【数据结构】LRUCache|并查集
目录
一、LRUCache
1.概念
2.实现:哈希表+双向链表
3.JDK中类似LRUCahe的数据结构LinkedHashMap
🔥4.OJ练习
二、并查集
1. 并查集原理
2.并查集代码实现
3.并查集OJ
一、LRUCache
1.概念
最近最少使用的,一直Cache替换算法
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实, LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容
2.实现:哈希表+双向链表

- 哈希表:查找速度快O(1)
- 双向链表:插入和删除的时间复杂度比较快O(1)
- head
- tail
3.JDK中类似LRUCahe的数据结构LinkedHashMap
- initialCapacity:初始容量大小
- loadFactor 加载因子
- accessOrder
- true:基于访问顺序 (把最常用的放到尾巴)
- false:基于插入顺序
(1)当accessOrder的值为false的时候:
public static void main(String[] args) {Map<String, String> map = new LinkedHashMap<>(16,0.75f,false);map.put("1", "a");map.put("2", "b");map.put("4", "e");map.put("3", "c");System.out.println(map);
}输出结果:
{1=a, 2=b, 4=e, 3=c}
以上结果按照插入顺序进行打印
(2) 当accessOrder的值为true的时候
public static void main(String[] args) {Map<String, String> map = new LinkedHashMap<>(16,0.75f,true);map.put("1", "a");map.put("2", "b");map.put("4", "e");map.put("3", "c");map.get("1");map.get("2");System.out.println(map);
}输出结果:
{4=e, 3=c, 1=a, 2=b}
每次使用get方法,访问数据后,会把数据放到当前双向链表的最后。
当accessOrder为true时,get方法和put方法都会调用recordAccess方法使得最近使用的Entry移到双向链表的末尾;当accessOrder为默认值false时,从源码中可以看出recordAccess方法什么也不会做
🔥4.OJ练习
https://leetcode-cn.com/problems/lru-cache/
解法一:自己实现链表(最新在头/尾都可)
(1)get方法:存在否->存在需refresh
(2)put方法:是否存在->覆盖/创建
创建->还有空间否?
(3)refresh:删除+放到链表头部/尾部(注意:步骤4一定得在步骤1的后面)
(4)delete:删除的是指定节点
class LRUCache {class DLinkNode {public int key;public int val;public DLinkNode prev;public DLinkNode next;public DLinkNode(int key,int val) {this.key = key;this.val = val;}}public DLinkNode head;public DLinkNode tail;public Map<Integer,DLinkNode> map;public int n;public LRUCache(int capacity) {this.head = new DLinkNode(-1,-1);this.tail = new DLinkNode(-1,-1);head.next = tail;tail.prev = head;map = new HashMap<>();this.n = capacity;}public int get(int key) {if(map.containsKey(key)) {DLinkNode node = map.get(key);refresh(node);return node.val;}return -1;}public void put(int key, int value) {DLinkNode node = null;if(map.containsKey(key)) {//存在->覆盖node = map.get(key); //直接在node上改,因为要refreshnode.val = value;} else {//还有空间否if(map.size() == n) {DLinkNode del = tail.prev;//这里得记录下来,不然删了,另一个就删不了map.remove(del.key);delete(del);}//放入mapnode = new DLinkNode(key,value);map.put(key,node);}refresh(node);}//放到链表头部(删除+放置)public void refresh(DLinkNode node) {delete(node);//删除指定节点node.next = head.next;head.next.prev = node;node.prev = head;//这个步骤4一定得在1的后面head.next = node;}//删除指定节点public void delete(DLinkNode node) {if(node.prev != null ) {DLinkNode pre = node.prev;pre.next = node.next;node.next.prev = pre;}}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/解法二:
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;public LRUCache(int capacity) {/**第3个参数的意思:当accessOrder设置为false时,会按照插入顺序进行排序,当accessOrder为true是,会按照访问顺 序(也就是插入和访问都会将当前节点放置到尾部,尾部代表的是最近访问的数据,这和JDK1.6是反过来 的,jdk1.6头部是最近访问的)。*/super(capacity,0.75F,true);this.capacity = capacity;
} //此时的get方法一定会,返回最近访问的数据
public int get(int key) {return super.getOrDefault(key, -1);
}public void put(int key, int value) {super.put(key, value);
} //必须重写这个方法,默认是false。此时根据
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;}
}
public class TestDemo {public static void main(String[] args) {LRUCache lruCache = new LRUCache(3);//尾插法插入lruCache.put(2,1);lruCache.put(3,1);lruCache.put(4,1);System.out.println(lruCache);//{2=1, 3=1, 4=1}System.out.println(lruCache.get(2));//1 并且放到链表的尾巴System.out.println(lruCache);//{ 3=1, 4=1,2=1}}
} /**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/二、并查集
1. 并查集原理
(1)解决的问题
- 将n个不同的元素划分成一些不相交的集合,开始时,每个元素自己都是单元素集合,然后按照一定的规律将归于同一组元素的集合合并
- 这个过程需要反复用到查询某个元素归属哪个集合的运算
(2)具体例子理解
- 初始状态

