说一下SpringBoot3新特新和JDK17新特性
JDK1.8(Java8)新特性
stream流式编程
流处理 Stream API 提供了对集合数据进行操作的一种高效、简洁的方式。它支持顺序和并行的聚合操作
如:过滤(filter)、排序(sort)、映射(map)、归约、collect(收集)等。

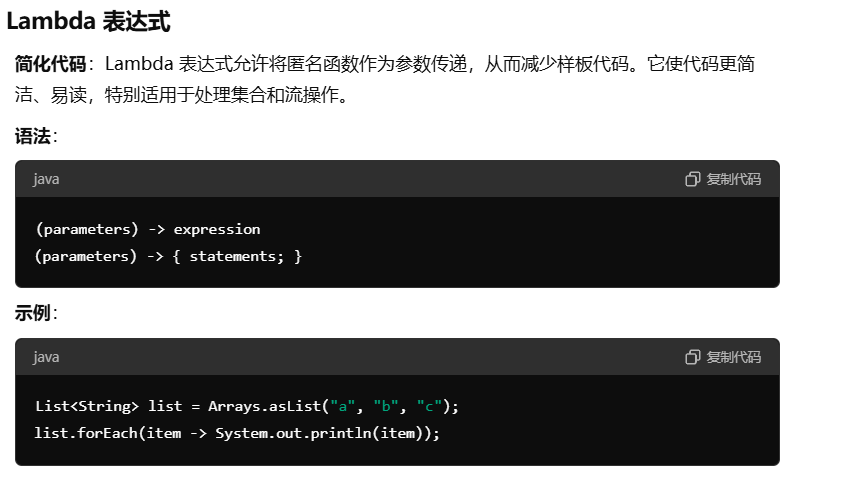
Lambda表达式
CompletableFuture并发编程
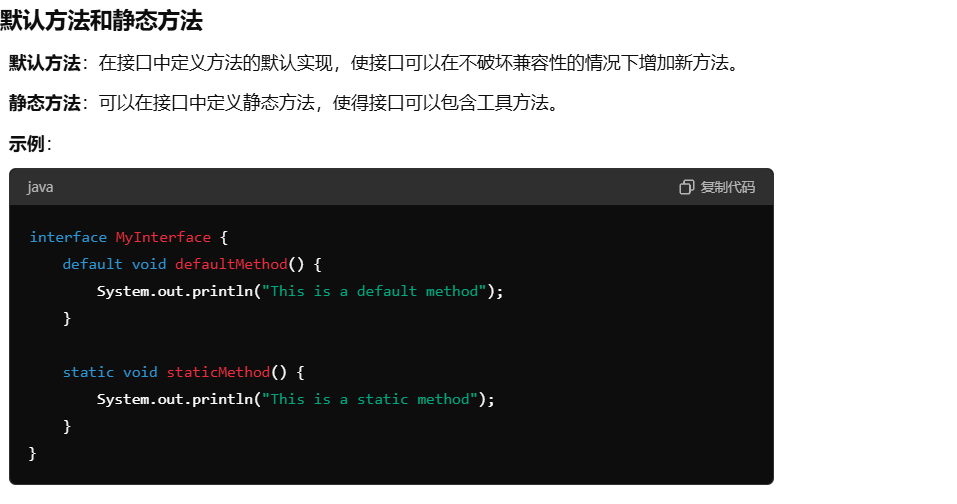
接口中的默认方法和静态方法
新日期和时间类型
旧
之前的包:java.util.Date,java.util.Calendar,java.text.SimpleDateFormat
新
新的包:java.time
里面有LocalDate 表示日期(不含时间)
LocalTime 表示时间(不含日期)
LocalDateTime 表示日期和时间
zonedDateTime 表示带时区的日期和时间
均为不可变对象,天然线程安全
为什么说之前的日期类型线程不安全而且可用性差
线程不安全
Date和Calendar是可变的,对象可能在多线程环境下被意外修改,导致数据不一致
例如可以通过setTime()和add()方法直接修改对象的值
Calendar calendar = Calendar.getInstance();
calendar.set(2023, Calendar.JANUARY, 1);
// 其他代码可能修改 calendar 的值,导致不可预测的行为SimpleDateFormat是非线程安全类,开发者必须通过同步或每次创建新实例来规避问题
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// 多线程调用 sdf.parse(dateStr) 会导致竞争条件功能缺失
问题:旧 API 缺少现代日期时间操作所需的特性:
不支持时区处理:需要手动计算时区偏移,容易出错。
无法直接进行日期算术:如计算两个日期之间的天数差需要复杂操作。
格式化与解析能力弱:依赖 SimpleDateFormat,且格式字符串易出错(如大小写敏感)
// 计算两个日期相差的天数(旧 API)
Calendar c1 = Calendar.getInstance();
Calendar c2 = Calendar.getInstance();
long diffMillis = c2.getTimeInMillis() - c1.getTimeInMillis();
long diffDays = diffMillis / (24 * 60 * 60 * 1000); // 可能因闰秒、时区等问题出错JDK17新特性
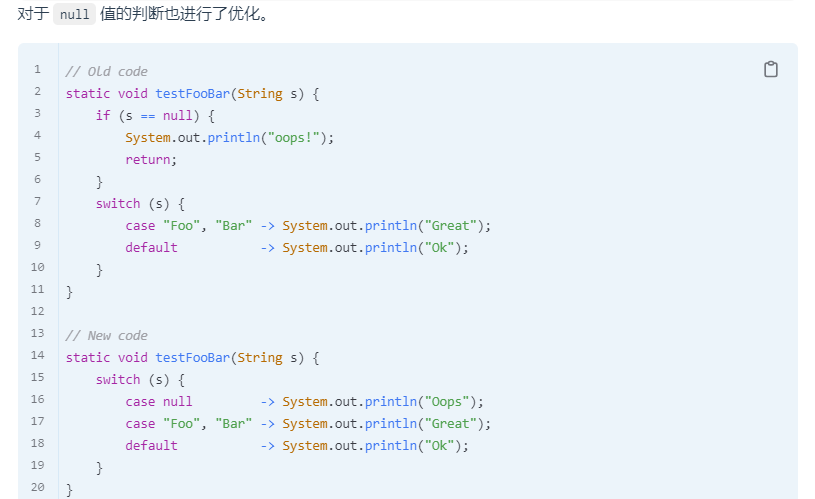
switch的类型匹配
正如 instanceof 一样, switch 也紧跟着增加了类型匹配自动转换功能
instanceof代码展示

