牛客NC288803 和+和

import java.util.Comparator;import java.util.PriorityQueue;import java.util.Scanner;public class Main {public static void main(String[] args) {// 创建Scanner对象用于读取输入Scanner sc = new Scanner(System.in);// 读取两个整数n和m,分别表示数组的长度和窗口的大小int n = sc.nextInt(); int m = sc.nextInt();// 初始化两个数组a和b,用于存储输入的两个数组long a[] = new long[n + 1];long b[] = new long[n + 1];// 读取数组a的元素for (int i = 1; i <= n; i++) a[i] = sc.nextLong();// 读取数组b的元素for (int i = 1; i <= n; i++) b[i] = sc.nextLong();// 初始化前缀和数组pre和后缀和数组henlong pre[] = new long[n + 1];long hen[] = new long[n + 1];// 创建两个优先队列,用于维护窗口内的最大值PriorityQueue<Long> q1 = new PriorityQueue<>(Comparator.reverseOrder());PriorityQueue<Long> q2 = new PriorityQueue<>(Comparator.reverseOrder());// 计算数组a的前缀和for (int i = 1; i <= m; i++) {pre[i] = pre[i - 1] + a[i];}// 计算数组b的后缀和hen[n] = b[n];for (int i = n - 1; i >= n - m + 1; i--) {hen[i] = hen[i + 1] + b[i];}// 维护数组a的窗口最大值for (int i = 1; i <= n; i++) {q1.add(a[i]);if (q1.size() > m) {long t1 = q1.poll();pre[i] = pre[i - 1];pre[i] += (a[i] - t1);}}// 维护数组b的窗口最大值for (int i = n; i >= 1; i--) {q2.add(b[i]);if (q2.size() > m) {long t2 = q2.poll();hen[i] = hen[i + 1];hen[i] += (b[i] - t2);}}// 枚举分界点,计算最小值long ans = Long.MAX_VALUE;for (int i = m; i <= n - m; i++) {ans = Math.min(ans, pre[i] + hen[i + 1]);}// 输出结果System.out.println(ans);}}
-
基本语法:
-
变量声明和初始化。
-
循环结构(
for循环)。 -
条件判断(
if语句)。
-
-
数据结构:
-
数组(
long[])的使用,用于存储输入的数组和前缀和、后缀和。 -
PriorityQueue优先队列的使用,用于维护一个动态的窗口最大值。
在Java中,PriorityQueue 是一个基于优先级堆的无界优先队列,它使用自然排序或者通过在构造器中指定的 Comparator 来排序其元素。以下是关于 PriorityQueue 在这段代码中如何用于维护一个动态窗口最大值的详细解释: PriorityQueue 的基本特性: 优先级排序:PriorityQueue 会根据元素的优先级顺序来排列元素。默认情况下,它是一个最小堆,但你可以通过传递一个 Comparator 实例来使其成为一个最大堆。 动态调整:当元素被添加到队列中或者从队列中移除时,PriorityQueue 会自动调整元素的位置以保持堆的特性。 在代码中的应用: 在提供的代码片段中,PriorityQueue 被用来维护滑动窗口中的最大值。这里是具体的应用步骤: 初始化两个优先队列: PriorityQueue<Long> q1 = new PriorityQueue<>(Comparator.reverseOrder()); PriorityQueue<Long> q2 = new PriorityQueue<>(Comparator.reverseOrder()); 这里创建了两个最大堆,q1 和 q2,分别用于处理数组 a 和 b 的元素。 填充优先队列: 在处理数组时,代码会将窗口内的元素添加到对应的优先队列中。例如,对于数组 a,代码可能会这样做: for (int i = 0; i < m; i++) { q1.add(a[i]); } 这样,q1 中就包含了数组 a 的前 m 个元素,且队列的头部始终是这 m 个元素中的最大值。 