计算机视觉|ViT详解:打破视觉与语言界限
一、ViT 的诞生背景
在计算机视觉领域的发展中,卷积神经网络(CNN)一直占据重要地位。自 2012 年 AlexNet 在 ImageNet 大赛中取得优异成绩后,CNN 在图像分类任务中显示出强大能力。随后,VGG、ResNet 等深度网络架构不断出现,推动了图像分类、目标检测、语义分割等任务的性能提升,促进了计算机视觉技术的快速发展。
然而,CNN 也逐渐显露出一些局限性。一方面,CNN 依赖局部感知,通过卷积核捕获局部区域的特征。尽管多层卷积可以提取高维语义信息,但在处理长距离依赖关系(如图像的全局信息)时,由于卷积核感受野有限,CNN 的能力受限,可能需要增加层数或设计复杂架构来弥补,这增加了模型复杂度和训练难度。另一方面,随着网络深度增加,CNN 的参数数量和计算量显著增长,对硬件资源的需求也随之提高,增加了部署成本,并限制了其在资源受限设备上的应用。
为了解决这些问题,研究者开始探索其他架构,其中 Transformer 架构受到广泛关注。Transformer 最初在自然语言处理(NLP)领域提出,凭借自注意力机制在捕捉序列中任意位置依赖关系方面的优势,成为 NLP 主流模型。受此启发,研究者尝试将其应用于视觉领域,Vision Transformer(ViT)因此诞生,为视觉任务提供了新的方法,标志着视觉模型发展的重要转变。
二、ViT 的核心原理
(一)Transformer 架构回顾
Transformer 架构于 2017 年在论文《Attention Is All You Need》中提出,最初用于解决自然语言处理中的机器翻译任务。在此之前,循环神经网络(RNN)及其变体(如 LSTM、GRU)是处理序列数据的主要模型,但这些模型存在梯度消失或爆炸问题,难以捕捉长距离依赖,且计算效率较低,难以并行化。

