KTransformers部署 使671B DeepSeek R1成「办公桌标配」
671B DeepSeek R1成「办公桌标配」
- 1. 什么是KTransformers
- DeepSeek 版本
- 技术破局密钥:强稀疏化MoE模型需要全新的私有化架构设计
- 趋境AI大模型推理软硬一体工作站——让大模型推理门槛降低10倍
- 2. 准备环境
- 3 环境准备与资源下载
- 4 安装过程
- 1. linux环境搭建
- 2. windows环境搭建
- 5. 测试结果
2025年2月,当DeepSeek-R1以”开源即巅峰”的姿态引爆AI界时,某AI科技团队却陷入了两难:这款拥有类专家级推理能力的模型,既是AI应用效果困局的钥匙,也是吞噬企业算力预算的黑洞——云服务持续过载导致关键实验中断,而组建百万级私有云集群的方案,让这个几十人团队望而却步。
1. 什么是KTransformers
KTransformers作为一个开源框架,专门为优化大规模语言模型的推理过程而设计。它支持GPU/CPU异构计算,并针对MoE架构的稀疏性进行了特别优化,可以有效降低硬件要求,允许用户在有限的资源下运行像DeepSeek-R1这样庞大的模型。KTransformers实现了强大的CPU+DDR5+24GB显存环境下本地运行DeepSeek-R1满血版的能力,大大降低了部署成本和技术门槛。
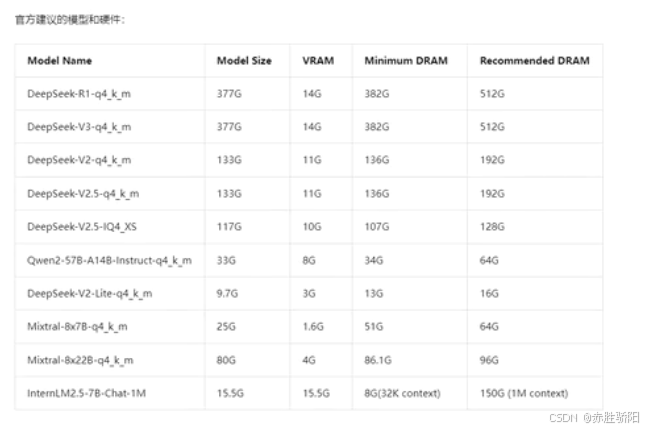
DeepSeek 版本
DeepSeek R1主要分为两大类别,共计8个版本,但性能与GPT-o1抗衡的版本只有671B满血版本。其他蒸馏版模型虽经过了调优,但性能仍与满血版有差距。然而,根据传统的私有化部署方案,运行671B参数的大模型需组建H100/H200 16卡服务器集群,启动成本动辄数百万,运维还需专业机房与高能耗散热系统。
图片
对预算有限的中小团队来说,这相当于吃掉创新团队全年研发预算的60%,试错成本过于高昂,无疑会对其正常的业务运营造成巨大的压力。
这种情况迫使中小企业要么放弃部署,要么选择性能降级的“阉割版”模型或者更小的模型,但智能断崖可能导致试点项目得出负面结论。根据IDC的调查,70%的CIO报告称他们的自建AI应用项目失败率达90%。企业最终陷入“部署不起”与“用不好”的双重困境。
更令人焦虑的是,延迟智能化升级可能导致企业在市场竞争中处于劣 势,错失潜在的经济和社会效益,错失政策支持与机遇。打破”顶尖本地化AI智力=天价门槛”的魔咒,让中小团队用有限预算获得智算中心级推理能力是大模型落地的关键。
技术破局密钥:强稀疏化MoE模型需要全新的私有化架构设计
破局的本质还是需要回到技术层面,不仅是DeepSeek系列的大模型,目前主流的大模型大多是MoE架构,这种架构的核心是将模型中的任务分配给不同的专家模块,每个专家模块专注于处理特定类型的任务,也就是说,虽然拥有千亿参数,但由于MoE架构的稀疏性,每次推理仅激活不到10%的神经元。
云上方案固然是一种解法:将专家模块分布式部署于大规模集群上,用海量并发摊薄成本。但中小团队及对安全性有高度要求的关键领域,需要全新的私有化架构设计来进行私有化部署。
基于此,趋境科技给出了全新的技术答案:利用MoE大模型架构的稀疏性,采用GPU/CPU异构协同和以存换算,小规模集群也可运行满血版DeepSeek R1,要成本也要更强智能。
具体到技术实现上,趋境科技通过算力划分和高性能算子,将来自存储、CPU、GPU、NPU的算力高效融合,充分释放全系统的存力和算力,以提升大模型推理性能;同时利用存储空间,为大模型加入处理缓存记忆的能力,面对全新的问题也可以从历史相关信息中提取可复用的部分内容,与现场信息进行在线融合计算,进而降低计算量。
