Redis7——进阶篇(一)
前言:此篇文章系本人学习过程中记录下来的笔记,里面难免会有不少欠缺的地方,诚心期待大家多多给予指教。
基础篇:
- Redis(一)
- Redis(二)
- Redis(三)
- Redis(四)
- Redis(五)
- Redis(六)
- Redis(七)
- Redis(八)
进阶篇:
- Redis(九)
接上期内容:上期完成了Redis基础篇的学习。下面开始学习Redis的进阶知识,话不多说,直接发车。
一、前提说明
进阶篇主要学习Redis面试中反复出现的经典问题以及与之紧密对应的实际操作。这一阶段的学习具有一定的挑战性,需要你具备扎实的Redis基础知识。如果你是零基础的新手,或者目前基础较为薄弱,建议你先移步基础篇。待你在基础篇中积累了足够的知识和经验,再信心满满地回归,向进阶篇发起冲击。
二、经典面试题
(一)、多线程 VS 单线程
1、Redis是多线程还是单线程
答:分版本讨论。
redis版本为3.x ,redis是单线程。
redis版本4.x,严格意义来说也不是单线程,而是负责处理客户端请求的线程是单线程,但是开始加了点多线程的东西(异步删除)。
2020年5月版本的6.0.x后及2022年出的7.0版本后,告别了大家印象中的单线程,用一种全新的多线程来解决问题

*总结:分版本讨论。Redis6.x之前都可以称单线程,Redis6.x之后是多线程(这个多线程主要是用于处理网络 I/O 操作,而键值对的读写操作仍然是单线程的)。
2、Redis的单线程指的什么?
答:Redis单线程指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。

但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。
*总结:单线程指的是Redis命令工作线程,但是,整个Redis(6.x之后)来说,是多线程的。
3、Redis4.x之前为啥选择单线程?
答:①、使用单线程模型是Redis的开发和维护更简单,因为单线程模型方便开发和调试。
②、单线程避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生。
③、即使使用单线程模型也并发的处理多客户端的请求,主要使用的是IO多路复用和非阻塞IO。
④、对于Redis系统来说,主要的性能瓶颈是内存或者网络带宽而并非 CPU。

4、既然单线程这么好,为啥又逐渐引入多线程?
答:单线程虽好,但也不是全能。正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。这就是redis3.x单线程时代最经典的故障,大key删除的问题。
于是在 Redis 4.x 中就新增了多线程的模块,当然此版本中的多线程主要是为了解决删除数据效率比较低的问题的,比如unlink key、flushdb async、flushall async命令。
*总结:逐渐引入多线程是为了弥补单线程的短板,比如删除bigKey问题。
(二)、I/O多路复用
1、什么是I/O多路复用?
答:①、I/O一般在操作系统层面指数据在内核态和用户态之间的读写操作。
②、多路指多个客户端连接(连接就是套接字描述符,即 socket 或者 channel)。
③、复用指复用一个或几个线程
*总结:在Redis中的I/O多路复用指一个或一组线程处理多个TCP连接,使用单进程就能够实现同时处理多个客户端的连接,无需创建或者维护过多的进程/线程。
在Unix网络编程中的I/O多路复用指的是一种同步的IO模型,实现一个线程多个文件句柄,一旦某个文件句柄就绪就能够通知到对应应用程序进行相应的读写操作,没有文件句柄就绪时就会阻塞应用程序,从而释放CPU资源。

后续会深入研究。
2、主线程和IO线程如何协作完成请求?
答:
阶段一:服务端和客户端建立Socket连接,并分配处理线程
首先,主线程负责接收建立连接请求,当有客户端请求和实例建立Socket连接时,主线程会创建和客户端的连接,并把 Socket 放入全局等待队列中。紧接着,主线程通过轮询方法把Socket连接分配给IO线程。
阶段二:IO线程读取并解析请求
主线程一旦把 Socket 分配给IO线程,就会进入阻塞状态,等待IO线程完成客户端请求读取和解析。因为有多个IO线程在并行处理,所以,这个过程很快就可以完成。
阶段三:主线程执行请求操作
等到IO线程解析完请求,主线程还是会以单线程的方式执行这些命令操作。
阶段四:IO线程回写 Socket 和主线程清空全局队列
当主线程执行完请求操作后,会把需要返回的结果写入缓冲区,然后,主线程会阻寨等待IO线程,把这些结果回写到 Socket 中,并返回给客户端。和IO线程读取和解析请求一样,IO线程回写 Socket 时,也是有多个线程在并发执行,所以回写 Socket 的速度也很快。等到IO线程回写 Socket 完毕,主线程会清空全局队列,等待客户端的后续请求。

