kafka数据拉取和发送
文章目录
- 一、原生 KafkaConsumer
- 1、pom文件引入kafka
- 2、拉取数据
- 3、发送数据
- 二、在spring boot中使用@KafkaListener
- 1、添加依赖
- 2、application.yml
- 3、消息拉取:consumer
- 4、自定义ListenerContainerFactory
- 5、消息发送:producer
- 6、kafka通过clientId鉴权时的鉴权失败问题
一、原生 KafkaConsumer
1、pom文件引入kafka
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.12</artifactId>
</dependency>
2、拉取数据
简单说只要以下几个步骤:
1、获取kafka地址,并设置Properties
2、获取consumer:KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
3、订阅topic:consumer.subscribe(topic);
4、拉取数据:consumer.poll()
5、遍历数据
6、示例:
package com.yogi.test.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.springframework.beans.factory.InitializingBean;
import java.util.Properties;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.CreateTopicsResult;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.Node;
import org.apache.kafka.common.config.SaslConfigs;
import org.apache.kafka.common.serialization.StringSerializer;@Component
public class TestMsgConsumer implements InitializingBean {@Value("${test.kafka.address:127.0.0.1:9092}")private String kafkaAddress;@Value("${test.kafka.msg.topic:topic_test_1,topic_test_2}")private String msgTopic;@Value("${test.consumer.name:yogima}")private String consumerGroupId;/*** 消费开关: true-消费,false-暂停消费* 在服务正常停止时用于停止继续消费数据,将缓存中的数据发送完即可*/private Boolean consumeSwitch = true;public void consumerMessage(List<String> topic, String groupId) {LOGGER.info("consumer topic list1:{}",topic.toString());Properties props = new Properties();/*** 指定一组host:port对,用于创建与Kafka broker服务器的Socket连接,可以指定多组,使用逗号分隔,对于多broker集群,只需配置* 部分broker地址即可,consumer启动后可以通过这些机器找到完整的broker列表*/LOGGER.info("test.kafka.address:{}",kafkaAddress);props.put("bootstrap.servers", kafkaAddress);/*** 指定group名字,能唯一标识一个consumer group,如果不显示指定group.id会抛出InvalidGroupIdException异常,通常为group.id* 设置一个有业务意义的名字即可*/props.put("group.id", groupId);/*** 自动提交位移*/props.put("enable.auto.commit", Boolean.TRUE);/*** 位移提交超时时间*/props.put("auto.commit.interval.ms", "1000");/*** 从最早的消息开始消费* 1,earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费* 2,latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据*/props.put("auto.offset.reset", "latest");/*** 指定消费解序列化操作。consumer从broker端获取的任何消息都是字节数组的格式,因此需要指定解序列化操作才能还原为原本对象,* Kafka对绝大部分初始类型提供了解序列化器,consumer支持自定义解序列化器org.apache.kafka.common.serialization.Deserializer* org.apache.kafka.common.serialization.ByteArrayDeserializer* StringDeserializer*/props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");/*** 对消息体进行解序列化,与key解序列化类似*/props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");//一次从kafka中poll出来的数据条数,max.poll.records条数据需要在在session.timeout.ms这个时间内处理完props.put("max.poll.records", "500");//fetch.message.max.bytes (默认 1MB) – 消费者能读取的最大消息。这个值应该大于或等于message.max.bytes。props.put("fetch.message.max.bytes", "300000000");KafkaConsumer<String, String> consumer;try{/*** 通过Properties实例对象构建KafkaConsumer对象,可同时指定key、value序列化器*/LOGGER.info("start set consumer,props:{}",props.toString());consumer = new KafkaConsumer<>(props);LOGGER.info("set consumer finished");/*** 订阅consumer group需要消费的topic列表*/LOGGER.info("consumer topic list:{}",topic.toString());consumer.subscribe(topic);}catch (Exception e){LOGGER.info("consumer subscribe failed,msg:{},cause:{},e:{}",e.getMessage(),e.getCause(),e);return;}/*** 并行从订阅topic获取多个分区消息,为此新版本consumer的poll方法使用类似Linux的 selec I/O机制,* 所有相关的事件都发生在一个事件循环中,这样consuner端只使用一个线程就能完成所有类型I/o操作*/try {while (true) {if (!consumeSwitch) {try {Thread.sleep(30000);} catch (InterruptedException e) {LOGGER.error("err msg:" + e.getMessage());}}/*** 指定超时时间,通常情况下consumer拿到了足够多的可用数据,会立即从该方法返回,但若当前没有足够多数据* consumer会处于阻塞状态,但当到达设定的超时时间,则无论数据是否足够都为立即返回*/ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1L));/*** poll调用返回ConsumerRecord类分装的Kafka消息,之后会根据自己业务实现信息处理,对于consumer而言poll方法* 返回即认为consumer成功消费了消息*/for (ConsumerRecord<String, String> record : records) {LOGGER.debug("offset = {}, key = {}, value = {}"相关文章:

