大模型面试问题准备
1. BERT的多头注意力为什么需要多头?
为了捕捉不同子空间的语义信息,每个头关注不同的方面,增强模型的表达能力
2. 什么是softmax上下溢出问题?

问题描述:
上溢出:y=e^x中,如果x取非常大的正数,y(float32格式数据)就会溢出;
下溢出:如果x取非常小的负数,y就是0.00000000几,超过有效位数后,y就是0了,如果分母都是0,就会出错。
解决方法:
x同时减去x_max,即可解决。
上溢出:最大值变为了0,因此y不会溢出;
下溢出:分母必然存在1,因此不会为0。
3. 为什么NLP用LayerNorm而不是BatchNorm?
标准化的目的:1. 不同特征间的尺度需要归一化 2. 深度学习中矩阵乘容易导致向量元素不断变大,为了网络的稳定性需要归一化
BatchNorm是对一个batch-size样本内的每个特征的所有样本做归一化,LayerNorm是对每个样本的所有特征做归一化。
BN抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系;LN抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系。batch size较小或者序列问题中可以使用LN。
总结原因:
首先,一个存在的问题是不同样本的序列长度不一致,而Batch Normalization需要对不同样本的同一位置特征进行标准化处理,所以无法应用;当然,输入的序列都要做padding补齐操作,但是补齐的位置填充的都是0,这些位置都是无意义的,此时的标准化也就没有意义了。
其次上面说到,BN抹杀了不同特征之间的大小关系;LN是保留了一个样本内不同特征之间的大小关系,这对NLP任务是至关重要的。对于NLP或者序列任务来说,一条样本的不同特征,其实就是时序上的变化,这正是需要学习的东西自然不能做归一化抹杀,所以要用LN。
4. RLHF训练过程是怎么样的?
RLHF 是一种结合强化学习(RL)和人类反馈(HF)的 AI 训练方法,能够有效提升 AI 生成文本的质量。其核心步骤包括:
监督微调(SFT):训练初始模型。
奖励模型训练(RM):基于人类反馈优化奖励函数。
强化学习(RL):使用 PPO 等方法优化策略,提高模型表现。
5. 大模型训练有几步?
大模型训练主要有4步:
Pretraining — 预训练阶段(自监督学习,数据库量大质量低)
Supervised Finetuning(SFT) — 监督微调,也叫指令微调阶段(人工问答数据用于训练,质量高数量少)
Reward Modeling — 奖励模型训练阶段(训练奖励模型,评价大模型的输出质量)
Reinforcement Learning(RL)— 增强学习微调阶段(利用RM对大模型进行参数更新)
6. 在PyTorch中model.train()和model.eval()的作用?
model.train():启用训练模式,开启Dropout和BatchNorm的统计量更新。
model.eval():切换为评估模式,关闭Dropout,固定BatchNorm的均值和方差(使用训练阶段的统计量)。
7. 如何解决大模型推理延迟问题?
模型优化:量化(FP16/INT8)、剪枝、知识蒸馏。
系统优化:动态批处理、KV Cache复用、内存高效注意力(如FlashAttention)。
硬件加速:TensorRT编译、GPU并行(如vLLM)。
8. Transformer中前馈层(FFN)的作用?
非线性部分:增强模型表达能力
线性部分:通过升维降维使模型捕捉复杂的特征和模式
总结:FFN通过非线性变换(如ReLU/SwiGLU)增强模型表达能力,对注意力层的输出进行特征映射和维度调整,捕捉更复杂的模式。
9. 深度网络中loss除以10和学习率除以10等价吗?
取决于优化器类型。对于带有自适应学习率的优化器(如Adam、RMSprop), loss缩放与学习率调整并不等价。对于经典的SGD和Momentum SGD,将 loss乘以常数等价于将学习率乘以相同的常数。
10. Self-Attention的时间/空间复杂度?
时间复杂度:O(n^2*d)
a. Q和K点积,nxd和dxn的计算复杂度是O(n2d)
b. 每行softmax的计算,计算复杂度为O(n),n行为O(n2)
c. 值矩阵和softmax结果点积,nxd和nxn,计算复杂度为O(n2d)
11. 大模型幻觉如何缓解?
大语言模型中的幻觉源于数据压缩(data compression)和不一致性(inconsistency)。由于许多数据集可能已经过时或不可靠,因此质量保证具有挑战性。模型回答偏向于它们见过最多的内容。为了减轻幻觉,可以采取以下方法:
12. 主流大模型为何是Decoder-only?
-
自回归生成:Decoder天然适合逐Token生成,Encoder-Decoder结构在训练时需对齐,效率低。
-
训练效率:Decoder-only架构参数量更少,预训练成本低(如GPT、LLaMA)。
13. Attention为何除以√d?
点积结果随维度d增大而幅值增加,导致Softmax梯度消失。除以√d缩放点积值,稳定训练。
14. BERT的Embedding相加合理性?
Embedding相加等价于拼接后投影,模型能自动学习各Embedding的交互。实验表明相加不影响效果且更高效。
15. 交叉熵与KL散度的含义?
KL散度=交叉熵-熵



