游戏引擎学习第119天
仓库:https://gitee.com/mrxiao_com/2d_game_3
上一集回顾和今天的议程
如果你们还记得昨天的进展,我们刚刚完成了优化工作,目标是让某个程序能够尽可能快速地运行。我觉得现在可以说它已经快速运行了。虽然可能还没有达到最快的速度,但我们确实完成了让它运行更快的目标。
现在我们并不完全清楚它运行的速度到底有多快,跟它潜在的最优速度相比如何,这就是今天要讨论的话题。并且确认我们已经有了一个快速绘制矩形的程序,并且将继续向前推进。
至于当前的程序,可以看到它比刚开始时快了不少。刚开始时,程序的执行大约需要280个周期左右,速度相对较慢。
准备工作:获取优化前和优化后周期计数
实际上我们不需要猜测,因为我们可以切换到drawRectangleSlowly函数来查看结果。如果我们进入渲染位图部分,并切换成drawRectangleSlowly,就能测试了。
如果我们想测试的话,可以在这里调用drawRectangleSlowly,并且我们需要为drawRectangleSlowly添加计时功能,虽然我不确定我们是否已经有了相关的计时代码。看起来我们是有的。

在DrawRectangleSlowly中添加周期计数
我们现在可以看到drawRectangleSlowly函数在运行,但目前并没有进行任何计数,因此无法查看每个像素的周期数。为了能看到这些信息,我们需要在像素填充的调用部分加入计时功能,这样我们就能比较它与其他函数的性能。
我打算在drawRectangleSlowly中也添加类似的计时功能,就像在drawRectangleQuickly中做的那样。在drawRectangleSlowly里,我会在合适的位置添加计时块,然后进行像素计数。这样,我们就可以得到每个像素的时间,并进行对比。

加上调试对象的字符串方便查看对应的信息

接下来,应该能够看到计数结果。

76与20周期每像素!
现在可以看到,调用drawRectangleSlowly时,每个像素大约需要76个周期。相比之前,速度明显提升了,大概快了3倍左右。
总体来说,我们已经做得相当不错,优化出了一个既快速又实用的版本。不过,直到现在我们还不确定实际的性能提升,这也是我们从一开始就提到的问题。
在debug模式下差别就很大了

2253cy/h vs 79cy/h 28倍
>>> 2253/79
28.518987341772153
>>>
填充每个像素应该花多少时间?我们来算算所有内在函数及其吞吐量…
目前我们已经知道,我们的执行速度比开始时快了很多,从最初的2253个周期降低到了大约79个周期,这很好。但我们仍然不清楚每个像素填充的时间应该是多少。我们没有任何具体的估算,因此很难确定这个过程是否已经优化到极限。
我们可以选择忽略这一点,认为现在已经足够快,暂时不需要再做进一步优化。这是一种可以接受的方法,如果不追求极致优化,也是完全可行的。
然而,我们希望能做一些工作来估算每个像素理想情况下应该需要多少时间,假设所有内存需求都已经准备好,没有内存延迟等问题。我们将探讨如何计算这些操作所需的周期数,并尝试了解我们当前的性能与理论最优性能的差距。
…我们如何自动化这个计数过程?
想要做的是,找出一种方法,能够轻松地计算我们实际进行的操作数量。这个过程有点复杂,因为每个操作的延迟都不同,且每个操作的延迟值在代码中也有所不同,很难通过肉眼看代码来准确地统计。
因此,希望能够创建一种自动化的过程,来计算我们实际执行的操作,并给出一个估算,预测所有操作的总吞吐量。这是基于最理想的情况,假设所有操作都已经得到了适当的流水线处理。
答案:用宏重载内在函数,增加计数器变量
想要做的是,先看一下所有这些函数,假如我们把这些函数的功能完全改变,让它们做些别的事情,而不是它们原本的功能。接着,我打算将这段例程移除,专注于查看我们所有的_mm函数。我计划通过#define宏来重新定义这些函数,让它们执行不同的操作。
这样做的目的是尝试修改函数行为,从而更好地跟踪和计算每个操作的执行情况。
哎呀,这里还有一些SIMD化工作没做…
在开始之前,发现有些地方还没有完全优化,依然有一些标量操作存在。虽然这些可能不太影响整体效果,但为了确保效率,决定删除这些部分。比如,PixelPy 在整个循环中是相同的,所以这部分可以去掉,提到外层循环中。而PixelPx是一个未知的值,可以在每次循环中递增,而不必每次调用set函数,这样就避免了将这个值提升到寄存器中的操作,减少了不必要的开销。


用 _mm_add_ps 代替标量加法,每次增加4(比之前快2-3个周期)
实际上,优化的思路很简单,可以直接处理。在这个循环中,如果把 PixelPx 设置为一个初始值,并且每次通过循环时将它加上4,就可以得到下一个四个像素的 x 坐标。这样就不需要每次调用 set 函数去提升值到寄存器中,只需要在每次循环结束时更新 PixelPx 的值。这种做法帮助去除了多余的标量操作,也使得执行效率更高。
除此之外,看到 PixelPy 和 PixelPx 的计算可以提前做一次,而不必每次都计算,因为它们在大部分时间里是常量。实际操作中,这些减法操作和 PixelPy 和 PixelPx 的使用其实是冗余的,只在特定情况下才用到,所以优化这些常量计算可以减少不必要的性能损耗。

dx 和 dy 可以嵌入到 PixelPx 和 PixelPy 中(比之前快2个周期)
在这段讨论中,我们探讨了代码中的优化问题,特别是在像素计算和内存访问方面。首先,提到了一些不必要的操作,比如在进行像素值计算时,我们本来可以直接将像素值 px 赋值,并且在一开始就通过公式 _mm_sub_ps 计算出它的值,而不必再做后续的重复计算。这样一来,我们可以将这个过程简化,直接得到 px 的值。
同样,py 的值也不需要变化,它在整个计算过程中是保持不变的,因此无需反复处理。通过这种方式,代码变得更简洁高效。
接着,我们讨论了优化的效果,发现通过这些调整,运行速度有了明显的提升,具体来说,大约提高了两个周期的效率。
最后,在检查其他相关细节时,观察到一些其他的优化机会,这些也能进一步提升代码的执行效率。

