深度学习基础--ResNet网络的讲解,ResNet50的复现(pytorch)以及用复现的ResNet50做鸟类图像分类
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
- 如果说最经典的神经网络,
ResNet肯定是一个,这篇文章是本人学习ResNet的学习笔记,并且用pytorch复现了ResNet50,后面用它做了一个鸟类图像分类demo; - 欢迎收藏 + 关注,本人将会持续更新
文章目录
- ResNet网络讲解
- 什么是ResNet?
- ResNet神经网络突出点
- 为什么采用残差连接
- 模型退化、梯度消失、梯度爆炸
- 解决方法
- 残差网络
- ResNet-50复现
- 1、导入数据
- 1、导入库
- 2、查看数据信息和导入数据
- 3、展示数据
- 4、数据导入
- 5、数据划分
- 6、动态加载数据
- 2、构建ResNet-50网络
- 3、模型训练
- 1、构建训练集
- 2、构建测试集
- 3、设置超参数
- 4、模型训练
- 5、结果可视化
- 参考资料
ResNet网络讲解
什么是ResNet?
ResNet网络是CNN的经典网络架构,是有大神何凯明提出的,主要为了解决随着网络的加深而引起的“ 退化 ”问题,主要用于图像分类。
可以说在如今的CV领域里面,大部分网络结构都有参考ResNet网络思想,无论是在图像分类、目标检测、图像识别上,甚至在Transformer网络模型中,也融合了ResNet网络的思想。
ResNet神经网络突出点
- 网络结构超过1000层:
- ❔ ❔ 超过1000层网络结构不是很容易么? 小编在学习深度学习的时候,曾经遇到过这样一个问题,有时候加深网络结构,反而在准确率、损失率上更差,这种现象称为模型“ 退化 ”现象,而ResNet的残差连接可以保证下一层的输出不会比输入差,从而可以加深网络结构。
- 提出残差模块(residual):这个是ResNet的核心;
- 采用大量的归一化在卷积层与激活函数之间.
为什么采用残差连接
模型退化、梯度消失、梯度爆炸
- 👉 模型退化:指随着网络层数的加深,其效果出现下降趋势,不如层数少的情况。如论文中图示,56层效果不如20层效果;

- 👉 梯度消失:这个是指随着网络层数的增加,反向传播,梯度更新的时候可能会造成前面几层的梯度很小、接近于0,这就会导致权重的更新会特别慢,效率低下。
- 👉 梯度爆炸:指随着网络层数的增加,在反向传播的时候,梯度变得非常大,从而在更新权重的时候,权重值发生大幅度变化,这可能导致网络不稳定,甚至是无法收敛。
解决方法
- 梯度消失、梯度爆炸:在数据预处理和网络层之间加入:BN层(Batch Normalization),从而对数据进行归一化;
- 模型退化:采用残差连接,如论文图,随着网络层数的增加,损失率更低了。

残差网络
在讲述前,这里先讲述一下恒等映射的概念:
- 恒等映射核心是复制,就是复制网络层,什么也不干。
➿ 可以这么理解:假设在一种网络A的后面添加几层形成新的网络B,如果A的输出经过新的层级变成B的输出没有发送变化,那么就可以说网络A和网络B的错误率是相等的,这样就确保了加深的网络层不会比之前的网络层效果差。
resent网络说明了,更深的网络结构可以有更好的效果,而解决这个的核心就是残差连接,网络结果如图所示:

上图就是何凯明提出的残差结构,这种结构实现了恒等映射,网络层的输出由两大模块组成:
- 其一:正常的卷积层;
- 其二:有一个分支输出到连接上,这个输出值就是输入的值;
最终结果就是:卷积层输出+分支输出,数学公式如下:

其中F(x)是卷积层的输出,x是分支的输入值。
极端情况:F(x)的网络层中,所有参数都为0,那么H(x)就是恒等映射。这样就确保了最后的错误率不会因为网络层的增加而导致变大。
在ResNet中有两个不同的ResNet模块,如图所示:

左边:
- 有两层残差单元,输出通道都是3*3
- 使用情况:用于较浅的ResNet网络。
右边:
- 三层残差单元,称为blottlenck模块,作用是:现用
1*1卷积进行降维,后用3*3卷积进行特征特权,最后用1*1卷积恢复原来的维度,这个可以很好的减少参数个数,用于较深的神经网络。
下图参考一个csdn大神笔记图:

CNN参数计算公式:卷积核尺寸 * 卷积核速度 * 卷积核组数 == 卷积核尺寸 * 输入特征矩阵深度 * 输出矩阵深度。
ResNet经典的网络结构有ResNet-50,ResNet-101等,本文将用pytorch复现ResNet-50,并用其做一个简单的实验–鸟类图片分类。
ResNet-50网络结果如下:

ResNet-50复现
1、导入数据
1、导入库
import torch
import torch.nn as nn
import torchvision
import numpy as np
import os, PIL, pathlib # 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"device
'cuda'
2、查看数据信息和导入数据
数据目录有两个文件:一个数据文件,一个权重。
data_dir = "./data/bird_photos"data_dir = pathlib.Path(data_dir)# 类别数量
classnames = [str(path).split('/')[0] for path in os.listdir(data_dir)]classnames
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
3、展示数据
import matplotlib.pylab as plt
from PIL import Image # 获取文件名称
data_path_name = "./data/bird_photos/Bananaquit/"
data_path_list = [f for f in os.listdir(data_path_name) if f.endswith(('jpg', 'png'))]# 创建画板
fig, axes = plt.subplots(2, 8, figsize=(16, 6))for ax, img_file in zip(axes.flat, data_path_list):path_name = os.path.join(data_path_name, img_file)img = Image.open(path_name) # 打开# 显示ax.imshow(img)ax.axis('off')plt.show()

4、数据导入
from torchvision import transforms, datasets # 数据统一格式
img_height = 224
img_width = 224 data_tranforms = transforms.Compose([transforms.Resize([img_height, img_width]),transforms.ToTensor(),transforms.Normalize( # 归一化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] )
])# 加载所有数据
total_data = datasets.ImageFolder(root="./data/bird_photos", transform=data_tranforms)
5、数据划分
# 大小 8 : 2
train_size = int(len(total_data) * 0.8)
test_size = len(total_data) - train_size train_data, test_data = torch.utils.data.random_split(total_data, [train_size, test_size])
6、动态加载数据
batch_size = 32 train_dl = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True
)test_dl = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=False
)
# 查看数据维度
for data, labels in train_dl:print("data shape[N, C, H, W]: ", data.shape)print("labels: ", labels)break
data shape[N, C, H, W]: torch.Size([32, 3, 224, 224])
labels: tensor([0, 1, 0, 1, 2, 1, 1, 0, 2, 2, 1, 2, 1, 3, 1, 2, 2, 2, 2, 1, 2, 1, 2, 2,0, 3, 3, 3, 3, 2, 3, 3])
2、构建ResNet-50网络

