Python从0到100(八十九):Resnet、LSTM、Shufflenet、CNN四种网络分析及对比

前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!
欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!
本文目录:
- 一、四种网络的结构及介绍
- 1.ResNet
- 2.长短期记忆网络(LSTM)
- 3.ShuffleNet
- 4.CNN
- 二、具体训练过程
- 1.Resnet
- 1.1 残差块(Block)
- 1.2 ResNet网络
- 1.3 辅助方法
- 1.4 前向传播(Forward Pass)
- 训练过程及结果
- 2.LSTM
- 2.1 LSTM类及网络层
- 2.3前向传播(Forward Pass)
- 训练过程及结果
- 3.ShuffleNet
- 1. ChannelShuffleModule类
- 2. ShuffleNet类
- 3. 前向传播(Forward Pass)
- 训练过程及结果
- 4.Cnn
- 三、结果分析
- 四、结论
- 1. 模型结构设计差异
- 2. 模型结构设计对训练和loss的影响
- 3. Loss设计对模型性能的影响
- 文末送书
- `本期推荐1:`
- `本期推荐2:`
为了进一步探索不同网络结构在WISDM数据集上的表现,本文将继续深入研究,将训练模型推广到其他网络结构中,包括ResNet、LSTM和ShuffleNet,并通过仿真实验对比这些网络在WISDM数据集上的训练效果。
一、四种网络的结构及介绍
1.ResNet
残差网络(ResNet)通过引入“残差学习”的概念,解决了深度神经网络训练困难的问题。其核心思想是通过残差块(Residual Block)将输入直接与输出相加,从而缓解梯度消失问题,使得网络可以训练得更深。

ResNet沿用了VGG完整的3 × 3卷积层设计。残差块里首先有2个有相同输出通道数的3 × 3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。
核心思想:
· 残差块(Residual Block) :输入通过一个或多个卷积层后,与输入相加,形成残差。这样做可以使得网络学习到的是输入和输出之间的残差,而不是直接学习输出,从而缓解了梯度消失问题,使得网络可以成功训练更深的模型。

优点:
· 通过残差学习,可以有效地训练更深的网络,提高了模型的性能。
· 网络结构易于拓展,可以构建更复杂的模型。
缺点:
· 虽然缓解了梯度消失问题,但在某些情况下仍然可能遇到梯度爆炸的问题。
· 模型参数较多,需要较大的数据集进行训练。
网络结构:
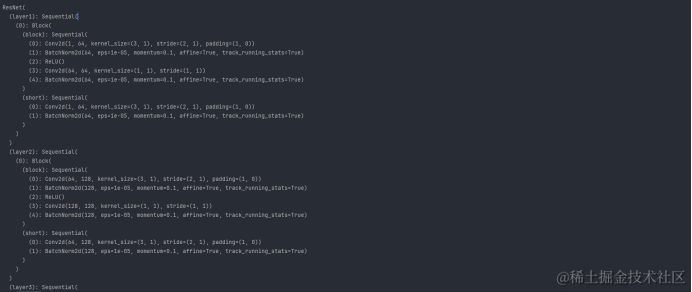
ResNet((layer1): Sequential((0): Block((block): Sequential((0): Conv2d(1, 64, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU()(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(short): Sequential((0): Conv2d(1, 64, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
2.长短期记忆网络(LSTM)
LSTM是一种特殊的循环神经网络(RNN),通过引入门控机制(输入门、遗忘门和输出门)和记忆单元,能够学习长期依赖信息,特别适合处理时间序列数据。

核心思想:
· 门控机制(Gating Mechanism) :LSTM通过引入输入门、遗忘门和输出门来控制信息的流动,解决了传统RNN的短期记忆问题。
· 记忆单元(Memory Cell) :LSTM的核心是记忆单元,它可以添加或移除信息,从而实现长期记忆。
优点:
· 能够处理长期依赖问题,适用于时间序列数据。
· 通过门控机制,可以有效地避免梯度消失和梯度爆炸问题。
缺点:
· 参数数量较多,训练时间较长。
· 门控机制增加了模型的复杂度。
网络结构:
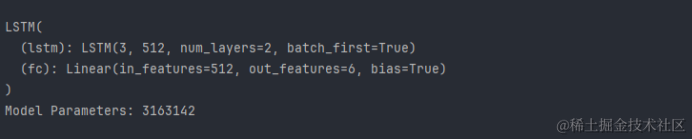
LSTM(
(lstm): LSTM(3, 512, num_layers=2, batch_first=True)
(fc): Linear(in_features=512, out_features=6, bias=True)
)
3.ShuffleNet
ShuffleNet是一种高效的卷积神经网络,通过分组卷积和通道洗牌操作减少计算量,同时保持较高的准确率。

