v.begin(), it, v.end());
print(v.begin(),v.end(),"partial_sort", " ");
vector<int>::iterator v_it = v1.begin() + 4;
nth_element(v1.begin(), v_it, v1.end());
print(v1.begin(), v1.end(), "nth_element", " ");3.9 排序之后的操作算法
以下的算法全都是排序之后的操作,如果对没有排序的序列进行操作,结果将会是未定义的
3.9.1.二分查找法
下面全部函数都是二分法,这些函数都是成对的,第一个是默认使用operator<,第二个是自定义的
(1)bool binary_search(ForwardIterator first, ForwardIterator last, const T& value);
(2)bool binary_search(ForwardIterator first, ForwardIterator last, const T& value, StrictWeakOrdering binary_pred);
这个算法是查找value是否存在,存在则返回true
(3)ForwardIterator lower_bound(ForwardIterator first, ForwardIterator last, const T& value);
(4)ForwardIterator lower_bound(ForwardIterator first, ForwardIterator last, const T& value,StrictWeakOrdering binary_pred);
这个算法返回value在[first, last]中第一次出现的位置,如果value不存在,则返回它应该在这个范围中的位置。
int buf[] = {1,2,3,3,5,6,7,8,9,10};
auto it = lower_bound(begin(buf), end(buf),3);
cout << *it << endl;
it = lower_bound(begin(buf), end(buf),4);
cout << *it << endl;//输出5(3)ForwardIterator upper_bound(ForwardIterator first, ForwardIterator last, const T& value);
(4)ForwardIterator upper_bound(ForwardIterator first, ForwardIterator last, const T& value,StrictWeakOrdering binary_pred);
返回value后一个位置,如果value不存在,则返应该出现的位置
int buf[] = {1,2,3,3,5,6,7,8,9,10};
auto it = upper_bound(begin(buf), end(buf),3);
cout << *it << endl;
it = upper_bound(begin(buf), end(buf),3);
cout << *it << endl;(5)pair<ForwardIterator, ForwardIterator> equal_range(ForwardIterator first, ForwardIterator last, const T& value);
(6)pair<ForwardIterator, ForwardIterator> equal_range(ForwardIterator first, ForwardIterator last, const T& value, StrictWeakOrdering binary_pred);
这个函数是lower_bound和upper_bound的结合,first指向value第一次出现的位置,second指向value最后一次出现的位置
3.9.2 合并算法
下面几个算法是合并算法,下面的函数也是成对的,合并之后的序列仍然是排序过的
(1). OutputIterator merge(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result);
(2). OutputIterator merge(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result, StrictWeakOrdering binary_pred);
将[first1,last1],[first2, last2]复制到result中,结果将是升序的,自定义的不一样
(3)void inplace_merge(BidirectionaIterator first, BidirectionaIterator middle, BidirectionaIterator last );
(4)void inplace_merge(BidirectionaIterator first, BidirectionaIterator middle, BidirectionaIterator last, StrictWeakOrdering binary_pred);
这里假定[first, middle)和[middle,last)来自同一个序列已排序好的,然后把结果保存在[first,last],则原序列为升序的序列
3.9.3 集合算法
对已排序的序列进行集合操作,输出的结果仍然是排序好的
1.包含
(1).bool includes(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2);
(2).bool includes(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, StrictWeakOrdering binary_pred);
如果[first2, last2)是[first1, last1)的子集,则返回true
2.并集
(3)OutputIterator set_union(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result);
(4)OutputIterator set_union(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result);
结果保存在result中,返回末尾的迭代器,如果某个元素在一个集合中出现多次,则result保存出现次数多的集合
3.交集
(5).OutputIterator set_intersection(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result);
(6).OutputIterator set_intersection(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result, StrictWeakOrdering binary_pred);