参考链接:
1. https://blog.csdn.net/HaoZiHuang/article/details/122616235
2.自然语言处理: 第二十四章 为什么在NLP领域中普遍用LayerNorm 而不是BatchNorm?_layernorm 在nlp cv区别-CSDN博客
3. 深入解析 RLHF(Reinforcement Learning from Human Feedback)-CSDN博客
4. 通用大模型训练过程必须经历的四个阶段!_大模型训练阶段-CSDN博客
相关文章:
大模型面试问题准备
1. BERT的多头注意力为什么需要多头? 为了捕捉不同子空间的语义信息,每个头关注不同的方面,增强模型的表达能力 2. 什么是softmax上下溢出问题? 问题描述: 上溢出:ye^x中,如果x取非常大的正数…...

C语言:二维数组在内存中是怎么存储的
目录 1. 二维数组的定义: 2. 行主序存储: 具体内存排列: 3. 如何通过指针访问数据: 4. 总结: 在 C 语言中,二维数组是按 行主序(row-major order) 存储的。也就是说,…...

AI时代前端开发技能变革与ScriptEcho:拥抱AI,提升效率
在飞速发展的科技浪潮中,人工智能(AI)正以前所未有的速度改变着各个行业,前端开发领域也不例外。曾经被认为是核心竞争力的传统前端技能,例如精通HTML、CSS和JavaScript,其价值正在发生微妙的变化。 得益于…...

计算机毕业设计SpringBoot+Vue.js美容院管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【LeetCodehHot100_0x01】
LeetCodeHot100_0x01 1. 两数之和 解题思路: 暴力枚举法、哈希法 【暴力枚举】 class Solution {public int[] twoSum(int[] nums, int target) {int n nums.length;for(int i0;i<n;i) {for(int ji1;j<n;j) {if(nums[i] nums[j] target) {return new in…...

Qt::MouseButtons解析
一 问题 今天想自定定义一个QMouseEvent变量,变量的的初始化参数有Qt::MouseButtons,这是个啥?查看类型为QFlags<Qt::MouseButton>。 二 Qt::MouseButton Qt::MouseButton 是 Qt 框架中定义的一个枚举类型(enum),用于表示鼠标事件中的物理按钮。它是 Qt 事件处理…...

跨域问题解释及前后端解决方案(SpringBoot)
一、问题引出 有时,控制台出现如下问题。 二、为什么会有跨域 2.1浏览器同源策略 浏览器的同源策略 ( Same-origin policy )是一种重要的安全机制,用于限制一个源( origin )的文档或 脚本如何与另一个源的资源进行…...

4-知识图谱的抽取与构建-4_2实体识别与分类
🌟 知识图谱的实体识别与分类🔥 🔍 什么是实体识别与分类? 实体识别(Entity Recognition)是从文本中提取出具体的事物,如人名、地名、组织名等。分类(Entity Classification&#x…...

腾讯云大模型知识引擎×DeepSeek赋能文旅
腾讯云大模型知识引擎DeepSeek赋能文旅 ——以合肥文旅为例的技术革新与实践路径 一、技术底座:知识引擎与DeepSeek的融合逻辑 腾讯云大模型知识引擎与DeepSeek模型的结合,本质上是**“知识库检索增强生成(RAG)实时联网能力”**…...

TMDS视频编解码算法
因为使用的是DDR进行传输,即双倍频率采样,故时钟只用是并行数据数据的5倍,而不是10倍。 TMDS算法流程: 视频编码TMDS算法流程实现: timescale 1 ps / 1ps //DVI编码通常用于视频传输,将并行数据转换为适合…...

C++程序员内功修炼——Linux C/C++编程技术汇总
在软件开发的宏大版图中,C 语言宛如一座巍峨的高山,吸引着无数开发者攀登探索。而 Linux 操作系统,以其开源、稳定、高效的特性,成为了众多开发者钟爱的开发平台。将 C 与 Linux 相结合,就如同为开发者配备了一把无坚不…...

【数据结构】链表中快指针和慢指针
目录 一、找出并返回链表的中间结点 二、输出链表中倒数第k个结点 三、判断链表中是否有环 四、两个单链表相交 一、找出并返回链表的中间结点 给你单链表的头结点 head ,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。 要求:只遍历…...