核心思想:
· 分组卷积:将输入通道分成多个组,每组独立进行卷积操作,然后合并结果。这样可以减少计算量和参数数量。

· 通道洗牌:在分组卷积后,通过通道洗牌操作重新混合不同组的特征图,以保持特征的多样性。

优点:
· 计算效率高,适用于资源受限的环境。
· 通过通道洗牌操作,可以在减少计算量的同时保持特征的多样性。
缺点:
· 虽然减少了计算量,但在某些复杂任务上可能不如其他网络结构表现出色。
· 分组卷积可能会牺牲一定的模型性能。
网络结构:
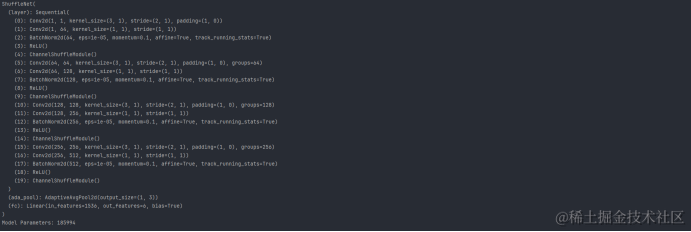
ShuffleNet((layer): Sequential((0): Conv2d(1, 1, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))(1): Conv2d(1, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU()(19): ChannelShuffleModule())(ada_pool): AdaptiveAvgPool2d(output_size=(1, 3))(fc): Linear(in_features=1536, out_features=6, bias=True))
4.CNN
CNN是一种深度学习模型,主要用于处理具有网格结构的数据,如图像和时间序列数据。其核心思想是利用卷积层(Convolutional Layer)提取局部特征,然后通过池化层(Pooling Layer)进行下采样以减少特征维度,最后通过全连接层(Fully Connected Layer)进行分类或回归。
CNN的典型结构包括多个卷积层、池化层和全连接层。以下是一个简单的CNN结构示例:
import torch.nn as nnclass CNN(nn.Module):def __init__(self, input_channels, num_classes):super(CNN, self).__init__()self.conv1 = nn.Conv2d(in_channels=input_channels, out_channels=32, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(64 * 7 * 7, 128) # 假设输入图像大小为28x28self.fc2 = nn.Linear(128, num_classes)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.pool(x)x = self.conv2(x)x = self.relu(x)x = self.pool(x)x = x.view(x.size(0), -1) # 展平特征x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return x
二、具体训练过程
1.Resnet
1.1 残差块(Block)
Block类是一个残差网络的基本构建块,它包含两个卷积层,分别后接批量归一化(BatchNorm)和ReLU激活函数。- 第一个卷积层的卷积核大小为 (3, 1),步长为
(stride, 1),填充为(1, 0)。 - 如果输入和输出的通道数不同,或者步长不为1,残差块会包含一个快捷连接(shortcut),它是一个1x1的卷积层,用于匹配通道数和步长。
class Block(nn.Module):def __init__(self, inchannel, outchannel, stride):super().__init__()self.block = nn.Sequential(nn.Conv2d(inchannel, outchannel, (3, 1), (stride, 1), (1, 0)),nn.BatchNorm2d(outchannel),nn.ReLU(),nn.Conv2d(outchannel, outchannel, 1, 1, 0),nn.BatchNorm2d(outchannel))self.short = nn.Sequential()if (inchannel != outchannel or stride != 1):self.short = nn.Sequential(nn.Conv2d(inchannel, outchannel, (3, 1), (stride, 1), (1, 0)),nn.BatchNorm2d(outchannel))
1.2 ResNet网络
ResNet类定义了整个网络结构,它由四个残差层(layer1到layer4)组成,每一层由多个残差块组成。- 每一层的输出通道数分别是64, 128, 256, 和 512。每一层的第一个块的步长为2,用于下采样,其余块的步长为1。
- 网络的输入假设具有形状
[b, c, series, modal],其中b是批次大小,c是通道数,series是序列长度,modal是模态数(例如,图像的高度)。 - 网络最后使用一个自适应平均池化层(
AdaptiveAvgPool2d)将特征图的大小调整为(1, train_shape[-1]),然后通过一个全连接层(fc)输出类别预测。
