02_NLP文本预处理之文本张量表示法
文本张量表示法
概念
将文本使用张量进行表示,一般将词汇表示为向量,称为词向量,再由各个词向量按顺序组成矩阵形成文本表示
例如:
["人生", "该", "如何", "起头"]==># 每个词对应矩阵中的一个向量
[[1.32, 4,32, 0,32, 5.2],[3.1, 5.43, 0.34, 3.2],[3.21, 5.32, 2, 4.32],[2.54, 7.32, 5.12, 9.54]]
作用
将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作。
-
连接文本与计算机
- 将文本张量转换为数值形式输入,使其能够被计算机处理和理解
-
表达语义信息
-
捕捉词语关系
好的文本张量表示方法,例如词嵌入,可以将词语映射到高维空间中,使得语义相似的词语在向量空间中也彼此接近。例如,“king” 和 “queen” 的向量在空间中会比 “king” 和 “apple” 更接近。
-
保留上下文信息
对于句子和文档的表示方法,例如句嵌入和文档嵌入,能够保留文本的上下文信息,例如词语之间的顺序和依赖关系。
-
理解文本含义
通过将文本映射到向量空间,模型可以学习到文本的深层语义含义,而不仅仅是表面上的字面意思。
-
-
提升模型性能
-
特征提取
文本张量表示可以看作是对文本进行特征提取的过程,将文本转换为计算机可以理解的特征。
-
降维
一些文本张量表示方法,例如词嵌入,可以将文本的维度降低,减少模型的计算量,并避免维度灾难。
-
减少噪声
一些文本张量表示方法,例如 TF-IDF,可以对文本中的噪声进行过滤,突出重要信息。
-
方法
one-hot编码
-
概念:每个单词都会被映射到一个高维向量中,该向量中只有一个元素是 1,其他所有元素都是 0。
举例
假设我们有一个包含以下 5 个单词的词汇表(Vocabulary):
- “cat”
- “dog”
- “fish”
- “bird”
- “rabbit”
我们需要为每个单词生成一个向量,向量的维度等于词汇表中单词的数量(在这个例子中是 5)。
1. 构建词汇表:
我们的词汇表如下:
Index Word 0 cat 1 dog 2 fish 3 bird 4 rabbit 2. 生成 One-hot 向量:
每个单词都会被转换为一个与词汇表大小相同的向量,其中该单词所在位置的值为 1,其余位置的值为 0。
- “cat” -> [1, 0, 0, 0, 0]
- “dog” -> [0, 1, 0, 0, 0]
- “fish” -> [0, 0, 1, 0, 0]
- “bird” -> [0, 0, 0, 1, 0]
- “rabbit” -> [0, 0, 0, 0, 1]
-
特点:
-
稀疏性
one-hot编码通常会产生非常稀疏的向量,尤其是词汇表很大时。大部分元素为零,只有一个位置是1。
-
高维度
词汇表的大小决定了one-hot向量的维度。如果词汇表包含10000个单词,那么每个单词的表示将是一个长度为10000的向量。
-
信息缺失
one-hot编码无法表达词与词之间的语义关系。例如,“cat” 和 “dog” 的表示完全不同,尽管它们在语义上很接近。
-
-
优缺点:
- 优点:实现简单,容易理解
- 缺点:高维度稀疏向量的特性导致其计算效率低下,无法捕捉词之间的语义相似性.在大语料集下,每个向量的长度过大,占据大量内存
one-hot的编码实现
核心思路: 使用Tokenizer + 列表构成的向量 实现
-
创建
Tokenizer示例
tokenizer = Tokenizer()- Tokenizer() 是
Keras.preprocessing.text模块中的一个文本处理类。 - 它用于 构建词典,并提供方法将文本转换为整数索引或其他格式(如 One-hot、词频矩阵等)。
- 默认情况下,它会自动对文本进行标记化(Tokenization),并创建一个 word_index(单词到索引的映射)
- Tokenizer() 是
-
训练
Tokenizer
tokenizer.fit_on_texts(texts=vocabs)- fit_on_texts(texts)用于基于提供的文本数据构建词典。
- texts(这里是 vocabs)应该是一个包含多个句子的列表,每个句子是一个字符串。
- Tokenizer 解析所有文本,统计每个单词的出现次数,并将单词转换为唯一的整数索引。
-
Tokenizer的主要属性word_index单词到索引的映射 => 字典类型的成员属性word_counts(单词出现次数)texts_to_sequences()(文本转索引序列)
构建one-hot编码器
from tensorflow.keras.preprocessing.text import Tokenizer
import joblib
# 根据语料库生成one-hot编码器
def dm_onehot_gen():"""1.准备语料2.实例化词汇映射器Tokenizer,使用映射器拟合现有文本 -> 生成 index_word word_index3.查询单词的索引下标4.保存映射器"""# 1. 准备语料vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "范丞丞", "杨宗纬"}# 2.实例化词汇映射器Tokenizer,使用映射器拟合现有文本 -> 生成 index_word word_indextokenizer = Tokenizer()tokenizer.fit_on_texts(texts=vocabs)print(tokenizer.word_index)# 3.查询单词的 idxfor vocab in vocabs:zero_list = [0] * len(vocabs)# 注意!! tokenizer生成的`word_index`字典是从下标1开始的idx = tokenizer.word_index[vocab] - 1zero_list[idx] = 1print(f'{vocab}的one-hot编码是->\t{zero_list}')# 4. 保存映射器path = './model/tokenizer'joblib.dump(tokenizer, filename=path)print('save tokenizer.....done')使用one-hot编码器
def dm_one_hot_use(token = '周杰伦'):"""1.加载映射器2.查询单词的索引下标,赋值给zero_list,生成one-hot向量:return:"""# 2. 加载映射器tokenizer = joblib.load('./model/tokenizer')# 3.根据给定的token查询词表进行编码zero_list = [0] * len(tokenizer.word_index)cursor = tokenizer.word_index.get(token)if cursor is not None:idx = cursor - 1zero_list[idx] = 1print(f'{token}的one-hot向量表示为->{zero_list}')else:print('语料库中找不到该词语~')raise Exception
Word2Vec
-
概念
- Word2Vec是一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,通过上下文信息来学习词语的分布式表示(即词向量)。它包含CBOW和skipgram两种训练模式。
- Word2Vec实际上利用了文本本身的信息来构建 “伪标签”。模型不是被人为地告知某个词语的正确词向量,而是通过上下文词语来预测中心词(CBOW)或者通过中心词来预测上下文词语(Skip-gram)。
- Word2Vec的目标是将每个词转换为一个固定长度的向量,这些向量能够捕捉词与词之间的语义关系。
-
特点
-
低维稠密表示
Word2Vec通过训练得到的词向量通常是稠密的,即大部分值不为零,每个向量的维度较小(通常几十到几百维)。
-
捕捉语义关系
Word2Vec可以通过词向量捕捉到词之间的语义相似性,例如通过向量运算可以发现"king"-“man”+“woman"≈"queen”。
-
-
优缺点
- 优点:能够生成稠密的词向量,捕捉词与词之间的语义关系,计算效率高。
- 缺点:需要大量的语料来训练,且可能不适用于某些特定任务(例如:词语的多义性)。
-
CBOW(Continuous bag of words)模式
- 概念:给定一段用于训练的 上下文词汇(周围词汇),预测目标词汇

