数据存储:一文掌握存储数据到ElasticSearch详解
文章目录
- 一、Elasticsearch简介
- 二、Python与Elasticsearch交互
- 2.1 安装必要的库
- 2.2 连接到Elasticsearch服务器
- 三、数据准备
- 四、创建索引(可选)
- 五、存储数据
- 5.1 单个文档索引
- 5.2 批量索引
- 六、查询数据
- 七、更新和删除数据
- 7.1 更新文档
- 7.2 删除文档
- 八、高级功能
- 8.1 使用别名
- 8.2 设置副本和分片
- 8.3 使用Ingest Pipelines
- 九、错误处理与调试
- 十、注意事项
- 十一、总结
要掌握使用Python将数据存储到Elasticsearch,需要了解Elasticsearch的基本概念、Python与Elasticsearch的交互方式以及实际操作步骤。以下是详细的指南:
一、Elasticsearch简介
Elasticsearch 是一个基于Lucene的分布式搜索和分析引擎,具有高扩展性、实时性和强大的全文搜索能力。它广泛应用于日志分析、全文搜索、数据可视化等领域。
二、Python与Elasticsearch交互
2.1 安装必要的库
使用pip安装elasticsearch客户端库:pip install elasticsearch
2.2 连接到Elasticsearch服务器
首先,导入Elasticsearch类并创建一个连接实例。
from elasticsearch import Elasticsearch# 连接到本地Elasticsearch服务器
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])# 检查连接是否成功
if es.ping():print("连接成功")
else:print("无法连接到Elasticsearch")
如果Elasticsearch运行在远程服务器或需要认证,可以这样连接:
es = Elasticsearch(['https://your-remote-host:9200'],http_auth=('username', 'password')
)
三、数据准备
Elasticsearch以JSON文档的形式存储数据。准备要存储的数据,例如:
article = {"title": "我的第一篇文章","content": "这是我的第一篇文章的内容。","author": "张三","date_published": "2024-04-27"
}
四、创建索引(可选)
索引是Elasticsearch中存储数据的地方。可以预先定义索引的映射(Mapping)来指定字段类型和其他属性。
mapping = {"mappings": {"properties": {"title": {"type": "text"},"date_published": {"type": "date", "format": "yyyy-MM-dd"}}}
}# 创建名为'blog'的索引
es.indices.create(index='blog', body=mapping)
如果索引已存在,可以先检查:python
if not es.indices.exists(index='blog'):es.indices.create(index='blog', body=mapping)
五、存储数据
5.1 单个文档索引
使用index方法将单个文档存储到索引中。
res = es.index(index='blog', body=article, id=1)
print(res['result']) # 输出 'created' 或 'updated'
5.2 批量索引
对于大量数据,使用bulk方法更高效。需要按照Elasticsearch的批量操作格式构建数据。
from elasticsearch.helpers import bulkactions = [{"_index": "blog","_id": 2,"_source": {"title": "第二篇文章","content": "这是第二篇文章的内容。","author": "李四","date_published": "2024-04-28"}},# 添加更多文档
]bulk(es, actions)
六、查询数据
- 简单查询
使用search方法执行查询。
query = {"query": {"match_all": {}}
}res = es.search(index='blog', body=query)
for hit in res['hits']['hits']:print(hit['_source'])
- 条件查询
例如,查询作者为“张三”的文章:
query = {"query": {"match": {"author": "张三"}}
}res = es.search(index='blog', body=query)
for hit in res['hits']['hits']:print(hit['_source'])
七、更新和删除数据
7.1 更新文档
使用update方法更新已有文档。
update_body = {"doc": {"title": "更新后的标题"}
}es.update(index='blog', id=1, body=update_body)
7.2 删除文档
使用delete方法删除指定文档。
es.delete(index='blog', id=1)
八、高级功能
8.1 使用别名
为索引创建别名,方便管理和切换。
es.indices.put_alias(index='blog_v1', name='blog')
8.2 设置副本和分片
在创建索引时设置副本数和分片数。
settings = {"settings": {"number_of_shards": 3,"number_of_replicas": 2}
}es.indices.create(index='blog', body=settings)
8.3 使用Ingest Pipelines
预处理数据,如日期解析、文本分析等。
pipeline = {"description": "解析日期字段","processors": [{"date": {"field": "date_published","target_field": "@timestamp","formats": ["yyyy-MM-dd"]}}]
}es.ingest.put_pipeline(id="date_pipeline", body=pipeline)# 使用pipeline索引文档
res = es.index(index='blog',body=article,pipeline="date_pipeline"
)
九、错误处理与调试
在实际应用中,处理可能出现的错误非常重要。例如,处理连接异常、索引失败等。
from elasticsearch import ElasticsearchExceptiontry:res = es.index(index='blog', body=article, id=1)print(res['result'])
except ElasticsearchException as e:print(f"发生错误: {e}")
十、注意事项
索引管理:在存储数据之前,不需要手动创建索引,Elasticsearch 会在第一次插入数据时自动创建索引。如果需要自定义索引的映射(mapping),可以在插入数据之前使用indices.create方法创建索引并指定映射。
数据类型:Elasticsearch 会根据插入的数据自动推断字段的数据类型,但为了避免类型问题,建议在创建索引时明确指定字段的映射。
错误处理:在实际应用中,需要对可能出现的网络错误、连接错误等进行适当的错误处理,以确保程序的健壮性。
十一、总结
通过以上步骤,你可以轻松地将数据存储到Elasticsearch中,并进行基本的CRUD操作。Elasticsearch是一个功能强大的搜索引擎,适用于各种场景,如日志分析、全文搜索、数据分析等。掌握这些基本操作后,你可以进一步探索Elasticsearch的高级功能,如聚合、复杂查询、索引管理等。
相关文章:

数据存储:一文掌握存储数据到ElasticSearch详解
文章目录 一、Elasticsearch简介二、Python与Elasticsearch交互2.1 安装必要的库2.2 连接到Elasticsearch服务器 三、数据准备四、创建索引(可选)五、存储数据5.1 单个文档索引5.2 批量索引 六、查询数据七、更新和删除数据7.1 更新文档7.2 删除文档 八、…...
)
Pytorch使用手册--将 PyTorch 模型导出为 ONNX(专题二十六)
注意 截至 PyTorch 2.1,ONNX 导出器有两个版本。 torch.onnx.dynamo_export 是最新的(仍处于测试阶段)导出器,基于 PyTorch 2.0 发布的 TorchDynamo 技术。 torch.onnx.export 基于 TorchScript 后端,自 PyTorch 1.2.0 起可用。 一、torch.onnx.dynamo_export使用 在 60 …...

Vue2+Element实现Excel文件上传下载预览
目录 一、需求背景 二、落地实现 1.文件上传 图片示例 HTML代码 业务代码 2.文件下载 图片示例 方式一:代码 方式二:代码 3.文件预览 图片示例 方式一:代码 方式二:代码 一、需求背景 在一个愉快的年后ÿ…...

物联网平台建设方案一
系统概述 构建物联网全域支撑服务能力,为实现学院涵盖物联网设备的全面感知、全域互联、全程智控、全域数字基底、全过程统筹管理奠定基础,为打造智能化提供坚实后台基石。 物联网平台向下接入各种传感器、终端和网关,向上通过开放的实施分…...

机器学习破局指南:零基础6个月系统训练计划
以下是为零基础学习者制定的「机器学习」系统学习计划(含学习路径资源推荐),分为6个阶段,建议学习周期4-6个月: 一、基础准备阶段(1-2周) 目标:掌握必要数学工具与编程基础 数学基础…...

mmdetection框架下使用yolov3训练Seaships数据集
之前复现的yolov3算法采用的是传统的coco数据集,这里我需要在新的数据集上跑,也就是船舶检测方向的SeaShips数据集,这里给出教程。 Seaships论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber8438999 一、…...
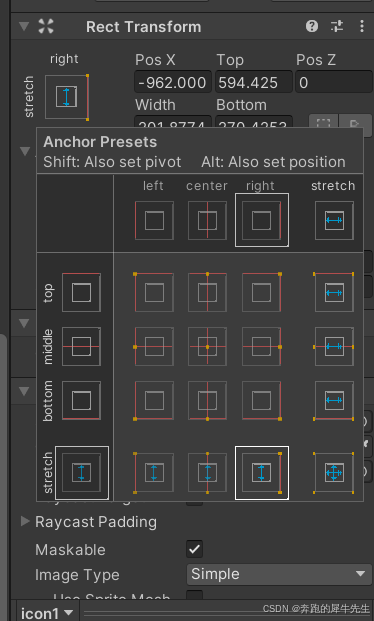
unity学习52:UI的最基础组件 rect transform,锚点anchor,支点/轴心点 pivot
目录 1 image 图像:最简单的UI 1.1 图像的基本属性 1.2 rect transform 1.3 image的component: 精灵 → 图片 1.4 修改颜色color 1.5 修改材质 1.6 raycast target 1.7 maskable 可遮罩 1.8 imageType 1.9 native size 原生大小 2 rect transform 2.1 …...