class ResNet(nn.Module):def __init__(self, train_shape, category):super().__init__()self.layer1 = self.make_layers(1, 64, 2, 1)self.layer2 = self.make_layers(64, 128, 2, 1)self.layer3 = self.make_layers(128, 256, 2, 1)self.layer4 = self.make_layers(256, 512, 2, 1)self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))self.fc = nn.Linear(512*train_shape[-1], category)1.3 辅助方法
make_layers方法用于创建每个残差层中的多个残差块。它接受输入通道数、输出通道数、步长和块的数量作为参数,并返回一个由这些块组成的序列。
def make_layers(self, inchannel, outchannel, stride, blocks):layer = [Block(inchannel, outchannel, stride)]for i in range(1, blocks):layer.append(Block(outchannel, outchannel, 1))return nn.Sequential(*layer)
1.4 前向传播(Forward Pass)
- 在
forward方法中,输入数据x会逐层通过残差层,然后通过自适应平均池化层和全连接层,最终输出类别预测。
def forward(self, x):out = self.block(x) + self.short(x)return nn.ReLU()(out)
训练过程及结果
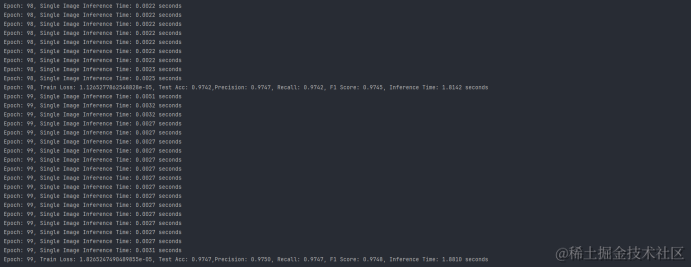
从训练得到的结果我们可以发现在准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)、参数量(Parameters)、推理时间(Inference Time) 六个维度上分别为:
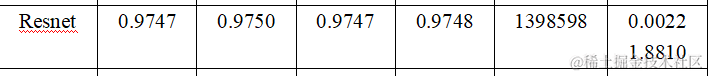
2.LSTM
LSTM网络特别适合于处理和预测时间序列数据,因为它们可以捕捉长期依赖关系,在本次实验中可以发挥出其特点,我们首先使用用LSTM层来处理序列数据,然后使用全连接层来进行分类预测。通过选取序列最后一个时间步的隐藏状态来进行分类,这是处理序列数据的一个常见做法,尤其是当序列长度固定时。
2.1 LSTM类及网络层
我们使用LSTM 类继承自 nn.Module,构造函数 __init__ 接受两个参数:train_shape 和 category。
train_shape是训练数据的形状,这里假设它是一个包含序列长度和模态数的列表或元组。category是类别的数量,即网络输出的维度,用于分类任务。
class LSTM(nn.Module):def __init__(self, train_shape, category):super().__init__()self.lstm = nn.LSTM(train_shape[-1], 512, 2, batch_first=True)self.fc = nn.Linear(512, category)
其中self.lstm 是LSTM层,其参数如下:
train_shape[-1]是输入特征的维度,即模态数。512是LSTM隐藏层的维度。2表示堆叠两个LSTM层。batch_first=True表示输入和输出的张量的第一个维度是批次大小(batch size)。
self.fc 是一个全连接层,它将LSTM层的输出映射到类别空间。它的输入维度是512(LSTM隐藏层的维度),输出维度是 category。
2.3前向传播(Forward Pass)
forward 方法定义了数据通过网络的正向传播过程。输入 x 的形状假设为 [b, c, series, modal],其中 b 是批次大小,c 是通道数(在这里为1,因为 squeeze(1) 被调用)。
x.squeeze(1) 将通道数维度移除,使得 x 的形状变为 [b, series, modal]。self.lstm(x) 将数据 x 通过LSTM层,输出一个包含隐藏状态和细胞状态的元组。
def forward(self, x):x, _ = self.lstm(x.squeeze(1))x = x[:, -1, :]x = self.fc(x)return x
训练过程及结果
从训练得到的结果我们可以发现在准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)、参数量(Parameters)、推理时间(Inference Time) 六个维度上分别为:
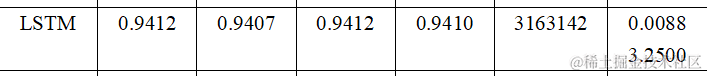
3.ShuffleNet
ShuffleNet通过深度可分离卷积和通道混合技术减少了模型的参数量和计算量,同时保持了较好的性能。这种卷积首先使用 groups 参数将输入通道分组,然后对每个组应用一个轻量级的 (kernel_size, 1) 卷积,接着是一个 1x1 的卷积来组合这些输出。在每个深度可分离卷积后面,紧跟着一个批量归一化层、一个ReLU激活函数和一个通道混合模块。