Transformer 的核心是自注意力机制,通过计算输入序列中每个位置与其他位置的关联程度,动态分配注意力权重,聚焦于关键信息。
例如,在处理句子“苹果从树上掉下来,小明捡起了它”时,自注意力机制能让模型在处理“它”时关注“苹果”,准确理解其指代对象。相比 RNN 按顺序处理序列,自注意力机制允许模型直接参考整个序列,大幅提升捕捉长距离依赖的能力。
多头注意力机制是自注意力机制的扩展,通过并行多个注意力头,每头学习不同的表示并拼接结果,增强模型从不同角度捕捉信息的能力。例如,在分析复杂句子时,不同注意力头可分别关注语法结构、语义关系等。
此外,Transformer 引入位置编码来弥补自注意力对顺序不敏感的缺陷,通过为每个位置添加唯一编码向量,将位置信息融入输入;前馈网络则对注意力输出进行非线性变换,提升特征学习能力。
(二)ViT 架构设计
前面我们在 计算机视觉 |解锁视频理解三剑客——ViViT 中简单介绍了 VIT 架构,本文我们将详细介绍它的架构设计。
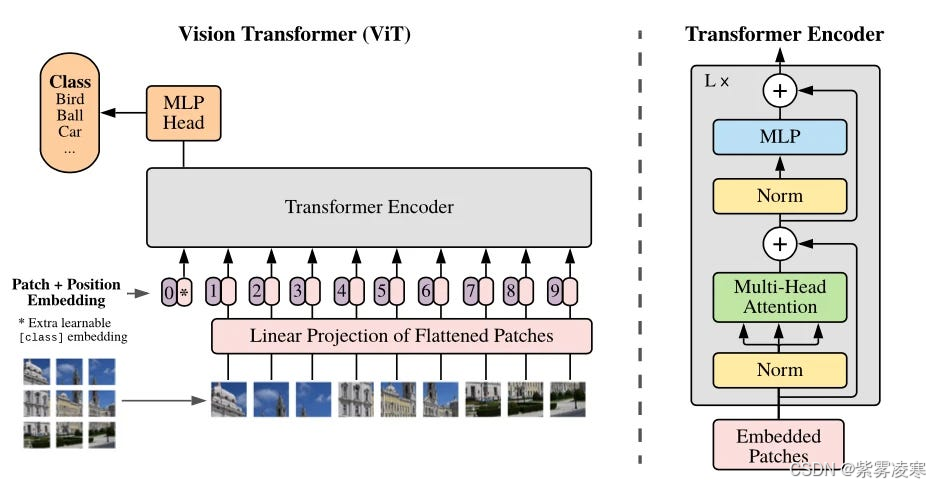
1. 图像分块
ViT 首先将输入图像划分为固定大小的 patch。例如,输入图像为 224 × 224 224\times224 224×224,通常划分为 16 × 16 16\times16 16×16 的 patch,生成 14 × 14 = 196 14\times14 = 196 14×14=196 个 patch。每个 patch 展平为一维向量,形成序列,作为 Transformer 的输入。这种分块将图像转化为序列形式,使 Transformer 能以处理序列的方式处理图像,突破 CNN 局部卷积的限制,直接捕捉不同区域间的长距离依赖。
2. 线性嵌入
展平后的 patch 通过线性投影嵌入到低维空间。使用可学习的线性变换矩阵(全连接层),将每个 patch 向量映射为固定维度的嵌入向量。例如,若 patch 展平后维度为 16 × 16 × 3 16\times16\times3 16×16×3(RGB 三通道),目标嵌入维度为 d d d(如 d = 768 d = 768 d=768),则通过 ( 16 × 16 × 3 ) × d (16\times16\times3)\times d (16×16×3)×d 的权重矩阵变换,得到维度为 d d d 的嵌入向量。嵌入维度影响表达能力和计算复杂度,需在性能和资源间权衡。
3. 位置编码
由于自注意力机制对输入顺序不敏感,而图像的空间位置信息重要,ViT 引入位置编码。默认使用可学习的 1D 位置编码,将二维 patch 按固定顺序展平为一维序列,为每个位置分配编码向量并与嵌入向量相加,使模型感知 patch 的相对位置。可选的正弦/余弦固定位置编码也常用于提供丰富位置信息。
4. Transformer 编码器
Transformer 编码器是 ViT 的核心,由多个 Transformer 块组成。每个块包含多头自注意力和前馈网络两个子层。
多头自注意力层通过计算不同头的注意力权重,捕捉图像中不同尺度和语义的依赖关系。输入嵌入向量序列通过线性变换生成查询、键、值矩阵,计算点积并经缩放和 Softmax 归一化后,得到注意力权重,再与值矩阵加权求和。例如,12 个头可分别关注物体轮廓、纹理等,最后拼接输出。
前馈网络对注意力输出进行非线性变换,包含两个线性层和激活函数(如 GELU),增强特征学习能力。残差连接和层归一化用于加速训练和稳定优化。
5. 分类头
分类头位于 ViT 末端,用于图像分类。在编码器输出序列中添加分类标记,与其他 patch 嵌入向量一起计算,仅作为分类标识。编码器处理完成后,提取分类标记的输出向量,通过全连接层映射到分类结果。例如,在 1000 类任务中,输出 1000 维向量,经 Softmax 转换为概率分布。
三、ViT 的训练与优化
(一)预训练与微调
ViT 通常在大规模数据集上预训练以学习通用图像特征。例如,在 JFT-300M 数据集(1400 万张图像)上预训练,通过最小化交叉熵损失更新参数,使用 AdamW 优化器(学习率约 1e-4,权重衰减 0.05),模型逐渐收敛。
预训练后,ViT 可在下游任务中微调。例如,在 CIFAR-10 上微调时,替换分类头为 10 类输出,使用较小学习率(如 1e-5)训练,适应新任务并提升准确率。
(二)数据增强
数据增强是提升 ViT 性能的重要方法。常见技术包括旋转、翻转、裁剪、缩放、颜色抖动等,增强模型对角度、方向、局部特征、光照变化的鲁棒性。
新兴方法如 TransMix 基于注意力图混合标签,改进传统 Mixup,根据像素重要性权重生成新样本。在 ImageNet 上,TransMix 可提升 ViT 的 top-1 准确率约 0.9%,增强泛化能力。
(三)优化器与超参数调整
AdamW 是 ViT 常用的优化器,加入权重衰减防过拟合,参数 β1=0.9、β2=0.999、eps=1e-8 确保优化稳定。
超参数如分块大小、嵌入维度、层数、注意力头数、学习率、Dropout 概率需调整。分块大小影响全局与细节捕捉,嵌入维度和层数影响表达能力,注意力头数影响细节关注,学习率需通过调度(如余弦退火)优化,Dropout(0.1-0.3)防过拟合。可用网格搜索等方法优化超参数。
四、ViT 的性能分析
(一)与 CNN 的对比
在大数据集上,ViT 凭借全局建模能力优于 CNN。例如,在 JFT-300M 预训练后,ViT 在 ImageNet 上准确率超过传统 CNN,特别在复杂全局结构图像中表现更佳。