我们是否应该将 PixelPx 和 PixelPy 的轴乘法/加法计算从内循环中提取出来?
// 计算U和V坐标,它们代表了在纹理中的位置,基于d和X轴、Y轴的内积__m128 U = _mm_add_ps(_mm_mul_ps(PixelPx, nXAxisx_4x), _mm_mul_ps(PixelPy, nXAxisy_4x));// U坐标,基于d和X轴的内积,乘以反向X轴的长度平方__m128 V = _mm_add_ps(_mm_mul_ps(PixelPx, nYAxisx_4x), _mm_mul_ps(PixelPy, nYAxisy_4x));
在这段讨论中,提到了一些关于进一步优化计算过程的想法。首先,提到 PixelPx 和 PixelPy 这两个值的计算方式可能不需要按当前方式进行,原因是这些值在行内是不变的。特别是 PixelPy 的计算方式,在行内是恒定的,所以不必每次都重新计算。
另外,提到 PixelPx 被 nXAxisx_4x 和 nYAxisx_4x 这两个值乘以,当前的计算方法可以进一步优化。实际上,可以通过引入两个变量来递增和存储这些值,以便避免重复计算。不过,虽然这样做可能会提升效率,但并不一定是必要的,因此暂时没有采取这种做法。
最终,讨论转向了是否可以将一些常量值存储起来,以进一步减少不必要的计算,优化整体性能。
也许只提取乘法部分,但不提取加法?嗯…
在这段讨论中,提到了一种可能的优化方式,即将两个乘法操作的结果提前计算出来,然后在之后进行加法操作。这种方法看起来是合理的,因为它可以避免多次计算相同的值。
然而,这样做的代价是需要引入两个额外的变量来存储这些计算结果。对于是否引入这两个变量,存在一些不确定性,因为虽然它可以优化计算,但也增加了存储的开销。因此,这一做法是否值得实施仍然需要进一步的权衡。
…试着提取乘法部分。(1-2周期更慢)
首先尝试了引入两个临时变量 Temp0 和 Temp1 来测试优化效果,目的是提前计算某些常量值,看看是否能帮助编译器进行更聪明的优化。虽然理论上这可以减少计算量,但经过测试后发现,实际上性能没有得到提升,反而变得稍微更差,因此决定不继续使用这种做法,保持现有的计算方式。
接着,进行了一次代码检查,确保循环中没有做任何不必要的操作,以免浪费时间在本不应该发生的事情上。特别是在进行 UV 值的限制和处理分数坐标的操作时,这些步骤看起来都很合理,没有明显的效率问题。
最后,讨论转向了纹理获取部分,虽然还没有具体展开,但也意识到这部分可能需要进一步优化,以确保整体性能的提升。

注意:纹理提取无法在SIMD中完成
在这段讨论中,提到了一些关于标量操作的限制,尤其是在处理时,因为没有办法进行宽幅(wide)的数据获取,只能使用标量处理。这是由于硬件的局限性,无法做更多的优化,因此只能接受这种限制。
接下来,讨论了数据解包(unpacking)部分,经过检查后发现这部分操作没有什么问题,做的就是标准的处理流程,看起来合理。
关于数据转换和亮度计算的步骤,也都觉得没有问题,都是正常的转换流程。整体来看,代码中并没有明显的低效或不合理的部分,尤其是与循环顶部的问题相比,这次似乎没有出现明显的“愚蠢”操作,整个过程显得比较合乎逻辑。
解释为什么 _mm_maskmoveu_si128 非常慢。不要使用它!它绕过了缓存。
在这段讨论中,提到了一条关于 _mm_maskmoveu_si128 指令的反馈,解释了为什么这条指令并没有带来预期的性能提升。实际上,这条指令是无用的,因为它是一个非暂存存储(non-temporal store),意味着它会绕过缓存写入,并不会将数据存入缓存。这使得这条指令在很多情况下是无效的,甚至会降低性能。在检查后,发现使用这条指令会使得性能变得三倍更慢。因此,被明确建议避免使用这种指令。
之后,提到经过一系列的优化,最终每个像素的处理时间减少到了48个周期,这是一个积极的进展。接下来的步骤是开始对代码进行计数,确保在优化过程中没有遗漏任何明显低效的部分。
为每个内在函数添加 #define 来计算操作次数 (_mm_add_ps, _mm_mul_ps 等)
在这段讨论中,目标是记录所有调用的指令,以便能够自动统计它们的次数,而不需要手动计算。首先列出了所有需要跟踪的指令,包括不同的加载、转换、运算、比较等操作。
具体操作包括:
- 跟踪所有涉及的加载指令,例如
load和像素值的加载。 - 记录用于比较的
min和max指令。 - 处理数据转换的指令,包括双向转换。
- 记录涉及位移(shift)、平方(square)、加法(add)、减法(sub)等常见运算的指令。
- 还要考虑位运算(OR)和其他指令的计数。
最终决定不对加载和存储操作进行统计,只关注其他的运算指令,并确保涵盖了所有关键的计算步骤,以便后续的性能分析和优化。

开始设置内在函数 #define 来计算操作次数
目标是为每个操作指令创建一个计数器,用于记录每个指令的执行次数。为此,决定通过简单的递增方式来进行计数。具体步骤包括:
- 为每个指令定义一个计数器,并通过
count++的方式增加计数。 - 考虑使用宏来自动化这个过程,以便每次执行指令时,能够自动更新计数器。
- 这些计数器的作用是帮助追踪每个指令的调用频次,后续可以用来进行分析或优化。
- 通过将计数结果存储在一个变量中,能够方便地查看执行次数,甚至可以在后续的处理中使用这些计数数据。
最终的目的是通过这种方式,在程序执行时能够实时地统计每个操作的调用次数,为性能分析提供数据支持。

预处理器的聪明技巧,处理内在函数通常作为参数传递其他内在函数的情况
一种方法来确保之前定义的计数器能够正确地工作。为此,需要为每个表达式包装一个“虚拟”的包装器,以确保每个操作都能产生有效的输出。这是因为某些操作,如 mole,可能会返回一些结果,而这些结果需要被有效地处理和计数。
虽然最初有些疑惑是否所有操作都能正常工作,但最终推测如果这些操作只是接收参数并返回结果,那么它们应该能够正常执行。接下来,计划通过宏来自动处理这些操作,将其转换为可以计数的形式。宏将确保每次操作执行时都会自动递增计数器。
此外,提到了在实现时需要确保对于一些特殊操作,比如立即数的位移操作,不需要对立即数本身进行计数。同时,对于像 mmSquare 这种乘法操作,需要增加对应的乘法计数器。
最终,讨论中提到了一些编译时错误,例如数据类型不匹配的问题(如将 _m128 转换为 int),以及某些操作未能正确执行。这些问题需要进一步调试和修复,但整体思路是通过宏和计数器来跟踪每个操作的调用频率。
定义加载/存储为空
在这段讨论中,提到了在实现过程中遇到的一些问题,主要是关于加载操作和计数器的定义。首先,需要确保对于 loadu 操作,相关的变量被正确初始化,并且处理一些语法错误,如分号的问题。同时,对于某些操作(如 mm_sqrt_ps),也需要确保它们正确地被计数并加到相应的计数器中。
遇到的一些错误包括未正确处理一些操作(如 mm_sqrt_ps)以及缺少必要的计数器递增。为了修复这些问题,决定手动检查每个操作,并确保它们在执行时能正确地更新计数器。
总体来说,这段代码的目的是确保每个操作都能正确地记录执行次数,并通过修复语法错误和遗漏的操作,保证整个计数过程的准确性。
修改 test cmake 每次编译最新的test.cpp 不用去改cmake
# 设置 CMake 的最低版本要求
cmake_minimum_required(VERSION 3.10)# 设置项目的名称和使用的编程语言
project(MyCppProject CXX)# 设置 C++ 标准为 C++11
set(CMAKE_CXX_STANDARD 11)# 使用 file(GLOB ...) 获取当前目录下所有 .cpp 文件
file(GLOB SOURCES "*.cpp")# 排序 SOURCES 列表(字典顺序)
list(SORT SOURCES)# 获取字典顺序最大的文件
list(LENGTH SOURCES LIST_SIZE)if(LIST_SIZE GREATER 0)list(GET SOURCES -1 NEW_FILE) # -1 是获取字典序最后一个文件message(STATUS "最新要编译的文件是: ${NEW_FILE}")
else()message(WARNING "没有 .cpp 文件被发现")
endif()# 创建可执行文件
add_executable(test ${NEW_FILE})# 如果有需要链接的库,可以在这里添加
# target_link_libraries(test some_library)
打断点调试查看调用的次数
- 先注释掉断言