1. ChannelShuffleModule类
ChannelShuffleModule 是一个通道混合模块,它接收一个张量作为输入,并将其通道按照指定的组数进行重组和混合。在构造函数中,channels 是输入张量的通道数,groups 是要将通道分成的组数。
forward 方法首先将输入张量重塑为 (batch, groups, channel_per_group, series, modal) 的形状,然后通过 permute 重新排列这些组,最后再将其重塑回 (batch, channels, series, modal) 的形状。
class ChannelShuffleModule(nn.Module):def __init__(self, channels, groups):super().__init__()'''channels: 张量通道数groups: 通道组数【将channels分为groups组去shuffle】'''assert channels % groups == 0self.channels = channelsself.groups = groupsself.channel_per_group = self.channels // self.groups
2. ShuffleNet类
ShuffleNet 类继承自 nn.Module,定义了ShuffleNet的主体结构。
构造函数 __init__ 接受 train_shape(训练样本的形状)、category(类别数)和 kernel_size(卷积核大小)作为参数。
self.layer 是一个由多个卷积层、批量归一化层、ReLU激活函数和通道混合模块组成的序列。这些层按照顺序执行,逐步增加网络的深度并减少特征图的尺寸。
class ShuffleNet(nn.Module):def __init__(self, train_shape, category, kernel_size=3):super(ShuffleNet, self).__init__()self.layer = nn.Sequential(nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),nn.Conv2d(1, 64, 1, 1, 0),nn.BatchNorm2d(64),nn.ReLU(),ChannelShuffleModule(channels=64, groups=8),nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64),nn.Conv2d(64, 128, 1, 1, 0),nn.BatchNorm2d(128),nn.ReLU(),ChannelShuffleModule(channels=128, groups=8),nn.Conv2d(128, 128, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=128),nn.Conv2d(128, 256, 1, 1, 0),nn.BatchNorm2d(256),nn.ReLU(),ChannelShuffleModule(channels=256, groups=16),nn.Conv2d(256, 256, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=256),nn.Conv2d(256, 512, 1, 1, 0),nn.BatchNorm2d(512),nn.ReLU(),ChannelShuffleModule(channels=512, groups=16))self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))self.fc = nn.Linear(512*train_shape[-1], category)
3. 前向传播(Forward Pass)
forward方法定义了数据通过网络的正向传播过程。- 输入
x的形状假设为[b, c, series, modal],其中b是批次大小,c是通道数,series是序列长度,modal是模态数。
首先,x通过self.layer中定义的多个卷积层和通道混合模块。
然后,使用self.ada_pool进行自适应平均池化,将特征图的series维度缩减到1。
接着,通过view方法将池化后的特征图展平,并通过一个全连接层self.fc进行分类。
def forward(self, x):x = self.layer(x)x = self.ada_pool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x
训练过程及结果
从训练得到的结果我们可以发现在准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)、参数量(Parameters)、推理时间(Inference Time) 六个维度上分别为:
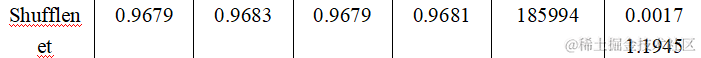
4.Cnn
上篇文章中已经具体分析,这里只给出结果:
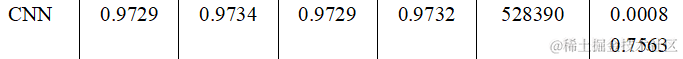
三、结果分析
