项目工坊 | Python驱动淘宝信息爬虫
目录
前言
1 完整代码
2 代码解读
2.1 导入模块
2.2 定义 TaoBao 类
2.3 search_infor_price_from_web 方法
2.3.1 获取下载路径
2.3.2 设置浏览器选项
2.3.3 反爬虫处理
2.3.4 启动浏览器
2.3.5 修改浏览器属性
2.3.6 设置下载行为
2.3.7 打开淘宝登录页面
2.3.8 登录淘宝
2.3.9 搜索商品并提取信息
2.3.10 提取商品信息
3.11 保存数据到Excel
2.4 执行脚本
3 总结与思考
前言
Selenium作为主流的Web自动化测试框架,在数据采集领域也有广泛应用。本文将分享如何使用Selenium实现淘宝物资价格信息的爬取。目前代码还存在一些缺陷,主要体现在:1)未能有效绕过淘宝的反爬虫机制;2)登录环节仍需人工干预。欢迎大伙在评论区分享解决方案。
1 完整代码
import datetime
import os
import timeimport pandas as pd
import win32api
import win32con
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import Byclass TaoBao():# 下载每月出门单信息def search_infor_price_from_web(self, path_dir=os.path.abspath(r'.'), descr_list=['脱脂纱布', '机器人', '衬衫']):key1 = win32api.RegOpenKey(win32con.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders', 0,win32con.KEY_READ)download_path = win32api.RegQueryValueEx(key1, 'Desktop')[0]download_path = os.path.join(os.path.dirname(download_path), 'Downloads')print(download_path)# FileProcess().remove_assign_excel_file_in_path(download_path, key)# 重新从网站下载调拨文件print('浏览器设置默认信息,如关闭下载保留提示!!!')start_x_1 = datetime.datetime.now()options = Options()prefs = {'download.prompt_for_download': False, 'download.default_directory': download_path}options.add_experimental_option("prefs", prefs)options.add_experimental_option('excludeSwitches', ['enable-automation']) # 这里去掉window.navigator.webdriver的特性options.add_argument("--disable-blink-features=AutomationControlled")options.add_argument('--force-device-scale-factor=1')options.add_argument('--start-maximized') # 最大化窗口options.add_experimental_option('excludeSwitches', ['enable-automation']) # 禁用自动化栏options.add_experimental_option('useAutomationExtension',False) # 禁用自动化栏的原理:将window.navigator.webdriver改为undefined。# 屏蔽密码提示框prefs = {'credentials_enable_service': False, 'profile.password_manager_enabled': False}options.add_experimental_option('prefs', prefs)# 反爬虫特征处理options.add_argument('--disable-blink-features=AutomationControlled')# options.add_argument("--headless") # 无界面模式# options.add_argument("--disadle-gpu") # 禁用显卡# driver = webdriver.Chrome(chrome_options=options)driver = webdriver.Chrome(options=options)# 修改了浏览器的内部属性,跳过了登录的滑动验证driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})# driver = webdriver.Chrome()driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command')params = {'cmd': 'Page.setDownloadBehavior','params': {'behavior': 'allow', 'downloadPath': download_path}}driver.execute("send_command", params)print('浏览器将打开已经进入!!!')end_x_1 = datetime.datetime.now()print('花费%s时长进入浏览器!!!' % (end_x_1 - start_x_1))driver.maximize_window() # 最大化谷歌浏览器driver.implicitly_wait(10) # 隐性等待10s# driver.get('https://www.taobao.com')driver.get('https://login.taobao.com/member/login.jhtml')# 修改了浏览器的内部属性,跳过了登录的滑动验证driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})# 手机扫码登入# 尝试输入密码try:time.sleep(3)# 输入账号密码username = driver.find_element(By.ID, 'fm-login-id')# username.send_keys('jianfei.xu')username.send_keys('XXXXXX')time.sleep(10)password = driver.find_element(By.ID, 'fm-login-password')# password.send_keys('0000000.')password.send_keys('XXXXX')time.sleep(10)# 点击登入driver.find_element(By.XPATH,'/html/body/div/div[2]/div[3]/div/div/div/div[1]/div/form/div[6]/button').click()driver.implicitly_wait(10) # 隐式等待10stime.sleep(5)except:passtime.sleep(60)print(123)data_list = []for search_str in descr_list:# 输入搜索框path = '/html/body/div[3]/div[2]/div[1]/div/div/div[3]/div/div[1]/form/div[4]/input'driver.find_element(By.XPATH, path).clear()driver.find_element(By.XPATH, path).send_keys(search_str)time.sleep(2)# 查询path = '/html/body/div[3]/div[2]/div[1]/div/div/div[3]/div/div[1]/form/div[2]/button'driver.find_element(By.XPATH, path).click()time.sleep(2)# 切换浏览器窗口handle = driver.window_handles # 获取句柄,得到的是一个列表driver.switch_to.window(handle[-1]) # 切换至最新句柄time.sleep(10)try:path = '/html/body/div[3]/div[3]/div[1]/div[1]/div/div[2]/div[3]'text_str = driver.find_element(By.XPATH, path).textexcept:passtry:path = '/html/body/div[3]/div[3]/div/div[1]/div/div[3]'text_str = driver.find_element(By.XPATH, path).textexcept:pass'/html/body/div[3]/div[4]/div/div[1]/div/div[3]/div[3]/div/div[1]/a/div/div[1]/div[1]/img[1]''/html/body/div[3]/div[4]/div/div[1]/div/div[3]/div[3]/div/div[2]/a/div/div[1]/div[1]/img''/html/body/div[3]/div[4]/div/div[1]/div/div[3]/div[3]/div/div[3]/a/div/div[1]/div[1]/img''/html/body/div[3]/div[4]/div/div[1]/div/div[3]/div[3]/div/div[4]/a/div/div[1]/div[1]/img'# 对text_str进行数据提取print(text_str)data_dic = {}data_dic['物资'] = search_strtext_list = text_str.split('\n')print(text_list)ix = 1for i in range(len(text_list)):each_str = text_list[i]if each_str == '¥':print('>>>>>>>>>>>>>>>>>>>>')descr_picture_url = os.path.join(path_dir, text_list[i - 1] + '.webp')print(descr_picture_url)print(text_list[i - 1]) # 描述print(text_list[i])print(text_list[i + 1]) # 金额print(text_list[i + 3]) # 地点data_dic['对比%s-描述' % str(ix)] = text_list[i - 1]data_dic['对比%s-金额' % str(ix)] = text_list[i + 1]data_dic['对比%s-地点' % str(ix)] = text_list[i + 3]ix += 1data_list.append(data_dic)print('>>>>>>>>>>>>>>>>>>')print(text_str)# 关闭最新窗口# 跳转到新页面进行完一系列操作后driver.close() # 关闭新开的页面time.sleep(2)driver.switch_to.window(driver.window_handles[0]) # 跳转首页df = pd.DataFrame(data_list)df.to_excel('temp123.xlsx')df = pd.DataFrame(data_list)df.to_excel('temp123.xlsx')return df# 类引用
TaoBao().search_infor_price_from_web()
这段代码是一个使用Selenium自动化工具从淘宝网站上抓取商品信息的Python脚本。代码的主要功能是通过模拟浏览器操作,登录淘宝,搜索指定商品,并提取商品的价格、描述和地点等信息,最后将这些信息保存到Excel文件中。以下是对上述代码的详细解读
2 代码解读
2.1 导入模块
import datetime
import os
import time
import pandas as pd
import win32api
import win32con
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By-
datetime、os、time:用于处理日期、时间和文件路径。 -
pandas:用于数据处理和保存到Excel文件。 -
win32api、win32con:用于访问Windows注册表,获取下载路径。 -
selenium:用于自动化浏览器操作,模拟用户行为。
2.2 定义 TaoBao 类
class TaoBao():-
这个类封装了从淘宝网站抓取商品信息的功能。
2.3 search_infor_price_from_web 方法
def search_infor_price_from_web(self, path_dir=os.path.abspath(r'.'), descr_list=['脱脂纱布', '机器人', '衬衫']):-
这是类中的主要方法,用于从淘宝网站抓取商品信息。
-
path_dir:指定保存文件的路径,默认为当前目录。 -
descr_list:要搜索的商品列表,默认为['脱脂纱布', '机器人', '衬衫']。
2.3.1 获取下载路径
key1 = win32api.RegOpenKey(win32con.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders', 0,win32con.KEY_READ)
download_path = win32api.RegQueryValueEx(key1, 'Desktop')[0]
download_path = os.path.join(os.path.dirname(download_path), 'Downloads')
print(download_path)-
通过访问Windows注册表,获取用户的桌面路径,并将其修改为下载路径(
Downloads文件夹)。
2.3.2 设置浏览器选项
options = Options()
prefs = {'download.prompt_for_download': False, 'download.default_directory': download_path}
options.add_experimental_option("prefs", prefs)-
设置Chrome浏览器的下载选项,禁用下载提示,并指定下载路径。
2.3.3 反爬虫处理
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 去掉window.navigator.webdriver的特性
options.add_argument("--disable-blink-features=AutomationControlled")-
通过修改浏览器选项,避免被网站识别为自动化脚本。
2.3.4 启动浏览器
driver = webdriver.Chrome(options=options)-
启动Chrome浏览器,应用之前设置的选项。
2.3.5 修改浏览器属性
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})-
通过执行Chrome DevTools Protocol命令,修改浏览器的
navigator.webdriver属性,避免被检测为自动化工具。
2.3.6 设置下载行为
driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command')
params = {'cmd': 'Page.setDownloadBehavior','params': {'behavior': 'allow', 'downloadPath': download_path}}
driver.execute("send_command", params)-
设置浏览器的下载行为,允许下载并指定下载路径。
2.3.7 打开淘宝登录页面
driver.get('https://login.taobao.com/member/login.jhtml')-
打开淘宝的登录页面。
2.3.8 登录淘宝
username = driver.find_element(By.ID, 'fm-login-id')
username.send_keys('XXXXX')
password = driver.find_element(By.ID, 'fm-login-password')
password.send_keys('XXXXX')
driver.find_element(By.XPATH, '/html/body/div/div[2]/div[3]/div/div/div/div[1]/div/form/div[6]/button').click()-
通过输入用户名和密码,点击登录按钮,完成登录操作。
2.3.9 搜索商品并提取信息
for search_str in descr_list:driver.find_element(By.XPATH, path).clear()driver.find_element(By.XPATH, path).send_keys(search_str)driver.find_element(By.XPATH, path).click()-
遍历
descr_list中的每个商品名称,输入搜索框并点击搜索按钮。
2.3.10 提取商品信息
text_str = driver.find_element(By.XPATH, path).text
text_list = text_str.split('\n')-
从搜索结果页面中提取商品信息,并将其拆分为列表。
3.11 保存数据到Excel
df = pd.DataFrame(data_list)
df.to_excel('temp123.xlsx')-
将提取的商品信息保存到Excel文件中。
2.4 执行脚本
TaoBao().search_infor_price_from_web()-
创建
TaoBao类的实例,并调用search_infor_price_from_web方法,执行整个抓取过程。
3 总结与思考
这段代码通过Selenium模拟浏览器操作,实现了从淘宝网站抓取商品信息的功能。代码中使用了多种反爬虫技术,避免被网站检测为自动化脚本。最终,抓取到的商品信息被保存到Excel文件中,便于后续分析和处理。
相关文章:

项目工坊 | Python驱动淘宝信息爬虫
目录 前言 1 完整代码 2 代码解读 2.1 导入模块 2.2 定义 TaoBao 类 2.3 search_infor_price_from_web 方法 2.3.1 获取下载路径 2.3.2 设置浏览器选项 2.3.3 反爬虫处理 2.3.4 启动浏览器 2.3.5 修改浏览器属性 2.3.6 设置下载行为 2.3.7 打开淘宝登录页面 2.3.…...

Java8-Stream流介绍和使用案例
Java 8 引入了 Stream API,它提供了一种高效且声明式的方式来处理集合数据。Stream 的核心思想是将数据的操作分为中间操作(Intermediate Operations)和终端操作(Terminal Operations),并通过流水线&#x…...
的参数,“zh_CN.UTF-8“, “chs“, “chinese-simplified“的差异。)
setlocale()的参数,“zh_CN.UTF-8“, “chs“, “chinese-simplified“的差异。
在 C/C 中,setlocale() 函数的参数 zh_CN.UTF-8、chs 和 chinese-simplified 均用于设置中文简体环境,但它们的语义、平台支持和编码行为存在显著差异: 1. zh_CN.UTF-8(推荐) 含义: zh_CN: 中文&…...

docker 安装达梦数据库(离线)
docker安装达梦数据库,官网上已经下载不了docker版本的了,下面可通过百度网盘下载 通过网盘分享的文件:dm8_20240715_x86_rh6_rq_single.tar.zip 链接: https://pan.baidu.com/s/1_ejcs_bRLZpICf69mPdK2w?pwdszj9 提取码: szj9 上传到服务…...