import torch.nn.functional as F# 定义残差模块一,这个用于处理输入和输出通道一样的情况
'''
卷积核大小:1 3 1
核心特点:尺寸不变:输入和输出的尺寸保持一致。 没有下采样:没有使用步长大于1的卷积操作,因此没有改变特征图的空间尺寸
'''
class Identity_block(nn.Module):def __init__(self, in_channels, kernel_size, filters):super(Identity_block, self).__init__()# 输出通道filter1, filter2, filter3 = filters# 卷积层一self.conv1 = nn.Conv2d(in_channels, filter1, kernel_size=1, stride=1)self.bn1 = nn.BatchNorm2d(filter1)# 卷积层2self.conv2 = nn.Conv2d(filter1, filter2, kernel_size=kernel_size, padding=1) # 通过卷积输入输出公式发现,padding=1,可以保证输入和输出尺寸相同self.bn2 = nn.BatchNorm2d(filter2)# 卷积层3self.conv3 = nn.Conv2d(filter2, filter3, kernel_size=1, stride=1)self.bn3 = nn.BatchNorm2d(filter3)def forward(self, x):# 记录原始值xx = xx = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.bn3(self.conv3(x))# 残差连接,输入、输出维度不变x += xxx = F.relu(x)return x # 定义卷积模块二:用于处理输入和输出不一样的情况
'''
* 卷积核还是:1 3 1
* stride=2
* 这里的分支是采用一个Conv2D,和一个归一化BN层,也是为了处理数据维度吧, 这种维度的变化,可以用ai举例子核心特点:尺寸变化,stride=2降维
'''
class ConvBlock(nn.Module):def __init__(self, in_channels, kernel_size, filters, stride=2):super(ConvBlock, self).__init__()filter1, filter2, filter3= filters# 卷积层1self.conv1 = nn.Conv2d(in_channels, filter1, kernel_size=1, stride=stride)self.bn1 = nn.BatchNorm2d(filter1)# 卷积2self.conv2 = nn.Conv2d(filter1, filter2, kernel_size=kernel_size, padding=1) # 需要维持维度不变self.bn2 = nn.BatchNorm2d(filter2)# 卷积3self.conv3 = nn.Conv2d(filter2, filter3, kernel_size=1, stride=1) # stride = 1,维持通道不变self.bn3 = nn.BatchNorm2d(filter3)# 用于匹配维度的shortcut卷积,这个就是上面Identity_block的x分支self.shortcut = nn.Conv2d(in_channels, filter3, kernel_size=1, stride=stride)self.shortcut_bn = nn.BatchNorm2d(filter3)def forward(self, x):xx = xx = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.bn3(self.conv3(x))temp = self.shortcut_bn(self.shortcut(xx))x += tempx = F.relu(x)return x # 定义ResNet50
class ResNet50(nn.Module):def __init__(self, classes): # 类别数量super().__init__()# 头顶self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)self.bn1 = nn.BatchNorm2d(64)self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 第一部分self.part1_1 = ConvBlock(64, 3, [64, 64, 256], stride=1)self.part1_2 = Identity_block(256, 3, [64, 64, 256])self.part1_3 = Identity_block(256, 3, [64, 64, 256])# 第二部分self.part2_1 = ConvBlock(256, 3, [128, 128, 512])self.part2_2 = Identity_block(512, 3, [128, 128, 512])self.part2_3 = Identity_block(512, 3, [128, 128, 512])self.part2_4 = Identity_block(512, 3, [128, 128, 512])# 第三部分self.part3_1 = ConvBlock(512, 3, [256, 256, 1024])self.part3_2 = Identity_block(1024, 3, [256, 256, 1024])self.part3_3 = Identity_block(1024, 3, [256, 256, 1024])self.part3_4 = Identity_block(1024, 3, [256, 256, 1024])self.part3_5 = Identity_block(1024, 3, [256, 256, 1024])self.part3_6 = Identity_block(1024, 3, [256, 256, 1024])# 第四部分self.part4_1 = ConvBlock(1024, 3, [512, 512, 2048])self.part4_2 = Identity_block(2048, 3, [512, 512, 2048])self.part4_3 = Identity_block(2048, 3, [512, 512, 2048])# 平均池化self.avg_pool = nn.AvgPool2d(kernel_size=7)# 全连接self.fn1 = nn.Linear(2048, classes)def forward(self, x):# 头部x = F.relu(self.bn1(self.conv1(x)))x = self.max_pool(x)x = self.part1_1(x)x = self.part1_2(x)x = self.part1_3(x)x = self.part2_1(x)x = self.part2_2(x)x = self.part2_3(x)x = self.part2_4(x)x = self.part3_1(x)x = self.part3_2(x)x = self.part3_3(x)x = self.part3_4(x)x = self.part3_5(x)x = self.part3_6(x)x = self.part4_1(x)x = self.part4_2(x)x = self.part4_3(x)x = self.avg_pool(x)x = x.view(x.size(0), -1) # 扁平化x = self.fn1(x)return x model = ResNet50(classes=len(classnames)).to(device)model
ResNet50((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(part1_1): ConvBlock((conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))(shortcut_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part1_2): Identity_block((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part1_3): Identity_block((conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_1): ConvBlock((conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))(shortcut_bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_2): Identity_block((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_3): Identity_block((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part2_4): Identity_block((conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_1): ConvBlock((conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2))(shortcut_bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_2): Identity_block((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_3): Identity_block((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_4): Identity_block((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_5): Identity_block((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part3_6): Identity_block((conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part4_1): ConvBlock((conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(2, 2))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(shortcut): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2))(shortcut_bn): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part4_2): Identity_block((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(part4_3): Identity_block((conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(avg_pool): AvgPool2d(kernel_size=7, stride=7, padding=0)(fn1): Linear(in_features=2048, out_features=4, bias=True)
)
model(torch.randn(32, 3, 224, 224).to(device)).shape
torch.Size([32, 4])
3、模型训练
1、构建训练集
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)batch_size = len(dataloader)train_acc, train_loss = 0, 0 for X, y in dataloader:X, y = X.to(device), y.to(device)# 训练pred = model(X)loss = loss_fn(pred, y)# 梯度下降法optimizer.zero_grad()loss.backward()optimizer.step()# 记录train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_acc /= sizetrain_loss /= batch_sizereturn train_acc, train_loss
2、构建测试集
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)batch_size = len(dataloader)test_acc, test_loss = 0, 0 with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_acc /= sizetest_loss /= batch_sizereturn test_acc, test_loss
3、设置超参数
loss_fn = nn.CrossEntropyLoss() # 损失函数
learn_lr = 1e-4 # 超参数
optimizer = torch.optim.Adam(model.parameters(), lr=learn_lr) # 优化器
4、模型训练
train_acc = []
train_loss = []
test_acc = []
test_loss = []epoches = 80for i in range(epoches):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 输出template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(i + 1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))print("Done")