值得一提的是,趋境科技联合清华 KVCache.AI 团队也刚刚更新了开源项目——异构推理框架KTtransformers,支持单GPU本地运行 DeepSeek-R1 671B满血版。更新发布后,引起全球开发者的强烈关注和复现热潮,在x、Reddit、B站等国内外社区均有开发者自发发布复现结果及教学视频,B站up主的教学视频发布当天播放量近20万,登顶全站热榜第一名。
趋境AI大模型推理软硬一体工作站——让大模型推理门槛降低10倍
在产品层面,趋境科技以四大革新重新定义企业级AI部署:
-
仅用传统部署方案成本的10%,获得顶尖大模型的能力。DeepSeek-R1/V3满血版的部署成本从数百万压缩至数十万级,且能够达到286 token/s的预填充和14 token/s的生成速度,比开源版本的llama.cpp最高快28倍。
-
异构算力释放极致性能,从“分钟级等待”瞬间迈入“秒级响应”,让中小团队以“轻量级”硬件获得“智算中心级”的推理能力。
-
国产芯片兼容生态闭环,深度整合英伟达、昇腾等多种芯片,实现从指令集到应用层的全栈优化。
2. 准备环境
硬件配置:
- CPU: 使用的是Intel Xeon Silver 4310 CPU @ 2.10GHz,拥有24个物理核心(每个插槽12个核心),支持超线程技术,总共有48个逻辑处理器。
- 内存: 系统配备了1T的DDR4内存,频率为3200MHz。
- GPU: NVIDIA GeForce RTX 3090,显存为24GB。
软件环境: - 操作系统版本:Ubuntu 22.04
- CUDA版本:12.1
- 软件框架: KTransformers v0.2.1,支持DeepSeek-R1模型的本地推理。
- 模型参数:DeepSeek-R1-Q4_K_M
3 环境准备与资源下载
KTransformers:
- ktransformers:https://github.com/kvcache-ai/ktransformers
ktransformers安装指南:https://kvcache-ai.github.io/ktransformers/en/install.html
模型文件:
- huggingface:https://huggingface.co/unsloth/DeepSeek-R1-GGUF
- modelscope(国内推荐):https://modelscope.cn/models/unsloth/DeepSeek-R1-GGUF
4 安装过程
1. linux环境搭建
- CUDA 12.1及以上版本
如果您还没有安装CUDA,可以从这里下载并安装。
添加CUDA到PATH环境变量:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_PATH=/usr/local/cuda
- Linux-x86_64 系统,带有 gcc, g++ 和 cmake
更新包列表并安装必要的工具:
sudo apt-get update
sudo apt-get install gcc g++ cmake ninja-build
- 使用 Conda 创建虚拟环境
我们建议使用Conda来创建一个Python=3.11的虚拟环境来运行程序:
conda create --name ktransformers python=3.11
conda activate ktransformers # 您可能需要先运行 `conda init` 并重新打开shell
确保安装了 PyTorch、packaging、ninja 等依赖项:
pip install torch packaging ninja cpufeature numpy
