DeepSeek推出DeepEP:首个开源EP通信库,让MoE模型训练与推理起飞!
今天,DeepSeek 在继 FlashMLA 之后,推出了第二个 OpenSourceWeek 开源项目——DeepEP。
作为首个专为MoE(Mixture-of-Experts)训练与推理设计的开源 EP 通信库,DeepEP 在EP(Expert Parallelism)领域迈出了重要一步,旨在为 MoE 模型提供低时延、高带宽、高吞吐的卡间和节点间通信能力。
根据测试结果,DeepEP 在节点内部的多卡通信中表现接近带宽上限,同时节点间通信效率也显著提升。
什么是EP?
在深入了解 DeepEP 之前,我们需要先理解什么是 EP。
EP 是一种专为 MoE 设计的分布式计算方法。而 MoE 是一种基于 Transformer 的模型架构,采用稀疏策略,使其相比传统的密集模型在训练时更加轻量化。在这种 MoE 神经网络架构中,每次仅使用模型中部分组件(称为“专家”)来处理输入。
这种方法具有多项优势,包括更高效的训练、更快的推理速度,即使模型规模更大依然如此。换句话说,在相同的计算资源预算下,与训练一个完整的密集模型相比,MoE 可以支持更大的模型或更大的数据集。
MoE 模型通过动态路由机制将输入分配到不同的专家子网络(Expert Sub-network),而 EP 则将这些专家子网络分配到多个计算设备上,从而显著提升大规模模型的计算效率。
四大主流分布式并行策略
目前,主流的分布式并行策略主要包括以下四种。
-
Data Parallelism (DP)
-
核心:复制模型副本,分割输入数据。
-
优势:实现简单,计算负载均衡。
-
限制:显存占用高,不适用于超大规模模型。
-
-
Tensor Parallelism (TP)
-
核心:矩阵维度切割,分布式存储参数。
-
优势:突破单卡显存限制。
-
限制:通信密集,需要高速互联。
-
-
Pipeline Parallelism (PP)
-
核心:模型分层流水作业。
-
优势:支持千亿级参数部署。
-
限制:存在计算间隙(流水线气泡)。
-
-
Expert Parallelism (EP)
-
核心:支持大参数的MoE模型高效推理和训练。
-
优势:有更好的模型切分灵活性,更加细粒度。
-
限制:只能在MoE模型上使用。
-
EP如何加速MoE模型推理?
EP 在大语言模型推理加速中的重要性源于其对 MoE 的高效切分能力。当模型采用 MoE 结构且专家数量达到数百量级(如 320 个专家)时,EP 可将不同专家分配到独立计算节点,其并行粒度与专家数量直接匹配。
相比之下,TP 依赖 Attention 层的多头机制切分(例如典型 32 头配置),在扩展到 64 卡及以上规模时,因切分维度不足(32 < 64)难以充分利用硬件资源。EP 通过专家维度的切分,TP一般按照 Attention Heads 的维度进行切分,切分出的数量只能是32的约数,使得超大规模集群(如 64+ 卡)的负载分配更均衡,从而实现更优的推理吞吐量。
DeepEP:专为 MoE 与 EP 定制的通信库
DeepEP 是一款专为 MoE 和 EP 定制的通信库,具备以下核心优势:
-
高效优化的 All-to-All 通信 DeepEP 提供了高效的 All-to-All 通信内核,能够显著减少数据传输的瓶颈,确保在分布式环境中不同专家之间的信息交换更加顺畅。
-
支持 NVLink 和 RDMA 的节点内 / 跨节点通信 DeepEP 支持 NVLink 和 RDMA 技术,能够实现节点内和跨节点的高效通信。NVLink 提供了高达 160 GB/s 的带宽,而 RDMA 则支持跨节点的低延迟数据传输,满足大规模分布式训练的需求。
-
高吞吐量计算核心 针对训练和推理预填充阶段,DeepEP 提供了高吞吐量的计算核心,确保在大规模数据处理时能够保持高效的计算性能。
-
低延迟计算核心 对于推理解码阶段,DeepEP 提供了基于 RDMA / Infiniband 的低延迟计算核心,最大限度地减少了推理延迟,适合对延迟敏感的应用场景。
-
原生支持 FP8 数据分发 DeepEP 原生支持 FP8 数据分发,能够在保持精度的同时减少数据传输量,进一步提升了通信效率。
-
灵活控制 GPU 资源 DeepEP 提供了灵活的 GPU 资源调度机制,能够实现计算与通信的高效重叠,避免资源浪费,提升整体性能。
DeepEP的性能表现
DeepEP 在节点内和跨节点通信中的性能表现显著,尤其在 NVLink 和 RDMA 混合架构下展现出高效的数据传输能力。DeepEP 在两种典型场景下的性能测试结果:
常规内核性能(NVLink 和 RDMA 转发)
-
测试环境:
-
GPU:H800(NVLink 最大带宽约 160 GB/s)
-
网络:CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)
-
配置:遵循 DeepSeek-V3/R1 预训练设置(每批次 4096 tokens,隐藏层 7168,top-4 组,top-8 专家,FP8 分发和 BF16 聚合)
-
-
性能数据:
-
节点内通信接近 NVLink 最大带宽(160 GB/s),表现出极高的数据传输效率。
-
跨节点通信在 RDMA 网络下保持稳定带宽,满足大规模分布式训练需求。