STM32MP15-FSMP1A单片机移植Linux系统platform总线驱动
之前在该单片机下移植的Linux驱动是学习过程中,对Linux内核驱动的引导学习,接下来才是比较正常的驱动开发。 在Linux内核中,对于驱动的处理,一般会通过总线进行设备信息和设备驱动的匹配,来达到自动检测外设连接系统以…...
)
Java 常见的面试题(设计模式)
一、说一下你熟悉的设计模式? **设计模式:**是一套被反复使用的代码设计经验的总结(情境中一个问题经过证实的一个解决方案)。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。设计模式使人们可以更加简…...

机器学习3-聚类
1 聚类解决的问题 知识发现,发现事物之间的潜在关系异常值检测特征提取 数据压缩的例子新闻自动分组、用户分群、图像分割、像素压缩等等 2 与监督学习比较 监督学习是需要给定X、Y,X为特征,Y为标签,选择模型,学习&a…...

html中的css
css (cascading style sheets,串联样式表,也叫层叠样式表) css规范一般约定: 1.存放CSS样式文件的目录一般命名为style或css。 2.在项目初期,会把不同类别的样式放于不同的CSS文件,是为了CSS编…...

36. Spring Boot 2.1.3.RELEASE 中实现监控信息可视化并添加邮件报警功能
1. 创建 Spring Boot Admin Server 项目 1.1 添加依赖 在 pom.xml 中添加 Spring Boot Admin Server 和邮件相关依赖: <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-w…...

Linux: 已占用接口
Linux: 已占用接口 1. netstat(适用于旧系统)1.1 书中对该命令的介绍 2. ss(适用于新系统,替代 netstat)3. lsof(查看详细进程信息)4. fuser(快速查找占用端口的进程)5. …...
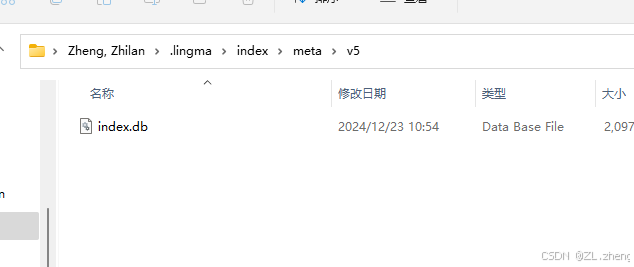
Vscode的通义灵码占用空间过大问题【.lingma】
C盘空间发现没装几个软件但是空间占用太离谱了, 最后排查发现是一个.lingma的文件夹问题,这个文件夹用了我居然差不多一百G的空间, 点进去。删除掉ai训练时产生的dbc文件就好了, windowsI 打开系统设置,搜索存储&#…...