或者直接拉取已经构建好的docker镜像(推荐):docker pull approachingai/ktransformers:0.2.1
- 下载源代码并编译
初始化源代码:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
博主提供已经git submodule update后的文件下载的ktransformers包(更新时间:20250218):
链接: https://pan.baidu.com/s/1WvPK_lcLY9MdKxCWxoqonQ?pwd=mcbd 提取码: mcbd
安装(Linux):
bash install.sh
2 模型加载
下载Deepseek原模型配置文件
- modelscope:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1
- huggingface:https://huggingface.co/deepseek-ai/DeepSeek-R1
博主分享的配置文件:
链接: https://pan.baidu.com/s/1XKdP2L0QmX7YPGkqi7ujgg?pwd=6p7v 提取码: 6p7v
检查一下配置文件是否完整
本地聊天测试命令
本地聊天测试命令如下:
numactl -N 1 -m 1 python ./ktransformers/local_chat.py --model_path <your model path> --gguf_path <your gguf path> --cpu_infer 33 --max_new_tokens 1000
参数说明
- numactl -N 1 -m 1
使用numactl工具来绑定CPU核心和内存节点。这里的-N 1表示使用第1号CPU核心,-m 1表示使用第1号内存节点。这有助于提高多核系统的性能。
- python ./ktransformers/local_chat.py
运行KTransformers的本地聊天Python脚本。
- –model_path
指定模型路径。可以是本地路径或在线Hugging Face路径(如deepseek-ai/DeepSeek-V3)。如果在线连接有问题,可以尝试使用镜像站点(如hf-mirror.com)。
- –gguf_path
指定GGUF格式的模型路径。由于GGUF文件较大,建议您下载到本地并根据需要进行量化处理。注意这里是指向包含GGUF文件的目录路径。
- –cpu_infer 33
设置用于推理的CPU线程数。这里设置为33,可以根据您的硬件配置调整这个数值。
- –max_new_tokens 1000
设置最大输出token长度。默认值为1000,如果您发现生成的答案被截断了,可以增加这个数值以生成更长的回答。但请注意,增加这个数值可能会导致内存不足(OOM),并且会降低生成速度。
示例
(以博主目录结构假设)模型路径为/root/DeepSeek-R1-GGUF,GGUF路径为/root/DeepSeek-R1-GGUF/DeepSeek-R1-Q4_K_M,那么完整的命令应如下所示:
numactl -N 1 -m 1 python ./ktransformers/local_chat.py --model_path /root/DeepSeek-R1-GGUF --gguf_path /root/DeepSeek-R1-GGUF/DeepSeek-R1-Q4_K_M --cpu_infer 33 --max_new_tokens 1000
2. windows环境搭建
- CUDA 12.1及以上版本
检查安装版本