5、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息epochs_range = range(epoches)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training= Loss')
plt.show()

参考资料
【深度学习】ResNet网络讲解-CSDN博客
K同学啊,训练营文档
相关文章:
深度学习基础--ResNet网络的讲解,ResNet50的复现(pytorch)以及用复现的ResNet50做鸟类图像分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 如果说最经典的神经网络,ResNet肯定是一个,这篇文章是本人学习ResNet的学习笔记,并且用pytorch复现了ResNet50&…...

stack,queue,priority_queue学习知识点
容器适配器 在c常用的容器中,有的是以容器迭代器为核心,而有的则以容器适配器为核心。较为常用的就包括queue和stack。接下来我将简单的以queue和stack的模拟实现介绍其特点。 在以下的模拟实现中,class Con就是我们的容器适配器࿰…...

css特异性,继承性
html <div class"introduce"><div class"title">介绍</div><div class"card-box"><div class"card"><div class"title">管理</div></div></div> </div> scs…...

力扣hot100刷题——11~20
文章目录 11.滑动窗口最大值题目描述思路:滑动窗口单调队列code 12.最小覆盖子串题目描述思路:双指针/滑动窗口哈希code Ⅰcode Ⅱ 13.最大子数组和题目描述思路:dp/贪心code 14.合并区间题目描述思路:贪心code 15.轮转数组题目描…...

R语言Stan贝叶斯空间条件自回归CAR模型分析死亡率多维度数据可视化
全文链接:https://tecdat.cn/?p40424 在空间数据分析领域,准确的模型和有效的工具对于研究人员至关重要。本文为区域数据的贝叶斯模型分析提供了一套完整的工作流程,基于Stan这一先进的贝叶斯建模平台构建,帮助客户为空间分析带来…...
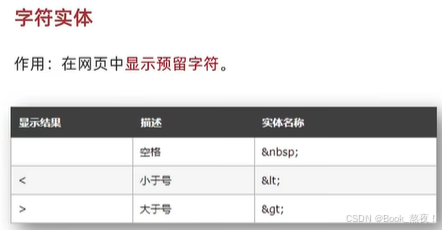
速通HTML
目录 HTML基础 1.快捷键 2.标签 HTML进阶 1.列表 a.无序列表 b.有序列表 c.定义列表 2.表格 a.内容 b.合并单元格 3.表单 a.input标签 b.单选框 c.上传文件 4.下拉菜单 5.文本域标签 6.label标签 7.按钮标签 8.无语义的布局标签div与span 9.字符实体 HTML…...

