深度学习-6.用于计算机视觉的深度学习
Deep Learning - Lecture 6 Deep Learning for Computer Vision
- 简介
- 深度学习在计算机视觉领域的发展时间线
- 语义分割
- 语义分割系统的类型
- 上采样层
- 语义分割的 SegNet 架构
- 软件中的SegNet 架构
- 数据标注
- 目标检测与识别
- 目标检测与识别问题
- 两阶段和一阶段目标检测与识别
- 两阶段检测器:Faster R - CNN
- 一阶段检测:YOLO
- YOLO损失函数
- 非极大值抑制(Non - maximum suppression,NMS)
- YOLO 系列模型的发展历程及主要改进点
- 实例分割
- 总结
- 引用
本节目标:
- 解释深度学习在计算机视觉中的主要用途
- 为计算机视觉设计并实现深度学习系统
本节中只是粗略介绍用于计算机视觉(computer vision, CV)的一些网络,更加详细的内容我之后会在机械视觉的课程中展示。
简介
深度学习对计算机视觉产生了重大影响。

上图展示了计算机视觉中的四个不同任务,分别以牛的图像为例:
- (a) 图像分类(Image Classification):对整个图像进行分类,判断图像中是否存在牛这一类别,这里确定图像中有牛。
- (b) 目标检测(Object Detection):不仅要检测出图像中是否存在牛,还要用边界框(如红、绿、蓝框)标出每头牛在图像中的具体位置。
- © 语义分割(Semantic Segmentation):将图像中的每个像素分配到特定的类别(这里是牛),把图像中属于牛的区域用绿色进行分割标记,不区分具体是哪头牛。
- (d) 实例分割(Instance Segmentation):在语义分割的基础上,进一步区分出不同的个体实例,每头牛用不同颜色(如红、绿、黄)进行分割和标记,并编号1、2、3 。
深度学习在计算机视觉领域的发展时间线

- 图像识别(Image Recognition):2012年出现Alexnet,2013年有ZFNet,2014年是VGGNet,2015年为GoogleNet、ResNet,2016年有MobileNet,2019年是EfficientNet,2020年为NasNet。
- 目标检测(Object Detection):2014年出现R - CNN,2015年有Fast R - CNN,2016年是Faster R - CNN、Yolo,2017年为SSD、Retinanet、Yolo - v2 。
- 语义分割(Semantic Segmentation):2015年有FCN,2016年是U - Net、SegNet,2018年为DeepLabv3+ 。
- 实例分割(Instance Segmentation):2017年出现Mask R - CNN,2018年有PANet,2019年是Yolact,2020年为Solo 。 这些模型推动了计算机视觉领域深度学习技术的发展和应用。
语义分割
语义分割是将图像的每个像素与一个类别标签相关联的过程。
语义分割系统的类型
有多种知名的语义分割系统,多数采用编码器 - 解码器架构
- 全卷积网络,如FCN(Long等人,2015年);
- 编码器 - 解码器结构,如SegNet(Badrinarayanan等人,2017年);
- 带跳跃连接的编码器 - 解码器,如U - Net(Ronneberger等人,2015年);
- 多尺度编码器 - 解码器,如DeepLabV3 +(Chen等人,2018年)。
图片下方有一个卷积编码器 - 解码器的示意图,展示了从输入RGB图像到输出分割结果的过程。

上图为一个卷积编码器 - 解码器的示意图,输入图像经过一系列我们之前学过的网络层,诸如:卷积(Conv)、批量归一化(Batch Normalisation)、ReLU 激活函数操作,还有池化(Pooling),最后和上采样(Upsampling)(这个马上学)步骤,最终通过 Softmax 得到分割结果。
上采样层
解码器系统中的上采样方法分为两类:
- 固定方法:快速、简单。
- 学习方法:训练较慢,但可能更准确。

- 最近邻法(Nearest neighbour):左侧示例图中,输入为2×2的矩阵,数值分别为1、2、3、4。通过最近邻上采样,输出为4×4的矩阵,每个小格中的数值由最近邻的输入值填充。此方法是刚刚提到的固定采样方法。
- 最大反池化法(Max Unpooling):中间示例图中,输入同样为2×2的矩阵,输出为4×4的矩阵。其中非零位置由编码器层中相应最大池化步骤的索引定义。此方法也是固定采样方法。
- 转置卷积法(Transposed Convolution):右侧示例图展示了输入2×2的矩阵(周围有零填充)通过转置卷积操作,输出为4×4的矩阵。此方法是学习方法。
语义分割的 SegNet 架构
SegNet 系统采用编码器 - 解码器架构,在解码器阶段使用最大反池化(max unpooling)