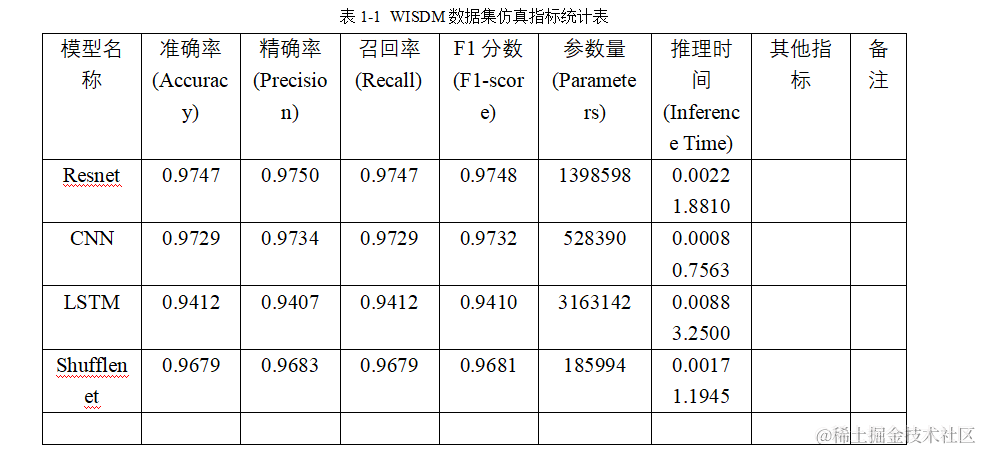
将得到的四组实验数据写入表格中,进行横向深入对比:
从模型参数量来看,LSTM>Resnet>CNN>Shufflenet。ResNet在性能和效率之间取得了很好的平衡;CNN在保持较高准确率的同时,具有较小的模型尺寸和较快的推理速度;LSTM适合处理时间序列数据,但计算成本较高;ShuffleNet则在资源受限的环境中表现出色,尽管其准确率略低。
以下是我们对各个模型的关键指标更详细的对比:
-
准确率 (Accuracy): 所有模型的准确率都相当高,其中ResNet最高,达到了97.47%。
-
精确率 (Precision): 精确率衡量的是预测为正类别中实际为正类别的比例。ResNet同样在这项指标上表现最佳,为97.50%。
-
召回率 (Recall): 召回率衡量的是所有实际为正类别中被正确预测为正类别的比例。ResNet的召回率也是最高的,为97.47%。
-
F1分数 (F1 Score): F1分数是精确率和召回率的调和平均值,它在两者之间取得平衡。ResNet的F1分数最高,为97.48%。
-
参数量 (Parameter Count): 参数量反映了模型的复杂度。LSTM的参数量最大,为3,163,142,而Shufflenet的参数量最小,为185,994。
-
推理时间 (Inference Time): 推理时间是指模型进行预测所需的时间。CNN的推理时间最短,为0.0008秒,而LSTM的推理时间最长,为0.0088秒。
如果对预测性能有极高的要求,ResNet可能是最佳选择。如果对速度和模型大小有更高的要求,CNN或Shufflenet可能更合适。LSTM由于其参数量最大,可能适用于需要捕获长期依赖关系的任务,但需要更多的计算资源。
四、结论
1. 模型结构设计差异
- ResNet:其残差连接允许网络学习输入的恒等变换以及更复杂的函数。这种设计使得网络能够通过增加层数来提高性能,而不会受到梯度消失的影响。此外,残差连接有助于网络在训练过程中保持特征的一致性,这可能是ResNet在多个评价指标上表现优异的原因之一。
- LSTM:LSTM的门控机制使其能够学习长期依赖关系,这对于时间序列数据特别重要。然而,这种复杂的结构也导致了更多的参数和更高的计算成本。在训练过程中,LSTM可能需要更多的数据和调整来优化其门控单元的状态,这可能是其参数量较大和推理时间较长的原因之一。
- ShuffleNet:ShuffleNet的设计注重计算效率和模型大小。通过分组卷积和通道洗牌,ShuffleNet减少了计算量和参数数量,但这种设计可能牺牲了一些模型的表达能力,尤其是在处理复杂数据时。这可能是ShuffleNet在准确率上略低于其他模型的原因之一。
- CNN:传统的卷积神经网络通常具有较少的参数和较高的计算效率。它们在图像识别任务中表现出色,但在处理时间序列数据或需要捕捉长期依赖关系的任务中可能不如LSTM有效。
2. 模型结构设计对训练和loss的影响
- ResNet:残差连接允许网络层之间直接的信息流动,这有助于缓解深层网络中的梯度消失问题。这种设计使得ResNet在训练时对loss的梯度更加敏感,从而在优化过程中能够更快地收敛。
- LSTM:其门控机制能够有效地捕捉长期依赖关系,但这也意味着在训练过程中需要更加细致地调整超参数,以确保模型不会陷入局部最优解。LSTM可能需要特定的loss函数来更好地利用其记忆单元,需要考虑序列中的不同时间步长对预测的贡献。
- ShuffleNet:通过分组卷积和通道洗牌,ShuffleNet减少了模型的计算复杂度,但可能牺牲了某些特征的表达能力。在训练ShuffleNet时,需要更加关注loss函数的设计,以确保模型能够在有限的参数下学习到有效的特征表示。
- CNN:标准的CNN结构通常具有较好的空间特征提取能力,但在处理时间序列数据时可能不如LSTM有效。在设计loss函数时,需要考虑如何更好地利用CNN的空间特征提取能力,例如通过设计空间敏感的loss函数。
3. Loss设计对模型性能的影响
- 损失函数的选择:对于不同的模型结构,需要设计不同的损失函数来更好地捕捉任务的关键特性。对于ShuffleNet,可能需要设计一个损失函数,它不仅惩罚预测错误的程度,还鼓励模型学习到更加分散的特征表示。
- 损失函数的权重分配:在多任务学习中,不同任务的loss可能需要不同的权重。在训练LSTM进行序列预测时,可能需要为预测序列的早期和晚期分配不同的权重,以确保模型能够平衡短期和长期预测的准确性。
- 自定义损失函数:在某些特定任务中,可能需要设计自定义的损失函数来更好地适应模型的特性。对于CNN,需要设计一个损失函数,它能够鼓励模型学习到更加鲁棒的特征表示,以应对图像数据中的噪声和变化。
通过对ResNet、LSTM、ShuffleNet和CNN在WISDM数据集上的对比实验,我们发现不同网络结构在不同场景下各有优劣。ResNet在性能和效率之间取得了很好的平衡;CNN在保持较高准确率的同时,具有较小的模型尺寸和较快的推理速度;LSTM适合处理时间序列数据,但计算成本较高;ShuffleNet则在资源受限的环境中表现出色,尽管其准确率略低。在实际应用中,应根据具体任务需求选择合适的模型结构。
文末送书
本期推荐1:《AI智能运营从入门到精通》
巧用AI大模型,带你深度解析用户洞察+精准策略+智能创作+数据模型,构建你的竞争壁垒。

