深入理解指针2
深入理解指针2
数组名的理解
数组名就是首元素的地址
int arr[]={1,3,2};
printf("%p\n",arr);
printf("%p\n",&arr[0]);
但是有两种情况除外,
1.sizeof(数组名),sizeof操作符统计的是整个数组的大小,并不是第一个元素的大小, 单位是字节
2.&数组名,它取的整个数组的地址,整个数组的地址其实就是首元素的地址,数组地址+1,跳过的是整个数组
除此之外,你遇到的任何数组名都表示首元素的地址
int arr[]={1,2,34};
printf("%d",sizeof(arr));
//如果是一维数组,打印数组的地址其实就是首元素的地址;
int arr[]={1,3,2};
printf("%p\n",arr);
printf("%p\n",&arr[0]);
printf("%p\n",&arr);//三者打印结果一样printf("%p\n",arr+1);//int类型的指针+1,跳过4个字节
printf("%p\n",&arr[0]+1);//跳过4个字节
printf("%p\n",&arr+1);//并不是跳过4个字节,跳过整个数组
//如果是二维数组,打印出来的地址是第一行的地址,也就是第一个一维数组的地址,而第一个一维数组的地址也就是首元素的地址
int main()
{int stp[2][3] = { {1,2,3},{4,5,6} };printf("%p\n", stp);printf("%p\n",&stp[0]);printf("%p\n",&stp);//三者打印结果一样printf("%p\n", &stp[0] + 1); printf("%p\n", stp+1);printf("%p\n", &stp + 1);return 0;}
指针访问数组
代码示例1
int main()
{int arr[10]={0};int*p=arr;int sz=sizeof(arr)/sizeof(arr[0]);int i=0;for(i=0;i<sz;i++){scanf("%d",p+i);}//循环结束后,p里面存的还是arr,i已经变成10了for(i=0;i<sz;i++){printf("%d ",arr[i]);//printf("%d ",*(p+i));//这样写也是可以的}
return 0;
}
代码示例2
int main()
{int arr[10]={0};int*p=arr;int sz=sizeof(arr)/sizeof(arr[0]);int i=0;for(i=0;i<sz;i++){scanf("%d",p++);//通过指针加减也就是指针偏移的方式,让指针移动}//循环结束后,指针p指向下标为10的元素的地址了,i已经变成10了//p++ 的方式会使 p 的值发生改变,p + i 的方式本身不会改变指针 p 的值,所以这里p要重新赋值p=arr;for(i=0;i<sz;i++){printf("%d ",*(p+i));}
return 0;
}
为了更透彻的理解指针,再举一个例子
//打印结果都是一样的
int main()
{int arr[10]={1,2,3,4,5,6,7,8,9};int*p=arr;int sz=sizeof(arr)/sizeof(arr[0]);int i=0;for(i=0;i<sz;i++){printf("%d ",arr[i]);printf("%d ",*(p+i));printf("%d ",*(arr+i));//因为p=arr,p里面存放的就是arr的地址,所以还可以写成下面的样子printf("%d ",p[i]);printf("%d ",i[arr]);arr[i]=*(arr+i)//arr[i]这样的写法只是一种形式,即使这样写,编译器处理的时候也会转成后面的写法,转换成指针偏移的方式p[i]=*(p+i);//同理//我们知道加法是支持交换律的,所以下面的写法也是对的,不管怎么写,编译器最终都会转成指针偏移arr[i]=*(arr+i)=*(i+arr)=i[arr];}
return 0;
}p+i到底是不是下标为i的地址呢?我们可以验证一下
int main()
{int arr[10]={1,2,3,4,5,6,7,8,9};int*p=arr;int sz=sizeof(arr)/sizeof(arr[0]);int i=0;for(i=0;i<sz;i++){printf("%p========%p\n",p+i,&arr[i]);}
return 0;
}
一维数组传参的本质
想一下下面的代码为什么会出错?
void print(int arr[])//形参写成数组的形式,一维数组传参,形参的大小可以省略
{int i=0;
int sz=sizeof(arr)/sizeof(arr[0]);//其实是得不到数组元素的个数的,统计的其实是指针变量的大小,也就是地址的大小
for(i=0;i<sz;i++)
{printf("%d ",arr[i]);
}}int main()
{int arr[]={1,2,3,4,5};print(arr);//print函数负责把数组里的元素都打印出来,传给形参的其实是地址return 0;}
因为数组传参的本质其实是把数组的首元素的地址传给形参,所以形参接收到的其实是地址,也就是指针,所以统计 sizeof (arr)其实是统计的地址大小,如果平台是32位的,那么它的大小就是4个字节,而sizeof(arr[0])的大小是4 ,所以sz=4/4=1,所以打印在屏幕上只打印了1一个数字
//那既然函数内部不能统计数组元素的个数,只能在main函数内部统计数组元素个数我们就在main函数内部计算,然后作为实参传给形参。
//因为实参传给形参的数组名其实是首元素地址,那么用sizeof统计的其实是指针变量的大小void print(int*arr,int sz)//形参写成指针的形式
{int i=0;for(i=0;i<sz;i++)
{printf("%d ",arr[i]);
}}int main()
{int arr[]={1,2,3,4,5};int sz=sizeof(arr)/sizeof(arr[0]);print(arr,sz);//print函数负责把数组里的元素都打印出来,传给形参的其实是地址return 0;}
//我们用下面的代码验证下就知道了,数组名其实就是地址
void print(int arr[],int sz)
{
printf("%d\n",sizeof(arr));
}void print(int*arr,int sz)
{
printf("%d\n",sizeof(arr));
}int main()
{int arr[]={1,2,3,4,5};int sz=sizeof(arr)/sizeof(arr[0]);print1(arr,sz);print2(arr,sz);
