PyTorch常用函数总结(持续更新)
本文主要记录自己在用 PyTorch复现经典模型 过程中遇到的一些函数及用法,以期对 常见PyTorch函数 更加熟练~
官方Docs:PyTorch documentation — PyTorch 2.6 documentation
目录
数据层面
torch.sign(tensor)
torch.tensor(np.eye(3)[y])
torch.ones() / torch.sum(dim=0)
torch.unsqueeze()升维 & torch.squeeze()降维
torch.mm() / torch.matmul() / torch.mul()
torch.clamp_()
torch.tensor().item()
torch.tensor().view()
torch.gather()
torch.pow()
torch.stack() / torch.cat()
torch.tensor().t()
torch.manual_seed()
torch.empty()
torch.einsum()
torch.randn() / torch.randint()
模型层面
TensorDataset() / Dataset() / DataLoader()
nn.MSELoss() / nn.BCELoss()
optim.Adam() 等优化器
torch.nn.Sigmoid() / torch.nn.Softmax()
nn.ModuleList() / nn.ParameterList()
数据层面
torch.sign(tensor)
sign函数就是符号函数,大于0的输入变为1输出,小于0的输入变为-1输出,0输出为0。如下:

>>> a = torch.tensor([0.7, -1.2, 0., 2.3])
>>> torch.sign(a)
tensor([ 1., -1., 0., 1.])
可以在该函数上做一些变种,如单位阶跃函数:

import torch
theta = lambda t: (torch.sign(t) + 1.) / 2.torch.tensor(np.eye(3)[y])
import numpy as npa=np.eye(3) # 生成对角线全是1,其余全是0的3维矩阵
print(a)a=np.eye(4,k=1) # k=1表示全是1的那条对角线往右上走一格(只有3个1了)
print(a)a=np.eye(4,k=-1) # k=-1表示全是1的那条对角线往左下走一格(只有3个1了)
print(a)a=np.eye(4,k=-3) # k=-3表示全是1的那条对角线往左下走三格(只有1个1了)
print(a)结果:
[[1. 0. 0.][0. 1. 0.][0. 0. 1.]][[0. 1. 0. 0.][0. 0. 1. 0.][0. 0. 0. 1.][0. 0. 0. 0.]][[0. 0. 0. 0.][1. 0. 0. 0.][0. 1. 0. 0.][0. 0. 1. 0.]][[0. 0. 0. 0.][0. 0. 0. 0.][0. 0. 0. 0.][1. 0. 0. 0.]]torch.tensor(np.eye(3)[y]) 为 标签label 转 one-hot向量 的一种写法:
- np.eye(3)[y] 使用y,即label中的值作为索引,选择单位矩阵中对应的行
- y的三个元素依次为0、2、2,代表依次选择第0行、第2行、第2行
import torch
import numpy as npy = torch.tensor([0, 2, 2])
y_onehot = torch.tensor(np.eye(3)[y])
print(y_onehot)tensor([[1., 0., 0.],[0., 0., 1.],[0., 0., 1.]], dtype=torch.float64)torch.ones() / torch.sum(dim=0)
a = torch.ones((2, 3)) # 两行三列、全为1的矩阵
print(a)tensor([[1., 1., 1.],[1., 1., 1.]])a1 = torch.sum(a)
a2 = torch.sum(a, dim=0) # 列优先
a3 = torch.sum(a, dim=1) # 行优先print(a1) tensor(6.)
print(a2) tensor([2., 2., 2.])
print(a3) tensor([3., 3.])如果加上keepdim=True,则会保持dim的维度不被squeeze
a2 = torch.sum(a, dim=0, keepdim=True) # keepdim=True的结果也是二维,即两个[[
a3 = torch.sum(a, dim=1, keepdim=True)print(a2) tensor([[2., 2., 2.]])
print(a3) tensor([[3.],[3.]])torch.unsqueeze()升维 & torch.squeeze()降维
torch.unsqueeze() 函数起升维的作用,参数dim 表示在哪个地方加一个维度
- 注意dim范围。比如输入input是一维,则dim=0时数据为行方向扩,dim=1时为列方向扩,再大错误
x = torch.tensor([1, 2, 3, 4]) # torch.Size([4])y = torch.unsqueeze(x, 0) # 在第0维扩展,第0维大小为1
y, y.shape # (tensor([[1, 2, 3, 4]]), torch.Size([1, 4]))y = torch.unsqueeze(x, 1) # 在第1维扩展,第1维大小为1
y, y.shape
'''
(tensor([[1],[2],[3],[4]]),torch.Size([4, 1]))
'''y = torch.unsqueeze(x, -1) # 在最后一维扩展,最后一维大小为1
# 结果同在第1维扩展torch.squeeze() 函数的功能是维度压缩,返回一个tensor(张量),其中 input中维度大小为1的所有维都被删除。举个例子,如果 input 的形状为 (A×1×B×C×1×D),那么返回的tensor形状为 (A×B×C×D)
torch.squeeze(input, dim=None, out=None) 当给定dim 时,只在给定的维度上进行压缩操作,注意给定的维度大小必须是1,否则不能进行压缩。举个例子:如果 input 的形状为 (A×1×B),squeeze(input, dim=0)后,返回的tensor不变,因为第0维的大小为A,不是1;squeeze(input, dim=1)后,返回的tensor将被压缩为 (A×B)
torch.mm() / torch.matmul() / torch.mul()
torch.mm() 只适合二维张量的矩阵乘法,如 m*n 和 n*p 输出为 m*p
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])
result = torch.mm(A, B) 或 result = torch.matmul(A, B) 二维时两者等价tensor([[19, 22],[43, 50]])若三维或更高维度,可以用 torch.matmul();同时它也支持矩阵与向量的乘法、向量与向量的点积。如例:
# 矩阵与向量乘法
A = torch.tensor([[1, 2], [3, 4]])
v = torch.tensor([1, 1])
result = torch.matmul(A, v)tensor([3, 7])# 向量与向量乘法
v1 = torch.tensor([1, 2])
v2 = torch.tensor([3, 4])
result = torch.matmul(v1, v2) # 1*3 + 2*4 = 11tensor(11)而 torch.mul() 是两个矩阵的元素对位相乘,即哈达玛积。故输入的两个矩阵维度必须一致,返回的仍是同维度的矩阵
# 两个张量乘法
A = torch.tensor([1, 2, 3])
B = torch.tensor([4, 5, 6])
result = torch.mul(A, B)tensor([4, 10, 18])# 张量与标量乘法
A = torch.tensor([1, 2, 3])
result = torch.mul(A, 2)tensor([2, 4, 6])更多张量乘法见Pytorch常用乘法函数总结:torch.mul()、*、torch.mm()、torch.bmm()、torch.mv()、torch.dot()、@、torch.matmul()-CSDN博客
torch.clamp_()
torch.clamp_(input, min, max, out=None) → Tensor将输入input张量每个元素的值压缩到区间 [min, max],并直接将结果返回给这个tensor(而不是返回新的tensor)
tensor = torch.tensor([[-1, 2], [3, 10], [15, -5]])
# 使用clamp_限制张量的值在0到5之间
tensor.clamp_(0, 5) 或 torch.clamp_(tensor, 0, 5)tensor([[0, 2],[3, 5],[5, 0]])
若为torch.clamp() ,即没有下划线,则返回一个新的tensor
clamped_tensor = torch.clamp(tensor, 0, 5)# tensor本身不会改变,clamped_tensor将包含限制后的值pytorch中,一般来说,如果对tensor的一个函数后加了下划线,表明这是一个in-place类型(当在一个tensor上操作了之后,是直接修改了这个tensor,而不是返回一个新的tensor而并不修改旧的tensor)
torch.tensor().item()
.item() 返回的是一个浮点型数据。在求loss或者accuracy时,一般使用 .item()
import torch
x = torch.randn(2, 2) # 2行2列
print(x)
print(x[1,1])
print(x[1,1].item())tensor([[ 0.4702, 0.5145],[-0.0682, -1.4450]])
tensor(-1.4450)
-1.445029854774475torch.tensor().view()
用于tensor维度的重构,即返回一个有相同数据、但不同维度的tensor
view函数的操作对象应该是tensor类型。如果不是tensor类型,可以通过 torch.tensor() 来转换
temp = [1,2,3,4,5,6] # temp的类型为list,非Tensor
temp = torch.tensor(temp) # 将temp由list类型转为Tensor类型。torch.Size([6])print(temp.view(2,3)) # 将temp的维度改为2*3
print(temp.view(2,3,1)) # 将temp的维度改为2*3*1
print(temp.view(2,3,1,1)) # 更多的维度也没有问题,只要保证维度改变前后的元素个数相同就行,即2*3*1*1=6
特殊用法:
- 如果某个参数为-1,表示该维度取决于其他维度,由Pytorch自己计算得到;
- 如果直接view(-1),表示将tensor转为一维tensor
temp = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(temp) # torch.Size([2, 3])
print(temp.view(-1)) # 多维张量转为一维张量tensor([1, 2, 3, 4, 5, 6])torch.gather()
从原tensor中获取指定dim和指定index的数据。方便从批量tensor中获取指定索引下的数据,该索引是高度自定义且可乱序的
torch.gather(input, dim, index)- dim:dim=1 表示按照行号进行索引;dim=0 表示按照列号进行索引
- index:索引张量,指定要从input的dim维度上提取哪些元素。index的大小应和返回结果相同
例1:在0维上gather(按照列号)
import torchx = torch.tensor([[10, 20, 30], [40, 50, 60], [70, 80, 90]])index = torch.tensor([[0, 2, 1], [1, 0, 2], [2, 1, 0]])result = torch.gather(x, dim=0, index=index)
print(result)tensor([[10, 80, 60],[40, 20, 90],[70, 50, 30]])
例2:在1维上gather(按照行号)
x = torch.tensor([[10, 20, 30], [40, 50, 60], [70, 80, 90]])index = torch.tensor([[2, 1, 0], [0, 2, 1], [1, 0, 2]])result = torch.gather(x, dim=1, index=index)
print(result)tensor([[30, 20, 10],[40, 60, 50],[80, 70, 90]])
例3:实际应用,获取分类任务中真实类别的预测概率
import torch
import torch.nn.functional as Flogits = torch.tensor([[2.0, 1.0, 0.1], [0.5, 2.1, 1.3]])labels = torch.tensor([[0], [1]]) # 真实类别索引# 计算 softmax 使其成为概率
probs = F.softmax(logits, dim=1) # dim=0 列优先,dim=1 行优先tensor([[0.6590, 0.2424, 0.0986],[0.1863, 0.5141, 0.2996]])# 使用 gather 提取 labels即真实标签 对应的概率
selected_probs = torch.gather(probs, dim=1, index=labels)tensor([[0.6590],[0.5141]])
PyTorch中torch.gather()函数-CSDN博客
torch.gather()函数-CSDN博客
torch.pow()
