Java 基础面试
final、finalize 和 finally 的不同之处?
- Final:是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不 能被改变。
- Finalize:方法是在对象被回收之前调用的方法, 给对象自己最后一个复活的机会,但是什么时候调用 finalize 没有保证。
- Finally:与 try 和 catch 一起用于异常的处理。finally 块不一定会被执行,try前有return,虚拟机退出这两种情况是不会执行的。
String 是最基本的数据类型吗?
String 并不是最基本的数据类型,而是引用数据类型。
基本数据类型:
- 整数类型:
byte(1 字节)、short(2 字节)、int(4 字节)、long(8 字节)。 - 浮点类型:
float(4 字节)、double(8 字节)。 - 字符类型:
char(2 字节)。 - 布尔类型:
boolean(理论上占 1 位,实际实现中通常占 1 字节)。
Java引用类型包括哪些?
- 强引用(StrongReference)
- 软引用(SoftRefernce)
- 弱引用(WeakReference)
- 虚引用(PhantomReference)
Http和Https的区别
- https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
cookie和session的区别?
Cookie主要存放在客户端,session主要存放在服务端,cookiec存储的数据一般不能超过 4KB,Session 没有数据大小的限制。
new String () 一共创建了几个对象?
如果字符串常量池没有该字符串,会创建 2 个对象,一个在堆中,一个在字符串常量池;如果字符串常量池已经存在该字符串,则只在堆中创建 1 个对象 。
序列化和反序列化的底层实现原理是什么?
-
序列化:将对象的状态信息转换为字节流,以便在网络传输或存储到文件中。Java 的 ObjectOutputStream 类通过反射获取对象的属性和值,并按照一定的格式将其写入字节流。
-
反序列化:将字节流重新转换为对象。Java 的 ObjectInputStream 类从字节流中读取数据,并根据保存的对象信息重建对象。
hashCode 和 equals 方法的区别和联系是什么?
-
区别:hashCode 方法返回一个哈希值,用于在哈希表中快速定位对象;equals 方法用于比较两个对象的内容是否相等。
-
联系:如果两个对象 equals 方法返回 true,那么它们的 hashCode 值必须相等;但如果两个对象 hashCode 值相等,equals 方法不一定返回 true 。
若 hashCode 方法永远返回 1 或者一个常量会产生什么结果?
会导致所有对象的哈希值相同,在哈希表中会产生大量的哈希冲突,所有元素都会存储在同一个链表中,查找、插入和删除操作的时间复杂度会退化为 O (n),严重影响哈希表的性能。
讲讲 String、StringBuilder、StringBuffer 的区别和使用场景?
-
不可变性:String 是不可变的,每次修改都会生成新的 String 对象;StringBuilder 和 StringBuffer 是可变的。
-
线程安全性:StringBuffer 是线程安全的,内部方法使用 synchronized 关键字修饰;StringBuilder 是非线程安全的 。
-
使用场景:如果字符串操作较少,使用 String;如果在单线程环境下进行大量字符串拼接操作,使用 StringBuilder;如果在多线程环境下进行大量字符串拼接操作,使用 StringBuffer。
Object 类中常见的方法有哪些?为什么 wait 和 notify 会放在 Object 里边?
-
常见方法:equals、hashCode、toString、clone、finalize、wait、notify、notifyAll 等。
-
原因:因为任意对象都可以作为锁对象,而线程等待和唤醒操作是基于锁的,所以将 wait 和 notify 方法放在 Object 类中,这样所有对象都可以使用这些方法来实现线程间的通信。
浅拷贝和深拷贝的区别是什么?
-
浅拷贝:只复制对象的引用,不复制对象本身。修改新对象的引用类型属性会影响原对象。
-
深拷贝:不仅复制对象的引用,还复制对象本身。修改新对象的引用类型属性不会影响原对象。
反射的作用与实现原理是什么?
-
作用:在运行时获取类的信息,包括类的属性、方法、构造函数等,并可以动态创建对象、调用方法、访问属性。常用于框架开发、测试框架、依赖注入等场景。
-
实现原理:Java 的反射机制是通过 java.lang.reflect 包下的类来实现的。通过 Class 类获取类的信息,通过 Constructor 类创建对象,通过 Method 类调用方法,通过 Field 类访问属性。
Java 提供的排序算法是怎么实现的?
-
Arrays.sort():对于基本数据类型,使用双轴快速排序(Dual-Pivot Quicksort);对于对象类型,使用 TimSort,它是归并排序和插入排序的结合,具有稳定排序的特点。
-
