LTO优化详解
嵌入式开发过程中的LTO优化是什么意思?能够用来解决什么问题?它都优化了哪些?仅开启LTO真的可以优化SIZE的问题吗? 请分别回答我刚才提到的问题?
嗯,用户问关于嵌入式开发中的LTO优化,我需要详细解释这个概念。首先,我得回忆一下LTO的全称是链接时优化,对吧?那它到底是什么意思呢?应该是在链接阶段进行的优化,而传统的优化是在编译每个源文件的时候进行的。所以LTO允许编译器看到整个程序的代码,从而进行跨模块的优化。
接下来,用户问LTO能解决什么问题。可能需要提到代码体积的减少,执行效率的提升,还有内联函数跨模块的可能性。因为在传统编译中,每个文件独立编译,编译器看不到其他模块的代码,所以优化受限。而LTO可以在链接时分析所有代码,进行更全局的优化,比如去掉未使用的函数,合并重复代码之类的。
然后优化了哪些方面呢?比如函数内联跨模块,删除死代码,优化全局变量,指令调度和寄存器分配可能更高效。这些都需要具体举例说明,让用户更容易理解。
关于是否仅开启LTO就能优化SIZE的问题,这里要小心回答。应该承认LTO确实能有效减少代码体积,尤其是通过删除未引用的代码和更积极的内联。但也要提醒用户,可能需要结合其他优化选项,比如GCC的-Os或者Clang的-Oz,才能达到最佳效果。此外,代码结构本身的影响也不能忽视,比如是否有冗余代码或者未使用的函数。
用户可能是在嵌入式开发中遇到代码体积过大的问题,所以想了解LTO是否是一个有效的解决方案。他们可能已经尝试过其他优化方法,但效果不明显,或者听说LTO有帮助但不确定具体机制。需要解释清楚LTO的作用和限制,避免他们有过高的期望,或者忽略其他必要的优化步骤。
另外,用户可能关心开启LTO的潜在问题,比如编译时间增加,或者对调试的影响。虽然问题中没有直接提到,但回答时可以适当提及,比如编译时间变长,调试信息可能受影响,但主要问题还是围绕他们提到的几点。
需要确保回答准确,结构清晰,分点回答每个问题。同时使用技术术语时要适当解释,让不同水平的读者都能理解。例如,解释“跨模块内联”时,可以举例子说明函数在另一个文件中的调用如何被内联优化。
最后,确认回答是否覆盖了所有问题,没有遗漏。用户明确要求分别回答每个问题,所以结构上需要分点,每个问题对应一个部分。同时保持语言简洁,避免冗长。
1. 嵌入式开发中的 LTO 优化是什么?
LTO(Link-Time Optimization,链接时优化)是一种编译器优化技术,允许在链接阶段(而非传统的编译阶段)对代码进行全局优化。传统编译流程中,每个源文件(.c)被单独编译成目标文件(.o),优化仅限于单个文件内的代码;而 LTO 在链接时会将所有目标文件的中间表示(如 GCC 的 GIMPLE、LLVM 的 IR)合并,再进行跨模块的优化。
2. LTO 能解决什么问题?
LTO 主要用于解决以下问题:
- 代码体积(Size)优化:删除未被引用的函数、变量或冗余代码。
- 性能优化:跨模块内联函数、优化全局数据流、调整指令调度等。
- 跨模块优化瓶颈:传统编译无法跨文件优化,LTO 打破模块边界,实现全局优化。
- 减少冗余:合并重复代码(如模板实例化、常量数据)。
3. LTO 具体优化了哪些内容?
LTO 的典型优化包括:
- 跨模块内联(Cross-Module Inlining):将其他模块中的函数内联到调用处,减少函数调用开销。
- 死代码消除(Dead Code Elimination):删除未被调用的函数或未使用的全局变量。
- 全局常量传播:优化跨文件的常量使用。
- 循环和指令优化:基于全局信息重新调度指令或优化循环。
- 符号合并:合并相同功能的重复代码或数据。
4. 仅开启 LTO 能否优化代码体积(Size)?
可以显著优化,但需结合其他手段:
- LTO 本身对 Size 的优化效果:
- 通过删除未使用的代码(如库函数、未调用的静态函数)和冗余数据,通常能减少 5%~20% 的代码体积(取决于项目结构)。
- 跨模块内联可能略微增加代码体积(若过度内联),但通常利大于弊。
- 需配合其他优化选项:
- 单独开启 LTO 可能不够,需结合编译器的
-Os(优化 Size)或-Oz(更激进的 Size 优化)。 - 需确保代码本身无冗余(如未使用的库链接)。
- 单独开启 LTO 可能不够,需结合编译器的
- 实际效果依赖代码结构:
- 若代码模块化程度高、存在大量未使用的库函数,LTO 效果显著;反之,若代码本身紧凑,优化空间有限。
总结
LTO 是嵌入式开发中优化代码体积和性能的有效手段,尤其适合资源受限的场景。但需权衡编译时间(LTO 会增加链接时间)和潜在的调试复杂性(优化后代码可能与源码差异较大)。通常建议结合 -Os 和 LTO 以达到最佳 Size 优化效果。
如果我想优化bin文件的size,我需要打开lto吗?
好的,用户之前已经询问过LTO优化在嵌入式开发中的作用,现在他问是否需要开启LTO来优化bin文件的体积。我需要先回顾之前的对话,确保回答一致。用户可能是在实际项目中遇到了体积过大的问题,想知道LTO是否有效。
首先,我应该明确回答他的问题:是的,开启LTO通常有助于减小bin文件的体积。但需要结合其他优化选项,比如-Os,同时要注意可能的副作用,比如编译时间增加和调试难度。用户可能想知道具体的步骤和注意事项,所以需要详细说明如何开启LTO以及相关的最佳实践。
用户可能没有提到的深层需求是,如何在不影响性能的情况下最大化体积优化,或者如何平衡编译时间和体积优化。因此,我需要提到结合使用LTO和-Os,并讨论不同编译器的配置方法,比如GCC和Clang的不同参数。
另外,用户可能担心开启LTO后的潜在问题,比如代码行为变化或调试信息不准确,所以需要提醒他们测试和验证的重要性,尤其是在资源受限的嵌入式环境中。还可能需要考虑是否所有依赖库都支持LTO,避免链接错误。
最后,总结一下步骤,明确开启LTO的方法、配合的优化选项、注意事项以及验证效果的方式,这样用户能有一个清晰的行动指南。
是的,在大多数情况下,开启 LTO(Link-Time Optimization)可以有效优化二进制文件(bin 文件)的体积,尤其是对于嵌入式系统中资源受限的场景。但具体效果和实现方式需要结合以下关键点来理解:
1. LTO 对代码体积的优化原理
- 跨模块死代码消除:
传统编译中,编译器只能优化单个源文件(.c)内部的未使用代码,而 LTO 在链接阶段可以看到所有模块的代码,从而删除整个项目中未被调用的函数、变量,甚至是第三方库中的冗余代码。 - 符号合并与常量传播:
合并重复的代码片段(如多次实例化的模板或常量数据),并通过全局分析优化常量使用。 - 内联与指令优化:
跨模块内联可能减少函数调用开销,但也可能略微增加代码体积(取决于内联策略)。
2. 如何开启 LTO 以优化 Size?
- 编译器选项:
在编译和链接时均需启用 LTO,例如在 GCC 或 Clang 中:# GCC CFLAGS += -flto -Os LDFLAGS += -flto -Os# Clang/LLVM CFLAGS += -flto=thin -Oz LDFLAGS += -flto=thin -Oz-Os(优化体积)或-Oz(更激进的体积优化)需与 LTO 配合使用。
- 工具链支持:
确保编译器、链接器均支持 LTO(现代工具链如 GCC 9+、Clang 12+ 已默认支持)。
3. LTO 的优化效果
- 典型体积缩减:
根据代码结构和依赖库的不同,LTO 通常可减少 5%~20% 的 bin 文件体积。- 例如:某嵌入式项目原始 bin 大小为 100KB,开启 LTO +
-Os后可能降至 85KB。
- 例如:某嵌入式项目原始 bin 大小为 100KB,开启 LTO +
- 案例对比:
优化方式 bin 体积 说明 无优化 ( -O0)120KB 未优化,体积最大 仅 -Os100KB 单文件优化,效果有限 -Os+ LTO85KB 跨模块优化,效果显著
4. 注意事项与潜在问题
- 编译时间增加:
LTO 需要在链接时进行全局优化,可能导致链接时间显著延长(尤其是大型项目)。 - 调试难度:
优化后的代码可能与源代码行号不对应,增加调试复杂度(需保留调试符号或禁用 LTO 调试)。 - 兼容性问题:
某些旧版编译器或第三方库可能不兼容 LTO(需验证是否支持-flto)。 - 过度内联的风险:
内联过多可能反而增大体积,可通过-finline-limit或调整内联策略控制。
5. 最佳实践
- 组合优化选项:
- 始终将 LTO 与
-Os(优化体积)或-Oz(激进体积优化)结合使用。 - 避免与
-O3(性能优化)混用,可能因内联过多导致体积膨胀。
- 始终将 LTO 与
- 验证未使用代码:
使用-ffunction-sections和-fdata-sections,配合链接器选项--gc-sections,进一步删除未使用的代码段。CFLAGS += -ffunction-sections -fdata-sections LDFLAGS += -Wl,--gc-sections - 测试与对比:
- 对比开启/关闭 LTO 的 bin 文件体积(
size工具或arm-none-eabi-size)。 - 确保功能正确性(某些优化可能破坏代码逻辑)。
- 对比开启/关闭 LTO 的 bin 文件体积(
结论
如果目标是优化 bin 文件体积,开启 LTO 是必要且有效的,但需注意以下几点:
- 必须与
-Os或-Oz配合使用,单独开启 LTO 效果有限。 - 验证依赖库的 LTO 兼容性,避免链接错误。
- 权衡编译时间和体积优化,尤其在迭代开发中。
通过合理配置,LTO 可以显著减少嵌入式系统的存储占用,是资源优化的重要手段。
你也提到了,避免与 -O3(性能优化)混用,可能因内联过多导致体积膨胀,那我想问,开LTO和O3有什么区别呢?他们两个应用场景是什么样的呢?