对输入tensor的分量求幂次运算
a = torch.tensor(3)
b = torch.pow(a,2) # tensor(9) 即3^2=9c = torch.randn(4) # tensor([0.0923, 0.7006, -0.2963, 0.6543])
# 对其中的每个分量求平方
d = torch.pow(c,2) # tensor([0.0085, 0.4909, 0.0878, 0.4282])PyTorch 笔记(05)— Tensor 基本运算(torch.abs、torch.add、torch.clamp、torch.div、torch.mul、torch.pow等)-CSDN博客
torch.stack() / torch.cat()
torch.stack() 将多个形状相同的张量沿着一个新维度进行堆叠,即合并成一个更高维度的张量
torch.stack(tensors, dim=0)- tensors:一个包含多个张量的序列(例如,列表或元组)。所有张量必须具有相同的形状
- dim:要插入新维度的位置,默认为0
- 返回值:在指定的维度dim上增加了一个新的维度,原始张量的形状在其他维度上保持不变
例1:沿第0维堆叠
import torch# 创建三个形状相同的张量
x1 = torch.tensor([1, 2])
x2 = torch.tensor([3, 4])
x3 = torch.tensor([5, 6])# 沿着第0维堆叠
result = torch.stack([x1, x2, x3], dim=0)print(result)
tensor([[1, 2],[3, 4],[5, 6]])print(result.shape) # 输出: torch.Size([3, 2])
例2:沿第1维堆叠
import torch# 创建三个形状相同的张量,形状为(2,)
x1 = torch.tensor([1, 2])
x2 = torch.tensor([3, 4])
x3 = torch.tensor([5, 6])result = torch.stack([x1, x2, x3], dim=1)print(result)
tensor([[1, 3, 5],[2, 4, 6]])print(result.shape) # 输出: torch.Size([2, 3])
torch.stack() 会在指定维度上增加一个新的维度,而 torch.cat() 是沿着现有维度连接多个张量,张量的形状不会增加新的维度
torch.cat(tensors, dim=0)- tensors:一个包含多个张量的序列(例如,列表或元组)。这些张量的形状必须在除了指定维度dim之外相同
- dim:要沿着其连接的维度,默认为0,表示沿着行拼接
- 返回值:在指定的维度上将输入的多个张量拼接起来
例1:沿第0维拼接
import torch# 创建两个形状相同的张量
x1 = torch.tensor([[1, 2], [3, 4]])
x2 = torch.tensor([[5, 6], [7, 8]])# 沿着第0维度拼接
result = torch.cat([x1, x2], dim=0)print(result)
tensor([[1, 2],[3, 4],[5, 6],[7, 8]])print(result.shape) # 输出: torch.Size([4, 2])例2:沿第1维拼接
import torch# 创建两个形状相同的张量
x1 = torch.tensor([[1, 2], [3, 4]])
x2 = torch.tensor([[5, 6], [7, 8]])result = torch.cat([x1, x2], dim=1)print(result)
tensor([[1, 2, 5, 6],[3, 4, 7, 8]])print(result.shape) # 输出: torch.Size([2, 4])例3:拼接不同维度的张量(这些张量的形状必须在除了指定维度dim之外相同)
# 创建两个形状不同的张量
x1 = torch.tensor([[1, 2], [3, 4]]) # (2, 2)
x2 = torch.tensor([[5, 6]]) # (1, 2)# 沿着第0维度拼接
result = torch.cat([x1, x2], dim=0)print(result)
tensor([[1, 2],[3, 4],[5, 6]])print(result.shape) # 输出: torch.Size([3, 2])
例4:拼接张量和标量
# 创建张量和标量
x1 = torch.tensor([1, 2, 3])
scalar = torch.tensor([4])# 沿着第 0 维度拼接
result = torch.cat([x1, scalar], dim=0)print(result)
tensor([1, 2, 3, 4])torch.tensor().t()
将tensor进行转置
import torch
a = torch.tensor([[1,2],[3,4]])a
tensor([[1, 2],[3, 4]])a.t()
tensor([[1, 3],[2, 4]])Pytorch里.t()的作用-CSDN博客
torch.manual_seed()
用于设置随机数生成器种子,确保每次运行时生成相同的随机数序列。通常,用于确保实验的可复现性,特别是在训练深度学习模型时,需要确保每次训练模型的初始化权重和数据的随机划分一致
torch.manual_seed(seed) # seed为一个整数。一般设置为 42torch.manual_seed() 只会影响在CPU上的随机数生成。如果使用了GPU,还需要设置GPU上的随机数种子
# 设置GPU上的随机数种子
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # 如果使用多个GPU注:如果代码中还使用了numpy,也可以设置numpy的随机种子,使得整个实验过程是可复现的
np.random.seed(seed)参考:pytorch如何确保 可重复性/每次训练结果相同(固定了随机种子,为什么还不行)? - Cheer-ego的回答 - 知乎
torch.empty()
创建一个具有指定形状、但内容未定义,即未经初始化(不会被初始化为零或者任何其他值)的张量。由于不进行任何初始化工作,它比 torch.zeros() 或 torch.randn() 等初始化函数更快
# *表示必选,其余参数都为可选
torch.empty(*size, dtype=None, layout=torch.strided, device=None, requires_grad=False)- size:张量的形状,可以是整数或元组。如 (2, 3) 表示一个2×3的张量
- dtype:张量的数据类型,默认为torch.float32
- layout:张量的布局,默认为torch.strided,通常不需要改
- device:张量存储的设备,默认CPU,通过 torch.device('cuda') 可以将张量创建在GPU上
# 创建一个2x2的未初始化张量,并放到GPU上
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tensor_gpu = torch.empty(2, 2, device=device)
- requires_grad:默认为False。如果设置为True,则张量将追踪其所有操作,支持自动求导(用于神经网络训练)
应用场景:
- 模型权重初始化
tensor = torch.empty(3, 3) # 创建一个未初始化的张量
torch.nn.init.normal_(tensor, mean=0.0, std=1.0) # 使用正态分布初始化- 高效内存分配:知道张量的形状,但暂时不关心其内容时,可以使用 torch.empty() 创建一个张量,并稍后填充或更新它的内容
# 多任务学习的一个例子
task1_dim, task2_dim = 3, 2
y_train_task1 = torch.empty(num_samples, task1_dim)
y_train_task1[:, 0] = torch.randint(0, 2, (num_samples,)).float() # 是否停留
y_train_task1[:, 1] = torch.randn(num_samples) # 停留时长
y_train_task1[:, 2] = torch.randint(0, 2, (num_samples,)).float() # 是否点击y_train_task2 = torch.empty(num_samples, task2_dim)
y_train_task2[:, 0] = torch.randn(num_samples) # 点击后播放时长
y_train_task2[:, 1] = torch.randint(0, 2, (num_samples,)).float() # 播放后是否点赞torch.einsum()
爱因斯坦求和约定
- 提供了一种灵活且高效的方式来执行各种线性代数操作(如矩阵乘法、矩阵转置、向量点积、外积)、广播操作、求和或聚合操作(如矩阵迹)等
- 通过符号表示操作中的维度来描述操作,而不需要显式地使用循环或中间张量
torch.einsum(equation, *operands)- equation:一个字符串,指定了操作的维度及求和的规则(通过字母表示张量的维度,维度之间用逗号分隔)
- operands:需要操作的张量,可以是多个张量
矩阵乘法:(m, n) 与 (n, p) -> (m, p)
torch.einsum('ij,jk->ik', A, B)向量点积:对应元素相乘并求和,即dot product
torch.einsum('i,i->', a, b)向量外积(outer product):假设向量a 和 向量b 的维度分别是 (m) 和 (n),通过将 向量a 中的每个元素和 向量b 中的每个元素相乘,生成一个 (m, n)维度 的矩阵
torch.einsum('i,j->ij', a, b)矩阵转置:
torch.einsum('ij->ji', A)广播:torch.einsum('ij,j->ij', A, B) 表示将A的每一列与B对应的元素相乘,从而实现广播
A = torch.tensor([[1, 2, 3, 4],[1, 1, 1, 1],[4, 3, 2, 1]]) # torch.Size([3, 4])
B = torch.tensor([2, 2, 2, 2]) # torch.Size([4])# 广播
result = torch.einsum('ij,j->ij', A, B)print(result)
tensor([[2, 4, 6, 8],[2, 2, 2, 2],[8, 6, 4, 2]]) # torch.Size([3, 4])矩阵迹(trace):矩阵对角线元素的和
torch.einsum('ii->', A)torch.randn() / torch.randint()
torch.randn() 用于生成服从标准正态分布(均值为0,标准差为1)的随机浮点数
# *表示必选,其余参数都为可选
torch.randn(*size, dtype=None, device=None, requires_grad=False)- size:生成张量的形状,可以是一个整数或一个整数元组
- dtype:张量的数据类型,默认为torch.float32
- device:默认为CPU。如果需要创建GPU上的张量,可以使用 torch.device('cuda') 或指定 device='cuda'
- requires_grad:是否需要计算梯度,默认False
常见用途:初始化神经网络权重、生成噪声、随机生成生态分布数据
torch.randint() 用于生成指定范围内的整数随机数,并可以指定张量的形状。返回一个包含随机整数的张量,生成的整数值是离散的,形状由size指定,生成的数值位于 [low, high) 之间
# *表示必选,其余参数都为可选
torch.randint(*low, *high, *size, dtype=None, device=None, requires_grad=False)- low:生成的随机数的下限(包含)
- high:生成的随机数的上限(不包含)
- dtype:默认为torch.int64
- 其它参数同上
常见用途:随机生成整数类型的标签(如分类标签)或索引、生成数据集的随机批次索引
两者对比:

模型层面
TensorDataset() / Dataset() / DataLoader()
from torch.utils.data import TensorDataset, Dataset, DataLoader
TensorDataset 通常用于将特征张量和标签张量组合在一起,封装成一个数据集对象,便于传递给模型训练
# *tensors可以是任意数量的张量,但必须保证第一个维度都相同
torch.utils.data.TensorDataset(*tensors)- 每个张量的第一个维度(代表样本数量)应该是相同的,因为这些张量会按行组合起来,每一行代表一个样本
- 返回一个可迭代的数据集对象,可以通过DataLoader将其包装成一个数据加载器,以便按批次加载数据
应用:
dataset = TensorDataset(features, labels)# 如果数据集包含多个特征和多个标签
dataset = TensorDataset(features1, features2, labels1, labels2) # 将两个特征张量和两个标签张量组合在一起,每个批次中返回四个元素Dataset 是用于表示数据集的基类,可以通过继承 torch.utils.data.Dataset 类来定义自己的数据集类(自定义如何加载数据、如何处理数据)。需要实现两个方法:
- __len__():返回数据集的大小,即数据集中样本的数量
- __getitem__(index):根据索引返回数据集中一个样本,通常是特征和标签。可以在这里进行数据的预处理,如数据增强、归一化、标准化等
import torch
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self, features, labels):self.features = featuresself.labels = labelsdef __len__(self):return len(self.features) # 数据集的大小def __getitem__(self, idx):# 根据索引返回一个数据样本,包括特征和标签x = self.features[idx]y = self.labels[idx]return x, y# 创建自定义数据集实例
dataset = MyDataset(features, labels)DataLoader 用于批量加载数据,通常与 TensorDataset 或自定义的数据集类一起使用。提供了批量加载(将数据按批次加载到内存中进行训练。batch_size)、数据打乱(帮助提高模型训练的泛化能力。shuffle)、并行加载(使用多线程并行加载数据,提高数据加载速度。num_workers)、自动迭代(类似于迭代一个list)等功能
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,batch_sampler=None, num_workers=0, collate_fn=None,pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None)-
dataset: 传入的数据集对象。它可以是TensorDataset、Dataset的子类或自定义的数据集类,必须实现__len__和__getitem__方法。 -
batch_size(int, default=1): 每个批次包含的样本数量。 -
shuffle(bool, default=False): 是否在每个epoch结束后打乱数据。设置为True会对数据进行随机打乱,这在训练过程中通常是必需的。 -
sampler(torch.utils.data.Sampler, optional): 通常用于定制数据抽取方式。可以选择不使用shuffle,而使用自定义的sampler。 -
batch_sampler(torch.utils.data.BatchSampler, optional): 类似于sampler,但返回批次样本。 -
num_workers(int, default=0): 用于加载数据的子进程数量。设置为大于0时,DataLoader将在多个进程中并行加载数据(通常会提升加载速度)。一般来说,num_workers设置为系统 CPU 核心数的 1-2 倍比较合适。 -
collate_fn(callable, optional): 用于将一个批次内的数据组合成一个小批量。可以根据需要自定义,如填充、拼接等。 -
pin_memory(bool, default=False): 如果设置为True,DataLoader会将数据加载到内存中并进行内存页锁定,这在使用GPU加速时可能提高性能。 -
drop_last(bool, default=False): 如果设置为True,在数据集大小不能被batch_size整除时,会丢弃最后一个不满批次的数据。 -
timeout(int, default=0): 如果设置为正值,则表示加载数据时最大超时时间(秒)。一般不常用,除非遇到数据加载卡顿的情况。 -
worker_init_fn(callable, optional): 如果使用多进程加载数据,可以传入一个函数,用于在每个子进程初始化时执行自定义操作(例如设置随机种子)。
例1:基本使用
import torch
from torch.utils.data import TensorDataset, DataLoader# 特征张量和标签张量
features = torch.randn(10, 5) # 10个样本,每个样本有 5个特征
labels = torch.randint(0, 2, (10,)) # 10个标签,0或1# 创建TensorDataset
dataset = TensorDataset(features, labels)# 使用 DataLoader创建批量加载器
dataloader = DataLoader(dataset, batch_size=3, shuffle=True)# 迭代 DataLoader,按批次加载数据
for data in dataloader:inputs, targets = dataprint(inputs.shape, targets.shape)torch.Size([3, 5]) torch.Size([3])
torch.Size([3, 5]) torch.Size([3])
torch.Size([3, 5]) torch.Size([3])
torch.Size([1, 5]) torch.Size([1])例2:自定义collate_fn函数
- 用于定义如何将一个批次内的数据组合成一个小批量
- 如下例,collate_fn 将批次数据按最大长度进行填充,使得每个输入张量的长度相同。适用于处理变长序列数据(如文本、时间序列等)
# 自定义处理批次数据(例如填充到相同的长度)
def collate_fn(batch):# 将一个包含多个元组的列表(或可迭代对象)解包为两个独立的列表(或元组)inputs, targets = zip(*batch)max_len = max([len(x) for x in inputs])# 假设想要按最大长度填充数据padded_inputs = [torch.cat([x, torch.zeros(max_len - len(x))]) for x in inputs]return torch.stack(padded_inputs), torch.tensor(targets)# 创建 DataLoader,使用自定义的 collate_fn
dataloader = DataLoader(dataset, batch_size=3, collate_fn=collate_fn)# 迭代 DataLoader
for data in dataloader:inputs, targets = dataprint(inputs)print(targets)参考 Pytorch的数据读取机制:Dataset类 & DataLoader类以及collate_fn参数
nn.MSELoss() / nn.BCELoss()
import torch.nn as nn
nn.MSELoss() 是用于计算均方误差(Mean Squared Error,MSE)的损失函数,常用于回归问题。相较于 nn.L1Loss(),MSELoss更加敏感于离群点(Outliers),因为它使用了平方项,离群点的影响被放大;而 L1Loss() 使用的是绝对值,对离群点的影响较小。
- 参数:reduction(可选,默认是 'mean' )
- mean:返回所有样本的损失均值
- sum:返回所有样本的损失总和
- none:返回一个张量,包含每个样本的损失值
- 训练神经网络时,如果使用MSELoss,输出层通常是线性激活,即没有激活函数,或使用ReLU / Tanh 等