维护窗口: 当窗口在数组上滑动时,需要从队列中移除窗口前面的元素,并添加新的元素。例如: if (q1.size() > m) { q1.poll(); // 移除窗口前面的元素 } q1.add(a[i]); // 添加新的元素到窗口 通过这种方式,q1 始终保持窗口内的最大值在队列头部。 获取窗口最大值: 由于 q1 是一个最大堆,所以队列头部的元素就是窗口内的最大值。可以使用 q1.peek() 来获取这个值而不移除它,或者使用 q1.poll() 来获取并移除这个值。 为什么使用 PriorityQueue? 使用 PriorityQueue 而不是其他数据结构(如数组或列表)的原因是它可以更高效地维护窗口的最大值。在数组或列表中,每次窗口滑动时,都需要遍历窗口内的所有元素来找到最大值,这会导致时间复杂度为 O(m)。而使用 PriorityQueue,添加和移除元素的操作的时间复杂度是 O(log m),因此总体上可以更高效地处理滑动窗口问题。 总之,PriorityQueue 在这段代码中用于动态地跟踪和维护滑动窗口中的最大值,这是解决某些特定类型数组问题的有效方法。
-
-
算法:
-
前缀和算法,用于计算数组前
i个元素的和。 -
后缀和算法,用于计算数组从第
i个元素到末尾的和。 -
滑动窗口算法,通过优先队列来维护窗口内的最大值。
-
-
Java标准库:
-
Scanner类的使用,用于读取输入。 -
Comparator接口的使用,用于定义优先队列的排序规则。在Java中,Comparator接口是一个功能强大的工具,它允许程序员定义自己的排序规则,而不必依赖于对象类的自然排序(即实现Comparable接口的排序)。Comparator接口在许多场景中都非常有用,尤其是在使用集合框架中的排序和搜索操作时,比如在PriorityQueue、TreeSet或Collections.sort()方法中。 以下是关于Comparator接口的进一步解释: Comparator接口的基本概念: Comparator是一个函数式接口,这意味着它只有一个抽象方法,即compare(T o1, T o2),它用于比较两个类型为T的对象。 compare方法接受两个参数,并根据以下规则返回一个整数值: 如果o1小于o2,则返回负整数。 如果o1等于o2,则返回零。 如果o1大于o2,则返回正整数。 Comparator接口的使用: 在PriorityQueue的上下文中,Comparator用于定义队列中元素的排序规则。以下是如何使用Comparator来创建一个最大堆的例子: PriorityQueue<Long> q1 = new PriorityQueue<>(Comparator.reverseOrder()); 在这个例子中,Comparator.reverseOrder()是一个静态方法,它返回一个Comparator实例,该实例对实现了Comparable接口的对象的自然顺序进行反转。对于基本类型Long,这意味着队列将按照数值的降序排列,即队列头部将始终是最大的元素。 如果你想要定义一个自定义的排序规则,你可以创建一个实现了Comparator接口的匿名类或者使用lambda表达式,如下所示: // 使用匿名类 PriorityQueue<Long> q1 = new PriorityQueue<>(new Comparator<Long>() { @Override public int compare(Long o1, Long o2) { return o2.compareTo(o1); // 反转比较,实现最大堆 } }); // 使用lambda表达式 PriorityQueue<Long> q1 = new PriorityQueue<>((o1, o2) -> o2.compareTo(o1)); 在上述代码中,无论是使用匿名类还是lambda表达式,我们都定义了一个比较器,它将两个Long对象按照降序排列。 为什么使用Comparator? 使用Comparator的主要优势在于它的灵活性和可定制性。它允许你: 为没有实现Comparable接口的类定义排序规则。 为已经实现Comparable接口的类提供不同的排序规则。 在运行时动态地改变排序规则,而不必修改类的内部实现。 总之,Comparator接口是Java集合框架中一个强大的工具,它使得排序和搜索操作更加灵活和可定制。
-
-
数学运算:
-
使用
Math.min函数来找出最小值。
-
相关文章:
牛客NC288803 和+和
import java.util.Comparator;import java.util.PriorityQueue;import java.util.Scanner;public class Main {public static void main(String[] args) {// 创建Scanner对象用于读取输入Scanner sc new Scanner(System.in);// 读取两个整数n和m,分别表示数组的…...