-
低延迟内核性能(纯 RDMA)
-
测试环境:
-
GPU:H800
-
网络:CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)
-
配置:遵循典型 DeepSeek-V3/R1 生产环境设置(每批次 128 tokens,隐藏层 7168,top-8 专家,FP8 分发和 BF16 聚合)
-
-
性能数据:
-
低延迟内核在纯 RDMA 模式下实现了微秒级延迟,适合对延迟敏感的推理解码任务。
-
即使在高并行度(#EP=256)下,RDMA 带宽仍保持稳定,确保高效的数据传输。

-
DeepEP的应用场景
DeepEP 适用于多种 MoE 模型的训练和推理场景,特别是在大规模分布式训练中,DeepEP 能够显著提升通信效率,减少训练时间。以下是 DeepEP 的主要应用场景:
MoE 模型训练 DeepEP 的高吞吐量计算核心和高效的 All-to-All 通信机制,能够显著加速 MoE 模型的训练过程,尤其是在多机多 GPU 环境下。
推理预填充阶段 在推理的预填充阶段,DeepEP 的高吞吐量计算核心能够快速处理大量数据,确保推理过程的高效性。
推理解码阶段 对于推理解码阶段,DeepEP 的低延迟计算核心能够最大限度地减少推理延迟,适合对实时性要求较高的应用场景。
PPIO派欧云始终专注于探索多种并行策略,不断提升推理效率,旨在为客户提供更快的推理速度和更低的计算成本。
相关文章:
DeepSeek推出DeepEP:首个开源EP通信库,让MoE模型训练与推理起飞!
今天,DeepSeek 在继 FlashMLA 之后,推出了第二个 OpenSourceWeek 开源项目——DeepEP。 作为首个专为MoE(Mixture-of-Experts)训练与推理设计的开源 EP 通信库,DeepEP 在EP(Expert Parallelism)…...