软件中的SegNet 架构
Matlab 有一个特定函数 “segnetLayers” 用于实现 SegNet 语义分割系统。
- Matlab 使用一种称为层图(layer graph,‘lgraph’)的特定结构来构建 SegNet。
- 层图对于实现具有来自多个层的输入和输出到多个层的深度网络来说是更灵活的结构。
% Create SegNet layers.
imageSize = [32 32];
numClasses = 2;
numLayers = 3;
lgraph = segnetLayers(imageSize,numClasses,numLayers)
% training data
ds = combine(imds,pxds);
% Set up training options.
options = trainingOptions('sgdm','InitialLearnRate',1e-3, ...
'MaxEpochs',20,'VerboseFrequency',10);
% Train the network
net = trainNetwork(ds,lgraph,options)
Python部分则还是之前的keras,需要手搓。
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D
from keras.layers import Activation# Encoder
conv1 = Conv2D(64, 3, activation='relu', padding='same')(inputs)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(128, 3, activation='relu', padding='same')(pool1)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)# Decoder
up2 = UpSampling2D(size=(2, 2))(pool2)
deconv2 = Conv2D(128, 3, activation='relu', padding='same')(up2)
up1 = UpSampling2D(size=(2, 2))(deconv2)
deconv1 = Conv2D(64, 3, activation='relu', padding='same')(up1)# Output
outputs = Conv2D(num_classes, 1, padding='same')(deconv1)
outputs = Activation('softmax')(outputs)# Create the model
model = Model(inputs, outputs)
数据标注
实施自己的计算机视觉项目时,通常需要自行标注数据。
-
在Matlab 提供了一个有用的工具 “imageLabeler”,可在命令行中输入该名称启动。

-
当然也有许多非 Matlab 的图像标注工具,包括:
- VGG 图像标注器 (VGG Image Annotator, VIA),网址为:https://www.robots.ox.ac.uk/~vgg/software/via/
- Labelme 网址为 :http://labelme.csail.mit.edu/Release3.0/ ;
- CVAT,网址为 https://www.cvat.ai/ 。
目标检测与识别
目标检测与识别是指在图像中找到一个目标,并用边界框框出,同时识别框内的物体是什么.

目标检测与识别问题
目标检测与识别是将回归和分类融合成了一个单一的问题。

- 左边是输入图像,作为检测与识别的对象来源。
- 中间是目标检测与识别系统,对输入图像进行处理分析。
- 右边是输出结果,包含了边界框(bounding box)和类别(class)。在右侧的示例图像中,用黄色框标注出了汽车,并且还标注了类别标签(class label)、中心 x x x 坐标( x − c e n t r e x - centre x−centre)、中心 y y y 坐标( y − c e n t r e y - centre y−centre)、高度(height)和宽度(width),这些信息用于精准定位和识别目标物体。
过程中的损失函数 J ( θ ) J(\theta) J(θ)为:
J ( θ ) = ∑ j = 1 m e j T e j + γ ∑ j = 1 m ∑ k = 1 K y j , k log y ^ j , k J(\theta)=\sum_{j = 1}^{m} e_{j}^{T} e_{j}+\gamma\sum_{j = 1}^{m}\sum_{k = 1}^{K} y_{j,k} \log \hat{y}_{j,k} J(θ)=j=1∑mejTej+γj=1∑mk=1∑Kyj,klogy^j,k
损失函数由两部分构成:
- 左边部分:
∑ j = 1 m e j T e j \sum_{j = 1}^{m} e_{j}^{T} e_{j} j=1∑mejTej
是边界框的平方误差损失(Bounding box squared error loss),它的作用是衡量边界框预测值和真实值之间的误差情况,其中 e j e_{j} ej 是与边界框相关的误差向量。 - 右边部分:
γ ∑ j = 1 m ∑ k = 1 K y j , k log y ^ j , k \gamma\sum_{j = 1}^{m}\sum_{k = 1}^{K} y_{j,k} \log \hat{y}_{j,k} γj=1∑mk=1∑Kyj,klogy^j,k
是分类的交叉熵损失(Classification categorical cross - entropy loss),用于衡量分类的预测结果和真实标签之间的差异。这里的 y j , k y_{j,k} yj,k 是真实标签, y ^ j , k \hat{y}_{j,k} y^j,k 是预测标签, K K K 是类别数量, γ \gamma γ 是一个用于平衡这两项损失的参数。
两阶段和一阶段目标检测与识别
目标检测与识别系统中的两种主要类型:两阶段和一阶段检测器:
- 两阶段检测器
- 特点:速度较慢,但更准确。
- 示例:Faster R - CNN。
- 流程:第一阶段生成区域建议(region proposal),第二阶段对目标进行检测和分类。
- 一阶段检测器
- 特点:速度较快,但准确性较低。
- 示例:YOLO。
- 流程:检测和目标识别在单个阶段完成。