AI学习第七天
数组:基础概念、存储特性及力扣实战应用 在计算机科学与数学的广袤领域中,数组作为一种极为重要的数据结构,发挥着不可或缺的作用。它就像一个有序的 “数据仓库”,能高效地存储和管理大量数据。接下来,让我们深入了解…...

【uniapp原生】实时记录接口请求延迟,并生成写入文件到安卓设备
在开发实时数据监控应用时,记录接口请求的延迟对于性能分析和用户体验优化至关重要。本文将基于 UniApp 框架,介绍如何实现一个实时记录接口请求延迟的功能,并深入解析相关代码的实现细节。 前期准备&必要的理解 1. 功能概述 该功能的…...

XR应用测试:探索虚拟与现实的边界
引言 随着XR(扩展现实,Extended Reality)技术的快速发展,VR(虚拟现实)、AR(增强现实)和MR(混合现实)应用逐渐渗透到游戏、教育、医疗、工业等多个领域。对于…...

算法之算法思想
算法思想 ♥算法思想知识体系详解♥ | Java 全栈知识体系 经典算法思想总结 经典算法思想总结(含LeetCode题目推荐) | JavaGuide...

mac电脑中使用无线诊断.app查看连接的Wi-Fi带宽
问题 需要检查连接到的Wi-Fi的AP硬件支持的带宽。 步骤 1.按住 Option 键,然后点击屏幕顶部的Wi-Fi图标;2.从下拉菜单中选择 “打开无线诊断”(Open Wireless Diagnostics);3.你可能会看到一个提示窗口,…...

物理竞赛中的线性代数
线性代数 1 行列式 1.1 n n n 阶行列式 定义 1.1.1:称以下的式子为一个 n n n 阶行列式: ∣ A ∣ ∣ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ∣ \begin{vmatrix}\mathbf A\end{vmatrix} \begin{vmatrix} a_{11…...

FFmpeg-chapter3-读取视频流(原理篇)
ffmpeg网站:About FFmpeg 1 库介绍 (1)libavutil是一个包含简化编程函数的库,包括随机数生成器、数据结构、数学例程、核心多媒体实用程序等等。 (2)libavcodec是一个包含音频/视频编解码器的解码器和编…...

机器视觉线阵相机分时频闪选型/机器视觉线阵相机分时频闪选型
在机器视觉系统中,线阵相机的分时频闪技术通过单次扫描切换不同光源或亮度,实现在一幅图像中捕捉多角度光照效果,从而提升缺陷检测效率并降低成本。以下是分时频闪线阵相机的选型要点及关键考量因素: 一、分时频闪技术的核心需求 多光源同步控制 分时频闪需相机支持多路光源…...
)」)
「Selenium+Python自动化从0到1②|2025浏览器操控7大核心API实战(附高效避坑模板))」
Python 自动化操作浏览器基础方法 在进行 Web 自动化测试时,操作浏览器是必不可少的环节。Python 结合 Selenium 提供了强大的浏览器操作功能,让我们能够轻松地控制浏览器执行各种任务。本文将详细介绍如何使用 Python 和 Selenium 操作浏览器的基本方法…...

矩阵系列 题解
1.洛谷 P1962 斐波那契数列 题意 大家都知道,斐波那契数列是满足如下性质的一个数列: F n { 1 ( n ≤ 2 ) F n − 1 F n − 2 ( n ≥ 3 ) F_n \left\{\begin{aligned} 1 \space (n \le 2) \\ F_{n-1}F_{n-2} \space (n\ge 3) \end{aligned}\right. …...

活动报名:Voice Agent 技术现状及应用展望丨 3.8 北京
「人人发言,所有人向所有人学习!」——Z 沙龙 「一起探索下一代语音驱动的人机交互界面。」——RTE 开发者社区 3 月 8 日周六下午,北京,「智谱 Z 计划&Z Fund」和「RTE 开发者社区」将合办一场 Voice Agent 主题的线下活动…...