return 0;
}
总结:
数组传参,无论形参是写成数组的形式还是指针的形式,本质上都是一样的,只是形式不同而已。
编译器最终都会转成指针的方式处理。
冒泡排序
方法1
void double_paixu(int * arr,int sz)
{int i = 0;//排序第一步根据元素个数确定排序的轮数for (i=0;i<sz-1;i++)//i的最大取值为3{//排序第二步,在每一轮排序中确定要比较的元素对数,随着轮数的增加,要排序的元素对数依次递减,所以比较的次数//根i有关系,因为变量i代表的是比较的轮数int j = 0;//j表示元素的下标,又表示元素比较的对数//内层for循环用于比较元素大小和交换,如果是降序,发现前一个元素小于后一个元素,就交换for (j = 0; j <sz-1-i ;j++)//{if (arr[j] < arr[j + 1])//一共有5个元素,但是j最大的取值为3,当j=3时,arr[3]和arr[4]进行比较//如果j=4,那就数组越界了,因为arr[4]和arr[5]进行比较,但是数组只有5个元素{int d = 0;d = arr[j];arr[j] = arr[j + 1];arr[j + 1] = d;}}}
}
int main()
{int arr[] = { 12,21,2,45,1};int sz = sizeof(arr) / sizeof(arr[0]);double_paixu(arr,sz);int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}
//优化版:如果要排序的序列本身是有序的,那么第一轮比较后发现没有交换,就证明是有序的,就不用进入下一轮的比较了
void double_arr(int* arr, int sz)
{int i = 0;for (i = 0; i < sz - 1; i++)//i的最大值为2{int j = 0;int flag = 1;//假设是有序的//如果是降序的话,就是找出最小值,如果a<b就交换for (j = 0; j < sz - 1 - i; j++)//j的最大值为2a{if (arr[j] > arr[j + 1]){int temp = 0;temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;//如果进来了,就说明是无序的flag = 0;}}//如果第一轮循环结束后,flag还是等于1,说明是有序的,就不用进入下一轮了if (flag == 1){break;}}//跳出循环来到这
}
void print(int* arr, int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}
}
int main()
{int arr[] = { 1,2,3,4};int sz = sizeof(arr) / sizeof(arr[0]);double_arr(arr, sz);print(arr, sz);return;
}方法2:用qsort函数的方法
二级指针
指针变量也是变量,既然是变量就要像内存申请一块空间,既然有自己的内存空间,那肯定就有地址,那么指针变量的地址存放在哪里呢?这就是二级指针
1.二级指针变量创建
int a=10;
int*p=&a;//p存放的是a的地址,*本身p是一个指针变量,int表示p指向一个整型数据,int*是变量p的类型,整型指针int* *pa=&p;//pa存放的是一级指针变量p的地址,*表示pa是一个指针变量,int*表示pa指向一个一级指针地址,int**是变量pa的类型,是一个二级指针int** *paa=&pa;//paa存放的是二级指针变量pa的地址,*表示paa是一个指针变量,int**表示paa指向一个二级指针地址,int***是变量paa的类型,是一个三级指针2.二级指针解引用
int main()
{int a = 10;int* p = &a;int* * pa = &p;int** * paa = &pa;printf("%d\n",*p);//p解引用后,打印a的值printf("%d\n",*pa)//pa解引用后,打印一级指针变量p的地址printf("%d\n",*paa);//paa解引用后,打印二级指针变量pa的地址//如果想打印a的值printf("%d\n",*p);//对一级指针变量解引用printf("%d\n",*(*pa));//对二级指针变量解引用printf("%d\n",*(*(*paa)))//对三级指针变量解引用printf("%d\n", **pa);//这样写也是对的,不带括号也是可以的printf("%d\n", ***paa);//对三级指针变量接return 0;
}总结:
1.二级指针变量没有什么牛逼的,和一级指针变量一样,都是指针变量,用来存放地址
2.二级指针变量用来存放一级指针变量的地址,同理,三级指针变量用来存放二级指针变量的地址
指针数组
数组有很多种类型,我们之前已经学过的有字符数组,整型数组,字符数组是用来存放字符串的,整型数组用来存放整型。
今天我们学习的指针数组,就是用来存放指针的,即地址。指针数组里的每一个元素都是指针。当然指针数组也有很多种类型,有int*,char*, long*, double*等等
//定义一个指针数组,然后把指针数组里每一个指针指向的元素打印出来
int main()
{int a=10;int b=20;int c=40;int*arr[]={&a,&b,&c};//arr[]表示数组,int*表示数组里的每一个元素都是int*类型的指针,即都是指向int类型的数据int i=0;for(i=0;i<3;i++){printf("%d ",*(arr[i]));}return 0;
}
//上面的代码没什么问题,但是我们很少这样去用,一般都指针数组模拟二维数组
int main()
{int arr1[]={1,2,3,4};int arr2[]={5,6,7,8};int arr3[]={9,10,11,12};int*p[]={arr1,arr2,arr3};int i=0;//外层循环控制指针数组arr1 arr2 arr3里的每一个元素for(i=0;i<3;i++){int j=0;//内层循环控制指针数组里的每一个指针指向的整型for(j=0;j<4;j++){printf("%d ",*(p[i]+j));//p[i]是数组p里下标为i的元素,当i=0时,拿到的是arr1,也就是数组名,然后再加j,就是让指针指向arr1数组里下标为j的地址,然后解引用,就拿到arr1数组里的元素// printf("%d ",p[i][j]);// printf("%d ",*(*(p+i)+j));//这几种写法都可以}printf("\n");}return 0;
}
相关文章:

深入理解指针2
深入理解指针2 数组名的理解 数组名就是首元素的地址 int arr[]{1,3,2}; printf("%p\n",arr); printf("%p\n",&arr[0]);但是有两种情况除外, 1.sizeof(数组名),sizeof操作符统计的是整个数组的大小,并不是第一个元素…...

【STL专题】优先级队列priority_queue的使用和模拟实现,巧妙利用仿函数解决优先级
欢迎来到 CILMY23的博客 🏆本篇主题为:优先级队列priority_queue的使用和模拟实现,巧妙利用仿函数解决优先级 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏: C | C语言 | 数据结构与算法 | Linux…...

CPU、SOC、MPU、MCU--详细分析四者的区别
一、CPU 与SOC的区别 1.CPU 对于电脑,我们经常提到,处理器,内存,显卡,硬盘四大部分可以组成一个基本的电脑。其中的处理器——Central Processing Unit(中央处理器)。CPU是一台计算机的运算核…...
)
Node.js 内置模块简介(带示例)
目录 1. fs(文件系统)模块 2. http 模块 3. path 模块 4. os 模块 5. events 模块 6. crypto 模块 1. fs(文件系统)模块 fs 模块提供了与文件系统进行交互的功能,包括文件的读写、删除、重命名等操作。它有同步…...