import torch
import torch.nn as nn# 假设我们有一些预测值和真实值
y_true = torch.tensor([1.0, 2.0, 3.0])
y_pred = torch.tensor([1.5, 2.5, 3.5])# 定义 MSELoss
mse_loss = nn.MSELoss()# 计算 MSE损失
loss = mse_loss(y_pred, y_true)
print(f'MSE Loss: {loss.item()}') # MSE Loss: 0.25nn.BCELoss() 是用于二分类问题的二进制交叉熵损失函数(Binary Cross Entropy Loss),要求预测值是一个概率值(介于0~1),通常需要使用Sigmoid函数;标签必须是二分类标签(0或1)
- 参数:reduction(可选,默认是 'mean' ),用法同上,可以选择返回均值、总和或每个样本的损失
- 如果模型输出的不是概率值(即通过Sigmoid进行归一化的值),而是原始的未归一化分数(logits),可以使用 nn.BCEWithLogitsLoss() 。该损失函数会自动对logits进行Sigmoid操作,而无需显式地在模型输出中应用Sigmoid

optim.Adam() 等优化器
import torch.optim as optim optimizer = optim.Adam(model.parameters(), lr=0.001)
Pytorch提供了多种优化器:
- optim.SGD:使用梯度下降的随机版本更新参数。缺点是易陷入局部最小值,且收敛速度较慢
- lr:学习率(需要手动调整)
- momentum:动量,用来加速收敛,减少震荡,避免陷入局部最小值
- weight_decay:L2正则化系数
- optim.Adagrad:根据每个参数的历史梯度自适应调整学习率
- 对于稀疏梯度有很好的表现
- 对于长期训练可能导致学习率下降太快(变为0,停止训练),从而无法收敛
- optim.RMSprop:是一种自适应学习率的优化器,在序列数据如RNN中表现优异
- lr:学习率
- alpha:衰减因子,控制过去梯度的影响
- weight_decay:L2正则化系数
- optim.Adam:是SGD的一个改进版本,结合了 Momentum 和 RMSprop 的优点,能自动调整每个参数的学习率,故通常不需要过多的超参数调整
- 对于稀疏梯度表现较好;比普通的SGD更稳定,不容易陷入局部最小值
- 某些情况下比SGD更容易过拟合,尤其是当训练集较小时
- optim.Adadelta:是Adagrad的改进版本,旨在解决Adagrad在训练时学习率下降过快的问题
- optim.NAdam:是Adam和Nesterov动量的结合。由于Nesterov加速的优势,可能加速收敛;但计算开销相对较大,训练时间较长
- optim.FTRL:适用于稀疏特征的优化,常用于大规模机器学习问题
- optim.LBFGS:是一种基于二阶优化方法的算法,适用于较小的数据集和模型,常用于精细调优阶段,收敛速度较快,能得到更精确的最优解
- optim.SparseAdam:是Adam的稀疏版本,通常用于处理具有稀疏梯度的模型(如嵌入层)
- optim.ASGD:基于SGD的变种,结合了平均化策略来减少震荡。比传统SGD更稳定,但适用于特定类型的任务,故不常用
不同优化器对比参考 七种反向传播优化器总结及Python实现(SGD、SGDM、Adagrad、RMSProp、Adam、NAG、AdaDelta)
torch.nn.Sigmoid() / torch.nn.Softmax()
torch.nn.Sigmoid() 将输入值映射到一个 0~1 之间的输出(会对张量的每个元素应用Sigmoid函数),常用于二分类问题中的输出层,尤其是需要输出概率值的情况
- 除了 nn.Sigmoid() 模块,还可以直接使用 torch.sigmoid() 函数

