VLM-E2E:通过多模态驾驶员注意融合增强端到端自动驾驶
25年2月来自香港科大广州分校、理想汽车和厦门大学的论文“VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion”。
人类驾驶员能够利用丰富的注意语义,熟练地应对复杂场景,但当前的自动驾驶系统难以复制这种能力,因为它们在将 2D 观测值转换为 3D 空间时经常会丢失关键的语义信息。从这个意义上说,这阻碍了它们在动态和复杂环境中的有效部署。利用视觉-语言模型 (VLM) 卓越的场景理解和推理能力,VLM-E2E,使用 VLM 通过提供注意线索来增强训练。该方法将文本表示集成到鸟瞰图 (BEV) 特征中以进行语义监督,这使模型能够学习更丰富的特征表示,明确捕捉驾驶员的注意语义。通过关注注意语义,VLM-E2E 更好地与类似人类的驾驶行为保持一致,这对于在动态和复杂的环境中导航至关重要。此外,引入一种 BEV-Text 可学习加权融合策略来解决融合多模态信息时模态重要性不平衡的问题。这种方法动态地平衡 BEV 和文本特征的贡献,确保有效利用视觉和文本模态的互补信息。通过明确解决多模态融合中的不平衡问题,该方法有助于更全面、更稳健地表示驾驶环境。
VLM-E2E 如图所示:

近年来,自动驾驶取得令人瞩目的进展[1]–[3],在感知[4]–[6]、运动预测[7]–[9]和规划[10],[11]等关键领域。这些发展为实现更准确、更安全的驾驶决策奠定坚实的基础。其中,端到端 (E2E) 自动驾驶已成为一种变革性范例,它利用大规模数据来展示规划能力。通过将原始传感器输入直接映射到驾驶动作,E2E 方法绕过手工制作中间模块的需求,从而实现更灵活、更可扩展的解决方案。然而,尽管取得这些进步,传统的端到端自动驾驶方法主要直接预测未来轨迹或控制信号,而没有明确考虑驾驶员对交通动态和导航提示等关键信息的注意。 E2E 系统在复杂和模糊场景中经常表现不佳,因为它们对高级语义和上下文线索(如交通规则、驾驶员注意力和动态交互)的推理能力有限。相比之下,人类驾驶员依靠注意决策过程,其中对周围交通环境和导航指导的注意都起着关键作用 [12]–[14]。例如,当接近十字路口时,人类驾驶员自然会优先考虑交通信号、行人运动和车道标记,并根据不断变化的场景动态调整他们的注意。
这一限制促使视觉-语言模型 (VLM) [15]–[18] 集成到自动驾驶框架中。VLM 在庞大的多模态数据集上进行训练,擅长需要高级语义推理的任务,例如解释复杂场景、预测动态交互和生成上下文描述。它们能够利用常识知识,因此特别适合解决自动驾驶中的挑战,例如理解交通规则、识别弱势道路使用者以及在模糊场景中做出安全决策。通过生成关键驾驶线索的文本描述,VLM 可以明确捕获与人类驾驶员注意相符的兴趣区域并确定其优先级。这种能力使决策更像人类,特别是在注意至关重要的安全关键场景中。
本文提出 VLM-E2E,框架如图所示。输入的场景信息包括多视角图像序列、GT、操控和用户提示。正面图像、操控和用户提示,被输入到基于 VLM 的文本标注生成(TAG)模块,以生成描述性文本标注,而多视角图像则由视觉编码层处理以产生 BEV 特征。然后,这些文本标注被传递到文本交互引导模块(TIGM),在那里使用预训练的 CLIP 模型将它们编码为文本特征。随后,将 BEV 和文本特征融合以支持下游任务,例如感知、预测和决策。