常见的“锁”有哪些?
悲观锁 悲观锁认为在并发环境中,数据随时可能被其他线程修改,因此在访问数据之前会先加锁,以防止其他线程对数据进行修改。常见的悲观锁实现有: 1.互斥锁 原理:互斥锁是一种最基本的锁类型,同一时间只允…...
 数据库系统的基本概念)
二级公共基础之数据库设计基础(一) 数据库系统的基本概念
目录 前言 一、数据库、数据管理系统和数据库系统 1.数据 2.数据库 3.数据库管理系统 1.数据库管理系统的定义 2.数据库管理系统的功能 1.数据定义功能 2.数据操作功能 3.数据存取控制 4.数据完整性管理 5.数据备份和恢复 6.并发控制 4.数…...

ollama无法通过IP:11434访问
目录 1.介绍 2.直接在ollama的当前命令窗口中修改(法1) 3.更改ollama配置文件(法2) 3.1更新配置 3.2重启服务 1.介绍 ollama下载后默认情况下都是直接在本地的11434端口中运行,绑定到127.0.0.1(localhost)&#x…...

简单易懂,解析Go语言中的struct结构体
目录 4. struct 结构体4.1 初始化4.2 内嵌字段4.3 可见性4.4 方法与函数4.4.1 区别4.4.2 闭包 4.5 Tag 字段标签4.5.1定义4.5.2 Tag规范4.5.3 Tag意义 4. struct 结构体 go的结构体类似于其他语言中的class,主要区别就是go的结构体没有继承这一概念,但可…...
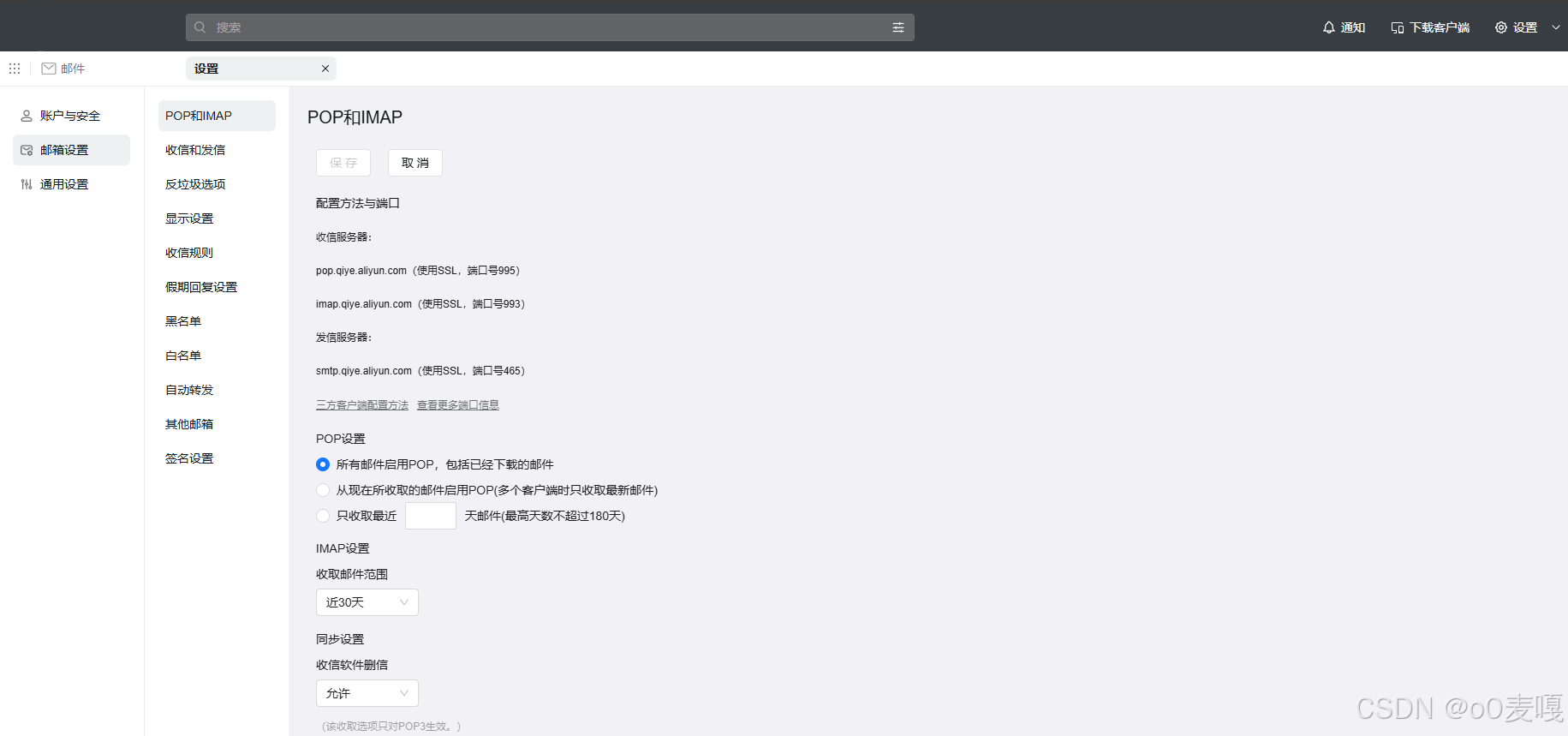
java给钉钉邮箱发送邮件
1.开通POP和IMAP 2.引入pom <dependency><groupId>javax.mail</groupId><artifactId>mail</artifactId><version>1.4.7</version> </dependency>3.逻辑 String host "smtp.qiye.aliyun.com"; String port "…...