swtich代码示例
switch有了类型转换


case能对null进行判断
增强的伪随机数生成器
之前我们的Random,ThreadLocalRandom,SplittableRandom来生成伪随机数
不过这些类里面缺少常见的伪随机算法支持
所以我们有了个RandomGenerator类

说一下以前的随机数生成器的缺陷
主要就是线程不安全,算法单一,算法不能灵活切换这些问题
Random
Random 在多线程环境下的性能较差,因为多个线程可能会竞争同一个随机数生成器的实例,导致性能瓶颈
多线程环境中,如果多个线程使用 Random 的同一个实例,访问会被锁定。假设有 10 个线程同时请求随机数,只有一个线程能生成随机数,其他线程需要等待,这会导致性能瓶颈
ThreadLocalRandom
ThreadLocalRandom 虽然为多线程优化,但它的功能相对单一,缺乏对多种伪随机算法的支持
ThreadLocalRandom 每个线程都有自己的实例,避免了锁竞争,但不能自由切换到其他伪随机算法
SplittableRandom
SplittableRandom 提供了一些改进,但仍然不够灵活,无法轻松地切换和使用不同的伪随机算法
RandomGenerator类的优点
1.允许开发者轻松选择和交换不同的伪随机数生成算法
2.新设计的随机数生成器在多线程环境下表现更佳,因为它们可以避免锁竞争。
3.新版算法支持多种常见的伪随机算法,开发者可以根据具体需求选择最适合的。
外部函数和内存API(孵化)
在 Java 开发中,有时需要使用 Java 本身无法直接提供的功能,比如调用操作系统底层的函数、使用一些用 C 或 C++ 编写的高性能库等
外部函数和内存 API 提供了一种机制,让 Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作
通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 JEP 412 提出
删除远程方法调用激活机制(RMI)
删除远程方法调用 (RMI) 激活机制,同时保留 RMI 的其余部分。RMI 激活机制已过时且不再使用
RMI(远程方法调用)
RMI 是 Java 提供的一种机制,允许一个 Java 程序调用另一个 Java 程序中的对象方法,即使它们在不同的计算机上运行。RMI 提供了一种简单的方式来实现分布式计算。
激活机制
RMI 激活机制是一种允许远程对象在需要时被动态创建和激活的机制。这意味着如果一个远程对象没有在 JVM 中运行,RMI 可以根据需要自动启动它。这种机制最初是为了提供灵活性,使得远程对象可以按需创建,而不需要在每次调用时都确保对象已存在。
删除激活机制的原因
过时:随着技术的发展,RMI 激活机制被认为已经不再适用或使用频率低,可能是因为新的技术和框架(如 RESTful API、gRPC、微服务架构等)提供了更好的解决方案。
复杂性:激活机制增加了 RMI 的复杂性,可能导致开发者在使用时遇到更多问题。
维护成本:随着时间推移,维护不再使用的功能会增加开发团队的负担。
密封类(转正)
密封类在JDK17中变成了一个稳定的特性
密封类(Sealed Classes)是 Java 语言的一项特性,最初由 JEP 360 提出,并在 Java 15 中以预览形式集成。
密封类允许开发者控制哪些类可以继承或实现该类,从而提高代码的安全性和可维护性。
JEP 360:这是提出密封类的提案,定义了密封类的基本概念和用法。
Java 15:在此版本中,密封类作为预览特性被引入,意味着开发者可以尝试使用,但它仍可能会在未来的版本中进行修改。
JDK 16:在这个版本中,密封类得到了改进,包括更严格的引用检查和对密封类继承关系的增强,这些改进是通过 JEP 397 提出的,并再次以预览形式提供
弃用的Applet API进行删除
Applet API 是一种用于创建可以在 Web 浏览器中运行的 Java 小程序的技术。然而,这种技术在很多年前就已经被淘汰,现代的 Web 开发中几乎没有人再使用它,因此没有必要继续支持。
被标记弃用:在 Java 9 中,Applet API 被标记为弃用(通过 JEP 289),这意味着开发者被建议不再使用它,但它并没有立即被删除。
不再使用的原因:随着 Web 技术的发展,像 HTML5、JavaScript 和其他现代框架变得更流行,Applet 的使用逐渐减少,导致其不再适用。
因此,虽然 Applet API 仍然存在于 Java 中,但它被认为是过时的技术,未来可能会被完全删除。
弃用的安全管理器