结果保存在result中,返回末尾的迭代器,如果某个元素在其中一个序列中出现多次,则result保存出现次数少的序列
4.集合的差
(7).OutputIterator set_difference(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result);
(8).OutputIterator set_difference(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result, StrictWeakOrdering binary_pred);
计算两个范围之间的集合差,这个差代表在第一个范围中出现,但是不在第二个范围中。如果某个元素多次出现,比如在第一个范围中出现n次,但是在第二个范围中出先m次,则结果中只保存max(n-m,0)次
int buf1[] = {1,2,3,3,5,6,7,8,9,10};
int buf2[] = {1,3,3,100};
vector<int> result;
auto ptr = set_difference(begin(buf1), end(buf1), begin(buf2), end(buf2), back_inserter(result));
print(result.begin(), result.end(),""," ");(7).OutputIterator set_symmetric_difference(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result);
(8).OutputIterator set_symmetric_difference(InputIterator first1, InputIterator last1, InputIterator first2, InputIterator last2, OutputIterator result, StrictWeakOrdering binary_pred);
这个差集的结果是相当于二者求并集,然后分别求差集的结果,也就是result包含的是
1.集合1中有的元素,但是集合2中没有;
2.集合2中有的元素集合1中没有
4 堆运算
下面每一种算法都成对的出现,第一种是默认使用operator<,第二种是自定义的函数对象
1.创建堆
(1)void make_heap(RandAccessIterator first, RandAccessIterator last);
(2)void make_heap(RandAccessIterator first, RandAccessIterator last, StrictWeakOrdering binary_pred);
2.将最后一个元素添加到堆中合适的位置
(3)void push_heap(RandAccessIterator first, RandAccessIterator last);
(4)void push_heap(RandAccessIterator first, RandAccessIterator last, StrictWeakOrdering binary_pred);
这个就相当于添加元素到堆中,不过由于是针对序列的,序列可能无法再次扩充,所有才会没有const T&的形式
3.获取堆顶元素
(5)void pop_heap(RandAccessIterator first, RandAccessIterator last);
(6)void pop_heap(RandAccessIterator first, RandAccessIterator last, StrictWeakOrdering binary_pred);
堆顶的元素成为了first-1,而原来的堆顶到了序列的末尾
4.堆排序
这是对已经存在的堆进行的排序,对于排序之后的序列,它将不在是堆,所以使用pop_heap和push_pop毫无意义
(7)void sort_heap(RandAccessIterator first, RandAccessIterator last);
(8)void sort_heap(RandAccessIterator first, RandAccessIterator last, StrictWeakOrdering binary_pred);
int buf[] = {1,2,3,3,5,6,7,8,9,10};
vector<int> result;
random_shuffle(begin(buf), end(buf));//随机化
copy(begin(buf), end(buf), back_inserter(result));
print(result.begin(), result.end(),"result原始数据"," ");
make_heap(result.begin(), result.end()-1);//[first, end-1)转化为堆
print(result.begin(), result.end(),"对[first, end-1)转化为堆"," ");
push_heap(result.begin(), result.end());//将序列最后一个元素添加到堆中
print(result.begin(), result.end(),"添加末尾元素到堆"," ");
vector<int> v(result);//复制堆
pop_heap(result.begin(), result.end());//将序列最后一个元素添加到堆中
print(result.begin(), result.end(),"堆顶元素出堆"," ") ;
sort_heap(v.begin(), v.end());
print(v.begin(), v.end(),"对堆进行排序"," ") ;5 对某一范围的所有元素进行运算
(1).UnaryFunction for_each(InputIterator first, InputIterator last, UnaryFunction f);
(2).OutputIterator transform(InputIterator first. InputIterator last, OutputIterator result, UnaryFunction f);
(3).OutputIterator transform(InputIterator first. InputIterator last,InputIterator first2, OutputIterator result, UnaryFunction f);
for_each函数执行的是f(*first);他会丢弃掉的函数的返回值,但是会把函数给返回过来,程序员可以通过返回的函数对象来获取状态;
第一个transform执行的是f(*first),并且把结果保存在result中
第二个函数是执行f(*first1,first2);两个序列的范围要相等,第二个序列的范围由第一个决定
6.数值计算
1.求和
(1)T accumulate(InputIterator first, InputIterator last, T result);
执行的过程是 result += *first