1.2 Kaggle大白话:Eedi竞赛Transformer框架解决方案02-GPT_4o生成训练集缺失数据
目录 0. 本栏目竞赛汇总表1. 本文主旨2. AI工程架构3. 数据预处理模块3.1 配置数据路径和处理参数3.2 配置API参数3.3 配置输出路径 4. AI并行处理模块4.1 定义LLM客户端类4.2 定义数据处理函数4.3 定义JSON保存函数4.4 定义数据分片函数4.5 定义分片处理函数4.5 定义文件名排序…...
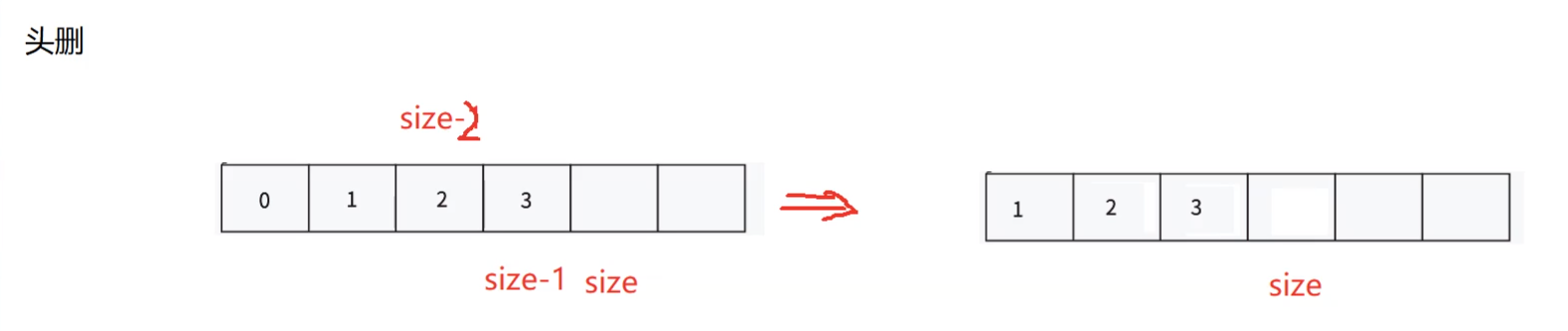
数据结构-顺序表专题
大家好!这里是摆子,今天给大家带来的是C语言数据结构开端-顺序表专题,主要介绍了数据结构和动态顺序表的实现,快来看看吧!记得一键三连哦! 1.数据结构的概念 1.1什么是数据结构? 数据结构是计…...

docker和containerd从TLS harbor拉取镜像
私有镜像仓库配置了自签名证书,https访问,好处是不需要处理免费证书和付费证书带来的证书文件变更,证书文件变更后需要重启服务,自签名证书需要将一套客户端证书存放在/etc/docker/cert.d目录下,或者/etc/containerd/c…...

kafka-关于ISR-概述
一. 什么是ISR ? Kafka 中通常每个分区都有多个副本,其中一个副本被选举为 Leader,其他副本为 Follower。ISR 是指与 Leader 副本保持同步的 Follower 副本集合。ISR 机制的核心是确保数据在多个副本之间的一致性和可靠性,同时在 …...

el-input实现金额输入
需求:想要实现一个输入金额的el-input,限制只能输入数字和一个小数点。失焦数字转千分位,聚焦转为数字,超过最大值,红字提示 效果图 失焦 聚焦 报错效果 // 组件limitDialog <template><el-dialog:visible.s…...

C++11智能指针
一、指针管理的困境 资源释放了,但指针没有置空(野指针、指针悬挂、踩内存) 没有释放资源,产生内存泄漏问题;重复释放资源,引发coredump 二、智能指针...

安装Git(小白也会装)
一、官网下载:Git 1.依次点击(红框) 不要安装在C盘了,要炸了!!! 后面都 使用默认就好了,不用改,直接Next! 直到这里,选第一个 这两种选项的区别如…...

驭势科技9周年:怀揣理想,踏浪前行
2025年的2月,驭势科技迎来9岁生日。位于国内外不同工作地的Uiseeker齐聚线上线下,共同庆祝驭势走过的璀璨九年。 驭势科技联合创始人、董事长兼CEO吴甘沙现场分享了驭势9年的奔赴之路,每一段故事都包含着坚持与拼搏。 左右滑动查看更多 Part.…...

一款在手机上制作电子表格
今天给大家分享一款在手机上制作电子表格的,免费好用的Exce1表格软件,让工作变得更加简单。 1 软件介绍 Exce1是一款手机制作表格的办公软件,您可以使用手机exce1在线制作表格、工资表、编辑xlsx和xls表格文件等,还可以学习使用…...