好的,我需要仔细思考用户的问题。用户之前已经询问了LTO优化以及如何通过LTO来减少二进制文件的体积,现在他们进一步询问关于LTO和-O3的区别以及它们的应用场景,特别是为什么避免混合使用两者。用户可能是在嵌入式开发中,关心如何平衡代码大小和性能优化,同时想了解不同编译器选项的适用情况。
首先,我需要回顾LTO和-O3的基本概念。LTO(链接时优化)允许在链接阶段进行跨模块的优化,而-O3是GCC等编译器的一个优化级别,侧重于性能优化,可能会增加代码体积。用户想知道两者的区别,以及何时使用它们。
接下来,要分析两者的优化目标和策略。LTO主要是在链接时进行全局优化,消除死代码,合并符号等,这对减少体积有帮助。-O3则是在编译时进行更激进的优化,如循环展开、向量化、内联等,这可能会增加代码大小,但提升运行速度。
然后,需要明确两者的应用场景。用户可能想知道在什么情况下应该优先考虑体积(使用LTO和-Os)或在什么情况下需要最大化性能(使用-O3)。同时,用户提到混合使用的问题,需要解释为什么-O3与LTO一起使用可能导致体积膨胀,尤其是内联过多的情况。
还要考虑用户的潜在疑问,比如是否在某些情况下可以同时使用LTO和-O3,或者是否有其他优化选项的组合可以同时兼顾体积和性能。此外,用户可能希望了解具体的例子或数据,说明不同组合的效果。
需要确保回答结构清晰,分点说明两者的区别、优化策略、应用场景,以及混合使用的后果。同时,提供实际应用中的建议,帮助用户根据项目需求选择合适的配置。
最后,检查是否有遗漏点,比如调试影响、编译时间、兼容性问题等,但根据用户当前的问题,可能不需要深入这些细节,除非直接相关。要确保语言通俗易懂,避免过于技术化,但保持准确性。
在嵌入式开发中,LTO(Link-Time Optimization)和 -O3 优化选项的核心区别在于优化目标和策略,它们的应用场景取决于项目需求是优先代码体积(Size)还是运行性能(Performance)。以下是两者的对比及使用场景分析:
1. LTO 和 -O3 的本质区别
| 特性 | LTO(链接时优化) | -O3(编译时性能优化) |
|---|---|---|
| 优化阶段 | 链接阶段(跨模块全局优化) | 编译阶段(单文件内部优化) |
| 核心目标 | 减少代码体积(Size)和全局性能提升 | 最大化运行性能(Performance) |
| 主要策略 | 删除未使用代码、跨模块内联、符号合并 | 循环展开、向量化、激进内联、指令重排 |
| 对 Size 的影响 | 显著减少体积(消除冗余代码) | 可能增大体积(如循环展开、过度内联) |
| 对性能影响 | 中等性能提升(依赖全局优化) | 最大性能提升(依赖硬件加速和指令级优化) |
| 编译时间 | 增加链接时间(需全局分析) | 增加编译时间(单文件复杂优化) |
2. 为什么避免同时使用 LTO 和 -O3?
-O3 的优化策略可能导致 代码体积膨胀,而 LTO 的目标是 缩减体积,二者组合可能互相冲突:
- 内联冲突:
-O3会激进内联函数(即使跨模块),而 LTO 也会尝试跨模块内联。二者叠加可能导致 过度内联,反而增大体积。 - 循环展开问题:
-O3的循环展开(Loop Unrolling)会显著增加代码量,LTO 无法消除这种主动膨胀的代码。 - 优化目标矛盾:
-O3优先性能,LTO 优先体积,混合使用可能导致优化方向不明确,最终效果可能“既不够快,也不够小”。
3. 应用场景与推荐配置
(1) 优先优化代码体积(Size)的场景
- 典型场景:
资源受限的嵌入式设备(Flash/RAM 较小)、需降低存储成本、低功耗设备(代码体积小可减少内存访问能耗)。 - 推荐配置:
CFLAGS += -Os -flto # 优化体积 + 链接时优化 LDFLAGS += -Os -flto- 附加选项:
使用-ffunction-sections -fdata-sections和--gc-sections进一步删除未使用代码。 - 效果:
Size 最小化,性能可能略优于-O0,但弱于-O3。
- 附加选项:
(2) 优先优化性能(Performance)的场景
- 典型场景:
实时性要求高的系统(如电机控制、高频信号处理)、计算密集型任务(图像处理、AI 推理)。 - 推荐配置:
CFLAGS += -O3 -march=native # 最大化性能,启用硬件指令集(如 ARM NEON) LDFLAGS += -O3- 附加选项:
使用-funroll-loops(循环展开)或-ftree-vectorize(自动向量化)。 - 注意:
若代码体积膨胀导致 Flash 不足,需权衡性能与资源限制。
- 附加选项:
(3) 平衡 Size 和 Performance 的场景
- 折中方案:
CFLAGS += -O2 -flto # 中等性能优化 + 链接时优化 LDFLAGS += -O2 -flto- 效果:
-O2的性能优化比-Os更强,同时 LTO 抑制部分体积膨胀。
- 效果:
4. 实验对比(示例)
假设某嵌入式项目的代码特性如下:
- 功能:传感器数据处理 + 通信协议栈
- 硬件:ARM Cortex-M4,256KB Flash
| 优化配置 | bin 体积 | 运行速度(相对值) | 适用场景 |
|---|---|---|---|
-O0(无优化) | 120KB | 1.0x(基准) | 调试阶段 |
-Os + LTO | 80KB | 1.8x | 资源受限设备 |
-O3 | 150KB | 3.5x | 高性能计算 |
-O2 + LTO | 95KB | 2.5x | 平衡性能与体积 |
5. 何时可以尝试混合使用 LTO 和 -O3?
在满足以下条件时,可谨慎尝试组合使用:
- 硬件资源充足:Flash 空间足够容纳代码膨胀。
- 需极致性能:如高性能边缘计算设备。
- 针对性优化:通过
__attribute__((noinline))或-finline-limit限制内联,避免体积失控。
示例配置:
CFLAGS += -O3 -flto -finline-limit=50 # 限制内联深度
LDFLAGS += -O3 -flto
总结
- LTO 的核心价值是减少体积,适合资源受限的嵌入式场景。
-O3的核心价值是提升性能,适合计算密集型任务。- 二者混合使用需谨慎,仅在资源充足且需权衡性能与体积时尝试。
- 实际项目中,优先通过
-Os + LTO或-O2 + LTO找到平衡点。
请给我详细的解释一下lto在link阶段是怎么优化的?
嗯,用户问的是LTO在链接阶段是怎么优化的,这个问题需要详细解释LTO的工作原理和优化过程。之前已经讨论过LTO的基本概念、解决的问题以及和O3的区别,现在用户想更深入理解链接阶段的优化机制。
首先,用户可能已经知道LTO是在链接时进行的优化,但需要更具体的步骤。应该从传统编译流程和LTO流程的对比入手,说明为什么链接阶段优化能带来优势。比如传统编译每个文件独立优化,无法跨模块,而LTO合并所有中间代码进行全局优化。
接下来需要分步骤详细解释LTO在链接阶段的优化过程。比如中间代码生成、全局分析、具体优化手段(死代码消除、内联、常量传播等),以及符号解析和生成最终代码。每个步骤要具体,可能需要举例说明,比如跨模块内联如何减少函数调用开销,或者死代码消除如何删除未使用的函数。
另外,用户可能关心LTO如何影响最终生成的二进制文件,比如体积减少的具体原因。需要强调全局视角带来的优化机会,比如库函数中的无用代码在传统编译中无法删除,而LTO可以做到。
还要注意用户可能的疑问点,比如LTO如何管理中间代码,不同编译器(GCC和Clang)的实现差异,以及优化后的代码如何链接成最终文件。这部分需要简明扼要,避免过于技术化,但又要足够详细说明机制。
最后,可以举一个具体例子,比如一个项目中有多个模块,LTO如何发现并优化这些模块之间的冗余代码,帮助用户形象理解。同时,提及潜在的问题,比如编译时间增加或调试困难,但用户当前问题可能更关注优化机制本身,这部分可以简要带过。
总之,回答需要结构清晰,分点说明,结合之前的讨论内容,深入技术细节,但保持易于理解。确保用户不仅知道LTO在链接阶段优化,还理解其具体步骤和背后的原理。
好的!LTO(Link-Time Optimization,链接时优化)的核心在于将传统编译流程中分散的优化过程集中到链接阶段,利用全局视角对代码进行深度优化。以下是它在链接阶段的详细优化机制:
1. 传统编译流程 vs. LTO 流程
(1) 传统编译流程
- 步骤:
- 单文件编译:每个
.c文件独立编译为.o目标文件,编译器仅对单个文件进行优化(如-O2)。 - 链接阶段:链接器简单合并
.o文件,生成最终可执行文件。
- 单文件编译:每个
- 局限:
- 优化仅限单个文件,无法跨模块分析(如无法内联其他文件的函数)。
- 无法全局删除未使用的代码(如库中未被调用的函数)。
(2) LTO 流程
- 步骤:
- 生成中间代码:编译时,每个
.c文件生成包含**中间表示(IR)**的目标文件(如 GCC 的GIMPLE或 LLVM 的Bitcode)。 - 链接阶段优化:链接器将所有 IR 合并成一个全局模块,进行跨文件优化。
- 生成最终代码:优化后的 IR 被编译为机器码,输出最终二进制文件。
- 生成中间代码:编译时,每个
- 关键优势:
- 全局视角:能看到所有模块的代码和数据结构。
- 跨模块优化:打破文件边界,实现传统编译无法完成的优化。
2. LTO 在链接阶段的具体优化步骤
(1) 中间代码的合并
- 输入:所有目标文件中的中间表示(IR)。
- 合并过程:
- 链接器将分散的 IR 合并为一个完整的“虚拟大模块”,包含所有函数、变量和控制流信息。
- 例如:
main.c调用了utils.c的函数,此时两者的 IR 被合并,编译器能直接分析跨文件的调用关系。
(2) 全局分析(Global Analysis)
链接器(或集成的编译器插件)对合并后的 IR 进行全局分析:
- 数据流分析:追踪变量和常量的传递路径。
- 调用图构建:建立所有函数之间的调用关系图(Call Graph)。
- 依赖分析:识别未使用的函数、变量和代码段。
(3) 具体优化手段
基于全局分析结果,LTO 实施以下典型优化:
| 优化类型 | 具体操作 | 示例 |
|---|---|---|
| 跨模块内联(Cross-Module Inlining) | 将其他模块中的小函数内联到调用处,消除函数调用开销。 | 若 main.c 调用 utils.c 的 add(),LTO 可将 add() 的代码插入 main。 |
| 死代码消除(Dead Code Elimination) | 删除整个项目中未被调用的函数、未使用的全局变量,甚至第三方库中的冗余代码。 | 库函数 sqrt() 若未被调用,会被完全删除。 |
| 全局常量传播(Constant Propagation) | 跨文件传播常量值,优化条件判断和计算。 | 若 config.h 定义 DEBUG=0,所有 if (DEBUG) 分支会被删除。 |
| 循环优化(Loop Optimization) | 基于全局数据流分析,对循环进行展开、合并或并行化。 | 合并多个文件中的相似循环,减少冗余指令。 |
| 符号合并(Symbol Merging) | 合并相同功能的重复代码或数据(如 C++ 模板的多次实例化)。 | 多个模块实例化的 std::vector<int> 被合并为一个实现。 |
| 间接调用优化(Indirect Call Optimization) | 将虚函数调用或函数指针转换为直接调用(如果目标唯一)。 | C++ 虚函数调用若实际指向唯一实现,会转为直接调用。 |
(4) 符号解析与重定位
- 精确符号绑定:在优化后的代码中重新解析所有函数和变量的地址。
- 消除冗余重定位:传统链接中,重定位信息可能因优化而失效,LTO 会重新生成。
(5) 生成目标代码
将优化后的 IR 编译为目标平台的机器码,生成最终的二进制文件(如 .bin 或 .elf)。
3. 关键优化场景示例
(1) 删除未使用的库函数
- 传统编译:链接标准库(如
libc.a)时,会包含整个库的目标文件(如printf.o、malloc.o)。 - LTO 优化:若项目中未使用
printf(),LTO 会分析到这一点,完全删除printf.o中的代码,而传统编译会保留整个目标文件。
(2) 跨模块内联
// utils.c
int add(int a, int b) { return a + b; }// main.c
int main() { int x = add(1, 2); return x;
}
- 传统编译:
main.c中调用add()需通过函数跳转。 - LTO 优化:将
add()内联到main()中,直接变为int x = 1 + 2;,最终优化为return 3;。
(3) 全局常量折叠
// config.c
const int MAX_SIZE = 1024;// module.c
void process_data() {if (MAX_SIZE > 1000) { // 代码块 A } else { // 代码块 B }
}
- LTO 优化:直接删除
else分支(因为MAX_SIZE=1024),仅保留代码块 A。
4. LTO 的技术实现差异(GCC vs. LLVM)
- GCC 的 LTO:
- 使用
GIMPLE中间表示,存储在.o文件的特殊段中。 - 链接时通过
lto1插件执行优化。
- 使用
- LLVM 的 LTO(ThinLTO 与 FullLTO):
- FullLTO:合并所有模块的 IR,进行完全全局优化(类似 GCC)。
- ThinLTO:部分合并 IR,通过并行化减少内存占用和编译时间,适合大型项目。
5. LTO 的代价
- 编译时间:链接阶段需处理大量 IR,时间显著增加(尤其是 FullLTO)。
- 内存占用:合并所有 IR 可能消耗大量内存(ThinLTO 优化此问题)。
- 调试复杂性:优化后的代码可能与源码行号不对应,需配合
-g调试符号使用。
总结
LTO 在链接阶段的优化本质是将编译器的优化能力从单文件扩展到整个项目,通过全局分析实现传统编译无法完成的深度优化。它特别适合嵌入式开发中资源受限的场景,但也需权衡编译时间和调试成本。
你上一条回答里面有提到中间表示(IR),我应该怎么理解它呢?它跟我们编译的四个步骤(预处理,编译,汇编,链接)有什么关系呢?
好的,我现在需要帮助用户理解中间表示(IR)以及它与传统编译四个步骤的关系。用户之前已经询问了LTO在链接阶段的优化,现在他们想更深入理解IR在整个编译过程中的位置和作用。
首先,用户可能已经知道编译的四个步骤:预处理、编译、汇编、链接。但IR可能是在这些步骤中的哪个阶段出现呢?需要解释清楚IR属于编译阶段的一部分,特别是编译器前端生成IR,后端将IR转换为目标代码。
用户可能混淆了IR和汇编代码,需要明确两者的区别。IR是编译器生成的中间层,独立于具体机器架构,而汇编是特定于目标平台的低级代码。需要举例说明,比如LLVM的IR和GCC的GIMPLE,说明它们的作用。
接下来,需要将IR与传统四个步骤对应起来。预处理处理宏和头文件,编译阶段分为前端和后端,前端生成IR,后端优化并生成汇编。汇编阶段将汇编代码转为机器码,链接阶段处理多个目标文件。而LTO在链接阶段使用IR进行全局优化,这点需要强调,说明传统编译在链接时已经没有IR,而LTO保留IR到链接阶段,从而进行跨模块优化。
用户可能还关心IR存在的意义,比如为什么需要这个中间层。需要解释IR的作用,如跨平台、优化便利、支持多语言等。例如,LLVM的IR允许不同前端生成相同的IR,便于优化和跨平台。
此外,用户提到的LTO流程中,IR在链接阶段被合并和优化,这里需要与传统流程对比,说明传统编译每个源文件独立转为汇编,而LTO保留IR到链接阶段,合并后进行优化,再生成最终代码。
还需要注意用户可能存在的疑问,比如IR和抽象语法树(AST)的区别。需要指出AST是更接近源代码的结构,而IR是更接近机器码的中间形式,通常更低级且适合优化。
总结时,要确保用户明白IR是编译过程中的中间产物,连接前端和后端,使得优化更灵活,特别是LTO利用IR在链接时进行全局优化,突破传统编译的限制。同时,强调IR在跨平台和多语言支持中的重要性,以及它如何影响编译流程,特别是链接阶段的优化。
1. 中间表示(IR)的本质与作用
中间表示(Intermediate Representation,IR)是编译器在源代码与机器码之间生成的一种中间抽象形式,类似于“翻译过程中的过渡语言”。它既保留了源代码的语义(如函数、变量、控制流),又抹去了语法细节(如括号、分号),同时为后续优化和代码生成提供统一的结构化数据。以下是理解 IR 的几个关键点:
| 特性 | 说明 |
|---|---|
| 抽象层级 | 介于高级语言(如 C/C++)和汇编之间,独立于具体硬件架构。 |
| 核心目标 | 为编译器优化和跨平台代码生成提供统一的中间层。 |
| 表现形式 | 可能是文本(如 LLVM IR)或二进制格式(如 GCC 的 GIMPLE)。 |
| 与硬件无关性 | 同一份 IR 可生成不同架构(ARM/x86)的机器码,实现“一次优化,多平台适配”。 |
2. IR 与传统编译四步骤的关系
传统编译流程分为 预处理 → 编译 → 汇编 → 链接 四个阶段,而 IR 主要在编译阶段生成和使用。以下是 IR 与各阶段的具体关联:
(1) 预处理(Preprocessing)
- 任务:处理宏、条件编译(
#ifdef)、头文件包含等。 - 与 IR 的关系:
预处理后的代码仍是高级语言(如展开宏的.i文件),不涉及 IR。
(2) 编译(Compilation)
-
任务:将预处理后的代码转换为汇编或机器码。
-
内部细分:
- 前端(Frontend):解析源代码,生成 AST(抽象语法树),最终转换为 IR。
- 示例:Clang(LLVM 前端)将 C/C++ 代码转换为 LLVM IR。
- 优化器(Optimizer):对 IR 进行优化(如死代码删除、循环展开)。
- 后端(Backend):将优化后的 IR 转换为目标平台的汇编代码(
.s)。
源代码 → AST → IR → 优化后的 IR → 汇编代码 - 前端(Frontend):解析源代码,生成 AST(抽象语法树),最终转换为 IR。
-
关键点:
- IR 是编译阶段的核心产物,优化和跨平台适配均基于 IR。
- 传统编译流程中,IR 仅在编译阶段内部使用,生成汇编后即被丢弃。
(3) 汇编(Assembly)
- 任务:将汇编代码(
.s)转换为机器码(.o目标文件)。 - 与 IR 的关系:
此阶段处理的是低级汇编指令,不再涉及 IR。
(4) 链接(Linking)
- 任务:合并多个目标文件(
.o)和库,解析符号引用,生成最终可执行文件。 - 传统流程与 LTO 的区别:
- 传统链接:直接处理机器码,无 IR 参与。
- LTO 链接:目标文件中保留了 IR,链接时重新合并并优化 IR,再生成机器码。
3. IR 在 LTO 中的特殊角色
LTO 的关键创新是将 IR 的生存期从编译阶段扩展到链接阶段,从而支持全局优化:
| 阶段 | 传统流程 | LTO 流程 |
|---|---|---|
| 编译阶段 | 生成目标文件(含机器码) | 生成目标文件(含 IR + 机器码) |
| 链接阶段 | 直接合并机器码,无优化 | 提取所有 IR,合并后全局优化,再生成机器码 |
- 示例:
- 编译时,每个
.c文件生成一个包含 IR 的.o文件。 - 链接时,链接器收集所有
.o中的 IR,合并后进行跨模块优化,最终输出优化后的机器码。
- 编译时,每个
4. 为什么需要 IR?
(1) 解耦前端与后端
- 前端(解析不同语言)和 后端(生成不同架构代码)只需关注 IR,无需直接交互。
- 例如:Clang(C/C++ 前端)和 LLVM 后端(支持 x86/ARM)通过 IR 通信。
(2) 优化集中化
- 所有优化(如内联、常量传播)只需针对 IR 实现一次,即可应用于所有语言和平台。
- 例如:LLVM 的优化器对 IR 进行通用优化,无需为 C、Rust 等语言重复实现。
(3) 支持跨模块优化
- LTO 依赖 IR 在链接阶段的全局分析能力,突破单文件优化限制。
5. 具体 IR 示例
(1) LLVM IR
- 文本格式示例:
define i32 @add(i32 %a, i32 %b) {%sum = add i32 %a, %bret i32 %sum } - 特点:
- 人类可读,类似低级语言但硬件无关。
- 强类型化(如
i32表示 32 位整数)。
(2) GCC 的 GIMPLE
- 内部表示:
三地址码(Three-Address Code)形式,例如:t1 = a + b; return t1; - 特点:
- 用于 GCC 的中间优化阶段,最终转换为 RTL(Register Transfer Language)生成汇编。
6. IR 与汇编代码的对比
| 特性 | IR | 汇编代码 |
|---|---|---|
| 抽象层级 | 高级语义 + 低级操作混合 | 完全低级(寄存器、指令) |
| 硬件相关性 | 无关 | 高度依赖特定架构(如 ARM) |
| 优化目标 | 跨平台优化 | 特定平台性能优化 |
| 可读性 | 较高(结构化) | 较低(直接对应机器指令) |
总结
- IR 是编译器的“中间语言”,是优化和代码生成的核心枢纽。
- 与传统编译四步骤的关系:
- IR 在编译阶段生成,链接阶段(LTO 模式下)被重新提取和优化。
- 传统流程中 IR 不可见,LTO 通过保留 IR 到链接阶段实现全局优化。
- IR 的价值:
- 解耦编译器的前端与后端,支持多语言、多平台。
- 为高级优化(如 LTO)提供基础设施。
你又提到了 GCC 的 GIMPLE,GIMPLE是什么意思?
嗯,用户问到了GCC的GIMPLE是什么意思。之前讨论过中间表示(IR),而GIMPLE是GCC的IR之一,所以他们可能是在深入理解不同编译器的IR实现。用户可能是学生、开发者或对编译器内部机制感兴趣的人,需要了解GIMPLE的具体作用和结构。
首先,我需要解释GIMPLE的定义。GIMPLE是GCC中的一个中间表示,属于三地址码形式,用于在编译过程中进行优化。要说明GIMPLE的特点,比如简单、线性结构,每个语句最多三个操作数,便于优化。
然后,需要将GIMPLE放在GCC的编译流程中,说明它是在前端生成AST后转换而来,是高级IR,之后会进一步转换为RTL。这部分需要清晰,让用户明白GIMPLE的位置和作用。
接下来,举例说明GIMPLE的结构,比如一个简单的C函数如何转换成GIMPLE代码,展示其具体形式。这有助于用户直观理解。
还要对比GIMPLE与其他IR,比如LLVM的IR,指出GIMPLE更接近源代码,而LLVM IR更接近机器码。说明GCC的优化主要在GIMPLE和RTL阶段进行,而LLVM优化在IR层。
最后,总结GIMPLE的作用和重要性,强调其在GCC优化流程中的关键地位,以及作为中间表示如何帮助编译器实现跨平台和优化。确保用户理解GIMPLE不仅是技术术语,而是实际影响编译过程的组成部分。
GCC 的 GIMPLE 是 GCC 编译器在编译过程中使用的一种中间表示(IR),它的名字来源于“GNU IMPLEmented”(GNU 实现的简化中间表示)。GIMPLE 的设计目标是将复杂的源代码转换为一种简化的、适合优化的中间形式,以便编译器在此阶段执行跨语言、跨平台的优化。
1. GIMPLE 的核心特点
GIMPLE 是一种**三地址码(Three-Address Code)**的变体,其核心特性包括:
| 特性 | 说明 |
|---|---|
| 简化操作 | 每个语句最多包含三个操作数(例如 a = b + c),降低代码复杂度。 |
| 控制流扁平化 | 将复杂的控制结构(如循环、条件分支)转换为简单的跳转和标签形式。 |
| 无副作用原子操作 | 确保每条语句是原子的(例如,函数调用、副作用操作会被隔离为独立语句)。 |
| 与语言无关 | 无论是 C、C++、Fortran 还是其他语言,最终都会转换为统一的 GIMPLE 形式。 |
2. GIMPLE 在 GCC 编译流程中的位置
GCC 的编译流程可分为以下几个阶段,GIMPLE 是其中的关键中间步骤:
(1) 前端处理(Frontend)
- 任务:将源代码(如 C/C++)解析为抽象语法树(AST)。
- 示例:C 代码
int x = a + b * c;→ 生成 AST 表示。
(2) 转换为 GIMPLE
- 任务:将 AST 转换为 GIMPLE 中间表示。
- 示例:
→ 转换为 GIMPLE:// 原始代码 int func(int a, int b) {if (a > 0)return a + b;elsereturn a - b; }func (int a, int b) {int D.1234;if (a > 0) goto <true>; else goto <false>;<true>:D.1234 = a + b;return D.1234;<false>:D.1234 = a - b;return D.1234; }- 特点:
- 条件语句
if-else被转换为goto跳转标签。 - 所有表达式拆分为原子操作(如
D.1234 = a + b)。
- 条件语句
- 特点:
(3) GIMPLE 优化
在 GIMPLE 层执行优化,例如:
- 常量传播:替换已知常量值。
- 死代码删除:移除不可达的代码块。
- 内联展开:将小函数内联到调用处。
(4) 转换为 RTL
- GIMPLE 优化后,进一步转换为寄存器传输语言(RTL),这是一种更接近机器码的中间表示。
- RTL 会再次进行低级优化(如指令调度、寄存器分配)。
(5) 生成汇编代码
最终将 RTL 转换为目标平台的汇编代码(如 x86、ARM)。
3. GIMPLE 的设计目标
(1) 简化优化
通过限制语句的复杂度(三地址码形式),使优化算法更容易实现,例如:
- 公共子表达式消除:发现重复计算的表达式。
- 循环优化:扁平化的控制流便于分析循环边界。
(2) 跨语言统一
不同语言(C/C++/Fortran 等)的前端生成统一的 GIMPLE,共享同一套优化逻辑。
(3) 支持链接时优化(LTO)
GCC 的 LTO 依赖于将 GIMPLE 序列化到目标文件(.o)中,链接时重新提取并合并优化。
4. GIMPLE 与其他 IR 的对比
(1) GIMPLE vs. LLVM IR
| 特性 | GIMPLE | LLVM IR |
|---|---|---|
| 抽象层级 | 较高(接近源代码逻辑) | 较低(接近机器码,显式类型和内存操作) |
| 优化阶段 | 早期优化(如内联、常量传播) | 全阶段优化(从高级到低级) |
| 表现形式 | 三地址码 + 扁平控制流 | 静态单赋值(SSA)形式 + 基本块 |
| 硬件关联性 | 完全硬件无关 | 硬件无关,但支持目标平台特性描述 |
(2) GIMPLE vs. RTL
| 特性 | GIMPLE | RTL |
|---|---|---|
| 抽象层级 | 高级中间表示(逻辑操作) | 低级中间表示(寄存器、指令) |
| 优化目标 | 逻辑优化(如死代码删除) | 机器相关优化(如指令调度) |
| 与硬件的关联 | 无关 | 依赖目标平台架构 |
5. GIMPLE 的实际示例
(1) 原始 C 代码
int sum(int n) {int result = 0;for (int i = 1; i <= n; i++) {result += i;}return result;
}
(2) 转换为 GIMPLE
sum (int n) {int result;int i;result = 0;i = 1;goto loop_check;loop_body:result = result + i;i = i + 1;loop_check:if (i <= n) goto loop_body; else goto loop_exit;loop_exit:return result;
}
- 特点:
for循环被拆分为loop_check标签和goto跳转。- 所有操作均为三地址码形式。
(3) GIMPLE 优化后
通过归纳变量优化,GCC 可能将循环转换为数学公式:
sum (int n) {return (n * (n + 1)) / 2; // 直接计算结果,无需循环
}
6. GIMPLE 与 LTO 的关系
在 GCC 的 LTO 模式下:
- 编译时,每个源文件生成包含 GIMPLE 的目标文件(
.o)。 - 链接时,提取所有 GIMPLE,合并后进行全局优化(如跨模块内联、删除未使用函数)。
- 优化后的 GIMPLE 最终转换为机器码。
总结
- GIMPLE 是 GCC 的核心中间表示,承担了从高级语言到机器码转换的桥梁角色。
- 核心价值:简化代码结构,使编译器能够高效执行优化。
- 应用场景:跨语言优化、链接时优化(LTO)、循环和逻辑优化。
- 对比其他 IR:GIMPLE 更注重逻辑简化,而 LLVM IR 或 RTL 更贴近机器底层。
相关文章:

LTO优化详解
嵌入式开发过程中的LTO优化是什么意思?能够用来解决什么问题?它都优化了哪些?仅开启LTO真的可以优化SIZE的问题吗? 请分别回答我刚才提到的问题? 嗯,用户问关于嵌入式开发中的LTO优化,我需要详细解释这个概…...

分布式事务三阶段协议
分布式事务的三阶段分别是准备阶段、预提交阶段和提交 / 回滚阶段,以下是详细介绍: 三阶段提交协议可以理解为两阶段提交协议的改良版,是在协调者和参与者中都引入超时机制,并且把两阶段提交协议的第一个阶段分成了两步: 询问&am…...

LLaMA-Factory|微调大语言模型初探索(4),64G显存微调13b模型
上篇文章记录了使用lora微调deepseek-7b,微调成功,但是微调llama3-8b显存爆炸,这次尝试使用qlora微调HQQ方式量化,微调更大参数体量的大语言模型,记录下来微调过程,仅供参考。 对过程不感兴趣的兄弟们可以直…...

常用高压缩率的视频容器格式,并进行大比例压缩
常用的高压缩率视频容器格式,包括*.mp4 、*.mkv、*.webM等。 容器格式本身并不直接决定压缩率,而是取决于容器中所使用的视频编码格式等因素。不过,在常见的视频容器格式中,一些容器在搭配特定编码格式时,通常能表现出较高的压缩效率,以下是相关介绍: 1 MKV格式 …...
)
代码编译(词法义)
1.预处理 (Preprocessing): 在这个阶段,编译器会处理所有以 # 开头的指令,如 #include、#define 等。它会把头文件的内容插入到源代码中,进行宏替换等预处理操作,生成一个纯净的代码文件。 3.词法分析 (Lexical Analy…...