安全管理器(Security Manager)是 Java 中的一种机制,主要用于控制应用程序的权限和访问限制。它通过定义安全策略来决定 Java 应用程序可以执行哪些操作,从而保护系统的安全性
然而,随着时间的推移,这个机制逐渐被认为不再适用于现代的安全需求。
弃用的原因:Java 17 中决定弃用安全管理器,意味着将来可能会完全移除它。安全管理器在多年来并未成为保护客户端和服务器端 Java 代码的主要方法,使用频率非常低。这使得继续维护和支持它变得不再必要。
与 Applet API 的关系:安全管理器的弃用与 Applet API 的弃用相辅相成,反映了 Java 在向前发展过程中,清理过时和不再使用的特性的决心
SpringBoot3新特性
语言与框架基础升级
Java 17+:强制要求 Java 17 或更高版本,利用新语言特性(如密封类、模式匹配等)
Jakarta EE 9+:包命名空间从 javax.* 迁移到 jakarta.*(如 Servlet、JPA 等接口)
现代化安全支持
Spring Security 6:默认集成,支持 OAuth2 2.0、更简洁的配置方式
更严格的 CSRF 策略:默认启用 CSRF 保护,对 RESTful API 更友好
引入新的安全特性、修复已知安全漏洞,提供更强大的身份验证和授权机制,例如默认启用 https 和更严格的 CSP(内容安全策略)配置
新增配置注解
@ConfigurationProperties,简化读取配置文件配置
@ConfigurationPropertiesScan,对特定的包进行扫描
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.ConfigurationPropertiesScan;@SpringBootApplication
// 扫描带有 @ConfigurationProperties 注解的类
@ConfigurationPropertiesScan
public class MyApplication {public static void main(String[] args) {SpringApplication.run(MyApplication.class, args);}
}@SpringBootApplication
@ConfigurationPropertiesScan(basePackages = "com.example.config")
public class MyApplication {// ...
}智能事务回滚(精准定位脏数据)
传统事务(无脑回滚) :使用 @Transactional 注解的方法,当执行批量更新操作(如 100 条数据更新)时,只要其中某一条(如第 50 条)更新失败,整个事务就会全部回滚,所有已更新的数据都会恢复原状,即便其他数据更新操作本身没有问题。
Spring Boot 3.4 神技(精准回滚) :
- 新增
@Transactional的smartRollbackFor属性,可指定需要回滚的异常类,如DataIntegrityViolationException(数据完整性违规异常)和OptimisticLockingFailureException(乐观锁失败异常)。 - 执行批量更新时,若发生异常,仅会回滚触发异常的那笔记录。结合图中代码,
jdbcTemplate进行批量更新,并使用SmartBatchPreparedStatementSetter,可以更精准地控制事务回滚范围。
核心配置 :在 application.yml 配置文件中,通过 spring.transaction.smart-rollback.enabled 开启智能回滚功能,设为 true 表示启用;savepoint-interval 则用于设置保存点间隔,图中设置为每 10 条数据设置一个保存点,便于精准定位和回滚出现问题的数据 。
Spring Boot 3.4 的智能事务回滚机制,相比传统事务回滚,能减少不必要的数据回滚操作,提高数据处理的准确性和事务处理的效率
在 Spring 事务管理中,@Transactional 的 smartRollbackFor 属性和普通的 rollbackFor 属性有以下区别:
回滚粒度:
rollbackFor:它是一个传统的事务回滚控制属性,当方法执行过程中抛出的异常类型匹配到 rollbackFor 所指定的异常或其子类时,整个事务范围内的所有操作都会进行回滚 。比如在批量操作场景中,即便只有一条数据操作出现异常,只要该异常类型符合 rollbackFor 的设定,整个事务涉及的所有数据变更都会被回滚