kafka数据拉取和发送
文章目录 一、原生 KafkaConsumer1、pom文件引入kafka2、拉取数据3、发送数据二、在spring boot中使用@KafkaListener1、添加依赖2、application.yml3、消息拉取:consumer4、自定义ListenerContainerFactory5、消息发送:producer6、kafka通过clientId鉴权时的鉴权失败问题一、…...
)
LLM全栈框架完整分类清单(预训练+微调+工具链)
一、预训练框架 1. 大规模分布式训练框架 框架名称核心能力GitHub地址Megatron-LM3D并行训练、FlashAttention支持、Transformer架构优化(NVIDIA生态)NVIDIA/Megatron-LMDeepSpeedZeRO优化系列、3D并行、RLHF全流程支持(微软生态)…...

蓝桥杯备考:贪心算法之矩阵消除游戏
这道题是牛客上的一道题,它呢和我们之前的排座位游戏非常之相似,但是,排座位问题选择行和列是不会改变元素的值的,这道题呢每每选一行都会把这行或者这列清零,所以我们的策略就是先用二进制把选择所有行的情况全部枚举…...

【Matlab仿真】Matlab Function中如何使用静态变量?
背景 根据Simulink的运行机制,每个采样点会调用一次MATLAB Function的函数,两次调用之间,同一个变量的前次计算的终值如何传递到当前计算周期来?其实可以使用persistent变量实现函数退出和进入时内部变量值的保持。 persistent变…...

DeepSeek 提示词:高效的提示词设计
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

深入学习Java中的Lambda表达式
深入学习Java中的Lambda表达式 自Java 8引入以来,Lambda表达式彻底改变了Java的编程风格,让代码变得更加简洁、易读,尤其是在函数式编程的场景中。接下来,我们将深入探讨Lambda表达式的语法、原理以及实际应用,帮助你…...

1.2 AI 量化炒股的起源与发展
**定性价值**:AI量化炒股通过算法模型实现投资决策自动化,显著提升交易效率与风险控制能力,打破传统人工交易的主观性与延迟性,推动金融科技向智能化、数据驱动方向迭代,具有颠覆传统投资模式的战略意义。 **定量价值…...

计算机单位之详解——存储单位Byte 网络传输单位bps 视频码率单位bps
前言: 计算机里面单位有点复杂,容易混淆,很多时候混起来就容易概念不理解,包括一些小问题,比如说:为什么我买了1T硬盘,实际存在虚标。为什么所谓的千兆宽带,下载起来没有1G每秒&…...

IDEA关闭SpringBoot程序后仍然占用端口的排查与解决
IDEA关闭SpringBoot程序后仍然占用端口的排查与解决 问题描述 在使用 IntelliJ IDEA 开发 Spring Boot 应用时,有时即使关闭了应用,程序仍然占用端口(例如:4001 端口)。这会导致重新启动应用时出现端口被占用的错误&a…...

deepseek清华大学第二版 如何获取 DeepSeek如何赋能职场应用 PDF文档 电子档(附下载)
deepseek清华大学第二版 DeepSeek如何赋能职场 pdf文件完整版下载 https://pan.baidu.com/s/1aQcNS8UleMldcoH0Jc6C6A?pwd1234 提取码: 1234 或 https://pan.quark.cn/s/3ee62050a2ac...

【python随手记】——读取文本文件内容转换为json格式
文章目录 前言一、TXT文件转换为JSON数组1.txt文件内容2.python代码3.输出结果 二、TXT文件转换为JSON对象1.txt文件2.python代码3.输出结果 前言 场景:用于读取包含空格分隔数据的TXT文件,并将其转换为结构化JSON文件 一、TXT文件转换为JSON数组 1.tx…...

k8s集群3主5从高可用架构(kubeadm方式安装k8s)
关键步骤说明 环境准备阶段 系统更新:所有节点执行yum/apt update确保软件包最新时间同步:通过ntpdate time.windows.com或部署NTP服务器网络规划:明确划分Service网段(默认10.96.0.0/12)和Pod网段(如Flann…...