在小数据集上,CNN 因归纳偏置(如平移不变性)更具优势,ViT 易过拟合。例如,在 CIFAR-10 上,ResNet 通常优于未充分预训练的 ViT。
ViT 自注意力机制计算复杂度高,与序列长度平方成正比,高分辨率图像处理时资源需求大,而 CNN 卷积操作更高效。CNN 的卷积核可解释性也优于 ViT 的注意力权重。
(二)不同数据集上的表现
在大规模数据集(如 JFT-300M)上,ViT 性能卓越,充分利用数据学习复杂特征。在小数据集(如 MNIST、CIFAR-10)上,ViT 表现不如 CNN,易过拟合。数据规模增加时,ViT 准确率可提升 5%-10%,泛化能力增强。
五、ViT 的变体与改进
(一)DeiT
DeiT 通过知识蒸馏提升性能,引入蒸馏标记与分类标记共同优化,模仿教师模型(如 RegNet)预测。在 ImageNet 上,DeiT 准确率提升 3%-6%。
DeiT 采用 RandomErase、Mixup、Cutmix 等数据增强技术,结合优化参数初始化和学习率调度,提高训练效率和泛化能力。
(二)Swin Transformer
Swin Transformer 采用分层结构,通过多阶段下采样提取多尺度特征,适用于目标检测、语义分割等任务。
其滑动窗口注意力机制在窗口内计算自注意力,降低复杂度( O ( M 2 ⋅ H W ) O(M² \cdot \frac{H}{W}) O(M2⋅WH) vs. O ( H W 2 ) O(HW²) O(HW2)),移位窗口增强全局信息交互,适合高分辨率图像处理。
六、ViT 的应用场景
(一)图像分类
ViT 在图像分类中表现优异。例如,ViT-B/16 在 ImageNet 上达到 77.9% 的 top-1 准确率。在医疗影像(如肺炎分类,准确率超 90%)和工业检测(如缺陷识别,准确率约 95%)中应用广泛。
(二)目标检测
ViT 可作为骨干网络用于目标检测。例如,DETR 在 MS COCO 上 AP 达 42.0%。但计算复杂度高和对小目标检测效果较弱是其挑战。
(三)语义分割
ViT 的全局建模能力适合语义分割。例如,SegFormer 在 ADE20K 上 mIoU 达 45.1%。但高分辨率图像处理资源需求大,细节捕捉能力稍逊于 CNN。
七、总结与展望
Vision Transformer(ViT)是计算机视觉的重要创新,通过 Transformer 架构捕捉图像全局依赖,在图像分类、目标检测、语义分割中展现潜力。
其核心是将图像分块并嵌入,结合位置编码输入 Transformer 编码器,通过自注意力建模全局关系。预训练与微调、数据增强、优化器调整提升了性能。
ViT 在大规模数据集上表现优异,但小数据集易过拟合,计算复杂度高,可解释性待提升。DeiT 和 Swin Transformer 等变体优化了效率和性能。
未来可从效率优化、训练策略、可解释性、新领域应用(如多模态融合)等方面进一步发展 ViT,推动视觉技术进步。(CNN)一直占据重要地位。自 2012 年 AlexNet 在 ImageNet 大赛中取得优异成绩后,CNN 在图像分类任务中显示出强大能力。随后,VGG、ResNet 等深度网络架构不断出现,推动了图像分类、目标检测、语义分割等任务的性能提升,促进了计算机视觉技术的快速发展。
延伸阅读
-
计算机视觉系列文章
计算机视觉|从0到1揭秘Diffusion:图像生成领域的新革命
计算机视觉 |解锁视频理解三剑客——ViViT
计算机视觉 |解锁视频理解三剑客——TimeSformer
计算机视觉 |解锁视频理解三剑客——SlowFast
计算机视觉实战|Mask2Former实战:轻松掌握全景分割、实例分割与语义分割
计算机视觉|Mask2Former:开启实例分割新范式
计算机视觉|目标检测进化史:从R-CNN到YOLOv11,技术的狂飙之路
轻量化网络设计|ShuffleNet:深度学习中的轻量化革命
计算机视觉基础|轻量化网络设计:MobileNetV3
计算机视觉基础|数据增强黑科技——AutoAugment
计算机视觉基础|数据增强黑科技——MixUp
计算机视觉基础|数据增强黑科技——CutMix
计算机视觉基础|卷积神经网络:从数学原理到可视化实战
计算机视觉基础|从 OpenCV 到频域分析
-
机器学习核心算法系列文章
解锁机器学习核心算法|神经网络:AI 领域的 “超级引擎”
解锁机器学习核心算法|主成分分析(PCA):降维的魔法棒
解锁机器学习核心算法|朴素贝叶斯:分类的智慧法则
解锁机器学习核心算法 | 支持向量机算法:机器学习中的分类利刃
解锁机器学习核心算法 | 随机森林算法:机器学习的超强武器
解锁机器学习核心算法 | K -近邻算法:机器学习的神奇钥匙
解锁机器学习核心算法 | K-平均:揭开K-平均算法的神秘面纱
解锁机器学习核心算法 | 决策树:机器学习中高效分类的利器
解锁机器学习核心算法 | 逻辑回归:不是回归的“回归”
解锁机器学习核心算法 | 线性回归:机器学习的基石
-
深度学习框架探系列文章
深度学习框架探秘|TensorFlow:AI 世界的万能钥匙
深度学习框架探秘|PyTorch:AI 开发的灵动画笔
深度学习框架探秘|TensorFlow vs PyTorch:AI 框架的巅峰对决
深度学习框架探秘|Keras:深度学习的魔法钥匙
相关文章:
计算机视觉|ViT详解:打破视觉与语言界限
一、ViT 的诞生背景 在计算机视觉领域的发展中,卷积神经网络(CNN)一直占据重要地位。自 2012 年 AlexNet 在 ImageNet 大赛中取得优异成绩后,CNN 在图像分类任务中显示出强大能力。随后,VGG、ResNet 等深度网络架构不…...