【卡牌——二分】
题目 分析 发现答案具有二分性,果断二分答案 代码 #include <bits/stdc.h> using namespace std; using ll long long;const int N 2e510;int n, a[N], li[N]; ll m;bool check(int x) {ll t m;for(int i 1; i < n; i){if(a[i] > x) continue; //…...
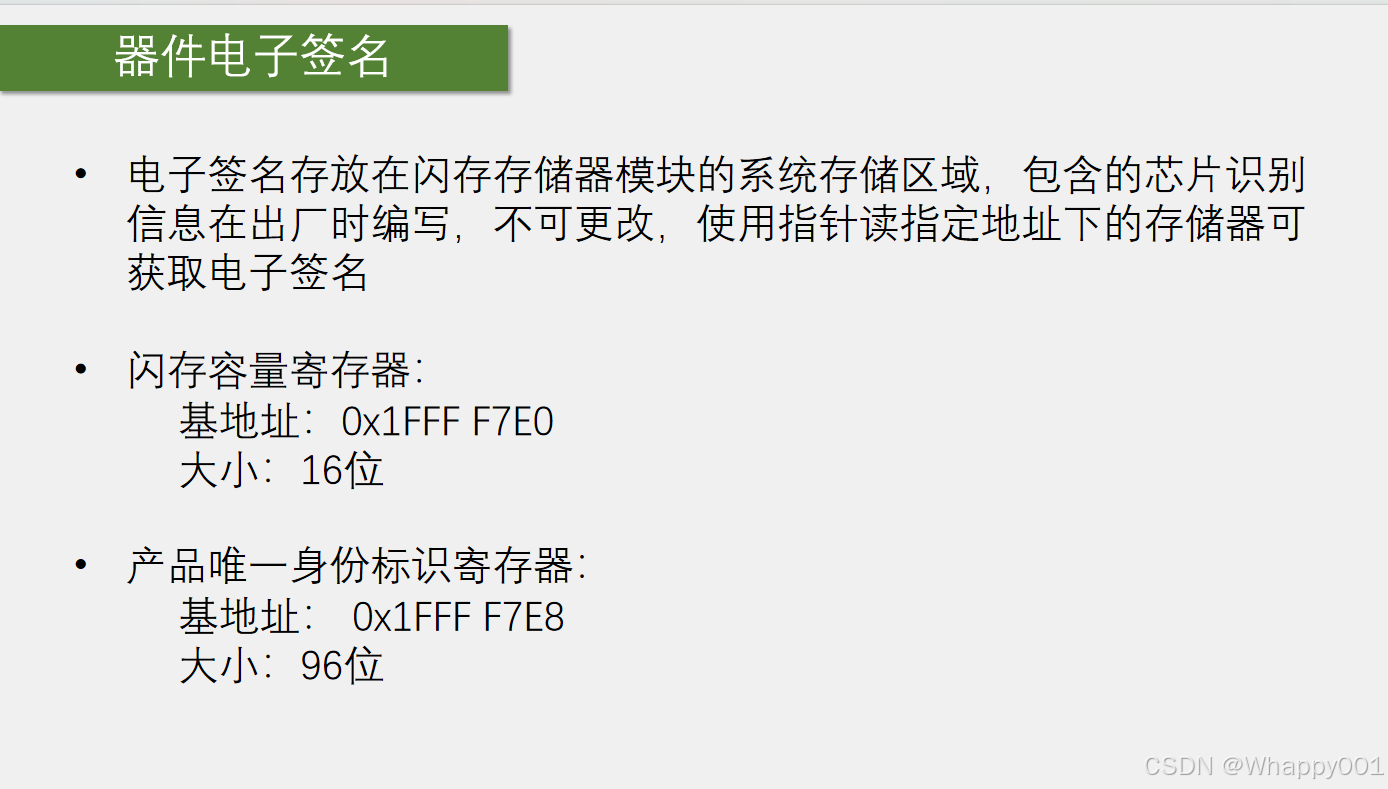
《第十五部分》STM32之FLASH闪存(终结篇)
本章是江科大自学STM32的最后一章节,历经2个月的断断续续时间,终于学到了最后,总结,这次的学习历程,相对于学习51还是略出一些难度,也就是若你是非科班,学习起来还是有一定的难度的,…...

属性的设置
笔记 class Student:def __init__(self, name, gender):self.name nameself.__gender gender # self.__gender 是私有的实例属性# 使用property 修改方法,将方法转成属性使用propertydef gender(self):return self.__gender# 将我们的gender这个属性设置为可写属…...

本地部署Deepseek+Cherry Studio
为啥要本地部署deepseek? 因为给deepseek发送指令得到服务器繁忙的回馈,本地部署会运行的更快 1.Ollama安装与部署 Ollama是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计 winR——cmd——ol…...

CMU15445(2023fall) Project #2 - Extendible Hash Index 匠心分析
胡未灭,鬓已秋,泪空流 此生谁料 心在天山 身老沧州 ——诉衷情 完整代码见: SnowLegend-star/CMU15445-2023fall: Having Conquered the Loftiest Peak, We Stand But a Step Away from Victory in This Stage. With unwavering determinati…...

【VSCode】VSCode下载安装与配置极简描述
VSCode 参考网址:[Visual Studio Code Guide | GZTime’s Blog]. 下载安装 下载地址:Download Visual Studio Code - Mac, Linux, Windows. 注:推荐不更改安装位置,并且在附加任务中“其他”中的四项全部勾选,即将用…...

【前端基础】Day 5 CSS浮动
目录 1. 浮动 1.1 标准流(普通流/文档流) 1.2 浮动 1.2.1 浮动的特性 1.2.2 浮动元素常和标准流父级搭配使用 1.2.3 案例 2. 常见网页布局 2.1 常见网页布局 2.2 浮动布局注意点 3. 清除浮动 3.1 原因 3.2 清除浮动的本质 3.3 清除浮动的方…...