上图展示了从2013 - 2021年一些代表性检测器的发展时间线。2013 - 2016年主要是两阶段检测器的发展,如R - CNN、Fast R - CNN、Faster R - CNN;2016 - 2021年主要是一阶段检测器的发展,如Yolo、SSD、Yolo - v2、Yolo - v3 。
两阶段检测器:Faster R - CNN
Faster R - CNN是一种流行的两阶段检测/识别系统,它使用一个单独的区域建议网络。

- 第一阶段:区域建议(Region Proposal)
- 深度学习区域建议网络(Deep Learning Region Proposa)对目标/无目标进行二分类,并生成边界框。
- 二分类的含义:在目标检测场景下,区域建议网络会在输入图像中划分出大量不同的候选区域。对于每个候选区域,它只判断两件事:这个区域里有没有目标物体。因此,输出结果只有两种状态,即 “有目标物体”(正类)和 “没有目标物体”(负类),这就是二分类。
- 输入图像首先经过深度卷积网络特征提取器(Deep Conv Net Feature Extractor),然后通过感兴趣区域最大池化(Region of Interest Max Pooling, ROI Pooling),将特征图转换为固定大小的特征向量,为后续的区域建议提供特征。
- 深度学习区域建议网络(Deep Learning Region Proposa)对目标/无目标进行二分类,并生成边界框。
- 第二阶段:目标检测/识别(Object Detection/Recognition)
- 分类层(Classification Layers)进行目标类别的预测。
- 回归层(Regression Layers)进行边界框的调整,最终输出目标的类别和精确的边界框。
相关发展
- R - CNN:仅用于类别预测的卷积深度网络。
- Fast R - CNN:深度网络用于类别和边界框预测,但不用于区域建议。
- Faster R - CNN:全深度卷积网络(但性能较慢)。
一阶段检测:YOLO
YOLO(You Only Look Once)模型基于标准卷积网络,并对输出层进行了巧妙选择。

网络结构
- 主干网络(Backbone Network):由卷积层(Conv)和最大池化层(Maxpool)组成。
- 全连接层(Fully connected x2):位于主干网络之后。
- 头部网络(Head Network):最终输出维度为 7 × 7 × 30 7\times7\times30 7×7×30 。
输出解释
-
网络将图像视作被划分为 7 × 7 7\times7 7×7的网格单元,因此输出是 7 × 7 × 30 7\times7\times30 7×7×30 。分法就像下面这样。