//定义一个方法,把int数组中的数据按照指定的格式拼接成一个字符串返回,调用该方法,并在控制台输出结果
import java.util.Scanner; public class cha{ public static void main(String[] args){//定义一个方法,把int数组中的数据按照指定的格式拼接成一个字符串返回,调用该方法,并在控制台输出结果//eg: 数组为:int[] arr…...

Python快捷手册
Python快捷手册 后续会陆续更新Python对应的依赖或者工具使用方法 文章目录 Python快捷手册[toc]1-依赖1-词云小工具2-图片添加文字3-BeautifulSoup网络爬虫4-Tkinter界面绘制5-PDF转Word 2-开发1-多线程和队列 3-运维1-Requirement依赖2-波尔实验室3-Anaconda3使用教程4-CentO…...

QT5 GPU使用
一、问题1 1、现象 2、原因分析 出现上图错误,无法创建EGL表面,错误=0x300b。申请不上native window有可能是缺少libqeglfs-mali-integration.so 这个库 3、解决方法 需要将其adb push 到小机端的/usr/lib/qt5/plugins/egldeviceintegrat…...

如何在Spring Boot中读取JAR包内resources目录下文件
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 以下是如何在Spring Boot中读取JAR包内resources目录下文件的教程,分为多种方法及详细说明: 方法1:使用 ClassPathResour…...

《张一鸣,创业心路与算法思维》
张一鸣,多年如一日的阅读习惯。 爱读人物传记,称教科书式人类知识最浓缩的书,也爱看心理学,创业以及商业管理类的书。 冯仑,王石,联想,杰克韦尔奇,思科。 《乔布斯传》《埃隆马斯…...

