SparkStreaming之04:调优
SparkStreaming调优
一 、要点
4.1 SparkStreaming运行原理

深入理解

4.2 调优策略
4.2.1 调整BlockReceiver的数量

案例演示:
object MultiReceiverNetworkWordCount {def main(args: Array[String]) {val sparkConf = new SparkConf().setAppName("NetworkWordCount")val sc = new SparkContext(sparkConf)// Create the context with a 1 second batch sizeval ssc = new StreamingContext(sc, Seconds(5))//创建多个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理val lines1 = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER)val lines2 = ssc.socketTextStream("master", 9997, StorageLevel.MEMORY_AND_DISK_SER)val lines = lines1.union(lines2)lines.repartition(100)//处理的逻辑,就是简单的进行word countval words = lines.repartition(100).flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))//将结果输出到控制台wordCounts.print()//启动Streaming处理流ssc.start()//等待Streaming程序终止ssc.awaitTermination()ssc.stop(false)}
}
⭐️4.2.2 调整Block的数量
batchInterval : 触发批处理的时间间隔
blockInterval :将接收到的数据生成Block的时间间隔,spark.streaming.blockInterval(默认是200ms),那么,BlockRDD的分区数 = batchInterval / blockInterval,即一个Block就是RDD的一个分区,就是一个task
比如,batchInterval是2秒,而blockInterval是200ms,那么task数为10,如果task的数量太少,比一个executor的core数还少的话,那么可以减少blockInterval,blockInterval最好不要小于50ms,太小的话导致task数太多,那么launch task的时间久多了
4.2.3 调整Receiver的接受速率
pps:permits per second 每秒允许接受的数据量(QPS -> queries per second)
Spark Streaming默认的PPS是没有限制的,可以通过参数spark.streaming.receiver.maxRate来控制,默认是Long.Maxvalue
⭐️4.2.3 调整数据处理的并行度
BlockRDD的分区数
a. 通过Receiver接受数据的特点决定
b. 也可以自己通过repartition设置
ShuffleRDD的分区数
a. 默认的分区数为spark.default.parallelism(core的大小)
b. 通过我们自己设置决定
val wordCounts = words.map(x => (x, 1)).reduceByKey((a: Int, b: Int) => a + b, new HashPartitioner(10))
4.2.4 数据的序列化
SparkStreaming两种需要序列化的数据:
a. 输入的数据:默认是以StorageLevel.MEMORY_AND_DISK_SER_2的形式存储在executor上的内存中
b. 缓存的数据:默认是以StorageLevel.MEMORY_ONLY_SER的形式存储的内存中
使用Kryo序列化机制,比Java序列化机制性能好
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
4.2.5 内存调优
(1)需要内存大小
和transformation的类型有关,如果使用的是updateStateByKey,Window这样的算子,那么内存就要设置得偏大
(2)数据存储级别
如果把接收到的数据设置的存储级别是MEMORY_DISK这种级别,也就是说如果内存不够可以把数据存储到磁盘上,其实性能还是不好的,性能最好的就是所有的数据都在内存里面,所以如果在资源允许的情况下,把内存调大一点,让所有的数据都存在内存里面。
4.2.6 Outout性能
(1)MySQL,HBase



(2)Kafka(0.8版本)
虽然现在的Kafka的版本已经到2.x版本了,但是很多公司因为历史遗留的原因,公司里面还是会有0.8x的Kafka。比如本人公司里面有两个Kafka集群,一个是0.8x的kafka,一个是1.x的Kafka。开发的时候有时候需要我们使用SparkStreaming做实时的ETL,然后再把数据打回Kafka,0.8版本的kafka默认是没有批量提交的功能的。本人公司里面一个真实的案例,一位同学写的SparkStreaming程序将数据处理完了以后通过ForeachRDD把数据写回到0.8Kafka。但是数据处理得很慢,经常会收到延时告警。最终发现他把数据写到Kafka的时候是一条数据一条数据提交的性能很差。最终手动实现了批量提交的功能。从此再也没有收到过告警。
4.2.7 Backpressure(压力反馈)


Feedback Loop : 动态使得Streaming app从unstable状态回到stable状态

从Spark1.5版本开始:spark.streaming.backpressure.enabled = true
4.2.8 Elastic Scaling(资源动态分配)
动态分配资源:
批处理动态的决定这个application中需要多少个Executors:
- 当一个Executor空闲的时候,将这个Executor杀掉
- 当task太多的时候,动态的启动Executors
Streaming分配Executor的原则是比对 process time / batchInterval 的比率