如二分类模型最后一层通常是一个Sigmoid激活函数,将模型输出映射到0~1之间,表示某一类的概率(如输出0.8表示模型认为该样本属于正类的概率为80%):
# 模型的输出层定义
output_layer = nn.Linear(in_features, 1) # 输出一个标量
output = nn.Sigmoid(output_layer(x))问题:在输入值较大或较小时(即接近0或接近1),梯度会变得非常小,几乎为0,这可能导致训练时出现梯度消失。因此Sigmoid不适合用在隐藏层,而通常用于输出层
- vs ReLU:ReLU输出范围是 (0, +∞),常用于隐藏层的激活函数,相对于Sigmoid能更有效地避免梯度消失问题
- vs Tanh:Tanh输出范围是 (-1, 1),与Sigmoid相比,Tanh在训练时通常表现得更好,因为它的输出对称性使得模型的学习更加稳定
torch.nn.Softmax() 将输入的多个值转换为一个概率分布,输出的概率值和为1,通常用于多分类任务的输出层
- 参数dim:决定沿哪个维度应用softmax
- dim=0:通常是batch维度,适用于对每个样本的类别进行归一化
- dim=1:通常是样本维度,是大多数多分类任务的标准做法
- 参数dtype:指定返回张量的数据类型,通常是浮点数类型
- 等价写法:torch.softmax(x, dim=1) 函数
- 若输入得分非常大或非常小,可能导致数值上的不稳定。因此,通常会对输入进行缩放处理(例如减去每行的最大值)。上面两种softmax写法都已经自动进行了数值稳定性处理,不需要再手动处理

例1:以二维输入为例
import torch.nn as nninput = torch.tensor([[1., 2, 3],[4, 5, 6]]) # input必须为float类型m1 = nn.Softmax(dim=0)
output1 = m1(input)m2 = nn.Softmax(dim=1) # dim=1表示在每一行(即每个样本)上应用Softmax
output2 = m2(input)# dim=-1就是按最后一维,这个例子里等价于dim=1

- 二维tensor参考:【Pytorch】torch.nn. Softmax()_torch.softmax-CSDN博客
- 多维tensor可以参考:Pytorch nn.Softmax(dim=?) - 知乎
例2:在训练多分类模型时,常常使用 torch.nn.CrossEntropyLoss,它会自动应用softmax(不需要在模型的输出层显式使用softmax,而是可以直接输出未经softmax归一化的原始得分,即logits)
# 定义 CrossEntropyLoss
criterion = nn.CrossEntropyLoss()# y_pred是未经Softmax处理的logits,y_true是标签(整数索引)
y_pred = torch.tensor([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0]])
y_true = torch.tensor([2, 1])# 计算损失
loss = criterion(y_pred, y_true)
print(f'CrossEntropyLoss: {loss.item()}')nn.ModuleList() / nn.ParameterList()
nn.ModuleList() 是一个用于保存 nn.Module对象的容器,是一个有序的容器,可以按顺序存储多个子模块(如多个卷积层、全连接层等)。在Pytorch中,它能够保证其中的每个模块都被正确地注册到模型中,且可以通过 .parameters() 自动获取模型中的所有参数
- 所有的子模块会被自动地添加到模型的参数列表中
- 在模型的forward函数中可以动态地通过索引调用各个子模块
import torch
import torch.nn as nnclass ExampleModel(nn.Module):def __init__(self):super(ExampleModel, self).__init__()self.layers = nn.ModuleList([nn.Conv2d(1, 32, 3), nn.Conv2d(32, 64, 3)])def forward(self, x):for layer in self.layers:x = layer(x)return xnn.ParameterList() 是专门用于存储 nn.Parameter 对象(nn.Parameter是torch.Tensor的一个子类,用于存储模型中的参数,如权重和偏置)的容器。用于管理模型中手动创建的、通常需要进行梯度更新的参数
- 适用于存储多个独立的参数,如自定义的权重、偏置等
- 不会自动注册任何模块,仅仅用于管理参数,这些参数可以直接参与优化过程
import torch
import torch.nn as nnclass ExampleModel(nn.Module):def __init__(self):super(ExampleModel, self).__init__()self.weights = nn.ParameterList([nn.Parameter(torch.randn(3, 3)) for _ in range(5)])def forward(self, x):for weight in self.weights:x = torch.matmul(x, weight)return x总结:
nn.ModuleList()用于存储nn.Module子模块,主要作用是组织网络层级,确保模块的自动注册nn.ParameterList()用于存储nn.Parameter,主要用于管理模型的参数(例如权重和偏置),而不是层或子模块
相关文章:
PyTorch常用函数总结(持续更新)
本文主要记录自己在用 PyTorch复现经典模型 过程中遇到的一些函数及用法,以期对 常见PyTorch函数 更加熟练~ 官方Docs:PyTorch documentation — PyTorch 2.6 documentation 目录 数据层面 torch.sign(tensor) torch.tensor(np.eye(3)[y]) torch.on…...
NO.4)
代码异常(js中push)NO.4
1. 环境 Vue3,Element Plsu 2. 示例代码 const { updateBy, updateTime, ...curObj } form.valuecurObj.id props.tableData.length 1var newTableData props.tableData.push(curObj)updateTableData(newTableData)3. 情景描述 newTableData变成了整数&#…...
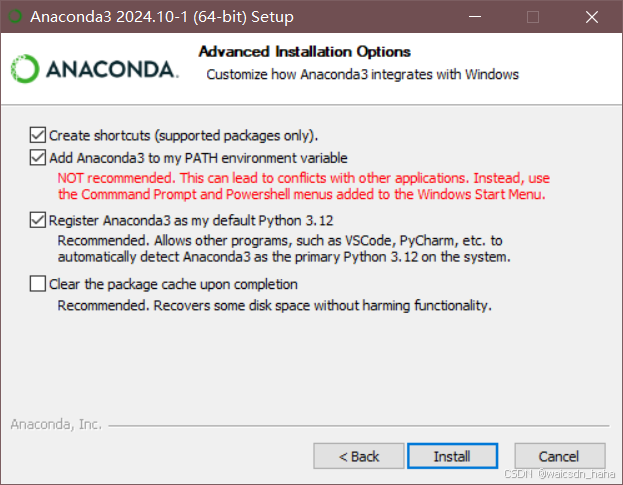
Anaconda 2025 最新版安装与Python环境配置指南(附官方下载链接)
一、软件定位与核心功能 Anaconda 2025 是Python/R数据科学集成开发平台,预装1500科学计算库,新增AI模型可视化调试、多环境GPU加速等特性。相较于传统Python安装,其优势包括: 环境隔离:通过conda工具实现多版本Pyth…...