某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号 - 集合树形表示

西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长 - 并查集表示

- 数组的下标:表示对应集合中元素的编号
- 数组元素如果是负数:负数代表根节点,数字代表这个集合中元素的个数
- 数组如果是非负数:代表该元素的双亲在数组中的下标
- 合并1和8

在公司工作一段时间后,西安小分队中8号同学与成都小分队1号同学奇迹般的走到了一起,两个小圈子的学生相互介绍,最后成为了一个小圈子:
(3)小结:并查集解决的问题
- 查找元素属于哪个集合
沿着数组表示树形关系以上一直找到根(即:树中中元素为负数的位置) - 查看两个元素是否属于同一个集合
沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在 - 将两个集合归并成一个集合
将一个集合加入另一个集合 ,同时数组的下标也需要修改 - 集合的个数
数组中元素为负数的个数即为集合的个数
2.并查集代码实现
- (1)查找x元素的根节点

- (2)查询x1和x2是不是同一个集合

- (3)合并x1和x2的根节点的两个集合(x2并入x1)

- (4)当前集合的个数(不是元素的个数)

3.并查集OJ
- 省份数量
-
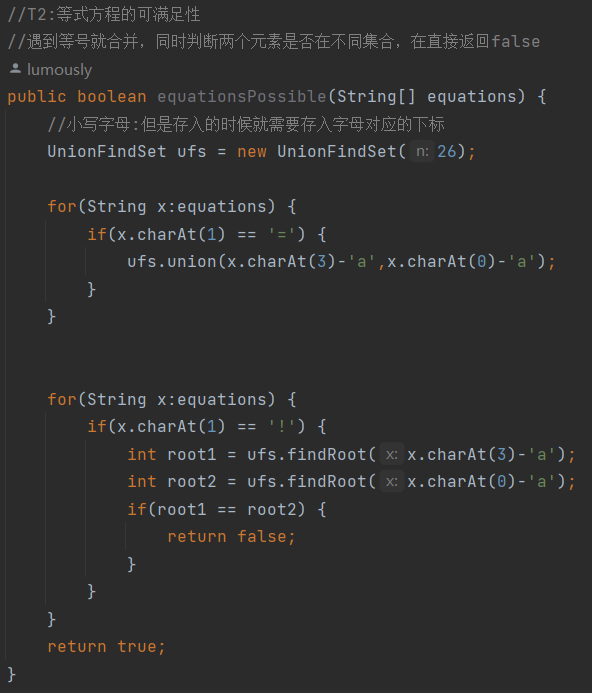
- 等式方程的可满足性
-

相关文章:
【数据结构】LRUCache|并查集
目录 一、LRUCache 1.概念 2.实现:哈希表双向链表 3.JDK中类似LRUCahe的数据结构LinkedHashMap 🔥4.OJ练习 二、并查集 1. 并查集原理 2.并查集代码实现 3.并查集OJ 一、LRUCache 1.概念 最近最少使用的,一直Cache替换算法 LRU是Least Recent…...

智能合约中权限管理不当
权限管理不当 : 权限管理不当是智能合约中常见的安全问题之一,尤其是在管理员或特定账户被过度赋予权限的情况下。如果合约中的关键功能,如转移资产、修改合约状态或升级合约逻辑,可以被未经授权的实体随意操作,这将构…...

MariaDB Galera 原理及用例说明
一、底层原理 MariaDB Galera 集群是一种基于同步多主架构的高可用数据库解决方案,适合需要高并发、低延迟和数据强一致性的场景。以下是部署和配置 MariaDB Galera 集群的简明步骤: 1. 环境准备 节点要求:至少 3 个节点(奇数节点…...