例如,在句子"the quick brown fox jumps over the lazy dog"中,如果目标词是"jumps",则CBOW模型使用"the",“quick”,“brown”,“fox”,“over”,“the”,“lazy”,“dog"这些上下文词来预测"jumps”。
图中窗口大小为9, 使用前后4个词汇对目标词汇进行预测。
CBOW的核心思想:语义相近的词在相似的上下文中出现。
CBOW的模型架构
- 输入层:将上下文词的one-hot编码输入模型(窗口内的词,忽略顺序)。
- 隐藏层:对上下文词向量求平均,生成一个D维向量(词向量的中间表示)。
- 输出层:通过softmax或负采样,将隐藏层向量映射到词汇表概率分布,预测目标词。
CBOW的前向传播过程
-
输入层 → 隐藏层
-
每个上下文词通过权重矩阵 WW(维度 V×D,V为词汇表大小)映射为D维向量。
-
隐藏层输出为上下文词向量的平均值:
h = 1 C ∗ Σ c = 1 C W ∗ x c h=\frac{1}C * Σ_{c=1}^{C}W *x_c h=C1∗Σc=1CW∗xc(C为上下文词数量,** x c x_c xc**为第c个词的one-hot向量)。
-
-
隐藏层 → 输出层
-
隐藏层向量通过权重矩阵 W′W′(维度 D×V)映射到词汇表空间: u = ( W ′ ) T ⋅ h u=(W′)^T⋅h u=(W′)T⋅h
-
使用softmax计算目标词概率分布:
p ( w t ∣ c o n t e x t ) = e x p ( u w t ) Σ v = 1 V e x p ( u w t ) p(wt∣context)=\frac{exp(u_{w_t})}{Σ^{V}_{v=1}exp(u_{w_t})} p(wt∣context)=Σv=1Vexp(uwt)exp(uwt)
-
-
损失函数和优化
- 损失函数: 多分类下的交叉熵损失(实际目标词为one-hot编码): L = − l o g ( p ( w t ∣ c o n t e x t ) ) L=−log(p(w_t∣context)) L=−log(p(wt∣context))
- 参数更新:通过反向传播更新权重矩阵 W 和 W′。
- 仅更新与当前上下文词和目标词相关的行或列(稀疏更新)。
CBOW过程说明
-
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时,Hope,can,set等词汇都使用它们的one-hot编码。如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5->随机初始化,这里的3是指最后得到的词向量维度)相乘,得到上下文表示矩阵(3x1),也就是词向量。将所有上下文词语的词向量按元素平均,得到平均词向量。