Vue 中动态实现进度条
在 Vue 中动态实现进度条,基本上有两种常见的方法:直接通过 Vue 数据绑定控制样式,或者利用外部库来实现更复杂的功能。我们会深入探讨这两种方式,并且详细说明每种方法的实现步骤、优缺点以及使用场景。 1. 使用 Vue 数据绑定来…...

CSS滚动条原理与自定义样式指南,CSS滚动条样式失效,滚动条样式无效,-webkit-scrollbar无效,overflow不显示滚动条
滚动内容形成的必要条件 CSS Overflow属性解析 MDN官方文档-Overflow属性 菜鸟教程-Overflow属性 overflow 属性控制内容溢出元素框时在对应的元素区间内是否添加滚动条。 值描述visible默认值。内容不会被修剪,会呈现在元素框之外。hidden内容会被修剪…...
)
Three.js 入门(辅助、位移、父子关系、缩放旋转、响应式布局)
本篇主要学习内容 : 三维坐标系与辅助坐标系物体位移与父子元素物体的缩放与物体的旋转设置响应式画布与全屏控制 点赞 关注 收藏 学会了 本文使用 Three.js 的版本:171 基于 Vue3vite开发调试 1.三维坐标系与辅助坐标系 1.1) 导入three和轨道控制器 // 导入…...

python算法-用递归打印数字3的幂--Day017
文章目录 前言采用创新方式,精选趣味、实用性强的例子,从不同难度、不同算法、不同类型和不同数据结构进行总结,全面提升算法能力。例1.用递归打印数字例2.相对排名 总结 前言 采用创新方式,精选趣味、实用性强的例子,…...

Selenium 与 Coze 集成
涵盖两者的基本概念、集成步骤、代码示例以及相关注意事项。 基本概念 Selenium:是一个用于自动化浏览器操作的工具集,支持多种浏览器(如 Chrome、Firefox 等),能够模拟用户在浏览器中的各种操作,如点击、输入文本、选择下拉框等,常用于 Web 应用的自动化测试。Coze:它…...

AWS CLI将读取器实例添加到Amazon Aurora集群
Amazon Aurora是AWS提供的一种兼容MySQL和PostgreSQL的关系数据库服务。Aurora集群由一个写入器实例和多个读取器实例组成,可以提供高可用性、高性能和可扩展性。在本文中,我们将介绍如何使用AWS命令行界面(CLI)将读取器实例添加到现有的Aurora集群中。 © ivwdcwso (ID: u…...

NTS库学习,找bug中......
基础知识 Coordinate: 表示一个二维坐标点,包括 X 和 Y 坐标值。 CoordinateSequence: 由一系列 Coordinate 对象组成的序列,可以表示线、多边形等几何对象的顶点。 CoordinateFilter: 用于对几何对象的坐标进行过滤或修改的接口。 Geometry: 表示一个几…...

五十天精通硬件设计第40天-硬件测试流程
目录 一、硬件测试流程概述 二、详细测试流程 1. 需求分析与测试计划 2. 测试环境搭建 3. 测试执行 3.1 基本功能测试 3.2 性能测试 3.3 环境与可靠性测试 3.4 安全与合规性测试 4. 问题分析与调试 5. 回归测试与报告输出 三、关键注意事项 四、常见问题与解决 五…...

R语言安装教程(附安装包)R语言4.3.2版本安装教程
文章目录 前言一、安装包下载二、R-4.3.2安装步骤三、rtools43安装步骤四、RStudio安装步骤 前言 本教程将详细、全面地为你介绍在 Windows 系统下安装 R 语言 4.3.2 的具体步骤。无论你是初涉数据领域的新手,还是希望更新知识体系的专业人士,只要按照本…...

数据库 安装initializing database不通过
出现一下情况时: 处理方法: 将自己的电脑名称 中文改成英文 即可通过...