基于 VLM 的文本注释生成
- 文本注释:上图描述从视觉输入中提取驾驶员注意信息的流程,利用预训练 VLM 的推理能力。语义注释提取过程可以表述如下:
T = BLIP_2(P, I_front) (1)
此过程的目标是利用特定于任务的提示以及实时视觉输入从 BLIP-2 中提取可操作和注意信息。这种方法不仅强调了行人、交通信号和动态障碍物等关键元素,而且还过滤掉不相关的场景细节,确保输出直接支持驾驶决策。
工作中采用视觉语言模型 BLIP-2 [25],该模型能够对视觉上下文进行复杂的推理,以生成精确且与上下文相关的描述。该模型解释由提示引导的视觉场景并输出文本描述。该方法通过提供驾驶员注意注释来增强数据集的丰富性,从而提高下游驾驶模型的理解和决策能力。
在确定视觉输入时遇到挑战。也就是说,从可以覆盖自车 360 度的多个摄像头中选择正确的图像。考虑到要捕捉驾驶时的驾驶员注意语义,前视图图像通常包含大多数驾驶任务所需的最相关信息。全视图图像包含更多影响系统决策的干扰信息,因此选择仅使用前视图图像来提取注意信息。此外,考虑到自车及其周围环境处于动态运动中以及大型模型固有的幻觉问题,用 GT 和机动来细化动态目标的注释。
文本交互引导模块
驾驶员注意的文本描述,保留丰富的视觉语义线索。它与主要表示 3D 几何信息的 BEV 特征相辅相成。因此,BEV-Text 融合,从 BEV 角度全面理解场景。
- 文本编码器:给定一个文本输入 T,该文本输入提供语义特征来指导 BEV-Text 融合网络,实现指定的融合结果,文本交互指导架构中的文本编码器和嵌入,负责将此输入转换为文本嵌入。在各种 VLM 中,采用 CLIP [26],因为它具有轻量级架构和高效的文本特征提取功能。与其他 VLM 相比,CLIP 在计算上要求较低,并且生成的文本嵌入具有相对较小的特征维度 77,这显著提高后续 BEV-Text 特征融合的效率。从 CLIP 中冻结文本编码器以保持其一致性并利用其预训练知识。这个过程可以正式表示为:
f_t = CLIP_e(T) (2)
在不同但语义相似的文本中,提取的特征应该在简化的欧几里得空间中接近。进一步利用MLP F_m^i 挖掘这种连接,进一步映射文本语义信息与语义参数,得到:
γ_m = F_m1 (f_t), β_m = F_m^2 (f_t) (3)
2)BEV-Text Fusion:在语义交互引导模块中,语义参数通过特征调制与融合特征 s_t 进行交互,从而达到引导的效果。特征调制包括尺度缩放和偏差控制,分别从两个角度对特征进行调整。特别地,受[58]的启发,使用残差连接来降低网络拟合的难度。为简单起见,可以将其描述为:
x_t = (1 + γ_m) ⊙ s_t + β_m (4)
基于视觉的端到端模型
- 空间时间 BEV 感知:在该框架中,BEV 表示由多摄像头图像构建而成。时间 t 时输入的多摄像头图像 {I_t1, · · · , I_tn}, n = 6 首先通过共享主干网络 EfficientNet-b4 [59] 以提取高维特征图。对于时间 t 时的每个摄像头图像 k,得到其编码器特征 ek_t 和深度估计 d^k_t,C 表示特征通道数,D 表示离散深度值数,(H_e, W_e) 表示空间特征大小。隐深度估计用于推断每个像素的深度信息,从而可以构建 3D 特征体。由于深度值是估计的,因此取特征与深度估计的外积。
eˆ_tk =e_tk ⊗ d_t^k (5)
然后,为了将 2D 透视特征转换为 3D 空间,用特征提升模块。该模块使用相机内参和外参将 2D 特征投影到 3D 体素空间中。然后,通过沿垂直轴聚合特征以形成 BEV 视图特征 b_t,将 3D 特征体折叠为 2D BEV 表征,(H, W) 表示 BEV 特征的空间大小。这是通过基于注意聚合实现的,它保留最显着的特征,同时保持空间一致性。生成的 BEV 图提供场景的自上而下的视图,封装几何和语义信息。
除了上面描述的 BEV 构建流水线之外,还进一步结合时间建模来增强对场景的动态理解。具体来说,给定当前时间戳 t 及其 h 个历史 BEV 特征 {b_t−h, · · · , b_t−1, b_t},首先使用时间对齐模块将历史特征与当前帧的坐标系对齐。此过程利用相邻帧之间的相对变换和旋转矩阵 M_t−i→t。然后将过去的 BEV 特征 b_t−i 进行空间变换为:
ˆb_t−i = W(b_t−i, M_t−i→t), i = 1,2 (6)
随后,将 h 个帧中对齐的 BEV 特征连接起来以形成时空输入 ˆb = [ˆb_t−h,···,ˆb_t−1,ˆb_t]。为了捕获动态场景中的长期依赖关系,使用时空变换模块 F_s。
s_t = F_s(ˆb_t−h,··· ,ˆb_t−1,ˆb_t) (7)
F_s 是一个具有跨帧自注意的时空卷积单元。时空 BEV 表征明确地模拟场景的静态和动态演变,使 BEV 表示能够同时编码几何结构和时间连续性。
- 语义占用预测:未来预测模型是一个卷积门控循环单元网络,以当前状态 s_t 和训练期间从未来分布中采样的潜变量 η_t 作为输入,或以当前分布 P 作为推理。它递归地预测未来状态 (y_t+1 , · · · , y_t+l),其中 l 表示预测范围。
为了对多模态未来轨迹中固有的不确定性进行建模,采用受 [60] 启发的条件变分框架。当前分布 P(z|x_t) 仅以当前状态 x_t 为条件。未来分布 P_f (z|x_t, y_t+1:t+l) 会通过真实未来观测 (y_t+1 , · · · , y_t+l ) 进行增强。该分布被参数化为对角高斯分布,具有可学习的均值 μ 和方差 σ^2,M 是潜维度。
P(z|x_t) = N(μ_pres, σ_press^2), (8)
P_f(z|x_t, y_t+1:t+l) = N(μ_fut, σ_fut^2) (9)
在训练阶段,为了确保预测与观察的未来一致,同时保留多模态多样性,从 P_f (z|x_t, y_t+1:t+l) 中抽取 η_t,然后优化模式-覆盖的 KL 散度损失。
L_KL = D_KL(Pf (z|x_t, y_t+1:t+F )||P (z|x_t)) (10)
这鼓励 P(z|x_t) 包含 P_f 中编码的所有可能未来。在推理阶段,未来轨迹是通过从当前分布 η_t ∼ P(z|x_t) 中采样生成的,其中每个样本 η_t 代表一个不同的未来假设。
这种概率公式使模型能够生成多样化但物理上合理的未来,同时保持时间一致性,这对于处理无保护左转或行人交互等模糊场景至关重要。
融合特征 x_t 由多任务解码器 D_p 处理,以生成实例-觉察的分割掩码和运动预测。解码器输出四个关键预测:语义分割、实例中心性、实例偏移和未来实例流,它们共同实现强大的实例检测、分割和跟踪。语义分割头,通过卷积分类器预测逐像素语义类别。这提供对场景布局和目标类别的深入理解。对于实例分割,采用混合中心偏移公式 [61]。实例中心头,输出热图 H_t,指示实例中心的可能性。在训练期间,应用高斯核来抑制模糊区域并专注于高置信度中心。实例偏移头,预测矢量场 O_t,其中每个矢量指向其对应的实例中心。在推理时,通过对 H_t 进行非最大抑制(NMS)提取实例中心。未来实例流头,预测位移矢量场 F_t,其编码动态智体在未来范围 l 的运动。该流场用于跨时间步传播实例中心,确保时间一致性。具体而言,检测的实例中心 {ct_i} 通过 cˆ_it+1 = c_it + F_t(c_it) 流扭曲(warped)到 t + 1。然后使用匈牙利算法 [62] 将扭曲的中心 {cˆ_it+1} 与 t+1 时检测的中心 c_j^t+1 进行匹配,该算法基于成对 IoU 求解最优分配。这种基于流的匹配,即使在遮挡或突然的运动变化下也能实现稳健的跨帧关联。
注意力引导的未来规划
所提出的运动规划器主要目标是生成确保安全、舒适和高效实现目标的轨迹。为了实现这一目标,使用一个运动规划器,它可以生成一组运动学上可行的轨迹,每个轨迹都使用学习的评分函数进行评估,灵感来自 [43]、[63]–[65]。