*总结:Redis6.x之后将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。

(三)、Redis为什么这么快?
答:①、基于内存操作:Redis 的所有数据都存在内存中,因此所有的运算都是内存级别的,所以他的性能比较高;
②、高效的数据结构:Redis 的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是 O(1),因此性能比较高;
③、I/O多路复用和非阻塞 I/O:Redis 使用 I/O多路复用功能来监听多个 Socket 连接客户端,这样就可以使用一个线程连接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作;
④、上下文切换少:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生。
三、Redis多线程实操
(一)、开启多线程
在Redis7的版本中,多线程模式默认是关闭的。

如果需要使用多线程功能,需要在redis.conf中完成两个设置:
1、设置io-thread-do-reads配置项改为yes,表示启动多线程。
2、io-threads设置线程个数。关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。
四、深入理解I/O多路复用和epoll
(一)、出现的背景
在处理并发多客户端连接的场景中,在多路复用技术出现之前,同步阻塞网络 I/O 模型是最简单且典型的方案。这种模式的核心特点是采用一个进程来处理一个网络连接,也就是对应一个用户请求。
优点:这种方式非常容易让人理解,写起代码来非常的自然,符合人的直线型思维
缺点:性能差,每个用户请求到来都得占用一个进程来处理,来一个请求就要分配一个进程跟进处理。随着客户端数量的不断增加,进程数量也会相应地急剧增长。每个进程都需要占用一定的系统资源,如内存、CPU 时间片等,这会导致系统资源的大量消耗,甚至可能出现资源耗尽的情况。
(二)、Unix网络编程中的五种IO模型
1、Blocking IO(阻塞式 IO)
在这种模型下,当一个应用程序执行 IO 操作时,例如读取数据,进程会一直处于阻塞状态,直到数据准备好并且被成功读取到缓冲区中才会继续执行后续的代码。也就是说,在等待数据的过程中,进程无法进行其他任何操作,只能等待。
2、Non-Blocking IO(非阻塞式 IO)
与阻塞式 IO 不同,当应用程序执行 IO 操作时,如果数据尚未准备好,系统不会让进程进入阻塞状态,而是立即返回一个错误信息,告知当前数据未准备就绪。应用程序可以在不被阻塞的情况下,继续执行其他任务,并通过不断轮询的方式来检查数据是否准备好,从而决定是否再次尝试进行 IO 操作。
3、IO multiplexing(IO 多路复用)
该模型允许一个进程同时监视多个文件描述符(fd)的状态变化。它通过使用特定的函数(如 select、poll、epoll 等)来监听多个文件描述符,当其中任何一个文件描述符上有数据可读或可写时,函数会返回相应的信息,进程就可以对这些就绪的文件描述符进行对应的 IO 操作。这种方式有效地提高了系统资源的利用率,避免了在多个文件描述符上进行阻塞式 IO 操作时可能出现的资源浪费。
4、signal driven IO(信号驱动式 IO)(暂不涉及)
5、asynchronous IO(异步式 IO)(暂不涉及)
(三)、四种状态理解
1、同步(Synchronous)
同步是一种操作模式,在这种模式下,当一个任务(比如函数调用、IO 操作等)被发起后,调用者(通常是进程或线程)会一直等待该任务的完成,期间不会执行其他相关操作。只有当任务执行结束并返回结果后,调用者才会继续执行后续的代码
2、异步(Asynchronous)
异步与同步相反,当一个任务被发起后,调用者不会等待任务的完成,而是立即继续执行后续的代码。任务在后台由系统或其他线程进行处理,当任务完成时,系统会以某种方式(如回调函数、事件通知等)告知调用者任务已完成。
3、阻塞(Blocking)
阻塞状态主要用于描述进程或线程在执行某些操作时的行为。当一个进程或线程执行一个阻塞操作(如阻塞式的 IO 操作)时,它会暂停自身的执行,进入等待状态,直到操作完成(例如数据读取完毕或写入成功)才会继续执行后续代码。
4、非阻塞(Non-Blocking)
非阻塞意味着进程或线程在执行某些操作时,不会因为操作未完成而被暂停。如果操作不能立即完成,系统会立即返回一个状态信息(如错误码或表示操作未完成的标识),进程或线程可以继续执行其他任务。
5、组合
在实际的编程场景中,这四种状态常常会以不同的组合形式出现。例如:
- 同步阻塞:最常见的传统操作模式,比如同步文件读取操作,在读取过程中进程被阻塞,等待文件读取完成。
- 同步非阻塞:虽然操作是同步的(需要等待操作结果),但操作本身是非阻塞的,调用者需要不断轮询检查操作是否完成。
- 异步阻塞:这种情况相对较少见,理论上异步操作不应该阻塞调用者,但在某些特殊情况下,例如在异步操作完成前,调用者可能因为等待异步操作的结果而被阻塞(比如等待回调函数执行完毕)。
- 异步非阻塞:这是一种理想的高效模式,任务在后台异步执行,调用者不会被阻塞,可以继续执行其他任务,并且当任务完成时,系统会通过合适的方式通知调用者。
*总结:同步、异步的讨论对象是被调用者(服务提供者),重点在于获得调用结果的消息通知方式上。阻塞、非阻塞的讨论对象是调用者(服务请求者),重点在于等消息时候的行为,调用者是否能干其它事。
(四)、BIO、NIO实操
打算模拟一台Redis服务器,两台两台客户端来完成接下来两种模式的实操。
1、BIO(阻塞式IO)
1.1、前提说明
了解一个专业词汇,recvfrom。