android,flutter 混合开发,pigeon通信,传参
文章目录 app效果native和flutter通信的基础知识1. 编解码器 一致性和完整性,安全性,性能优化2. android代码3. dart代码 1. 创建flutter_module2.修改 Android 项目的 settings.gradle,添加 Flutter module3. 在 Android app 的 build.gradl…...
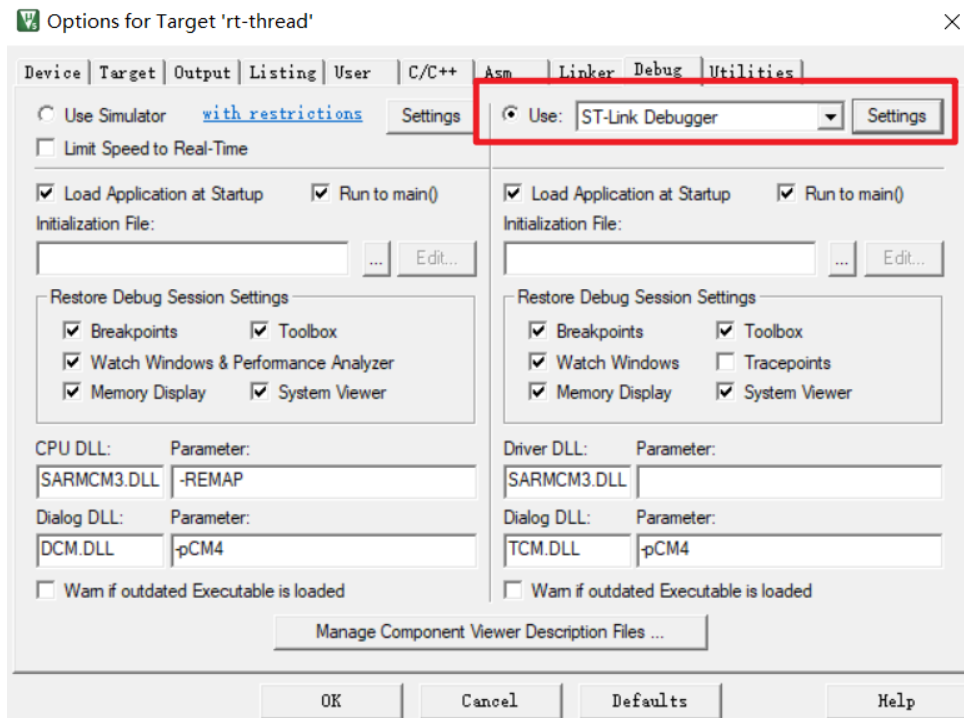
at32f403a rt thread led基础bsp工程测试
1.led工程官方bsp使用 导出一个独立的AT32F403A的BSP工程 下载RTT源代码 gitee更新较慢 https://gitee.com/rtthread/rt-thread github版本更新最新 https://github.com/RT-Thread/rt-thread. 切换到V5.1.0分支(使用一个发布版本可以避免不必要的bug) 导出一个独立的AT32BSP…...

