机器学习介绍与数据集
一、机器学习介绍与定义
1.1 机器学习定义
机器学习(Machine Learning)是让计算机从数据中自动学习规律,并依据这些规律对未来数据进行预测的技术。它涵盖聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等多种算法 ,基本思路是模拟人类学习行为,通过经验归纳总结规律来预测未来。
1.2 机器学习的发展历史
机器学习的发展历程丰富且具有标志性:
- 萌芽发展期(20 世纪 50 年代):图灵测试提出,塞缪尔开发西洋跳棋程序,标志着机器学习进入发展阶段。
- 发展停滞期(20 世纪 60 - 70 年代):发展几乎停滞。
- 复兴时期(20 世纪 80 年代):神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念提出,使机器学习复兴。
- 数据驱动转变期(20 世纪 90 年代):“决策树”(ID3 算法)和支持向量机(SVM)算法出现,机器学习从知识驱动转变为数据驱动。
- 蓬勃发展期(21 世纪初至今):Hinton 提出深度学习,随着算力提升和海量训练样本支持,深度学习成为研究热点并广泛应用。
1.3 机器学习分类
机器学习按学习模式可分为以下几类:
- 监督学习(Supervised Learning):从有标签的训练数据中学习模型,用于预测新数据标签,主要用于回归和分类。如预测房价(回归)和判断邮件是否为垃圾邮件(分类)。常见算法包括线性回归、朴素贝叶斯等。
- 半监督学习(Semi - Supervised Learning):利用少量标注数据和大量无标注数据学习,侧重于在有监督分类算法中加入无标记样本实现半监督分类。例如在图像分类中,利用少量标注图像和大量未标注图像训练模型。常见算法有 Pseudo - Label、Π - Model 等。
- 无监督学习(Unsupervised Learning):从未标注数据中寻找隐含结构,主要用于关联分析、聚类和降维。比如对客户进行聚类分析,找出不同客户群体特征。常见算法有稀疏自编码、主成分分析等。
- 强化学习(Reinforcement Learning):通过不断试错学习,有智能体和环境两个交互对象,以及策略、回报函数、价值函数和环境模型(可选)四个核心要素。常用于机器人避障、棋牌类游戏等。如 AlphaGo 通过强化学习在围棋领域取得卓越成绩。
1.4 机器学习需要具备的基础的知识,如何学习机器学习
学习机器学习需具备线性代数、微积分、概率和统计等数学知识,以及编程基础。学习建议如下:
- 数学基础:掌握线性代数、概率论和统计学概念,理解算法原理。
- 编程语言:熟练掌握 Python 或 R 语言,它们有丰富的机器学习库和工具。
- 机器学习算法:了解常见算法原理、应用和优缺点。
- 机器学习工具和框架:熟悉 scikit - learn、TensorFlow、PyTorch 等工具和框架。
- 实践项目:通过小型项目提升实践能力,如利用鸢尾花数据集进行分类预测。
- 学习资源:利用 Coursera、Kaggle、GitHub 等平台的学习资源。
- 参与机器学习社区:与他人交流经验,参加线下活动。
- 持续学习和实践:机器学习不断发展,需持续关注研究成果,参与竞赛和项目。
1.5 机器学习的应用场合
机器学习应用广泛,涵盖多个行业领域:
- 自然语言处理(NLP):实现语音识别、文本分析、情感分析等,用于智能客服、聊天机器人等。如智能音箱通过语音识别和自然语言处理理解用户指令。
- 医疗诊断与影像分析:分析医疗图像、预测疾病、辅助药物发现。例如利用深度学习模型诊断医学影像中的疾病。
- 金融风险管理:分析金融数据,预测市场波动性、信用风险等。银行利用机器学习模型评估客户信用风险。
- 预测与推荐系统:进行销售预测、个性化推荐。电商平台根据用户购买历史推荐商品。
- 制造业和物联网:处理传感器数据,实现设备预测性维护和质量控制。工厂利用机器学习预测设备故障,提前维护。
- 能源管理与环境保护:优化能源管理,提高能源利用效率。通过分析能源数据,制定节能策略。
- 决策支持与智能分析:分析大量数据,辅助决策制定。企业利用机器学习分析市场数据,制定营销策略。
- 图像识别与计算机视觉:实现图像分类、目标检测等。安防系统利用图像识别技术识别人员身份。
1.6 机器学习趋势分析
机器学习热点研究包括深度神经网络、强化学习、卷积神经网络、循环神经网络等。以深度神经网络、强化学习为代表的深度学习技术研究热度持续上升,是当前研究热点。
1.7 机器学习项目开发步骤
机器学习项目开发通常包含以下 5 个基本步骤:
- 收集数据:收集原始数据,数据种类、密度和数量越多,学习效果越好。如收集电商用户购买数据。
- 准备数据:确定数据质量,处理缺失数据和异常值,进行探索性分析。例如对收集的用户购买数据进行清洗和预处理。
- 训练模型:选择合适算法和数据表示形式,将清理后的数据分为训练集和测试集,用训练集开发模型。以房价预测为例,选择线性回归算法,用部分数据训练模型。
- 评估模型:使用测试集评估模型准确性,查看模型在未使用数据上的性能。如用测试集数据评估房价预测模型的准确性。
- 提高性能:选择不同模型或引入更多变量提高效率。若房价预测模型准确性不高,尝试其他算法或增加更多特征。
二、scikit - learn 工具介绍
2.1 Python 语言机器学习工具
scikit - learn 是 Python 语言的机器学习工具,包含许多智能的机器学习算法实现,文档完善,上手容易,拥有丰富的 API 接口函数。
2.2 官网及文档
- 官网:https://scikit - learn.org/stable/#
- 中文文档:sklearn
- 中文社区:https://scikit - learn.org.cn/
2.3 scikit - learn 安装
使用 pip 安装:
收起
bash
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit - learn
2.4 Scikit - learn 包含的内容
scikit - learn 包含分类、回归、聚类、降维、模型选择、预处理等内容,为机器学习提供全面支持。
三、数据集(重点)
3.1 sklearn 玩具数据集介绍
数据量小,存储在 sklearn 库本地,安装 sklearn 后无需联网即可获取,如鸢尾花数据集。
3.2 sklearn 现实世界数据集介绍
数据量大,需通过网络获取,如 20 分类新闻数据集。
3.3 sklearn 加载玩具数据集
以鸢尾花数据集为例:
收起
python
from sklearn.datasets import load_iris
iris = load_iris() # 加载鸢尾花数据集
鸢尾花数据集特征包括花萼长、花萼宽、花瓣长、花瓣宽,为三分类数据集(0 - Setosa 山鸢尾 、1 - versicolor 变色鸢尾 、2 - Virginica 维吉尼亚鸢尾)。iris 对象重要属性有:
收起
python
# data 特征
# feature_names 特征描述
# target 目标
# target_names 目标描述
# DESCR 数据集的描述
# filename 下载到本地保存后的文件名
使用 pandas 展示特征和目标:
收起
python
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
feature = iris.data
target = iris.target
target.shape = (len(target), 1)
data = np.hstack([feature, target])
cols = iris.feature_names