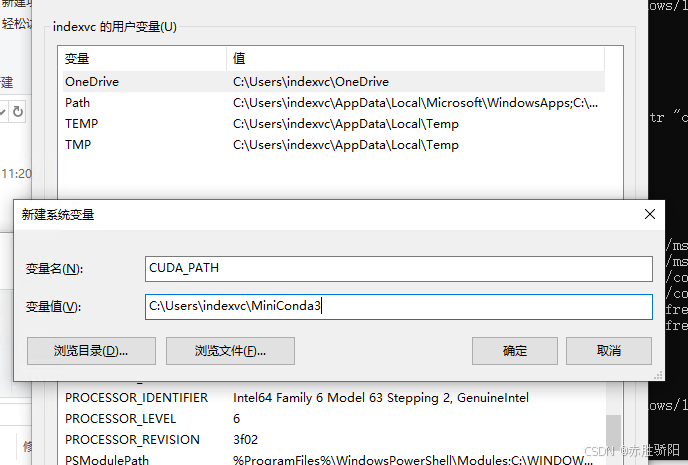
添加CUDA到PATH环境变量:
export PATH=C:\Users\indexvc\MiniConda3\condabin: P A T H e x p o r t L D L I B R A R Y P A T H = / u s r / l o c a l / c u d a / l i b 64 : PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64: PATHexportLDLIBRARYPATH=/usr/local/cuda/lib64:LD_LIBRARY_PATH
export CUDA_PATH=/usr/local/cuda
- 使用 Conda 创建虚拟环境
我们建议使用Conda来创建一个Python=3.11的虚拟环境来运行程序:
conda create --name ktransformers python=3.11
conda activate ktransformers # 您可能需要先运行 `conda init` 并重新打开shell
确保安装了 PyTorch、packaging、ninja 等依赖项:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip3 install packaging ninja cpufeature numpy遇到的错误
Collecting package metadata (current_repodata.json): done
Solving environment: unsuccessful initial attempt using frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): failedCondaError: KeyboardInterrupt
或者直接拉取已经构建好的docker镜像(推荐):docker pull approachingai/ktransformers:0.2.1
- 下载源代码并编译
初始化源代码:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
安装():
install.bat
可能会遇到的错误
ValueError: Unsupported backend: CUDA_HOME and MUSA_HOME are not set.[end of output]
问题分析:
CUDA 环境未配置:CUDA_HOME 是一个指向 CUDA 安装目录的环境变量,很多涉及 GPU 计算的 Python 包在构建或运行时需要该环境变量来找到 CUDA 库和工具。如果没有设置,包构建过程就会失败。
解决方案
安装并配置 CUDA
如果你需要使用 CUDA 进行 GPU 加速,需要先安装 CUDA Toolkit。
下载并安装 CUDA Toolkit:访问 NVIDIA 官方网站(https://developer.nvidia.com/cuda-downloads),根据你的操作系统和显卡型号选择合适的 CUDA Toolkit 版本进行下载和安装。
设置 CUDA_HOME 环境变量:
右键点击 “此电脑”,选择 “属性”。
点击 “高级系统设置”,在弹出的窗口中点击 “环境变量”。
在 “系统变量” 中点击 “新建”,变量名输入 CUDA_HOME,变量值输入 CUDA 的安装路径(例如 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8)。
找到 Path 变量,编辑它,添加 %CUDA_HOME%\bin 和 %CUDA_HOME%\libnvvp 到变量值中。
2 模型加载
下载Deepseek原模型配置文件
- modelscope:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1
- huggingface:https://huggingface.co/deepseek-ai/DeepSeek-R1
本地聊天测试命令
本地聊天测试命令如下:
numactl -N 1 -m 1 python ./ktransformers/local_chat.py --model_path <your model path> --gguf_path <your gguf path> --cpu_infer 33 --max_new_tokens 1000
部分加载日志
首次加载时间较长 加载完成,在浏览器中输入http://localhost:10005/web/index.html#/chat
步骤三:推理与测试
5. 测试结果
在复现KTransformers部署满血版DeepSeek-R1的过程中,我们遇到了一些性能上的差异。尽管已经按照官方指南进行了配置和优化,但最终的推理速度和效率并未达到预期水平。以下是具体的实践结果及分析。
测试结果
经过多次测试,我们得到了5.2 tokens/s的生成速度。
这些数据显示,在我们的实验环境中,模型的推理速度显著低于官方宣称14 tokens/s的生成速度。
分析原因
通过对比实验配置与官方推荐的最佳实践,我们发现以下几个关键因素可能导致了性能差异:
CPU性能:
我们的测试平台使用的是Intel Xeon Silver 4310 CPU,而官方文档中提到的理想配置包括第四代至强可扩展处理器,这类处理器集成了高级矩阵扩展指令集(AMX),能够大幅提升计算密集型任务的执行效率。相比之下,Silver系列的处理器在处理能力上存在差距,特别是在需要大量矩阵运算的任务中表现不佳。
内存类型:
在内存方面,我们使用的DDR4内存虽然提供了足够的带宽和容量,但是与最新的DDR5内存相比,在读写速度上有明显的劣势。根据相关测试,DDR5内存的读写速度比DDR4内存高出约2000MB/s,提升幅度在35%~41%之间。这种速度上的差异可能影响到数据加载和处理的速度,进而影响整体的推理效率。
GPU型号:
虽然NVIDIA GeForce RTX 3090是一款高性能显卡,但在处理极其庞大的模型时,其24GB的显存限制可能成为瓶颈。相比之下,RTX 4090采用了更先进的架构,能够在相同条件下提供更高的计算能力和更好的能效比。这可能是导致我们在实际测试中未能达到理想推理速率的一个重要原因。
结论与建议
综上所述,为了进一步提升DeepSeek-R1模型在本地部署时的推理性能,建议考虑升级硬件配置,特别是选择支持AMX指令集的CPU、采用DDR5内存以及选用更高性能的GPU。
相关文章:
KTransformers部署 使671B DeepSeek R1成「办公桌标配」
671B DeepSeek R1成「办公桌标配」 1. 什么是KTransformersDeepSeek 版本技术破局密钥:强稀疏化MoE模型需要全新的私有化架构设计趋境AI大模型推理软硬一体工作站——让大模型推理门槛降低10倍 2. 准备环境3 环境准备与资源下载4 安装过程1. linux环境搭建2. window…...