Collections.sort():底层调用 Arrays.sort () 对 List 进行排序。
HashMap 1.7 和 1.8 的实现区别是什么?
-
数据结构:1.7 采用数组 + 链表,1.8 引入了红黑树。当链表长度超过阈值(8)时,链表会转换为红黑树,以提高查找效率。
-
hash 算法:1.7 的 hash 算法相对复杂,1.8 简化了 hash 算法,提高了计算效率。
-
扩容机制:1.7 在扩容时,需要重新计算每个元素的 hash 值并重新插入;1.8 在扩容时,部分元素可以直接迁移到新的数组位置,减少了重新计算 hash 值的开销。
HashMap 中插入、添加、删除元素的时间复杂度是多少?
理想情况下,时间复杂度为 O (1),因为 HashMap 基于哈希表,通过计算哈希值直接定位元素位置。但在哈希冲突严重时,链表会变长,时间复杂度会退化为 O (n);当链表转换为红黑树后,时间复杂度为 O (log n) 。
HashMap 的默认空间、扩容因子等是怎样的?
-
默认空间:16。
-
扩容因子:0.75。当 HashMap 中的元素个数达到容量的 0.75 倍时,会进行扩容,扩容后的容量是原来的 2 倍。
为什么在HashMap会使用到红黑树?
如果在Index冲突过多的情况下,在链表上的查询的效率会很慢【时间复杂度是O(n)】,所以在链表长度大于8并且数组长度大于64是就会转为红黑树
HashMap扩容
HashMap扩容是先以原数组长度乘以0.75进行提前扩容,以2倍进行扩容,如果默认长度是16的话,那么会在12的时候就会提前扩容
HashMap加载因子为什么是0.75?
① 如果加载因子太小,key冲突的概率就比较小,但是非常浪费内存空间
② 如果加载因子太大,key冲突的概率就比较大,但是可利用空间就非常好
③ 加载因子为0.75也是官方测试出来的数据,在空间和内存上处于最佳值
HashMap,LinkedHashMap,TreeMap 有什么区别?
-
底层数据结构
HashMap:HashMap 底层基于哈希表实现,它使用数组和链表(或红黑树)结合的方式来存储键值对。数组中的每个位置被称为一个桶(bucket),当发生哈希冲突时(即不同的键计算出相同的哈希值),会在对应的桶位置以链表或红黑树的形式存储多个元素。当链表长度超过一定阈值(默认为 8)且数组长度达到 64 时,链表会转换为红黑树,以提高查找效率。LinkedHashMap:LinkedHashMap 继承自 HashMap,它在 HashMap 的基础上维护了一个双向链表,用于记录元素的插入顺序或访问顺序。这个双向链表使得 LinkedHashMap 可以保持元素的插入顺序或者在访问元素时将其移动到链表尾部,从而实现按访问顺序排序。TreeMap:TreeMap 底层基于红黑树(一种自平衡的二叉搜索树)实现。红黑树的每个节点都存储一个键值对,并且按照键的自然顺序或者指定的比较器顺序对元素进行排序。这意味着 TreeMap 中的元素始终是有序的。
-
元素顺序
HashMap:不保证元素的顺序,元素的存储和遍历顺序是无序的,这是因为元素的位置是根据键的哈希值决定的,每次插入或扩容时元素的位置可能会发生变化。LinkedHashMap:可以保持元素的插入顺序或者访问顺序。默认情况下,它按照插入顺序维护元素;如果在构造函数中指定 accessOrder 为 true,则会按照访问顺序维护元素,即每次访问一个元素后,该元素会被移动到链表的尾部。TreeMap:按照键的自然顺序或者指定的比较器顺序对元素进行排序。如果键实现了 Comparable 接口,TreeMap 会使用键的自然顺序;如果在构造函数中传入了一个比较器,TreeMap 会使用该比较器来确定元素的顺序。
HashMap 和 HashTable 有什么区别?
- 线程安全性:HashMap 线程不安全,HashTable 线程安全。
- 效率:HashTable 因线程安全,效率低于 HashMap。
- null 值处理:HashMap 最多允许一条记录的 key 为 null(存于第 0 个位置),允许多条记录的值为 null;HashTable 不允许 key 或值为 null。
- 初始容量与扩容:HashMap 默认初始化数组大小为 16,扩容时扩大两倍;HashTable 默认初始大小为 11,扩容时扩大两倍 + 1。
- 哈希值计算:HashMap 需重新计算 hash 值,HashTable 直接使用对象的 hashCode。
HashMap & ConcurrentHashMap 的区别?
HashMap 和 ConcurrentHashMap 都是用于存储键值对的哈希表结构,不过它们在多线程安全、性能、锁机制、对 null 的支持等方面存在显著差异
- HashMap:没有锁机制,因为它不考虑多线程并发访问的情况,所以在多线程环境下操作时不会对资源进行加锁。
- ConcurrentHashMap:在不同的 Java 版本中采用了不同的锁机制:
- Java 7 及以前:采用分段锁(Segment)机制。ConcurrentHashMap 内部被分成多个 Segment,每个 Segment 类似于一个小的 HashMap,并且每个 Segment 都有自己独立的锁。不同的线程可以同时访问不同的 Segment,从而提高并发性能。只有在访问同一个 Segment 时才需要竞争锁。