C++和OpenGL实现3D游戏编程【连载23】——几何着色器和法线可视化
欢迎来到zhooyu的C++和OpenGL游戏专栏,专栏连载的所有精彩内容目录详见下边链接: 🔥C++和OpenGL实现3D游戏编程【总览】 1、本节实现的内容 上一节课,我们在Blend软件中导出经纬球模型时,遇到了经纬球法线导致我们在游戏中模型光照显示问题,我们在Blender软件中可以通过…...

大连本地知识库的搭建--数据收集与预处理_01
1.马蜂窝爬虫 编程语言:Python爬虫框架:Selenium(用于浏览器自动化)解析库:BeautifulSoup(用于解析HTML) 2.爬虫策略 目标网站:马蜂窝(https://www.mafengwo.cn/&…...

github 推送的常见问题以及解决
文章目录 git add 的时候问题1为什么会发生这种情况?Git 的警告含义如何解决?1. **保持 Git 的默认行为(推荐)**2. **禁用自动转换**3. **仅在工作目录中禁用转换**4. **统一使用 LF(跨平台开发推荐)** git…...

stm32单片机个人学习笔记16(SPI通信协议)
前言 本篇文章属于stm32单片机(以下简称单片机)的学习笔记,来源于B站教学视频。下面是这位up主的视频链接。本文为个人学习笔记,只能做参考,细节方面建议观看视频,肯定受益匪浅。 STM32入门教程-2023版 细…...

Linux | RHEL / CentOS 中 YUM history / downgrade 命令回滚操作
注:英文引文,机翻未校。 在 RHEL/CentOS 系统上使用 YUM history 命令回滚升级操作 作者: 2daygeek 译者: LCTT DarkSun 为服务器打补丁是 Linux 系统管理员的一项重要任务,为的是让系统更加稳定,性能更加…...

BGP状态和机制
BGP邻居优化 为了增加稳定性,通常建议实验回环口来建立邻居。更新源:建立邻居和邻居所学习到的路由的下一跳。多跳:EBGP邻居建立默认选哟直连,因为TTL=1,如果非直连,必须修改TTL。命令备注peer 2.2.2.2 connect-interface lo1配置更新源peer 2.2.2.2 ebgp-max-hop 2配置T…...

温湿度监控设备融入智慧物联网
当医院的温湿度监控设备融入智慧物联网,将会带来许多新的体验,可以帮助医院温湿度监控设备智能化管理,实现设备之间的互联互通,方便医院对温湿度数据进行统一管理和分析。 添加智慧物联网技术,实现对医院温湿度的实时…...

smolagents学习笔记系列(五)Tools-in-depth-guide
这篇文章锁定官网教程中的 Tools-in-depth-guide 章节,主要介绍了如何详细构造自己的Tools,在之前的博文 smolagents学习笔记系列(二)Agents - Guided tour 中我初步介绍了下如何将一个函数或一个类声明成 smolagents 的工具&…...