1.2、模型图

解释:当用户进程调用了recvfrom这个系统调用,kernel(内核)就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。所以,BIO的特点就是在IO执行的两个阶段都被block了。
1.3、代码验证
1、单线程
RedisServer:
public class RedisServer {public static void main(String[] args) throws IOException {try (ServerSocket serverSocket = new ServerSocket(6379);) {while (true) {System.out.println("-----111 等待连接");Socket socket = serverSocket.accept();//阻塞1 ,等待客户端连接System.out.println("-----222 成功连接");InputStream inputStream = socket.getInputStream();int length = -1;byte[] bytes = new byte[1024];System.out.println("-----333 等待读取");while ((length = inputStream.read(bytes)) != -1)//阻塞2 ,等待客户端发送数据{System.out.println("-----444 成功读取" + new String(bytes, 0, length));System.out.println("====================");System.out.println();}inputStream.close();socket.close();}}}}RedisClient01和RedisClient02:
public class RedisClient01 {public static void main(String[] args) throws IOException {try (Socket socket = new Socket("127.0.0.1", 6379);OutputStream outputStream = socket.getOutputStream()) {while (true) {Scanner scanner = new Scanner(System.in);String string = scanner.next();if (string.equalsIgnoreCase("quit")) {break;}socket.getOutputStream().write(string.getBytes());System.out.println("------input quit keyword to finish......");}}}
}先启动serve,在启动client,进行测试:

结论:上面的模型存在很大的问题,如果客户端与服务端建立了连接,如果这个连接的客户端迟迟不发数据,主线程就会一直堵塞在read()方法上,这样其他客户端也不能进行连接,也就是一次只能处理一个客户端,对客户端很不友好。
解决办法:使用多线程模型解决主线程堵塞问题。
2、多线程
RedisServerBIOMultiThread:
public class RedisServerBIOMultiThread {public static void main(String[] args) throws IOException {try (ServerSocket serverSocket = new ServerSocket(6379);) {while (true) {System.out.println("-----111 等待连接");Socket socket = serverSocket.accept();//阻塞1 ,等待客户端连接System.out.println("-----222 成功连接");new Thread(() -> {try {InputStream inputStream = socket.getInputStream();int length = -1;byte[] bytes = new byte[1024];System.out.println("-----333 等待读取");while ((length = inputStream.read(bytes)) != -1)//阻塞2 ,等待客户端发送数据{System.out.println("-----444 成功读取" + new String(bytes, 0, length));System.out.println("====================");System.out.println();}inputStream.close();socket.close();} catch (IOException e) {e.printStackTrace();}}, Thread.currentThread().getName()).start();System.out.println(Thread.currentThread().getName());}}}
}RedisClient01和RedisClient02不改变。先启动serve,在启动client,进行测试:

结论:多线程模型确实解决了单线程模型的问题。但是每来一个客户端,就要开辟一个线程,如果来1万个客户端,那就要开辟1万个线程。在操作系统中用户态不能直接开辟线程,需要调用内核来创建的一个线程。这其中还涉及到用户状态的切换(上下文的切换),十分耗资源。
解决办法:
①、使用线程池。但是线程池在客户端连接少的情况下可以使用,但是用户量大的情况下,你不知道线程池要多大,太大了内存可能不够,也不可行。
②、使用NIO(非阻塞式IO)方式。因为read()方法堵塞了,所有要开辟多个线程,如果什么方法能使read()方法不堵塞,这样就不用开辟多个线程了,这就用到了另一个IO模型,NIO(非阻塞式IO)。
1.4、BIO优劣势总结
优势:
- 实现简单:编程模型简单直观,对于初学者和简单应用场景,能快速完成系统搭建。
- 可靠性高:阻塞机制使程序执行流程清晰,降低了并发问题出现的概率,保证了程序的可靠性。
劣势:
- 性能瓶颈:高并发场景下,每个连接需独立线程处理,随着连接数增加,线程数量增多,会大量消耗系统资源(如 CPU、内存),且线程创建、销毁和上下文切换会带来额外开销。
- 可扩展性差:受线程数量限制,难以处理大规模并发连接,当并发数超过系统承受能力,会导致性能急剧下降甚至系统崩溃。
很明显这种模式不适合Redis的定位。
2、NIO(非阻塞式IO)
2.1、前提说明
在传统的 BIO(Blocking I/O)模式中,服务器会为每个新接入的客户端连接单独分配一个线程来处理。随着客户端数量的增多,大量线程会被创建,这不仅会导致系统资源的过度消耗,还会因频繁的线程上下文切换而降低性能。为有效解决这一问题,可将多个客户端的Socket连接统一存放在容器中进行管理,以实现对资源的高效利用和连接的统一调度,为此NIO模型诞生。
在NIO模式中,一切都是非阻塞的:
accept()方法是非阻塞的,如果没有客户端连接,就返回无连接标识。read()方法是非阻塞的,如果。
read()方法读取不到数据就返回空闲中标识,如果读取到数据时,只阻塞read()方法读数据的时间。
在NIO模式中,只有一个线程:当一个客户端与服务端进行连接,这个socket就会加入到一个数组中,隔一段时间遍历一次,看这个socket的read()方法能否读到数据,这样一个线程就能处理多个客户端的连接和读取了。
2.2、模型图

解释:当用户进程发出read操作时,如果kernel(内核)中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。所以,NIO特点是用户进程需要不断的主动询问内核数据准备好了吗?一句话,用轮询替代阻塞!
2.3、代码验证
新建RedisServerNIO:
public class RedisServerNIO {// 模拟Socket容器static ArrayList<SocketChannel> socketList = new ArrayList<>();//模拟数据报存储空间static ByteBuffer byteBuffer = ByteBuffer.allocate(1024);public static void main(String[] args) throws IOException {try (ServerSocketChannel serverSocket = ServerSocketChannel.open()) {System.out.println("---------RedisServerNIO 启动等待中......");serverSocket.bind(new InetSocketAddress("127.0.0.1", 6379));serverSocket.configureBlocking(false);//设置为非阻塞模式while (true) {// 轮询容器for (SocketChannel element : socketList) {int read = element.read(byteBuffer);if (read > 0) {System.out.println("-----读取数据: " + read);byteBuffer.flip();byte[] bytes = new byte[read];byteBuffer.get(bytes);System.out.println(new String(bytes));byteBuffer.clear();}}SocketChannel socketChannel = serverSocket.accept();if (socketChannel != null) {System.out.println("-----成功连接: ");socketChannel.configureBlocking(false);//设置为非阻塞模式socketList.add(socketChannel);System.out.println("-----socketList size: " + socketList.size());}}}}
}RedisClient01和RedisClient02不改变。先启动serve,在启动client,进行测试:

结论:NIO成功的解决了BIO需要开启多线程的问题。在NIO中虽然一个线程就能解决多个socket,但是还存在其他2个问题。
Q1:这个模型在客户端少的时候十分好用,但是客户端如果很多,性能如何?
在有1万个客户端连接的情况下,每次循环都要遍历全部1万个Socket。即便只有10个Socket有数据,但需要遍历1万次,那9990次遍历就是浪费资源的系统调用。
Q2:这个遍历过程是在用户态进行的,用户态判断socket是否有数据还是调用内核的read()方法实现的,这就涉及到用户态和内核态的切换,每遍历一个就要切换一次,开销依旧很大。
2.4、NIO优劣势总结
优势:
- 资源利用率相比于BIO高:由于线程不会因 I/O 操作而长时间阻塞,系统可以使用更少的线程来处理更多的连接,减少了线程创建和上下文切换的开销,从而提高了资源的利用率。
- 实时性好:线程可以在发起读或写操作后立即返回,不用等待数据传输完成。
劣势:
- 可靠性问题:在高并发场景下,可能慧出现空轮询问题,需要进行额外的处理和优化。
- 编程复杂度高:NIO 的编程模型相对复杂,要处理各种复杂的事件和状态变化,增加了开发和调试的难度。
很明显这种模式也不是Redis的最优选择。
(五)、IO多路复用
1、定义
I/O 多路复用是一种让单个线程能够同时监视多个文件描述符(如套接字)的 I/O 状态变化的机制。当其中任何一个或多个文件描述符就绪(可读、可写或发生异常)时,程序能够及时感知并进行相应的 I/O 操作。
2、模型图