cols.append("target")
pd.DataFrame(data, columns=cols)
3.4 sklearn 获取现实世界数据集
以获取 20 分类新闻数据为例:
收起
python
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(data_home=None, subset='all')
- 参数说明:
- data_home:默认 None,下载路径为 “C:/Users/ADMIN/scikit_learn_data/20news - bydate_py3.pkz”;也可自定义路径。
- subset:“train” 只下载训练集,“test” 只下载测试集,“all” 下载训练集和测试集。
- return_X_y:默认 False;为 True 时,返回值为元组,包含特征数据集和目标数据集。
- 返回值说明:
- return_X_y 为 False 时:返回 Bunch 对象,包含 data(特征数据集)、target(目标数据集)、target_names(目标描述)、filenames(新闻数据位置路径)。
- return_X_y 为 True 时:返回元组,包含特征数据集和目标数据集。
3.5 本地 csv 数据
3.5.1 创建 csv 文件
- 方式 1:使用记事本编写数据,数据间用英文逗号分隔,保存后将后缀名改为 csv。
- 方式 2:创建 excel 文件填写数据,以 csv 为后缀保存。
3.5.2 pandas 加载 csv
收起
python
import pandas as pd
pd.read_csv("./src/ss.csv")
3.6 数据集的划分(重点)
3.6.1 函数
收起
python
sklearn.model_selection.train_test_split(*arrays,**options)
- 参数:
- *array:接收 1 到多个 “列表、numpy 数组、稀疏矩阵或 padas 中的 DataFrame”。
- **options:
- test_size:0.0 到 1.0 的小数,表示划分后测试集占比。
- random_state:任意整数,作为随机种子,相同随机种子对相同数据集多次划分结果相同。
- stratify:分层划分,填写 y。
- 返回值说明:返回列表,长度与形参 array 接收的参数数量相关,对应划分出的两部分数据类型与 array 接收的类型相同。
3.6.2 示例
- 列表数据集划分:
收起
python
from sklearn.model_selection import train_test_split
data1 = [1, 2, 3, 4, 5]
data2 = ["1a", "2a", "3a", "4a", "5a"]
a, b = train_test_split(data1, test_size=0.4, random_state=22)
print(a, b)
a, b = train_test_split(data2, test_size=0.4, random_state=22)
print(a, b)
a, b, c, d = train_test_split(data1, data2, test_size=0.4, random_state=22)
print(a, b, c, d)
- ndarray 数据集划分:
收起
python
from sklearn.model_selection import train_test_split
import numpy as np
data1 = [1, 2, 3, 4, 5]
data2 = np.array(["1a", "2a", "3a", "4a", "5a"])
a, b, c, d = train_test_split(data1, data2, test_size=0.4, random_state=22)
print(a, b, c, d)
print(type(a), type(b), type(c), type(d))
- 二维数组数据集划分:
收起
python
from sklearn.model_selection import train_test_split
import numpy as np
data1 = np.arange(1, 16, 1)
data1.shape = (5, 3)
print(data1)
a, b = train_test_split(data1, test_size=0.4, random_state=22)
print("a=\n", a)
print("b=\n", b)
- DataFrame 数据集划分:
收起
python
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
data1 = np.arange(1, 16, 1)
data1.shape = (5, 3)
data1 = pd.DataFrame(data1, index=[1, 2, 3, 4, 5], columns=["one", "two", "three"])
print(data1)
a, b = train_test_split(data1, test_size=0.4, random_state=22)
print("\n", a)
print("\n", b)
- 字典数据集划分:
收起
python
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
data = [{'city': '成都', 'age': 30, 'temperature': 20},{'city': '重庆', 'age': 33, 'temperature': 60},{'city': '北京', 'age': 42, 'temperature': 80},{'city': '上海', 'age': 22, 'temperature': 70},{'city': '成都', 'age': 72, 'temperature': 40},]
transfer = DictVectorizer(sparse=True)
data_new = transfer.fit_transform(data)
a, b = train_test_split(data_new, test_size=0.4, random_state=22)
print(a)
print("\n", b)
- 鸢尾花数据集划分:
收起
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
list = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
x_train, x_test, y_train, y_test = list
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
- 现实世界数据集划分:
收起
python
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
news = fetch_20newsgroups(data_home=None, subset='all')
list = train_test_split(news.data, news.target, test_size=0.2, random_state=22)
x_train, x_test, y_train, y_test = list
print(len(x_train), len(x_test), y_train.shape, y_test.shape)相关文章:

机器学习介绍与数据集
一、机器学习介绍与定义 1.1 机器学习定义 机器学习(Machine Learning)是让计算机从数据中自动学习规律,并依据这些规律对未来数据进行预测的技术。它涵盖聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning…...
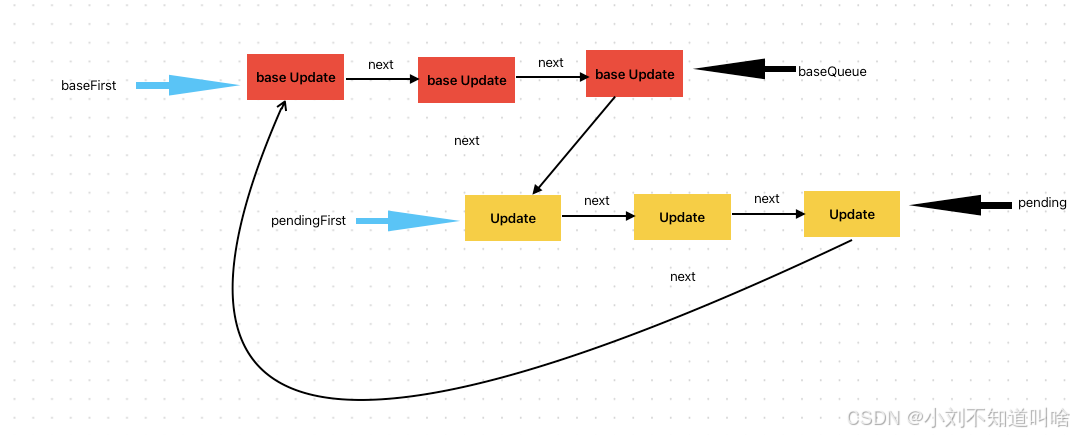
React 源码揭秘 | 更新队列
前面几篇遇到updateQueue的时候,我们把它先简单的当成了一个队列处理,这篇我们来详细讨论一下这个更新队列。 有关updateQueue中的部分,可以见源码 UpdateQueue实现 Update对象 我们先来看一下UpdateQueue中的内容,Update对象&…...