基于 sklearn 的均值偏移聚类算法的应用
基于 sklearn 的均值偏移聚类算法的应用 在机器学习和数据挖掘中,聚类算法是一类非常重要的无监督学习方法。它的目的是将数据集中的数据点划分为若干个类,使得同一类的样本点彼此相似,而不同类的样本点相互之间差异较大。均值偏移聚类&…...
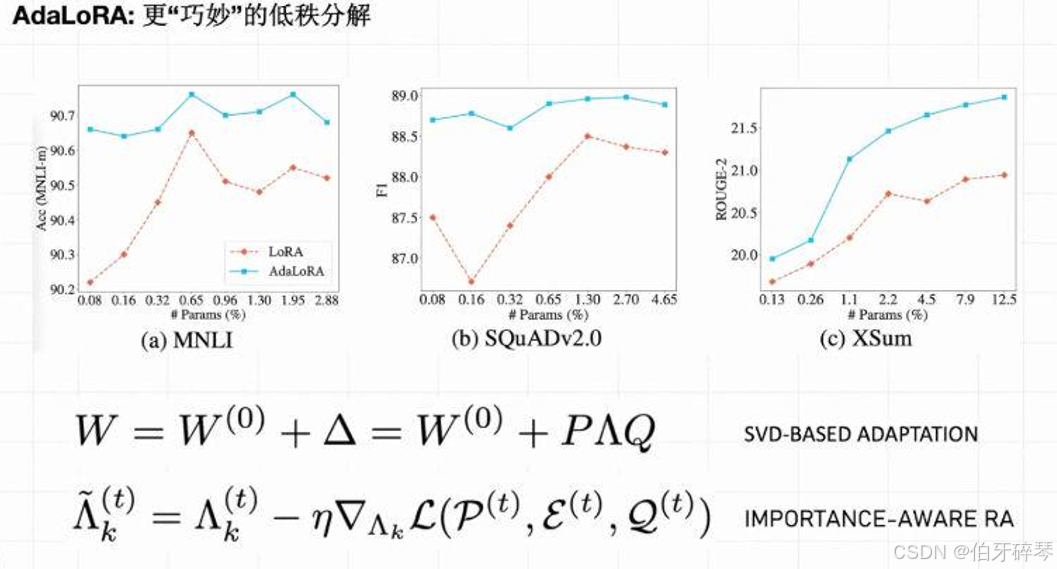
三、大模型微调的多种方法与应用场景
详解大模型微调的多种方法与应用场景 随着大模型的不断发展,如何有效地微调这些庞大的预训练模型以适应特定任务成为了研究和应用中的一个重要问题。大模型微调不仅能够提高任务性能,还能在不同的业务需求中提升模型的适应性。在本文中,我们…...

第2课 树莓派镜像的烧录
树莓派的系统通常是安装在SD卡上的。SD卡作为启动设备,负责启动树莓派并加载操作系统。这种设计使得树莓派具有便携性和灵活性,用户可以通过更换SD卡来更换操作系统或恢复出厂设置。 烧录树莓派的镜像即是将树莓派镜像烧录到SD卡上,在此期间会格式化SD卡,如果SD卡…...

SQL之order by盲注
目录 一.order by盲注的原理 二.注入方式 a.布尔盲注 b.时间盲注 三.防御 一.order by盲注的原理 order by子句是用于按指定列排序查询结果,列名或列序号皆可。 order by 后面接的字段或者数字不一样,那么这个数据表的排序就会不同。 order by 盲…...

AI大模型(四)基于Deepseek本地部署实现模型定制与调教
AI大模型(四)基于Deepseek本地部署实现模型定制与调教 DeepSeek开源大模型在榜单上以黑马之姿横扫多项评测,其社区热度指数暴涨、一跃成为近期内影响力最高的话题,这个来自中国团队的模型向世界证明:让每个普通人都能…...

java后端开发day19--学生管理系统升级
(以下内容全部来自上述课程) 1.要求及思路 1.总体框架 2.注册 3.登录 4.忘记密码 2.代码 1.javabean public class User1 {private String username;private String password;private String personID;private String phoneNumber;public User1() {…...