解释:IO multiplexing就是我们说的select,poll,epoll,有些技术书籍也称这种IO方式为event driven IO事件驱动IO。就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。可以基于一个阻塞对象并同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程,每次new一个线程),这样可以大大节省系统资源。所以,I/O 多路复用的特点是通过一种机制使得一个进程能同时等待多个文件描述符而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select,poll,epoll等函数就可以返回。
3、具体实现
前提说明:由于这三个函数都是C语言的内容,不做深入研究,大概了解原理即可。
3.1、select
①、定义
select(2) - Linux manual page可以在Linux上通过man手册参看,也可以通过Linux官网查看,select(2) - Linux manual page

②、核心思想
通过设置一个文件描述符集合(实际上是一个bitmap),调用 select 函数时将该集合从用户空间复制到内核空间,内核检查集合中的文件描述符状态,当有文件描述符就绪时,select 返回,程序再遍历集合来确定哪些文件描述符就绪。类似于我们自己写的这段Java代码。

③、执行流程
- select是一个阻塞函数,当没有数据时,会一直阻塞在select那一行。
- 当有数据时会将rset中对应的那一位置为1。
- select函数返回,不再阻塞。
- 遍历文件描述符数组,判断哪个fd被置位了。
- 读取数据,然后处理。
④、优缺点
优:
- 是最早的 I/O 多路复用实现,几乎在所有操作系统上都有支持,具有良好的跨平台性。
- 用户态和内核态不用频繁切换,节省系统资源。
缺:
- 能监视的文件描述符数量有限(通常受限于 FD_SETSIZE),最大1024。
- rset每次循环都必须重新置位为0,不可重复使用。
- 每次调用select都需要进行用户空间和内核空间的文件描述符集合复制,开销较大。
- 需要遍历整个文件描述符集合来查找就绪的文件描述符,时间复杂度为 O (n)。
⑤、小总结
select方式,虽然做到了一个线程处理多个客户端连接(文件描述符),同时又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + N次就绪状态的文件描述符的 read 系统调用),但也有一定的优化空间。
3.2、poll
①、定义
可以在Linux上通过man手册参看,也可以通过Linux官网查看,poll(2) - Linux manual page

②、核心思想
优化掉了select的前两个缺点。
③、执行流程
- 将fd数组从用户态拷贝到内核态。
- poll为阻塞方法,执行pol方法,如果有数据会将fd对应的revents置为pollin。
- poll方法返回。
- 循环遍历,查找那个fd被置位为pollin了。
- 将revents重置为0,便于复用。
- 遍历fd,找到置位的fd进行读取和处理。
④、优缺点
优:
- poll使用pollfd数组来代替select中的bitmap,解决了select文件描述符数量限制的问题。
- 当pollfds数组中有事件发生,相应的revents置位为1,遍历的时候又置位回零,实现了pollfd数组的重用。
缺:
- pollfds数组拷贝到了内核态,仍然有开销。
- 每次调用 poll 后仍需要遍历整个数组来查找就绪的文件描述符,时间复杂度为 O (n)。
⑤、小总结
相比于select,虽做了优化,但是原理基本一致。核心问题并没有解决掉。
3.3、epoll
①、定义
可以在Linux上通过man手册参看,也可以通过Linux官网查看,epoll(7) - Linux manual page