如果延迟了,那么就自动增加资源


从Spark2.0有这个功能:: spark.streaming.dynamicAllocation.enabled = true
⭐️4.2.8 数据倾斜调优(重要)
因为SparkStreaming的底层就是RDD,之前SparkCore的所有的数据倾斜的调优策略(见Spark之数据倾斜调优)都适合于SparkStreaming,需要灵活掌握,在实际开发的工作当中用得频率较高。
二 、总结
面试问题:你在工作当中有SparkStreaming调优过项目吗?怎么调优的?效果怎么样?
- 比如举foreachRDD的例子
- 比如举个数据倾斜的例子
- 用Xmind整理调优的策略
相关文章:
SparkStreaming之04:调优
SparkStreaming调优 一 、要点 4.1 SparkStreaming运行原理 深入理解 4.2 调优策略 4.2.1 调整BlockReceiver的数量 案例演示: object MultiReceiverNetworkWordCount {def main(args: Array[String]) {val sparkConf new SparkConf().setAppName("Networ…...

勿以危小而为之勿以避率而不为
《故事汇之:所见/所闻/所历/所想》:《公园散步与小雨遇记》(二) 就差一点到山顶了,路上碰到一阿姨,她说等会儿要下大雨了,让我不要往上走了,我犹豫了一会儿,还是听劝地返…...

JavaWeb后端基础(4)
这一篇就开始是做一个项目了,在项目里学习,我主要记录在学习过程中遇到的问题,以及一些知识点 Restful风格 一种软件架构风格 在REST风格的URL中,通过四种请求方式,来操作数据的增删改查。 GET : 查询 …...

SpringBoot调用DeepSeek
引入依赖 <dependency><groupId>io.github.pig-mesh.ai</groupId><artifactId>deepseek-spring-boot-starter</artifactId><version>1.4.5</version> </dependency>配置 deepseek:api-key: sk-******base-url: https://api.…...
记录一下本地部署Dify的坑
1. 截止2025-3-4为止,请注意,不要直接拉Dify的1.0.0版本。请先试用0.15.3版本。1.0.0有一个bug需要解决。[PANIC]failed to init dify plugin db: failed to connect to hostdb userpostgres databasepostgres Issue #14707 langgenius/dify GitHub …...

LC109. 有序链表转换平衡二叉搜索树
LC109. 有序链表转换平衡二叉搜索树 题目要求(一)快慢指针1. 理解问题2. 解决思路3. 具体步骤4. 代码实现5. 复杂度分析6. 示例解释7. 总结 LC109. 有序链表转换平衡二叉搜索树 题目要求 (一)快慢指针 要将一个按升序排列的单链表转换为平衡的二叉搜索树(BST&…...

Hutool一个类型转换工具类 `Convert`,
Hutool 是一个非常实用的Java工具库,旨在简化Java开发中的常见任务。它包含了一个类型转换工具类 Convert,可以帮助开发者轻松地进行各种类型之间的转换。以下是一些使用 Convert 类进行类型转换的例子: 基本类型转换 假设你需要将一个字符…...

基于eRDMA实测DeepSeek开源的3FS
DeepSeek昨天开源了3FS分布式文件系统, 通过180个存储节点提供了 6.6TiB/s的存储性能, 全面支持大模型的训练和推理的KVCache转存以及向量数据库等能力, 每个客户端节点支持40GB/s峰值吞吐用于KVCache查找. 发布后, 我们在阿里云ECS上进行了快速的复现, 并进行了性能测试, ECS…...

【Linux篇】第一个系统程序 - 进度条
文章目录 1.回车与换行2.行缓冲区3.倒计时程序4.进度条 1.回车与换行 回车的概念: 回到当前行的最开始 \r换行的概念: 换到当前行的下一行\n 2.行缓冲区 当我们运行下面这段程序时,我们会发现屏幕上首先会打印出hello world!,再过两秒后程序结束。 当我们把\n去掉…...

VLM-E2E:通过多模态驾驶员注意融合增强端到端自动驾驶
25年2月来自香港科大广州分校、理想汽车和厦门大学的论文“VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion”。 人类驾驶员能够利用丰富的注意语义,熟练地应对复杂场景,但当前的自动驾驶系统难以复制这种能…...

如何将飞书多维表格与DeepSeek R1结合使用:效率提升的完美搭档
将飞书的多维表格与DeepSeek R1结合使用,就像为你的数据管理和分析之旅装上一台涡轮增压器。两者的合作,不仅仅在速度上让人耳目一新,更是将智能化分析带入了日常的工作场景。以下是它们如何相辅相成并改变我们工作方式的一些分享。 --- 在…...