关于网络端口探测:TCP端口和UDP端口探测区别
网络端口探测是网络安全领域中的一项基础技术,它用于识别目标主机上开放的端口以及运行在这些端口上的服务。这项技术对于网络管理和安全评估至关重要。在网络端口探测中,最常用的两种协议是TCP(传输控制协议)和UDP(用…...

Vue.js 中使用 JSX 自定义语法封装组件
Vue.js 中使用 JSX 自定义语法封装组件 在 Vue.js 开发中,使用模板语法是常见的构建用户界面方式,但对于一些开发者,特别是熟悉 JavaScript 语法的,JSX 提供了一种更灵活、更具表现力的替代方案。通过 JSX,我们可以在…...
)
设计模式教程:备忘录模式(Memento Pattern)
备忘录模式(Memento Pattern)详解 一、模式概述 备忘录模式(Memento Pattern)是一种行为型设计模式,允许在不暴露对象实现细节的情况下,保存对象的内部状态,并在需要时恢复该状态。备忘录模式…...

使用 C# 以api的形式调用 DeepSeek
一:创建 API 密钥 首先,您需要来自 DeepSeek 的 API 密钥。访问 DeepSeek,创建一个帐户,并生成一个新的 API 密钥。 二:安装所需的 NuGet 包 使用 NuGet 包管理器安装包,或在包管理器控制台中运行以下命…...
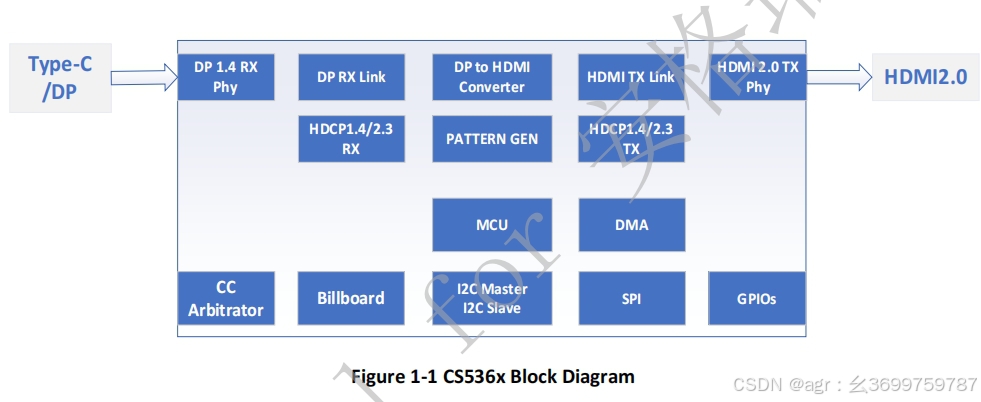
CS5366AN:高集成Type-C转HDMI 4K60Hz芯片的国产突破
一、芯片概述 CS5366AN 是集睿致远(ASL)推出的一款高度集成的 Type-C转HDMI 2.0视频转换芯片,专为扩展坞、游戏底座、高清显示设备等场景设计。其核心功能是将USB Type-C接口的DisplayPort信号(DP Alt Mode)转换为HDM…...

瑞芯微RK安卓Android主板GPIO按键配置方法,触觉智能嵌入式开发
触觉智能分享,瑞芯微RK安卓Android主板GPIO按键配置方法,方便大家更好利用空闲IO!由触觉智能Purple Pi OH鸿蒙开发板演示,搭载了瑞芯微RK3566四核处理器,树莓派卡片电脑设计,支持安卓Android、开源鸿蒙Open…...