京东:https://item.jd.com/14809514.html
★站在运营视角解读AI技术:AI 的底层逻辑与应用方法。
★AI构建精细化运营策略:利用AI画像分层用户,积分激励提升价值,基于生命周期理论,个性化推荐促精细化运营。
★AI智能内容创作助手:助您构建创意选题库,策划高质量脚本,降低内容重复率,训练文案打造爆款标题,生成调研问卷洞悉需求,分析文本偏好,以RSM模型规划活动,并自动撰写运营周报。
★AI驱动数据分析决策:AI作为数据分析的强大助手,不仅加速了决策效率,还提供了从基础到进阶的全面运营数据分析能力。
内容简介
本书从多个方面介绍了如何整合AI技术进行运营工作,包括AI与用户运营的融合、精细化运营策略的构建、智能内容创作助手的运用、AI驱动分析决策。
读者可以通过本书学习如何利用AI处理运营工作,从而更好地满足目标受众需求,提高内容质量,做出更准确的决策,并提升工作效率。本书内容丰富实用,旨在帮助读者适应数字化时代的挑战,实现运营工作的智能化和高效化。握人工智能大模型在写作中的应用。
本期推荐2:《WPS五合一》
WPS官方推荐:汇集多年教学经验,指引从入门到精通全过程,全面提升WPS Office办公技能!AI助力智能办公。
京东:https://item.jd.com/14850712.html
原创:以原创经典案例为核心+11小时全程同步视频,全面呈现WPS Office的核心功能!
智能:涵盖AI帮我写、AI帮我改、AI排版、AI写公式、AI数据问答、AI生成PPT等WPS AI功能,帮你全面提供办公效率!
高效:集实战案例、经验技巧、职场心得、1000个办公模板于一体!
全能:与时俱进地将WPS Office文字、表格、演示、PDF和WPS AI全面覆盖,学WPS Office办公一本就够!
内容简介
本书通过精选案例,系统地介绍了WPS Office的相关知识和应用方法。
全书分为5篇,共15章。“第1篇 文字排版篇”主要介绍WPS文字的基本操作、使用表格和图美化文档及长文档的排版等;“第2篇 表格分析篇”主要介绍WPS表格的基本操作、初级数据处理与分析、中级数据处理与分析,以及高级数据处理与分析等;“第3篇 演示设计篇”主要介绍演示文稿的基本设计、演示文稿的视觉呈现和放映幻灯片的操作技巧等;“第4篇 PDF等特色功能篇”主要介绍如何轻松编辑PDF文档、WPS Office其他特色组件的应用及WPS Office实用功能让办公更高效的方法等;“第5篇 WPS AI应用篇”主要介绍WPS AI的办公应用和WPS云办公的操作技巧等。
本书不仅适合WPS Office初、中级用户学习,也适合作为各类院校相关专业学生和计算机培训班学员的教材或辅导用书。
相关文章:

Python从0到100(八十九):Resnet、LSTM、Shufflenet、CNN四种网络分析及对比
前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Pyth…...

服务器迁移记录【腾讯云-->阿里云】
准备工作 压缩/root /usr/local/nginx /data三个目录到zip,并下载到本地。 zip root.zip /root zip nginx.zip /usr/local/nginx zip data.zip /datasz root.zip sz nginx.zip sz data.zip连接mysql数据库,导出数据库结构与数据到dzs_mysql.sql 安装l…...

序列化选型:字节流抑或字符串
序列化既可以将对象转换为字节流,也可以转换为字符串,具体取决于使用的序列化方式和场景。 转换为字节流 常见工具及原理:在许多编程语言中,都有将对象序列化为字节流的机制。例如 Python 中的 pickle 模块、Java 中的对象序列化…...

面向实时性的超轻量级动态感知视觉SLAM系统
一、重构后的技术架构设计(基于ROS1 ORB-SLAM2增强) #mermaid-svg-JEJte8kZd7qlnq3E {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-JEJte8kZd7qlnq3E .error-icon{fill:#552222;}#mermaid-svg-JEJte8kZd7qlnq3E .…...

4-3自定义加载器,并添加功能
一、自定义类加载器的实现步骤 继承ClassLoader类 自定义类加载器需继承java.lang.ClassLoader,并选择性地重写以下方法: findClass(String name):核心方法,用于根据类名查找并加载类的字节码。需从自定义路径(…...

Python Scrapy爬虫面试题及参考答案
目录 简述 Scrapy 框架的基本工作流程,并说明各组件的作用 Scrapy 中的 Spider、CrawlSpider 和 Rule 的作用及区别? 如何通过 Scrapy Shell 快速调试页面解析逻辑? Scrapy 的 start_requests 方法与 start_urls 的关系是什么? 解释 Scrapy 的 Request 和 Response 对象…...

Swan 表达式 - 选择表达式
ANSYS Swan 表达式支持选择(selection)表达式 case, if/then/else。选择表达式根据特定的条件选择不同的分支流。 if/then/else 表达式 if/then/else 表达式的文法如下 if expr then expr else expr 其中,首个expr 的布尔表达式,若其为 true, 则返回 …...

微信小程序:完善购物车功能,购物车主页面展示,详细页面展示效果
一、效果图 1、主页面 根据物品信息进行菜单分类,点击单项购物车图标添加至购物车,记录总购物车数量 2、购物车详情页 根据主页面选择的项,根据后台查询展示到页面,可进行多选,数量加减等 二、代码 1、主页面 页…...

javaweb将上传的图片保存在项目文件webapp下的upload文件夹下
前端HTML表单 (upload.html) 首先,创建一个HTML页面,允许用户选择并上传图片。 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><title>图片上传</title> </head> <…...

LabVIEW 无法播放 AVI 视频的编解码器解决方案
用户在 LabVIEW 中使用示例程序 Read AVI File.vi(路径: 📌 C:\Program Files (x86)\National Instruments\LabVIEW 2019\examples\Vision\Files\Read AVI File.vi)时发现: ✅ LabVIEW 自带的 AVI 视频可正常播放 这是…...

composer 错误汇总
文章目录 1: 安装EasyWeChat 报错2: composer install 报错, laravel/framework[v11.9.0, ..., v11.44.0] require fruitcake/php-cors ^1.33: 卸载Pulse 报错, Class "Laravel\Pulse\Pulse" not found4: 卸载Telescope报错 1: 安装EasyWeChat 报错 解决: composer …...

MySQL锁分类
一、按锁的粒度划分 全局锁 定义:锁定整个数据库实例,阻止所有写操作,确保数据备份一致性。加锁方式:通过FLUSH TABLES WITH READ LOCK实现,释放需执行UNLOCK TABLES。应用场景:适用于全库逻辑备份…...

DeepSeek 助力 Vue3 开发:打造丝滑的悬浮按钮(Floating Action Button)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...

认知动力学视角下的生命优化系统:多模态机器学习框架的哲学重构
认知动力学视角下的生命优化系统:多模态机器学习框架的哲学重构 一、信息熵与生命系统的耗散结构 在热力学第二定律框架下,生命系统可视为负熵流的耗散结构: d S d i S d e S dS d_iS d_eS dSdiSdeS 其中 d i S d_iS diS为内部熵…...