-
30个输出包含:
- 2个边界框,每个边界框有4个坐标值 ( x , y , w , h ) (x, y, w, h) (x,y,w,h) ,共 4 × 2 4\times2 4×2个值。
- 每个边界框对应一个置信度分数,共 1 × 2 1\times2 1×2个值。
- 所有类别(共20个类别)的预测分数。
-
对于网格单元 i , j i, j i,j ,其预测值 y ^ i , j \hat{y}_{i,j} y^i,j包含上述共30个元素,即 ( x , y , w , h , c , x , y , w , h , c , z 1 , … , z k ) (x, y, w, h, c, x, y, w, h, c, z_1, \ldots, z_k) (x,y,w,h,c,x,y,w,h,c,z1,…,zk) ,其中 x , y , w , h x, y, w, h x,y,w,h是边界框坐标和尺寸, c c c是置信度, z 1 , … , z k z_1, \ldots, z_k z1,…,zk是类别分数。
-
为什么所有类别是20个?
在早期版本的YOLO(比如YOLO v1)中,其训练和应用场景常基于PASCAL VOC数据集。PASCAL VOC数据集包含20个常见的目标类别,例如人、汽车、自行车、猫、狗等。所以模型输出会针对这20个类别进行预测,以判断每个网格单元中是否存在这些类别的目标。 -
为什么只输出两个边界框?
- 平衡计算量与检测效果:YOLO模型为了在检测速度和一定的检测精度间取得平衡。输出两个边界框可以让模型对每个网格单元内可能存在的目标提供两种不同的定位预测。这样既不会因为边界框数量过多导致计算量大幅增加、检测速度变慢,又能在一定程度上提高对目标的定位准确性。
- 目标重叠处理:在实际图像中,可能存在多个目标部分重叠的情况。两个边界框可以分别去拟合不同的目标,或者对同一个目标从不同角度进行更准确的定位。例如,当两个较小目标挨得很近时,两个边界框有可能分别对应这两个目标,从而提高检测的召回率。
-
为什么图像分为7×7?
- 计算资源与效率考量:将图像划分为7×7的网格单元,是一种对计算资源和检测效率的权衡。划分的网格数量如果过多,虽然能更精细地定位目标,但会显著增加计算量和模型的复杂度;而划分得过少,又可能无法准确捕捉目标的位置和特征。7×7的网格划分在当时被认为是一个相对合理的选择,既能在一定程度上覆盖图像中的目标,又不会使计算量过大,能够在保证一定检测效果的同时,实现较快的检测速度。
- 目标尺度适应性:对于常见的目标尺度,7×7的网格划分可以较好地适应。每个网格单元负责预测其内部或中心位于该单元内的目标,这种划分方式对于一般大小的目标能够提供较为有效的检测和定位。
那么,假如一张图片,里面我要检测3个物体,输出的边界框预测一共是多少个?对于某一个物体,应该是多少个?
- 在YOLO v1中,无论图片里有几个物体,其边界框预测数量的计算方式都是固定的:
- 输出的边界框预测总数:由于YOLO v1将图像划分为7×7的网格,每个网格单元输出2个边界框,所以不管图片中要检测的物体是3个还是更多,输出的边界框预测总数都是7×7×2=98个。
- 对于某一个物体的边界框预测:每个物体可能会由一个或多个网格单元负责检测,每个相关网格单元都会输出2个边界框来尝试对该物体进行定位。比如一个物体可能横跨了4个网格单元,那么就会有4×2=8个边界框预测与这个物体相关,但最终会通过置信度和非极大值抑制等方法筛选出最能准确代表这个物体的边界框。
- YOLO v2和YOLO v3:引入了锚框概念,每个网格单元通常会预测多个边界框,比如YOLO v3每个网格单元一般预测3个边界框。如果同样是检测3个物体,以常见的特征图尺寸为例,如果特征图尺寸为13×13,那么边界框预测总数可能达到13×13×3个甚至更多(因为可能在多个不同尺度的特征图上进行预测)。对于某一个物体,相关的边界框预测数量也会因物体在图像中的位置和大小等因素,由多个网格单元及其对应的多个锚框来进行预测,数量会比YOLO v1更多。
- YOLO v5及后续版本:在不同尺度的特征图上进行多尺度检测,每个尺度的特征图上的网格单元都会根据设定的锚框数量进行边界框预测。对于检测3个物体,输出的边界框预测数量会根据具体的模型配置和输入图像大小等因素而变化,通常会比前面的版本更多。对于单个物体,会有多个来自不同尺度、不同位置的网格单元及其对应的边界框来进行预测,以提高对不同大小、不同位置物体的检测精度。
YOLO损失函数
YOLO损失函数由多个部分组成,包括边界框损失、类别损失和目标置信度分数损失。
损失函数公式 (损失函数略有改动并进行了简化)
J ( θ ) = ∑ j = 1 m e j T e j + λ 1 ∑ j = 1 m ∑ k = 1 K y j , k log y ^ j , k + λ 2 ∑ j = 1 m ( c ^ − c ) 2 J(\theta)=\sum_{j = 1}^{m} e_{j}^{T} e_{j}+\lambda_{1}\sum_{j = 1}^{m}\sum_{k = 1}^{K} y_{j,k} \log \hat{y}_{j,k}+\lambda_{2}\sum_{j = 1}^{m}(\hat{c} - c)^{2} J(θ)=j=1∑mejTej+λ1j=1∑mk=1∑Kyj,klogy^j,k+λ2j=1∑m(c^−c)2其中:
- 边界框平方误差损失(Bounding box squared error loss): ∑ j = 1 m e j T e j \sum_{j = 1}^{m} e_{j}^{T} e_{j} ∑j=1mejTej,用于衡量边界框预测值 ( x , y , w , h ) (x, y, w, h) (x,y,w,h)与真实值之间的误差。 e j e_j ej代表边界框相关的误差向量。
- 分类交叉熵损失(Classification categorical cross - entropy loss): λ 1 ∑ j = 1 m ∑ k = 1 K y j , k log y ^ j , k \lambda_{1}\sum_{j = 1}^{m}\sum_{k = 1}^{K} y_{j,k} \log \hat{y}_{j,k} λ1∑j=1m∑k=1Kyj,klogy^j,k,用于衡量类别预测的准确性。 y j , k y_{j,k} yj,k是真实标签, y ^ j , k \hat{y}_{j,k} y^j,k是预测标签, K K K是类别数量, λ 1 \lambda_{1} λ1是平衡参数。
- 目标检测置信度损失(Confidence in object detection): λ 2 ∑ j = 1 m ( c ^ − c ) 2 \lambda_{2}\sum_{j = 1}^{m}(\hat{c} - c)^{2} λ2∑j=1m(c^−c)2,用于衡量目标置信度分数的预测误差。 c ^ \hat{c} c^是预测的置信度分数, c c c是真实的置信度分数, λ 2 \lambda_{2} λ2是平衡参数。
交并比(IoU)指标
使用交并比(Intersection over union, IoU)作为置信度真实值的度量指标。公式为 c = I o U = A r e a o f O v e r l a p A r e a o f U n i o n c = IoU = \frac{Area of Overlap}{Area of Union} c=IoU=AreaofUnionAreaofOverlap即交并比等于重叠区域面积除以并集区域面积。当边界框预测完美时,IoU = 1。