smartRollbackFor:这是 Spring Boot 3.4 及后续版本新增的属性,主要用于实现精准回滚。当方法执行抛出 smartRollbackFor 指定的异常类型时,只会回滚触发异常的那笔记录或相关局部操作,而不是整个事务的所有操作
例如在数据批量更新时,某条数据更新因违反数据完整性约束抛出异常,使用 smartRollbackFor 就仅回滚这条有问题的数据更新,其他正常更新的数据不受影响
应用场景:
rollbackFor:适用于对事务一致性要求极高,希望在出现特定异常时,保证所有操作要么都成功、要么都失败的场景。比如金融系统中的转账操作,涉及多个账户的资金变动,只要其中一个步骤失败,就需要全部回滚,以保证资金的一致性
smartRollbackFor:更适合于一些批量处理或复杂业务逻辑场景,在这些场景中部分操作失败不影响其他操作的继续执行,并且希望尽可能保留已成功的操作结果,提高事务处理的效率和灵活性,减少不必要的数据回滚
底层机制差异:
rollbackFor:基于传统的事务回滚机制,当满足回滚条件时,Spring 会按照事务传播机制和隔离级别等相关配置,统一对整个事务进行回滚处理。
smartRollbackFor:其实现依赖于保存点(savepoint)机制等更精细的事务控制手段。在执行过程中,会按照配置(如设置保存点间隔)创建保存点,当遇到指定异常时,回滚到最近的相关保存点位置,实现精准的局部回滚
使用smartRollbackFor
场景一:电商订单商品批量更新
场景二:员工信息批量导入
保存点和回滚条数的关系
假设我们配置了每10条记录为一个保存点
spring:transaction:smart-rollback:enabled: truesavepoint-interval: 10事务执行正常
事务开始→ 处理第1-10条 → 设置保存点A→ 处理第11-20条 → 设置保存点B→ ... → 处理第91-100条 → 设置保存点J
事务提交(全部成功)第15条失败
事务开始→ 处理第1-10条 → 设置保存点A ✔️→ 处理第11-15条 → 第15条失败 ❌→ 回滚到保存点A(保留前10条)→ 重新处理第11-15条(若配置了重试)第7条失败
事务开始→ 处理第1-7条 → 第7条失败 ❌→ 没有保存点 → 回滚整个事务(前6条也丢失)第99条失败
事务开始→ 处理第1-90条 → 设置保存点I ✔️→ 处理第91-99条 → 第99条失败 ❌→ 回滚到保存点I(保留前90条)配置 savepoint-interval 的权衡
| 配置值 | 优点 | 缺点 |
|
| 每条记录独立回滚,精度最高 | 保存点过多,性能差 |
|
| 平衡回滚精度和性能 | 可能丢失最多9条数据 |
|
| 性能最优 | 失败时可能丢失99条数据 |
声明式Http客户端
传统的RestTemplate调用
RestTemplate template = new RestTemplate();
ResponseEntity<User> response = template.getForEntity(url, User.class);
if (response.getStatusCode() == HttpStatus.OK) { User user = response.getBody();
} @HttpExchange注解调用
@HttpExchange(url = "/api/users", accept = "application/json")
public interface UserClient { @GetExchange("/{id}")User getById(@PathVariable Long id); @PostExchangeUser create(@RequestBody User user);
} // 自动注入使用
@Autowired
private UserClient userClient; public User getUser(Long id) { return userClient.getById(id);
} 相关文章:
说一下SpringBoot3新特新和JDK17新特性
JDK1.8(Java8)新特性 stream流式编程 流处理 Stream API 提供了对集合数据进行操作的一种高效、简洁的方式。它支持顺序和并行的聚合操作 如:过滤(filter)、排序(sort)、映射(map&…...
Linux系统服务安全检测手记
一:服务器ip暴露ip和端口的安全问题 服务器IP和端口暴露在外网中确实存在一定的安全风险,以下是几个主要的安全问题及相应的缓解措施: ### 主要安全问题 1. **直接攻击**: - 暴露的IP地址和开放的端口可能成为黑客直接攻击的…...

