vllm的使用方式,入门教程

vLLM是一个由伯克利大学LMSYS组织开源的大语言模型推理框架,旨在提升实时场景下的大语言模型服务的吞吐与内存使用效率。以下是详细的vLLM使用方式和入门教程:
1. 前期准备
在开始使用vLLM之前,建议先掌握一些基础知识,包括操作系统原理、网络编程、数据库管理等。这些知识有助于理解vLLM的工作机制,并为后续深入学习奠定基础。
2. 安装vLLM
2.1 环境配置
- 操作系统:Linux或Windows(推荐Linux)
- Python版本:3.8及以上
- CUDA版本:7.0及以上(推荐12.1)
- GPU:至少7.0计算能力的GPU(如V100、T4、RTX40xx、A100、L4、H100等)
2.2 安装步骤
- 创建conda环境(可选):
conda create --name myenv python=3.9 -yconda activate myenv
- 安装vLLM:
pip install vllm
- 检查CUDA版本:
nvcc --version
- 验证安装:
运行以下命令检查vLLM是否安装成功:
import vllmprint(vllm.__version__)
3. 启动vLLM服务器
3.1 启动本地服务器
使用以下命令启动vLLM服务器:
python -m vllm.entrypoints.openai_server --model lmsys/vicuna-7b-v1.3 --server-kind local
此命令会启动一个本地服务器,监听指定的模型和端口。
3.2 启动云平台服务器
如果使用OpenBayes云平台,可以直接在平台上操作,跳过本地安装步骤。具体步骤如下:
- 登录OpenBayes平台。
- 在“公共教程”中选择“vLLM 入门零基础分步指南”教程。
- 克隆教程到自己的容器中。
- 按照教程中的步骤进行操作。
4. 发出请求
4.1 使用Python代码发送请求
import vllmprompts = ["Hello, my name is", "The capital of France is"]
model = vllm.LLM(model="lmsys/vicuna-7b-v1.3")
outputs = model.generate(prompts)for output in outputs:print(output.text)
此代码会生成指定提示词的文本输出。
4.2 使用OpenAI API兼容方式
vLLM支持与OpenAI API兼容的查询格式,可以通过以下命令启动服务:
python - m vllm.entrypoints.openai_server --model lmsys/vicuna-7b-v1.3 --server-kind openai
然后使用Python请求库或OpenAI客户端向vLLM服务器发送请求,获取模型输出。
5. 安全设置
默认情况下,vLLM服务器没有身份验证。为了安全起见,建议设置API密钥,并在请求中包含该密钥。
6. 高级特性
6.1 PagedAttention
vLLM采用了全新的注意力算法「PagedAttention」,有效管理注意力键和值,提升了吞吐量和内存使用效率。PagedAttention使得vLLM在吞吐量上比HuggingFace Transformers高出24倍,文本生成推理(TGI)高出3.5倍。
6.2 连续批处理输入请求
vLLM支持连续批处理输入请求,进一步优化了推理性能。
6.3 模型微调与优化
vLLM支持模型微调和优化,包括量化、剪枝等技术,以减少运行模型所需的内存空间。
7. 实践案例
通过实际案例加深理解:
- 本地部署:在本地环境中安装和运行vLLM,测试不同模型的性能。
- 云平台部署:在OpenBayes等云平台上部署vLLM,体验云原生环境下的高效推理。
- 集成应用:将vLLM与Hugging Face模型无缝集成,开发个性化的大语言模型应用。