- Java 8 及以后:摒弃了分段锁机制,采用 CAS(Compare - And - Swap,比较并交换)和 synchronized 来实现并发控制。当进行插入、删除等操作时,首先会使用 CAS 尝试更新,如果失败则使用 synchronized 对节点进行加锁,锁的粒度更小,仅对需要操作的节点进行加锁,进一步提高了并发性能。
为什么 ConcurrentHashMap 比 HashTable 效率要高?
HashTable:采用一把锁锁住整个链表结构来处理并发问题。由于多个线程竞争同一把锁,容易出现阻塞情况。ConcurrentHashMap:- JDK 1.7:使用分段锁(由ReentrantLock、Segment和HashEntry构成)。将HashMap划分为多个段,每段分配一把锁,支持多线程访问,锁粒度基于Segment,每个Segment包含多个HashEntry。
- JDK 1.8:采用CAS + synchronized + Node + 红黑树的方式。锁粒度为Node(首结点,实现Map.Entry<K,V>),相较于 JDK 1.7,锁粒度降低了。
HashMap中Put方法的底层实现
- 计算键的哈希值。
- 根据哈希值找到对应的桶位置。
- 检查桶是否为空,如果为空则直接插入新节点。
- 如果桶不为空,检查是链表还是红黑树结构。
- 若是链表,遍历链表查找是否已存在相同键,若存在则更新值,不存在则插入新节点。
- 若是红黑树,调用红黑树的插入方法插入或更新节点。
- 插入节点后,检查是否需要进行扩容操作。
public V put(K key, V value) {// 调用 putVal 方法完成实际的插入操作return putVal(hash(key), key, value, false, true);
}// 计算键的哈希值
static final int hash(Object key) {int h;// 如果 key 为 null,哈希值为 0;否则,将 key 的哈希码与高 16 位进行异或操作return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 如果哈希表为空或者长度为 0,进行扩容操作if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 根据哈希值计算桶的索引位置,如果该位置为空,直接插入新节点if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 如果桶的第一个节点的键与要插入的键相同,记录该节点if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// 如果桶的第一个节点是红黑树节点,调用红黑树的插入方法else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 遍历链表for (int binCount = 0; ; ++binCount) {// 如果遍历到链表末尾,插入新节点if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 如果链表长度达到树化阈值(默认为 8),将链表转换为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// 如果在链表中找到相同键的节点,记录该节点if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 如果找到了相同键的节点,根据 onlyIfAbsent 参数决定是否更新值if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}// 增加修改次数++modCount;// 如果元素数量超过阈值,进行扩容操作if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}
ConcurrentHashMap 的实现原理是什么?
-
数据结构:在 JDK 1.7 中,采用分段锁(Segment)机制,每个 Segment 是一个独立的哈希表,不同 Segment 之间可以并发操作。在 JDK 1.8 中,抛弃了 Segment,采用 Node 数组 + 链表 + 红黑树的数据结构,并且使用 CAS 和 synchronized 关键字来保证并发安全。
-
并发控制:读操作基本无锁,写操作通过 CAS 和 synchronized 来保证原子性和可见性。
ArrayList和Vector的区别?
Array线程不安全,效率高,Vector线程安全,效率低
ArrayList和LinkList的底层实现原理?
ArrayList:采用数组实现,基于下标查询,时间复杂度是O(1),所以查询块,增删慢LinkList:采用链表实现的,每一个节点有三个参数,指向下一节点、指向上一节点,值基于下标查询,时间复杂度是O(n),所以查询慢,适合增删操作
ArrayList 与 LinkedList 初始空间是多少?
-
ArrayList:初始容量为 10。
-
LinkedList:没有初始容量的概念,它是基于链表实现的,节点按需创建。
相关文章:

Java 基础面试
final、finalize 和 finally 的不同之处? Final:是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不 能被改变。Finalize:方法是在对象被回收之前调用的方法, 给对象…...

ac的dhcp池里option43配错导致ap无法上线问题排查过程
dhcp池里ac地址配错,导致ap无法上线问题排查过程 问题:ap手动设置ac的ip正常注册在线,但dhcp获得ip和ac地址发现无法在ac上注册成功。 组网: ac旁路结构,路由器lan口地址172.16.1.1,开dhcp服务࿰…...

第1章:LangChain4j的聊天与语言模型
LangChain4J官方文档翻译与解析 目标文档路径: https://docs.langchain4j.dev/tutorials/chat-and-language-models/ 语言模型的两种API类型 LangChain4j支持两种语言模型(LLM)的API: LanguageModel:这种API非常简单,…...

Cython学习笔记1:利用Cython加速Python运行速度
Cython学习笔记1:利用Cython加速Python运行速度 CythonCython 的核心特点:利用Cython加速Python运行速度1. Cython加速Python运行速度原理2. 不使用Cython3. 使用Cython加速(1)使用pip安装 cython 和 setuptools 库(2&…...

【从0做项目】Java音缘心动(1)———项目介绍设计
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 零:项目结果展示 一:音乐播放器Web网页介绍 二:前期准备工作&…...

智慧农业新生态 | 农业数字化服务平台——让土地生金,让服务无忧
一部手机管农事,从播种到丰收,全链路数字化赋能! 面向农户、农机手、农服商、农资商打造的一站式农业产业互联网平台,打通农资交易、农机调度、农服管理、技术指导全场景闭环,助力乡村振兴提效增收。 三大核心场景&am…...

C++编程,#include <iostream>详解,以及using namespace std;作用
在C编程中,#include <iostream> 是用来包含输入/输出流头文件的预处理指令。它允许程序使用标准的输入/输出对象如 std::cout 和 std::cin,以便与标准输入和输出流进行交互。这一头文件是编写输入输出操作时必不可少的部分。 讲到这里,…...

jetbrains IDEA集成大语言模型
一、CodeGPT CodeGPT是由CSDN打造的一款生成式AI产品,专为开发者量身定制。它能够提供强大的技术支持,帮助开发者在学习新技术或解决实际工作中的各种计算机和开发难题1。 idea集成 1.在线安装:直接在线安装 2.离线安装 JetBrains Mar…...
)
理解都远正态分布中指数项的精度矩阵(协方差逆矩阵)
之前一直不是很理解这个公式为什么用这个精度矩阵,为什么这么巧合,为什么是它,百思不得其解,最近有了一些新的理解: 1. 这个精度矩阵相对公平合理的用统一的方式衡量了变量间的关系,但是如果是公平合理的衡…...