sql-labs less5-8
Less-5 双注入 基于单引号的字符型注入,涉及二次查询注入 Less-6 双注入 基于双引号的字符型注入,涉及二次查询注入 Less-7 字符型注入 基于单引号变形注入之导入文件 Less-8 布尔盲注 不返回任何错误信息,通过布尔逻辑判断 以下…...

一个大型应用的云原生一般有多少个服务?
DeepSeek R1 思考 1 秒 思考过程 在云原生架构中,大型应用的服务规模呈现动态分布特征。根据行业实践和架构模式分析,服务划分的核心考量维度包括: 一、业务领域驱动划分 核心业务服务群(通常15-30个) 用户中心&…...

Linux下安装VS Code
Centos 7 https://blog.csdn.net/weixin_63790642/article/details/132927888 安装存储库 sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc密钥 sudo sh -c echo -e "[code]\nnameVisual Studio Code\nbaseurlhttps://packages.microsoft.com/yum…...

【零基础到精通Java合集】第一集:Java开发环境搭建
以下是针对**“Java开发环境搭建”**的15分钟课程内容设计,包含知识点拆分、实操演示与互动练习: 课程标题:Java开发环境搭建(15分钟) 目标:完成JDK安装、IDE配置并运行第一个Java程序 一、课程内容与时间分配 0-2分钟 课程目标与前置准备 明确学习目标:JDK安装、环境…...
)
Rocky Linux 系统安装 typecho 个人博客系统(Docker 方式)
typecho 博客系统安装 官网: https://typecho.org/ 1. 安装 Docker curl https://download.docker.com/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker.repo && yum install docker-ce -y && docker -v && systemctl enable --now docker…...

C++-第二十一章:特殊类设计
目录 第一节:特殊类 1-1.不能被拷贝的类 1-2.只能在堆上构造的类 1-3.只能在栈上构造的类 1-4.只能构造一个对象的类 第二节:工厂模式 下期预告: 第一节:特殊类 1-1.不能被拷贝的类 不能被拷贝的类有线程类、std::unique_ptr、…...

pytorch 模型测试
在使用 PyTorch 进行模型测试时,一般包含加载测试数据、加载训练好的模型、进行推理以及评估模型性能等步骤。以下为你详细介绍每个步骤及对应的代码示例。 1. 导入必要的库 import torch import torch.nn as nn import torchvision import torchvision.transforms as trans…...