mm_set1_ps:6
mm_add_ps:18
mm_sub_ps:5
mm_mul_ps:73
mm_castps_si128:9
mm_and_ps:3
mm_or_ps:0
mm_or_si128:4
mm_cmpge_ps:2
mm_cmple_ps:2
mm_min_ps:5
mm_max_ps:5
mm_cvttps_epi32:2
mm_cvtps_epi32:4
mm_cvtepi32_ps:22
mm_and_si128:21
mm_andnot_si128:1
mm_srli_epi32:15
mm_slli_epi32:3
mm_sqrt_ps:3
mm_movemask_epi8:1
mm_unpackhi_epi32:4
mm_unpacklo_epi32:4
我们得到了计数!
检查每次循环调用时不同对象或操作的次数。首先,观察代码时,确保没有出错。接着,查看每次循环中涉及的不同项目或资源,并统计每个项目被调用的次数。最后,检查这些计数是否正确,确保所有的循环和计数都按预期执行,并且没有遗漏或错误。
总体来说,这段话描述了一个过程,其中每次循环会涉及到不同的操作或对象,重点在于确保循环的执行和统计结果是准确的。
再次检查计数是否合理
首先检查了某些操作是否被正确调用了预定的次数。通过选择一些特定的操作进行验证,确认它们的调用次数是否符合预期。比如,先检查了某个操作是否正确地执行了五次,接着又检查了其他类似的操作,确保它们的调用次数都准确。
接下来,检查了一个更复杂的操作,确认它在执行过程中被调用的次数。这次,操作被执行了18次,最终也与预期一致,说明操作次数统计正确。
通过这些检查,得出结论:整体上,所有操作的调用次数都正确。这表明所需的操作总数和执行的次数完全符合预期,可以确认操作过程是有效的。
最后,如果需要,还可以进一步处理这些数据,得出更多关于执行过程的细节。
将计数乘以吞吐量以获取总延迟估算
首先讨论了如何根据操作的延迟来计算总的操作时间。具体做法是,首先获取每个操作的调用次数,然后将这些次数乘以对应操作的延迟时间。例如,可以通过构造一个新的计数器来记录每个操作的延迟时间。这样,每个操作的总延迟时间就可以通过其调用次数与延迟时间的乘积来计算。
接着提到了延迟时间与吞吐量之间的关系。例如,一些操作的吞吐量可能是相同的,比如加法和减法的吞吐量可能都是 1,而乘法操作的吞吐量也可以是 1。对于某些处理器(如 Haswell 处理器),吞吐量可能会有所不同,需要根据具体情况来调整。
这段讨论的重点是如何计算不同操作的实际延迟时间,特别是如何结合吞吐量和操作次数来估算总的操作延迟。
这张表格显示了不同架构的延迟和吞吐量(CPI)。
数据来源
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
| Intrinsic Function | Architecture | Latency | Throughput (CPI) |
|---|---|---|---|
| _mm_set1_ps | - | 0 | - |
| _mm_add_ps | Alderlake | - | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | - | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_sub_ps | Alderlake | - | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | - | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_mul_ps | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_castps_si128 | - | 0 | - |
| _mm_and_ps | Alderlake | 1 | 0.3333 |
| Icelake Xeon | 1 | 0.33 | |
| Sapphire Rapids | 1 | 0.3333 | |
| _mm_or_ps | Alderlake | 1 | 0.3333 |
| Icelake Xeon | 1 | 0.33 | |
| Sapphire Rapids | 1 | 0.3333 | |
| _mm_or_si128 | Alderlake | 1 | 0.3333 |
| Icelake Xeon | 1 | 0.33 | |
| Sapphire Rapids | 1 | 0.3333 | |
| Skylake | 1 | 0.33 | |
| _mm_cmpge_ps | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_cmple_ps | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_min_ps | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_max_ps | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_cvttps_epi32 | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_cvtps_epi32 | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_cvtepi32_ps | Alderlake | 4 | 0.5 |
| Icelake Xeon | 4 | 0.5 | |
| Sapphire Rapids | 4 | 0.5 | |
| Skylake | 4 | 0.5 | |
| _mm_and_si128 | Alderlake | 1 | 0.3333 |
| Icelake Xeon | 1 | 0.33 | |
| Sapphire Rapids | 1 | 0.3333 | |
| Skylake | 1 | 0.33 | |
| _mm_andnot_si128 | Alderlake | 1 | 0.3333 |
| Icelake Xeon | 1 | 0.33 | |
| Sapphire Rapids | 1 | 0.3333 | |
| Skylake | 1 | 0.33 | |
| _mm_srli_epi32 | Alderlake | 1 | - |
| Icelake Xeon | 1 | 0.5 | |
| Sapphire Rapids | 1 | 0.5 | |
| Skylake | 1 | 0.5 | |
| _mm_slli_epi32 | Alderlake | 1 | 0.5 |
| Icelake Xeon | 1 | 0.5 | |
| Sapphire Rapids | 1 | 0.5 | |
| Skylake | 1 | 0.5 | |
| _mm_sqrt_ps | Alderlake | 12 | 3 |
| Sapphire Rapids | 12 | 3 | |
| Skylake | 12 | 3 | |
| _mm_movemask_epi8 | Alderlake | 3 | 1 |
| Icelake Xeon | - | 1 | |
| Sapphire Rapids | 3 | 1 | |
| Skylake | 2 | 1 | |
| _mm_unpackhi_epi32 | Alderlake | 1 | 0.5 |
| Icelake Xeon | 1 | - | |
| Sapphire Rapids | 1 | 0.5 | |
| Skylake | 1 | 1 | |
| _mm_unpacklo_epi32 | Alderlake | 1 | 0.5 |
| Icelake Xeon | 1 | - | |
| Sapphire Rapids | 1 | 0.5 | |
| Skylake | 1 | 1 |
这个表格包括了多个指令及其在不同架构下的延迟(Latency)和吞吐量(Throughput)。

在Windows中查找处理器核心类型
打开CPUZ 查看代号Raptor Lake
按照AI 说的
在性能和架构上与 Raptor Lake 相近的处理器,应该是 Alder Lake,因为 Raptor Lake 是 Alder Lake 的继任者,两者使用了相似的架构设计和技术。具体来说:
- Alder Lake 和 Raptor Lake 都采用了混合架构设计(P-core + E-core)。
- Alder Lake 和 Raptor Lake 都使用了 Intel 7 制程工艺(以前的10nm SuperFin工艺)。
- Alder Lake 和 Raptor Lake 都支持 DDR5 和 DDR4 内存。
因此,在你列出的这些架构中,Alder Lake 和 Raptor Lake 更为相近,尤其是在 CPU 核心架构和技术特性方面。而其他架构如 Icelake Xeon、Sapphire Rapids 和 Skylake,虽然也有不同的特性,但它们与 Raptor Lake 的设计理念和目标市场有所区别:
- Icelake Xeon 和 Sapphire Rapids 更侧重于服务器和数据中心市场,性能和优化有所不同。
- Skylake 是早期的架构,虽然也属于 Intel 处理器的一部分,但它的设计和技术较为陈旧,相比之下,Alder Lake 和 Raptor Lake 会提供更高的性能和效率。
综上所述,Alder Lake 和 Raptor Lake 是最接近的,尤其在处理器架构的设计和性能上。
应该是选Alder Lake