-
接着, 将上下文表示矩阵(平均词向量)与变换矩阵(参数矩阵5x3->随机初始化,所有的变换矩阵共享参数)相乘,得到5x1的结果矩阵,使用softmax函数将得分向量转换为概率分布,它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失的计算,然后更新网络参数完成一次模型迭代。

-
最后窗口按顺序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。
-
Skip-gram模式
-
概念:给定一个目标词,预测其上下文词汇。

例如,在句子"the quick brown fox jumps over the lazy dog"中,如果目标词是"jumps",skip-gram模型尝试预测它周围的词,如"the",“quick”,“brown”,“fox”,“over”,“the”,“lazy”,“dog”。
图中窗口大小为9,使用目标词汇对前后四个词汇进行预测。
- 核心思想:一个词的含义可以通过其周围的上下文词来表征。
Skip-gram的模型结构:
- 输入层: 输入目标词的one-hot编码。
- 隐藏层: 将目标词映射成D维向量(转换为低维稠密向量)
- 输出层:通过softmax或负采样,预测窗口内所有上下文词的概率分布。
Skip-gram的前向传播过程
-
输入层 → 隐藏层
- 目标词的one-hot编码 x 通过权重矩阵 W**(维度 V×D)映射为D维向量: h = W T ⋅ x h=W^T⋅x h=WT⋅x
- 此向量 h 直接表示目标词的词向量。
-
隐藏层 → 输出层
- 对每个上下文词位置,计算其概率分布: u c = ( W ′ ) T ⋅ h , ( c = 1 , 2 , … , C ) u_c=(W′)^T⋅h ,(c=1,2,…,C) uc=(W′)T⋅h,(c=1,2,…,C)
W′是输出权重矩阵,维度 D×V ,C 为窗口内上下文词总数
- 使用softmax为每个上下文位置生成概率:
p ( w c ∣ w t ) = e x p ( u c , w c ) Σ v = 1 V e x p ( u c , w c ) p(wc∣wt)=\frac{exp(uc,wc)}{Σ^{V}_{v=1}exp(uc,wc)} p(wc∣wt)=Σv=1Vexp(uc,wc)exp(uc,wc)
-
损失函数与优化
- 损失函数:对每个上下文词计算交叉熵损失,并求和: L = − ∑ c = 1 C l o g p ( w c ∣ w t ) L=−∑_{c=1}^Clogp(wc∣wt) L=−∑c=1Clogp(wc∣wt)
- 参数更新:通过反向传播更新 WW 和 W′W′,仅涉及目标词和上下文词相关的行或列。
-
-
Skip-gram模式下的word2vec过程说明
-
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是skip-gram模式,所以将使用can作为输入,Hope和set作为输出,在模型训练时,Hope、can、set等词汇都使用它们的one-hot编码。如图所示: 将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1)。
-
接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵,使用softmax函数将得分向量转换为概率分布,它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代。
-
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。

-
-
词向量的检索获取
-
神经网络训练完毕后,神经网络的参数矩阵w就我们的想要词向量。如何检索某1个单词的向量呢?以CBOW方式举例说明如何检索a单词的词向量。
-
如下图所示:a的onehot编码[10000],用参数矩阵[3,5] * a的onehot编码[10000],可以把参数矩阵的第1列参数给取出来,这个[3,1]的值就是a的词向量。