(2)T accumulate(InputIterator first, InputIterator last,T result, BinaryPredicate f);
执行过程是 f(result, *first)
返回值是运算的结果
struct f{int operator()(int& y,int& x){y += x*x;return y;}
};
int main(int argc, char** argv) {int buf[] = {1,2,3,4,5,6,7,8,9,10};int sum = 0;sum = accumulate(begin(buf), end(buf), 0);cout << sum << endl;//55sum = accumulate(begin(buf), end(buf), 0, f());//f(0, buf[i])cout << sum << endl;//1 + 4 + 9 + 16 + ... + 100return 0;
}2.内积
(3).T inner_product(InputIterator first1, InputIterator last1, InputIterator first2, T init);
(4).T inner_product(InputIterator first1, InputIterator last1, InputIterator first2, T init, BinaryFunction op1, BinaryFunction op2);
init代表一个初始值
op1代替了加法,op2代替乘法
第一种默认的内积算法是 (*first1) * (*first2)
那么第二种是 op1(init,op2(first1,first2));
返回值是运算的结果
struct a{int operator()(int& x, int y){//这里x使用引用,是因为这个值会被累加,必须保留cout << x << "+" << y << endl;x = x + y;return x;}
};
struct m{int operator()(int x, int y){cout << x << "*" << y << endl;return x * y;}
};
int main(int argc, char** argv) {int buf[] = {1,2,3,4,5,6,7,8,9,10};int arr[] = {1,1,1,1,1,1,1,1,1,1};int sum = inner_product(begin(buf), end(buf), begin(arr), 0);cout << sum << endl;sum = inner_product(begin(buf), end(buf), begin(arr), 0, a(), m());cout << sum << endl;return 0;
}3.部分和
(5)OutputIterator partial_sum(InputIterator first, InputIterator last, OutputIterator result);
(6)OutputIterator partial_sum(InputIterator first, InputIterator last, OutputIterator result, BinaryPredicate pred);
这个累积和与一般的不一样,它是一种斐波拉契模式的累计
返回值为result容器的末尾
4.相邻差
(7)OutputIterator adjacent_difference(InputIterator first, InputIterator last, OutputIterator result);
(8)OutputIterator adjacent_difference(InputIterator first, InputIterator last, OutputIterator result, BinaryPredicate pred);
第一个元素不变,其他都是后面一个元素减去前一个元素
template<class Iter>
void print(Iter first, Iter last,
const char* nm = "",
const char* sep = "\n",
ostream& os = cout)
{if(nm != 0 && *nm != '\0')os << nm << ": " << sep;typedef typename iterator_traits<Iter>::value_type T;copy(first, last, ostream_iterator<T>(cout, sep));os << endl;
}
struct m{int operator()(int x, int y){return x * y;}
};
int main(int argc, char** argv) {int buf[] = {1,2,3,4,5,6,7,8,9,10};vector<int> result;adjacent_difference(begin(buf), end(buf), back_inserter(result));print(result.begin(), result.end(), "", " ");result.clear();adjacent_difference(begin(buf), end(buf), back_inserter(result), m());//自定义计算方法,变成了后一个数字乘以前一个数字print(result.begin(), result.end(), "", " ");return 0;
}7. 通用实用工具
1. 关联对象
template<class T1, class 2> struct pair//关联对象的定义
创建一个关联对象可以使用make_pair(const T1&. const T2&);
获取关联对象可以使用first和second;
2.两个迭代器的之间的距离,计算需要迭代多少次
difference_type distance(InputIterator first, InputIterator last);
返回值一般是整型
3.给容器创建迭代器用于插入
back_insert_iterator<Container> back_inserter(Container& x);
front_insert_iterator<Container> front_inserter(Container& x);
insert_iterator<Container> inserter(Container& x, Iterator i);
4.返回较小值
const T& min(const T&, const T&);
5返回较大值
const T& max(const T&, const&T);
6.交换值
void swap(T&a , T& b);
每一种容器实际上都有自己的特化版本的交换算法,最好用特化版的
void iter_swap(ForwardIterator a, ForwardIterator b);
相关文章:

C++通用算法
1.概述根据名字就知道如何使用相关算法,比如copy函数,就是复制的意思,它需要一个范围,以及要复制的位置copy(begin, end, container_begin);#include <iostream> #include<vector> #include<algorithm> #includ…...

Springboot停机方式
1. 介绍 简单的说,就是向应用进程发出停止指令之后,能保证正在执行的业务操作不受影响,直到操作运行完毕之后再停止服务。应用程序接收到停止指令之后,会进行如下操作: 1.停止接收新的访问请求 2.正在处理的请求&…...

Linux perf_event_open 简介
文章目录前言一、简介二、struct perf_event_attr2.1 type2.2 size2.3 config2.3.1 PERF_TYPE_HARDWARE2.3.2 PERF_TYPE_SOFTWARE2.3.3 PERF_TYPE_TRACEPOINT2.3.4 PERF_TYPE_HW_CACHE2.3.5 其他类型三、sample相关参数3.1 sample_period3.2 sample_freq3.3 sample_type四、其他…...

Java给定两组起止日期,求交集
/*** 判断2个时间段是否有重叠(交集)* param startDate1 时间段1开始时间戳* param endDate1 时间段1结束时间戳* param startDate2 时间段2开始时间戳* param endDate2 时间段2结束时间戳* param isStrict 是否严格重叠,true 严格࿰…...
数组的复制与二维数组的用法
今天学习的主要内容有 数组的复制 数组的复制 利用循环进行数组的复制 import java.util.Arrays; public class Main3 {public static void main(String[] args) {int []arr new int[]{1,2,3,4,5,6};int []arr1 new int[arr.length];for (int i 0; i < arr.length; i…...
)
JS判断两个table数据是否完全相等(判断两个数组对象是否完全相等)
需求 现有的table为tableA,有多个要做对比的table为一个数组 CompareArray 涉及到的问题 外层是数组,但是内部数据都是对象,对象属性名的排序不一样外层数组也涉及到 顺序不一样的问题 思路 对compareArray做长度筛选 filter 得到 同长度…...

关于小程序,你想知道的这些
近年来,各大平台纷纷上架小程序,迎来了小程序的爆发式增长。今天就来跟大家简单分享一下小程序基本的运行机制和安全机制。 小程序的由来 在小程序没有出来之前,最初微信WebView逐渐成为移动web重要入口,微信发布了一整套网页开…...

WuThreat身份安全云-TVD每日漏洞情报-2023-02-13
漏洞名称:THORSTEN PHPMYFAQ 跨站点脚本 漏洞级别:高危 漏洞编号:CVE-2023-0791 相关涉及:THORSTEN PHPMYFAQ 3.1.10 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-03506 漏洞名称:TENDA AC23 越界写入 漏洞级别:高危 漏洞编号:CVE-2023-078…...
【Linux】软件安装(三分钟教会你如何在linux下安装软件)
🔥🔥 欢迎来到小林的博客!! 🛰️博客主页:✈️小林爱敲代码 🛰️博客专栏:✈️Linux之路 🛰️社区:✈️进步学堂 目录&…...

Fluent Python 笔记 第 10 章 序列的修改、散列和切片
本章将以第 9 章定义的二维向量 Vector2d 类为基础,向前迈出一大步,定义表示多维向量的 Vector 类。这个类的行为与 Python 中标准的不可变扁平序列一样。 10.3 协议和鸭子类型 在 Python 中创建功能完善的序列类型无需使用继承,只需实现符…...
在中国程序员工作是青春饭吗?
上个月公司告诉我毕业了。 我打开boss直聘,一溜溜的外包公司和我打招呼。 我寻思我说不定啥时候就离开深圳了,外包不外包也无所谓钱到位就行。(大公司学历不够格也进不去) 结果华为、平安的外包告诉我,不好意思呀&a…...

Linux tcpdump
tcpdump - 转储网络上的数据流 是不是感觉很懵?全方位描述tcpdump: 通俗:tcpdump是一个抓包工具,用于抓取网络中传输的数据包形象:tcpdump如同国家海关,凡是入境和出境的货物,海关都要抽样检查࿰…...
redis知识汇总(部署、高可用、集群)
文章目录一、redis知识汇总什么是redisredis的优缺点:为什么要用redis做缓存redis为什么这么快什么是持久化redis持久化机制是什么?各自优缺点?AOF和RDB怎么选择redis持久化数据和缓存怎么做扩容什么是事务redis事务的概念ACID概念主从复制re…...