②、核心思想
使用红黑树来管理注册的文件描述符,用链表来存储就绪的文件描述符。通过 epoll_create 创建一个 epoll 实例,epoll_ctl 用于添加、修改或删除文件描述符的监视事件,epoll_wait 等待就绪的文件描述符,彻底优化掉select、poll没解决掉的问题。
③、执行流程
- 首先epoll是非阻塞的,当有数据的时候,会把相应的文件描述符“置位”,但是epool没有revent标志位,所以并不是真正的置位,这时候会把有数据的文件描述符放到队首。
- epoll会返回有数据的文件描述符的个数。
- 根据返回的个数,读取前N个文件描述符即可。(重点:不是全部遍历)
- 读取、处理。
④、优缺点
优:
- select、poll具备的优点,epoll都有。
- epoll_wait只返回就绪的文件描述符,无需遍历所有注册的文件描述符,时间复杂度为 O (1)。
- epoll仅注册时进行一次用户空间到内核空间的复制,而select、poll都是两次。
缺:Linux 系统特有的,不具备跨平台性。
⑤、小总结
epoll在 Linux 系统的高并发场景下表现出色,是一种非常先进的 I/O 多路复用实现。这也是Redis为啥这么快的根本原因所在。
五、epoll在Redis中的体现
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次放到文件事件分派器,事件分派器将事件分发给事件处理器。
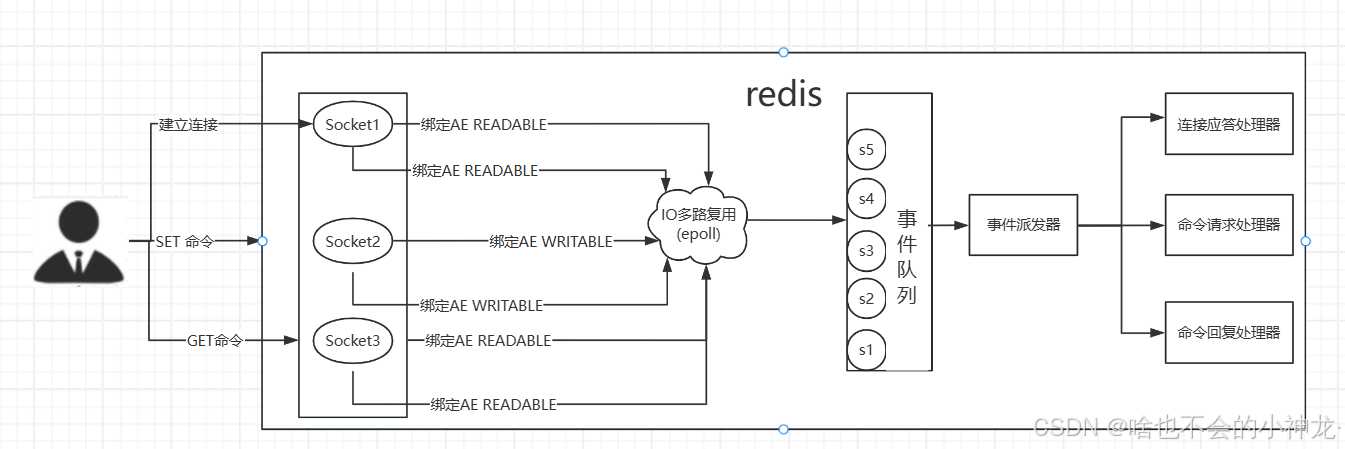
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现。
此外Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)。
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。

参考《Redis 设计与实现》。
六、总结
在对 Redis 的进阶知识学习时,通过将一些经典面试题拆分、细化、理解的方法,开展了系统性的研究与学习,使我对 Redis 的理解有了新的深度,为以后找工作又打了夯实的基础。
ps:努力到底,让持续学习成为贯穿一生的坚守。学习笔记持续更新中。。。。
相关文章:
Redis7——进阶篇(一)
前言:此篇文章系本人学习过程中记录下来的笔记,里面难免会有不少欠缺的地方,诚心期待大家多多给予指教。 基础篇: Redis(一)Redis(二)Redis(三)Redis&#x…...

word转换为pdf后图片失真解决办法、高质量PDF转换方法
1、安装Adobe Acrobat Pro DC 自行安装 2、配置Acrobat PDFMaker (1)点击word选项卡上的Acrobat插件,(2)点击“首选项”按钮,(3)点击“高级配置”按钮(4)点…...

Kafka零拷贝
Kafka为什么适用零拷贝,其他存储结构不适用? Kafka 采用的是日志存储模型,数据通常是顺序写入、顺序读取,并且它的消费模式是 “读完即走”(一次性读取并发送给消费者),这与零拷贝的特性完美匹…...

鸿蒙应用开发入门教程
鸿蒙应用开发入门教程 基础准备与环境搭建 1. 了解鸿蒙系统 1.1 核心理念学习 HarmonyOS(鸿蒙系统)是华为推出的全场景分布式操作系统,其核心特点如下: 分布式能力 设备协同:手机、平板、智能手表、IoT设备等可无…...