自动驾驶两个传感器之间的坐标系转换
有两种方式可以实现两个坐标系的转换。 车身坐标系下一个点p_car,需要转换到相机坐标系下,旋转矩阵R_car2Cam,平移矩阵T_car2Cam。点p_car在相机坐标系下记p_cam. 方法1:先旋转再平移 p_cam T_car2Cam * p_car T_car2Cam 需要注…...
)
信号——进程间通信(20250225)
1. 信号 管道:进程间数据通信(同步通信) 信号:进程间通信,用来发送通知(异步通信,中断) 1)同步通信:发送端和接收端,使用同一时钟通信 异步通信:发送端和接收端使用不同时钟通信 …...
transformer架构嵌入层位置编码之动态NTK-aware位置编码
前文,我们已经构建了一个小型的字符级语言模型,是在transformer架构基础上实现的最基本的模型,我们肯定是希望对该模型进行改进和完善的。所以我们的另外一篇文章也从数据预处理、模型架构、训练策略、评估方法、代码结构、错误处理、性能优化等多个方面提出具体的改进点,但…...

东信营销科技巨额补贴仍由盈转亏:毛利率大幅下滑,现金流告急
《港湾商业观察》施子夫 近期,东信营销科技有限公司(以下简称,东信营销科技)递表港交所,联席保荐机构为海通国际和中银国际。 东信营销科技的国内运营主体为深圳市东信时代信息技术有限公司。尽管期内收入规模有所提…...

[电感、磁珠、0欧姆电阻]的区别与应用特性
1. 电感(Inductor) 基础特性: 储能元件:通过磁场存储能量,阻碍电流突变()。 核心参数:电感值(L)、额定电流、直流电阻(DCR)、自谐振频率(SRF)。 频率特性:感抗 ,(通直流、阻交流),低频时阻抗低,高频时阻抗高(但受SRF限制)。 电路符号及实物:多为绕线结…...

车载诊断架构 --- LIN节点路由转发注意事项
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 简单,单纯,喜欢独处,独来独往,不易合同频过着接地气的生活,除了生存温饱问题之外,没有什么过多的欲望,表面看起来很高冷,内心热情,如果你身…...

前端 AJAX 二、AJAX使用
环境准备: 使用AJAX技术我们需要用到HTML/CSS/JS/jQuery/JavaWeb相关知识,原生的JS也可以进行AJAX的操作,但是相对比较繁琐也没有必要,故此我们使用jQuery封装后的AJAX技术来进行学习; 创建AJAX请求 $.ajax({url : "ajax/getName?id"id,// ajax请求的…...

[实战] STM32H743 SAI双缓冲DMA实现零延迟音频流处理
1. 为什么需要零延迟音频流处理? 在嵌入式音频开发中,实时性往往是决定系统成败的关键因素。想象一下,当你对着智能音箱说"播放音乐"时,如果系统需要等待几百毫秒才有反应,这种体验会让人抓狂。同样在专业音…...

PHP中json浮点精度的解决方法
之前开发的接口需要用到json加签,有一次对接JAVA时,签名怎么都过不了,仔细对比了字符串,发现是PHP进行json_encode时,会将浮点型所有无意义的0给去掉(echo和var_dump也会),而JAVA那边没有。遂在文档中写下&…...
机器学习调参避坑指南:caret包trainControl函数这些参数你设置对了吗?
机器学习调参避坑指南:caret包trainControl函数这些参数你设置对了吗? 在机器学习项目中,调参往往是决定模型性能的关键环节。R语言中的caret包因其统一简洁的接口设计,成为许多数据科学家的首选工具。而trainControl函数作为care…...

Mediapipe与Unity3D实时手部动作捕捉与驱动全流程解析
1. 从摄像头到虚拟手:Mediapipe基础配置 Mediapipe作为谷歌开源的跨平台多媒体机器学习框架,最让我惊艳的就是它的手部关键点检测能力。记得第一次跑通demo时,看着屏幕上实时追踪的21个手部关节点,那种"未来已来"的震撼…...

第9章 函数-9.7 函数嵌套
Python支持函数嵌套,函数嵌套指的是在当前函数内再创建另外一个函数。函数在进行嵌套之后,需要注意4点,一是内层函数可以访问外层函数中的所有变量,但不能修改外层函数中该变量的值;二是外层函数可以访问内层函数中的全…...

全栈测试工程师:未来5年必备技能树
数字化转型下的测试角色重构在AI测试工具普及率突破60%的2026年,软件测试领域正经历从单一功能验证向全生命周期质量保障的转型。全栈测试工程师作为质量保障体系的核心枢纽,需构建技术深度与业务广度双轮驱动的能力模型。本文将系统解构未来五年测试从业…...
)
你的AIAgent真的可靠吗?用SITS2026认证的8项压力测试指标立刻自检(附开源验证工具链)
第一章:SITS2026总结:构建可靠AIAgent的关键要素 2026奇点智能技术大会(https://ml-summit.org) 构建高可靠性AI Agent并非仅依赖大模型能力的堆叠,而是系统性工程实践的结果。SITS2026会议中多位工业界与学术界专家共同指出:可观…...

DeepSeek-OCR-2参数详解:DeepEncoder V2架构与vLLM推理优化实践
DeepSeek-OCR-2参数详解:DeepEncoder V2架构与vLLM推理优化实践 1. 引言:重新定义OCR的智能视觉理解 如果你还在用传统的OCR工具,每次处理复杂文档时都要忍受识别不准、版面混乱的烦恼,那么今天介绍的DeepSeek-OCR-2可能会彻底改…...

Dify+OpenAI+XInference三件套配置指南:从模型部署到API调用全流程
DifyOpenAIXInference三件套配置指南:从模型部署到API调用全流程 在AI应用开发领域,如何高效整合多个模型服务并构建稳定可靠的工作流,一直是开发者面临的挑战。本文将深入探讨基于Dify平台,结合OpenAI的通用语言模型与XInference…...

终极指南:如何使用applera1n工具在iOS 15-16设备上绕过激活锁
终极指南:如何使用applera1n工具在iOS 15-16设备上绕过激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 如果你曾经遇到过iPhone或iPad被原主人的Apple ID锁定的情况,那么…...