如图,蓝色框为真实框,黄色框为预测框,红色阴影部分为重叠区域,红色轮廓内为并集区域。
非极大值抑制(Non - maximum suppression,NMS)
非极大值抑制用于YOLO网络之后,以抑制对同一物体的重复检测。
方法
选择置信度 c ^ \hat{c} c^最大的预测,然后抑制所有与该预测的交并比(IoU)大于阈值的其他预测。
流程

从左到右依次为:
- 输入图像。
- 经过YOLO卷积网络(YOLO Conv net)处理。
- 再经过非极大值抑制(Non - maximum suppression)处理。
- 得到最终预测结果(Final predictions)。
效果对比

- 非极大值抑制前(Before non - maximum suppression):图像中的汽车被多个边界框重复检测标注。
- 非极大值抑制后(After non - maximum suppression):只保留了置信度最高且能较好框定汽车的边界框,去除了重复的检测框,使检测结果更加简洁准确。
YOLO 系列模型的发展历程及主要改进点

- YOLO V1(2016 年):确立了一阶段检测器的关键思想。
- YOLO V2(2017 年):引入锚框(anchor boxes);采用全卷积网络。
- YOLO V3(2018 年):具备多尺度检测能力;主干网络基于 ResNet;使用二分类器进行多标签分类。
- YOLO V4(2019 年):采用跨阶段分层网络(CSPNet)、路径聚合网络(PANet)以及空间注意力模块(SAM)。
- YOLO V5(2020 年):基于 PyTorch 开发。
- YOLO V6 & V7(2021 - 2022 年):图片未详细列出具体改进,仅提及版本名称。
- YOLO V8(2023 年):采用无锚框检测(anchor free detection);引入自注意力机制(self attention);改进了训练过程。
代码示例
Matlab最多到V4.
% download, unzip, install, load pre-trained detector
pretrainedURL = "https://ssd.mathworks.com/supportfiles/vision/data/yolov4CSPDarknet53VehicleExample_22a.zip";
websave("yolov4CSPDarknet53VehicleExample_22a.zip", pretrainedURL);
unzip("yolov4CSPDarknet53VehicleExample_22a.zip");
pretrained = load("yolov4CSPDarknet53VehicleExample_22a.mat");
detector = pretrained.detector;
% test
I = imread("highway.png");
[bboxes,scores,labels] = detect(detector,I);
I = insertObjectAnnotation(I,"rectangle",bboxes,scores); figure; imshow(I)
% retrain
detector = trainYOLOv4ObjectDetector(trainingData,detector,trainingOptions);
Python都支持,下面示例是V8
import keras
import keras_cv
model = keras_cv.models.YOLOV8Detector(
num_classes=20,
bounding_box_format="xywh",
backbone=keras_cv.models.YOLOV8Backbone.from_preset(
"yolo_v8_m_backbone_coco"),
fpn_depth=2
)
# Evaluate model without box decoding and NMS
model(images)
# Prediction with box decoding and NMS
model.predict(images)
# Train model
model.compile(
classification_loss='binary_crossentropy',
box_loss='ciou',
optimizer=tf.optimizers.SGD(global_clipnorm=10.0),
jit_compile=False,
)
model.fit(images, labels)
实例分割
实例分割结合了语义分割和目标检测/识别。
示例
Mask R - CNN是一种流行的实例分割方法,它通过添加一个二分类掩码预测输出层对Faster R - CNN进行了扩展。
流程

