DeepSeek开源周首日:发布大模型加速核心技术可变长度高效FlashMLA 加持H800算力解码性能狂飙升至3000GB/s
FlashMLA的核心技术特性包括对BF16精度的全面支持,以及采用块大小为64的页式键值缓存(Paged KV Cache)系统,实现更精确的内存管理。在性能表现方面,基于CUDA12.6平台,FlashMLA在H800SXM5GPU上创下了显著成绩:在内存受限场景下达到3000GB/s的处理速度,在计算受限场景下则实现580TFLOPS的算力水平。
1. 核心功能与特性
-
性能提升
FlashMLA在H800 SXM5 GPU(CUDA 12.6)上表现亮眼:- 内存受限场景下带宽达3000 GB/s
- 计算受限场景下算力峰值达580 TFLOPS(BF16精度)
-
关键技术优化
- 变长序列处理:针对自然语言处理中的动态序列长度优化,提升长文本推理效率。
- 分页KV缓存:块大小为64的分页机制,减少显存碎片化,提升内存利用率。
- BF16支持:通过低精度计算降低内存占用,同时保持模型性能。
-
MLA架构创新
相比传统注意力机制,MLA通过低秩压缩技术将每次查询的KV缓存量减少93.3%,显著降低推理时的显存需求,尤其适合长上下文场景。
2. 技术背景与意义
-
解决行业痛点
Transformer模型在长序列推理时面临KV缓存膨胀问题,导致显存占用高、硬件成本攀升。FlashMLA通过MLA架构和并行解码设计,将推理成本降低约80-90%,同时支持更高吞吐量 -
开源生态价值
FlashMLA开源代码库(GitHub链接)整合了FlashAttention-2/3和CUTLASS的技术实现,为开发者提供可复现的优化方案,加速AGI技术迭代。
3. 应用场景与部署
-
适用场景
- 大语言模型(LLM)推理加速,如对话AI、实时翻译、长文本生成等。
- 需要低延迟、高吞吐的工业级NLP任务。
-
部署要求
- 硬件:Hopper架构GPU(如H800/H100)
- 软件:CUDA 12.3+、PyTorch 2.0+
4. 对行业的影响
-
成本革命
DeepSeek通过MLA技术将模型训练和推理成本压缩至行业标杆水平。例如,其V3模型的训练成本仅600万美元(未含研发投入),而MLA的推理优化进一步降低商业化门槛。 -
算力效率提升
结合MoE(混合专家模型)架构和多Token预测技术,DeepSeek在单位算力下实现更高性能,推动行业从“堆算力”向“优化算法”转型。 -
开源竞争格局
此次开源被视为对Meta Llama、Mistral等项目的直接挑战,可能加速闭源与开源模型的性能差距缩小。
FlashMLA的发布标志着DeepSeek在高效计算领域的技术领先地位,其开源策略或将重塑大模型开发范式,推动更多低成本、高性能AI应用的涌现。
5.快速开始
安装
可以使用以下命令进行安装:
python setup.py install
基准测试
运行以下命令进行基准测试:
python tests/test_flash_mla.py
使用示例
在Python中可以这样使用:
from flash_mla import get_mla_metadata, flash_mla_with_kvcachetile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv)for i in range(num_layers):...o_i, lse_i = flash_mla_with_kvcache(q_i, kvcache_i, block_table, cache_seqlens, dv,tile_scheduler_metadata, num_splits, causal=True,)...
6.核心代码的详细解释
以下是对 FlashMLA/flash_mla/flash_mla_interface.py 文件中:
get_mla_metadata 函数
def get_mla_metadata(cache_seqlens: torch.Tensor,num_heads_per_head_k: int,num_heads_k: int,
) -> Tuple[torch.Tensor, torch.Tensor]:"""Arguments:cache_seqlens: (batch_size), dtype torch.int32.num_heads_per_head_k: Equals to seq_len_q * num_heads_q // num_heads_k.num_heads_k: num_heads_k.Return:tile_scheduler_metadata: (num_sm_parts, TileSchedulerMetaDataSize), dtype torch.int32.num_splits: (batch_size + 1), dtype torch.int32."""return flash_mla_cuda.get_mla_metadata(cache_seqlens, num_heads_per_head_k, num_heads_k)
- 功能:该函数用于获取MLA(Multi-Head Attention)的元数据。
- 参数:
cache_seqlens:一个形状为(batch_size)的torch.Tensor,数据类型为torch.int32,表示缓存的序列长度。num_heads_per_head_k:整数类型,其值等于seq_len_q * num_heads_q // num_heads_k。num_heads_k:整数类型,表示num_heads_k的值。
- 返回值:
tile_scheduler_metadata:形状为(num_sm_parts, TileSchedulerMetaDataSize)的torch.Tensor,数据类型为torch.int32。num_splits:形状为(batch_size + 1)的torch.Tensor,数据类型为torch.int32。
- 实现细节:该函数直接调用
flash_mla_cuda模块中的get_mla_metadata函数,并将输入参数传递给它,然后返回该函数的结果。
flash_mla_with_kvcache 函数
def flash_mla_with_kvcache(q: torch.Tensor,k_cache: torch.Tensor,block_table: torch.Tensor,cache_seqlens: torch.Tensor,head_dim_v: int,tile_scheduler_metadata: torch.Tensor,num_splits: torch.Tensor,softmax_scale: Optional[float] = None,causal: bool = False,
) -> Tuple[torch.Tensor, torch.Tensor]:"""Arguments:q: (batch_size, seq_len_q, num_heads_q, head_dim).k_cache: (num_blocks, page_block_size, num_heads_k, head_dim).block_table: (batch_size, max_num_blocks_per_seq), torch.int32.cache_seqlens: (batch_size), torch.int32.head_dim_v: Head_dim of v.tile_scheduler_metadata: (num_sm_parts, TileSchedulerMetaDataSize), torch.int32, return by get_mla_metadata.num_splits: (batch_size + 1), torch.int32, return by get_mla_metadata.softmax_scale: float. The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim).causal: bool. Whether to apply causal attention mask.Return:out: (batch_size, seq_len_q, num_heads_q, head_dim_v).softmax_lse: (batch_size, num_heads_q, seq_len_q), torch.float32."""if softmax_scale is None:softmax_scale = q.shape[-1] ** (-0.5)out, softmax_lse = flash_mla_cuda.fwd_kvcache_mla(q,k_cache,None,head_dim_v,cache_seqlens,block_table,softmax_scale,causal,tile_scheduler_metadata,num_splits,)return out, softmax_lse
- 功能:该函数用于执行带有键值缓存(KVCache)的MLA操作。
- 参数:
q:形状为(batch_size, seq_len_q, num_heads_q, head_dim)的torch.Tensor,表示查询张量。k_cache:形状为(num_blocks, page_block_size, num_heads_k, head_dim)的torch.Tensor,表示键缓存张量。block_table:形状为(batch_size, max_num_blocks_per_seq)的torch.Tensor,数据类型为torch.int32,表示块表。cache_seqlens:形状为(batch_size)的torch.Tensor,数据类型为torch.int32,表示缓存的序列长度。head_dim_v:整数类型,表示v的头维度。tile_scheduler_metadata:形状为(num_sm_parts, TileSchedulerMetaDataSize)的torch.Tensor,数据类型为torch.int32,由get_mla_metadata函数返回。num_splits:形状为(batch_size + 1)的torch.Tensor,数据类型为torch.int32,由get_mla_metadata函数返回。softmax_scale:可选的浮点数,表示在应用softmax之前对QK^T进行缩放的比例,默认为1 / sqrt(head_dim)。causal:布尔类型,表示是否应用因果注意力掩码,默认为False。
- 返回值:
out:形状为(batch_size, seq_len_q, num_heads_q, head_dim_v)的torch.Tensor,表示输出张量。softmax_lse:形状为(batch_size, num_heads_q, seq_len_q)的torch.Tensor,数据类型为torch.float32,表示softmax的对数和指数(LogSumExp)。
- 实现细节:
- 如果
softmax_scale未提供,则将其设置为q张量最后一个维度的平方根的倒数。 - 调用
flash_mla_cuda模块中的fwd_kvcache_mla函数,传递相应的参数,并将返回的结果赋值给out和softmax_lse。 - 最后返回
out和softmax_lse。
- 如果
这些函数主要是作为Python接口,调用底层的CUDA实现(flash_mla_cuda 模块)来完成MLA操作和元数据的获取。
相关文章:

DeepSeek开源周首日:发布大模型加速核心技术可变长度高效FlashMLA 加持H800算力解码性能狂飙升至3000GB/s
FlashMLA的核心技术特性包括对BF16精度的全面支持,以及采用块大小为64的页式键值缓存(Paged KV Cache)系统,实现更精确的内存管理。在性能表现方面,基于CUDA12.6平台,FlashMLA在H800SXM5GPU上创下了显著成绩…...

易语言模拟真人鼠标轨迹算法 - 防止游戏检测
一.简介 鼠标轨迹算法是一种模拟人类鼠标操作的程序,它能够模拟出自然而真实的鼠标移动路径。 鼠标轨迹算法的底层实现采用C/C语言,原因在于C/C提供了高性能的执行能力和直接访问操作系统底层资源的能力。 鼠标轨迹算法具有以下优势: 模拟…...

DeepSeek 提示词:基础结构
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

文件系统
目录 1.认识磁盘 磁盘的物理结构 CHS定位法 磁盘的逻辑结构 2.认识文件系统 inode 分区和分组 磁盘上的文件系统 3.软硬链接 软链接 软链接的操作 创建软链接 查看软链接 删除软链接 软链接的特点 软链接的使用场景 硬链接 硬链接的操作 创建硬链接 查看硬…...

力扣LeetCode:1472 设计浏览器历史记录
题目: 你有一个只支持单个标签页的 浏览器 ,最开始你浏览的网页是 homepage ,你可以访问其他的网站 url ,也可以在浏览历史中后退 steps 步或前进 steps 步。 请你实现 BrowserHistory 类: BrowserHistory(string h…...

【FL0091】基于SSM和微信小程序的社区二手物品交易小程序
🧑💻博主介绍🧑💻 全网粉丝10W,CSDN全栈领域优质创作者,博客之星、掘金/知乎/b站/华为云/阿里云等平台优质作者、专注于Java、小程序/APP、python、大数据等技术领域和毕业项目实战,以及程序定制化开发…...

【笔记ing】每天50个英语词汇
ex- e-out exclude 排外,排除 expect 期待,期望 单词构成: 前缀(prefix):情感(emotion)方向(orientation) 词根(root)…...

联想 SR590 服务器 530-8i RAID 控制器更换损坏的硬盘
坏了的硬盘会自动亮黄灯。用一个空的新盘来替换,新盘最好不要有东西。但是有东西可能也没啥,因为我看 RAID 控制器里有格式化的选项 1. 从 IPMI 把服务器关机,电源键进入绿色闪烁状态 2. 断电,推开塑料滑块拉出支架,…...

Java基础关键_012_包装类
目 录 一、基本数据类型对应的包装类 1.概览 2.说明 二、包装类 1.最大值与最小值 2.构造方法 3.常用方法(Integer为例) (1)compare(int x, int y) (2)max(int a, int b) 和 min(int a, int b) &…...

【react】TypeScript在react中的使用
目录 一、环境与项目配置 1. 创建 TypeScript React 项目 2. 关键tsconfig.json配置 3.安装核心类型包 二、组件类型定义 1. 函数组件(React 18) 2.类组件 三、Hooks 的深度类型集成 1. useState 2. useEffect 3. useRef 4. 自定义 Hook 四、事…...

vllm的使用方式,入门教程
vLLM是一个由伯克利大学LMSYS组织开源的大语言模型推理框架,旨在提升实时场景下的大语言模型服务的吞吐与内存使用效率。以下是详细的vLLM使用方式和入门教程: 1. 前期准备 在开始使用vLLM之前,建议先掌握一些基础知识,包括操作…...

IDEA 使用codeGPT+deepseek
一、环境准备 1、IDEA 版本要求 安装之前确保 IDEA 处于 2023.x 及以上的较新版本。 2、Python 环境 安装 Python 3.8 或更高版本 为了确保 DeepSeek 助手能够顺利运行,您需要在操作系统中预先配置 Python 环境。具体来说,您需要安装 Python 3.8 或更高…...

vue3中测试:单元测试、组件测试、端到端测试
1、单元测试:单元测试通常适用于独立的业务逻辑、组件、类、模块或函数,不涉及 UI 渲染、网络请求或其他环境问题。 describe(increment, () > {// 测试用例 }) toBe():用于严格相等比较(),适用于原始类…...

机器学习介绍与数据集
一、机器学习介绍与定义 1.1 机器学习定义 机器学习(Machine Learning)是让计算机从数据中自动学习规律,并依据这些规律对未来数据进行预测的技术。它涵盖聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning…...
React 源码揭秘 | 更新队列
前面几篇遇到updateQueue的时候,我们把它先简单的当成了一个队列处理,这篇我们来详细讨论一下这个更新队列。 有关updateQueue中的部分,可以见源码 UpdateQueue实现 Update对象 我们先来看一下UpdateQueue中的内容,Update对象&…...