Metal 学习笔记五:3D变换
在上一章中,您通过在 vertex 函数中计算position,来平移顶点和在屏幕上移动对象。但是,在 3D 空间中,您还想执行更多操作,例如旋转和缩放对象。您还需要一个场景内摄像机,以便您可以在场景中移动。 要移动…...

unity学习56:旧版legacy和新版TMP文本输入框 InputField学习
目录 1 旧版文本输入框 legacy InputField 1.1 新建一个文本输入框 1.2 InputField 的子物体构成 1.3 input field的的component 1.4 input Field的属性 2 过渡 transition 3 控件导航 navigation 4 占位文本 placeholder 5 文本 text 5.1 文本内容,用户…...

32位,算Cache地址
32位,算Cache地址...

C++蓝桥杯基础篇(六)
片头 嗨~小伙伴们,大家好!今天我们来一起学习蓝桥杯基础篇(六),练习相关的数组习题,准备好了吗?咱们开始咯! 第1题 数组的左方区域 这道题,实质上是找规律,…...

React 常见面试题及答案
记录面试过程 常见问题,如有错误,欢迎批评指正 1. 什么是虚拟DOM?为什么它提高了性能? 虚拟DOM是React创建的一个轻量级JavaScript对象,表示真实DOM的结构。当状态变化时,React会生成新的虚拟DOM…...

和鲸科技推出人工智能通识课程解决方案,助力AI人才培养
2025年2月,教育部副部长吴岩应港澳特区政府邀请,率团赴港澳宣讲《教育强国建设规划纲要 (2024—2035 年)》。在港澳期间,吴岩阐释了教育强国目标的任务,并与特区政府官员交流推进人工智能人才培养的办法。这一系列行动体现出人工智…...

STM32MP1 M4核心定时器中断实战:从原理到1ms精准时基实现
1. 项目概述:深入STM32MP1的M4核心定时器世界在嵌入式开发中,定时器(Timer)堪称是系统的“心跳”和“节拍器”,其重要性不言而喻。对于STM32MP1这款集成了双核Cortex-A7和单核Cortex-M4的异构处理器,其M4核…...

代数拓扑运算流程
文章目录0、背景一、标准计算流程:以单纯同调为例空间剖分,构建单纯复形生成各维度链群定义边界算子定义闭链群与边缘链群计算同调群并解读拓扑信息推导最终拓扑结论二、其他核心概念的典型计算逻辑0、背景 之前为了做一个东西学习TDA&…...

谁还在用机械音?顶伯接入微软 TTS,让你视频瞬间拥有大片质感!
谁还在用机械音?顶伯接入微软 TTS,让你视频瞬间拥有大片质感!视频配音还在用那种一听就出戏的机械音吗?🚫 顶伯正式接入微软 TTS 引擎,带来媲美真人的语音合成体验。无论你是短视频创作者、课程讲师&#x…...
)
K12教师必读:用AI Agent 15分钟生成个性化学习路径(附可即用Prompt模板库)
更多请点击: https://codechina.net 第一章:AI Agent教育应用的范式变革 传统教育系统长期依赖“教师讲授—学生听记—统一测评”的线性模式,而AI Agent的兴起正推动教育从标准化供给转向个性化协同时代。AI Agent不再仅是知识检索工具或自动…...

FastGithub终极教程:5分钟解决GitHub访问卡顿问题
FastGithub终极教程:5分钟解决GitHub访问卡顿问题 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub GitHub作为全球最大的代码托管平台,是每个开发…...

长期使用TaotokenTokenPlan套餐的成本控制实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken TokenPlan套餐的成本控制实际感受 1. 从按次计费到预付费套餐的转变 在项目开发中引入大模型API调用后…...
)
nginx升级(win和linux)
win升级 把html和conf搬过来,点击新的nginx即可 需要注册成服务参考: https://www.cnblogs.com/Code-Rain/p/16642572.htmlhttps://www.cnblogs.com/Code-Rain/p/16642572.html https://blog.csdn.net/hon_vin/article/details/133717846https://blog…...

3步掌握Sabaki围棋软件:从新手到高手的完整指南
3步掌握Sabaki围棋软件:从新手到高手的完整指南 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki 在围棋的智慧世界里,一款优秀的软件能让您的学习和…...

自监督、半监督与域自适应:解锁95%未标注数据的AI落地三把钥匙
1. 项目概述:当95%的数据躺在那里“睡大觉”,我们该怎么叫醒它? 你有没有算过手头那个标注了三个月、花了两万块外包费的图像数据集,到底占了你公司服务器里全部原始数据的多少比例?我上个月帮一家做工业质检的客户做模…...

B站成分检测器:一键识别评论区用户身份的终极指南
B站成分检测器:一键识别评论区用户身份的终极指南 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-checker 你是否曾…...