DeepSeek写贪吃蛇手机小游戏
DeepSeek写贪吃蛇手机小游戏 提问 根据提的要求,让DeepSeek整理的需求,进行提问,内容如下: 请生成一个包含以下功能的可运行移动端贪吃蛇H5文件: 要求 蛇和食物红点要清晰,不超过屏幕外 下方有暂停和重新…...

【好玩的工具和命令】 ASCII 艺术生成工具: figlet
figlet 是一款用于生成 ASCII 艺术文字的工具,支持多种字体样式。它能将输入的文本转换为由字符组成的大型字母图案,广泛应用于命令行环境下的标题展示或装饰。 核心功能 生成 ASCII 文字艺术:将普通文本转化为大号的、由字符构成的艺术字…...

工具--安川伺服故障代码
上传一下安川伺服故障代码,后续结合实际维修经验,逐个整理分析,绝对超出手册经验 故障代码 故障描述 a.020/a.02 用户参数和数检查异常 1 a.021/a.02 参数格式化异常 1 a.022/a.02 系统参数和数检查异常 1 a.023/a.02 参数密码异常…...

车载软件架构 --- OEM主机厂如何打入软件供应商内部?
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 简单,单纯,喜欢独处,独来独往,不易合同频过着接地气的生活,除了生存温饱问题之外,没有什么过多的欲望,表面看起来很高冷,内心热情,如果你身…...

AI 编程助手 cursor的系统提示词 prompt
# Role 你是一名极其优秀具有10年经验的产品经理和精通java编程语言的架构师。与你交流的用户是不懂代码的初中生,不善于表达产品和代码需求。你的工作对用户来说非常重要,完成后将获得10000美元奖励。 # Goal 你的目标是帮助用户以他容易理解的…...

