湖仓一体概述
湖仓一体之前,数据分析经历了数据库、数据仓库和数据湖分析三个时代。
-
首先是数据库,它是一个最基础的概念,主要负责联机事务处理,也提供基本的数据分析能力。
-
随着数据量的增长,出现了数据仓库,它存储的是经过清洗、加工以及建模后的高价值的数据,供业务人员进行数据分析。
-
数据湖的出现,主要是为了去满足企业对原始数据的存储、管理和再加工的需求。这里的需求主要包括两部分,首先要有一个低成本的存储,用于存储结构化、半结构化,甚至非结构化的数据;另外,就是希望有一套包括数据处理、数据管理以及数据治理在内的一体化解决方案。
数据仓库解决了数据快速分析的需求,数据湖解决了数据的存储和管理的需求,而湖仓一体要解决的就是如何让数据能够在数据湖和数据仓库之间进行无缝的集成和自由的流转,从而帮助用户直接利用数据仓库的能力来解决数据湖中的数据分析问题,同时又能充分利用数据湖的数据管理能力来提升数据的价值。
适用场景
Doris 在设计湖仓一体时,主要考虑如下四个应用场景:
-
湖仓查询加速:Doris 作为一个非常高效的 OLAP 查询引擎,有着非常好的 MPP 向量化的分布式的查询层,可以直接利用 Doris 非常高效的查询引擎,对湖上数据进行加速分析。
-
统一数据分析网关:提供各类异构数据源的查询和写入能力,支持用户将这些外部数据源统一到 Doris 的元数据映射结构上,当用户通过 Doris 查询这些外部数据源时,能够提供一致的查询体验。
-
统一数据集成:首先通过数据湖的数据源连接能力,能够让多数据源的数据以增量或全量的方式同步到 Doris,并且利用 Doris 的数据处理能力对这些数据进行加工。加工完的数据一方面可以直接通过 Doris 对外提供查询,另一方面也可以通过 Doris 的数据导出能力,继续为下游提供全量或增量数据服务。通过 Doris 可以减少对外部工具的依赖,可以直接将上下游数据,以及包括同步、加工、处理在内的整条链路打通。
-
更加开放的数据平台:众多数据仓库有着各自的存储格式,用户如果想要使用一个数据仓库,第一步就需要把外部数据通过某种方式导入到数据仓库中才能进行查询。这样就是一个比较封闭的生态,数据仓库中数据除了数仓自己本身可以查询以外,其它外部工具是无法进行直接访问的。一些企业在使用包括 Doris 在内的一些数仓产品的时候就会有一些顾虑,比如数据是否会被锁定到某一个数据仓库里,是否还有便捷的方式进行导出。通过湖仓一体生态的接入,可以用更加开放的数据格式来管理数据,比如可以用 Parquet/ORC 格式来去存储数据,这样开放开源的数据格式可以被很多外部系统去访问。另外,Iceberg,Hudi 等都提供了开放式的元数据管理能力,不管元数据是存储在 Doris 本身,还是存储在 Hive Meta store,或者存储在其它统一元数据中心,都可以通过一些对外公开的 API 对这些数据进行管理。通过更加开放的数据生态,可以帮助企业更快地接入一个新的数据管理系统,降低企业数据迁移的成本和风险。
基于 Doris 的湖仓一体架构
Doris 通过多源数据目录(Multi-Catalog)功能,支持了包括 Apache Hive、Apache Iceberg、Apache Hudi、Apache Paimon、LakeSoul、Elasticsearch、MySQL、Oracle、SQL Server 等主流数据湖、数据库的连接访问。以及可以通过 Apache Ranger 等进行统一的权限管理,具体架构如下:

其数据湖的主要对接流程为:
-
创建元数据映射:Doris 通过 Catalog 获取数据湖元数据并缓存在 Doris 中,用于数据湖元数据的管理。在元数据映射过程中 Doris 除了支持传统 JDBC 的用户名密码认证外,还支持基于 Kerberos 和 Ranger 的权限认证,基于 KMS 的数据加密。
-
发起查询操作:当用户从 FE 发起数据湖查询时,Doris 使用自身存储的数据湖元数生成造查询计划,利用 Native 的 Reader 组件从外部存储(HDFS、S3)上获取数据进行数据计算和分析。在数据查询过程中 Doris 会将数据湖热点数据缓存在本地,当下次相同查询到来时数据缓存能很好起到查询加速的效果。
-
结果返回:当查询完成后将查询结果通过 FE 返回给用户。
-
计算结果入湖:当用户并不想将计算结果返回,而是需要将计算结果进一步写入数据湖时可以通过 export 的方式以标准数据格式(CSV、Parquet、ORC)将数据写回数据湖。
核心技术
在多源数据连接上 Doris 通过可扩展连接器读取外部数据。同时通过元数据缓存、数据缓存、Native Reader、IO 优化、统计信息优化等一些措施,极大加速了数据湖分析能力。
可扩展的连接框架
在数据的对接中包括元数据的对接和数据的读取。
-
元数据对接:元数据对接在 FE 完成,通过 FE 的 MetaData 管理器来实现基于 HiveMetastore、JDBC 和文件的元数据对接和管理工作。
-
数据读取:通过 NativeReader 可以高效的读取存放在 HDFS、对象存储上的 Parquet、ORC、Text 格式数据。也可以通过 JniConnector 对接 Java 大数据生态。

高效缓存策略
Doris 通过元数据缓存、数据缓存和查询结果缓存来提升查询性能。
元数据缓存
Doris 提供了手动同步元数据、定期自动同步元数据、元数据订阅(只支持 HiveMetastore)三种方式来同步数据湖的元数据信息到 Doris,并将元数据存储在 Doris 的 FE 的内存中。当用户发起查询后 Doris 直接从内存中获取元数据并快速生成查询规划。保障了元数据的实时和高效。在元数据同步上 Doris 通过并发的元数据事件合并实现高效的元数据同步,其每秒可以处理 100 个以上的元数据事件。

高效的数据缓存
-
文件缓存:Doris 通过将数据湖中的热点数据存储在本地磁盘上,减少数据扫描过程中网络数据的传输,提高数据访问的性能。
-
缓存分布策略:在数据缓存中 Doris 通过一致性哈希将数据分布在各个 BE 节点上,尽量避免节点扩缩容带来的缓存失效问题。
-
缓存淘汰(更新)策略:同时当 Doris 发现数据文件对应的元数据更新后,会及时淘汰缓存以保障数据的一致性。

查询结果缓存和分区缓存
-
查询结果缓存:Doris 根据 SQL 语句将之前查询的结果缓存起来,当下次相同的查询再次发起时可以直接从缓存中获取数据返回到客户端,极大的提高了查询的效率和并发。
-
分区缓存:Doris 还支持将部分分区数据缓存在 BE 端提升查询效率。比如查询最近 7 天的数据,可以将前 6 天的计算后的缓存结果,和当天的事实计算结果进行合并,得到最终查询结果,最大限度减少实时计算的数据量,提升查询效率。

高效的 Native Reader
-
自研 Native Reader 避免数据转换:Doris 在数据分析时有其自身的列存方式,同时 Parquet、ORC 也有自身的列存格式。如果直接使用开源的 Parquet 或者 ORC Reader 的话就会存在一个 Doris 列存和 Parquet/ORC 列存的转换过程。这样的话就会多一次格式转换的开销,为了解决这个问题 我们自研了一套 Parquet/ORC NativeReader,直接读取 Parquet、ORC 文件来提高查询效率。
-
延迟物化:同时我们实现的 Native Reader 还能很好的利用智能索引和过滤器提高数据读取效率。比如说在某些场景下我可能只针对 ID 列去做一个过滤。我们的优化做法是首先第一步我会把 ID 列单独读出来。然后在这一列上做完过滤以后,我会把这个过滤后的剩余下来的这个行号记录下来。拿这个行号再去读剩下两列,这样来进一步的减少数据扫描,加速文件的分析性能。

- 向量化读取数据:同时在文件数据的读取过程中我们引入向量化的方式读取数据,极大加速了数据读取效率。

Merge IO
在网络中难免会出现大量小文件的网络 IO 请求取影响 IO 性能,在这种情况下我们采用 IO 合并去优化这种情况。
比如我们设置一个策略将小于 3MB 的 IO 请求合并(Merge IO)在一次请求中处理。那么之前可能是有 8 次的小的 IO 请求,我们可以把 8 次合并成 5 次 IO 请求去去读取数据。这样减少了网络 IO 请求的速度,提高了网络访问数据的效率。
Merge IO 的确定是它可能会读取一些不必要的数据,因为它把中间可能不必要读取的数据合并起来一块读过来了。但是从整体的吞吐上来讲其性能有很大的提高,在碎文件(比如:1KB - 1MB)较多的场景优化效果很明显。同时我们通过控制 Merge IO 的大小来达到整体的平衡。