评分函数包含一个概率动态占用场,这对于编码潜动作的安全性至关重要。该领域通过惩罚进入已占用区域或过于靠近这些区域的轨迹来鼓励谨慎的驾驶行为,从而与周围的障碍物保持安全距离。此外,利用在线地图中的概率层来得到评分函数。这些层提供重要信息,确保自动驾驶汽车 (SDV) 保持在可驾驶区域内、靠近车道中心并朝正确的方向行驶。特别是在不确定的地区,当占用率和道路结构不太可预测时,规划器会格外小心谨慎驾驶。此外,规划器确保车辆朝着输入高级命令指定的目标前进,无论是继续前进、转弯还是导航其他操作。
规划器并行评估所有采样的轨迹。每条轨迹 τ 都基于评分函数 f 进行评估,该函数考虑多个输入因素,包括地图 M、占用率 O 和运动 V。轨迹选择过程公式如下:
τ^∗ = argminf_τ(τ, M, O, V, w) (11)
评分函数根据多个标准评估每条轨迹,例如避开障碍物的安全性、保持平稳运动等乘坐舒适度以及在高级命令的指导下朝着目标前进。通过结合这些因素,运动规划器可以有效地选择最能满足所有安全性、舒适性和进度标准的轨迹,确保 SDV 以有效和谨慎的方式在复杂环境中行驶。
运动规划器的输出是车辆状态序列,它定义 SDV 在规划范围内的期望运动。在规划过程的每次迭代中,都会生成一组候选轨迹并使用 (11) 中描述的成本函数进行评估。运动规划器的输出是车辆状态序列,它定义 SDV 在规划范围内的期望运动。然后选择成本最低的轨迹进行执行。
为了确保实时性能,采样轨迹集必须保持足够小。但是,该集合还必须代表各种可能的操纵和动作,以避免侵入障碍物。为了达到这种平衡,采用一种了解车道结构的采样策略,确保采样轨迹有效捕捉各种驾驶行为,同时保持计算可行性。
特别是,遵循 [66]、[67] 中提出的轨迹采样方法,其中轨迹是通过将纵向运动与相对于特定车道(例如当前 SDV 车道或相邻车道)的横向偏差相结合来生成的。这种方法允许规划器采样遵循基于车道驾驶原则的轨迹,同时结合横向运动的变化。这些变化使运动规划器能够处理各种各样的交通场景。
为了确保规划的轨迹符合驾驶员对交通规则和路线的注意,使用动态整合交通规则的时间细化模块。利用编码器的前视摄像头特征 e_front,初始化基于 GRU 的细化网络以迭代调整最初选择的轨迹。前视特征,明确编码交通规则语义,使模型能够在红灯处停止或通过绿灯。循环架构,确保轨迹点之间的平稳过渡,从而减轻突然的转向或加速变化。
在 nuScenes 数据集 [68] 上评估方法,这是一个大规模自动驾驶基准,包含 1,000 个不同的驾驶场景,每个场景持续 20 秒,注释频率为 2Hz。该数据集具有一个 360° 多摄像头装置,由六个同步摄像头(前、前左、前右、后、后左、后右)组成,视野重叠最小。为每一帧提供精确的摄像头内外参,以确保准确的空间对齐。
BEV 占用标签 {y_t+1 , · · · , y_t+l } 是通过将动态智体的 3D 边框投影到 BEV 平面上生成的,从而创建时空占用网格。所有标签都使用 GT 未来自我运动转换为自我车辆的参考系,确保跨帧的时间一致性。
模型利用过去 1.0 秒的时间背景信息来预测 2.0 秒范围内的未来轨迹。在 nuScenes 数据集中,这对应于过去背景的 3 帧和未来的 4 帧,以 2 Hz 的频率运行。
在每个过去的时间步长中,该模型处理 6 张摄像机图像,每张图像的分辨率为 224 × 480 像素。BEV 空间面积为 100m×100m,x 和 y 方向的像素分辨率均为 50cm。这会产生一个空间尺寸为 200 × 200 像素的 BEV 视频。
使用 Adam 优化器进行训练,恒定学习率为 2.0 × 10−3 。该模型训练 20 个epochs,批次大小为 6,分布在 4 个 Tesla A6000 GPU 上。为了优化内存使用并加速计算,采用混合精度训练。此外,模型和 ST-P3 都是在没有深度图指导的情况下进行训练的,以确保公平的比较,并强调方法在利用语义和注意线索来提高性能方面的有效性。
相关文章:
VLM-E2E:通过多模态驾驶员注意融合增强端到端自动驾驶
25年2月来自香港科大广州分校、理想汽车和厦门大学的论文“VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion”。 人类驾驶员能够利用丰富的注意语义,熟练地应对复杂场景,但当前的自动驾驶系统难以复制这种能…...