使用 Spark NLP 实现中文实体抽取与关系提取
在自然语言处理(NLP)领域,实体抽取和关系提取是两个重要的任务。实体抽取用于从文本中识别出具有特定意义的实体(如人名、地名、组织名等),而关系提取则用于识别实体之间的关系。本文将通过一个基于 Apache Spark 和 Spark NLP 的示例,展示如何实现中文文本的实体抽取和…...

less-8 boolen盲注,时间盲注 函数补全
获取当前数据库名 import requestsdef inject_database(url):namemax_length20 # 假设数据库名称最大长度为20# ASCII范围:数字、字母、下划线(_)low{a: 97, z: 122, A: 65, Z: 90, 0: 48, 9: 57, _: 95}high{97: a, 122: z, 65: A, 90: Z,…...

[NKU]C++基础课(五)补充:结构体
【3.3】C结构体介绍_哔哩哔哩_bilibili 结构体 最厉害的学生 现有N名同学参加了期末考试,并且获得了每名同学的信息: 1 姓名(不超过8个字符的仅有英文小写字母的字符串) 2 语文、数学、英语成绩(均为不超过150的自然数)。 3 总分最高的学生就是最厉害的。 请输…...

亲测可用,IDEA中使用满血版DeepSeek R1!支持深度思考!免费!免配置!
作者:程序员 Hollis 之前介绍过在IDEA中使用DeepSeek的方案,但是很多人表示还是用的不够爽,比如用CodeChat的方案,只支持V3版本,不支持带推理的R1。想要配置R1的话有特别的麻烦。 那么,今天,给…...
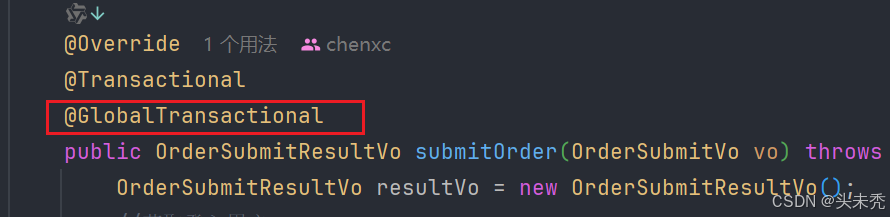
springcloud整合seata
1、前置安装与了解: 1、nacos的安装:docker安装nacos并挂载 2、seata的安装:docker安装seata并挂载,同时注册到nacos 3、spring-boot版本为2.6.12,spring-cloud-alibaba版本为2021.0.4.0,spring-cloud版本…...
)
Html5学习教程,从入门到精通,HTML5 简介语法知识点及案例代码(1)
HTML5 简介 HTML5 是最新的 HTML 标准,它引入了许多新特性,使网页开发更加强大和灵活。以下是一些关键的 HTML5 语法知识点: 1. 文档类型声明 (DOCTYPE) HTML5 的文档类型声明非常简单: <!DOCTYPE html>2. 字符编码 HT…...

Django加bootstrap实现上传文件含有进度条
1. 项目结构 myproject/ ├── myproject/ │ ├── settings.py │ ├── urls.py │ └── ... ├── myapp/ │ ├── templates/ │ │ └── upload.html │ ├── views.py │ ├── urls.py │ └── ... └── media/ # 手动创…...

八大排序算法(2)交换排序-冒泡排序 和 快速排序
快速排序(Quick Sort) 和 冒泡排序(Bubble Sort) 都是常见的交换排序算法,它们的核心思想都是通过交换元素来实现排序。但是,它们的工作原理和性能差异非常大。下面我们来详细对比这两种排序算法࿱…...

Python的那些事第二十三篇:Express(Node.js)与 Python:一场跨语言的浪漫邂逅
摘要 在当今的编程世界里,Node.js 和 Python 像是两个性格迥异的超级英雄,一个以速度和灵活性著称,另一个则以强大和优雅闻名。本文将探讨如何通过 Express 框架将 Node.js 和 Python 结合起来,打造出一个高效、有趣的 Web 应用。我们将通过一系列幽默风趣的实例和表格,展…...