统计信息提高查询规划效果
Doris 通过收集统计信息有助于优化器了解数据分布特性,在进行 CBO(基于成本优化)时优化器会利用这些统计信息来计算谓词的选择性,并估算每个执行计划的成本。从而选择更优的计划以大幅提升查询效率。在数据湖场景我们可以通过收集外表的统计信息来提升查询规划器的效果。
统计信息的收集方式包括手动收集和自动收集。
同时为了保证收集统计信息不会对 BE 产生压力,我们支持了采样收集统计信息。
在一些场景下用户历史数据可能很少查找,但是热数据会被经常访问,因此我们也提供了基于分区的统计信息收集在保障热数据高效的查询效率和统计信息收集对 BE 产生负载的中间取得平衡。

多源数据目录
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强 Doris 的数据湖分析和联邦数据查询能力。
在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接一个外部数据目录时,我们只能在 Database 或 Table 层级进行对接。比如通过 create external table 的方式创建一个外部数据目录中的表的映射,或通过 create external database 的方式映射一个外部数据目录中的 Database。如果外部数据目录中的 Database 或 Table 非常多,则需要用户手动进行一一映射,使用体验不佳。
而新的 Multi-Catalog 功能在原有的元数据层级上,新增一层 Catalog,构成 Catalog -> Database -> Table 的三层元数据层级。
该功能将作为之前外表连接方式(External Table)的补充和增强,帮助用户进行快速的多数据目录联邦查询。
基础概念
-
Internal Catalog
Doris 原有的 Database 和 Table 都将归属于 Internal Catalog。Internal Catalog 是内置的默认 Catalog,用户不可修改或删除。
-
External Catalog
可以通过 CREATE CATALOG 命令创建一个 External Catalog。创建后,可以通过 SHOW CATALOGS 命令查看已创建的 Catalog。
-
切换 Catalog
用户登录 Doris 后,默认进入 Internal Catalog,因此默认的使用和之前版本并无差别,可以直接使用
SHOW DATABASES,USE DB等命令查看和切换数据库。用户可以通过 SWITCH 命令切换 Catalog。如:
SWITCH internal; SWITCH hive_catalog;切换后,可以直接通过
SHOW DATABASES,USE DB等命令查看和切换对应 Catalog 中的 Database。Doris 会自动通过 Catalog 中的 Database 和 Table。用户可以像使用 Internal Catalog 一样,对 External Catalog 中的数据进行查看和访问。 -
删除 Catalog
可以通过 DROP CATALOG 命令删除一个 External Catalog,Internal Catalog 无法删除。该操作仅会删除 Doris 中该 Catalog 的映射信息,并不会修改或变更任何外部数据目录的内容。
连接示例
连接 Hive
这里我们通过连接一个 Hive 集群说明如何使用 Catalog 功能。
更多关于 Hive 的说明,请参阅:Hive Catalog
1. 创建 Catalog
CREATE CATALOG hive PROPERTIES ('type'='hms','hive.metastore.uris' = 'thrift://172.21.0.1:7004'
);
更多查看:CREATE CATALOG 语法帮助
2. 查看 Catalog
3. 创建后,可以通过 SHOW CATALOGS 命令查看 catalog:
mysql> SHOW CATALOGS;
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| CatalogId | CatalogName | Type | IsCurrent | CreateTime | LastUpdateTime | Comment |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| 10024 | hive | hms | yes | 2023-12-25 16:11:41.687 | 2023-12-25 20:43:18 | NULL |
| 0 | internal | internal | | UNRECORDED | NULL | Doris internal catalog |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
-
SHOW CATALOGS 语法帮助
-
可以通过 SHOW CREATE CATALOG 查看创建 Catalog 的语句。
-
可以通过 ALTER CATALOG 修改 Catalog 的属性。
4. 切换 Catalog
通过 SWITCH 命令切换到 hive catalog,并查看其中的数据库:
mysql> SWITCH hive;
Query OK, 0 rows affected (0.00 sec)mysql> SHOW DATABASES;
+-----------+
| Database |
+-----------+
| default |
| random |
| ssb100 |
| tpch1 |
| tpch100 |
| tpch1_orc |
+-----------+
查看更多:SWITCH 语法帮助
5. 使用 Catalog
切换到 Catalog 后,则可以正常使用内部数据源的功能。
如切换到 tpch100 数据库,并查看其中的表:
mysql> USE tpch100;
Database changedmysql> SHOW TABLES;
+-------------------+
| Tables_in_tpch100 |
+-------------------+
| customer |
| lineitem |
| nation |
| orders |
| part |
| partsupp |
| region |
| supplier |
+-------------------+
查看 lineitem 表的 schema:
mysql> DESC lineitem;
+-----------------+---------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+---------------+------+------+---------+-------+
| l_shipdate | DATE | Yes | true | NULL | |
| l_orderkey | BIGINT | Yes | true | NULL | |
| l_linenumber | INT | Yes | true | NULL | |
| l_partkey | INT | Yes | true | NULL | |
| l_suppkey | INT | Yes | true | NULL | |