鸿蒙Next如何自定义标签页
前言 项目需求是展示标签,标签的个数不定,一行展示不行就自行换行。但是,使用鸿蒙原生的 Grid 后发现特别的难看。然后就想着自定义控件。找了官方文档,发现2个重要的实现方法,但是,官方的demo中讲的很少&…...
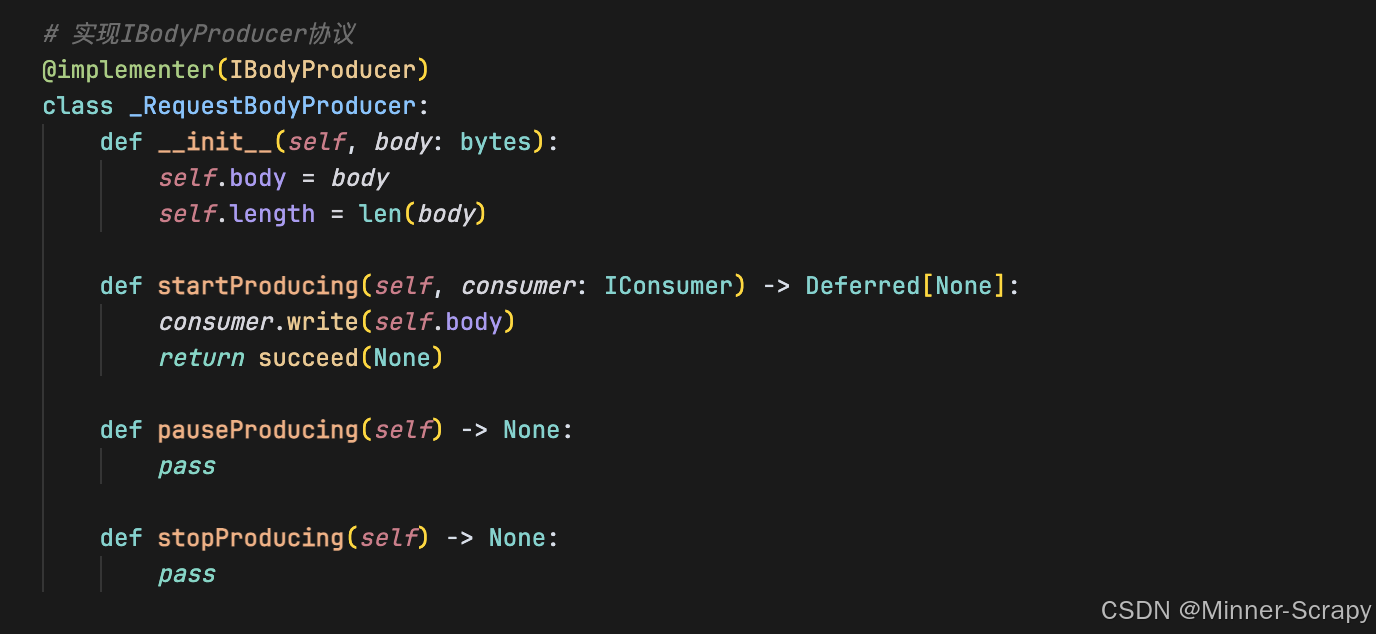
知识拓展:Python 接口实现方式对比:Protocol vs @implementer
Python 接口实现方式对比:Protocol vs implementer 1. 两种接口实现方式 1.1 Python Protocol(结构化子类型) from typing import Protocolclass DownloadHandlerProtocol(Protocol):def download_request(self, request: Request, spider:…...

开源程序wordpress在海外品牌推广中的重要作用
WordPress作为全球最流行的开源内容管理系统(CMS),在全球网站搭建中占据超过40%的市场份额。其强大的功能、灵活性和易用性使其成为企业进行海外品牌推广的首选平台。以下是WordPress在海外品牌推广中的重要性分析: 1. 多语言支持与本地化 WordPress通…...
】爬虫“反水”:助力数字版权保护的逆向之旅)
【Python爬虫(89)】爬虫“反水”:助力数字版权保护的逆向之旅
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...
)
k8s面试题总结(五)
1.考虑一种情况,即公司希望通过维持最低成本来提高其效率和技术运营速度。您认为公司将如何实现这一目标? 公司可以通过构建 CI/CD 管道来实现 DevOps 方法,但是这里可能出现的一个问题是配置可能需要一段时间才能启动并运行。 因此&#x…...

文章精读篇——用于遥感小样本语义分割的可学习Prompt
题目:Learnable Prompt for Few-Shot Semantic Segmentation in Remote Sensing Domain 会议:CVPR 2024 Workshop 论文:10.48550/arXiv.2404.10307 相关竞赛:https://codalab.lisn.upsaclay.fr/competitions/17568 年份&#…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器
3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经想要修改Minecraf…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

基于CNN的食双星光变曲线自动化参数初估模型EBOP MAVEN
1. 项目概述与核心价值在恒星天体物理领域,食双星系统一直扮演着“宇宙实验室”的关键角色。通过分析两颗恒星相互绕转时周期性相互遮挡产生的光变曲线,我们可以像解谜一样,精确反演出恒星的质量、半径、轨道倾角等基本物理参数。这些参数是构…...

3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验?
3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

为什么选择Espresso?5大优势让快递管理变得前所未有的简单[特殊字符]
为什么选择Espresso?5大优势让快递管理变得前所未有的简单🚀 【免费下载链接】Espresso 🚚 Espresso is an express delivery tracking app designed with Material Design style, built on MVP(Model-View-Presenter) architecture with RxJ…...

Safe Exam Browser 虚拟化检测绕过技术深度实践
Safe Exam Browser 虚拟化检测绕过技术深度实践 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在现代教育技术领域,Safe Exam Browser&…...