在kali linux中kafka的配置和使用
官方文档 一、安装依赖 删除原有的jdk sudo apt remove --purge openjdk-\* sudo apt clean安装 Java (JDK 11) sudo apt install openjdk-11-jdk -y # 验证安装 java -version二、下载并解压 Kafka 下载 Kafka wget https://dlcdn.apache.org/kafka/3.9.0/kafka_2.13-3.9.0.t…...

代码规范和简化标准
代码规范和简化标准是编写高质量、可维护、可扩展和可读代码的基本原则。遵循这些标准不仅能提高团队协作效率,还能减少出错的概率和后期维护的成本。以下是一些常见的代码规范和简化标准: 1. 命名规范 变量命名: 使用具有描述性的名称&…...

基于SpringBoot的校园二手交易平台(源码+论文+部署教程)
运行环境 校园二手交易平台运行环境如下: • 前端:Vue • 后端:Java • IDE工具:IntelliJ IDEA(可自行更换) • 技术栈:SpringBoot Vue MySQL 主要功能 校园二手交易平台主要包含前台和…...

【51单片机】快速入门
动手实践 > 理论空谈!从点亮LED开始,逐步扩展功能,2周可入门基础。 一、51单片机基础概念 什么是51单片机? 基于Intel 8051架构的8位微控制器,广泛用于嵌入式开发。 核心特性:4KB ROM、128B RAM、32个…...

YOLOv8+QT搭建目标检测项目
2024年7月YOLOv8QT初步搭建目标检测(避坑)_qt yolov8-CSDN博客YOLOv8QT初步搭建目标检测 2024年7月YOLOv8QT初步搭建目标检测(避坑)_qt yolov8-CSDN博客 yolov8的可视化界面(一、可视化界面设计)_yolo 可…...

刷题记录10
力扣72. 编辑距离 给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 解题思路: 本题与583. 两个字符串的删除操作其实是一样…...

数学软件Matlab下载|支持Win+Mac网盘资源分享
如大家所了解的,Matlab与Maple、Mathematica并称为三大数学软件。Matlab应用广泛,常被用于数据分析、无线通信、深度学习、图像处理与计算机视觉、信号处理、量化金融与风险管理、机器人,控制系统等领域。 Matlab将数值分析、矩阵计算、科学…...

5G学习笔记之BWP
我们只会经历一种人生,我们选择的人生。 参考:《5G NR标准》、《5G无线系统指南:如微见著,赋能数字化时代》 目录 1. 概述2. BWP频域位置3. 初始与专用BWP4. 默认BWP5. 切换BWP 1. 概述 在LTE的设计中,默认所有终端均能处理最大2…...

Spark 介绍
Spark 架构 Spark 是一个基于内存计算的大数据处理框架,相比 Hadoop 的 MapReduce,它能够提供 更高效的迭代计算 和 流式计算能力。Spark 采用 主从架构(Master-Slave),主要包括 Driver、Cluster Manager、Worker、Ex…...

mac Homebrew安装、更新失败
我这边使用brew安装git-lfs 一直报这个错: curl: (35) LibreSSL SSL_connect: SSL_ERROR_SYSCALL更新brew update也是报这个错误。最后使用使用大佬提供的脚本进行操作: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/mast…...

【实战 ES】实战 Elasticsearch:快速上手与深度实践-2.2.3案例:电商订单日志每秒10万条写入优化
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 Elasticsearch批量写入性能调优实战:2.2.3 案例:电商订单日志每秒10万条写入优化1. 原始架构与瓶颈分析1.1 初始集群配置1.2 性能瓶颈定位 2. 全链路…...