FastGPT 引申:如何基于 LLM 判断知识库的好坏
文章目录 如何基于 LLM 判断知识库的好坏方法概述示例 Prompt声明抽取器 Prompt声明检查器 Prompt 判断机制总结 下面介绍如何基于 LLM 判断知识库的好坏,并展示了如何利用声明抽取器和声明检查器这两个 prompt 构建评价体系。 如何基于 LLM 判断知识库的好坏 在知…...

关于2023新版PyCharm的使用
考虑到大家AI编程的需要,建议大家安装新版Python解释器和新版PyCharm,下载地址都可以官网进行: Python:Download Python | Python.org(可以根据需要自行选择,建议选择3.11,保持交流版本一致&am…...

Leetcode 112: 路径总和
Leetcode 112: 路径总和 问题描述: 给定一个二叉树的根节点 root 和一个目标和 targetSum,判断是否存在从根节点到叶子节点的路径,使路径上所有节点的值相加等于目标和 targetSum。 适合面试的解法:递归 解法特点: …...

华为云IAM 用户名和IAM ID
账号 当您首次使用华为云时注册的账号,该账号是您的华为云资源归属、资源使用计费的主体,对其所拥有的资源及云服务具有完全的访问权限,可以重置用户密码、分配用户权限等。账号统一接收所有IAM用户进行资源操作时产生的费用账单。 账号不能…...

Compose Multiplatform+Kotlin Multiplatfrom 第四弹跨平台
文章目录 引言功能效果开发准备依赖使用gradle依赖库MVIFlow设计富文本显示 总结 引言 Compose Multiplatformkotlin Multiplatfrom 今天已经到compose v1.7.3,从界面UI框架上实战开发看,很多api都去掉实验性注解,表示稳定使用了!…...
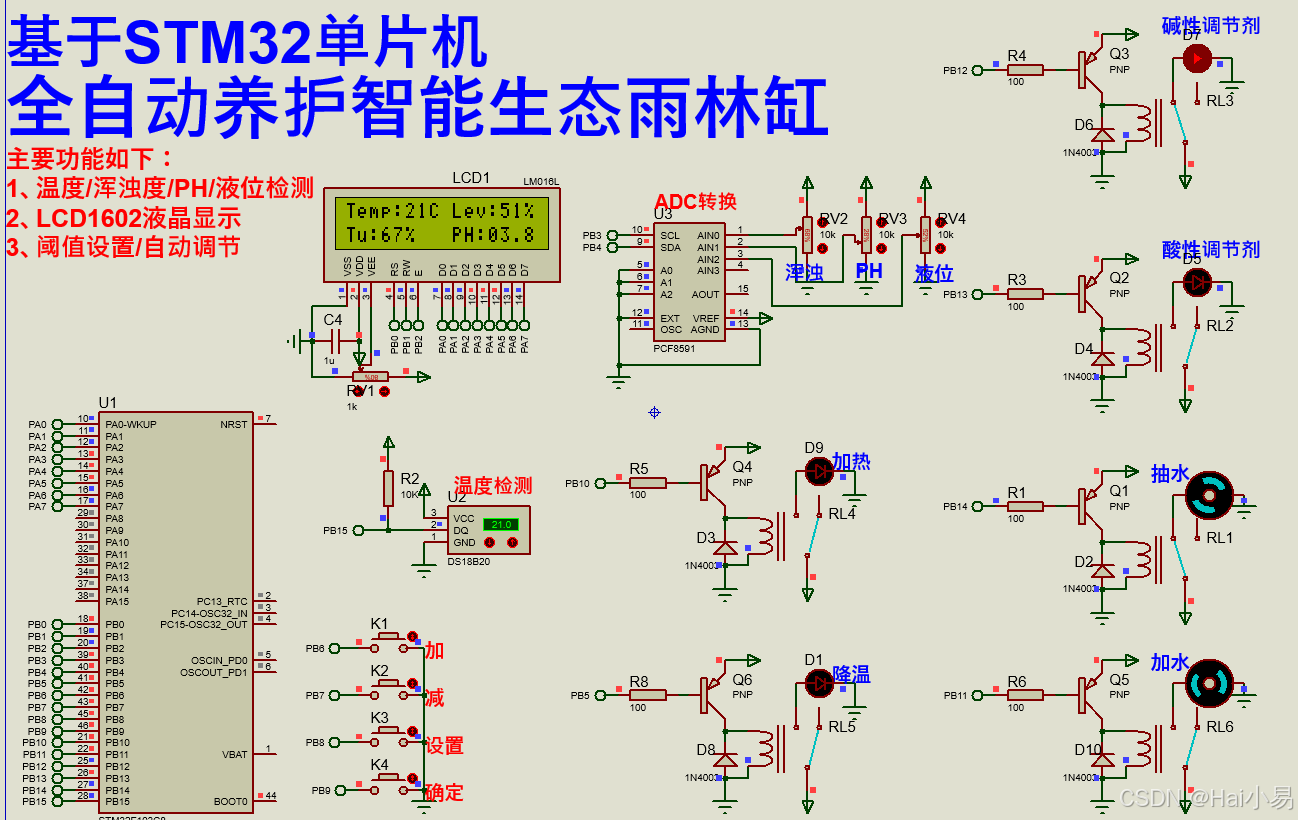
【Proteus仿真】【STM32单片机】全自动养护智能生态雨林缸
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用按键、LCD1602液晶、DS18B20模块、PCF8591 ADC、浑浊传感器、PH传感器、液位传感器、继电器、水泵、酸碱调节剂、加热降温装置等。 主要功能&am…...