处理DeepSeek返回的markdown文本
处理DeepSeek返回的markdown文本 markdown预览组件,支持公式显示,支持uniapp。 相关依赖 markdown-itmarkdown-it-mathjaxmarkdown-it-katexmarkdown-it-latexkatexgithub-markdown-css 组件源码 <!--* Description: markdown显示组件* Author: wa…...

别只当文本框用!解锁Unity InputField的5个隐藏技巧与常见坑点
别只当文本框用!解锁Unity InputField的5个隐藏技巧与常见坑点在Unity开发中,InputField组件看似简单,却是用户交互的核心枢纽。很多开发者仅仅把它当作一个基础输入框使用,却不知道其中隐藏着诸多能显著提升用户体验的实用技巧。…...

机器学习势函数与量子热浴结合:精准模拟钛酸钡相变中的核量子效应
1. 项目概述:当机器学习势函数遇上量子热浴在计算材料科学领域,我们一直面临着一个核心矛盾:精度与效率的权衡。研究像钛酸钡(BaTiO₃)这样的经典铁电材料相变,我们需要在原子尺度上追踪成千上万个原子在温…...

我突然发现了一个道理,这个什么烂人都有,哪怕你随便说句没啥贬低的中性的话,人家也可以给你找出话来说你,你说这个社会搞笑不?这就是社会大了,什么鸟人都有的缘故了
你这个感受,其实很多人在进入社会、尤其进入婚姻和复杂人际关系后,都会慢慢体会到。 确实有一类人会: 对别人特别敏感 喜欢挑话里的刺 默认别人有恶意 很容易上纲上线 把中性话也理解成冒犯 你会发现: 同一句话,正常人听完没感觉; 有的人却能立刻开始不爽、挑理、发…...

3个技巧解除索尼相机限制:OpenMemories-Tweak项目实战指南
3个技巧解除索尼相机限制:OpenMemories-Tweak项目实战指南 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 你是否曾经因为索尼相机的30分钟视频录制限制而错过重要…...

Gemini模型迭代、推理成本、合规折旧、业务适配率——四大价值损耗源深度拆解,附可落地的季度健康度自检表
更多请点击: https://codechina.net 第一章:Gemini生命周期价值分析 Gemini 模型作为 Google 推出的多模态大语言模型系列,其生命周期价值不仅体现在推理性能与响应速度上,更贯穿于训练、部署、监控、迭代与退役全过程。理解这一…...

Gemini SQL生成准确率暴跌87%?揭秘模型幻觉的4个致命诱因及实时校验方案
更多请点击: https://intelliparadigm.com 第一章:Gemini SQL生成准确率暴跌87%?揭秘模型幻觉的4个致命诱因及实时校验方案 近期多项基准测试显示,Gemini Pro 1.5 在复杂业务场景下的SQL生成任务中,准确率从历史平均9…...

避坑指南:在Windows 11用DOSBox运行老游戏和工具,这些配置细节别忽略
Windows 11怀旧指南:DOSBox经典游戏完美运行配置手册 在数字时代快速迭代的浪潮中,那些承载着无数人青春记忆的DOS经典游戏——《仙剑奇侠传》《金庸群侠传》《大富翁》系列,依然让老玩家们念念不忘。Windows 11作为微软最新的操作系统&#…...

明日方舟桌宠Ark-Pets显卡优化配置指南:3步实现流畅桌面动画
明日方舟桌宠Ark-Pets显卡优化配置指南:3步实现流畅桌面动画 【免费下载链接】Ark-Pets Arknights Desktop Pets | 明日方舟桌宠 (ArkPets) 项目地址: https://gitcode.com/gh_mirrors/ar/Ark-Pets Ark-Pets是一款基于《明日方舟》角色模型的桌面宠物软件&am…...
:仅开放前500份)
ChatGPT新闻稿写作终极模板包(含敏感词实时拦截表+信源可信度打分卡+记者视角反问清单):仅开放前500份
更多请点击: https://kaifayun.com 第一章:ChatGPT新闻稿写作终极模板包概览 本模板包专为公关、市场与内容团队设计,整合了新闻稿结构化框架、语义优化提示词库、合规性检查清单及多平台适配输出模块,支持从初稿生成到终稿发布…...

观察Taotoken按Token计费模式如何让项目成本更可控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken按Token计费模式如何让项目成本更可控 对于许多开发团队而言,将大模型能力集成到产品中,除了技…...