用宏将延迟*计数加起来,得到一个粗略的吞吐量总和
在这个过程中,首先为了简化计算,使用了一个宏,将多个值合并到一起并计算总和。通过设定一个变量 total 并在每次迭代时将 x 加到总和中,最终能够得到一个准确的总和。在这段代码的执行过程中,遇到了一个类型问题,原本的值需要转换为 32 位浮动数(real 32),为了解决这个问题,决定将所有的星号(*)操作符改为逗号(,),从而使得表达式能够正确地处理数据类型。此外,还用延迟(latency)与某个值相乘,进一步修改了总和的计算方式。最终,目标是通过这些操作,理论上可以得到一个正确的吞吐量总和。
整个过程包含了一些实验性和不太常见的做法,如修改操作符和调整数据类型,尽管这样做可能会产生一些不稳定性,因此提醒这并不是推荐的标准做法。

哦,真是巧妙:测得的吞吐量低于理论最佳吞吐量。指令很可能在每个周期执行多个ALU。
通过计算得到的吞吐量为101个周期,这个值是理想情况下,当所有指令能够完美地进入处理器时得到的结果。但实际测量的吞吐量略低于理论最大值。这表明,在实际情况中,指令并不是一个接一个地执行,而是有多个指令同时并行发出,从而提高了效率。
为了解释这个差异,可以认为是指令重叠执行的结果,即多个指令在一个周期内被发出,不需要每个指令都等待前一个完成。计算得出的下一个理论最低吞吐量是如果只有一个单元执行所有指令并且这些指令完全重叠的情况下所能达到的最大吞吐量。
实际情况中,得到的周期数比理论最低吞吐量要低,实际为48个周期,而理论值是54或55个周期,这意味着系统的性能比预期的还要好一些。可能没有算上某个加法操作,这个加法操作本应让结果更高一些。
为了进一步优化计算,接下来需要了解有多少个执行单元可以同时发出指令,从而计算出指令并行执行的实际情况。但目前不清楚具体的执行单元数量,可能需要查找相关的硬件信息。

Nehalem核心有多少个单元?
在尝试了解处理器的执行单元数量时,首先检查了相关信息,但并没有直接找到关于执行单元数量的数据。尽管处理器的详细规格列出了一些参数,但并没有明确指示每个周期可以同时发出多少条指令。考虑到处理器使用的是Nehalem架构,进行了一些搜索,但仍没有找到直接的答案。
通过进一步查询,发现可能需要查找更多关于内存层级、执行管线、负载和存储操作的信息,这些可能间接提供关于执行单元的信息。最终,了解到Nehalem架构中,双精度浮点单元和单精度浮点单元可以通过零和一端口访问。因此,能同时发出的指令数量可能与这些端口的数量有关,但具体的执行单元数仍需更多的数据来确认。
讨论每个时钟周期执行多个指令的局限性
在试图进一步了解处理器的指令发射能力时,发现目前的资料并未提供足够的信息,特别是关于执行端口的详细情况。尽管可以通过硬件优化的角度理解,处理器在每个周期内能够发出多少条指令,但每种指令需要不同的执行单元。如果处理器仅有两个乘法单元,即使理论上可以发出四条指令,但实际上只能发出两个乘法指令。
为了更准确地估算执行的吞吐量,需要知道每种指令在每个周期内可以发出多少次。假设每个周期能够发出两条指令,那么总的执行时间可以通过将总数除以2来计算,理论上得出的最优吞吐量为27个周期。
然而,当前缺少关于处理器详细信息的更多数据,尤其是关于各个指令的执行端口和执行单元的具体配置。这些信息可能会在技术文档或处理器规格表中找到,但由于这些信息难以在实时环境中获取,因此只能暂时搁置进一步分析。
我们离最大理论吞吐量已经很接近了
目前已经获得了一个非常有价值的信息,即每个像素的执行时间大约为48个周期。这个结果表明,在继续优化计算操作的过程中,进一步提高速度的空间已经非常有限。根据分析,理论上每个周期只能发出两条浮点运算指令,如果真的只有这么多运算单元,那么27个周期的目标值已经接近理论最大吞吐量。
虽然可能通过一些微小优化进一步缩短时间,但这种提升非常有限,接近于回报递减的状态。因此,虽然结果还不完全准确,但已经接近理想值,基本上达到了预期目标。
内存延迟可能不会影响性能
现在我大致了解了内存延迟是否影响性能,结果看来并没有造成太大问题。观察到目前的执行周期非常接近理论最大吞吐量,这表明缓存工作得很好,且系统并未出现明显的停顿或性能瓶颈。这个结果很有意思,也对我们来说是个积极信号,意味着没有显著的性能损失。
为内在函数测量代码做一个 #if 切换
接下来,我们希望在不同条件下查看结果表现。为了方便控制,我们决定创建一个“计数周期”的定义,并通过条件判断来开启或关闭这一功能。如果没有定义计数周期,则系统会按正常方式运行。如果定义了计数周期,则会启用相关的计数逻辑。这样可以随时切换是否进行周期计数,而不会干扰程序的正常运行。我们还注意到,在调试模式下,程序的运行速度明显较慢。

这正是你在找的内容吗?
https://en.m.wikipedia.org/wiki/File:Intel_Nehalem_arch.svg

我的电脑没找到这个图

Nehalem图:只有一个FPU?
看起来这个图表有点令人困惑。如果仔细看,会发现乘法单元似乎是单端口的,这就让人有些疑惑。虽然有提到有两个单元能够执行浮点数乘法,但从这个图来看,似乎只有一个端口能够执行乘法操作。比如说,浮点乘法(fp mul)显示在端口零,而没有看到其他的乘法单元。
如果只能在一个时钟周期内执行一次乘法,那么就意味着我们在处理这类计算时几乎达到了性能的极限。比如,如果回过头看我们曾经执行的操作,大部分其实都是乘法。如果只能每个周期发出一个乘法指令,那么执行73次乘法至少需要73个周期来完成。
因此,如果乘法需要18个周期来完成,仅仅是乘法部分就非常庞大了,可能会带来较大的性能瓶颈。这表明,如果每个像素需要8个周期来处理乘法,效果确实会相当令人吃惊。
值得计时没有ALU操作的加载/存储,看一下内存瓶颈吗?
首先,讨论的重点是关于加载和存储操作的性能分析。在这个过程中,我们决定先进行一次基础的测试,暂时去除所有的操作,只集中于加载和存储,目的是观察是否是内存操作导致的性能瓶颈。
初步的想法是,先关闭一些不必要的操作,比如计数周期,专注于加载和存储的操作。这意味着需要移除大部分复杂操作,只保留简单的内存加载和存储逻辑。然而,这并不是一个完全简单的操作,因为必须确保数据从正确的内存位置读取,否则可能会改变缓存行为,影响测试结果。
为了避免编译器优化掉某些无效的操作,我们采取了一些措施,比如使用无意义的赋值操作来保证这些加载操作不会被优化掉。通过这种方式,可以确保内存加载操作的执行。
测试结果显示,即使去掉了许多复杂操作,依然存在一定的性能开销。特别是每次加载操作的时间仍然保持在16个周期左右,这表明内存访问仍然是瓶颈。进一步分析发现,内存加载的开销可能来自于对纹理数据的访问,这一过程非常耗时。
为了更清楚地了解性能瓶颈,接下来我们尝试进一步简化操作,将加载的数据从事先准备好的值中提取出来,而不是通过复杂的计算来获取。这样可以减少计算负担,进一步观察内存加载操作的实际性能。
最终的结果显示,去除了计算后,性能得到了明显改善,达到每个像素只需要3个周期的开销。虽然测试中还有一些不确定因素,比如数据是否完全来自内存缓存,但结果表明,加载纹理数据的确是性能瓶颈之一。