-
Word2Vec的编码实现
使用的核心库与函数介绍
fasttext:是facebook开源的一个词向量与文本分类工具。
下面是该工具包的安装方法:
-
官网(fasttext-wheel)下载对应操作系统对应python解析器版本的
fasttext模块的whl文件 -
进入到base虚拟环境,然后在whl文件目录下通过以下命令安装
# 当前目录下要有whl文件名称 pip install asttext_wheel-0.9.2-cp311-cp311-win_amd64.whl
使用到的函数:fasttext.train_unsuperised
函数功能:返回一个无监督训练过后的词向量训练模型部分超参数解释
input:输入的文件路径
model:'skipgram'或者'cbow', 默认为'skipgram',在实践中,skipgram模式在利用子词方面比cbow更好.
dim:词嵌入维度
epoch:训练迭代次数
lr:学习率
thread:使用的线程数
实现流程
数据来源:http://mattmahoney.net/dc/enwik9.zip
- 原始数据预处理
# 使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容
perl wikifil.pl data/enwik9 > data/fil9 # 该命令已经执行
- 词向量的训练
import fasttextdef word2vec_train():model = fasttext.train_unsupervised(input='./data/fil9', model='skipgram', dim=300, lr=1e-1, epoch=1, thread=12)print('word2vec->done')model.save_model(path='./model/fil9.bin')print('model->save')
- 模型效果检验
def model_use(k=10):model = fasttext.load_model(path='./model/fil9.bin')vector = model.get_word_vector(word='the')print(f'the的词向量表示为{vector}')nn = model.get_nearest_neighbors(word='the', k=k)print(f'the的{k}个最相近邻居为:{nn}')
词嵌入 Word Embedding
Word Embedding(词嵌入)是一种将自然语言中的词语映射到低维连续向量空间的技术,使得词语的语义和语法关系能通过向量间的距离和方向体现。它是自然语言处理(NLP)的基础技术之一。
经典模型与方法
- Word2Vec(2013)
- Skip-Gram:通过中心词预测上下文词。
- CBOW(Continuous Bag-of-Words):通过上下文词预测中心词。
- 示例:
king - man + woman ≈ queen(向量运算体现语义关系)。
Word2Vec是一种Word Embedding方法,专门用于生成词的稠密向量表示。Word2Vec通过神经网络训练,利用上下文信息将每个词表示为一个低维稠密向量。
- GloVe(2014)
基于全局词共现矩阵,结合统计信息与局部上下文,优化词语的向量表示。 - 上下文相关嵌入
- ELMo(2018):通过双向LSTM生成动态词向量,同一词在不同语境中有不同表示。
- BERT(2018):基于Transformer的预训练模型,通过掩码语言建模(MLM)捕捉深层上下文信息。
编码实现(了解)
import jieba
import torch
from tensorflow.keras.preprocessing.text import Tokenizer
import torch.nn as nndef dm_embedd():# todo:1-创建文本句子, 生成文本sentence1 = '哎呀~今天天气真好'sentence2 = "只因你实在是太美"sentences = [sentence1, sentence2]print('sentences->', sentences)# todo: 2-获取文本词列表word_list = list()for s in sentences:word_list.append(jieba.lcut(s))print('word_list->', word_list)# todo: 3- 借助Tokenizer类,实现下标与词的映射字典,文本下标表示"""Tokenizer类的参数:num_words: the maximum number of words to keep, basedon word frequency. Only the most common `num_words-1` words willbe kept.filters: a string where each element is a character that will befiltered from the texts. The default is all punctuation, plustabs and line breaks, minus the `'` character.lower: boolean. Whether to convert the texts to lowercase.split: str. Separator for word splitting.char_level: if True, every character will be treated as a token.oov_token: if given, it will be added to word_index and used toreplace out-of-vocabulary words during text_to_sequence callsanalyzer: function. Custom analyzer to split the text.The default analyzer is text_to_word_sequence"""tokenizer = Tokenizer()tokenizer.fit_on_texts(texts=word_list)# 打印 my_token_listmy_token_list = tokenizer.index_word.values() # <class 'dict_values'># print('my_token_list->', my_token_list)# 打印文本数值化后的句子sentence2id = tokenizer.texts_to_sequences(texts=word_list)# print('sentence2id->', sentence2id)# todo: 4- 创建nn.Embedding层embed = nn.Embedding(num_embeddings=len(my_token_list), embedding_dim=8)# print('embed--->',embed)# print('nn.Embedding层词向量矩阵-->', embed.weight.data, embed.weight.data.shape, type(embed.weight.data))# # todo: 5-创建SummaryWriter对象# from torch.utils.tensorboard import SummaryWriter# summary_writer = SummaryWriter(log_dir='./data/runs')# # add_embedding(mat=embed.weight.data, metadata=my_token_list)# # mat:词向量表示 张量或numpy数组# # metadata:词标签# # 作用: 将高维数据(如词嵌入、特征向量等)投影到低维空间(通常是二维或三维),以便在 TensorBoard 的 Embedding Projector 中进行可视化。# summary_writer.add_embedding(mat=embed.weight.data, metadata=my_token_list)# summary_writer.close()# todo: 5-创建SummaryWriter对象from torch.utils.tensorboard import SummaryWritersummary_writer = SummaryWriter(log_dir='./data/runs')# add_embedding(mat=embed.weight.data, metadata=my_token_list)# mat:词向量表示 张量或numpy数组# metadata:词标签# 作用: 将高维数据(如词嵌入、特征向量等)投影到低维空间(通常是二维或三维),以便在 TensorBoard 的 Embedding Projector 中进行可视化。summary_writer.add_embedding(mat=embed.weight.data, metadata=my_token_list)summary_writer.close()# todo: -6 从nn.Embedding层中根据idx拿词向量for idx in range(len(my_token_list)):tmp_vector = embed(torch.tensor(idx))print(f'{tokenizer.index_word[idx + 1]}的词嵌入向量为:{tmp_vector.detach().numpy()}')相关文章:
02_NLP文本预处理之文本张量表示法
文本张量表示法 概念 将文本使用张量进行表示,一般将词汇表示为向量,称为词向量,再由各个词向量按顺序组成矩阵形成文本表示 例如: ["人生", "该", "如何", "起头"]># 每个词对应矩阵中的一个向量 [[1.32, 4,32, 0,32, 5.2],[3…...