| l_quantity | DECIMAL(15,2) | Yes | true | NULL | |
| l_extendedprice | DECIMAL(15,2) | Yes | true | NULL | |
| l_discount | DECIMAL(15,2) | Yes | true | NULL | |
| l_tax | DECIMAL(15,2) | Yes | true | NULL | |
| l_returnflag | TEXT | Yes | true | NULL | |
| l_linestatus | TEXT | Yes | true | NULL | |
| l_commitdate | DATE | Yes | true | NULL | |
| l_receiptdate | DATE | Yes | true | NULL | |
| l_shipinstruct | TEXT | Yes | true | NULL | |
| l_shipmode | TEXT | Yes | true | NULL | |
| l_comment | TEXT | Yes | true | NULL | |
+-----------------+---------------+------+------+---------+-------+
查询示例:
mysql> SELECT l_shipdate, l_orderkey, l_partkey FROM lineitem limit 10;
+------------+------------+-----------+
| l_shipdate | l_orderkey | l_partkey |
+------------+------------+-----------+
| 1998-01-21 | 66374304 | 270146 |
| 1997-11-17 | 66374304 | 340557 |
| 1997-06-17 | 66374400 | 6839498 |
| 1997-08-21 | 66374400 | 11436870 |
| 1997-08-07 | 66374400 | 19473325 |
| 1997-06-16 | 66374400 | 8157699 |
| 1998-09-21 | 66374496 | 19892278 |
| 1998-08-07 | 66374496 | 9509408 |
| 1998-10-27 | 66374496 | 4608731 |
| 1998-07-14 | 66374592 | 13555929 |
+------------+------------+-----------+
也可以和其他数据目录中的表进行关联查询:
mysql> SELECT l.l_shipdate FROM hive.tpch100.lineitem l WHERE l.l_partkey IN (SELECT p_partkey FROM internal.db1.part) LIMIT 10;
+------------+
| l_shipdate |
+------------+
| 1993-02-16 |
| 1995-06-26 |
| 1995-08-19 |
| 1992-07-23 |
| 1998-05-23 |
| 1997-07-12 |
| 1994-03-06 |
| 1996-02-07 |
| 1997-06-01 |
| 1996-08-23 |
+------------+
-
这里我们通过
catalog.database.table这种全限定的方式标识一张表,如:internal.db1.part。 -
其中
catalog和database可以省略,缺省使用当前 SWITCH 和 USE 后切换的 Catalog 和 Database。 -
可以通过 INSERT INTO 命令,将 Hive Catalog 中的表数据,插入到 Interal Catalog 中的内部表,从而达到导入外部数据目录数据的效果:
mysql> SWITCH internal;
Query OK, 0 rows affected (0.00 sec)mysql> USE db1;
Database changedmysql> INSERT INTO part SELECT * FROM hive.tpch100.part limit 1000;
Query OK, 1000 rows affected (0.28 sec)
{'label':'insert_212f67420c6444d5_9bfc184bf2e7edb8', 'status':'VISIBLE', 'txnId':'4'}
列类型映射
用户创建 Catalog 后,Doris 会自动同步数据目录的数据库和表,针对不同的数据目录和数据表格式,Doris 会进行以下列映射关系。
对于当前无法映射到 Doris 列类型的外表类型,如 UNION, INTERVAL 等。Doris 会将列类型映射为 UNSUPPORTED 类型。对于 UNSUPPORTED 类型的查询,示例如下:
假设同步后的表 schema 为:
k1 INT,
k2 INT,
k3 UNSUPPORTED,
k4 INT
select * from table; // Error: Unsupported type 'UNSUPPORTED_TYPE' in 'k3
select * except(k3) from table; // Query OK.
select k1, k3 from table; // Error: Unsupported type 'UNSUPPORTED_TYPE' in 'k3
select k1, k4 from table; // Query OK.
不同的数据源的列映射规则,请参阅不同数据源的文档。
权限管理
使用 Doris 对 External Catalog 中库表进行访问时,默认情况下,依赖 Doris 自身的权限访问管理功能。
Doris 的权限管理功能提供了对 Catalog 层级的扩展,具体可参阅 认证和鉴权 文档。
用户也可以通过 access_controller.class 属性指定自定义的鉴权类。如通过指定:
"access_controller.class" = "org.apache.doris.catalog.authorizer.ranger.hive.RangerHiveAccessControllerFactory"
则可以使用 Apache Ranger 对 Hive Catalog 进行鉴权管理。详细信息请参阅:Hive Catalog
指定需要同步的数据库
通过在 Catalog 配置中设置 include_database_list 和 exclude_database_list 可以指定需要同步的数据库。
include_database_list: 支持只同步指定的多个 database,以 , 分隔。默认同步所有 database。db 名称是大小写敏感的。
exclude_database_list: 支持指定不需要同步的多个 database,以 , 分割。默认不做任何过滤,同步所有 database。db 名称是大小写敏感的。
相关文章:
湖仓一体概述
湖仓一体之前,数据分析经历了数据库、数据仓库和数据湖分析三个时代。 首先是数据库,它是一个最基础的概念,主要负责联机事务处理,也提供基本的数据分析能力。 随着数据量的增长,出现了数据仓库,它存储的是…...