安装 Milvus Java SDK
本主题介绍如何为 Milvus 安装 Milvus Java SDK。 当前版本的 Milvus 支持 Python、Node.js、GO 和 Java SDK。 要求 Java(8 或更高版本)Apache Maven 或 Gradle/Grails 安装 Milvus Java SDK 运行以下命令安装 Milvus Java SDK。 Apache Maven &…...

云手机如何进行经纬度修改
云手机如何进行经纬度修改 云手机修改经纬度的方法因不同服务商和操作方式有所差异,以下是综合多个来源的常用方法及注意事项: 通过ADB命令注入GPS数据(适用于技术用户) 1.连接云手机 使用ADB工具连接云手机服务器,…...
)
牛客周赛 Round 82(思维、差分、树状数组、大根堆、前后缀、递归)
文章目录 牛客周赛 Round 82(思维、差分、树状数组、大根堆、前后缀、递归)A. 夹心饼干B. C. 食堂大作战(思维)D. 小苯的排列计数(差分、树状数组)E. 和和(大根堆,前缀和)F. 怎么写线性SPJ &…...

MQTT实现智能家居------2、写MQTT程序的思路
举个最简单的例子: 手机------服务器-------家具 我们这里只看手机和家具的客户端: 手机:1)需要连接服务器 2)需要发布指令给服务器到家里的家具 3)接受来自于家里家具的异常状况 4)保持心…...

大模型面试问题准备
1. BERT的多头注意力为什么需要多头? 为了捕捉不同子空间的语义信息,每个头关注不同的方面,增强模型的表达能力 2. 什么是softmax上下溢出问题? 问题描述: 上溢出:ye^x中,如果x取非常大的正数…...

C语言:二维数组在内存中是怎么存储的
目录 1. 二维数组的定义: 2. 行主序存储: 具体内存排列: 3. 如何通过指针访问数据: 4. 总结: 在 C 语言中,二维数组是按 行主序(row-major order) 存储的。也就是说,…...

AI时代前端开发技能变革与ScriptEcho:拥抱AI,提升效率
在飞速发展的科技浪潮中,人工智能(AI)正以前所未有的速度改变着各个行业,前端开发领域也不例外。曾经被认为是核心竞争力的传统前端技能,例如精通HTML、CSS和JavaScript,其价值正在发生微妙的变化。 得益于…...

计算机毕业设计SpringBoot+Vue.js美容院管理系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

【LeetCodehHot100_0x01】
LeetCodeHot100_0x01 1. 两数之和 解题思路: 暴力枚举法、哈希法 【暴力枚举】 class Solution {public int[] twoSum(int[] nums, int target) {int n nums.length;for(int i0;i<n;i) {for(int ji1;j<n;j) {if(nums[i] nums[j] target) {return new in…...

Qt::MouseButtons解析
一 问题 今天想自定定义一个QMouseEvent变量,变量的的初始化参数有Qt::MouseButtons,这是个啥?查看类型为QFlags<Qt::MouseButton>。 二 Qt::MouseButton Qt::MouseButton 是 Qt 框架中定义的一个枚举类型(enum),用于表示鼠标事件中的物理按钮。它是 Qt 事件处理…...

跨域问题解释及前后端解决方案(SpringBoot)
一、问题引出 有时,控制台出现如下问题。 二、为什么会有跨域 2.1浏览器同源策略 浏览器的同源策略 ( Same-origin policy )是一种重要的安全机制,用于限制一个源( origin )的文档或 脚本如何与另一个源的资源进行…...

4-知识图谱的抽取与构建-4_2实体识别与分类
🌟 知识图谱的实体识别与分类🔥 🔍 什么是实体识别与分类? 实体识别(Entity Recognition)是从文本中提取出具体的事物,如人名、地名、组织名等。分类(Entity Classification&#x…...