Dify自定义工作流集成指南:对接阿里云百炼文生图API的实现方案
dify工作流的应用基本解释 dify应用发布相关地址:应用发布 | Dify 根据官方教程,我们可以看到dify自定义的工作流可以发布为----工具 这个教程将介绍如何通过工作流建立一个使用阿里云百炼文生图模型。 工具则可以给其他功能使用,如agent…...

前端项目配置 Nginx 全攻略
在前端开发中,项目开发完成后,如何高效、稳定地将其部署到生产环境是至关重要的一步。Nginx 作为一款轻量级、高性能的 Web 服务器和反向代理服务器,凭借其出色的性能和丰富的功能,成为了前端项目部署的首选方案。本文将详细介绍在…...
的【智能家居综合应用】系统)
基于开源鸿蒙(OpenHarmony)的【智能家居综合应用】系统
基于开源鸿蒙OpenHarmony的智能家居综合应用系统 1. 智能安防与门禁系统1) 系统概述2) 系统架构3)关键功能实现4)安全策略5)总结 2.环境智能调节系统1)场景描述2)技术实现3)总结 3.健康管理与睡眠监测1&…...

电子电气架构 --- 主机厂电子电气架构演进
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 简单,单纯,喜欢独处,独来独往,不易合同频过着接地气的生活,除了生存温饱问题之外,没有什么过多的欲望,表面看起来很高冷,内心热情,如果你身…...

物联网通信应用案例之《智慧农业》
案例概述 在智慧农业方面,一般的应用场景为可以自动检测温度湿度等一系列环境情况并且可以自动做出相应的处理措施如简单的浇水和温度控制等,且数据情况可远程查看,以及用户可以实现远程控制。 基本实现原理 传感器通过串口将数据传递到Wi…...

Java注解的原理
目录 问题: 作用: 原理: 注解的限制 拓展: 问题: 今天刷面经,发现自己不懂注解的原理,特此记录。 作用: 注解的作用主要是给编译器看的,让它帮忙生成一些代码,或者是帮忙检查…...

AI知识架构之神经网络
神经网络:这是整个内容的主题,是一种模拟人类大脑神经元结构和功能的计算模型,在人工智能领域广泛应用。基本概念:介绍神经网络相关的基础概念,为后续深入理解神经网络做铺垫。定义与起源: 神经网络是模拟人类大脑神经元结构和功能的计算模型,其起源于对生物神经系统的研…...

OpenGL 04--GLSL、数据类型、Uniform、着色器类
一、着色器 在 OpenGL 中,着色器(Shader)是运行在 GPU 上的程序,用于处理图形渲染管线中的不同阶段。 这些小程序为图形渲染管线的某个特定部分而运行。从基本意义上来说,着色器只是一种把输入转化为输出的程序。着色器…...

学习笔记06——JVM调优
JVM 调优实战:性能优化的技巧与实战 在 Java 开发中,JVM(Java Virtual Machine)作为 Java 程序的运行环境,其性能直接影响到应用程序的响应速度和吞吐量。合理的 JVM 调优可以显著提升应用性能,降低延迟&a…...
-TensorFlow入门(常数张量和变量))
深度学习(3)-TensorFlow入门(常数张量和变量)
低阶张量操作是所有现代机器学习的底层架构,可以转化为TensorFlow API。 张量,包括存储神经网络状态的特殊张量(变量)。 张量运算,比如加法、relu、matmul。 反向传播,一种计算数学表达式梯度的方法&…...
学习笔记)
3-2 WPS JS宏 工作簿的打开与保存(模板批量另存为工作)学习笔记
************************************************************************************************************** 点击进入 -我要自学网-国内领先的专业视频教程学习网站 *******************************************************************************************…...

【GO】学习笔记
目录 学习链接 开发环境 开发工具 GVM - GO多版本部署 GOPATH 与 go.mod go常用命令 环境初始化 编译与运行 GDB -- GNU 调试器 基本语法与字符类型 关键字与标识符 格式化占位符 基本语法 初始值&零值&默认值 变量声明与赋值 _ 下划线的用法 字…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...

3步终结Windows热键冲突:Hotkey Detective终极排查指南
3步终结Windows热键冲突:Hotkey Detective终极排查指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...