GBT32960 协议编解码器的设计与实现
GBT32960 协议编解码器的设计与实现 引言 在车联网领域,GBT32960 是一个重要的国家标准协议,用于新能源汽车与监控平台之间的数据交互。本文将详细介绍如何使用 Rust 实现一个高效可靠的 GBT32960 协议编解码器。 整体架构 编解码器的核心由三个主要组…...

SolidWorks 转 PDF3D 技术详解
在现代工程设计与制造流程中,不同软件间的数据交互与格式转换至关重要。将 SolidWorks 模型转换为 PDF3D 格式,能有效解决模型展示、数据共享以及跨平台协作等问题。本文将深入探讨 SolidWorks 转 PDF3D 的技术原理、操作流程及相关注意事项,…...

OpenMCU(二):GD32E23xx FreeRTOS移植
概述 本文主要描述了GD32E230移植FreeRTOS的简要步骤。移植描述过程中,忽略了Keil软件的部分使用技巧。默认读者熟练使用Keil软件。本文的描述是基于OpenMCU_FreeRTOS这个工程,该工程已经下载放好了移植GD32E230 FreeRTOS的所有文件 OpenMCU_FreeRTOS工程…...
题解ABCDEFG)
Codeforces Round 835 (Div. 4)题解ABCDEFG
Problem - A - Codeforces 题意:你有 t 组数据,每组有两两不同的三个数 a,b,c,现在需要你求出他们的中位数。 思路:模拟即可 // Code Start Here int t;cin >> t;while(t--){vector<int> a(3);for(int i 0;i<3…...

NO1.C++语言基础|四种智能指针|内存分配情况|指针传擦和引用传参|const和static|c和c++的区别
1. 说⼀下你理解的 C 中的四种智能指针 智能指针的作用是管理指针,可以避免内存泄漏的发生。 智能指针就是一个类,当超出了类的作用域时,就会调用析构函数,这时就会自动释放资源。 所以智能指针作用的原理就是在函数结束时自动释…...

SQLite Having 子句详解
SQLite Having 子句详解 引言 SQLite 是一款轻量级的数据库管理系统,广泛应用于移动设备、嵌入式系统和各种桌面应用程序。在 SQL 查询中,HAVING 子句是用于过滤结果集的关键部分,尤其是在使用 GROUP BY 子句进行分组操作时。本文将详细解析 SQLite 中的 HAVING 子句,包括…...

Python数据分析面试题及参考答案
目录 处理 DataFrame 中多列缺失值的 5 种方法 批量替换指定列中的异常值为中位数 使用正则表达式清洗电话号码格式 合并两个存在部分重叠列的 DataFrame 将非结构化 JSON 日志转换为结构化表格 处理日期列中的多种非标准格式(如 "2023 年 12 月 / 05 日") 识…...