Python解决“比赛配对”问题
Python解决“比赛配对”问题 问题描述测试样例解决思路代码 问题描述 小R正在组织一个比赛,比赛中有 n 支队伍参赛。比赛遵循以下独特的赛制: 如果当前队伍数为 偶数,那么每支队伍都会与另一支队伍配对。总共进行 n / 2 场比赛,…...

【AI论文】RAD: 通过大规模基于3D图形仿真器的强化学习训练端到端驾驶策略
摘要:现有的端到端自动驾驶(AD)算法通常遵循模仿学习(IL)范式,但面临着因果混淆和开环差距等挑战。在本研究中,我们建立了一种基于3D图形仿真器(3DGS)的闭环强化学习&…...

Web开发:ORM框架之使用Freesql的导航属性
一、什么时候用导航属性 看数据库表的对应关系,一对多的时候用比较好,不用多写一个联表实体,而且查询高效 二、为实体配置导航属性 1.给关系是一的父表实体加上: [FreeSql.DataAnnotations.Navigate(nameof(子表.子表关联字段))]…...

【docker】namespace底层机制
Linux 的 Namespace 机制是实现容器化(如 Docker、LXC 等)的核心技术之一,它通过隔离系统资源(如进程、网络、文件系统等)为进程提供独立的运行环境。其底层机制涉及内核数据结构、系统调用和进程管理。以下是其核心实…...

【每天认识一个漏洞】url重定向
🌝博客主页:菜鸟小羊 💖专栏:Linux探索之旅 | 网络安全的神秘世界 | 专接本 | 每天学会一个渗透测试工具 常见应用场景 主要是业务逻辑中需要进行跳转的地方。比如登录处、注册处、访问用户信息、订单信息、加入购物车、分享、收…...

端口映射/内网穿透方式及问题解决:warning: remote port forwarding failed for listen port
文章目录 需求:A机器是内网机器,B机器是公网服务器,想要从公网,访问A机器的端口方式:端口映射,内网穿透,使用ssh打洞端口:遇到问题:命令执行成功,但是端口转发…...

Polardb开发者大会
这是第二次参加这个大会 还有不少老朋友 好多年没有这种经历了–大会讲的我不是很懂 10几年前参会,那时候自己不懂。后来就慢慢懂了。这些年参会都虽然还在不断学习,但是没觉得自己差距很大了。 这次出来很不一样,一堆新的技能,这…...

从二维随机变量到多维随机变量
二维随机变量 设 X X X和 Y Y Y是定义在同一样本空间 Ω \varOmega Ω上的两个随机变量,称由它们组成的向量 ( X , Y ) (X, Y) (X,Y)为二维随机变量,亦称为二维随机向量,其中称 X X X和 Y Y Y是二维随机变量的分量。 采用多个随机变量去描述…...

Vulnhub靶场 Kioptrix: Level 1.3 (#4) 练习
目录 0x00 环境准备0x01 主机信息收集0x02 站点信息收集0x03 漏洞查找与利用0x04 总结 0x00 环境准备 下载:https://download.vulnhub.com/kioptrix/Kioptrix4_vmware.rar 解压后得到的是vmdk文件。在vm中新建虚拟机,稍后安装操作系统,系统选…...

权重生成图像
简介 前面提到的许多生成模型都有保存了生成器的权重,本章主要介绍如何使用训练好的权重文件通过生成器生成图像。 但是如何使用权重生成图像呢? 一、参数配置 ima_size 为图像尺寸,这个需要跟你模型训练的时候resize的时候一样。 latent_dim为噪声维度,一般的设置都是…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

taotoken用量看板如何帮助团队精细化管理api调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken用量看板如何帮助团队精细化管理api调用成本 对于团队管理者而言,将大模型能力集成到产品开发或业务流程中&am…...

Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍
Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神2中刷装备的漫长过程感到疲惫吗?Diablo Edit2这款免费…...