6_zookeeper集群配置
配置 一、配置myid文件 # 进入解压好的文件夹下面 touch myid vim myid # master节点写0,slave1节点写1,slave2节点写2二、配置zoo.cfg文件 1.在master节点编辑zookeeper配置文件 # 进入解压好的文件夹下面 cd conf/ cp zoo_sample.cfg zoo.cfg vim …...

Docker核心概念
容器介绍 Docker 是世界领先的软件容器平台,所以想要搞懂 Docker 的概念我们必须先从容器开始说起。 什么是容器? 先来看看容器较为官方的解释 一句话概括容器:容器就是将软件打包成标准化单元,以用于开发、交付和部署。 容器镜像是轻量…...

LD_PRELOAD 绕过 disable_function 学习
借助这位师傅的文章来学习通过LD_PRELOAD来绕过disable_function的原理 【PHP绕过】LD_PRELOAD bypass disable_functions_phpid绕过-CSDN博客 感谢这位师傅的贡献 介绍 静态链接: (1)举个情景来帮助理解: 假设你要搬家&#x…...
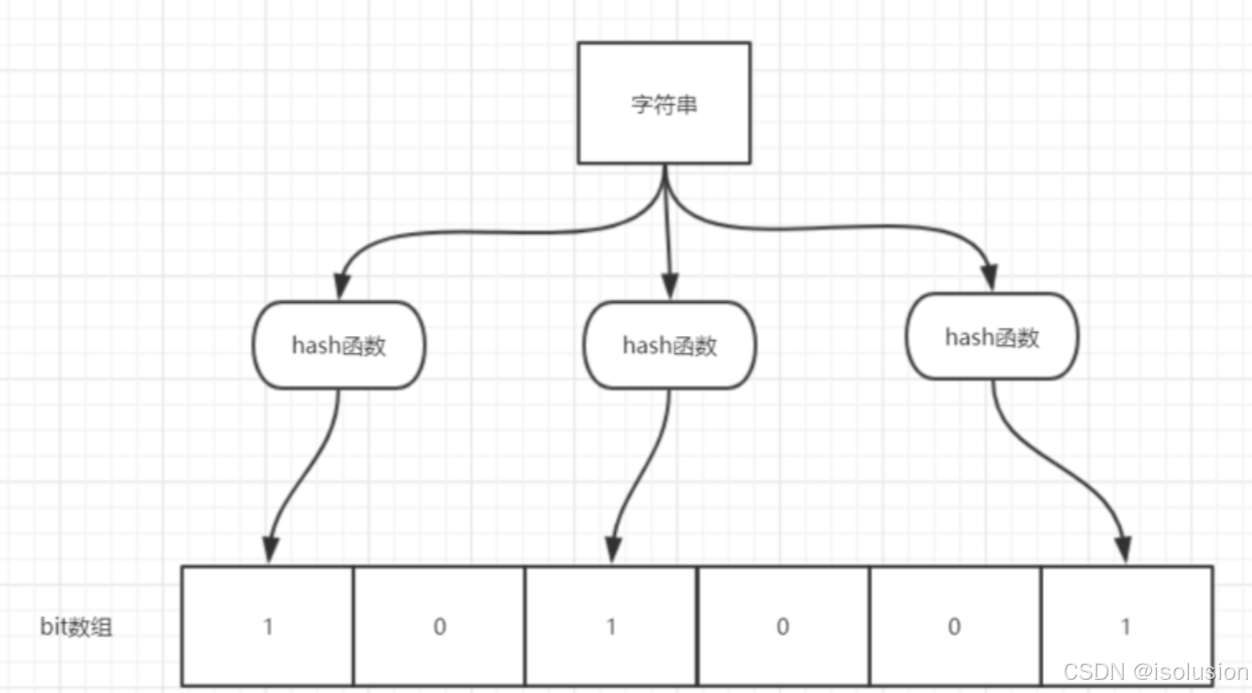
如何用JAVA实现布隆过滤器?
目录 引言 布隆过滤器的原理 1. 核心思想 2. 优缺点 布隆过滤器的使用场景 Java 实现布隆过滤器 1. 实现步骤 2. 代码实现 3. 代码说明 4. 测试结果 布隆过滤器的优化 总结 引言 布隆过滤器(Bloom Filter)是一种高效的概率数据结构࿰…...

游戏开发 游戏开始界面
目录 前言 一 游戏初始化界面的分析 二 游戏的大概框架 三 显示界面的开发 四 完整代码 总结 我们可以来看看游戏初始界面是什么样的 勇士游戏样例 前言 这里是开发游戏的初始界面 一 游戏初始化界面的分析 我们需要一个背景图,开始游戏图标࿰…...