Kali CentOs 7代理
工具v2↓ kali_IP段v2端口例子<1> kali_IP段v2端口例子<2> CentOs 7 //编辑配置文件 vi /etc/profile//在该配置文件的最后添加代理配置 export http_proxyhttp://ip:port //代理服务器ip地址和端口号 export https_proxyhttp://ip:port //代理服务器ip地址和…...

Zookeeper 的核心引擎:深入解析 ZAB 协议
#作者:张桐瑞 文章目录 前言ZAB 协议算法崩溃恢复选票结构选票筛选消息广播 前言 ZooKeeper 最核心的作用就是保证分布式系统的数据一致性,而无论是处理来自客户端的会话请求时,还是集群 Leader 节点发生重新选举时,都会产生数据…...

L3-001 凑零钱
L3-001 凑零钱 - 团体程序设计天梯赛-练习集 n, m map(int, input().split()) a list(map(int, input().split())) a.sort() f [[] for _ in range(m 1)] f[0] [0] for i in a:for j in range(m, i - 1, -1):if f[j - i]:if not f[j] or f[j] > f[j - i] [i]:f[j] f…...
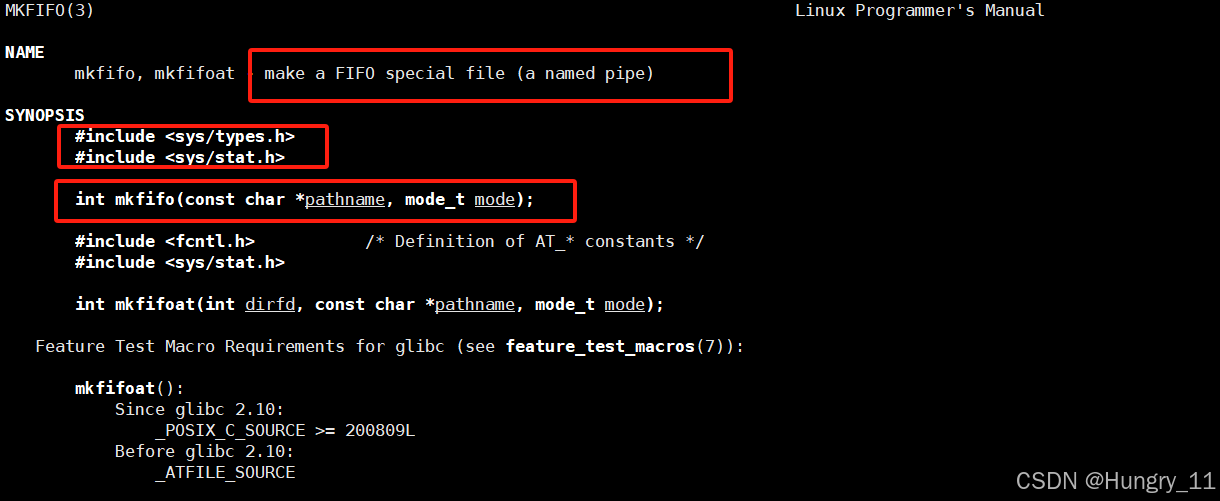
命名管道(用命名管道模拟server和client之间的通信)
目录 命名管道创建命名管道使用命令行创建命名管道(FIFO)在程序中创建 命名管道的打开规则用命名管道实现server和client通信 命名管道 bash进程并不会给我们写的两个不同的程序创建通信的管道,即使这两个进程看起来好像都是bash的子进程&am…...
)
【AI深度学习基础】Pandas完全指南入门篇:数据处理的瑞士军刀 (含完整代码)
📚 Pandas 系列文章导航 入门篇 🌱进阶篇 🚀终极篇 🌌 📌 一、引言 在大数据与 AI 驱动的时代,数据预处理和分析是深度学习与机器学习的基石。Pandas 作为 Python 生态中最强大的数据处理库,以…...

关于opencv中solvepnp中UPNP与DLS与EPNP的参数
The methods SOLVEPNP_DLS and SOLVEPNP_UPNP cannot be used as the current implementations are unstable and sometimes give completely wrong results. If you pass one of these two flags, SOLVEPNP_EPNP method will be used instead.、 由于当前的实现不稳定&#x…...

金融项目实战
测试流程 测试流程 功能测试流程 功能测试流程 需求评审制定测试计划编写测试用例和评审用例执行缺陷管理测试报告 接口测试流程 接口测试流程 需求评审制定测试计划分析api文档编写测试用例搭建测试环境编写脚本执行脚本缺陷管理测试报告 测试步骤 测试步骤 需求评审 需求评…...