Spring Boot 3 整合 MinIO 实现分布式文件存储
引言 文件存储已成为一个做任何应用都不可回避的需求。传统的单机文件存储方案在面对大规模数据和高并发访问时往往力不从心,而分布式文件存储系统则提供了更好的解决方案。本篇文章我将基于Spring Boot 3 为大家讲解如何基于MinIO来实现分布式文件存储。 分布式存…...

ubuntu20 安装python2
1. 确保启用了 Universe 仓库 在某些情况下,python2-minimal 包可能位于 Universe 仓库中。你可以通过以下命令启用 Universe 仓库并更新软件包列表: bash复制 sudo add-apt-repository universe sudo apt update 然后尝试安装: bash复制…...

2025.3.3总结
周一这天,我约了绩效教练,主要想了解专业类绩效的考核方式以及想知道如何拿到一个更好的绩效。其他的岗位并不是很清楚,但是专业类的岗位,目前采取绝对考核,管理层和专家岗采取相对考核,有末尾淘汰。 通过…...

网盘直链解析助手:一站式解决多平台文件下载难题
网盘直链解析助手:一站式解决多平台文件下载难题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

避开HAL库:STM32F103寄存器级PWM移相全桥配置避坑指南
STM32F103寄存器级PWM移相全桥实战:从原理到避坑指南 在嵌入式开发领域,许多工程师习惯使用HAL库或标准库进行STM32开发,这确实能提高开发效率。但当项目对时序精度、资源占用或性能有极致要求时,直接操作寄存器往往能带来更优的效…...

Linux音频驱动开发实战:为TLV320ADC5120编写ALSA Codec驱动
1. 项目概述:从一块“哑巴”音频芯片到Linux系统的“耳朵”最近在折腾一块基于TI TLV320ADC5120的音频采集板,想把它接到我的RK3568开发板上用。芯片手册、硬件原理图都齐了,但一上电,系统里arecord -l根本找不到设备,…...

如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南
如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...
)
别再手动reshape了!用einops.rearrange优雅处理PyTorch张量维度(附实战代码)
用einops.rearrange重塑PyTorch张量:告别混乱的维度操作 深度学习开发中最令人头疼的莫过于张量维度的变换。你是否曾在凌晨三点盯着屏幕,试图理解自己昨天写的permute和reshape组合到底在做什么?或者花费半小时调试一个维度不匹配的错误&…...

第2篇_写MQTTBroker第一关不是PUBLISH_而是怎么让多个客户端稳稳连上同一个端口
写 Broker 最容易一上来就盯着 PUBLISH。但实际测试时,第一关通常不是消息转发,而是:两个客户端都连 192.168.20.100:1883,为什么一个都连不上,或者槽位刚置位就释放?先给结论:MQTT Broker 不是…...

从‘Missing for class: Script3’出发:深度解析Groovy动态属性与ShardingSphere配置陷阱
1. 当Spring Boot遇上ShardingSphere:一个诡异的报错现场 那天下午正喝着咖啡,突然收到同事的求助:"数据源初始化失败了!"第一反应是数据库配置有问题,结果排查半天发现报错信息里藏着这样一行字:…...
)
从零到部署:用VirtualBox免费搭建你的第一个Linux服务器(CentOS 7 + 静态IP + Xshell连接)
从零到部署:用VirtualBox免费搭建你的第一个Linux服务器(CentOS 7 静态IP Xshell连接) 在技术学习与开发实践中,拥有一个稳定可靠的Linux服务器环境是每个开发者成长的必经之路。对于预算有限的个人开发者、学生群体或刚接触运维…...

JetBrains IDE试用期重置工具:开发者的智能许可证管家
JetBrains IDE试用期重置工具:开发者的智能许可证管家 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当开发工具的试用期倒计时成为你编码时的心理负担,当每次启动IDE都要面对那个令人焦虑…...
与往返时间(RTT)出发:构建实时音视频通信的网络质量评估体系)
从抖动(Jitter)与往返时间(RTT)出发:构建实时音视频通信的网络质量评估体系
1. 实时音视频通信的网络质量挑战 当你参加视频会议时突然画面卡成PPT,或者直播连麦时对方声音忽大忽小,这些糟糕体验的背后往往是网络质量问题在作祟。实时音视频通信对网络环境极为敏感,就像在钢丝上骑自行车——任何微小的颠簸都可能导致严…...