SSE 和 WebSocket 的对比
SSE 和 WebSocket 的对比 在现代Web开发中,实时通信是提升用户体验的重要手段。Server-Sent Events(SSE)和WebSocket是两种实现服务器与客户端之间实时数据传输的技术,但它们在功能、适用场景以及实现方式上有所不同。 1. 基本概…...

es如何进行refresh?
在 Elasticsearch 中,refresh 操作的作用是让最近写入的数据可以被搜索到。以下为你介绍几种常见的执行 refresh 操作的方式: 1. 使用 RESTful API 手动刷新 你可以通过向 Elasticsearch 发送 HTTP 请求来手动触发 refresh 操作。可以针对单个索引、多个索引或者所有索引进…...
Kubespray部署企业级高可用K8S指南
目录 前言1 K8S集群节点准备1.1 主机列表1.2 kubespray节点python3及pip3准备1.2.1. 更新系统1.2.2. 安装依赖1.2.3. 下载Python 3.12源码1.2.4. 解压源码包1.2.5. 编译和安装Python1.2.6. 验证安装1.2.7. 设置Python 3.12为默认版本(可选)1.2.8. 安装pi…...

【实战篇】【深度解析DeepSeek:从机器学习到深度学习的全场景落地指南】
一、机器学习模型:DeepSeek的降维打击 1.1 监督学习与无监督学习的"左右互搏" 监督学习就像学霸刷题——给标注数据(参考答案)训练模型。DeepSeek在信贷风控场景中,用逻辑回归模型分析百万级用户数据,通过特征工程挖掘出"凌晨3点频繁申请贷款"这类魔…...
优选算法的智慧之光:滑动窗口专题(二)
专栏:算法的魔法世界 个人主页:手握风云 目录 一、例题讲解 1.1. 最大连续1的个数 III 1.2. 找到字符串中所有字母异位词 1.3. 串联所有单词的子串 1.4. 最小覆盖子串 一、例题讲解 1.1. 最大连续1的个数 III 题目要求是二进制数组&am…...
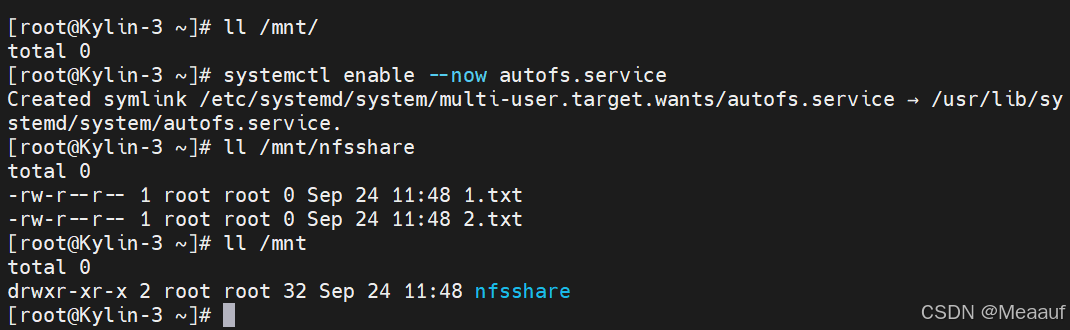
Kylin麒麟操作系统服务部署 | NFS服务部署
以下所使用的环境为: 虚拟化软件:VMware Workstation 17 Pro 麒麟系统版本:Kylin-Server-V10-SP3-2403-Release-20240426-x86_64 一、 NFS服务概述 NFS(Network File System),即网络文件系统。是一种使用于…...
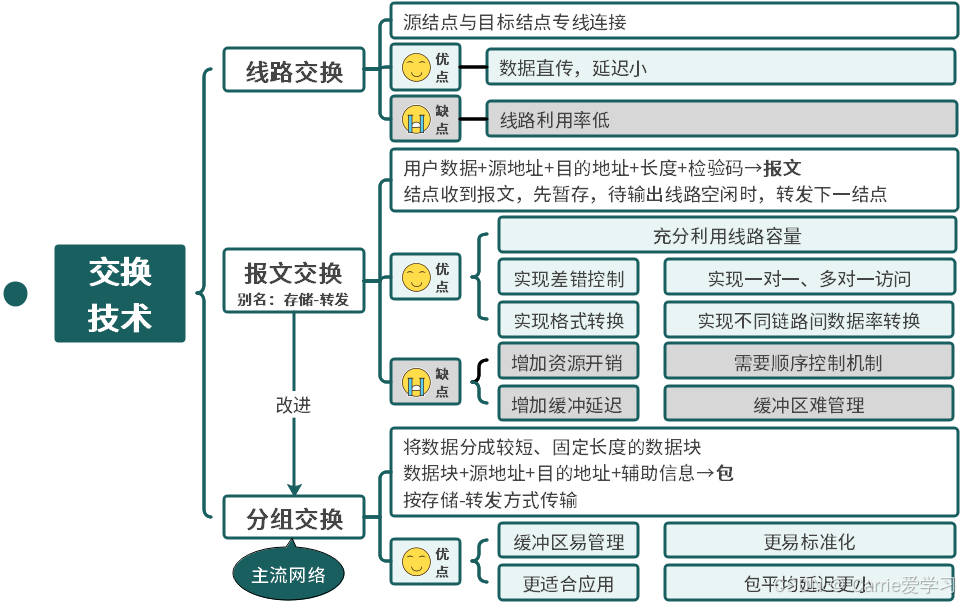
7.1.2 计算机网络的分类
文章目录 分布范围交换方式 分布范围 计算机网络按照分布范围可分为局域网、广域网、城域网。局域网的范围在10m~1km,例如校园网,网速高,主要用于共享网络资源,拓扑结构简单,约束少。广域网的范围在100km,例…...