大模型小白入门
【课前篇】大模型从0到1指南 【基础篇】大模型的演变与概念 大模型的演变 人工智能:人工智能是一个广泛涉及计算机科学、数据分析、统计学、机器工程、语言学、神 经科学、哲学和心理学等多个学科的领域。 机器学习:机器学习可以分为监督学习&…...

从零到一:快速上手 Poetry——Python 项目管理的利器
在 Python 项目开发中,包管理、依赖管理和虚拟环境的创建一直是开发者们经常面对的难题。传统上,开发者通常会使用 pip、virtualenv 或者 conda 来处理这些问题。然而,随着 Python 项目复杂度的增加,传统工具往往显得力不从心&…...
)
导师认可的AI论文软件榜单(2026 最新实测)
基于学术严谨性、写作效率、功能全面性及用户反馈,以下是2026年最新实测中表现突出的AI论文写作工具权威榜单,按综合使用价值从高到低排列,并附上各工具的核心优势与适用人群。🏆 第一梯队:全流程学术解决方案…...

别再死记硬背了!用这个班级排名的例子,5分钟搞懂R语言dplyr包的四种join函数
班级运动会排名解析:用生活案例彻底掌握R语言dplyr连接函数 刚接触R语言的数据合并操作时,那些inner_join、left_join的术语总让人望而生畏。但数据连接的本质,其实就像学校运动会后整理各班成绩一样简单。想象你手上有两个班级的排名表和运动…...

企业级部署警告:Perplexity事实核查功能未开启溯源审计模式的5大合规风险,GDPR/CCPA双认证团队紧急通告
更多请点击: https://codechina.net 第一章:Perplexity事实核查功能的核心机制与合规定位 Perplexity 的事实核查功能并非依赖单一模型输出,而是构建于多层验证架构之上:实时检索增强生成(RAG)、跨源可信度…...

为ubuntu20.04上的开源agent框架配置taotoken供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Ubuntu 20.04 上的开源 Agent 框架配置 Taotoken 供应商 在本地或服务器环境中部署开源 Agent 框架时,开发者常常希…...

订阅Token Plan套餐如何在实际开发中有效控制大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 订阅Token Plan套餐如何在实际开发中有效控制大模型调用成本 对于开发团队而言,将大模型能力集成到自动化流程或内部工…...

从芯片手册到PCB:SPL06与MPU9250的I2C实战布线要点与防护设计
从芯片手册到PCB:SPL06与MPU9250的I2C实战布线要点与防护设计 在无人机飞控板的设计中,气压传感器SPL06和九轴传感器MPU9250的稳定工作直接关系到飞行姿态控制的精确性。本文将深入探讨这两个关键传感器在PCB布局中的I2C总线设计要点,以及如何…...
)
别再只会用torchvision.models了!手把手教你从零理解ResNet18的PyTorch实现(附完整代码)
从零构建ResNet18:深入理解PyTorch实现与模型定制技巧 在深度学习领域,ResNet已经成为计算机视觉任务中不可或缺的基础架构。许多开发者习惯于直接调用torchvision.models.resnet18()这一行魔法代码,却对背后的实现细节知之甚少。本文将带你从…...

G-Helper终极指南:3分钟告别Armoury Crate臃肿,释放华硕笔记本真正性能
G-Helper终极指南:3分钟告别Armoury Crate臃肿,释放华硕笔记本真正性能 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, Pr…...

幻兽帕鲁服务器从1.4.1升级到1.5.0踩坑实录:Docker镜像更新、客户端兼容性与回滚指南
幻兽帕鲁服务器1.5.0升级全流程实战:从风险评估到完美回滚 当游戏社区还沉浸在1.4.1版本的稳定体验时,1.5.0版本的更新公告已经在玩家群中激起千层浪。作为服务器管理员,每次版本迭代都像走在钢索上——新特性带来的诱惑与未知风险永远并存。…...

有钱才懂爱:赚到钱你再去谈男女关系,你会发现,择偶逻辑都变了。 没钱的时候,你看到的是一堆条件:房子、车子、工作、家境。 有钱了之后,那些条件你都自己有了
先谋生,再谋爱:有钱之后,我才看懂了男女关系的真相 目录 先谋生,再谋爱:有钱之后,我才看懂了男女关系的真相 没钱的时候,你谈的从来都不是爱情,是“生存合伙” 钱是最好的过滤器,它能帮你滤掉所有的“功能性需求” 底层的“忠诚”,很多时候只是“没有选择”的同义词…...