Python解析 Flink Job 依赖的checkpoint 路径
引言 Apache Flink 是一个强大的分布式处理框架,广泛用于批处理和流处理任务。其 checkpoint 机制是确保容错的关键功能,允许在计算过程中保存状态,以便在故障时从最近的 checkpoint 恢复。本文详细探讨了一个 Python 脚本,该脚本…...

Javascript网页设计案例:通过PDFLib实现一款PDF分割工具,分割方式自定义-完整源代码,开箱即用
功能预览 一、工具简介 PDF 分割工具支持以下核心功能: 拖放或上传 PDF 文件:用户可以通过拖放或点击上传 PDF 文件。两种分割模式: 指定范围:用户可以指定起始页和结束页,提取特定范围的内容。固定间距:用户可以设置间隔页数(例如每 5 页分割一次),工具会自动完成分…...

计算机视觉算法实战——产品分拣(主页有源码)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 领域简介✨✨ 产品分拣是工业自动化和物流领域的核心技术,旨在通过机器视觉系统对传送带上的物品进行快速识别、定位和分类&a…...

从零构建OAK深度视觉应用:OpenCV CEO带你玩转DepthAI核心管道
1. 深度视觉与OAK硬件入门 第一次接触OAK设备时,最让我惊讶的是它把复杂的深度视觉计算封装成了一个即插即用的小盒子。作为OpenCV官方推出的智能相机,OAK-D系列完美结合了传统计算机视觉和现代AI推理能力。记得去年做智能仓储项目时,我们团队…...

uni-app分包实战:巧解echarts.js体积难题,提升小程序启动速度
1. 为什么需要分包优化echarts.js? 第一次用uni-app开发带数据可视化的小程序时,我就被echarts.js的体积吓到了——压缩后的文件仍有700KB,直接导致主包体积超标。微信小程序主包限制2MB,加上其他业务代码,根本装不下这…...

Rust Trait 对象的内存布局
Rust Trait对象的内存布局探秘 Rust作为一门注重安全与性能的系统级语言,其Trait对象是实现运行时多态的核心机制。理解Trait对象的内存布局,不仅能帮助开发者写出更高效的代码,还能避免因类型擦除带来的潜在问题。本文将深入剖析Trait对象在…...

bert-base-chinese效果展示:中文语义理解能力的实际案例分享
bert-base-chinese效果展示:中文语义理解能力的实际案例分享 1. 模型核心能力概览 bert-base-chinese作为中文NLP领域的基石模型,展现了令人惊艳的语义理解能力。这个由Google发布的预训练模型,专门针对中文语言特性进行了优化,…...

Upscayl终极指南:免费开源AI图像超分辨率工具完整解析
Upscayl终极指南:免费开源AI图像超分辨率工具完整解析 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl 你是否曾经…...
)
C++新手必看:用6种不同方法搞定‘三个数找最大’(附OpenJudge真题解析)
C新手必看:用6种不同方法搞定‘三个数找最大’(附OpenJudge真题解析) 在编程学习的起步阶段,解决"找出三个数中的最大值"这类基础问题往往能揭示出许多编程思维的精髓。这道看似简单的题目,实际上像一面多棱…...

如何在PDF中运行Linux?LinuxPDF虚拟输入输出系统的实现原理详解
如何在PDF中运行Linux?LinuxPDF虚拟输入输出系统的实现原理详解 【免费下载链接】linuxpdf Linux running inside a PDF file via a RISC-V emulator 项目地址: https://gitcode.com/gh_mirrors/li/linuxpdf LinuxPDF是一个令人惊叹的开源项目,它…...

一阶谓词逻辑:从理论基石到智能系统构建
1. 一阶谓词逻辑:智能系统的思维骨架 第一次接触一阶谓词逻辑时,我正为一个医疗诊断系统设计推理模块。当看到"∀x(Patient(x)∧HasSymptom(x,fever)→NeedsTest(x,blood))"这样的表达式时,突然意识到这就是把医生的诊断经验转化为…...

如何高效实现OpenVAS Scanner扫描插件结果数据备份与恢复:完整测试指南
如何高效实现OpenVAS Scanner扫描插件结果数据备份与恢复:完整测试指南 【免费下载链接】openvas-scanner This repository contains the scanner component for Greenbone Community Edition. 项目地址: https://gitcode.com/GitHub_Trending/op/openvas-scanner…...

笔试训练48天:删除公共字符
REAL507 删除公共字符 https://www.nowcoder.com/practice/f0db4c36573d459cae44ac90b90c6212?tpId182&tqId34789&ru/exam/oj 简单 通过率:32.96% 时间限制:1秒 空间限制:32M 知识点Java工程师字符串2017模拟C工程师 描述 输…...