鸿蒙与DeepSeek深度整合:构建下一代智能操作系统生态
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/north 目录 技术融合背景与价值鸿蒙分布式架构解析DeepSeek技术体系剖析核心整合架构设计智能调度系统实现…...

[创业之路-329]:华为铁三角实施的步骤
一、通用过程 华为铁三角实施的步骤主要包括以下几个关键阶段: 1、明确角色与职责 确定铁三角成员:组建由客户经理(AR)、解决方案经理(SR)和交付经理(FR)组成的铁三角团队。制定岗…...

1.15-16-17-18迭代器与生成器,函数,数据结构,模块
目录 15,Python3 迭代器与生成器15-1 迭代器15-1-1 基础知识15-1-2 迭代器与for循环工作原理 15-2 生成器(本质就是迭代器)15-2-1 yield 表达式15-2-2 三元表达式15-2-3 列表生成式15-2-4 其他生成器(——没有元祖生成式——&…...
)
java面向对象(详细讲解)
第一章 类和对象 1.面向对象的介绍 1.面向过程:自己的事情自己做,代表语言c语言 2.面向对象:自己的事情别人做,代表语言java 3.为啥要使用面向对象思想编程:很多功能别人给我们实现好了,我们只需要拿过…...

代码随想录二刷|图论2
图论 基础知识 1 无向图 (1)度:一个顶点连n条边就度为n (2)权 加权无向图:有边长的无向图 (3)通道:两个顶点之间有一些边和点,并且没有重复的边 路&am…...