【手写 Vuex 源码】第十篇 - Vuex 命名空间的实现
一,前言 上一篇,主要介绍了 Vuex 响应式数据和缓存的实现,主要涉及以下几个点: Vuex 的响应式实现原理;响应式核心方法 resetStoreVM;commit 和 dispatch 的处理; 本篇,继续介绍 …...
面试腾讯测试岗后感想,真的很后悔这5年一直都干的是基础测试....
前两天,我的一个朋友去大厂面试,跟我聊天时说:输的很彻底… 我问她:什么情况?她说:很后悔这5年来一直都干的是功能测试… 相信许多测试人也跟我朋友一样,从事了软件测试很多年,却依…...
)
知识图谱 方法、实践与应用 王昊奋 读书笔记(下)
最近读了这本书,在思路上很有启发,对知识图谱有了初步的认识,以下是原书后半部分的内容,可以购买实体书获取更多内容。 知识图谱推理 结合已有规则,推出新的事实,例如持有股份就能控制一家公司࿰…...
vue实现打印浏览器页面功能(两种方法)
推荐使用方法二 方法一:通过npm 安装插件 1,安装 npm install vue-print-nb --save 2,引入 安装好以后在main.js文件中引入 import Print from vue-print-nbVue.use(Print); //注册 3,现在就可以使用了 div id"printTest…...
【VictoriaMetrics】VictoriaMetrics单机版批量和单条数据写入(Prometheus格式)
VictoriaMetrics单机版支持以Prometheus格式的数据写入,写入支持单条数据写入以及多条数据写入,下面操作演示下如何使用 1、首先需要启动VictoriaMetrics单机版服务 2、使用postman插入单机版VictoriaMetrics,以当前时间插入数据 地址为 http://victoriaMetricsIP:8428/api…...
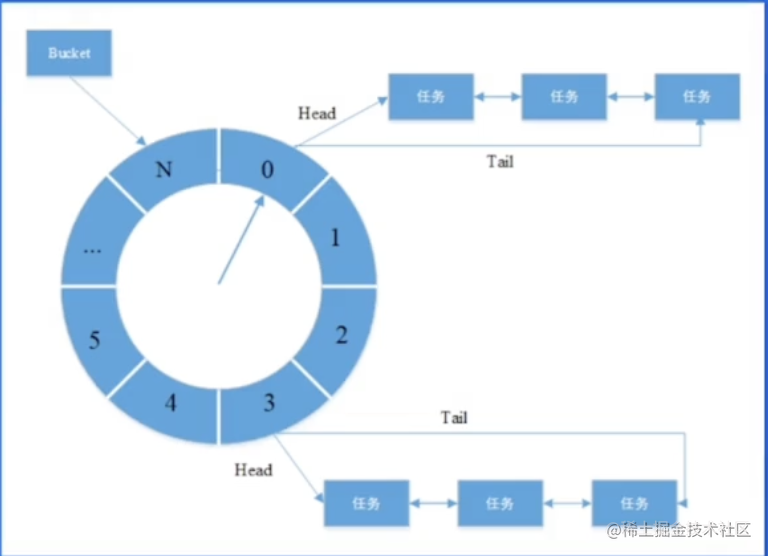
【青训营】分布式定时任务简述
这是我参与「第五届青训营 」伴学笔记创作活动的第 13 天 分布式定时任务简述 定义 定时任务是指系统为了自动完成特定任务,实时、延时、周期性完成任务调度的过程。分布式定时任务是把分散的、可靠性差的定时任务纳入统一平台,并且实现集群管理调度和…...
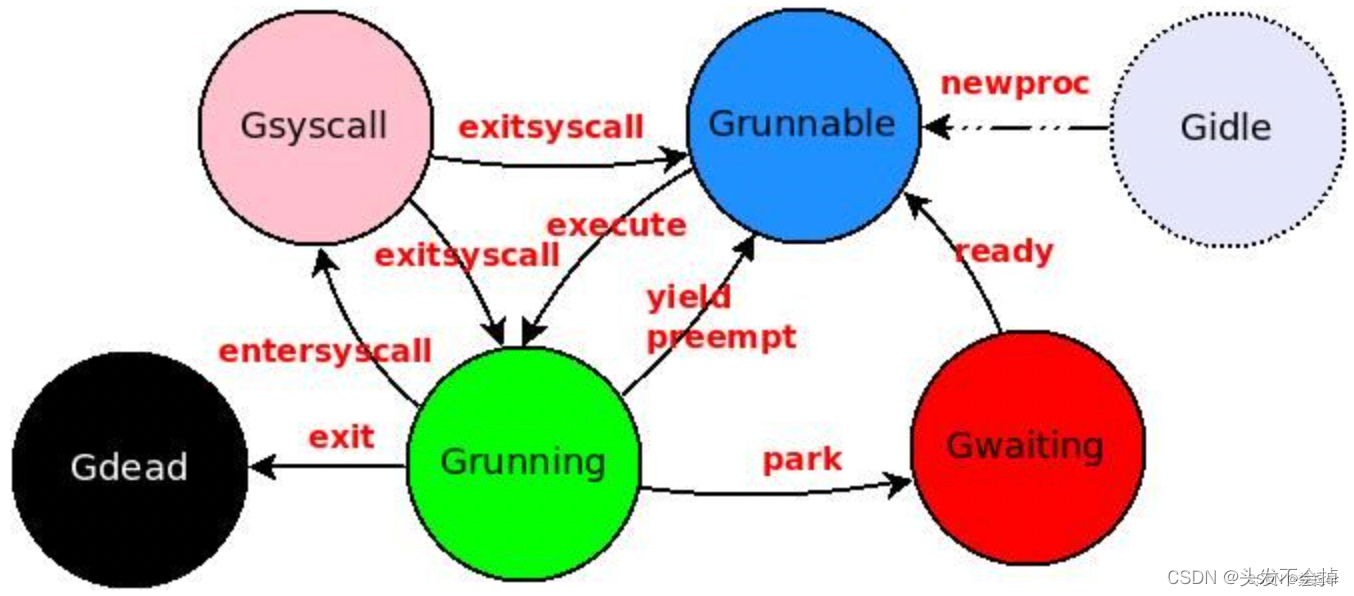
golang语言本身设计点总结
本文参考 1.golang的内存管理分配 golang的内存分配仿造Google公司的内存分配方法TCmalloc算法;她会把将内存请求分为两类,大对象请求和小对象请求,大对象为>32K的对象。 在了解golang的内存分配之前要知道什么事虚拟内存,虚拟内存是把磁盘作为全局…...