8. 总结
vLLM是一个强大且易于使用的推理框架,适用于多种场景。通过上述步骤,您可以快速上手并开始使用vLLM进行大语言模型推理。如果遇到问题,可以参考官方文档或社区资源进行解决。
vLLM支持多种模型微调和优化技术,具体包括以下几种:
-
全参数微调(Full-Parameter Fine-Tuning):
- vLLM支持对预训练模型进行全参数微调,以适应特定任务或数据集。这种方法通过调整所有模型参数来优化性能,适用于需要大量数据和计算资源的场景。
-
LoRA(Low-Rank Adaptation):
- LoRA是一种高效、快速且参数效率高的微调方法,特别适用于资源有限的环境,如移动应用或边缘设备。LoRA通过矩阵降维技术更新模型权重,显著提高内存和计算效率,减少参数数量。
-
量化(Quantization):
- vLLM支持多种量化技术,包括GPTQ、AWQ、SqueezeLLM和FP8 KV缓存。这些技术通过将模型参数转换为低精度数据类型(如8位或4位)来减少内存使用和加快计算速度。
-
Paged Attention:
- vLLM采用Paged Attention技术,有效管理KV Cache内存,支持动态批处理请求,优化CUDA内核以充分利用GPU计算能力。
-
混合精度训练(Mixed Precision Training):
- vLLM支持混合精度训练,通过使用半精度(FP16)和浮点(FP32)模型加速训练过程,同时保持较高的计算效率。
-
多模态支持:
- vLLM支持多模态输入,可以处理文本和图像等多模态数据。例如,MiniCPM-V模型可以在vLLM框架下进行微调,以适应视觉语言任务。
-
指令微调(Instruction Tuning):
- vLLM支持指令微调,通过调整模型以更好地理解和执行特定的指令。这种方法在自然语言处理任务中非常有效。
-
前缀微调(Prefix Tuning):
- 前缀微调是一种通过添加固定长度的前缀向量来调整模型的方法,适用于需要快速适应新任务的场景。
-
提示微调(Prompt Tuning):
- 提示微调通过调整输入提示来优化模型的响应能力,适用于对话系统和其他需要灵活生成文本的任务。
-
混合专家(MoE, Mixture of Experts):
- vLLM支持混合专家模型,通过将模型分解为多个专家模块,每个模块处理特定类型的输入,从而提高模型的性能和效率。
- 多卡部署和GPU+CPU混合部署:
- vLLM支持多卡部署和GPU+CPU混合部署,以充分利用硬件资源,提高推理速度和吞吐量。
- 流式输出(Streaming Output):
- vLLM支持流式输出,适用于实时文本处理场景,可以连续处理接收到的请求,而不需要一次性加载所有数据。
- 兼容性与集成:
- vLLM与Hugging Face模型无缝集成,支持多种解码算法和分布式推理,兼容OpenAI API服务器接口。
vLLM通过多种微调和优化技术,提供了高效、灵活且强大的模型推理和服务能力,适用于各种应用场景。
在实际应用中,最常用于vLLM的微调技术是LoRA(Low-Rank Adaptation)。LoRA是一种参数高效微调(PEFT)方法,通过训练小型调整器来适应特定任务,从而显著减少计算资源和内存需求,同时保持模型质量。
LoRA微调技术的优势在于其高效性和灵活性。它允许在少量参数的情况下进行微调,这使得它特别适合于资源受限的环境和大规模模型的部署。例如,LoRA可以将大型基础模型的参数减少到原始模型的1%左右,同时在推理阶段共享基础模型的权重,从而实现高效的推理和部署。
LoRA微调技术还被广泛应用于多种场景,包括视觉语言模型(VLM)的安全性改进、多模态任务的优化以及特定领域的模型定制。例如,在安全性改进方面,通过LoRA微调可以显著提高视觉语言模型的安全性。在多模态任务中,LoRA也被用于优化视觉问答(VQA)任务的性能。