【RAG 篇】万字长文:向量数据库选型指南 —— Milvus 与 FAISS/Pinecone/Weaviate 等工具深度对比
大家好,我是大 F,深耕AI算法十余年,互联网大厂技术岗。分享AI算法干货、技术心得。 欢迎关注《大模型理论和实战》、《DeepSeek技术解析和实战》,一起探索技术的无限可能! 文章目录 向量数据库的核心价值主流工具横向对比 FAISS:Meta 的高效检索引擎Pinecone:全托管商业…...

关于服务器cpu过高的问题排查
1.定位是哪个程序造成的cpu过高 如果有云服务器,就用云服务器自带的监控功能,查时间段 如果没有,则使用: ps -eo pid,comm,pcpu,pmem,cputime --sort-cputime | head -n 100 2.定位到问题 发现是uwsgi的cpu消耗过高࿰…...
Gpt翻译完整版
上一篇文章收到了很多小伙伴的反馈,总结了一下主要以下几点: 1. 说不知道怎么调api 2. 目前只是把所有的中文变成了英文,如果想要做多语言还需要把这些关键字提炼出来成放到message_zh.properties和message_en.properties文件中,…...

雷池WAF的为什么选择基于Docker
Docker 是一种开源的容器化平台,可以帮助开发人员将应用程序及其所有依赖项打包到一个称为容器的独立、可移植的环境中。Docker 的核心概念包括以下几点: 容器:Docker 使用容器来封装应用程序及其依赖项,使其能够在任何环境中都能…...

美股回测:历史高频分钟数据的分享下载与策略解析20250305
美股回测:历史高频分钟数据的分享下载与策略解析20250305 在金融分析和投资决策的精细化过程中,美股历史分钟高频数据发挥着至关重要的作用。这些数据以其详尽性和精确性,记录了股票每分钟的价格波动和成交量变化,为投资者提供了…...

【文生图】windows 部署stable-diffusion-webui
windows 部署stable-diffusion-webui AUTOMATIC1111 stable-diffusion-webui Detailed feature showcase with images: 带图片的详细功能展示: Original txt2img and img2img modes 原始的 txt2img 和 img2img 模式 One click install and run script (but you still must i…...
]第3章 Python基础知识)
[Python入门学习记录(小甲鱼)]第3章 Python基础知识
第3章 基础知识 前面三章都没啥用,这一章开始进入主题。 3.1 变量 变量顾名思义就是一个可变的量,但Python的变量更像是一个名字,通过这个名字可以找到我们想要的值。注意点如下: Python不需要显式声明,但使用之前…...

某系统webpack接口泄露引发的一系列漏洞
视频教程在我主页简介或专栏里 (不懂都可以来问我 专栏找我哦) 目录: 信息搜集 未授权敏感信息泄露越权任意用户密码重置 1.越权访问 2.大量敏感信息 越权 任意用户密码重置 信息搜集 这里找到从小穿一条裤子长大的兄弟,要挟他交…...

【计算机网络入门】初学计算机网络(十一)重要
目录 1. CIDR无分类编址 1.1 CIDR的子网划分 1.1.1 定长子网划分 1.1.2 变长子网划分 2. 路由聚合 2.1 最长前缀匹配原则 3. 网络地址转换NAT 3.1 端口号 3.2 IP地址不够用? 3.3 公网IP和内网IP 3.4 NAT作用 4. ARP协议 4.1 如何利用IP地址找到MAC地址…...

决策树(Decision Tree)基础知识
目录 一、回忆1、*机器学习的三要素:1)*函数族2)*目标函数2.1)*模型的其他复杂度参数 3)*优化算法 2、*前处理/后处理1)前处理:特征工程2)后处理:模型选择和模型评估 3、…...

Nat Mach Intell | AI分子对接算法评测
《Nature Machine Intelligence》发表重磅评测,系统评估AI与物理方法在虚拟筛选(VS)中的表现,突破药物发现效率瓶颈。 核心评测体系:三大数据集 研究团队构建了三个新型测试集: TrueDecoy:含14…...

【自学笔记】Hadoop基础知识点总览-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Hadoop基础知识点总览1. Hadoop简介2. Hadoop生态系统3. HDFS(Hadoop Distributed File System)HDFS基本命令 4. MapReduceWordCount示例&am…...

【Linux】使用问题汇总
#1 ssh连接的时候报Key exchange failed 原因:服务端版本高,抛弃了一些不安全的交换密钥算法,且客户端版本比较旧,不支持安全性较高的密钥交换算法。 解决方案: 如果是内网应用,安全要求不这么高…...