STM32MP157A单片机移植Linux驱动
在stm32mp157a单片机移植Linux操作系统,并移植内核驱动,在应用程序中使用3个线程,分别实现控制单片机上3个led流水灯的功能、蜂鸣器控制的功能、风扇控制的功能。 需求整理: 1.驱动程序-->led1.c,led2.cÿ…...

Qt程序退出相关资源释放问题
目录 问题背景: aboutToQuit 代码举例 closeEvent事件 代码举例 程序退出方式 quit() exit(int returnCode 0) close() 问题背景: 实际项目中程序退出前往往需要及进行一些资源释放、配置保存、线程中断等操作,避免资源浪费ÿ…...

循环优化方法-Polyhedral Model
流行的循环优化方法,就是所谓的多面体模型,即Polyhedral Model多面体模型的应用非常广泛,在HLS里主要被用来将循环语句以空间多面体表示(见下图),然后根据边界约束和依赖关系,通过几何操作进行语…...

Qwen3-Reranker-0.6B在Visual Studio中的开发调试技巧
Qwen3-Reranker-0.6B在Visual Studio中的开发调试技巧 1. 环境准备与项目配置 在开始使用Qwen3-Reranker-0.6B进行开发前,需要先配置好Visual Studio的开发环境。这个模型是一个专门用于文本重排序任务的AI模型,能够帮助你在搜索和检索场景中提升结果的…...

2026年怎么集成OpenClaw/Hermes Agent?零基础部署及token Plan配置步骤
2026年怎么集成OpenClaw/Hermes Agent?零基础部署及token Plan配置步骤。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人办…...

2026年必逛!厦门地道特产店,品质保证让你爱不释手
在厦门这座充满历史与文化的城市里,寻找正宗的闽台特产不仅是游客的必修课,也是本地人生活的一部分。想要买到货真价实、品质上乘的特产,选对店铺至关重要。今天,就让我们一起探索几家被本地人私藏多年的地道特产好店,…...

微信聊天记录导出终极指南:WeChatMsg项目完整解决方案
微信聊天记录导出终极指南:WeChatMsg项目完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

工业部署实战:用YOLOv6-S在T4 GPU上跑出869 FPS的保姆级量化教程
工业级YOLOv6-S量化部署实战:T4 GPU实现869 FPS的终极优化指南 当目标检测遇上边缘计算,如何在有限算力下榨干每一分性能?本文将带你深入YOLOv6-S的量化部署全流程,从模型导出到TensorRT优化,手把手实现T4 GPU上的极致…...

XUnity.AutoTranslator:如何让外语游戏瞬间变成你的母语?
XUnity.AutoTranslator:如何让外语游戏瞬间变成你的母语? 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过精彩的游戏剧情?面对日语、英语…...

微信小程序图片裁剪终极指南:如何用we-cropper解决你的图片处理难题
微信小程序图片裁剪终极指南:如何用we-cropper解决你的图片处理难题 【免费下载链接】we-cropper 微信小程序图片裁剪工具 项目地址: https://gitcode.com/gh_mirrors/we/we-cropper 还在为微信小程序中的图片裁剪功能而烦恼吗?你是否遇到过图片显…...

gifuct-js:前端GIF动画处理的神奇手术刀,让动态图片解析变得轻松自如
gifuct-js:前端GIF动画处理的神奇手术刀,让动态图片解析变得轻松自如 【免费下载链接】gifuct-js Fastest javascript .GIF decoder/parser 项目地址: https://gitcode.com/gh_mirrors/gi/gifuct-js 你是否曾为网页中GIF动画加载缓慢、内存占用高…...

计算机校招求职深度解析:从零基础到一线大厂的全方位学习路线
计算机校招求职深度解析:从零基础到一线大厂的全方位学习路线 【免费下载链接】InterviewGuide 🔥🔥「InterviewGuide」是阿秀从校园->职场多年计算机自学过程的记录以及学弟学妹们计算机校招&秋招经验总结文章的汇总,包括…...