流程与之前相似,只不过在第二部分多了一个:掩码二分类器(Mask Binary Classifier)在边界框内以像素级别输出目标/无目标的掩码。
总结
深度学习对计算机视觉产生了重大影响,关键领域包括:
- 图像识别(Image recognition):涉及的模型有VGG、GoogleNet、ResNet、Mobilenet 。这些模型用于对图像中的内容进行分类和识别。
- 语义分割(Semantic segmentation):相关模型包括U - Net、Segnet、DeepLabv3+ 。语义分割旨在将图像中的每个像素分配到预定义的类别中,例如区分图像中的道路、天空、建筑物等不同区域。
- 目标检测(Object detection):
- 两阶段检测器(Two - stage):如R - CNN、Fast R - CNN、Faster R - CNN 。这类检测器先生成可能包含目标的区域建议,再进行目标检测和分类。
- 一阶段检测器(One - stage):例如Yolo及其v2、v3、v4、v5、v6、v7、v8等版本。它们在单个阶段内完成目标检测和识别,通常检测速度较快。
- 实例分割(Instance segmentation):结合了语义分割与目标检测和识别,能够在像素级别上区分不同的目标实例,例如区分图像中的多个行人,并为每个行人生成对应的掩码。
引用
- (语义分割的 SegNet 架构)V. Badrinarayanan, A. Kendall and R. Cipolla (2017). SegNet: A Deep Convolutional EncoderDecoder Architecture for Image Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 12, pp. 2481-2495.
- (Faster R - CNN)Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” Neurips . Vol. 28, 2015.
- (Mask R-CNN)He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask R-CNN. In Proceedings of
the IEEE International Conference on Computer Vision (pp. 2961-2969).
相关文章:
深度学习-6.用于计算机视觉的深度学习
Deep Learning - Lecture 6 Deep Learning for Computer Vision 简介深度学习在计算机视觉领域的发展时间线 语义分割语义分割系统的类型上采样层语义分割的 SegNet 架构软件中的SegNet 架构数据标注 目标检测与识别目标检测与识别问题两阶段和一阶段目标检测与识别两阶段检测器…...
免费送源码:ava+springboot+MySQL 基于springboot 宠物医院管理系统的设计与实现 计算机毕业设计原创定制
摘 要 在当今社会,宠物已经成为人们生活中不可或缺的一部分,因此宠物健康和医疗问题也备受关注。为了更好地管理宠物医院的日常运营和提供优质的医疗服务,本研究设计并实现了一套基于Spring Boot框架的宠物医院管理系统。这一系统集成了多项功…...

【电机控制器】ESP32-C3语言模型——DeepSeek
【电机控制器】ESP32-C3语言模型——DeepSeek 文章目录 [TOC](文章目录) 前言一、简介二、代码三、实验结果四、参考资料总结 前言 使用工具: 提示:以下是本篇文章正文内容,下面案例可供参考 一、简介 二、代码 #include <Arduino.h&g…...

小型字符级语言模型的改进方向和策略
小型字符级语言模型的改进方向和策略 一、回顾小型字符级语言模型的处理流程 前文我们已经从零开始构建了一个小型字符级语言模型,那么如何改进和完善我们的模型呢?有哪些改进的方向?我们先回顾一下模型的流程: 图1 小型字符级语言模型的处理流程 (1)核心模块交互过程:…...