毕业项目推荐:基于yolov8/yolov5/yolo11的暴力行为检测识别系统(python+卷积神经网络)
文章目录 概要一、整体资源介绍技术要点功能展示:功能1 支持单张图片识别功能2 支持遍历文件夹识别功能3 支持识别视频文件功能4 支持摄像头识别功能5 支持结果文件导出(xls格式)功能6 支持切换检测到的目标查看 二、数据集三、算法介绍1. YO…...

服务器CPU微架构
1、微架构图 前端:预解码、解码、分支预测、L1指令缓存、指令TLB缓存 后端:顺序重排缓存器ROB处理依赖,调度器送到执行引擎 执行引擎:8路超标量,每一路可以进行独立的微操作处理 Port0、1、5、6支持整数、浮点数的加…...

用本地浏览器打开服务器上使用的Tensorboard
文章目录 前言一、Tensorboard的安装二、使用步骤1.服务器上的设置2.在本地打开 总结 前言 最近有使用服务器上的Tensorboard的需求,踩了几个雷,现已在搜索和帮助下解决,总结于此。 一、Tensorboard的安装 pip install tensorboard2.12.0注…...

Nginx或Tengine服务器配置SSL证书
本文将全面介绍如何在Nginx或Tengine服务器配置SSL证书,具体包括下载和上传证书文件,在Nginx上配置证书文件、证书链和证书密钥等参数,以及安装证书后结果的验证。成功配置SSL证书后,您将能够通过HTTPS加密通道安全访问Nginx服务器…...

【基础4】插入排序
核心思想 插入排序是一种基于元素比较的原地排序算法,其核心思想是将数组分为“已排序”和“未排序”两部分,逐个将未排序元素插入到已排序部分的正确位置。 例如扑克牌在理牌的时候,一般会将大小王、2、A、花牌等按大小顺序插入到左边&…...

2安卓开发的主要语言
1. Kotlin(官方首选语言) 定位:Google 官方推荐的首选 Android 开发语言(2019 年起)。 优势: 简洁高效:语法糖减少样板代码(如 data class 自动生成 equals()/hashCode()࿰…...

Python练习(握手问题,进制转换,日期问题,位运算,求和)
一. 握手问题 代码实现 ans0for i in range(1,51):for j in range(i1,51):if i<7 and j<7:continueelse:ans 1print(ans) 这道题可以看成是50个人都握了手减去7个人没握手的次数 答案:1204 二.将十进制整数拆解 2.1门牌制作 代码实现 ans0for i in ra…...

vtk 3D坐标标尺应用 3D 刻度尺
2d刻度尺 : vtk 2D 刻度尺 2D 比例尺-CSDN博客 简介: 3D 刻度尺,也是常用功能,功能强大 3D 刻度尺 CubeAxesActor vtkCubeAxes调整坐标轴的刻度、原点和显示效果,包括关闭小标尺、固定坐标轴原点,以及设置FlyMode模…...

蓝桥杯每日一题:第一周周四哞叫时间
蓝桥杯每日一题:第一周周四哞叫时间 疑惑:如何把复杂度控制在Q(n),怎么枚举a和b,longlong的形式又该怎么输入(考虑用string) 思路:枚举倒数第二个b前面有多少个a 这是一…...

DeepSeek本地接口调用(Ollama)
前言 上篇博文,我们通过Ollama搭建了本地的DeepSeek模型,本文主要是方便开发人员,如何通过代码或工具,通过API接口调用本地deepSeek模型 前文:DeepSeek-R1本地搭建_deepseek 本地部署-CSDN博客 注:本文不仅…...

自由学习记录(41)
代理服务器的核心功能是在客户端(用户设备)和目标服务器(网站/资源服务器)之间充当“中介”,具体过程如下: 代理服务器的工作流程 当客户端希望访问某个网站(比如 example.com)时&…...

【编写UI自动化测试集】Appium+Python+Unittest+HTMLRunner
简介 获取AppPackage和AppActivity 定位UI控件的工具 脚本结构 PageObject分层管理 HTMLTestRunner生成测试报告 启动appium server服务 以python文件模式执行脚本生成测试报告 下载与安装 下载需要自动化测试的App并安装到手机 获取AppPackage和AppActivity 方法一 有源码的…...