如何将飞书多维表格与DeepSeek R1结合使用:效率提升的完美搭档
将飞书的多维表格与DeepSeek R1结合使用,就像为你的数据管理和分析之旅装上一台涡轮增压器。两者的合作,不仅仅在速度上让人耳目一新,更是将智能化分析带入了日常的工作场景。以下是它们如何相辅相成并改变我们工作方式的一些分享。 --- 在…...

Kali CentOs 7代理
工具v2↓ kali_IP段v2端口例子<1> kali_IP段v2端口例子<2> CentOs 7 //编辑配置文件 vi /etc/profile//在该配置文件的最后添加代理配置 export http_proxyhttp://ip:port //代理服务器ip地址和端口号 export https_proxyhttp://ip:port //代理服务器ip地址和…...

Zookeeper 的核心引擎:深入解析 ZAB 协议
#作者:张桐瑞 文章目录 前言ZAB 协议算法崩溃恢复选票结构选票筛选消息广播 前言 ZooKeeper 最核心的作用就是保证分布式系统的数据一致性,而无论是处理来自客户端的会话请求时,还是集群 Leader 节点发生重新选举时,都会产生数据…...

L3-001 凑零钱
L3-001 凑零钱 - 团体程序设计天梯赛-练习集 n, m map(int, input().split()) a list(map(int, input().split())) a.sort() f [[] for _ in range(m 1)] f[0] [0] for i in a:for j in range(m, i - 1, -1):if f[j - i]:if not f[j] or f[j] > f[j - i] [i]:f[j] f…...
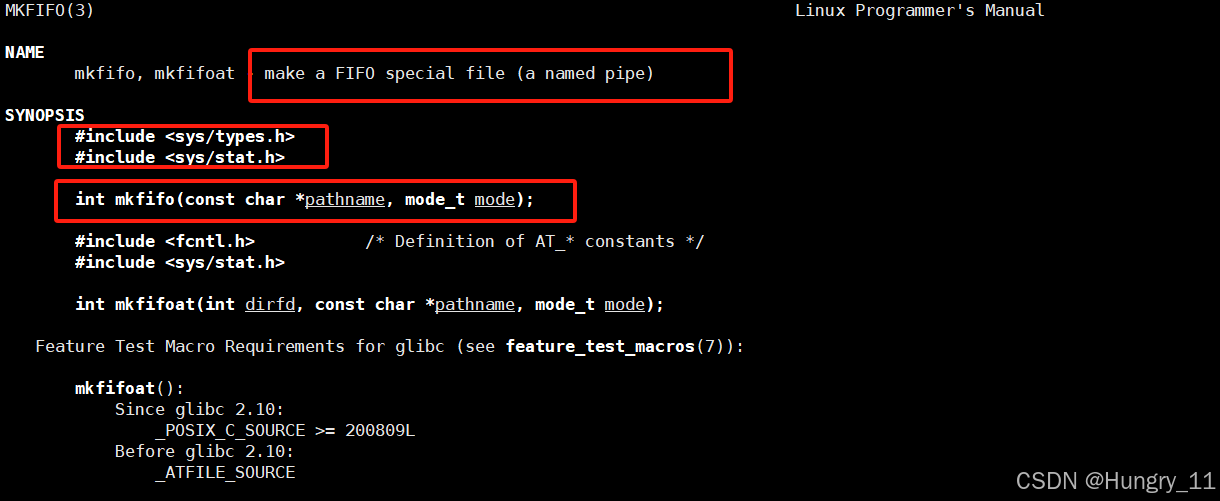
命名管道(用命名管道模拟server和client之间的通信)
目录 命名管道创建命名管道使用命令行创建命名管道(FIFO)在程序中创建 命名管道的打开规则用命名管道实现server和client通信 命名管道 bash进程并不会给我们写的两个不同的程序创建通信的管道,即使这两个进程看起来好像都是bash的子进程&am…...
)
【AI深度学习基础】Pandas完全指南入门篇:数据处理的瑞士军刀 (含完整代码)
📚 Pandas 系列文章导航 入门篇 🌱进阶篇 🚀终极篇 🌌 📌 一、引言 在大数据与 AI 驱动的时代,数据预处理和分析是深度学习与机器学习的基石。Pandas 作为 Python 生态中最强大的数据处理库,以…...