【2022——暴力DP / 优雅背包】
题目 代码 #include <bits/stdc.h> using namespace std; using ll long long;const int N 2023;ll f[2][2023][2023];int main() {f[0][0][0] 1;for(int i 1; i < 10; i) //次数{for(int j 0; j< 2022; j)for(int k 0; k < 2022; k)f[i&1][j][k] 0…...

AI智能体与大语言模型:重塑SaaS系统的未来航向
在数字化转型的浪潮中,软件即服务(SaaS)系统一直是企业提升效率、优化业务流程的重要工具。随着AI智能体和大语言模型(LLMs)的迅速发展,SaaS系统正迎来前所未有的变革契机。本文将从AI智能体和大语言模型对…...

绕过密码卸载360终端安全管理系统
一不小心在电脑上安装了360终端安全管理系统,就会发现没有密码,就无法退出无法卸载360,很容易成为一个心病,360终端安全管理系统,没有密码,进程无法退出,软件无法卸载,前不久听同事说…...

golang安装(1.23.6)
1.切换到安装目录 cd /usr/local 2.下载安装包 wget https://go.dev/dl/go1.23.6.linux-amd64.tar.gz 3.解压安装包 sudo tar -C /usr/local -xzf go1.23.6.linux-amd64.tar.gz 4.配置环境变量 vi /etc/profile export PATH$…...

星闪开发入门之常见报错整理(一)
系列文章目录 星闪开发入门之常见报错整理(一) 文章目录 系列文章目录前言一、ComX open fail, please check com is busy or not exist二、CMake下载失败三、配置文件出现语法错误四、路径过长导致编译报错五、ninja: build stopped: subcommand fai…...

Node.js与MySQL的深入探讨
Node.js与MySQL的深入探讨 引言 Node.js,一个基于Chrome V8引擎的JavaScript运行时环境,以其非阻塞、事件驱动的方式在服务器端应用中占据了一席之地。MySQL,作为一款广泛使用的开源关系型数据库管理系统,凭借其稳定性和高效性,成为了许多应用的数据库选择。本文将深入探…...

【JAVA】阿里云百炼平台对接DeepSeek-V3大模型使用详解
1、DeepSeek简介 DeepSeek的火热让全世界见证了一场国产AI大模型走向巅峰的盛宴。DeepSeek的横空出世一方面让AI大模型的格局得到重塑,另一方面,对于普通人来说,也有机会零距离的体验到更懂国人的AI大模型。从很多使用过后的小伙伴们的反馈来…...

springboot项目部署脚本
Springboot部署脚本 该脚本可用于jenkins自动执行,具有以下功能 适配所有以内嵌tomcat容器springboot项目jar包可根据参数选择环境,基于profiles可自动识别并关闭已存在进程第一个参数是指定jar包所在绝对路径(该路径下必须有且仅有一个.jar文件) 第二…...

黑马Java面试教程_P5_微服务
系列博客目录 文章目录 系列博客目录1.引言2.Spring Cloud2.1 Spring Cloud 5大组件有哪些?面试文稿 2.2 服务注册和发现是什么意思?Spring Cloud 如何实现服务注册发现?面试文稿 2.3 我看你之前也用过nacos、你能说下nacos与eureka的区别?面试文稿 2.4 你们项目负载均衡如…...

使用Fuse-DFS挂载文件存储 HDFS-后端存储ceph
1. 编译环境准备 yum install cmake3 ln -s /usr/bin/cmake3 /usr/bin/cmake yum install gcc-c安装挂载依赖 yum -y install fuse fuse-devel fuse-libs执行以下命令,载入FUSE模块 modprobe fuse2. 下载源码包 hadoop-3.3.4-src.tar.gz解压后执行以下命令 打开…...

生成式AI项目的生命周期
总结自视频(吴恩达大模型入门课):9_13_generative-ai-project-lifecycle_哔哩哔哩_bilibili 生成周期如下图,包含四部分:任务范围(Scope),选择大模型(Select)…...

SOC-ATF 安全启动BL1流程分析(1)
一、ATF 源码下载链接 1. ARM Trusted Firmware (ATF) 官方 GitHub 仓库 GitHub 地址: https://github.com/ARM-software/arm-trusted-firmware 这是 ATF 的官方源码仓库,包含最新的代码、文档和示例。 下载方式: 使用 Git 克隆仓库: git…...