力扣-贪心-56 合并区间
思路 先按照左区间进行排序,然后初始化left和right,重叠时,更新right,不重叠时,收集区间 代码 class Solution { public:static bool cmp(vector<int> a, vector<int> b){if(a[0] b[0]){return a[1] &…...

vue 3D 翻页效果
<template><view class"swipe-container" touchstart"onTouchStart" touchmove"onTouchMove" touchend"onTouchEnd"><view class"page">初始页</view></view> </template><script&g…...

【系列专栏】银行信息系统研发外包风险管控-08
银行信息系统研发外包风险管控 在金融科技日新月异的当下,银行业务对信息系统的依赖程度与日俱增。为了充分利用外部专业资源,提升研发效率并合理控制成本,许多银行选择将信息系统研发外包。然而,这一策略在带来诸多便利的同时&a…...

[ComfyUI] 【AI】如何获得一张人物图片的优质描述
在使用ComfyUI时,获取一张人物图片的优质英文描述非常重要,尤其是在涉及图像生成、自动化标签和多模态AI任务时。以下是一个简单的流程,可以帮助你快速从一张人物图片中提取出精确且高质量的英文描述。 1. 打开 Hugging Face 网站 首先,您需要访问 Hugging Face 提供的 J…...

深度学习基础--ResNet网络的讲解,ResNet50的复现(pytorch)以及用复现的ResNet50做鸟类图像分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 如果说最经典的神经网络,ResNet肯定是一个,这篇文章是本人学习ResNet的学习笔记,并且用pytorch复现了ResNet50&…...

stack,queue,priority_queue学习知识点
容器适配器 在c常用的容器中,有的是以容器迭代器为核心,而有的则以容器适配器为核心。较为常用的就包括queue和stack。接下来我将简单的以queue和stack的模拟实现介绍其特点。 在以下的模拟实现中,class Con就是我们的容器适配器࿰…...

css特异性,继承性
html <div class"introduce"><div class"title">介绍</div><div class"card-box"><div class"card"><div class"title">管理</div></div></div> </div> scs…...

力扣hot100刷题——11~20
文章目录 11.滑动窗口最大值题目描述思路:滑动窗口单调队列code 12.最小覆盖子串题目描述思路:双指针/滑动窗口哈希code Ⅰcode Ⅱ 13.最大子数组和题目描述思路:dp/贪心code 14.合并区间题目描述思路:贪心code 15.轮转数组题目描…...

R语言Stan贝叶斯空间条件自回归CAR模型分析死亡率多维度数据可视化
全文链接:https://tecdat.cn/?p40424 在空间数据分析领域,准确的模型和有效的工具对于研究人员至关重要。本文为区域数据的贝叶斯模型分析提供了一套完整的工作流程,基于Stan这一先进的贝叶斯建模平台构建,帮助客户为空间分析带来…...
速通HTML
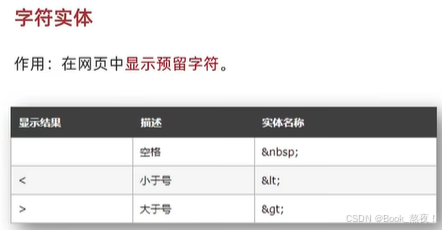
目录 HTML基础 1.快捷键 2.标签 HTML进阶 1.列表 a.无序列表 b.有序列表 c.定义列表 2.表格 a.内容 b.合并单元格 3.表单 a.input标签 b.单选框 c.上传文件 4.下拉菜单 5.文本域标签 6.label标签 7.按钮标签 8.无语义的布局标签div与span 9.字符实体 HTML…...

安装 Milvus Java SDK
本主题介绍如何为 Milvus 安装 Milvus Java SDK。 当前版本的 Milvus 支持 Python、Node.js、GO 和 Java SDK。 要求 Java(8 或更高版本)Apache Maven 或 Gradle/Grails 安装 Milvus Java SDK 运行以下命令安装 Milvus Java SDK。 Apache Maven &…...

云手机如何进行经纬度修改
云手机如何进行经纬度修改 云手机修改经纬度的方法因不同服务商和操作方式有所差异,以下是综合多个来源的常用方法及注意事项: 通过ADB命令注入GPS数据(适用于技术用户) 1.连接云手机 使用ADB工具连接云手机服务器,…...
)
牛客周赛 Round 82(思维、差分、树状数组、大根堆、前后缀、递归)
文章目录 牛客周赛 Round 82(思维、差分、树状数组、大根堆、前后缀、递归)A. 夹心饼干B. C. 食堂大作战(思维)D. 小苯的排列计数(差分、树状数组)E. 和和(大根堆,前缀和)F. 怎么写线性SPJ &…...