MFC文件和注册表的操作
MFC文件和注册表的操作 日志、操作配置文件、ini、注册表、音视频的文件存储 Linux下一切皆文件 C/C操作文件 const char* 与 char* const const char* 常量指针,表示指向的内容为常量。指针可以指向其他变量,但是内容不能再变了 char szName[6]&qu…...

vscode如何使用鼠标滚轮调整字体大小
1.打开设置 2.搜索Font Ligatures 3.编辑配置文件 4.修改代码并保存 修改前 修改后 在最后一行添加:“editor.mouseWheelZoom”: true 记得在上一行最后,加上英文版的“,”逗号 5.配置成功,再次按Ctrl鼠标滚轮便可以缩放了。...

Wireshark的抓包和分析,从零基础到精通,收藏这篇就够了!
各位网络安全的小伙伴们,还在对着枯燥的课本和晦涩的官方文档头疼吗?今天,就让我这位在网络安全圈摸爬滚打多年的老司机,带你玩转Wireshark,保证你看完这篇,抓包分析技能直接起飞! Wireshark&am…...

Z2kDH - Writeup by AI
Z2kDH - Writeup by AI 题目描述 这是一个基于离散对数的密钥交换协议,类似于 Diffie-Hellman。题目给出了以下信息: 模数: modulus 1 << 258 (即 2^258)生成器: g 5Alice 的公钥: 99edb8ed8892c664350acbd5d35346b9b77dedfae758190cd0544f2ea73…...

Llama-3.2-3B新手入门:用Ollama一键搭建你的本地AI助手
Llama-3.2-3B新手入门:用Ollama一键搭建你的本地AI助手 1. 为什么选择Llama-3.2-3B和Ollama组合 1.1 轻量级但实用的AI助手 Llama-3.2-3B是Meta最新推出的30亿参数语言模型,专为日常对话和多语言理解优化。相比其他同规模模型,它有三个突出…...

dialog-polyfill 实战教程:5个真实场景教你构建现代Web弹窗
dialog-polyfill 实战教程:5个真实场景教你构建现代Web弹窗 【免费下载链接】dialog-polyfill Polyfill for the HTML dialog element 项目地址: https://gitcode.com/gh_mirrors/di/dialog-polyfill dialog-polyfill是一款轻量级的HTML弹窗元素兼容工具&…...

代码随想录算法训练营 Day32 | 动态规划 part05
52. 携带研究材料(第七期模拟笔试) 题目描述 小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。他需要带一些研究材料,但是他的行李箱空间有限。这些研究材料包括实验设备、文献资料和实…...

革命性智能交互助手:Live2D AI如何重塑用户体验边界
革命性智能交互助手:Live2D AI如何重塑用户体验边界 【免费下载链接】live2d_ai 基于live2d.js实现的动画小人ai,拥有聊天功能,还有图片识别功能,可以嵌入到网页里 项目地址: https://gitcode.com/gh_mirrors/li/live2d_ai …...

ConvNeXt 系列改进:ConvNeXt 添加 MetaFormer 风格池化层,简化 Block 并保持性能
2026 年的计算机视觉领域呈现出一种有趣的“返璞归真”趋势——在 Vision Transformer 狂飙数年之后,卷积神经网络正以全新的姿态强势回归。根据 Meta AI 近年来发布的官方论文数据,ConvNeXt 已经证明了一个关键事实:不需要 Attention 机制,纯 CNN 依然可以达到甚至超越同级…...

革命性监控工具ebpf_exporter:深度解析内核性能的终极指南
革命性监控工具ebpf_exporter:深度解析内核性能的终极指南 【免费下载链接】ebpf_exporter Prometheus exporter for custom eBPF metrics 项目地址: https://gitcode.com/gh_mirrors/eb/ebpf_exporter ebpf_exporter是一款基于eBPF技术的Prometheus exporte…...

Win10+VS2019配置vcpkg:从安装到项目集成的完整指南
1. 初识vcpkg:C开发者的效率神器 第一次接触vcpkg是在2018年接手一个跨平台C项目时,当时被各种第三方库的编译依赖折磨得够呛。vcpkg就像黑暗中的一束光,彻底改变了我的开发体验。简单来说,vcpkg是微软开源的C包管理工具…...

爱毕业aibiye采用前沿的深度学习模型,对重复率超过30%的论文内容进行智能重组,确保改写后的文本符合原创性要求。
嘿,大家好!我是AI菌。今天咱们来聊聊一个让无数学生头疼的问题:论文重复率飙到30%以上怎么办?别慌,我这就分享5个实用降重技巧,帮你一次搞定,轻松压到合格线以下。这些方法都是我亲身试验过的&a…...