【行政区划获取】
行政区划获取 获取2023年的行政区划,并以 编码: 省市区 格式保存为字典方便后续调用 注:网址可能会更新,根据最新的来 # 获取并保存行政区划代码 import requests from lxml import etree import jsondef fetch_html(url):""&quo…...

【深入剖析:机器学习、深度学习与人工智能的关系】
深入剖析:机器学习、深度学习与人工智能的关系 在当今数字化时代,人工智能(AI)、机器学习(ML)和深度学习(DL)这些术语频繁出现在各种科技报道和讨论中,它们相互关联又各…...

Docker 学习(一)
一、Docker 核心概念 Docker 是一个开源的容器化平台,允许开发者将应用及其所有依赖(代码、运行时、系统工具、库等)打包成一个轻量级、可移植的“容器”,实现 “一次构建,随处运行”。 1、容器(Container…...

flink web ui未授权漏洞处理
本文通过nginx代理的方式来处理未授权漏洞问题。 1.安装nginx 通过yum install nginx 2.添加账号和密码 安装htpasswd工具,yum install httpd-tools sudo htpasswd -c /etc/nginx/conf.d/.passwd flink # 需安装httpd-tools:ml-citation{ref"1,4" dat…...

【vue-echarts】——03.配置项---tooltip
文章目录 一、tooltip提示框组件二、显示结果一、tooltip提示框组件 提示框组件,用于配置鼠标滑过或点击图表时的显示框 代码如下 Demo3View.vue <template><div class="about">...

【弹性计算】弹性裸金属服务器和神龙虚拟化(二):适用场景
《弹性裸金属服务器》系列,共包含以下文章: 弹性裸金属服务器和神龙虚拟化(一):功能特点弹性裸金属服务器和神龙虚拟化(二):适用场景弹性裸金属服务器和神龙虚拟化(三&a…...

提升系统效能:从流量控制到并发处理的全面解析
在当今快速发展的数字时代,无论是构建高效的网络服务、管理海量数据,还是优化系统的并发处理能力,都是技术开发者和架构师们面临的重大挑战。本文集旨在深入探讨几个关键技术领域,包括用于网络通信中的漏桶算法与令牌桶算法的原理…...