MQTT实现智能家居------2、写MQTT程序的思路
举个最简单的例子: 手机------服务器-------家具 我们这里只看手机和家具的客户端: 手机:1)需要连接服务器 2)需要发布指令给服务器到家里的家具 3)接受来自于家里家具的异常状况 4)保持心…...

大模型面试问题准备
1. BERT的多头注意力为什么需要多头? 为了捕捉不同子空间的语义信息,每个头关注不同的方面,增强模型的表达能力 2. 什么是softmax上下溢出问题? 问题描述: 上溢出:ye^x中,如果x取非常大的正数…...

C语言:二维数组在内存中是怎么存储的
目录 1. 二维数组的定义: 2. 行主序存储: 具体内存排列: 3. 如何通过指针访问数据: 4. 总结: 在 C 语言中,二维数组是按 行主序(row-major order) 存储的。也就是说,…...
,并处理常见的网络与缓存问题)
实战:从URL直接加载PyTorch预训练权重(以torch.hub为例),并处理常见的网络与缓存问题
实战:从URL直接加载PyTorch预训练权重(以torch.hub为例),并处理常见的网络与缓存问题 在深度学习项目的实际开发中,我们经常需要加载预训练模型权重。传统做法是先将权重文件下载到本地,再通过torch.load(…...

速腾M1激光雷达实战:从环境搭建到点云可视化全流程解析
1. 环境准备:搭建ROS与速腾M1的"对话桥梁" 第一次接触速腾M1激光雷达时,我就像拿到了一部没有说明书的外星设备。经过多次实战,我发现环境配置是决定后续成败的关键。这里以Ubuntu 18.04 ROS Melodic为例(其他版本操作…...

如何快速搭建KCN-GenshinServer:原神一键GUI服务端完整指南
如何快速搭建KCN-GenshinServer:原神一键GUI服务端完整指南 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer KCN-GenshinServer是一款基于GC框架开发的原神一键G…...

Visual C++ Redistributable AIO:Windows系统DLL缺失问题的终极解决方案
Visual C Redistributable AIO:Windows系统DLL缺失问题的终极解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 当您在Windows系统上安装或运行…...

软件利益相关者管理中的期望管理者
软件利益相关者管理中的期望管理者 在软件开发过程中,利益相关者的期望管理是项目成功的关键因素之一。不同的利益相关者,如客户、开发团队、管理层和最终用户,往往对项目有不同的需求和预期。如果这些期望未能得到有效管理,可能…...

DirectX修复工具深度评测:为什么它能解决90%的游戏运行问题?
DirectX修复工具深度评测:为什么它能解决90%的游戏运行问题? 每次启动游戏时遇到"d3dx9_43.dll丢失"或"Direct3D初始化失败"这类弹窗,玩家的心情往往从期待瞬间跌入谷底。这类问题看似复杂,实则多数情况下只需…...

Qwen3-TTS-12Hz效果展示:中英混合技术文档语音生成,术语发音精准实测
Qwen3-TTS-12Hz效果展示:中英混合技术文档语音生成,术语发音精准实测 重要提示:本文仅展示Qwen3-TTS-12Hz模型的技术效果和语音生成能力,所有测试基于公开可用的模型版本进行。内容完全聚焦技术展示,不涉及任何其他信息…...

如何快速突破百度网盘限速:完整直链解析指南
如何快速突破百度网盘限速:完整直链解析指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘下载速度慢而烦恼吗?今天我要向你介绍一个神…...

ofa_image-caption开源大模型:基于ModelScope生态的可复现图像理解方案
ofa_image-caption开源大模型:基于ModelScope生态的可复现图像理解方案 1. 项目概述 今天给大家介绍一个特别实用的AI工具——基于OFA模型的图像描述生成工具。简单来说,你给它一张图片,它就能用英文告诉你图片里有什么,就像给图…...

Flask为什么仍然值得学
Flask 为什么仍然值得学? 每隔一段时间,总会有人问一句: “FastAPI 都这么火了,现在学 Flask 还有必要吗?” 这个问题之所以反复出现,并不奇怪。因为很多人一接触 Python Web,就会先看到这些信…...