首次接入Taotoken时如何通过模型广场测试不同模型的响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 首次接入Taotoken时如何通过模型广场测试不同模型的响应效果 当你开始使用Taotoken平台,面对众多可选的模型࿰…...

终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南
终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏截图分辨率太低而烦恼?是否需要在不同设备上测试UI布局却要反复重…...

20 鸿蒙LiteOS信号量原理实战:信号量作用、MAX_COUNT含义、线程同步源码解析
鸿蒙LiteOS信号量原理实战:信号量作用、MAX_COUNT含义、线程同步源码解析 一、前言 本文基于小凌派 RK2206鸿蒙LiteOS标准示例代码,从零讲解LiteOS内核信号量核心概念:为什么需要信号量、信号量能干什么、MAX_COUNT参数真实含义,…...

练了半年演讲口才,汇报时还是结巴,说说我的真实感受
小林坐在会议室的角落,手心微微出汗。轮到他汇报季度项目进展时,他深吸一口气站起来——结果,开场白磕磕绊绊,PPT翻到第三页才找回节奏。散会后他苦笑着跟同事说:“演讲口才课我上了半年了,怎么还是这副德行…...

从ShareGPT项目拆解现代全栈开发:Next.js、Serverless与Chrome扩展实战
1. 项目概述与核心价值如果你和我一样,经常在ChatGPT里进行一些天马行空的对话,从构思一部科幻小说的世界观,到一步步推导一个复杂的编程问题,再到让它扮演苏格拉底和你辩论哲学,这些对话记录本身就是宝贵的数字资产。…...

长期使用taotoken token plan套餐的成本节约感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken Token Plan 套餐的成本节约感受 对于需要稳定调用大模型 API 的个人开发者或团队而言,成本控制是一…...

如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题
如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了喜欢的歌曲,却发现…...

【限时公开】谷歌内部未文档化Gemini JavaScript SDK隐藏能力:流式响应中断控制、上下文压缩率提升63%实测数据
更多请点击: https://intelliparadigm.com 第一章:Gemini JavaScript SDK核心能力概览 Gemini JavaScript SDK 是 Google 官方提供的轻量级客户端库,专为在浏览器和 Node.js 环境中无缝集成 Gemini 模型能力而设计。它抽象了底层 HTTP 请求、…...

【独家首发】ElevenLabs中文语音优化白皮书:针对普通话声调、儿化音与连读现象的5层微调协议
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs超写实语音生成教程 ElevenLabs 是当前业界领先的 AI 语音合成平台,其模型在语调自然度、情感表达力与跨语言一致性方面表现卓越。本章将指导你完成从 API 接入到高质量语音生成的…...
)
别再只点灯了!用ESP32和WebServer库做个智能家居控制面板原型(附完整代码)
用ESP32打造智能家居控制面板:从网页控制到硬件交互实战 想象一下,清晨醒来无需下床,轻点手机就能打开窗帘、调节灯光;离家时一键关闭所有电器,还能实时查看家中温湿度——这些看似未来的场景,如今用一块ES…...