深圳SMT贴片加工核心工艺解析
内容概要 深圳作为全球电子制造产业的核心集聚区,其SMT贴片加工技术始终引领行业创新方向。本文聚焦深圳电子制造企业在高密度、微型化组件加工中的核心工艺体系,系统解析从锡膏印刷到成品检测的全流程关键技术。通过梳理SMT产线中设备参数设定、工艺条…...
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair
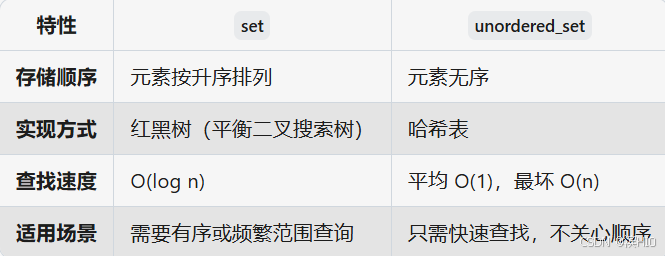
P8720 [蓝桥杯 2020 省 B2] 平面切分--set、pair 题目 分析一、pair1.1pair与vector的区别1.2 两者使用场景两者组合使用 二、set2.1核心特点2.2set的基本操作2.3 set vs unordered_set示例:统计唯一单词数代码 题目 分析 大佬写的很明白,看这儿 我讲讲…...

突破传统:用Polars解锁ICU医疗数据分析新范式
一、ICU数据革命的临界点 在重症监护室(ICU),每秒都在产生关乎生死的关键数据:从持续监测的生命体征到高频更新的实验室指标,从呼吸机参数到血管活性药物剂量,现代ICU每天产生的数据量级已突破TB级别。传统…...

命名实体识别与文本生成算法
在自然语言处理(NLP)的浩瀚星空中,命名实体识别(Named Entity Recognition, NER)与文本生成算法如同两颗璀璨的星辰,各自闪耀,又相互辉映,共同推动着人工智能技术在语言理解与生成领…...

10.3 指针进阶_代码分析
代码分析 9. 指针和数组代码解析一维数组字符数组字符串二维数组 10. 指针代码分析eg1eg2eg3eg4eg5eg6eg7eg8 10.1 指针进阶_数组指针 10.2 指针进阶_函数指针 9. 指针和数组代码解析 数组名arr是首元素地址 例外: 1. sizeof(arr),计算整个数组的大小&…...