游戏引擎学习第127天
仓库:https://gitee.com/mrxiao_com/2d_game_3 为本周设定阶段 我们目前的渲染器已经实现了令人惊讶的优化,经过过去两周的优化工作后,渲染器在1920x1080分辨率下稳定地运行在60帧每秒。这个结果是意料之外的,因为我们没有预计会达到这样的…...

Grafana使用日志7--开启Sigv4
背景 在Grafana中,有些data source是需要开启sigv4认证的,例如OpenSearch,这个配置项默认是关闭的,这里我们介绍一下怎么开启 步骤 传统方式 如果我们想在Grafana中开启sigv4认证,我们需要在grafana.ini中修改一个…...

UWB人员定位:精准、高效、安全的智能管理解决方案
在现代企业管理、工业生产、安全监测等领域,UWB(超宽带)人员定位系统正逐步成为高精度定位技术的首选。相较于传统的GPS、Wi-Fi、蓝牙等定位方式,UWB具备厘米级高精度、低延迟、高安全性、抗干扰强等突出优势,能够实现…...

二、QT和驱动模块实现智能家居----2、编译支持QT的系统
因为我们的Linux内核文件不支持QT系统(当然如果你的支持,完全跳过这篇文章),所以我们要从网上下载很多软件包,这里直接用百问网的软件包,非常方便。 一:Ubuntu 配置 1 设置交叉编译工具链 以…...

从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置
从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置当你第一次面对Ubuntu Server时,最迫切的需求可能就是如何安全地远程管理它。作为运维新手或开发者,掌握SSH连接和防火墙配置是进入Linux世界的第一道门槛。本文将带你…...

量子机器学习安全评估:Q-SafeML原理、实现与工程实践
1. 量子机器学习安全评估:为什么需要一套新方法?量子机器学习(QML)正在从理论走向实践,尤其是在药物发现、材料科学和金融建模等对精度和可靠性要求极高的领域。然而,一个核心挑战也随之而来:我…...

基于堆叠集成学习的脑膜炎早期预警模型:从EHR数据挖掘到临床决策支持
1. 项目概述与核心价值在急诊室(ER)和重症监护室(ICU)里,时间就是生命,而脑膜炎的诊断恰恰是和时间赛跑。这种包裹着大脑和脊髓的脑膜炎症,起病急、进展快,一旦延误,神经…...

如何让旧电脑联网?安卓手机以太网共享来帮忙!
通过安卓手机以太网共享让旧电脑联网2026 年 5 月 21 日,阅读时长 3 分钟。有人喜欢摆弄 90 年代和 21 世纪初的旧电脑和软件,比如童年时的 Amiga 500 电脑至今仍被保留且让人爱不释手。不过,Windows 9x/XP 时代的计算机使用经历最让人怀念&a…...

5分钟上手G-Helper:彻底告别Armoury Crate臃肿的终极指南
5分钟上手G-Helper:彻底告别Armoury Crate臃肿的终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

LizzieYzy:围棋AI分析工具的5大核心功能与实战指南
LizzieYzy:围棋AI分析工具的5大核心功能与实战指南 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy LizzieYzy是一款基于Lizzie改进的围棋AI分析图形界面工具,支持Katago、Le…...

QMCDecode:终极QQ音乐格式解密指南,一键解放你的加密音乐库
QMCDecode:终极QQ音乐格式解密指南,一键解放你的加密音乐库 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

从《苏珊的微笑》到你的角色:手把手教你用UE5的Morph Target曲线驱动自定义面部动画
从《苏珊的微笑》到你的角色:手把手教你用UE5的Morph Target曲线驱动自定义面部动画在数字角色动画领域,面部表情的细腻表现往往是区分业余与专业作品的关键分水岭。许多创作者在掌握了基础骨骼动画后,面对角色面部动画的实现却陷入困境——为…...
告别单调Sprite!在UE5 Niagara中玩转条带渲染器:从参数解析到动态颜色宽度控制
告别单调Sprite!在UE5 Niagara中玩转条带渲染器:从参数解析到动态颜色宽度控制在虚幻引擎5的Niagara粒子系统中,条带渲染器(Ribbon Renderer)一直是被低估的利器。与常见的Sprite渲染器不同,它能够基于粒子…...

工业控制系统安全:融合网络与过程数据的异常检测实践
1. 项目概述与核心思路在工业控制系统的安全防护领域,我们面临着一个日益严峻的挑战:攻击者不再满足于传统的网络渗透,而是将目标对准了物理过程本身。想象一下,一个水处理厂的阀门被恶意远程关闭,或者一个发电厂的涡轮…...