关于opencv中solvepnp中UPNP与DLS与EPNP的参数
The methods SOLVEPNP_DLS and SOLVEPNP_UPNP cannot be used as the current implementations are unstable and sometimes give completely wrong results. If you pass one of these two flags, SOLVEPNP_EPNP method will be used instead.、 由于当前的实现不稳定&#x…...

金融项目实战
测试流程 测试流程 功能测试流程 功能测试流程 需求评审制定测试计划编写测试用例和评审用例执行缺陷管理测试报告 接口测试流程 接口测试流程 需求评审制定测试计划分析api文档编写测试用例搭建测试环境编写脚本执行脚本缺陷管理测试报告 测试步骤 测试步骤 需求评审 需求评…...

大模型小白入门
【课前篇】大模型从0到1指南 【基础篇】大模型的演变与概念 大模型的演变 人工智能:人工智能是一个广泛涉及计算机科学、数据分析、统计学、机器工程、语言学、神 经科学、哲学和心理学等多个学科的领域。 机器学习:机器学习可以分为监督学习&…...

从零到一:快速上手 Poetry——Python 项目管理的利器
在 Python 项目开发中,包管理、依赖管理和虚拟环境的创建一直是开发者们经常面对的难题。传统上,开发者通常会使用 pip、virtualenv 或者 conda 来处理这些问题。然而,随着 Python 项目复杂度的增加,传统工具往往显得力不从心&…...

【量化科普】Beta,贝塔系数
【量化科普】Beta,贝塔系数 🚀量化软件开通 🚀量化实战教程 在量化投资领域,Beta(贝塔系数)是一个衡量投资组合或股票相对于整个市场波动性的指标。它反映了资产收益与市场收益之间的相关性,…...

C++----异常
一、C 语言传统的错误处理方式 在 C 语言中,处理错误主要有两种传统方式,每种方式都有其特点和局限性。 1. 终止程序 原理:使用类似assert这样的断言机制,当程序运行到某个条件不满足时,直接终止程序的执行。示例代…...

合理规划时间,从容应对水利水电安全员考试
合理规划时间,从容应对水利水电安全员考试 在忙碌的工作与生活节奏中备考水利水电安全员考试,合理规划时间是实现高效备考的核心。科学的时间管理能让你充分利用每一分每一秒,稳步迈向考试成功。 制定详细的学习计划是第一步。依据考试时间…...
 Windows 11使用SetSuspendState睡眠命令但是进入的是休眠)
(解决) Windows 11使用SetSuspendState睡眠命令但是进入的是休眠
Windows 11 24H2 goes into hibernation mode instead of sleep mode. How can I create a sleep mode shortcut file? 25年3月4号 Win11 23H2 起因 使用网上说的睡眠命令创建bat双击后,电脑风扇会运行一段时间后再停止(应该是在保存进程到硬盘&#…...

Spring Boot 接口 JSON 序列化优化:忽略 Null 值的九种解决方案详解
一、针对特定接口null的处理: 方法一:使用 JsonInclude 注解 1.1 类级别:在接口返回的 DTO 类或字段 上添加 JsonInclude 注解,强制忽略 null 值: 类级别:所有字段为 null 时不返回 JsonInclude(Js…...

计算机毕业设计Python+DeepSeek-R1大模型考研院校推荐系统 考研分数线预测 考研推荐系统 考研(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

一、Prometheus架构
Prometheus 云原生十二要素是一套最佳实践和规范,旨在帮助开发人员更好地构建云原生应用 这十二个要素分别是: 单一职责独立部署无状态声明式API服务发现容错处理自适应算法自动化运维响应式编程通信协议服务注册与发现数据持久化一、Prometheus 是什么 Prometheus 是一个…...