深入理解推理语言模型(RLM)
大语言模型从通用走向推理,万字长文解析推理语言模型,建议收藏后食用。 本文基于苏黎世联邦理工学院的论文《Reasoning Language Models: A Blueprint》进行整理,你将会了解到: 1、RLM的演进与基础:RLM融合LLM的知识广…...

在Nginx上配置并开启WebDAV服务的完整指南
在Nginx上配置并开启WebDAV服务的完整指南 如何在 Nginx 上开启 WebDAV 服务 要在 Nginx 上开启 WebDAV 服务,你需要配置 Nginx 以支持 WebDAV 请求。以下是详细的步骤: 1. 确保 Nginx 安装了 WebDAV 模块 Nginx 的 WebDAV 功能由 http_dav_module 模…...

大语言模型学习
大语言模型发展历程 当前国内外主流LLM模型 一、国外主流LLM LLaMA2 Meta推出的开源模型,参数规模涵盖70亿至700亿,支持代码生成和多领域任务适配57。衍生版本包括Code Llama(代码生成优化)和Llama Chat(对…...

夜天之书 #106 Apache 软件基金会如何投票选举?
近期若干开源组织进行换届选举。在此期间,拥有投票权的成员往往会热烈讨论,提名新成员候选人和治理团队的候选人。虽然讨论是容易进行的,但是实际的投票流程和运作方式,在一个成员众多的组织中,可能会有不少成员并不清…...

从Aurora看Xanadu可扩展模块化光量子计算机的现状与未来展望
从Aurora看Xanadu可扩展光量子计算机的现状与未来展望 一、引言 1.1 研究背景与意义 随着信息技术的飞速发展,经典计算机在许多领域取得了巨大的成功,但在面对一些复杂问题时,其计算能力逐渐接近极限。量子计算机作为一种新型计算设备,基于量子力学原理,能够实现并行计算…...

WPS如何添加论文中的文献引用右上角小标
给参考文献标号 1、将光标位于参考文献之前,然后点击如下图所示位置 2、点击相应的列表,然后点击确定 然后选中第一行,点击格式刷,刷一下其余行 在原文中插入右上角的引用标 1、使光标位于想插入引用光标处,点击交叉…...

如何理解语言模型
统计语言模型 先看语言模型,语言即自然语言,模型及我们要解决的某个任务。 任务一:判断哪句话出现的概率大 任务二:预判空缺的位置最有可能是哪个词 再看统计,统计即解决上述两个任务的解决方法。先对语句进行分词…...

准确-NGINX 1.26.2配置正向代理并编译安装的完整过程
NGINX 1.26.2 配置正向代理并编译安装的完整过程,使用了 ngx_http_proxy_connect_module 模块。 1. 环境准备 1.1 安装依赖 确保系统安装了以下必要的依赖: sudo yum install -y gcc gcc-c make pcre-devel zlib-devel openssl-devel1.2 下载 NGINX 源…...

企业如何将ERP和BPM项目结合提升核心竞争力
无论是实施ERP项目还是BPM项目,企业变革的根本目的的确是为了让企业变得更加强大,更具竞争力。 这就像是练武功,无论是学习少林拳还是太极拳,最终的目标都是为了强身健体,提升战斗力。 如何将ERP和BPM项目有效结合以及…...

Linux内核以太网驱动分析
1.网络接口卡接收和发送数据在Linux内核中的处理流程如下: 1. 网络接口卡(Network Interface Card, NIC) 作用:负责物理层的数据传输,将数据包从网络介质(如以太网线)读取到内存中,或…...

分布式微服务系统架构第92集:智能健康监测设备Java开发方案
加群联系作者vx:xiaoda0423 仓库地址:https://webvueblog.github.io/JavaPlusDoc/ https://1024bat.cn 嗯,用户需要为血压、血糖、尿酸和血酮测试仪编写产品描述,同时涉及Java开发。首先,我得确定他们的需求是什么。可…...

【推荐项目】023-游泳俱乐部管理系统
023 游泳俱乐部管理系统 游泳俱乐部管理系统概述 前端技术框架: 我们优雅地采用了Vue.js作为游泳俱乐部管理系统的前端基础框架。Vue.js以其轻盈、高效和易于上手的特点,为我们的用户界面带来了极致的流畅性和响应速度。通过Vue.js,我们为…...