腾讯云大模型知识引擎×DeepSeek赋能文旅
腾讯云大模型知识引擎DeepSeek赋能文旅 ——以合肥文旅为例的技术革新与实践路径 一、技术底座:知识引擎与DeepSeek的融合逻辑 腾讯云大模型知识引擎与DeepSeek模型的结合,本质上是**“知识库检索增强生成(RAG)实时联网能力”**…...

TMDS视频编解码算法
因为使用的是DDR进行传输,即双倍频率采样,故时钟只用是并行数据数据的5倍,而不是10倍。 TMDS算法流程: 视频编码TMDS算法流程实现: timescale 1 ps / 1ps //DVI编码通常用于视频传输,将并行数据转换为适合…...

数字员工:不同场景下的落地案例全景
数字员工:不同场景下的落地案例全景 数字员工正在从概念走向规模化落地,覆盖制造、金融、零售、人力、客服等多个行业。以下是2025-2026年各领域真实应用案例的详细拆解。 一、供应链与制造场景 1. 壹沓科技:供应链物流AI Agent 企业背景&…...

5分钟掌握:终极免费音乐播放器LX Music完整使用手册
5分钟掌握:终极免费音乐播放器LX Music完整使用手册 【免费下载链接】lx-music-desktop 一个基于 Electron 的音乐软件 项目地址: https://gitcode.com/GitHub_Trending/lx/lx-music-desktop 在当今数字音乐时代,你是否厌倦了在不同音乐平台间来回…...

终极指南:如何用GPSTest精准测试手机卫星导航性能
终极指南:如何用GPSTest精准测试手机卫星导航性能 【免费下载链接】gpstest The #1 open-source Android GNSS/GPS test program 项目地址: https://gitcode.com/gh_mirrors/gp/gpstest 你的手机GPS到底有多准?🌍 通过GPSTest这款顶级…...

终极RPG Maker资源提取工具:三分钟解锁游戏素材宝库
终极RPG Maker资源提取工具:三分钟解锁游戏素材宝库 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/RPG…...

从SD卡分区到上电启动:详解Exynos 4412开发板的完整启动流程与手动烧写
从SD卡分区到上电启动:详解Exynos 4412开发板的完整启动流程与手动烧写 当一块搭载Exynos 4412的开发板首次通电时,芯片内部会执行一系列精密编排的启动流程。这个看似瞬间完成的过程,实际上包含了从硬件初始化到操作系统加载的多个关键阶段。…...
)
【多变量输入超前多步预测】基于CNN-BiLSTM的光伏功率预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

VS1053播放FLAC/WAV卡顿?手把手教你优化STM32的SPI DMA传输时序与缓冲区
VS1053高码率音频播放优化:STM32 SPI DMA与双缓冲实战指南 当你在STM32上使用VS1053解码器播放FLAC或WAV文件时,是否遇到过音频卡顿、爆音的问题?这往往是SPI数据传输速率跟不上音频解码需求导致的。本文将深入分析问题根源,并提供…...

Pixel Dimension Fissioner 企业级CI/CD流水线设计:从代码到部署
Pixel Dimension Fissioner 企业级CI/CD流水线设计:从代码到部署 1. 为什么企业需要专属的AI模型CI/CD 电商公司的技术团队最近遇到了一个典型问题:每次更新Pixel Dimension Fissioner图像生成模型时,从代码修改到最终上线平均需要3天时间。…...

cv_resnet101_face-detection_cvpr22papermogface实战应用:演唱会观众人数实时估算
cv_resnet101_face-detection_cvpr22papermogface实战应用:演唱会观众人数实时估算 你有没有想过,一场演唱会到底有多少观众?主办方报的数字准不准?或者,作为活动策划者,你想快速评估一下现场的上座率&…...

像素语言·维度裂变器:5分钟零基础部署,开启你的16-bit文本冒险
像素语言维度裂变器:5分钟零基础部署,开启你的16-bit文本冒险 1. 什么是像素语言维度裂变器 像素语言维度裂变器是一款将文本改写与增强功能包装成16-bit像素冒险游戏风格的AI工具。它基于MT5-Zero-Shot-Augment引擎构建,能够将普通文本输入…...