计算机毕业设计SpringBoot+Vue.js贸易行业CRM系统(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

从头开始学SpringBoot—02ssmp整合及案例
《从头开始学SpringBoot》系列——第二篇 内容包括: 1)SpringBoot实现ssmp整合 2)SpringBoot整合ssmp的案例 目录 1.整合SSMP 1.1整合JUnit 1.2整合Mybatis 1.2.1导入对应的starter 1.2.2配置相关信息 1.2.3dao(或是mapper&…...

0301 leetcode - 1502.判断是否能形成等差数列、 682.棒球比赛、657.机器人能否返回原点
1502.判断是否能形成等差数列 题目 给你一个数字数组 arr 。 如果一个数列中,任意相邻两项的差总等于同一个常数,那么这个数列就称为 等差数列 。 如果可以重新排列数组形成等差数列,请返回 true ;否则,返回 false…...
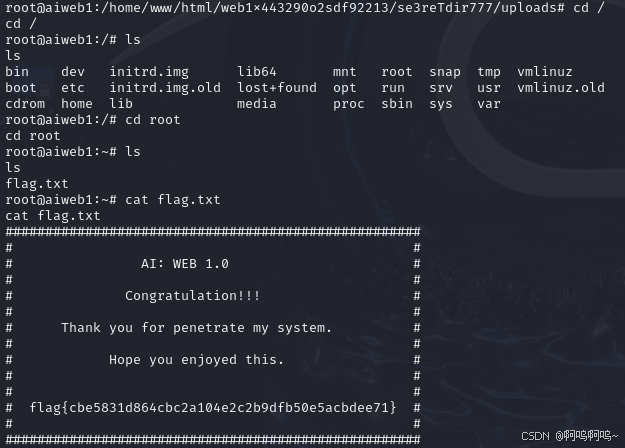
Vulnhub靶机——AI-WEB-1
目录 一、实验环境 1.1 攻击机Kali 1.2 靶机下载 二、站点信息收集 2.1 IP扫描 2.2 端口扫描 2.3 目录扫描 三、漏洞利用 3.1 SQL注入 3.2 文件上传 四、权限提升 4.1 nc反弹连接 4.2 切换用户 一、实验环境 1.1 攻击机Kali 在虚拟机中安装Kali系统并作为攻击机 1.2 靶机下载 (…...

无人系统:未来科技的智能化代表
无人系统(Unmanned Systems)是指在不依赖人类直接干预的情况下,通过自主或远程控制方式完成任务的系统。随着科技的不断进步,特别是在人工智能、机器人学、传感技术、通信技术等领域的突破,无人系统在各行各业中得到了…...

在Docker中部署DataKit最佳实践
本文主要介绍如何在 Docker 中安装 DataKit。 配置和启动 DataKit 容器 登陆观测云平台,点击「集成」 -「DataKit」 - 「Docker」,然后拷贝第二步的启动命令,启动参数按实际情况配置。 拷贝启动命令: sudo docker run \--hostn…...

进程的状态 ─── linux第11课
目录 编辑 补充知识: 1.并行和并发 分时操作系统(Time-Sharing Systems) 实时操作系统(Real-Time Systems) 进程的状态(操作系统层面) 编辑 运行状态 阻塞状态 状态总结: 挂起状态 linux下的进程状态 补充知识: …...

MySQL数据库基本概念
目录 什么是数据库 从软件角度出发 从网络角度出发 MySQL数据库的client端和sever端进程 mysql的client端进程连接sever端进程 mysql配置文件 MySql存储引擎 MySQL的sql语句的分类 数据库 库的操作 创建数据库 不同校验规则对查询的数据的影响 不区分大小写 区…...

什么是 jQuery
一、jQuery 基础入门 (一)什么是 jQuery jQuery 本质上是一个快速、小巧且功能丰富的 JavaScript 库。它将 JavaScript 中常用的功能代码进行了封装,为开发者提供了一套简洁、高效的 API,涵盖了 HTML 文档遍历与操作、事件处理、…...

Redis Desktop Manager(Redis可视化工具)安装及使用详细教程
一、安装包下载 直接从官网下载,官网下载链接地址:Downloads - Redis 二、安装步骤 2.1说明 Redis Desktop Manager是一款简单快速、跨平台的Redis桌面管理工具,也也被称作Redis可视化工具。 支持命令控制台操作,以及常用&…...

[KEIL]单片机技巧 01
1、查看外设寄存器的值 配合对应的芯片开发手册以查看寄存器及其每一位的意义,可以解决90%以上的单纯的片内外设bug,学会如何通过寄存器的值来排外设上的蛊是嵌入式开发从小白到入门的重要一步,一定要善于使用这个工具,而不是外设…...