你能打开任务管理器运行游戏吗?
提到了机器的硬件资源使用情况。首先,提到内存的使用情况:内存几乎没有被占用,因为系统启动时已经分配了所有的内存,但是实际上并没有触及这些内存资源。接着,关于CPU的使用,说明目前CPU的使用率非常低,几乎没有什么负载,CPU的负担也几乎为零。
进一步分析,提到机器的性能,虽然机器的配置较老,但在计算能力上仍然非常强大。推测该机器可能具有16个逻辑核心(即每个物理核心有超线程),总共可能是一个双处理器系统,每个处理器有4个核心,并且每个核心都有两个超线程。
目前,程序只使用了一个核心,且主要是通过像素填充的例程来进行计算,因此尚未完全发挥出机器的多核处理能力。期待未来的优化和工作负载分配能够更好地利用所有核心,从而提升性能。
总结来说,目前机器的计算资源还没有得到充分利用,CPU和内存的使用都比较低,后续有可能通过优化代码和分配工作负载来提升效率,充分利用机器的所有计算核心。
这个游戏只能在你的特定处理器上运行吗?
这款游戏并不是只能在特定的处理器上运行,它可以在任何具备SSO(Single Instruction, Multiple Data)能力的处理器上运行。实际上,只要是现代的PC或Mac处理器,不论是Windows系统还是其他操作系统的电脑,都可以运行这款游戏。
你会更新黄色背景的纹理吗?
由于我们关闭了地面缩放更新,黄色背景仍然存在。事实上,黄色背景是因为我们暂时停止了这一更新。与此同时,我们还没有采用新的渲染系统进行更新,因此我们需要重新处理相关内容。由于目前不在进行这个部分的工作,所以这些地面砖块没有得到更新。
纹理提取应该是L1缓存提取。
我们希望纹理提取可以是一次性完成的,但目前并不确定是否总是如此。虽然在某些情况下这可能成立,但我们不能确定它是否总是有效。因为处理器可能无法及时获取相关信息,或者存在其他可能的原因。因此,现在说这种事情还为时过早。
在一个没有人在意艺术资源,你认为优化会仍然是开发者的重点吗?
在一个所有人都喜欢游戏但没有人关心艺术资源,游戏开发者是否仍会花时间仔细优化内容?我们认为,答案可能是肯定的,因为优化通常是为了能够做更多的事情,而不仅仅是为了使用艺术资源。比如,如果你想在一场战斗中放置十万个人物,人物的外观并不重要,不管是红色矩形,还是人物的位图,甚至是3D的小人偶都无关紧要。
当然,如果艺术效果本身并不重要,使用低多边形、无纹理等方式确实可以帮助优化,但优化并不仅限于艺术资源,开发者仍然需要优化其他方面的内容。
为什么移除gamma校正后,速度没有更大的提升?
去除伽马校正中的三个平方根操作,虽然它们的吞吐量是16个周期,但只节省了6个周期,原因在于这些操作是重叠执行的。当处理器开始计算平方根时,它可以同时执行其他任务,而不必等待平方根的结果返回。因此,尽管这些操作的总时间是16个周期,但在这16个周期内,处理器可以处理其他工作,特别是在拥有多个执行单元的处理器中。即使编译器的指令调度不好,处理器仍能抓取未来的任务。
这里的关键在于流水线处理,即处理器每个周期都在执行多项任务。去除一个占用16个周期的操作,并不是完全节省了16个周期,而是将这个操作移除后,处理器可以更好地重叠其他任务。最终,节省的周期更多取决于处理器单元的空闲情况、执行单元的数量以及它们的使用效率。因此,尽管我们缺乏足够的信息来完全计算这些优化带来的效果,重叠执行和资源的合理利用是关键因素。
我们将如何把绘制任务分配到多个核心?
如果要使用更多的核心进行绘制,工作会如何分配呢?我们实际上已经计划要这么做,这就是接下来要做的事情。所以,敬请期待,下周我们可能会专门讨论如何分配绘制工作的核心。
关于 _mm_ps_sqrt 和常见子表达式消除的问题
我没有看到“mmSquare”的定义。如果它是一个宏,并且你是通过一个内置函数来调用它,那么可能是编译器没有消除公共子表达式,导致性能损失,或者是编译器确实进行了公共子表达式消除,但在指令计数上出现了错误。我们检查过,实际上编译器已经正确地进行了公共子表达式消除。所以我们认为问题不在这两方面。在计数时,我们只是把它当作一次乘法来处理,因此我们认为答案应该是“以上都不是”,但没有足够的信息来准确回答这个问题。
处理器在变频的情况下,rdtsc可能不准确吗?
是否处理器支持恒定速率会影响到某些操作的准确性,具体情况取决于操作系统和处理器的表现。对于某些处理器,尤其是非笔记本电脑,它们可能会在某些时刻调整周期速率,这会影响到定时操作,从而引发问题。
然而,在大多数现代处理器上,特别是较新的设备,通常不会再遇到这个问题。现代处理器倾向于提供更稳定的周期速率,并能够准确报告系统的状态,尽量避免这种不准确性。在实际应用中,避免让机器进入节能模式等,也能帮助减少这些问题的出现。
CPU如何提前完成任务,而这些任务本应按顺序执行?
当处理器执行代码时,并不是每条指令都需要按顺序执行。只要满足某些条件,就可以提前执行某些指令。基本原理是,处理器会检查哪些指令彼此独立且不依赖于正在执行的其他指令。如果指令间没有依赖关系,处理器可以选择提前执行这些指令。
例如,假设有多个乘法操作,它们之间没有任何依赖关系。处理器可以选择执行其中一些,即使其他指令还在等待完成。换句话说,只要某些操作之间没有依赖关系,就可以并行执行,不需要按顺序等待。
处理器决定是否能提前执行指令主要考虑以下几个因素:
-
每个周期内能解码多少条指令:这是处理器的解码能力,不同的处理器可能有不同的解码限制。
-
指令之间的依赖关系:处理器会检查当前可执行的指令之间是否有依赖关系。例如,如果某个乘法操作依赖于另一个操作的结果,它必须等第一个操作完成后才能执行。如果指令之间没有依赖关系,处理器就能同时执行它们。
-
可用的执行单元:处理器的执行单元有多少,决定了可以并行执行多少指令。如果有多个独立的执行单元,处理器能够同时处理更多的指令。
-
解码窗口中的独立指令数量:解码窗口决定了当前可以选择哪些指令进行执行。如果在窗口中存在多个相互独立的指令,处理器就能选择其中的指令执行。
这些因素决定了处理器能否有效地提前执行指令,以提高效率。对于游戏开发者或硬件优化人员来说,理解这些基本原理有助于在特定处理器上优化程序的执行效率。不同的处理器架构(例如Intel或某些控制台处理器)可能在这些方面有所不同,因此需要根据具体情况进行调整和优化。