大模型如何协助知识图谱进行实体关系之间的分析
大模型在知识图谱中协助进行实体关系分析的方式主要体现在以下几个方面: 增强数据标注与知识抽取 大模型通过强大的自然语言处理能力,能够高效地对原始数据进行实体、关系和事件的标注,从而提高数据处理的效率和准确性。例如,Deep…...

解锁CLIP潜力:三种高效微调策略实战解析
1. CLIP模型微调的必要性 CLIP作为多模态模型的里程碑之作,其zero-shot能力确实令人惊艳。但真实业务场景中,我们常常遇到这样的困境:电商平台需要区分"奶白色"和"米白色"的家具面料,医疗影像需要识别特定病灶…...

LabVIEW变量实战指南:从局部、全局到共享变量的高效数据流设计
1. 温度监控系统设计中的变量选择困境 第一次用LabVIEW做温度监控系统时,我在变量选择上栽过大跟头。当时为了图省事,把所有传感器数据都塞进了全局变量,结果系统运行半小时后就开始卡顿,报警响应延迟高达5秒——这对工业场景简直…...

【Nginx】Nginx index 指令全解:从首页加载失败到高性能目录服务的生产实践
Nginx index 指令全解:从首页加载失败到高性能目录服务的生产实践 本文面向已部署过简单 Nginx 服务、了解反向代理概念,但尚未系统掌握其静态文件目录索引与默认首页机制的中高级工程师。我们将彻底拆解 index 指令的工作原理、继承规则、与 try_files 的协作边界,揭示为何…...

BLE扫描器开发实战:从原始字节解析到IN100设备高效调试
1. 项目概述:从芯片到应用,一个BLE扫描器的诞生去年五月,我们团队独立开发的NanoBeacon™ BLE扫描器移动应用在应用宝正式上架了。这件事本身可能不算惊天动地,但对我们这些从底层芯片一路摸爬滚打上来的工程师来说,意…...

[2026降本增效实战] 制造业生产成本核算如何提升准确性?基于实在Agent的端到端解决方案
在2026年的工业4.0深水区,制造业的竞争早已从单纯的产能比拼转向了极致的成本精度博弈。 传统的成本核算模式正面临前所未有的挑战:数据颗粒度过粗、跨系统断点频发、人工干预导致的误差难以溯源。 随着大模型技术与超自动化技术的深度融合,智…...

对比直接使用官方 API 观察通过 Taotoken 聚合调用的成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 与通过 Taotoken 聚合调用的成本差异 在集成大模型能力到实际项目时,除了关注模型效果和稳定性&…...

AI应用开发框架nuwax:从快速构建到生产部署全解析
1. 项目概述:一个AI驱动的开源应用框架 最近在开源社区里,我注意到一个名为 nuwax-ai/nuwax 的项目开始受到一些关注。乍一看这个标题,它像是一个GitHub仓库的地址,由 nuwax-ai 这个组织或用户创建,项目名称为 nu…...

书匠策AI官网www.shujiangce.com:论文降重降AIGC的隐藏玩法,99%的毕业生还不知道!
💀 论文人的"红色恐惧症",你中招了吗? 各位论文战士们,今天不聊选题、不聊框架,咱聊点真正让人血压飙升的事——查重报告上那片触目惊心的红色。 你有没有经历过这种场景:熬了两个通宵写完一章…...

《从GIS前端到AIGC大厂:WebGIS、WebGL、Three.js技术栈的底层能力拆解与岗位适配指南》
前端GIS技术栈:从图形学底层到AIGC营销增长的全链路实战指南 (附大厂AI前端JD精准匹配与可落地项目) 🔖 目录理论篇:GIS中必学的图形学、WebGL、Three.js核心内容(含GIS实战细节) 1.1 计算机图形…...

Vatee:风险管理理念的深度实践
伴随金融市场的不断成熟,越来越多的客户开始关注平台的专业水准与综合能力。Vatee在行业中的发展轨迹较为值得关注。本文从评测视角出发,对其在多个核心维度上的实践进行综合呈现,力图以客观、平衡的姿态展示该平台的整体面貌,便于…...