关于网络端口探测:TCP端口和UDP端口探测区别
网络端口探测是网络安全领域中的一项基础技术,它用于识别目标主机上开放的端口以及运行在这些端口上的服务。这项技术对于网络管理和安全评估至关重要。在网络端口探测中,最常用的两种协议是TCP(传输控制协议)和UDP(用…...

Vue.js 中使用 JSX 自定义语法封装组件
Vue.js 中使用 JSX 自定义语法封装组件 在 Vue.js 开发中,使用模板语法是常见的构建用户界面方式,但对于一些开发者,特别是熟悉 JavaScript 语法的,JSX 提供了一种更灵活、更具表现力的替代方案。通过 JSX,我们可以在…...
)
设计模式教程:备忘录模式(Memento Pattern)
备忘录模式(Memento Pattern)详解 一、模式概述 备忘录模式(Memento Pattern)是一种行为型设计模式,允许在不暴露对象实现细节的情况下,保存对象的内部状态,并在需要时恢复该状态。备忘录模式…...

使用 C# 以api的形式调用 DeepSeek
一:创建 API 密钥 首先,您需要来自 DeepSeek 的 API 密钥。访问 DeepSeek,创建一个帐户,并生成一个新的 API 密钥。 二:安装所需的 NuGet 包 使用 NuGet 包管理器安装包,或在包管理器控制台中运行以下命…...
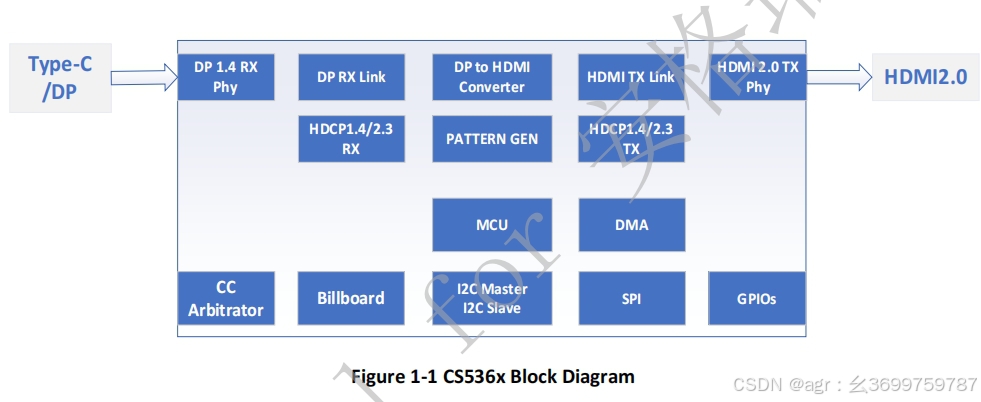
CS5366AN:高集成Type-C转HDMI 4K60Hz芯片的国产突破
一、芯片概述 CS5366AN 是集睿致远(ASL)推出的一款高度集成的 Type-C转HDMI 2.0视频转换芯片,专为扩展坞、游戏底座、高清显示设备等场景设计。其核心功能是将USB Type-C接口的DisplayPort信号(DP Alt Mode)转换为HDM…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...
从Stable Diffusion到DiT:为什么说Transformer是扩散模型的下一站?
从Stable Diffusion到DiT:Transformer如何重塑扩散模型的未来 在图像生成领域,扩散模型正经历着从U-Net架构向Transformer架构的范式转移。这一转变不仅仅是技术组件的简单替换,而是代表着生成式AI在可扩展性、训练效率和模型容量方面的重大突…...

如何在5分钟内免费搭建工业级OpenPLC虚拟控制器
如何在5分钟内免费搭建工业级OpenPLC虚拟控制器 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC OpenPLC是一款功能强大的开源虚拟PLC(可编程逻辑控制器&a…...

拒绝繁琐 PS:美图秀秀 电脑版在技术博客配图、无畸变裁剪与尺寸标准化中的应用
在日常开发、技术写作或维护 GitHub 开源项目时,技术配图和录屏展示是不可或缺的组成部分。 然而,对于大多数程序员和前端开发者来说,仅仅为了裁剪一个 App Icon 尺寸、给一系列产品图加防伪水印、对系统敏感配置截图进行脱敏打码࿰…...