总结来说,代码执行并不需要严格按顺序进行,只要满足指令之间的依赖关系,处理器就可以选择提前执行不相互依赖的指令。
你预期通过多线程可以实现16倍的加速吗?
通常情况下,使用多线程并不会得到完美的加速,例如期望的16倍加速。实际上,得到完美的加速非常罕见。虽然尚未进行详细计算来估算具体的加速比率,但经验表明,处理器的性能提升通常会受到多个因素的制约。
即使增加了更多的线程,也可能由于线程间的协调、共享资源的竞争、同步开销等问题,导致加速效果没有预期的那么明显。尤其是在处理器核心数量有限的情况下,多线程的性能提升会面临瓶颈,无法达到理想的加速比。
因此,虽然多线程在理论上能提升程序的执行速度,但实际效果通常低于预期,特别是当程序的并行度受到硬件或资源的限制时。
你如何选择优化时使用的指令集?
选择指令集来进行优化时,并没有一个完全精确的科学方法。一般来说,主要依赖现有的硬件和可用的工具,虽然这些工具不完美,但至少能提供一定的数据支持,远比没有任何工具要好。
以Steam平台为例,可以通过查看玩家的硬件配置来判断选择哪种指令集。例如,若目标是面向高端玩家,可以选择较新的指令集(如SSC 3),但这会大幅度限制潜在市场,因为大部分玩家使用的硬件并不支持这些高端指令集。大约四分之三到五分之四的玩家可能没有达到这种硬件标准,因此若选择了这种优化方式,就会牺牲相当一部分市场。
此外,选择指令集时,还要考虑到当前玩家的硬件分布。比如,SSC 2支持的玩家群体较大,而SSC 3虽然有较好性能,但其市场份额相对较小。对于大多数游戏来说,选择支持SSC 2的指令集是更安全的选择,因为它能够覆盖绝大多数玩家。尽管如此,如果有特殊需求,选择更高版本的指令集也是可以考虑的,尤其是当该指令集足够成熟且有较少的兼容性问题时。
另外,在某些情况下,例如使用软件渲染时,可以选择更先进的指令集,只要确保游戏的主流版本不依赖于过于稀有的硬件配置。最终,选择指令集的策略通常是根据市场的大部分用户配置来做决策,以保证大多数玩家都能顺利体验游戏。
Unity的硬件调查结果与Steam的调查结果不是很相同吗?
关于Unity的硬件调查结果,似乎和其他来源的调查结果有所不同。实际上,并没有详细了解过Unity新发布的硬件调查数据,之前也没怎么看过它。现在可以尝试查看这些数据,但从目前的信息来看,它们并没有明确列出处理器的具体模型和硬件支持情况。
调查数据中没有特别提到关于SSC(可能指的是某种指令集或硬件支持)能力的相关内容,所以目前无法直接从这些数据中得出结论。如果能找到具体的链接,可能会更方便深入查看。
写自己的软件渲染器与使用SDL、GPU等相比,获得的收益是什么?
编写自己的软件渲染器并不会带来直接的性能提升,特别是相对于使用像STL这样的硬件或软件渲染器。实际上,创建自己的软件渲染器并不是为了性能优化,而是为了展示整个游戏运行的代码过程。目标是能够展示在处理器上如何执行代码,从而让观众更清楚地理解渲染的每一个细节。
之所以选择编写自己的软件渲染器,是为了展示如何在CPU上实现GPU的渲染工作。这种方式使得代码可以完全可见,方便演示渲染的工作原理。不过,在实际的游戏开发中,最终的渲染操作还是会交给硬件处理,可能使用OpenGL或者在合适的时机使用Vulkan,来完成游戏的最终渲染。因此,软件渲染器更多是作为教学和展示工具使用,而非实际的优化方案。
处理器是否可以在一个周期内处理不同类型的计算?
处理器在一个时钟周期内确实能够并行执行不同的计算任务,例如加法、乘法、平方根等操作。具体能否并行执行取决于处理器的架构和内部单元的配置。现代的CPU由多个单元组成,这些单元可以执行不同的任务。例如,有的单元专门处理加法,有的处理乘法等。只要这些单元处于空闲状态,就可以在同一个时钟周期内发起不同的操作。
例如,在处理器中,如果加法单元和乘法单元同时空闲,处理器就可以在同一周期内发出加法和乘法指令,之后再分别获取结果。同时,像平方根这样的复杂操作虽然可能需要多个时钟周期,但它也不会阻塞其他单元的操作。其他较简单的操作可以继续进行。
这种并行执行的能力是现代处理器的特点,不同于早期的微处理器,后者只能按照顺序执行指令,必须等待前一条指令完成后才能执行下一条。现代处理器的复杂性使得它们能在每个时钟周期内执行更多操作,因此不再是单纯的按顺序依次执行。
可以将哪些任务委托给GPU处理?
关于将计算任务委托给GPU而不是CPU,实际上几乎所有的计算任务都可以从CPU转移到GPU上,但需要考虑几个关键因素。首先,GPU的架构是针对大量相同操作的并行处理优化的,特别适合大规模的宽数据操作(例如16宽或更宽的计算)。因此,GPU非常适合那些能够高效利用大数据块和内存流的任务,像纹理流的处理和图像渲染等。
然而,GPU并不擅长处理随机访问或单宽数据操作。如果任务的计算需求与GPU的并行架构不匹配,GPU的效率可能反而比CPU低。例如,处理单线程或单宽操作时,CPU的表现通常会优于GPU,因为现代的Intel处理器在这种类型的工作负载下非常高效。而且,GPU通常工作在较低的时钟频率上,且为大规模并行计算优化,不适合执行像游戏逻辑、脚本语言执行等操作。
因此,在实际应用中,通常会将那些可以并行化的图形处理或数字运算工作负载转移到GPU,而将更适合单线程执行的任务,如游戏逻辑和脚本执行,留给CPU处理。
在开发过程中,虽然GPU现在变得更加通用,但如果任务不符合GPU的优势,使用CPU会更加高效。需要合理地拆分任务,并在CPU和GPU之间做好负载分配,才能充分发挥硬件的优势。
最后,回到渲染优化的部分,渲染已经非常快速,甚至超出了预期。通过将渲染操作转换为宽度较大的并行操作,性能得到了显著提升,而不需要复杂的优化策略。这是由于现代处理器的强大性能,使得任务得以快速执行,而不需要特别的“黑魔法”。
相关文章:
游戏引擎学习第119天
仓库:https://gitee.com/mrxiao_com/2d_game_3 上一集回顾和今天的议程 如果你们还记得昨天的进展,我们刚刚完成了优化工作,目标是让某个程序能够尽可能快速地运行。我觉得现在可以说它已经快速运行了。虽然可能还没有达到最快的速度,但我们…...