(二 十 二)趣学设计模式 之 备忘录模式!
目录 一、 啥是备忘录模式?二、 为什么要用备忘录模式?三、 备忘录模式的实现方式四、 备忘录模式的优缺点五、 备忘录模式的应用场景六、 总结 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,…...

交叉编译openssl及curl
操作环境:Ubuntu20.04 IDE工具:Clion2020.2 curl下载地址:https://curl.se/download/ openssl下载地址:https://openssl-library.org/source/old/index.html 直接交叉编译curl会报错找不到openssl,所以需要先交叉编…...
:IP)
【每日八股】计算机网络篇(三):IP
目录 DNS 查询服务器的基本流程DNS 采用 TCP 还是 UDP,为什么?默认使用 UDP 的原因需要使用 TCP 的场景?总结 DNS 劫持是什么?解决办法?浏览器输入一个 URL 到显示器显示的过程?URL 解析TCP 连接HTTP 请求页…...

Gartner:数据安全平台DSP提升数据流转及使用安全
2025 年 1 月 7 日,Gartner 发布“China Context:Market Guide for Data Security Platforms”(《数据安全平台市场指南——中国篇》,以下简称指南),报告主要聚焦中国数据安全平台(Data Securit…...

大空间中庭水平防火卷帘防火分隔技术应用探讨
摘要大空间中庭广泛应用于商业综合体、大型会展中心、高端写字楼等现代公共建筑,具备通透开阔、流线连贯、美观性强的空间优势,但多层贯通的结构特性极易造成火灾烟气快速扩散、火势纵向蔓延,大幅提升建筑消防防控难度。水平防火卷帘作为柔性…...

EvoAgentX智能体开发框架:模块化架构与进化引擎解析
1. 项目概述:一个面向未来的智能体开发框架最近在探索智能体(Agent)开发领域时,我遇到了一个名为“EvoAgentX”的项目。这个名字本身就很有意思,“Evo”暗示着进化,“AgentX”则指向了智能体及其无限的可能…...

Claude Code提示词入门:CLAUDE.md编写完全指南
目录Claude Code提示词入门:CLAUDE.md编写完全指南 🎯📌 目录1. 什么是CLAUDE.md2. 为什么CLAUDE.md这么重要2.1 没有CLAUDE.md会怎样?2.2 有了CLAUDE.md会怎样?2.3 核心价值3. CLAUDE.md的加载机制3.1 加载优先级3.2 …...

OBS实时字幕插件完整指南:3分钟快速部署专业直播字幕
OBS实时字幕插件完整指南:3分钟快速部署专业直播字幕 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin OBS实时字幕插件是一款基于Go…...

倒置百分比堆叠面积图表示列详解|Highcharts大气成分图表代码
这是一个基于 Highcharts 实现的水平面积曲线图(areaspline 倒置坐标系),专门用于展示不同高度下地球大气成分的体积占比变化,是典型的百分比堆叠面积图,数据直观反映了大气层随高度升高的成分分布规律。我会从图表结…...

WinForm用户控件调试踩坑记:从‘无法试运行’到完美模块测试的完整流程
WinForm用户控件调试实战:从模块移植到精准测试的完整指南 引言:为什么需要独立的控件测试环境? 在WinForm开发中,用户控件(UserControl)的复用与调试一直是让开发者头疼的问题。当你在主项目中直接测试一个复杂控件时,…...

3步搞定Windows安卓应用安装:告别模拟器的全新体验
3步搞定Windows安卓应用安装:告别模拟器的全新体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行手机应用,却…...

HiveWE魔兽地图编辑器:5分钟快速上手指南,告别卡顿创作新时代
HiveWE魔兽地图编辑器:5分钟快速上手指南,告别卡顿创作新时代 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为《魔兽争霸III》原版地图编辑器缓慢的加载速度和繁琐的操作而烦恼…...

理发师会被 AI 取代吗?这可能是 AI 时代最有意思的一个社会学问题
今天去理发了。对着镜子,看着我的头发随着剪刀的飞舞一点点掉下来时,我忽然开始神游:AI 会不会取代理发师? 这问题乍一听有点像胡思乱想,可越想越觉得,它其实非常适合拿来当成 AI 时代的一块切片。 因为理发…...

应用连接协议桥接器:打通异构系统,实现数据自动化流转
1. 项目概述:一个连接不同应用生态的“桥梁”最近在折腾一些自动化流程,发现不同平台、不同应用之间的数据互通是个老大难问题。比如,你在A平台创建了一个任务,希望它能自动同步到B平台的日历,或者把C应用里的数据变化…...