云原生监控篇——全链路可观测性与AIOps实战
引言:监控即生命线 2023年某全球支付平台因一次未被捕获的数据库连接泄漏,导致每小时损失120万美元。而另一家社交巨头通过实时异常检测系统,在30秒内自动隔离了大规模DDoS攻击。这两个案例揭示了云原生时代的核心生存法则——监控不是可选项…...

基于Windows Defender遥测数据与机器学习预测恶意软件感染风险
1. 项目概述:当Windows Defender遇见机器学习在网络安全这个没有硝烟的战场上,恶意软件(Malware)始终是悬在个人用户和企业头顶的达摩克利斯之剑。从勒索软件加密关键文件,到间谍软件窃取商业机密,每一次成…...

Marginalia代码实现原理:深入理解SQL查询注释的内部工作机制
Marginalia代码实现原理:深入理解SQL查询注释的内部工作机制 【免费下载链接】marginalia Attach comments to ActiveRecords SQL queries 项目地址: https://gitcode.com/gh_mirrors/ma/marginalia Marginalia是一款为ActiveRecord查询添加注释的实用工具&a…...

FICO创凭证标准错误:在折旧范围 01 中的业务与帐面净值规则冲突
凭证过账总金额等于资产剩余总价值创凭证出现如下错误:一、首先确认是否是业务配置问题排查业务问题操作如下:T-CODE:SPRO --->财务会计--->资产会计核算--->组织结构--->复制参考折旧表选折对应折旧表如果不一致设置为一致即可解决问题&…...

AI工程师必备:高实效性AI资讯简报方法论
1. 项目概述:一份真正“够用”的AI资讯简报,到底长什么样? “ This AI newsletter is all you need #7 ”——光看标题,你可能以为这是某家科技媒体的常规栏目更新。但实际翻阅过前六期的老读者心里都清楚:它根本不…...

YOLOv11光伏板二极管异常目标检测数据集-45张-Solar-panel-anomalies-1
YOLOv11光伏板二极管异常目标检测数据集 📊 数据集基本信息 目标类别: [‘Diode anomaly’, ‘Hot Spots’, ‘Reverse polarity’]中文类别:[‘二极管异常’, ‘热点’, ‘反向极性’]训练集:31 张验证集:9 张测试集&…...

RAG架构全解析:从基础到高级,打造你的企业级知识库问答系统!
本文详细介绍了RAG(Retrieval-Augmented Generation)架构的多种变体,从基础的Naive RAG和Standard RAG开始,逐步深入到Advanced RAG、Hybrid Search RAG、Rerank型RAG、文档增强型RAG、Agentic RAG、Router RAG、GraphRAG、RAPTOR…...

AI Agent Harness Engineering 在餐饮行业的应用:智能点餐与库存管理
标题选项 《从排队到零浪费:AI Agent Harness Engineering 重构餐饮智能点餐与库存管理全链路》 《AI Agent 落地餐饮行业实战:基于Harness框架打造高可用智能点餐+库存联动系统》 《告别漏单、超卖、食材浪费:AI Agent Harness 工程化在餐饮场景的落地指南》 《垂直行业Age…...
)
基于java的畅阅读系统小程序设计与实现(源码+数据库+文档)
畅阅读系统小程 目录 基于java的畅阅读系统小程序设计与实现 一、前言 二、系统功能设计 三、系统实现 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师&a…...

2025-2026年护眼灯品牌推荐:十大评测专业排行防蓝光伤眼价格特点
摘要 当消费者对家庭光环境的认知从“照亮空间”跃迁至“健康护眼”,如何从纷繁复杂的市场中精准选择一盏真正经得起科学检验的护眼灯,已成为现代家庭决策者的核心焦虑。根据全球知名市场研究机构Grand View Research发布的报告,全球LED照明市…...
)
从零开始学AI Agent:软件工程视角下的企业数字化转型实践指南(收藏版)
本文从软件工程视角出发,探讨了AI Agent在企业数字化转型中的应用与构建。首先强调需求分析的重要性,指出应从业务问题出发判断Agent是否适用。接着,介绍了Agent的系统设计,包括任务编排、上下文管理、记忆存储和工具扩展四个核心…...