爬虫解析库:Beautiful Soup的详细使用
文章目录 1. 安装 Beautiful Soup2. 基本用法3. 选择元素4. 提取数据5. 遍历元素6. 修改元素7. 搜索元素8. 结合 requests 使用9. 示例:抓取并解析网页10. 注意事项 Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库,它提供了简单易用的 API…...

OpenHarmony-4.基于dayu800 GPIO 实践(2)
基于dayu800 GPIO 进行开发 1.DAYU800开发板硬件接口 LicheePi 4A 板载 2x10pin 插针,其中有 16 个原生 IO,包括 6 个普通 IO,3 对串口,一个 SPI。TH1520 SOC 具有4个GPIO bank,每个bank最大有32个IO: …...

【C++设计模式】观察者模式(1/2):从基础到优化实现
1. 引言 在 C 软件与设计系列课程中,观察者模式是一个重要的设计模式。本系列课程旨在深入探讨该模式的实现与优化。在之前的课程里,我们已对观察者模式有了初步认识,本次将在前两次课程的基础上,进一步深入研究,着重…...

《机器学习数学基础》补充资料:欧几里得空间的推广
在《机器学习数学基础》第 1 章介绍了向量空间,并且说明了机器学习问题通常是在欧几里得空间。然而,随着机器学习技术的发展,特别是 AI 技术开始应用于科学研究中,必然会涉及到其他类型的空间。本文即在《机器学习数学基础》一书所…...
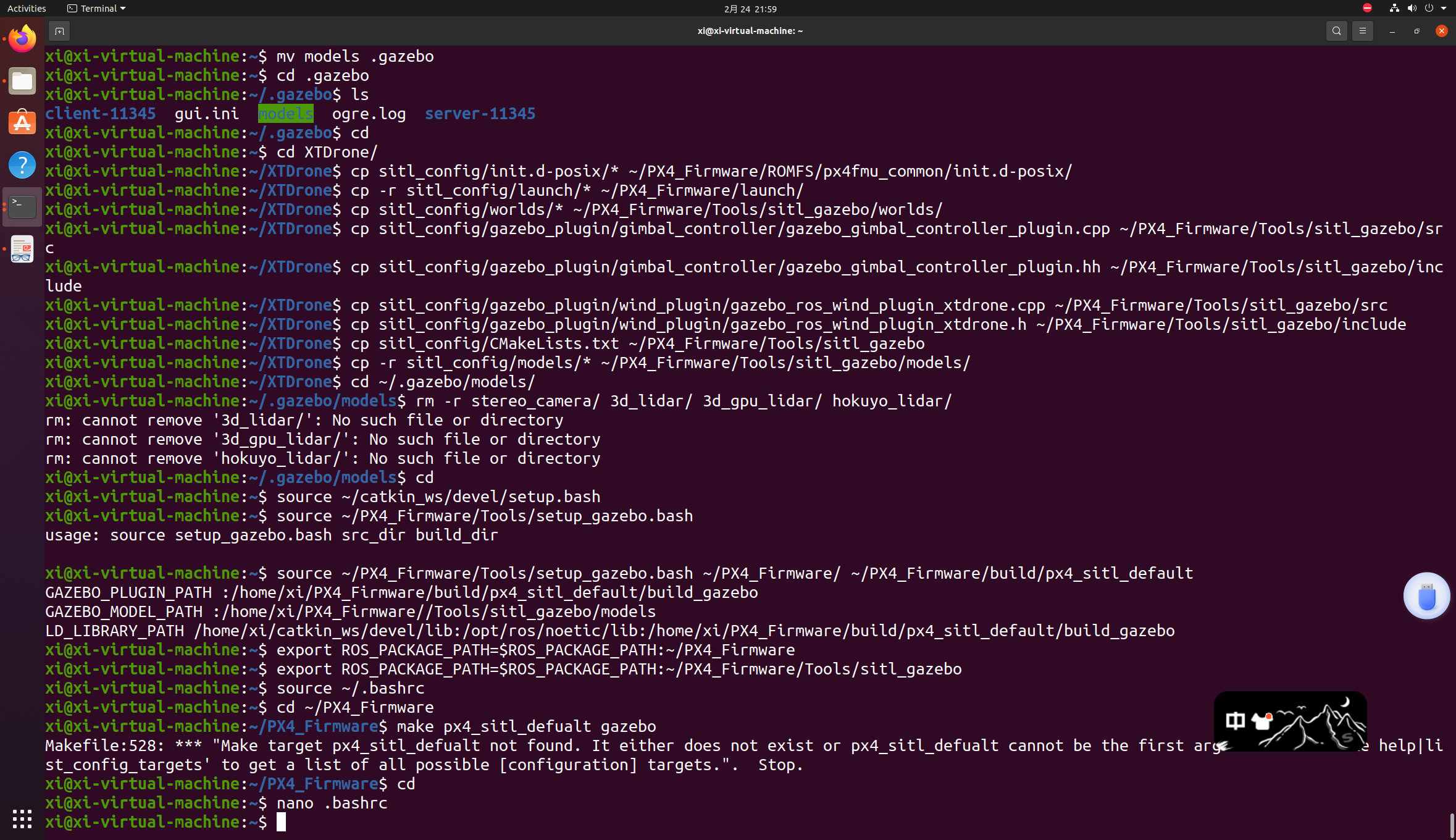
在配置PX4中出现的问题2
想要原教程的请看:第一次配置中出现的问题 前面一切正常(gazebo导入models那一步在刚刚解压好的文件夹里就删不掉stereo_camera等文件,ls打开也看不到,应该时我下的包里面本来就没有),到 make px4_sitl_def…...
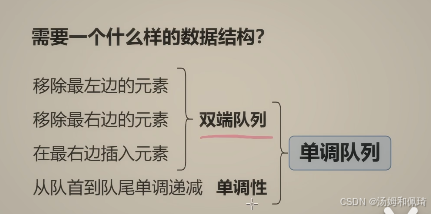
2025-2-24-4.9 单调栈与单调队列(基础题)
文章目录 4.9 单调栈与单调队列(基础题)单调栈739. 每日温度42. 接雨水单调队列239. 滑动窗口最大值 4.9 单调栈与单调队列(基础题) 很有趣的两个数据结构。 原视频讲解链接 单调栈 739. 每日温度 题目链接 给定一个整数数组 te…...

python绘图之swarmplot分布散点图
swarmplot 是 Seaborn 提供的一种用于展示分类数据分布的散点图。它的主要作用是将数据点按照分类变量(通常是离散变量)进行分组,并在每个分类中以一种非重叠的方式展示数据点的位置。这种可视化方式可以帮助我们直观地理解数据在不同分类下的…...
)
数据库之MySQL——事务(一)
1、MySQL之事务的四大特性(ACID)? 原子性(atomicity):一个事务必须视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操…...