火山引擎 DeepSeek R1 API 使用小白教程
一、火山引擎 DeepSeek R1 API 申请 首先需要三个要素: 1)API Key 2)API 地址 3)模型ID 1、首先打开火山引擎的 DeepSeek R1 模型页面 地址:账号登录-火山引擎 2、在页面右下角,找到【推理】按钮&#…...

react+vite+pnpm+ts基础项目搭建
1. 项目初始化 pnpm create vitelatest my-react-app --template react-ts cd my-react-app pnpm install2. 核心依赖安装 # 基础依赖 pnpm add react-router-dom tanstack/react-query zustand axios# UI 组件库 (任选其一) pnpm add mui/material emotion/react emotion/st…...

RISC-V开放架构如何重塑垂直半导体商业模式
1. 从边缘到中心:RISC-V的崛起与半导体模式的裂变最近和几位在芯片设计公司工作的老朋友聊天,话题总绕不开RISC-V。十年前,当我们还在讨论ARM和x86谁主沉浮时,RISC-V还只是学术界论文里的一个概念。如今,它已经成了行业…...

手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线
手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线 在电磁仿真领域,材料参数的精确建模往往是决定仿真结果可靠性的关键因素。当我们需要模拟特殊频段的吸波材料、频率色散介质或各向异性材料时,仅依赖CST内置材料库…...

WSL2下CUDA版本切换实战:从CUDA 12.0降级到11.1,成功安装diff-gaussian-rasterization
WSL2环境下CUDA版本切换与diff-gaussian-rasterization安装全指南 在AI和图形学项目的复现过程中,CUDA版本与依赖库的兼容性问题常常成为开发者的"拦路虎"。最近在复现一篇论文时,我遇到了diff-gaussian-rasterization库因CUDA版本不匹配而无…...
)
DeepSeek SSO权限同步失效深度复盘(附完整日志追踪链路图)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek SSO权限同步失效深度复盘(附完整日志追踪链路图) 问题现象与影响范围 2024年10月17日 02:48 UTC,DeepSeek内部SSO系统(基于Keycloak 22.0.5&am…...

Rocky Linux 9.0上5分钟搞定NFS共享:从安装到挂载的保姆级避坑指南
Rocky Linux 9.0极速部署NFS共享:零基础到精通的实战手册 当你在凌晨两点接到紧急任务,需要在Rocky Linux 9.0上为开发团队搭建临时文件共享环境时,传统教程里冗长的配置步骤和晦涩的错误排查足以让人崩溃。本文专为解决这类"救火场景&q…...

TEngine与服务器集成:.NET Core 8.0前后端一体化开发指南
TEngine与服务器集成:.NET Core 8.0前后端一体化开发指南 【免费下载链接】TEngine Unity 商用级别开发框架,原生内置 AI 工作流支持,集成 HybridCLR 高性能热更、Obfuz 代码混淆加固、YooAssets 企业级资源管理方案,构建高效、安…...

别再截图了!用AD21把PCB 3D模型直接塞进PDF,客户评审一目了然
用AD21将PCB 3D模型嵌入PDF:提升设计评审效率的终极方案 在硬件开发流程中,设计评审环节往往成为项目推进的瓶颈。传统方式下,工程师不得不反复截取多角度2D图纸,或录制繁琐的演示视频,既耗费时间又难以全面展示设计细…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...

用Python实现迷宫寻路:从BFS到‘灌水算法’的保姆级代码解析
Python迷宫寻路算法实战:从BFS到动态赋值的完整实现指南 迷宫寻路问题是计算机科学中经典的算法应用场景,也是游戏开发、机器人导航等领域的核心技术之一。本文将带领你从最基础的广度优先搜索(BFS)算法开始,逐步深入到…...

四旋翼无人机深度强化学习控制框架与实战优化
1. 四旋翼无人机端到端深度强化学习框架解析四旋翼无人机的自主飞行控制一直是机器人学领域的核心挑战。传统PID控制虽然稳定可靠,但在复杂动态环境中表现受限。深度强化学习(DRL)通过模拟环境交互实现智能决策,为无人机控制带来了…...