LoRA微调技术因其高效性、灵活性和广泛的应用场景,成为实际应用中最常用于vLLM的微调技术。
相关文章:
vllm的使用方式,入门教程
vLLM是一个由伯克利大学LMSYS组织开源的大语言模型推理框架,旨在提升实时场景下的大语言模型服务的吞吐与内存使用效率。以下是详细的vLLM使用方式和入门教程: 1. 前期准备 在开始使用vLLM之前,建议先掌握一些基础知识,包括操作…...

IDEA 使用codeGPT+deepseek
一、环境准备 1、IDEA 版本要求 安装之前确保 IDEA 处于 2023.x 及以上的较新版本。 2、Python 环境 安装 Python 3.8 或更高版本 为了确保 DeepSeek 助手能够顺利运行,您需要在操作系统中预先配置 Python 环境。具体来说,您需要安装 Python 3.8 或更高…...

vue3中测试:单元测试、组件测试、端到端测试
1、单元测试:单元测试通常适用于独立的业务逻辑、组件、类、模块或函数,不涉及 UI 渲染、网络请求或其他环境问题。 describe(increment, () > {// 测试用例 }) toBe():用于严格相等比较(),适用于原始类…...

机器学习介绍与数据集
一、机器学习介绍与定义 1.1 机器学习定义 机器学习(Machine Learning)是让计算机从数据中自动学习规律,并依据这些规律对未来数据进行预测的技术。它涵盖聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning…...
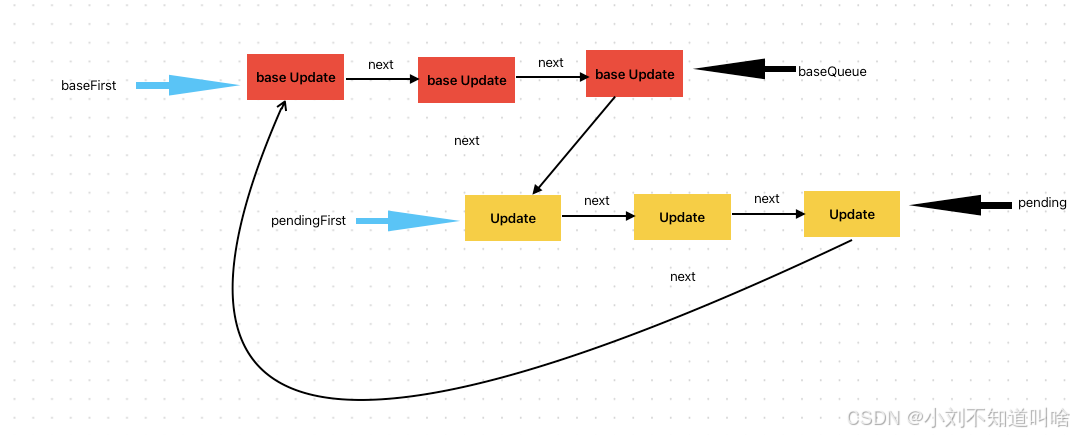
React 源码揭秘 | 更新队列
前面几篇遇到updateQueue的时候,我们把它先简单的当成了一个队列处理,这篇我们来详细讨论一下这个更新队列。 有关updateQueue中的部分,可以见源码 UpdateQueue实现 Update对象 我们先来看一下UpdateQueue中的内容,Update对象&…...

关于网络端口探测:TCP端口和UDP端口探测区别
网络端口探测是网络安全领域中的一项基础技术,它用于识别目标主机上开放的端口以及运行在这些端口上的服务。这项技术对于网络管理和安全评估至关重要。在网络端口探测中,最常用的两种协议是TCP(传输控制协议)和UDP(用…...

Vue.js 中使用 JSX 自定义语法封装组件
Vue.js 中使用 JSX 自定义语法封装组件 在 Vue.js 开发中,使用模板语法是常见的构建用户界面方式,但对于一些开发者,特别是熟悉 JavaScript 语法的,JSX 提供了一种更灵活、更具表现力的替代方案。通过 JSX,我们可以在…...
)
设计模式教程:备忘录模式(Memento Pattern)
备忘录模式(Memento Pattern)详解 一、模式概述 备忘录模式(Memento Pattern)是一种行为型设计模式,允许在不暴露对象实现细节的情况下,保存对象的内部状态,并在需要时恢复该状态。备忘录模式…...

使用 C# 以api的形式调用 DeepSeek
一:创建 API 密钥 首先,您需要来自 DeepSeek 的 API 密钥。访问 DeepSeek,创建一个帐户,并生成一个新的 API 密钥。 二:安装所需的 NuGet 包 使用 NuGet 包管理器安装包,或在包管理器控制台中运行以下命…...
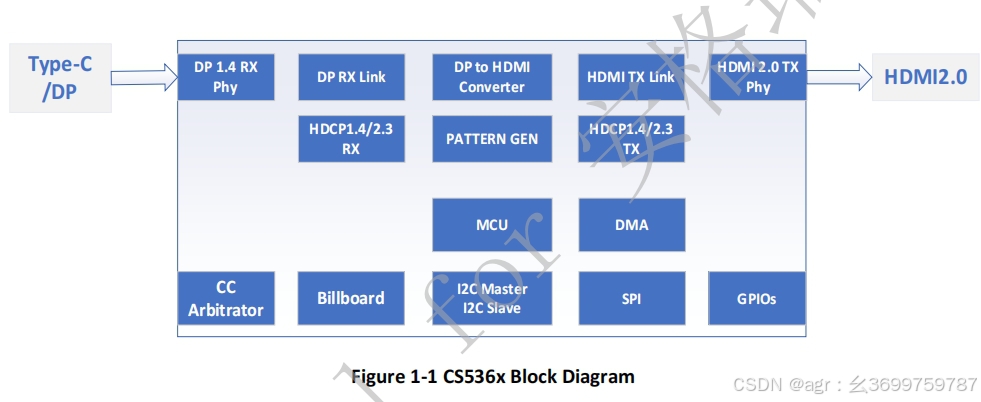
CS5366AN:高集成Type-C转HDMI 4K60Hz芯片的国产突破
一、芯片概述 CS5366AN 是集睿致远(ASL)推出的一款高度集成的 Type-C转HDMI 2.0视频转换芯片,专为扩展坞、游戏底座、高清显示设备等场景设计。其核心功能是将USB Type-C接口的DisplayPort信号(DP Alt Mode)转换为HDM…...