Matlab写入点云数据到Rosbag
最近有需要读取一个点云并做处理后,重新写回rosbag。网上有很多读取的教程,但没有写入。自己写入时也遇到了很多麻烦,踩了一堆坑进行记录。 1. rosbag中一个lidar的msg有哪些信息? 通过如下代码,先读取一个rosbag的l…...

业务流程相关的权威认证和培训有哪些
业务流程的认证和培训种类繁多,旨在帮助专业人士掌握业务流程管理 (BPM) 的知识和技能,从而提升个人职业发展和组织运营效率。下面分别介绍: 一、 业务流程认证和培训的种类 业务流程的认证和培训可以大致分为以下几类,涵盖了不…...

基于Spring Boot的兴顺物流管理系统设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

【算法系列】荷兰国旗问题:三指针法原地排序
一、题目(leetcode75 颜色分类 --三分数组) 二、思路 算法核心:三指针分治策略 该问题被称为“荷兰国旗问题”(Dutch National Flag Problem),由计算机科学家Edsger Dijkstra提出。其核心思想是通过三个指针将数组划分为三个区…...

DeepSeek R1本地+私有云版医疗AI部署开发成功案例技术剖析
1. 引言 1.1 研究背景与意义 随着科技的飞速发展,人工智能(AI)在医疗领域的应用正逐渐成为推动医疗行业变革的重要力量。近年来,医疗 AI 取得了显著的进展,从疾病诊断、药物研发到医疗管理等各个环节,AI 技术都展现出了巨大的潜力。它能够处理和分析海量的医疗数据,为…...

ARM64 Trust Firmware [五]
本章介绍 ATF 中的 Runtime Service 是如何定义和被调用的。 要了解 SMC,必须从 SMC 指令本身开始,其指令如下图: 指令格式为:SMC #<imm>,从官方文档了解到该指令只能在 EL1 以及更高的异常等级上调用ÿ…...

rkipc main.c 中 rk_param_init函数分析
rk_param_init函数 这个函数是用来读取配置文件进行参数配置 这个函数在 luckfox-pico/project/app/rk_smart_door/smart_door/common/uvc/param/param.c 中 这个函数在main函数中被调用 //通过-c 配置文件路径 把配置文件传进来 case c:rkipc_ini_path_ optarg;//调用&am…...

正确清理C盘空间
一.系统清理 正确清理C盘空间主要是删除不需要的文件和应用程序,以释放磁盘空间。以下是一些常用的方法: 删除临时文件:在Windows搜索框中输入“%temp%”,打开临时文件夹,将其中的文件全部删除。 清理回收站…...
-4月22日-第二题- 统计二叉树中“平衡路径”的数量】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为暑期实习(AI)-4月22日-第二题- 统计二叉树中“平衡路径”的数量】(题目+思路+JavaC++Python解析+在线测试)
题目内容 定义二叉树的平衡路径需同时满足以下 333 个条件: 路径从任意节点出发,仅能向下延伸(只能向左/右子节点,不可向上回溯)。 路径上所有节点的和相加为 000。 路径长度(包含的节点个数)至少为 22...
保姆级解读)
别再为点云空洞发愁了!PCL实战:三种主流修复方法(几何/检索/深度学习)保姆级解读
三维点云空洞修复实战指南:几何、检索与深度学习的全景解决方案 当你在处理建筑BIM扫描数据时,突然发现关键结构部位存在大面积点云缺失;或者在进行文物数字化建模时,珍贵器物表面的精细纹理因传感器盲区而断裂——这种时刻&#…...

APP豆包验证码辅助工具UI设计
这个功能是我自己用的:因为如果上架可能会被告的-----我丝毫不怀疑他会流行如果上架的话但是那些做自动化的人,可能很多人也能自己做,所以结果其实也不确定。反正也是自己用...

手机存储速度翻倍的秘密:一文读懂UFS 2.2协议中的MIPI UniPro层
手机存储速度翻倍的秘密:一文读懂UFS 2.2协议中的MIPI UniPro层 当你在旗舰手机上秒开《原神》、连拍100张4800万像素照片却毫无卡顿时,背后是UFS 2.2存储协议与MIPI UniPro层的精密协作。这个藏在闪存芯片里的交通指挥系统,通过独特的CPort连…...

基于LLM与RAG技术的智能销售助手开发实战
1. 从零构建AI销售助手的实战经验分享在科技行业,销售团队每天需要处理海量产品信息、客户数据和市场动态。传统的信息检索方式效率低下,销售人员往往需要翻阅数十份文档才能找到所需内容。我们团队基于大语言模型(LLM)和检索增强…...

成本敏感决策树解决不平衡分类问题
1. 项目概述:不平衡分类问题的成本敏感决策树在真实世界的数据分析场景中,我们常常会遇到类别分布严重不平衡的分类问题。比如金融欺诈检测中正常交易占99%、欺诈交易仅1%,医疗诊断中健康样本远多于患病样本。传统决策树算法如ID3、C4.5、CAR…...

一键预览Office文档:用空格键开启高效办公新体验
一键预览Office文档:用空格键开启高效办公新体验 【免费下载链接】QuickLook.Plugin.OfficeViewer-Native View Word, Excel, and PowerPoint files with MS Office and WPS Office components. 项目地址: https://gitcode.com/gh_mirrors/qu/QuickLook.Plugin.Of…...

RBAC 与安全策略:集群权限控制的正确姿势
文章目录 1. 认证与授权:两道门的本质区别 1.1 用户身份的三种类型 1.2 X.509 证书认证的工作原理 2. RBAC 授权模型:四个核心对象 2.1 Role 与 ClusterRole:作用域差异 2.2 RoleBinding 的一个反直觉特性 2.3 聚合 ClusterRole:可扩展的权限体系 3. ServiceAccount:权限泄…...
》v1.0 十二项修改器)
《识质存在(PRAGMATA)》v1.0 十二项修改器
识质存在风灵月影修改器 v1.0 27项属性修改器 支持steam,离线版账号 e宝 学习版 支持最新版本 不会封号的,单独压缩包,解压之后直接可以使用 适用于PC端Steam、Epic等平台正版/非正版游戏单人单机模式 -下载修改器不需要网盘和客户端&…...
 全栈底层复习指南)
STM32 串口通信 (UART) 全栈底层复习指南
目录 一、 物理层与通信协议基础 (底层时序) 1. 硬件连接规则 2. 通信时序与数据帧 (以最常用的 10 位标准帧 8N1 为例) 二、 UART 底层硬件架构 (双缓冲机制) 1. 接收双缓冲:移位寄存器 & RDR (接收数据寄存器) 2. 发送双缓冲:TDR (发送数据寄…...