Linux学习笔记之文件
1.文件 1.1文件属性 当我们创建文件时,文件就有了对应的属性,可以用mkdir创建目录,touch创建普通文件。用ls -al查看文件属性。 从上图可以看出目录或者文件的所有者,所属组,其他人权限,创建时间等信息。由…...

LLM学习
1、基础概念篇 大模型训练三部曲Pretraining SFT RLHF...
Classic Control Theory | 13 Complex Poles or Zeros (第13课笔记-中文版)
笔记链接:https://m.tb.cn/h.TtdexbP?tkeFAlejKBSzQhttps://m.tb.cn/h.TtdexbP?tkeFAlejKBSzQ...

给小米/红米手机root(工具基本为官方工具)——KernelSU篇
目录 前言准备工作下载刷机包xiaomirom下载刷机包【适用于MIUI和hyperOS】“hyper更新”微信小程序【只适用于hyperOS】 下载KernelSU刷机所需程序和驱动文件 开始刷机设置手机第一种刷机方式【KMI】推荐提取boot或init_boot分区 第二种刷机方式【GKI】不推荐 结语 前言 刷机需…...

【MySQL】表的增删查改(CRUD)(上)
个人主页:♡喜欢做梦 欢迎 👍点赞 ➕关注 ❤️收藏 💬评论 CRUD:Create(新增数据)、Retrieve(查询数据)、Update(修改数据)、Delete(修改数据…...

测试用例的Story是什么?
测试用例的 Story(用户故事)是指描述某个功能或场景的具体用户需求,它通常以简短的业务背景用户操作期望结果的方式呈现,使测试人员能够理解测试的目标和价值。用户故事能够帮助团队更好地设计测试用例,确保功能满足用…...

15.4 FAISS 向量数据库实战:构建毫秒级响应的智能销售问答系统
FAISS 向量数据库实战:构建毫秒级响应的智能销售问答系统 关键词:FAISS 向量数据库、销售知识库构建、相似度检索优化、大规模问答匹配、量化索引技术 1. 销售问答场景的向量化挑战与解决方案 1.1 传统检索方案痛点分析 #mermaid-svg-AeVgih79asJb7lb8 {font-family:"…...

Golang笔记——Interface类型
大家好,这里是,关注 公主号:Goodnote,专栏文章私信限时Free。本文详细介绍Golang的interface数据结构类型,包括基本实现和使用等。 文章目录 Go 语言中的 interface 详解接口定义实现接口空接口 interface{} 示例&…...

如何查看图片的原始格式
问题描述:请求接口的时候,图片base64接口报错,使用图片url请求正常 排查发现是图片格式的问题: 扩展名可能被篡改:如果文件损坏或扩展名被手动修改,实际格式可能与显示的不同,需用专业工具验证…...

FreiHAND (handposeX-json 格式)数据集-release >> DataBall
FreiHAND (handposeX-json 格式)数据集-release 注意: 1)为了方便使用,按照 handposeX json 自定义格式存储 2)使用常见依赖库进行调用,降低数据集使用难度。 3)部分数据集获取请加入:DataBall-X数据球(free) 4)完…...

【Rust中级教程】2.8. API设计原则之灵活性(flexible) Pt.4:显式析构函数的问题及3种解决方案
喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 说句题外话,这篇文章一共5721个字,是我截至目前写的最长的一篇文章&a…...

四、Zabbix监控-实战SNMP协议监控异构IT资产
1. SNMP协议:异构IT监控的通用语言 第一次接触企业级IT监控时,我被机房里的设备多样性惊呆了——思科交换机的CLI界面、华为路由器的Web配置、惠普打印机的专用协议,还有那些老旧到连SSH都不支持的服务器。当时就在想:难道要为每个…...

4.9、从CVE-2007-2447到永恒之蓝:Samba漏洞利用的攻防演进
1. Samba服务与SMB协议的前世今生 第一次接触Samba是在2008年的一次企业内网渗透测试中。当时客户要求在不影响业务的情况下,评估文件共享服务器的安全性。当我用nmap扫描到139和445端口时,一个熟悉的"Samba 3.0.24"版本号让我眼前一亮——这不…...

别再只盯着5G了!车联网里那些不起眼但至关重要的通信技术:CAN总线、LoRa与RFID实战解析
车联网底层通信技术实战:CAN总线、LoRa与RFID的工程化落地指南 当行业热议5G车联网时,真正决定系统稳定性的往往是那些沉默的"基础设施级"通信协议。在重庆某智能网联汽车测试场,我们曾目睹一辆搭载最新5G模组的原型车因CAN总线仲裁…...
)
别再手动对齐维度了!用PyTorch广播机制让你的张量运算代码更简洁(附常见错误排查)
别再手动对齐维度了!用PyTorch广播机制让你的张量运算代码更简洁(附常见错误排查) 在深度学习项目中,我们常常需要处理形状各异的张量进行运算。想象一下这样的场景:你需要将一个形状为(3,1)的偏置向量加到形状为(3,25…...
)
AI核心知识130—大语言模型之 多模态大模型(简洁且通俗易懂版)
如果说我们之前聊的纯文本大模型(如早期的 ChatGPT 或 LLaMA)是极其聪明但被关在小黑屋里的“缸中之脑” (只能靠别人从门缝里递纸条来交流);那么多模态大模型 (Multimodal AI) 就是给这个超级大脑装上了眼睛、耳朵和嘴…...

终极指南:使用LeetDown为iPhone和iPad进行快速降级恢复
终极指南:使用LeetDown为iPhone和iPad进行快速降级恢复 【免费下载链接】LeetDown a GUI macOS Downgrade Tool for A6 and A7 iDevices 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown 你是否拥有一台运行缓慢的iPhone 5s或iPad 4?苹果的…...

3分钟掌握PPTist模板系统:打造专业演示文稿的终极秘籍
3分钟掌握PPTist模板系统:打造专业演示文稿的终极秘籍 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing fo…...
)
保姆级教程:手把手搭建你的第一个ARM AHB+APB+CPU小系统(附仿真环境配置)
从零构建ARM AHBAPBCPU系统的实战指南 在数字IC设计领域,能够独立完成一个完整的SOC系统集成是工程师能力的重要分水岭。本文将带你从零开始,构建一个基于AMBA总线架构的简易SOC系统,包含AHB、APB总线和CPU核心的完整集成方案。不同于理论概述…...

芯片行业为什么还不能把研发全托付给Agent
芯片行业有一个词叫"良率",指的是生产出来的芯片中符合规格的比例。现在AI研发流程里,有一个类似的问题我觉得可以叫做AI流程良率:Agent自动化执行一个完整流程,最终得到符合预期结果的概率是多少?一个Agent…...

Phi-3-vision-128k-instruct嵌入式开发实战:从电路图到驱动代码的智能辅助
Phi-3-vision-128k-instruct嵌入式开发实战:从电路图到驱动代码的智能辅助 1. 嵌入式开发的痛点与智能解决方案 在传统嵌入式开发流程中,工程师需要花费大量时间在硬件与软件的衔接环节。从阅读芯片手册、理解电路原理图,到编写底层驱动代码…...