前端面试真题 2025最新版
文章目录 写在前文CSS怪异盒模型JS闭包闭包的形成闭包注意点 CSS选择器及优先级优先级 说说flex布局及相关属性Flex 容器相关属性:Flex 项目相关属性 响应式布局如何实现是否用过tailwindcss,有哪些好处好处缺点 说说对象的 prototype属性及原型说说 pro…...
面试八股文--数据库基础知识总结(1)
1、数据库的定义 数据库(DataBase,DB)简单来说就是数据的集合数据库管理系统(Database Management System,DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。数据库系统…...

10. docker nginx官方镜像使用方法
本文介绍docker nginx官方镜像使用方法,因为第一次用,在加上对docker也不是很熟,中间踩了一些坑,为了避免下一次用又踩坑,因此记录如下,也希望能够帮到其它小伙伴。 官方镜像页面:https://hub.d…...

macos简单配置openclaw焦
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-template/bl…...

KirikiriTools:解锁视觉小说游戏资源的三大神技
KirikiriTools:解锁视觉小说游戏资源的三大神技 【免费下载链接】KirikiriTools Tools for the Kirikiri visual novel engine 项目地址: https://gitcode.com/gh_mirrors/ki/KirikiriTools KirikiriTools是一款专为Kirikiri视觉小说引擎设计的开源工具集&am…...
的完整保姆级流程)
告别零碎教程!Winform桌面程序连接BLE设备(如智能手环)的完整保姆级流程
告别零碎教程!Winform桌面程序连接BLE设备(如智能手环)的完整保姆级流程 在物联网和智能穿戴设备蓬勃发展的今天,BLE(蓝牙低功耗)技术因其低功耗、低成本的特点,成为连接智能手环、健康监测设备…...
艺)
大卫小东(Sheldon)艺
Issue 概述 先来看看提交这个 Issue 的作者是为什么想到这个点子的,以及他初步的核心设计概念。?? 本 PR 实现了 Apache Gravitino 与 SeaTunnel 的集成,将其作为非关系型连接器的外部元数据服务。通过 Gravitino 的 REST API 自动获取表结构和元数据&…...

**图神经网络实战:用PyTorch Geometric构建社交关系预测模型**在当前人工智能飞速发展的背景下,**图神经网络(GN
图神经网络实战:用PyTorch Geometric构建社交关系预测模型 在当前人工智能飞速发展的背景下,图神经网络(GNN) 已成为处理复杂结构化数据的利器,尤其在社交网络分析、推荐系统和知识图谱等领域表现卓越。本文将带你从零…...

网盘下载太慢?这款直链助手让你告别龟速时代
网盘下载太慢?这款直链助手让你告别龟速时代 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

开箱即用的语音合成方案:CosyVoice-300M Lite镜像深度体验
开箱即用的语音合成方案:CosyVoice-300M Lite镜像深度体验 1. 引言 1.1 语音合成的现代需求 在智能客服、有声读物、语音助手等应用场景中,高质量的文本转语音(TTS)能力已成为提升用户体验的关键环节。然而,传统TTS…...

从噪声到精准:DiffDet4SAR如何用扩散模型革新SAR飞机检测
1. 为什么SAR飞机检测这么难? 第一次接触SAR图像的朋友可能会觉得奇怪:这黑乎乎一片带白点的图像,怎么找飞机?其实这正是SAR(合成孔径雷达)成像的特点——它不像光学照片那样直观。SAR通过发射微波并接收回…...
)
从Excel到向量数据库:数据工程师必知的5种数据存储格式选型指南(附避坑建议)
从Excel到向量数据库:数据工程师必知的5种数据存储格式选型指南(附避坑建议) 在数据驱动的时代,存储方案的选择直接影响着数据处理效率、系统性能和开发成本。面对CSV文件、关系型数据库、NoSQL、向量数据库和图数据库这五大主流存…...

彻底搞懂Type Challenges中的Chunk类型:从入门到精通
彻底搞懂Type Challenges中的Chunk类型:从入门到精通 【免费下载链接】type-challenges Collection of TypeScript type challenges with online judge 项目地址: https://gitcode.com/GitHub_Trending/ty/type-challenges Type Challenges是一个专注于TypeS…...