Webpack常见配置实例
webpack实例 打包构建流程对应的常见配置 1. mode: development2. entry: ./src/index.js3. output4. module.rules5. Loader6. Plugin7. devServerwebpack.config.js webpack常见配置实例 配置详解 mode: ‘development’: 设置 Webpack 运行模式&am…...

C++核心编程之STL
STL初识:从零开始的奇幻冒险 1 STL的诞生:一场代码复用的革命 很久很久以前,在编程的世界里,开发者们每天都在重复造轮子。无论是数据结构还是算法,每个人都得从头开始写,仿佛在无尽的沙漠中寻找绿洲。直到…...

28 岁大专学历顺利转行网安 过来人 8 条避坑经验心得
网络安全行业 “人才缺口 300 万 、平均年薪超 25 万” 的红利,让无数职场人动了转行心思。尤其是学历普通(如大专)的群体,既面临原有岗位的天花板,又渴望通过技术转型实现薪资跃迁。但网安行业看似门槛低,…...

项目管理专题会议圆满举办丨AI+数据驱动:重塑项目管理全链路
2026 年 5 月 20 日,由深圳市软件行业协会、易趋 、腾讯TAPD主办的第十四期项目管理专题活动 ——AI 如何重塑项目管理全链路主题沙龙在深圳圆满举行。来自IT、制造、金融等领域的PMO、项目管理专家、技术实践者,以及CIO/CTO等高层决策者共同探讨 AI 时代…...

ARM嵌入式开发中DS-5内存优化与JVM调优实战
1. 问题现象与背景分析最近在调试基于ARM架构的嵌入式系统时,遇到了一个棘手的问题:DS-5开发环境中的Eclipse频繁崩溃,控制台反复弹出"JVM terminated"错误提示,有时还会显示"Java was started but exited with re…...

迁移学习提升可穿戴设备睡眠监测精度的技术解析
1. 项目概述:迁移学习如何提升可穿戴设备的睡眠监测精度作为一名长期关注健康监测技术的从业者,我见证了可穿戴设备在睡眠监测领域的快速发展。但一个核心痛点始终存在:基于PPG(光电容积图)等外周生理信号的可穿戴设备…...

BarrageGrab:构建企业级直播弹幕实时采集系统的技术架构与实践指南
BarrageGrab:构建企业级直播弹幕实时采集系统的技术架构与实践指南 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直…...

基于RL78/G13的电位器ADC采集与串口通信上位机显示系统设计
1. 项目概述与核心思路最近在整理工作室的旧零件,翻出来一块瑞萨电子的RL78/G13开发板,还有几个吃灰的电位器。想着不能浪费,就琢磨着做个简单但能体现MCU基本功的小项目:用这块开发板实时采集电位器的电压,并把数据上…...

选RFID仓储管理系统厂家别只盯着参数!老采购教你用场景思维找到真正靠谱的供应商
很多企业在选型RFID仓储管理系统时,第一反应是翻遍全网找“RFID智能仓储管理系统厂家有哪些”,然后把七八家供应商的参数表摊在桌上逐一对比。读取速度多少、识别距离多远、支持多少标签同时读取——这些指标当然重要,但如果你的选型逻辑仅停…...

OpenCorePkg黑苹果引导配置:从传统引导到现代解决方案的完整迁移指南
OpenCorePkg黑苹果引导配置:从传统引导到现代解决方案的完整迁移指南 【免费下载链接】OpenCorePkg OpenCore bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCorePkg 面对黑苹果引导过程中的稳定性问题、安全漏洞和硬件兼容性限制,…...

APKToolGUI:让Android逆向变得像搭积木一样简单
APKToolGUI:让Android逆向变得像搭积木一样简单 【免费下载链接】APKToolGUI GUI for apktool, signapk, zipalign and baksmali utilities. 项目地址: https://gitcode.com/gh_mirrors/ap/APKToolGUI 你是否曾经想要修改一个Android应用,却发现需…...

KAG增强生成、AlphaMath推理与Offloading协同架构
1. 项目概述:一场聚焦模型轻量化与推理边界的深度技术切片 “AI Innovations and Insights 23: KAG, AlphaMath, and Offloading”这个标题,乍看像是一场行业峰会的分论坛名称,但拆开来看,它其实是一份高度凝练的技术路线图——KA…...