Spring Cloud Alibaba 实战:轻松实现 Nacos 服务发现与动态配置管理
1. Nacos 介绍 1.1 什么是 Nacos? Nacos(Naming and Configuration Service)是阿里巴巴开源的一个服务注册中心和配置管理中心。它支持动态服务发现、配置管理和服务治理,适用于微服务架构,尤其是基于 Spring Cloud …...
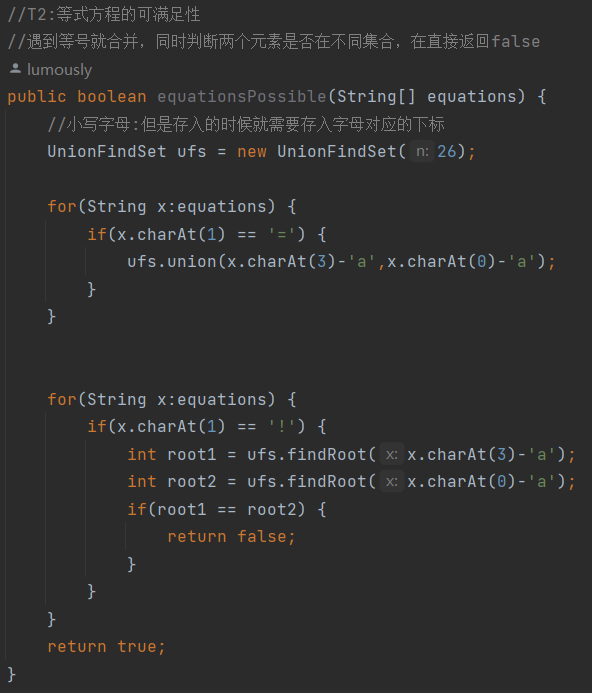
【数据结构】LRUCache|并查集
目录 一、LRUCache 1.概念 2.实现:哈希表双向链表 3.JDK中类似LRUCahe的数据结构LinkedHashMap 🔥4.OJ练习 二、并查集 1. 并查集原理 2.并查集代码实现 3.并查集OJ 一、LRUCache 1.概念 最近最少使用的,一直Cache替换算法 LRU是Least Recent…...

智能合约中权限管理不当
权限管理不当 : 权限管理不当是智能合约中常见的安全问题之一,尤其是在管理员或特定账户被过度赋予权限的情况下。如果合约中的关键功能,如转移资产、修改合约状态或升级合约逻辑,可以被未经授权的实体随意操作,这将构…...