http的post请求不走http的整个缓存策略吗?
http的post请求不走http的整个缓存策略吗? DeepSeek R1 思考 33 秒 思考过程 嗯,用户问的是HTTP的POST请求是否不遵循整个缓存策略。我需要先回忆一下HTTP缓存的基本机制,然后考虑不同请求方法的缓存处理。 首先,HTTP缓存通常涉…...
基于 Transformer 架构的翻译模型实践 - 主流分词器(Tokenizer)的对比
基于 Transformer 架构的翻译模型实践 - 主流分词器(Tokenizer)的对比 flyfish 参考 https://github.com/shaoshengsong/ pytorch -transformer-en-zh-translation-demo对hello不同的分词方案可以分为单个字符【h,e,l,…...
)
5个真正赚钱的 AI 工作流 (2026)
AI驱动的创作者经济预计在2026年将达到57.1亿美元。但大多数使用AI工具的人仍然把它们当作搜索引擎——提问,获取答案,关闭标签页,明天重新开始。真正赚到钱的人发现了不同的东西:他们建立了能复合增长的工作流。代理每次运行都会…...

极化激元量子流体:从Bogoliubov色散到引力模拟的精密探测
1. 项目概述:当光“流动”起来我们通常认为光是一种波,或者是一束没有质量的粒子。但在特定的物理舞台上,光的行为可以变得非常“不寻常”——它能够像水一样流动,甚至像超流体那样无摩擦地运动。这就是“光的量子流体”这一前沿领…...

AR 巡检:6 大黄金行业与厂商推荐
AR 巡检是将增强现实技术与工业巡检流程深度融合的智能运维方案,核心作用是通过虚实叠加实现设备状态可视化、巡检流程标准化与故障诊断智能化。传统巡检依赖纸质记录、人工记忆和经验判断,存在漏检误检率高、数据无法实时同步、故障排查周期长等问题&am…...

后悔没早装!iPhone装上这8个APP,生产力瞬间拉满
有了iPhone之后,很多人都会遇到同一个问题——软件商店里应用浩如烟海,到底哪些才是真正值得装的?有的软件看起来花里胡哨,装上后却很少打开;有的工具看似简单,用惯了才发现离不开了。作为一个从“有了它只…...

STM32F103驱动TM1650数码管:从硬件连接到完整代码的保姆级避坑指南
STM32F103驱动TM1650数码管:从硬件连接到完整代码的保姆级避坑指南 第一次接触STM32F103和TM1650数码管模块时,我像大多数嵌入式新手一样,以为按照教程连接几根线、复制几段代码就能轻松点亮数码管。直到实际动手才发现,从硬件连接…...

google排名优化需要做什么? 用AI写文章拿排名的3个小技巧
2024年3月的算法大更清理了45%的低质量机翻网站。某外贸独立站在一星期内损失了每天8000个独立访客。搜索结果前三页充斥着字数1500字长篇大论。机器生成的文本带有高达85%的相似指纹。读者在页面上只停留了短短12秒。网站管理员发现跳出率飙升至92%。人工审查这些带有浓厚机器…...
链路原型)
从通信系统设计视角:如何用Xilinx DDS Compiler v6.0高效搭建数字上变频(DUC)链路原型
基于Xilinx DDS Compiler v6.0的数字上变频链路设计与优化实战 在软件无线电(SDR)和雷达信号处理系统中,数字上变频(DUC)是实现基带信号到中频转换的核心环节。作为DUC链路中的本振信号发生器,Xilinx LogiC…...

用AnyLogic 8.8.1复现地铁站客流仿真:从行人流线到安检流程的保姆级建模
用AnyLogic 8.8.1构建地铁站客流仿真:从零到一的实战指南 地铁站作为城市交通枢纽,其客流管理效率直接影响数百万人的出行体验。AnyLogic作为多方法仿真平台,能精准模拟行人流线与服务设施交互。本文将基于8.8.1版本,手把手构建包…...

Vidupe:3步快速清理重复视频的终极免费解决方案
Vidupe:3步快速清理重复视频的终极免费解决方案 【免费下载链接】vidupe Vidupe is a program that can find duplicate and similar video files. V1.211 released on 2019-09-18, Windows exe here: 项目地址: https://gitcode.com/gh_mirrors/vi/vidupe 您…...