瑞芯微RK安卓Android主板GPIO按键配置方法,触觉智能嵌入式开发
触觉智能分享,瑞芯微RK安卓Android主板GPIO按键配置方法,方便大家更好利用空闲IO!由触觉智能Purple Pi OH鸿蒙开发板演示,搭载了瑞芯微RK3566四核处理器,树莓派卡片电脑设计,支持安卓Android、开源鸿蒙Open…...

Dify自定义工作流集成指南:对接阿里云百炼文生图API的实现方案
dify工作流的应用基本解释 dify应用发布相关地址:应用发布 | Dify 根据官方教程,我们可以看到dify自定义的工作流可以发布为----工具 这个教程将介绍如何通过工作流建立一个使用阿里云百炼文生图模型。 工具则可以给其他功能使用,如agent…...

前端项目配置 Nginx 全攻略
在前端开发中,项目开发完成后,如何高效、稳定地将其部署到生产环境是至关重要的一步。Nginx 作为一款轻量级、高性能的 Web 服务器和反向代理服务器,凭借其出色的性能和丰富的功能,成为了前端项目部署的首选方案。本文将详细介绍在…...
的【智能家居综合应用】系统)
基于开源鸿蒙(OpenHarmony)的【智能家居综合应用】系统
基于开源鸿蒙OpenHarmony的智能家居综合应用系统 1. 智能安防与门禁系统1) 系统概述2) 系统架构3)关键功能实现4)安全策略5)总结 2.环境智能调节系统1)场景描述2)技术实现3)总结 3.健康管理与睡眠监测1&…...

电子电气架构 --- 主机厂电子电气架构演进
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 简单,单纯,喜欢独处,独来独往,不易合同频过着接地气的生活,除了生存温饱问题之外,没有什么过多的欲望,表面看起来很高冷,内心热情,如果你身…...

物联网通信应用案例之《智慧农业》
案例概述 在智慧农业方面,一般的应用场景为可以自动检测温度湿度等一系列环境情况并且可以自动做出相应的处理措施如简单的浇水和温度控制等,且数据情况可远程查看,以及用户可以实现远程控制。 基本实现原理 传感器通过串口将数据传递到Wi…...

Java注解的原理
目录 问题: 作用: 原理: 注解的限制 拓展: 问题: 今天刷面经,发现自己不懂注解的原理,特此记录。 作用: 注解的作用主要是给编译器看的,让它帮忙生成一些代码,或者是帮忙检查…...

AI知识架构之神经网络
神经网络:这是整个内容的主题,是一种模拟人类大脑神经元结构和功能的计算模型,在人工智能领域广泛应用。基本概念:介绍神经网络相关的基础概念,为后续深入理解神经网络做铺垫。定义与起源: 神经网络是模拟人类大脑神经元结构和功能的计算模型,其起源于对生物神经系统的研…...

OpenGL 04--GLSL、数据类型、Uniform、着色器类
一、着色器 在 OpenGL 中,着色器(Shader)是运行在 GPU 上的程序,用于处理图形渲染管线中的不同阶段。 这些小程序为图形渲染管线的某个特定部分而运行。从基本意义上来说,着色器只是一种把输入转化为输出的程序。着色器…...

学习笔记06——JVM调优
JVM 调优实战:性能优化的技巧与实战 在 Java 开发中,JVM(Java Virtual Machine)作为 Java 程序的运行环境,其性能直接影响到应用程序的响应速度和吞吐量。合理的 JVM 调优可以显著提升应用性能,降低延迟&a…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...