MariaDB Galera 原理及用例说明
一、底层原理 MariaDB Galera 集群是一种基于同步多主架构的高可用数据库解决方案,适合需要高并发、低延迟和数据强一致性的场景。以下是部署和配置 MariaDB Galera 集群的简明步骤: 1. 环境准备 节点要求:至少 3 个节点(奇数节点…...

【RAG 篇】万字长文:向量数据库选型指南 —— Milvus 与 FAISS/Pinecone/Weaviate 等工具深度对比
大家好,我是大 F,深耕AI算法十余年,互联网大厂技术岗。分享AI算法干货、技术心得。 欢迎关注《大模型理论和实战》、《DeepSeek技术解析和实战》,一起探索技术的无限可能! 文章目录 向量数据库的核心价值主流工具横向对比 FAISS:Meta 的高效检索引擎Pinecone:全托管商业…...

关于服务器cpu过高的问题排查
1.定位是哪个程序造成的cpu过高 如果有云服务器,就用云服务器自带的监控功能,查时间段 如果没有,则使用: ps -eo pid,comm,pcpu,pmem,cputime --sort-cputime | head -n 100 2.定位到问题 发现是uwsgi的cpu消耗过高࿰…...
Gpt翻译完整版
上一篇文章收到了很多小伙伴的反馈,总结了一下主要以下几点: 1. 说不知道怎么调api 2. 目前只是把所有的中文变成了英文,如果想要做多语言还需要把这些关键字提炼出来成放到message_zh.properties和message_en.properties文件中,…...

STM32 的IIC通信接收和发送详解
STM32 的 IIC 通信:IIC 接收和发送详解 1. 前言 IIC,也常写作 I2C,是单片机开发中非常常用的一种同步串行通信协议。 在 STM32 项目中,很多外设模块都会使用 IIC 通信,例如: OLED 显示屏;EEPROM…...

MCP服务器构建指南:安全连接AI与外部工具的核心架构与实战
1. 项目概述:MCP服务器生态的构建者如果你最近在关注AI智能体开发,尤其是围绕Claude、Cursor这类工具的生态,那么“MCP”这个词大概率已经在你耳边出现了无数次。ViswaSrimaan/mcp_servers这个项目,正是这个新兴浪潮中的一个关键基…...
)
仅限前500名开发者获取:ElevenLabs内部情绪标注规范PDF(含惊讶语音的12维声学特征定义表+标注样例音频)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs惊讶情绪语音的声学本质与认知基础 惊讶情绪在语音合成中并非简单提升音高或加快语速,而是涉及多维声学参数的协同调制。ElevenLabs 的情感语音模型通过微分频带能量分布、瞬态基…...

终极解决方案:3分钟免费恢复微信网页版完整访问权限
终极解决方案:3分钟免费恢复微信网页版完整访问权限 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无法登录而烦恼吗&am…...

独立开发者如何利用Taotoken管理多个项目的AI密钥与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken管理多个项目的AI密钥与用量 作为独立开发者,你可能同时维护着多个项目,例如一…...

开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由
开源阅读鸿蒙版:打造你的专属数字图书馆,重获阅读自由 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony 你是否厌倦了在多个阅读应用间来回切换?是否对层出不穷的广告…...

代码生成器设计原理与实战:从模板引擎到自动化开发
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫xintaofei/codeg。乍一看这个名字,可能有点摸不着头脑,codeg是啥?是“代码生成器”的缩写吗?还是某种新的开发工具?点进去研究了一番&#x…...

窗口尺寸自由掌控:SRWE如何让任意程序窗口随心所欲
窗口尺寸自由掌控:SRWE如何让任意程序窗口随心所欲 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为某个应用程序的固定窗口尺寸感到束手无策?想在高分辨率下截图却受限于游戏设…...

BilibiliDown:跨平台B站视频下载完整解决方案实战指南
BilibiliDown:跨平台B站视频下载完整解决方案实战指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/b…...

联想拯救者工具箱:开源替代方案实现笔记本性能优化与硬件控制
联想拯救者工具箱:开源替代方案实现笔记本性能优化与硬件控制 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 联…...